
著者: vivo インターネット ビッグ データ チーム - Huang Guihu、Chen Shengzun
HBase は、高い信頼性、高い拡張性、高性能を備えたオープンソースの分散型非リレーショナル データベースであり、ビッグ データ処理、リアルタイム コンピューティング、データの保存と取得などの分野で広く使用されています。分散クラスターでは、ハードウェア障害がノードまたはクラスターレベルのサービス中断、メタテーブルの損傷、RIT、リージョンホール、オーバーラップなどの問題を引き起こす可能性があり、障害を迅速に修復してビジネスを復元する方法が重要です。この記事は主に、HBase メタ テーブルに関する一般的な障害とそれに対応する解決策について説明します。
1. 背景
HBase の開発、運用、保守関連の仕事をしたことのある友人なら、ある程度この感覚を持っていると思います。HBase は、分散非リレーショナル データベースのリーダーとして、安定性が高く、パフォーマンスが高く、インストールと拡張が非常に簡単であるだけではありません。 、しかし、それには欠けています 成熟した監視システムは、トラブルシューティングには非常に不親切です。 HBase についての包括的な理解が不足している場合、編集者として、バージョン 1.x ~ 2.x を含むさまざまなサイズの 20 以上の HBase クラスターを運用および保守してきました。メタテーブルの破損や正常なオンライン接続の失敗、リージョンの重複など、私たちはリージョンホールやパーミッションの喪失などのオンライン問題に対処してきました。また、さまざまな問題に対してHBaseのソースコードから正しい答えを探してきました。この記事は、編集者が多くの失敗からまとめた、メタ テーブルに対する共通の解決策。
2. HBaseメタメタ情報テーブル
HBase メタ テーブル (カタログ テーブルとも呼ばれます) は、HBase クラスター内のすべてのリージョンと、それに対応するリージョンサーバー情報を保存する特別な HBase テーブルです。メタ情報テーブルのデータ精度は、HBase クラスターの通常の動作にとって非常に重要です。メタ情報テーブル内のデータが正しいことは、クラスターが安定して動作するために必要な条件です。メタ テーブル内のデータに一貫性がない場合、RIT (Region In Transition) が発生したり、HMaster が正常に初期化されなかったりするため、クラスターが正常に起動できなくなります。これは、HBase クラスターにおけるメタ テーブルの重要性を示しています。メタ テーブルの構造、データ形式、それを解析するプロセスを開始します (この記事は主に HBase 2.4.8 バージョンに焦点を当てており、HBase 1.x バージョンも散在します)。
2.1 メタテーブルの構造
メタ テーブルには主に、info、table、rep_barrier という 3 つの列ファミリーが含まれており、それぞれリージョン情報とテーブル ステータスを記録します。
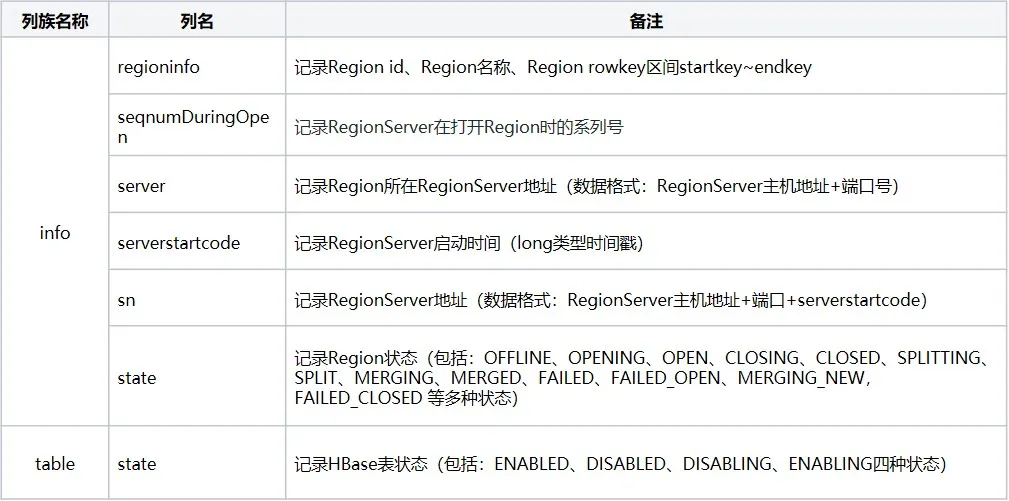
2.2 メタテーブルのロードプロセス
上記のメタ テーブル構造を通じて、HBase の運用とメンテナンスを行った友人は皆、このような経験をしていると考えています。クラスタによっては、起動が遅くなる場合もあれば、場合によってはクラスタが再起動する場合もあります。不適切な操作です。メタテーブルのロード中にスタックし、後続のプロセスを実行できません。メタ テーブルのロード プロセスを全体的に理解していれば、各クラスターの起動時間について多かれ少なかれ心理的な予想ができます。メタ テーブルのロードに関連するプロセスは次のとおりです。
