
検索アプリケーションでは、従来のキーワード検索が常に主要な検索方法であり、完全に一致するクエリのシナリオに適しており、待ち時間が短く、結果の解釈性が良好です。ただし、キーワード検索ではコンテキスト情報が考慮されないため、無関係な結果が生成される可能性があります。近年、ベクトル検索技術に基づく検索強化技術であるセマンティック検索がますます普及しており、機械学習モデルを使用してデータ オブジェクト (テキスト、画像、オーディオ、ビデオなど) をベクトル距離で表します。オブジェクト間の類似性。使用されるモデルが問題領域との関連性が高い場合、多くの場合、コンテキストと検索意図をよりよく理解できるため、検索結果の関連性が向上します。問題の領域に到達すると、効果は大幅に減少します。
キーワード検索とセマンティック検索には明らかな長所と短所がありますが、それらの長所を組み合わせることで検索全体の関連性を向上させることはできるでしょうか?答えは、次の 2 つの主な理由により、単純な算術の組み合わせでは期待される結果を達成できないということです。
-
まず、異なるタイプのクエリのスコアは同じ比較可能な次元にないため、単純な算術計算を直接実行することはできません。
-
第 2 に、分散検索システムでは、スコアは通常シャード レベルであり、すべてのシャードのスコアをグローバルに正規化する必要があります。
要約すると、これらの問題を解決するには、各クエリ句を個別に実行し、シャード レベルでクエリ結果を収集し、最後にすべてのクエリのスコアを正規化してマージして最終結果を返す、理想的なクエリ タイプを見つける必要があります。ハイブリッド検索ソリューションです。
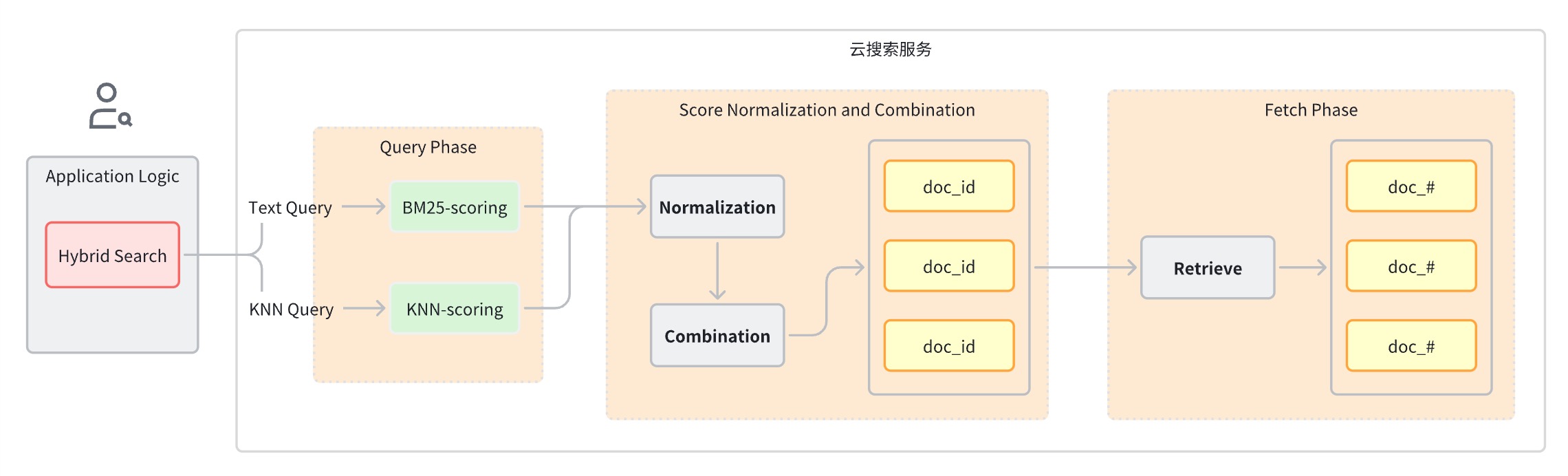
通常、ハイブリッド検索クエリは次の手順に分割できます。
-
クエリ フェーズ: キーワード検索とセマンティック検索に混合クエリ句を使用します。
-
スコアの正規化と結合ステージ。クエリ ステージに続きます。
-
各クエリ タイプは異なる範囲のスコアを提供するため、このステージでは各クエリ句のスコア結果に対して正規化操作を実行します。サポートされている正規化メソッドは min_max、l2、および rrf です。
-
正規化されたスコアを結合するための結合方法には、arithmetic_mean、geometric_mean、およびharmonic_meanが含まれます。
-
-
ドキュメントは、結合された評価に基づいて並べ替えられ、ユーザーに返されます。
実装のアイデア
これまでの原則の紹介から、ハイブリッド検索アプリケーションを実装するには、少なくともこれらの基本的な技術的機能が必要であることがわかります。
