(II)HDFSデータストリーム
ファイルシステムとしては、ファイルを読み書きすることは、最も基本的なニーズである、私達の顧客のこの部分は、HDFSと対話する方法を理解することです、それは、クライアントとHDFSで、ノード(名前ノードとデータノード)の2種類で構成さHDFS何の間のデータフロー。
1、ドキュメントの読み取り処理を解析します
ファイルから読み込んHDFSクライアントは、内部の読み取り処理が実際にはより複雑になり、図の次の基本的な流れで表すことができるファイルをお読みください。
クライアントの場合は、まず最初に、ファイルシステムオブジェクトの呼び出すことです読みたいファイルを開くには、open()メソッドを、そしてDFSは、クライアントへの入力ストリームはファイル入力ストリームFSDataInputStream返すread()メソッドは、データを読み込む呼び出して、読み取りが完了すると、これに入力ストリームコールclose()メソッドは、図1,3,6に対応するステップのこれらの3つの処理を終了します。
HDFS内のファイルの読み出しを実現するために、実際には、分析するためのクライアントの観点から、上記の3つのステップは、より複雑なメカニズムをサポートする必要がある、とこれらのプロセスは、クライアントに対して透過的ですので、クライアントの感触顧客が連続した流れを読んでいるかのように、それはそうです。
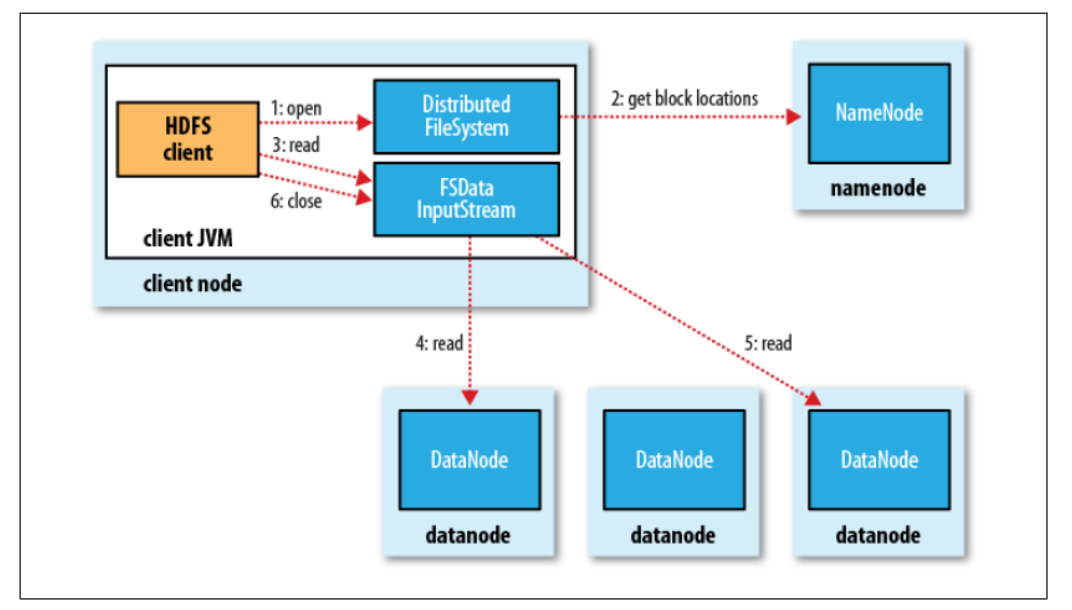
具体的には、HDFSの観点から、オープン・クライアントがオブジェクトファイルシステム()メソッドを呼び出し、オブジェクトが実際にファイルシステムは、ファイルシステムを配布され、分散ファイルの一例であり、分散ファイルは、リモートプロシージャコール(RPC)を介して行うことに、名前ノードを呼び出しファイルの開始ブロックの位置が取得される(ステップ2、データブロックコピーの存在名前ノードデータノードリターンアドレス)。クライアント場合はもちろん、HDFSの複数のコピーがデータ・ブロックを保存したので(デフォルトは3)、要求は一つのアドレスより満足データノードであり、その後、クライアントからの距離に応じて距離の近くに嗜好データノードをソートします(:ここでローカリゼーションデータの利点の使用についてのMapReduceなど)自体で端部がデータノードで、クライアントは、ローカルからデータを読み出すことができます。
openメソッドの完了後、DistributedFileSystemクラスが返さFSDataInputStreamファイル入力ストリームオブジェクトをクライアントに。このクラスは、順番に名前ノードのデータノードとI / Oを管理しDFSInputStreamオブジェクトとしてカプセル化