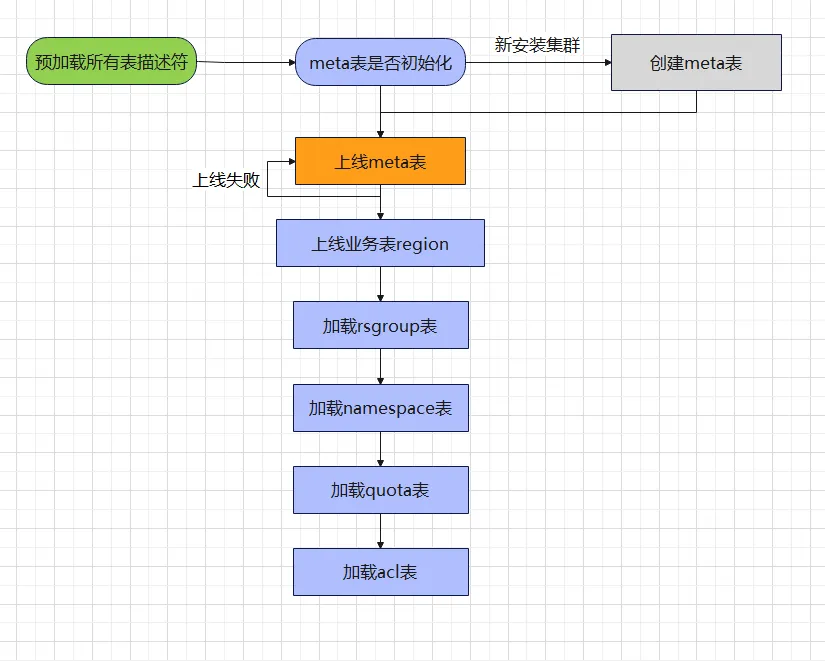
上記のメタ テーブルの読み込みフローチャートを通じて、一部のクラスターの起動が遅く、一部のクラスターが起動に失敗する理由を簡単に見つけることができます。以下では 2 種類のシナリオを分析します。
- クラスターの起動が遅くなります。
通常、新しいクラスターやテーブルの数が少ないクラスターは起動が速くなる傾向がありますが、テーブルの数が多いクラスターは起動にかなり時間がかかる傾向があり、場合によってはクラスターの起動時間が長くなることがあります。クラスターに何か問題があるのですが、なぜこれほど長い間正常な状態にならないのでしょうか?読み込みプロセス全体で時間がかかる箇所が 2 か所あります。
すべてのテーブル記述子をプリロードする: HBase データ ディレクトリ全体をスキャンし、.tabledesc ディレクトリの下にあるデータ ファイルを解析して HMaster メモリに保存する必要があります。テーブルの数が多い場合 (10,000 テーブル以上)、このプロセスが頻繁に行われます。 HMaster ページに「テーブル記述子の事前ロード」という文字が表示されたら、クラスターが事前ロード段階にあることを意味します。メタ テーブルのロード段階がまだ始まっていないため、辛抱強く待つ必要があります。に達しました。
オンライン ビジネス テーブル リージョン: メタ テーブルのデータ サイズは通常、数十 MB から数百 MB の間です。クラスターの起動フェーズでは、オフライン リージョンを確認してオンラインにする必要があります。開く速度を速くしたい場合は、hbase の値 (デフォルトは 5) を適切に調整できます。
- クラスターの起動に失敗しました:
メタ テーブルのオンライン エラー: デフォルトのリソース グループの HRegionServer がハングアップし、再起動後にマシンの開始コードが変更されると、メタ データ シャードが開いているノードを見つけることができず、クラスターの起動に失敗します。
3. メタテーブルを修復する方法
HBase クラスターのステータスは主にメタ テーブルを通じて維持されるため、メタ テーブルが破損したり間違ったりすると、HBase クラスターが使用できなくなり、データ損失のリスクに直面します。メタ テーブルのデータの整合性が非常に重要であることはわかっていますが、どのような状況でデータの不整合が発生するのでしょうか? (HBase 2.4.8 修復コマンドについては、hbase-operator-tools ツールを参照してください)。
-
リージョンサーバーがダウンまたは異常です: リージョンサーバーがダウンまたは異常な場合、メタテーブルに保存されているリージョンおよびリージョンサーバーの情報が正しくないか、失われている可能性があります。
-
データの破損またはエラー: メタ テーブル内のデータが破損しているか正しくない場合、HBase クラスターが利用できなくなり、データが失われる可能性があります。
-
不正な操作: メタ テーブル内のデータの削除や変更など、メタ テーブルに対して不正な操作が実行されると、エラーやメタ テーブルの損失が発生する可能性があります。
メタ テーブルの障害は一般的な用語であり、その種類に応じて、長期 RIT、リージョン ホール、リージョン オーバーラップ、テーブル記述ファイルの損失、メタ テーブルの HDF パスの空、メタ テーブルのデータの損失などに大別できます。これらのタイプの障害については、それぞれ分析して修正します。
3.1 リット
RIT (Region In Transition) は、HBase クラスター内の進行中の状態遷移を指します。たとえば、RegionServer が停止したり、リージョンが分割されたり、結合されたりするなど、HBase クラスター内のリージョンの状態が変化します。その他の操作。リージョンの状態には主に次の 12 の状態と変換図が含まれます。