-
全文検索エンジン
-
ベクトル検索エンジン
-
ベクトル埋め込み用の機械学習モデル
-
テキスト、オーディオ、ビデオ、その他のデータをベクトルに変換するデータ パイプライン
-
フュージョンソーティング
Volcano Engine クラウド検索は、オープン ソースの Elasticsearch プロジェクトと OpenSearch プロジェクトに基づいて構築されており、開始初日から完全かつ完成度の高いテキスト検索機能とベクトル検索機能をサポートしています。同時に、一連の機能の反復も実行されています。ハイブリッド検索シナリオの進化により、すぐに使えるハイブリッド検索ソリューションが提供されます。この記事では、画像検索アプリケーションを例として、Volcano Engine クラウド検索サービス ソリューションを利用してハイブリッド検索アプリケーションを迅速に開発する方法を紹介します。

そのエンドツーエンドのプロセスは次のように要約されます。
-
関連オブジェクトの構成と作成
-
インジェスト パイプライン: 画像変換ベクトルをインデックスに保存するためのモデルの自動呼び出しをサポートします。
-
検索パイプライン: 類似度計算のためのテキスト クエリ ステートメントのベクトルへの自動変換をサポートします。
-
k-NN インデックス: ベクトルが格納されるインデックス
-
-
画像データセット データを OpenSearch インスタンスに書き込むと、OpenSearch が機械学習モデルを自動的に呼び出して、テキストを Embedding ベクトルに変換します。
-
クライアントがハイブリッド検索クエリを開始すると、OpenSearch は機械学習モデルを呼び出して、受信クエリを埋め込みベクトルに変換します。
-
OpenSearch は、ハイブリッド検索リクエスト処理を実行し、キーワード検索スコアとセマンティック検索スコアを組み合わせて、検索結果を返します。
実際の戦闘を計画する
環境整備
-
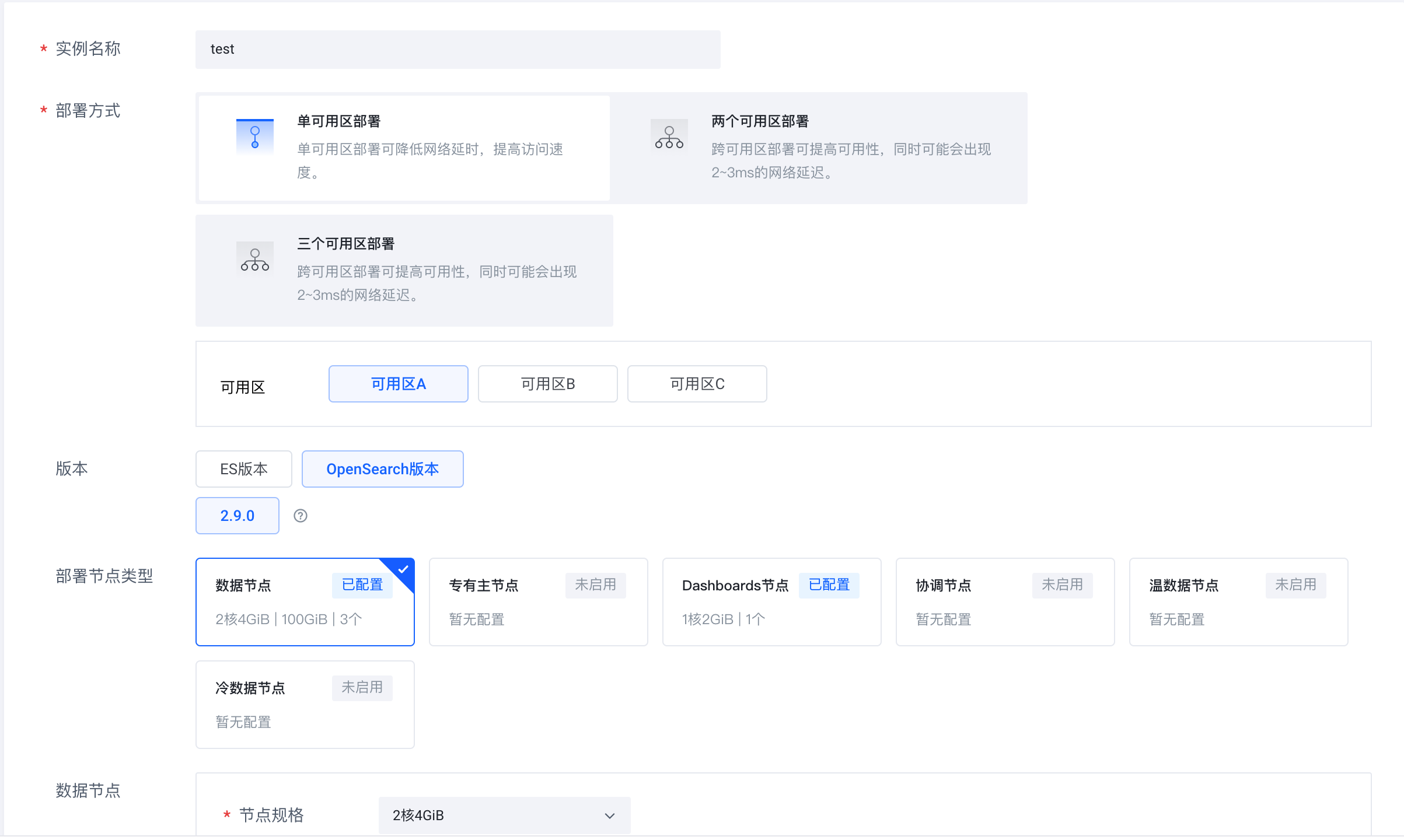
Volcano Engine クラウド検索サービス (https://console.volcengine.com/es) にログインし、インスタンス クラスターを作成し、バージョンとして OpenSearch 2.9.0 を選択します。
-
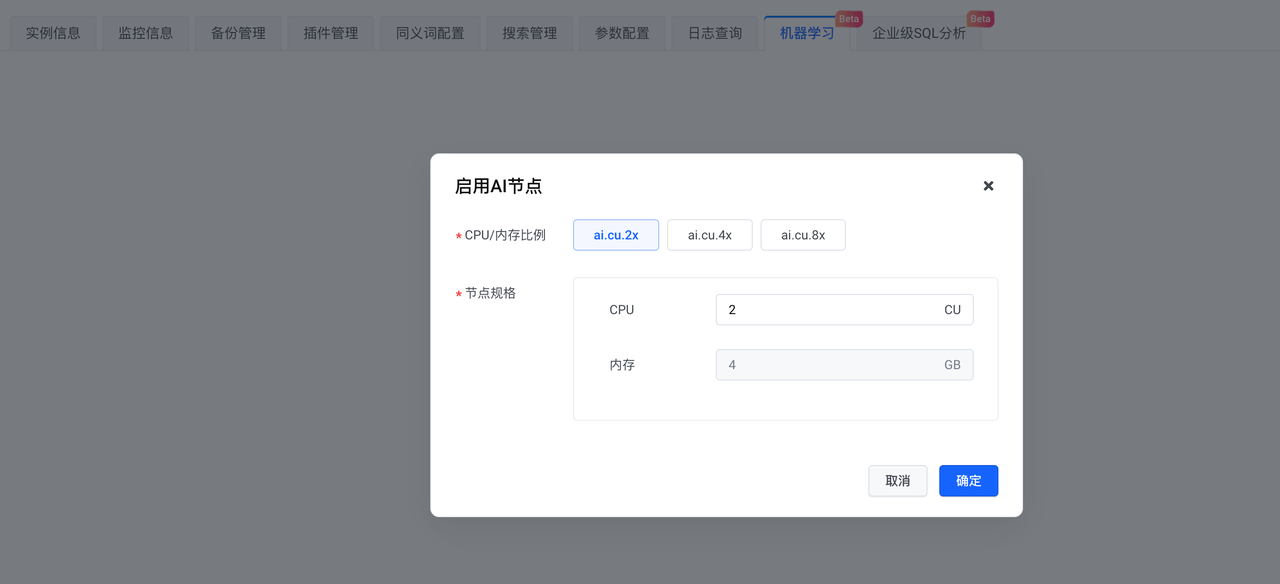
インスタンスが作成されたら、AI ノードを有効にします。
-
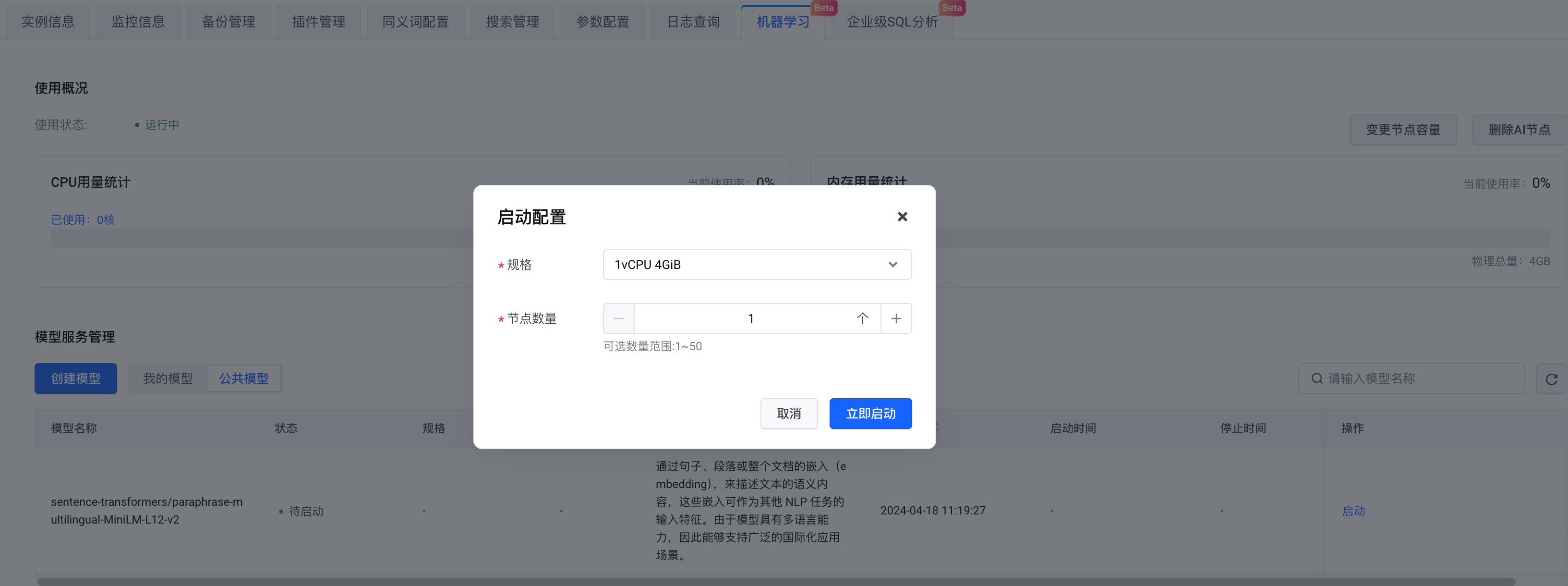
