ダウンロードしてインストールします。https://www.elastic.co/cn/downloads/
コンセプト
ElasticSearchは、分散、拡張性の高い、高リアルタイム検索とでデータ分析エンジン。検索、分析および探査で大量のデータを作るのは簡単です。ElasticSearch伸縮性の完全な利用レベルは、本番環境ではより多くの貴重なデータになることができます。次のステップに分けElasticSearchの原理は、すべてのユーザーデータの最初は、弾性検索データベースに送信され、その後、対応するワード文ワードコントローラを介して、その重量及びその結果は、データ・ワード、ユーザが検索に格納されています時間データは、その後、重量ランク、スコアリングの結果に基づいてされ、その後、ユーザに結果を返します。根底にあるのLuceneに基づきます。
ElasticsearchはLogstashデータ収集と分析と分析エンジンを記録し、Kibanaと呼ばれる可視化プラットフォーム共同開発と呼ばれています。これらの3つの製品は、「弾性スタック」(旧称「ELKスタック」)と呼ばれる統合ソリューションを、できるように設計されています。
反転フルテキスト検索、インデックス(概略図)
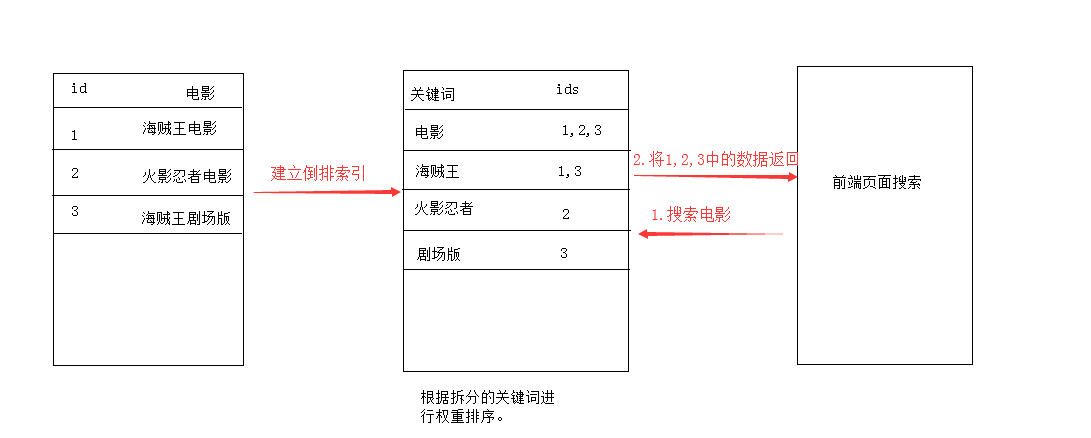
luceneの
luceneのは、私たちはJavaの開発を使用する際に、様々なアルゴリズムを含む逆索引、および検索コードを、作成含まれているJARパッケージ、(パッケージ多様であるのLuceneジャーの導入、その後のLucene APIに基づいて開発されていますluceneのを使用することができ、我々は既存のデータのインデックス付けに行くことができ、Luceneのは、我々の組織のインデックスデータ構造に、上記のローカルディスクになります。一部の機能に加えて、我々はまた、luceneの提供およびAPIは、ディスクのために来て使用することができます検索用のインデックスデータ。
Elasticsearch
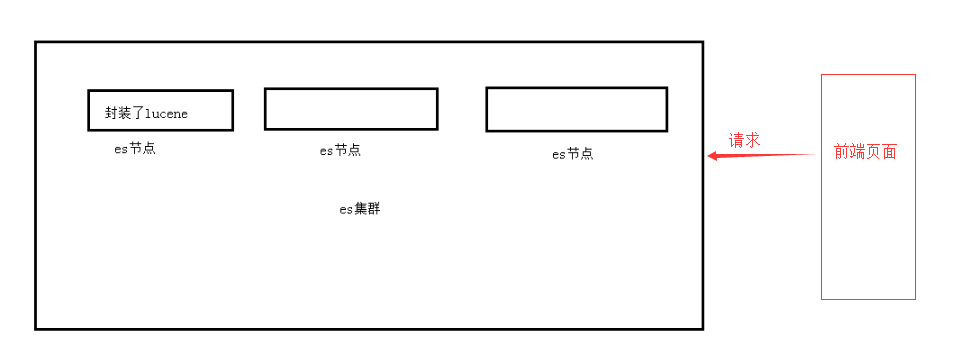
1.自动维护数据的分布到多个节点索引的建立,还有搜索请术分布到多个节点的执行
2.自动维护数据的冗余副本,包证说,一些机器宕机了,不会丢失任何的数据
3.封装了更多的高级功能,以给我们提供更多高级的支持,让我们快速的开发应用,开发更加复杂的应用,复杂的搜索功能,聚合分析的功能,基于地理位置的搜素(距离我当前位置1公里以内的烤内店)
shard和replica
shard:单机器无法存储大量数据,es可以将一个索引中的数据切分为多个shard,分布在多台服务器上存储。有了shard就可以横向扩展,存储更多数据,让搜索和分析等操作分不到多态服务器上去执行,提高吞吐量和性能。,每一个share都是一个Lucene index
replica:任何服务器随时可能故障或宕机,此时shard可能就会丢失,因此可以为每个shard创建多个replica副本。replica可以在shard故障时提供备用服务,保证数据不丢失,多个replica还可以提供检索操作的吞吐量和性能。primary share(建立索引时一次设置,不能修改,默认5个),replica shard(随时修改数重,默认1个,默认每个索引10个shard,5个primary shard,5个replica shard,最小的高可用配置,是2台服务器。
index和type和document
ES中document相当数据库中的一行。
ES中的type相当数据库中的表
ES中的index相当数据库中的数据库
使用
windows启动
启动命令(进入bin目录)
elasticsearch.bat
如果出现
ElasticsearchException[X-Pack is not supported and Machine Learning is not available for [windows-x86]; you can use the other X-Pack features (unsupported) by setting xpack.ml.enabled: false in elasticsearch.yml错误
解决:在elasticsearch.yml配置文件最后添加,重新启动
xpack.ml.enabled: false
访问浏览器
http://127.0.0.1:9200/
出现,表示启动陈宫
{
"name" : "xxxx-PC", //表示node(节点名称):在哪一台服务器上启动
"cluster_name" : "elasticsearch", //集群名称,如果需要修改,在conf/elasticsearch.yml中修改
"cluster_uuid" : "SSOU_2kJSW6xsHZFwfLrhg",
"version" : {
"number" : "7.2.0",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "508c38a",
"build_date" : "2019-06-20T15:54:18.811730Z",
"build_snapshot" : false,
"lucene_version" : "8.0.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
使用kibana
Kibana是一个开源的分析和可视化平台,设计用于和Elasticsearch一起工作。
启动(bin目录下)
kabana.bat
打开浏览器
http://localhost:5601
使用开发工具(dev tools)操作下面的命令
集群操作
GET /_cluster/health GET _cat/health?v 查看集群健康状况,status="green":表示每个索引的primary shard和replica shard都是active状态的 ="yellow": 表示每个索引的primary shard是active,但是部分replica shard都是不是active状态的 ="red":表示不是所有索引的primary shard是active,部分索引有数据丢失。 GET _cat/indices?v 快速查看集群中索引的情况 PUT /index_test?pretty 新建索引 index_test:测试的索引名 DELETE /index_test 删除index_test索引
数据的crud
put /index/type/id
{
"json数据"
}
示例:
PUT /test/test1/1 es会自动创建index和type
{
"name":"zy"
}