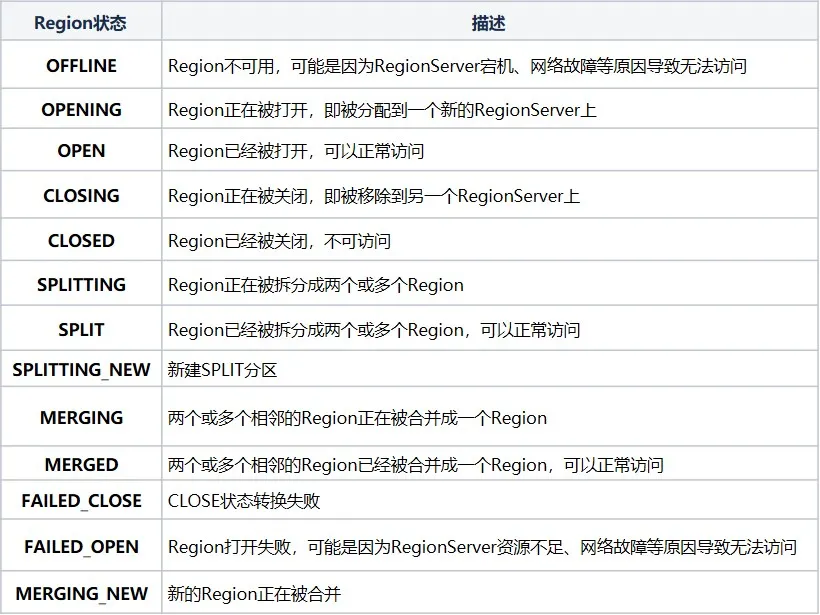
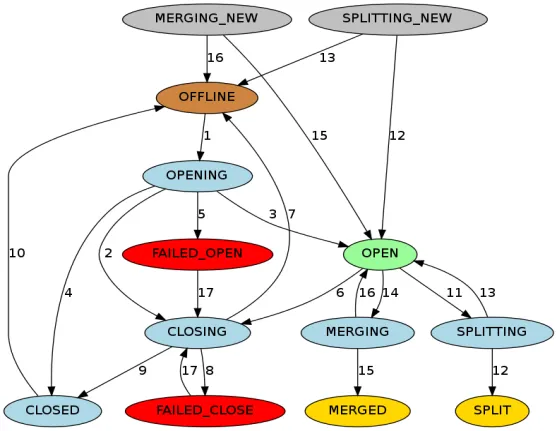
リージョンのステータスをより明確にするために、操作の種類に応じて割り当て、割り当て解除、分割、マージに分けることができます。RegionServer がダウンしているか異常である場合、データが破損している場合、または操作中にエラーが発生した場合、RIT は次のように処理します。 RIT は HBase の運用と保守の問題でよく発生しますが、根本的なロジックが明確であれば、ほとんどの場合、手動による介入なしで RIT の問題に対処することが容易になります。介入が必要になるのは、RIT が長期間発生する場合だけです。では、RIT の長期的な時間とは何でしょうか。なぜ長期的なRITが起こるのでしょうか?
HBase 1.x および HBase 2.x バージョンを使用したことがある場合は、HBase 2.x では RIT があまり一般的ではないと感じるでしょう。実際、リージョンの操作は主に AssignmentManager クラスを介してリージョンを転送することです。 2 つのバージョンのコードを確認すると、hbase.assignment.maximum が見つかりました。試行パラメータ (割り当ての再試行回数) のデフォルト値は、HBase 2.4.8 の最大の整数です。 .MAX_VALUE (HBase 1.x では値のデフォルトは 10) これが、HBase では長期的な RIT の理由が 2.x では比較的まれである理由です。
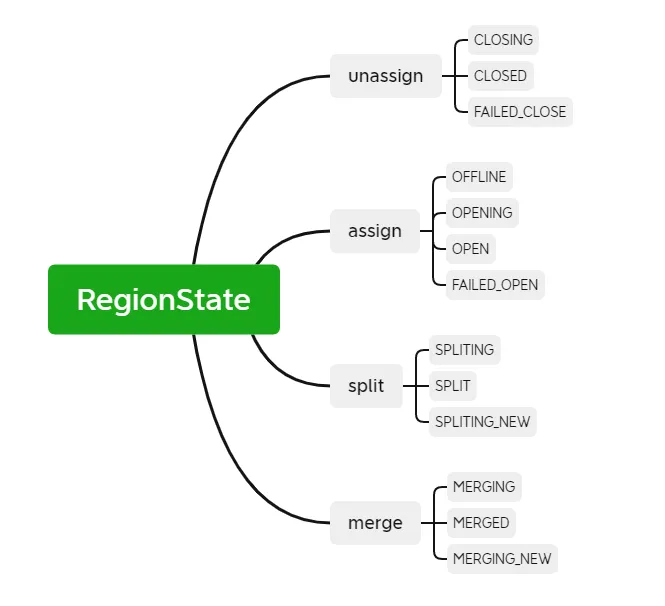
RIT処理方式:
-
RIT は、大きなテーブルを作成または削除するときに発生します。これは主に、リージョンの数が多く、クラスターへの負荷が高いため、割り当ておよび割り当て解除の応答時間が長くなることが原因です。通常、HBase では手動での処理は必要ありません。介入し、自然に治癒することができます。
-
クラスターのバージョンが 1.x の場合、hbase.assignment.maximum.attempts 値を適切に調整して再試行回数を増やすことができます。たとえば、FAILED_OPEN と FAILED_CLOSE は通常、自己修復するか、手動で assign コマンドを実行してそれぞれを割り当てることができます。リージョンをオンラインにします (リージョンが多数ある場合は、HMaster 修復に切り替えます)。
-
リージョンの割り当てが失敗し、RegionServer がない場合、手動割り当ては復元できません。たとえば、リージョンは bogus.example.com に割り当てられており、ノード 1 と 1 は HMaster を切り替えることによってのみ復元できます。
考えるべき質問:
手動介入後でもリージョンが正常にオンラインにならず、HMaster を切り替えることで復元できるのはなぜですか? (HMaster 起動処理 TransitRegionStateProcedure、HMaster クラスのソースコードを参照)
3.2 リージョンホール
HBase テーブルを作成するときに、Region ルールを注意深く分析すると、Region の startkey と endkey が左側が閉じ、右側が開いた連続した間隔に属していることがわかり、驚くでしょう。突然 1 つになった場合にどのような問題が発生するでしょうか。 (以下に示すように) これらの間隔が欠落していますか?