モデルの選択に関しては、独自のモデルを作成することも、公開モデルを選択することもできます。ここでは パブリック モデル を選択します。構成が完了したら、[ 今すぐ開始] を クリックします。
この時点で、ハイブリッド検索が依存する OpenSearch インスタンスと機械学習サービスの準備が整いました。
データセットの準備
データセットとして Amazon Berkeley Objects Dataset (https://registry.opendata.aws/amazon-berkeley-objects/) を使用します。データセットはローカルにダウンロードする必要はなく、コードロジックを通じて OpenSearch に直接アップロードされます。詳細については、以下のコードの内容を参照してください。
ステップ
Python の依存関係をインストールする
pip install -U elasticsearch7==7.10.1
pip install -U pandas
pip install -U jupyter
pip install -U requests
pip install -U s3fs
pip install -U alive_progress
pip install -U pillow
pip install -U ipythonOpenSearch に接続する
# Prepare opensearch info
from elasticsearch7 import Elasticsearch as CloudSearch
from ssl import create_default_context
# opensearch info
opensearch_domain = '{{ OPENSEARCH_DOMAIN }}'
opensearch_port = '9200'
opensearch_user = 'admin'
opensearch_pwd = '{{ OPENSEARCH_PWD }}'
# remote config for model server
model_remote_config = {
"method": "POST",
"url": "{{ REMOTE_MODEL_URL }}",
"params": {},
"headers": {
"Content-Type": "application/json"
},
"advance_request_body": {
"model": "sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2"
}
