K平均クラスタリング
n個の観測値は、k個のクラスタに分類し、特定の基準(類似のデータ点)、(分割されたユーザ、製品カテゴリ、等)に応じて、ポイント。
主要コンセプト:重心


K平均クラスタリング変数の距離を計算しやすい数値変数要件です。
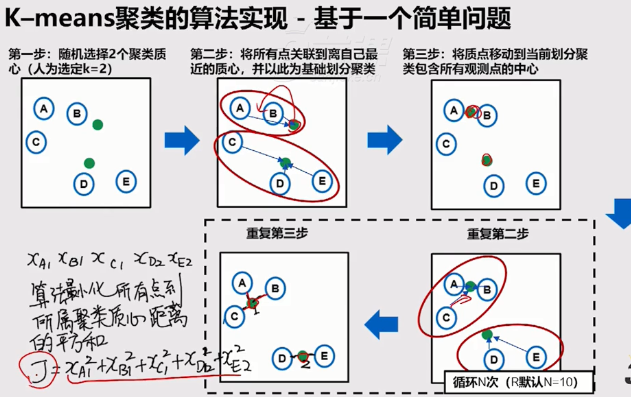
アルゴリズム
R言語
K平均アルゴリズムは、距離値に変換され、距離測定のクラスタリングされています。いいえ正規化は、距離が非常に遠く離れて作るんだろう。
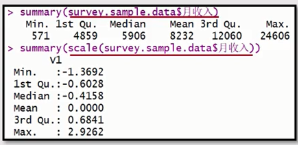
補足:重要性の尺度の正規化
こうした違いの年齢や収入値として、2つの変数間の数値に大きな違いは非常に充実しています。
ステップ

クラスタの数、すなわち、kの値を決定する最初のステップ
方法:肘のルール+実際のビジネス・ニーズ

第二段階は、K-means法のモデルを実行します

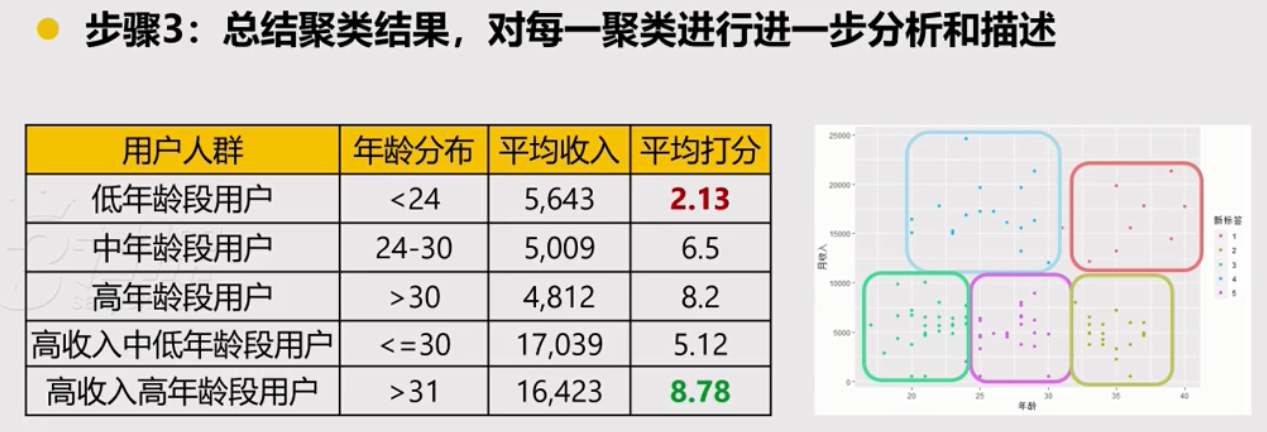
第3のステップは、クラスタモデルの結果を要約します