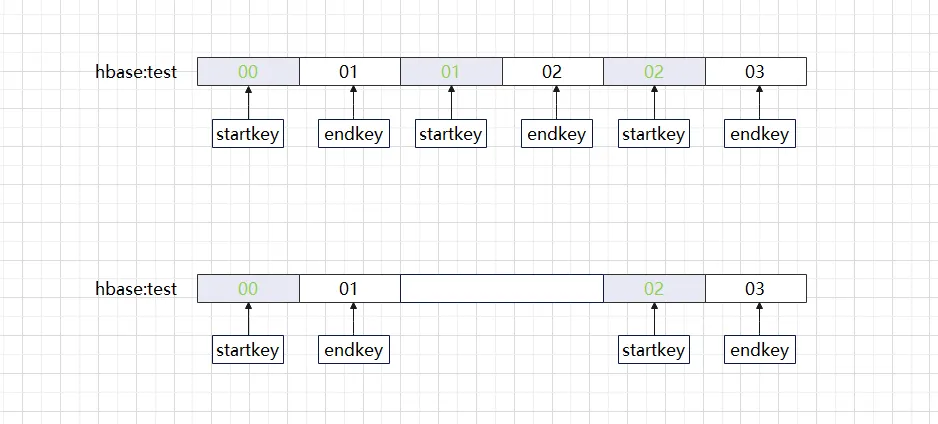
上記の状況は、よく「リージョンのホール」と呼ばれるものです。HBase hbck ツールを使用して確認すると、「エラー: 01 と 02 の間にリージョン チェーンにホールがあります。」というエラー メッセージが表示されます。 hdfs に新しい .regioninfo とリージョン ディレクトリを追加して、HBase クラスターにホールが発生すると、多くの場合、自動的に修復できず、通常の状態に戻すには手動の介入が必要になります。空白部分にリージョンを記入するだけで十分ですか?通常のアプローチでは、最初に空のリージョンを追加し、メタ テーブル情報が正しいかどうかを確認し、最後にそのリージョンをオンラインにします。この一連の操作を手動で実行すると、エラーが発生しやすいだけでなく、時間がかかります。ここではさまざまなバージョンの HBase 修復方法を説明します。実際、さまざまなバージョンの処理方法は若干異なりますが、処理プロセスは同じです。
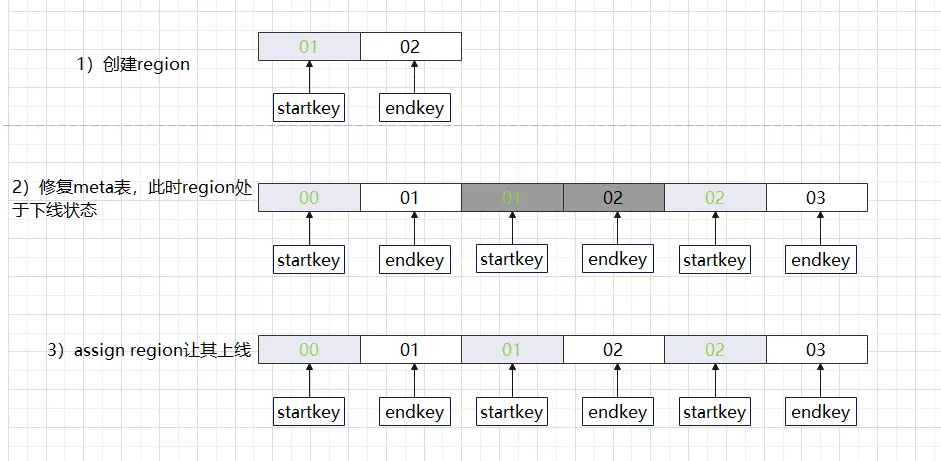
領域穴加工方法:
(1) HBase 1.xの修復方法
-
HBase hbck –fixHdfsHoles : HDFS 上に空のリージョン ファイル パスを作成します
-
HBase hbck -fixMeta : リージョンが配置されているメタ テーブル データを修復します。
-
HBase hbck –fixAssignments : オンライン修復後のリージョン
-
または、HBase hbck –repairHoles は (fixHdfsHoles、fixMeta、fixAssignments) の組み合わせと同等です。
(2) HBase 2.4.8の修復方法(後述のhbase-operator-toolsツールを参照)
HBase 2.4.8 にはリージョン ディレクトリ操作を追加するための関連コマンドが提供されていないため、実際には、HBase 2.4.8 の多くのツール クラスと、hbase-server-2.4 の HBaseTestingUtility クラスがリージョンを作成するためのメソッドを提供しています。 8 テスト パッケージは、リージョン関連の入り口を操作するために、この方法に基づいた回復に主に焦点を当てています。
-
extraRegionsInMeta -fix : まず、メタ テーブルの hdfs ディレクトリに存在しないレコードを削除します。
-
HBaseTestingUtility.createLocalHRegion : リージョンの連続性を確保するための hdfs ファイル パスを作成します。
-
addFsRegionsMissingInMeta : 新しいリージョン情報をメタ テーブルに追加します (追加が成功すると、リージョン ID が返されます)。
-
assigns : 最後に、新しく追加されたリージョンをオンラインにします
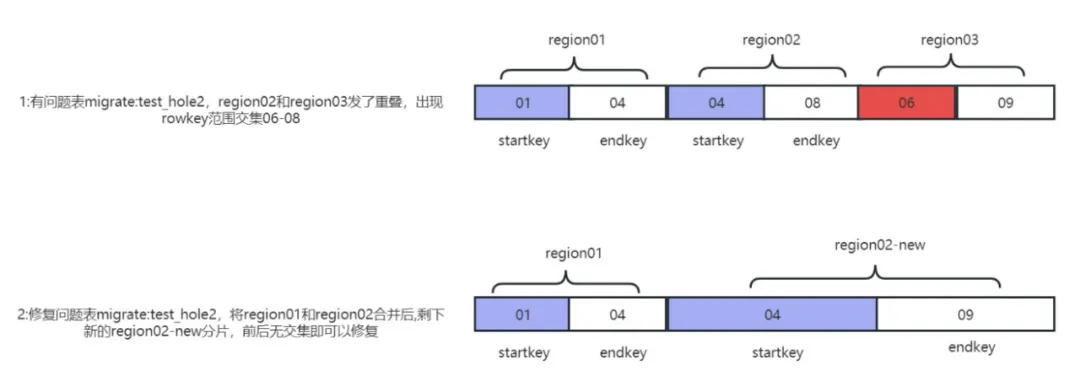
3.3 領域の重複
リージョンに穴ができるため、同じ開始キーと終了キーが複数存在することになりますか?答えは「はい」です。複数のリージョンの startkey と endkey が同じリージョンである場合、この状況を「リージョンの重複」と呼びます。領域の重複は HBase でシミュレートするのが難しく、処理するのも難しい問題です。 hbck チェックを実行すると、このようなログが表示される場合があります。エラー: 複数のリージョンに同じ startkey: 02 があります。

別のタイプの重複領域が 1 つまたは 2 つの隣接するシャードの行キー範囲と交差するこのタイプの問題は、総称して重複問題と呼ばれます。このより困難なシナリオでは、独自に開発したツールを使用して重複問題の再発をシミュレートし、修復します。ワンクリックでの重なり(折り)と穴(穴)の問題。
オーバーラップ問題シミュレーション機能
領域の重複の問題は、実際には 2 つの異なる領域が重複していることです。たとえば、Region01 の startkey と endkey の範囲は (01,02) です。 2 つのリージョンが交差する (01、02) 場合、hbck 検出によりオーバーラップの問題が報告されます。
実稼働環境では、領域が分割され、同時にマシンがハングアップした場合にのみ重複の問題が発生します。問題を再現できることは、その後の作業にとって重要です。修復と障害のドリル 重複問題の再現原理:
