1、問題を特定
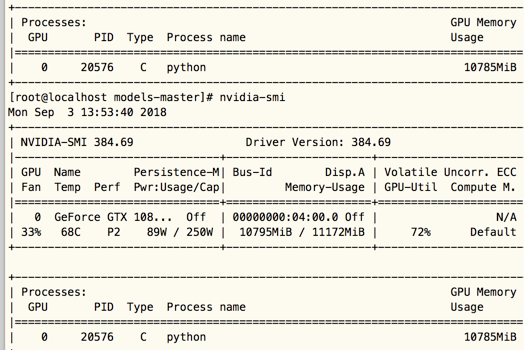
現時点ではモデルの列車は約11秒かかり、間違いなくGPUの呼び出しに成功はありません

GPUは成功したコール、NVIDIA-SMI、かどうか解釈のnvidia-SMIコマンド
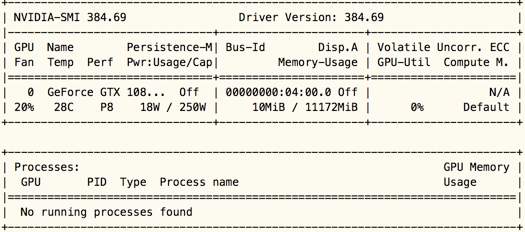
実行中のプロセスでは見つかりませGPU、GPUは、問題が何であるか、呼び出されませんされていませんか?次の理由を見つける必要があり、私たちが最初に考えたtensorflowバージョンGPU版かどうかです。
2、表示tensorflowバージョン
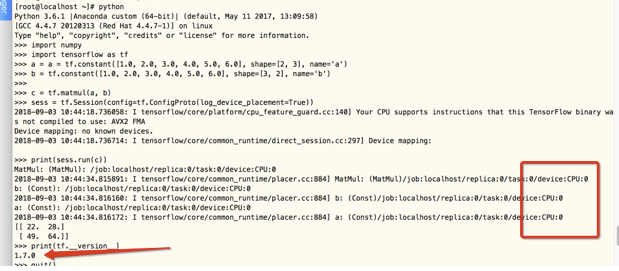
デフォルトの表示はtensorflowバージョン1.7.0その後、CPUと呼ばれ、また、GPUのCUDAを呼び出し、時間のチェックにcudnn関連が発見します

次のCUDAを表示するには、私たちの最初のバージョン
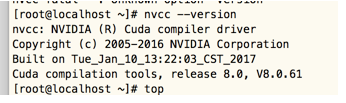
バージョン8.0、そして我々はtensorflowバージョンの競合があるかどうかを見て、参照:TensorFlow GPUバージョンの概要

9.0版CUDAされる表示バージョン1.5以降、および当社tensorflowバージョン1.7、理論的には以上の9.0 CUDAを必要とする、今2つのアイデアがあります。
1、バージョンをアップグレードCUDA。
2、tensorflowバージョンをダウングレード。
少し早いインターネットをチェック、のは、思考の最初の2種類を使用してみましょう、あなたが遭遇する可能性のある問題が、よりになりますアップグレードCUDA
3、バージョン1.4へのダウングレードtensorflow
tensorflow-GPUの== 1.4.0をインストールするPIP
テストの実行は、CPUやGPUであります
輸入numpyの
TFとしてインポートtensorflow
a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a')
b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2], name='b')
c = tf.matmul(a, b)
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
print(sess.run(c))
之后就会出现详细的信息:

然后设置train.py里面的文件,不同模块找不同模块的train.py文件,在object_detection模块修改一下内容:

修改为False即可,在运行模块,可以发现速度快了很多
服务器终端输入:nvidia-smi,发现已经有相关GPU的进程在跑