}
# dimension for knn vector
knn_dimension = 384
# load cer and create ssl context
ssl_context = create_default_context(cafile='./ca.cer')
# create CloudSearch client
cloud_search_cli = CloudSearch([opensearch_domain, opensearch_port],
ssl_context=ssl_context,
scheme="https",
http_auth=(opensearch_user, opensearch_pwd)
)
# index name
index_name = 'index-test'
# pipeline id
pipeline_id = 'remote_text_embedding_test'
# search pipeline id
search_pipeline_id = 'rrf_search_pipeline_test'-
OpenSearch リンクのアドレス、ユーザー名、パスワードの情報を入力します。 model_remote_config は リモート機械学習モデルの接続構成であり、 モデル 呼び出し情報 で確認 できます。 呼び出し情報 内の すべての remote_config構成を model_remote_config に コピーします。
-
[インスタンス情報] - > [サービス アクセス] セクション で 、証明書を現在のディレクトリにダウンロードします。
-
インデックス名、パイプライン ID、および検索パイプライン ID を指定します。
取り込みパイプラインの作成
インジェスト パイプラインを作成し、使用する機械学習モデルを指定し、指定されたフィールドをベクトルに変換して埋め込みます。以下のように、
キャプション
フィールドをベクトルに変換し、
caption_embedding
に格納します。
# Create ingest pipeline
pipeline_body = {
"description": "text embedding pipeline for remote inference",
"processors": [{
"remote_text_embedding": {
"remote_config": model_remote_config,
"field_map": {
"caption": "caption_embedding"
}
}
}]
}