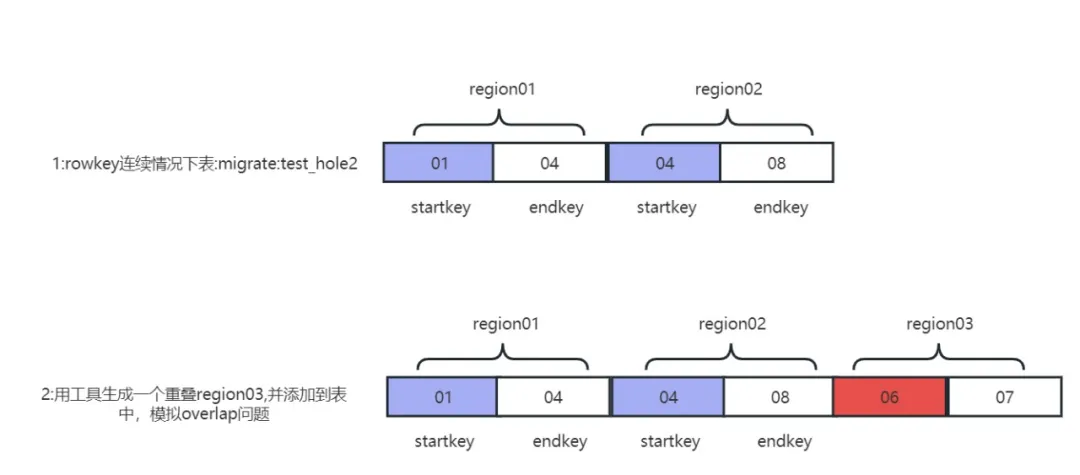
重複問題の再発
1) 重複する行キー範囲を持つリージョン シャードを生成します。
java -jar -Drepair.tableName=migrate:test_hole2 -Dfix.operator=createRegion -DRegion.startkey=06 -DRegion.endkey=07 hbase-meta-tool-0.0.1.jar
2) 重複問題領域をテーブル ディレクトリに移動します。
sudo -uhdfs hdfs dfs -mv /tmp/.tmp/data/migrate/test_hole2/c8662e08f6ae705237e390029161f58f /hbase/data/migrate/test_hole2
3) 通常テーブル merge:test_hole2: のメタテーブル情報を削除します。
java -jar -Drepair.tableName=migrate:test_hole2 -Dfix.operator=delete hbase-meta-tool-0.0.1.jar
4) 重複問題テーブルのメタデータ情報を再構築します。
java -jar -Drepair.tableName=migrate:test_hole2 -Dfix.operator=fixFromHdfs hbase-meta-tool-0.0.1.jar
5) クラスターを再起動した後、hbck はリージョンが c8662e08f6ae705237e390029161f58f と重複していることを報告し、重複の問題が正常に再現されました。

方法 1: ワンクリックで重なりと穴を修復する
フォールド数が 64 を超えない場合に適しており、独自開発ツール hbase-meta-tool を使用して、隣接する領域の範囲を行キーの交差部分とマージし、穴や欠落している範囲がある場合は新しい領域を生成できます。問題が修復できることを示します。 問題修復の原理は次のとおりです。
1) クラスターのオーバーラップとホールの問題を修正します。
java -jar -Dfix.operator= fixOverlapAndHole hbase-meta-tool-0.0.1.jar
方法2:大規模な折れ修理
サーバー側の異常を修復するために数千、数万件を超える大規模なフォールディングに適しており、以下の修復方法を採用します
1) 折り畳みの問題があるテーブルのメタデータをワンクリックでクリアします。
java -jar -Drepair.tableName=migrate:test1 -Dzookeeper.address=zkAddress -Dfix.operator=delete hbase-meta-tool-0.0.1.jar
2) 元のテーブル データをバックアップします。
hdfs dfs -mv /hbase/data/migrate/test/ /back
3) 元のテーブルを削除し、各リージョン シャードのバックアップ データをインポートします。
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /back/test/region01-regionN migrate:test1
3.4 メタテーブルのデータ修復
HBase オンライン クラスターでは、次のような困難な問題が発生する可能性があります。
-
コプロセッサ テーブルが正しく構成されておらず、コプロセッサ パスが見つからず、リージョンのロード中に jar も見つからないため、クラスタが繰り返しハングし、drop コマンドでクラスタを削除できなくなります。
-
HBase メタ テーブル内の要素の数が間違っており、開始コードが間違っており、オンライン プロセス中にサーバーのテーブルが見つからず、テーブルがオンラインになりません。
クラスター内の他のテーブル サービスに影響を与えずに、サービスを停止せずに問題のあるテーブルを個別に修復する必要があります。
問題のあるテーブルのメタデータ修復
1) テーブル merge:test1 に問題があると仮定すると、ワンクリックで問題のテーブル メタデータを削除できます。
java -jar -Drepair.tableName=migrate:test1 -Dfix.operator=delete hbase-meta-tool-0.0.1.jar