このDFSInputStreamファイルが開始アドレスのデータノードいくつかのブロックを格納し、そのため、クライアントはそう繰り返し呼び出さ、入力ストリーム()メソッドは、データを読み取るためにどのデータノード(最新のネットワークトポロジの距離)に知るために使用することができますの読み取りを呼び出しますこの方法は、クライアント(ステップ4)にデータノードからデータを読み出すことができます。ブロックの終わりに達すると、次の最高のブロックデータノードの検索データノード接続を閉じると、プロセスを繰り返します。
必要に応じてもちろん、私たちは、読み取り処理に始まる保存されているDFSInputStream上のファイルの数ブロックを述べ、また、データのデータノードアドレスブロックの次のバッチを取得するために再び名前ノードをお願いします。クライアントが読み取りを完了すると、それはcloseメソッドは、ストリームを閉じます呼び出します。
読み取り処理した場合、データノード経験障害は、それだけで別の最近保存されたデータノードからの入力ストリームは、障害データノードが、後にそこからのデータ読み出しを避けることを念頭に、データ・ブロックのコピーを読むことができることは明らかです。
要約:
:これらは、このプロセスの分析から、我々が見ることができる、HDFSの文書の読み取り処理されているクライアントは、データノードに直接接続することの利点は、データを読み、別のデータノードに分散したデータから、同時にできるように同時クライアントサービスの数が多いです。管理ノードのみ応答要求データ・ブロック位置として名前ノードは、クライアントは、各データブロック最良のデータノードに知らせることができる(メモリに格納されたデータノードの位置情報を、非常に効率的に得ることができます)。これは、特定のデータ伝送作業を必要とせずに名前ノードになり、そうでない状況のクライアント数で名前ノードがボトルネックになります。
2、ファイル書き込みプロセスの分析
次に、我々はファイルの作成プロセスを分析し、重要な考慮事項は、ファイルにデータを書き込み、最後にファイルを閉じる方法を、ケースは新しいファイルを作成する方法です。
クライアントの観点から、このプロセスは比較的単純である、同様に、最初のDistributedFileSystemに呼び出して新しいファイルを作成するためのオブジェクト()メソッドを作成し、クライアントが呼び出すことができるFSDataOutputStreamファイル出力ストリームオブジェクトを返します書き込みデータ出力ストリーム()メソッドを書いた後、書き込みが出力ストリームのclose()メソッドを閉じる(チャートで1,3,6の手順)を呼び出して、完成されています。
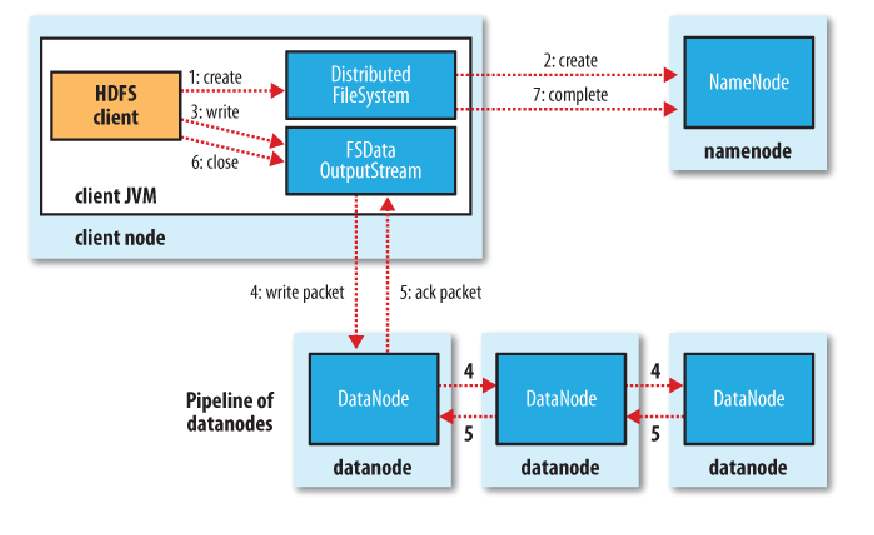
然而,具体的,从HDFS的角度来看,这个写数据的过程就相当复杂了。客户端在调用create方法新建文件时,DistributedFileSystem会对namenode创建一个RPC调用,在文件系统的命名空间中新建一个文件,此时还没有相应的数据块(步骤2)。namedata接收到这个RPC调用后,会进行一系列的检查,确保这个文件不存在,并且这个客户端有新建文件的权限,然后再通过检查后就会为这个新文件在命名空间中加入一条记录(如果未通过检查则会返回异常),最后给客户端返回一个FSDataOutputStream对象。