# create request
resp = cloud_search_cli.ingest.put_pipeline(id=pipeline_id, body=pipeline_body)
print(resp)検索パイプラインの作成
クエリに必要なパイプラインを作成し、リモート モデルを構成します。
サポートされている正規化方法と加重合計方法:
-
正規化方法:
min_max、l2、rrf -
重み付け加算方法:
arithmetic_mean、geometric_mean、harmonic_mean
ここでは rrf 正規化方法を選択します。
# Create search pipeline
import requests
search_pipeline_body = {
"description": "post processor for hybrid search",
"request_processors": [{
"remote_embedding": {
"remote_config": model_remote_config
}
}],
"phase_results_processors": [ # normalization and combination
{
"normalization-processor": {
"normalization": {
"technique": "rrf", # the normalization technique in the processor is set to rrf
"parameters": {
"rank_constant": 60 # param
}
},
"combination": {
"technique": "arithmetic_mean", # the combination technique is set to arithmetic mean
"parameters": {
"weights": [
0.4,
0.6
]
}
}
}
}
]
}
headers = {
'Content-Type': 'application/json',
}
# create request
resp = requests.put(
url="https://" + opensearch_domain + ':' + opensearch_port + '/_search/pipeline/' + search_pipeline_id,
auth=(opensearch_user, opensearch_pwd),
json=search_pipeline_body,
headers=headers,
verify='./ca.cer')