2) hdfs テーブルの .regioninfo フォルダーの内容を読み取り、ワンクリックで正しいメタデータを再構築します。
java -jar -Drepair.tableName=migrate:test1 -Dfix.operator=fixFromHdfs hbase-meta-tool-0.0.1.jar
3.5メタブレイク
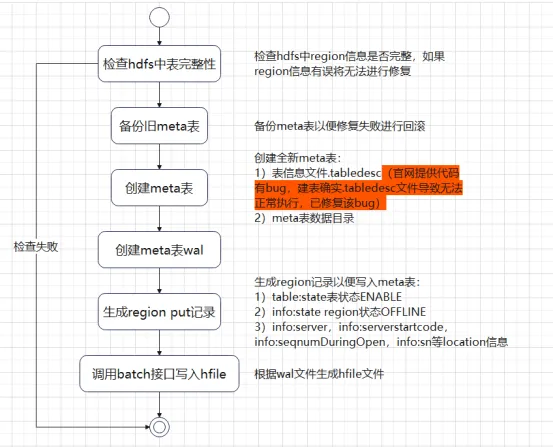
上記の 5 つの状況はすべて、メタ テーブルが正常にオンラインであるという前提で修復されます。メタ テーブルのデータが破損し、オンラインにできない場合、どのように修復すればよいでしょうか。通常、メタ テーブルを再構築してからリージョン情報をメタ テーブルに書き込むことを考えますが、クラスターがオフラインの場合、HBase シェルまたは HBase API は通常、create を実行してテーブルを構築できません。
メタテーブルの初期化クラス InitMetaProcedure を分析したところ、メタテーブルの作成プロセスは大きく 2 つのステップに分かれていることがわかりました。
1) リージョンディレクトリと .tabledesc ファイルを作成します。
2) リージョンを割り当ててオンラインにします。
InitMetaProcedure コア ソース コード:
InitMetaProcedure
protected Flow executeFromState(MasterProcedureEnv env, InitMetaState state) throws ProcedureSuspendedException, ProcedureYieldException, InterruptedException {
try {
switch (state) {
case INIT_META_WRITE_FS_LAYOUT:
Configuration conf = env.getMasterConfiguration();
Path rootDir = CommonFSUtils.getRootDir(conf);
TableDescriptor td = writeFsLayout(rootDir, conf);
env.getMasterServices().getTableDescriptors().update(td, true);
setNextState(InitMetaState.INIT_META_ASSIGN_META);
return Flow.HAS_MORE_STATE;
case INIT_META_ASSIGN_META:
addChildProcedure(env.getAssignmentManager().createAssignProcedures(Arrays.asList(RegionInfoBuilder.FIRST_META_RegionINFO)));
return Flow.NO_MORE_STATE;
default:
throw new UnsupportedOperationException("unhandled state=" + state);
}
} catch (IOException e) {
}
private static TableDescriptor writeFsLayout(Path rootDir, Configuration conf) throws IOException {
LOG.info("BOOTSTRAP: creating hbase:meta region");
FileSystem fs = rootDir.getFileSystem(conf);
Path tableDir = CommonFSUtils.getTableDir(rootDir, TableName.META_TABLE_NAME);
if (fs.exists(tableDir) && !fs.delete(tableDir, true)) {
LOG.warn("Can not delete partial created meta table, continue...");
}
TableDescriptor metaDescriptor = FSTableDescriptors.tryUpdateAndGetMetaTableDescriptor(conf, fs, rootDir);
HRegion.createHRegion(RegionInfoBuilder.FIRST_META_RegionINFO, rootDir, conf, metaDescriptor, null).close();