类似于文件读的过程,这个FSDataOutputStream对象转而封装成为一个DFSOutputStream对象,用于处理datanode和namenode之间的I/O。
接下来,客户端就可以调用输出流的write()方法进行数据写入,而在写入时,DFSOutputStream将数据分为一个一个的数据包,先写入内部队列,称为“数据队列”。然后有一个单独的DataStreamer来处理数据队列,它的职责是挑选出适合存储数据副本的一组datanode,并要求namenode分配新的数据块。假设副本数为3,那么选出来的datanode就是3个,这3个dadanode会构成一个数据管线。DataStreamer将数据包流式传输到管线中的第一个datanode,第一个存储并发到第二个,第二个存储并发到第三个(步骤4)。
然后DFSOutputStream对象内部还有一个数据包队列用于接收datanode的确认回执,称为“确认队列”,收到所有datanode的确认消息后,该数据包才会从队列中删除。
在客户端完成数据的写入后,对数据流调用close()方法(步骤6),该操作将剩余的所有数据包写入数据管线,并联系namenode告知文件写入完成之前,等待确认(步骤7)。
3、一致模型
HDFS的一致模型描述了文件读、写的数据可见性。
基于以上对文件读写过程的分析,我们知道新建一个文件之后,它可以在命名空间中立即可见,但是即使数据流已经刷新并存储,写入文件的内容并不保证能立即可见。当写入的数据超过一个数据块后,第一个数据块对新的reader就是可见的,也就是说:当前正在写的块对其他reader不可见。
HDFS提供了一种将所有缓存刷新到datanode中的方法,即对FSDataOutputStream调用hflush()方法,当hflush方法调用成功后,到目前为止写入的数据都到达了datanode的写入管道并且对所有reader可见。
但是,hflush()并不保证数据已经都写到磁盘上,为确保数据都写入磁盘,可以使用hsync()操作代替。
在HDFS中,close方法实际上隐含了执行hflush()方法。
4、通过distcp并行复制
当我们想从Hadoop文件系统中复制大量数据或者将大量数据复制到HDFS中时,可以采用Hadoop自带的一个程序distcp,它用来并行复制。
distcp的一个用法是代替hadoop fs -cp,也可以用来在两个HDFS集群之间传输数据。
$ hadoop distcp file1 file2
$ hadoop distcp dir1 dir2
$ hadoop distco -update -delete -p hdfs://namenode1/foo hdfs://namenode2/foo总结
以上主要对HDFS文件系统的文件读写进行了详细的介绍,重点是掌握HDFS的文件读写流程,体会这种机制对整个分布式系统性能提升带来的好处。