print(resp.text)k-NNインデックスの作成
-
事前に作成した取り込みパイプラインを index.default_pipeline フィールドに設定します。
-
同時にプロパティを設定し、 caption_embedding を knn_vector に設定します。ここでは faiss で hnsw を使用します。
# Create k-NN index
# create index and set settings, mappings, and properties as needed.
index_body = {
"settings": {
"index.knn": True,
"number_of_shards": 1,
"number_of_replicas": 0,
"default_pipeline": pipeline_id # ingest pipeline
},
"mappings": {
"properties": {
"image_url": {
"type": "text"
},
"caption_embedding": {
"type": "knn_vector",
"dimension": knn_dimension,
"method": {
"engine": "faiss",
"space_type": "l2",
"name": "hnsw",
"parameters": {}
}
},
"caption": {
"type": "text"
}
}
}
}
# create index
resp = cloud_search_cli.indices.create(index=index_name, body=index_body)
print(resp)データセットをロードする
データセットをメモリに読み取り、使用する必要のあるデータの一部をフィルタリングして除外します。
# Prepare dataset
import pandas as pd
import string
appended_data = []
for character in string.digits[0:] + string.ascii_lowercase:
if character == '1':
break
try:
meta = pd.read_json("s3://amazon-berkeley-objects/listings/metadata/listings_" + character + ".json.gz",
lines=True)
except FileNotFoundError:
continue
appended_data.append(meta)
appended_data_frame = pd.concat(appended_data)
appended_data_frame.shape
meta = appended_data_frame
def func_(x):
us_texts = [item["value"] for item in x if item["language_tag"] == "en_US"]
return us_texts[0] if us_texts else None
meta = meta.assign(item_name_in_en_us=meta.item_name.apply(func_))
meta = meta[~meta.item_name_in_en_us.isna()][["item_id", "item_name_in_en_us", "main_image_id"]]
print(f"#products with US English title: {len(meta)}")
meta.head()
image_meta = pd.read_csv("s3://amazon-berkeley-objects/images/metadata/images.csv.gz")
dataset = meta.merge(image_meta, left_on="main_image_id", right_on="image_id")
dataset.head()データセットをアップロードする
データ セットを Opensearch にアップロードし、各データの image_url とキャプションを渡します。
caption_embedding
を渡す必要はありません 。リモート機械学習モデルを通じて自動的に生成されます。
# Upload dataset
import json
from alive_progress import alive_bar
cnt = 0
batch = 0
action = json.dumps({"index": {"_index": index_name}})
body_ = ''
with alive_bar(len(dataset), force_tty=True) as bar:
for index, row in (dataset.iterrows()):
if row['path'] == '87/874f86c4.jpg':
continue
payload = {}
payload['image_url'] = "https://amazon-berkeley-objects.s3.amazonaws.com/images/small/" + row['path']
payload['caption'] = row['item_name_in_en_us']
body_ = body_ + action + "\n" + json.dumps(payload) + "\n"
cnt = cnt + 1
if cnt == 100:
resp = cloud_search_cli.bulk(
request_timeout=1000,
index=index_name,
body=body_)
cnt = 0
batch = batch + 1
body_ = ''
bar()
print("Total Bulk batches completed: " + str(batch))ハイブリッド検索クエリ
靴
のクエリ を例に挙げます。クエリには 2 つのクエリ句が含まれています。1 つは
match
クエリで、もう 1 つは
remote_neural
クエリです。クエリを実行する場合、以前に作成した検索パイプラインをクエリ パラメーターとして指定します。検索パイプラインは受信テキストをベクトルに変換し、 後続のクエリのために
caption_embedding
フィールドに保存します。
# Search with search pipeline
from urllib import request
from PIL import Image
import IPython.display as display
def search(text, size):
resp = cloud_search_cli.search(
index=index_name,
body={
"_source": ["image_url", "caption"],
"query": {
"hybrid": {
"queries": [
{
"match": {
"caption": {
"query": text
}
}
},
{
"remote_neural": {
"caption_embedding": {
"query_text": text,
"k": size
}
}
}
]
}
}
},
params={"search_pipeline": search_pipeline_id},
)
return resp
k = 10
ret = search('shoes', k)
for item in ret['hits']['hits']:
display.display(Image.open(request.urlopen(item['_source']['image_url'])))
print(item['_source']['caption'])ハイブリッド検索表示

上記では、画像検索アプリケーションを例として、Volcano Engine クラウド検索サービス ソリューションを利用してハイブリッド検索アプリケーションを迅速に開発する方法の実践的なプロセスを紹介しています。皆さん、Volcano Engine コンソールにログインして操作してください。
Volcano Engine クラウド検索サービスは、 Elasticsearch、Kibana、その他のソフトウェアおよび一般的に使用されるオープン ソース プラグインと互換性があり、構造化テキストと非構造化テキストの複数条件の取得、統計、レポートを提供し、ワンクリックで展開できます。スケーリング、運用とメンテナンスの簡素化、分析、情報検索分析、その他のビジネス機能の迅速な構築が可能です。
{{名前}}
{{名前}}