return metaDescriptor;
}
InitMetaProcedure コード ロジックを参照して、テーブルを作成してオンラインにするための対応するツールを作成できます。メタ テーブルがオンラインになった後は、各テーブルのリージョン情報をメタに書き込み、すべてのリージョンをオンラインに割り当てて通常の状態に戻すだけです。クラスターの状態。上記のプロセスを通じて、メタ テーブルの修復プロセスはそれほど複雑ではないことがわかりました。ただし、運用環境に多数のテーブルがある場合、または個々の大きなテーブルに数千の領域がある場合、手動で追加するのは非常に時間がかかります。常に比較的単純なプロセス (HBase 1.x hbck ツール、HBase 2.x hbase-operator-tools) を以下に紹介します。オフライン修復プロセスを見てみましょう。
HBase 1.x の修正
-
HBase クラスターを停止します。
-
sudo -u hbase hbase org.apache.hadoop.hbase.util.hbck.OfflineMetaRepair -fix
-
クラスターを再起動して修復を完了します。
HBase 2.4.8 修復方法 (hbase-operator-tools ツール)
1) HDFSパスに基づいてメタテーブルを自動生成
-
HBase クラスターを停止します。
-
sudo -u hbase hbase org.apache.hbase.hbck1.OfflineMetaRepair -fix
-
クラスターを再起動して修復を完了します。
2) 単一テーブルの修復方法
-
Zookeeper の HBase ルート ディレクトリを削除します。
-
HMasterとRegionServerが配置されているhdfs WALディレクトリを削除します。
-
クラスターを再起動した後、メタにデータがないため、クラスターは通常の状態に入ることができません。
-
add Regional コマンドを実行して、hbase:namespace、hbase:quota、hbase:rsgroup、および hbase:acl の 4 文字テーブルをクラスターに追加します。追加が完了すると、ログにリージョンとそれに続く割り当てとこれらのテーブルが出力されます。これらの領域は、次の割り当て操作のために記録する必要があります。
sudo -u hbase hbase --config /etc/hbase/conf hbck -j hbase-tools.jar addFsRegionsMissingInMeta hbase:namespace hbase:quota hbase:rsgroup hbase:acl
- 前の手順で印刷領域をオンラインで追加します
sudo -u hbase hbase --config /etc/hbase/conf hbck -j hbase-hbck2.jar assigns regionid
- ビジネス テーブルはオンラインです (手順 4 ~ 5 を繰り返すだけで、ビジネス テーブルを徐々にオンラインにできます)。
予防
(ビジネス テーブルに多くのリージョンがあり、5 番目のリージョンが割り当てられていない場合、すべてのリージョンを正常にオンラインにすることができません。正常にオンラインにするには、パフォーマンスを無効にしてから有効にする必要があります。)
注: hbase-operator-tools OfflineMetaRepair ツールには、修正が必要な次のバグがあります。
1. HBaseFsck createNewMeta メソッドによって作成されたメタ テーブルに .tabledesc ファイルがありません。
修正する前に:
TableDescriptor td = new FSTableDescriptors(getConf()).get(TableName.META_TABLE_NAME);
変更後:
FileSystem fs = rootdir.getFileSystem(conf);
TableDescriptor metaDescriptor = FSTableDescriptors.tryUpdateAndGetMetaTableDescriptor(getConf(), fs, rootdir);
2. HBaseFsckgeneratePuts のデフォルトのリージョン状態は CLOSED です。これは、HMaster が再起動時に OFFLINE 状態でオンラインになるだけであるためです (CLOSED の場合、手動で 1 つずつオンラインにする作業負荷が非常に大きくなります)。
修正する前に:
addRegionStateToPut(p, org.apache.hadoop.hbase.master.RegionState.State.CLOSED);
変更後:
addRegionStateToPut(p, org.apache.hadoop.hbase.master.RegionState.State.OFFLINE);
欠点がある
1) オフライン修復では、クラスター サービスを停止する必要があります。停止時間は修復時間によって異なります (約 10 ~ 15 分)。
2) 領域の重複や穴などの問題がある場合は、OfflineMetaRepair オフライン修復コマンドを実行する前に手動で処理する必要があります。
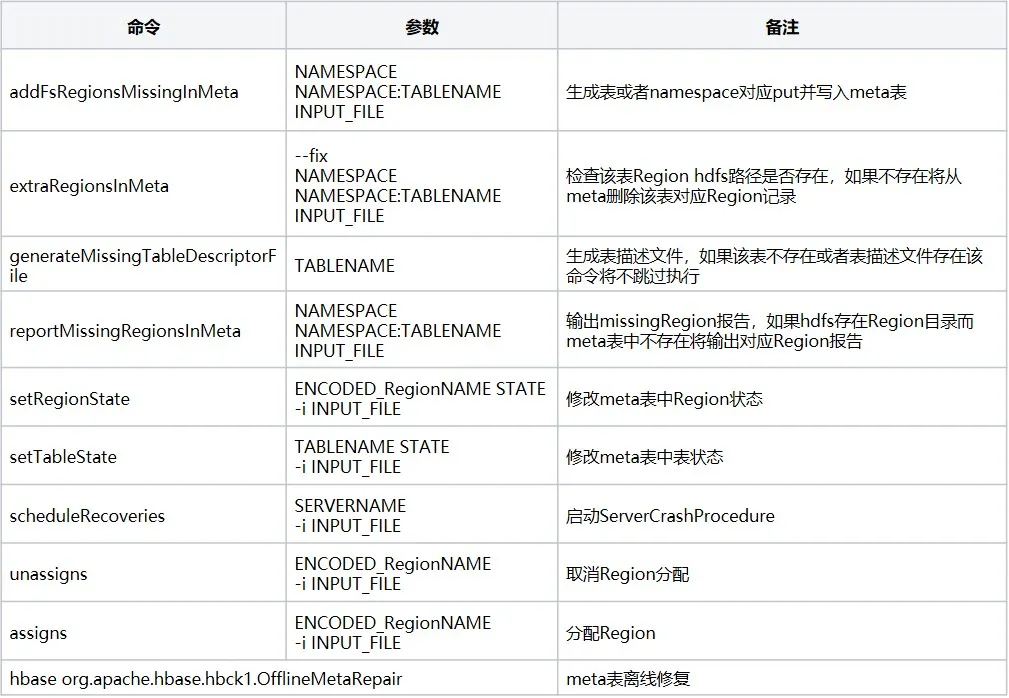
4. hbase-operator-tools ツール
hbase-operator-tools は、HBase 管理者が HBase クラスターを管理および保守するのを支援するために使用される HBase のツール セットです。 hbase-operator-tools は、バックアップおよびリカバリ ツール、リージョン管理ツール、データ圧縮および移動ツールなどを含む一連のツールを提供します。これらのツールは、管理者が HBase クラスターをより適切に管理し、クラスターの安定性と信頼性を向上させるのに役立ちます。ソース コードを使用するには、ソース コード git addressをコンパイルする必要があります。一般的なコマンドは次のとおりです。
5. まとめ
HBase メタ テーブルのデータの精度は、HBase クラスターの通常の動作にとって非常に重要です。メタ テーブルのデータが正しいことを確認する方法と、データが破損した場合に迅速に修復する方法は非常に重要です。メタを包括的に理解していないと、クラスターに障害が発生するたびに途方に暮れることになります。この記事では、メタ テーブル構造の読み込みプロセス、一般的な問題、および関連する修復方法の分析に主に焦点を当てています。上記の修復方法は、次の 2 つのカテゴリに大別できます。
-
オンライン修復: メタテーブルは、hbck および自社開発ツールを使用して通常どおり修復でき、データの整合性を確保できます。
-
オフライン修復: メタ テーブルは正常にオンラインにならず、HDFS のリージョン情報に基づいてメタ テーブルが再構築され、HBase サービスが復元されます。
クラスターの規模が比較的大きく、オフライン修復時間が比較的長い場合、クラスターは長時間サービスを停止する必要があり、実際の状況に基づいてテーブル レベルの修復を実行することはできません。メタ テーブル ファイルが破損していて正常にオンラインにできない場合を除きます)メタ情報の不整合が発生した場合は、問題の拡大を避けるために、クラスターで hbck チェックを定期的に実行することをお勧めします。メタ情報が混乱しており、クラスターが再起動すると、混乱したリージョンの割り当てに失敗し、他のリージョンは正常にオンラインになれなくなります。定期検査でビジネス テーブルにメタ情報の混乱があることが判明した場合、メタ テーブルはテーブル情報を削除し、hdfs パス情報に基づいてリージョンをメタ テーブルに追加し直します (addFsRegions-MissingInMeta コマンドは、hdfs パスに基づいてメタ テーブルにリージョンを正しく追加できます)。
参考記事:
高校生が成人式として独自のオープンソースプログラミング言語を作成―ネットユーザーの鋭いコメント: アップル、M4チップ RustDeskをリリース 不正行為横行で国内サービス停止 雲峰氏がアリババを辞任。将来的には、Windows プラットフォームの タオバオ (taabao.com) で独立したゲームを制作する予定です。Web バージョンの最適化作業を再開し、 プログラマの目的地、 Visual Studio Code 1.89 が最も一般的に使用される Java LTS バージョンである Java 17 をリリースします。Windows 10 には、市場シェアは70%、Windows 11は減少し続けるOpen Source Daily | GoogleはオープンソースのRabbit R1を支持、Microsoftの不安と野心;