

この記事では、特に電子商取引の分野において、人工知能によって生成された画像の品質を評価および改善するために美的基準を策定および適用する方法を紹介します。これは主に、美的基準の策定、美的モデルのトレーニング、美的モデルの適用の 4 つのカテゴリに分かれています。モデル、および淘宝網スタイルのモデルのアップグレード。

-
画質基準:最新の設計フレームワークでは、定義された画質基準は基本的に統一されています。スキルとテクニックの定義に焦点を当てることは、絵、絵画、写真、画像の品質評価にも及びます。これに基づいて、絵を作成する手段の特性も重視されます。 -
画像コンテンツの標準:イデオロギーに基づいた表現品質の要件は広範であり、コンテンツ表現のニーズを満たすために画像品質の標準は破られるでしょう。通常、業界の評論家や裁判官などの権威ある人物によって定義および解釈されます。 

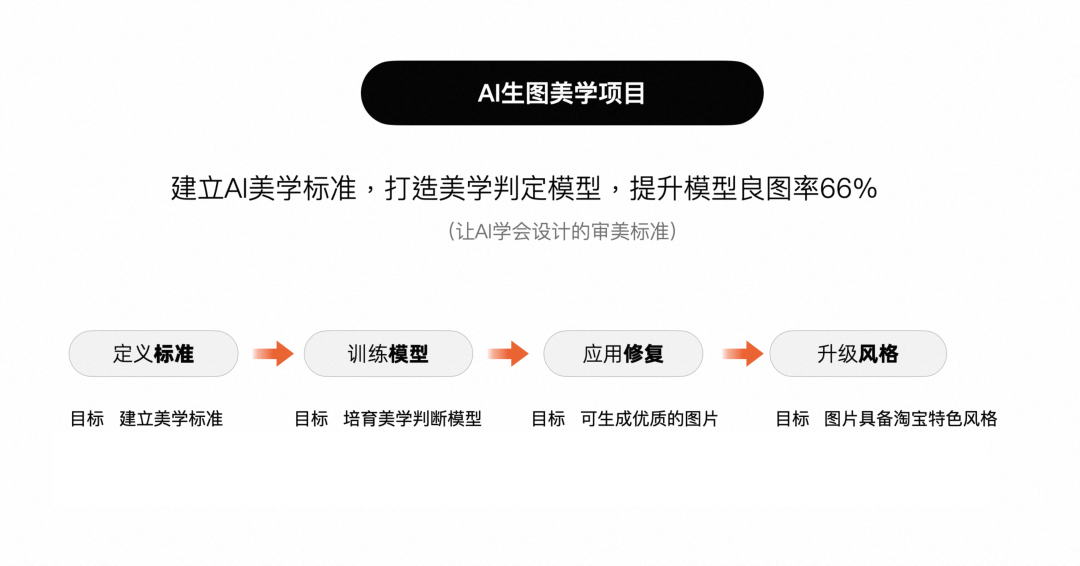
美学プロジェクトの目標
最初のステップは美的基準を策定することです。AI 描画基準と AI スタイル基準を策定し、中国芸術院および教授と共同研究します。プロ意識、適切性、客観性、権威を強調します。
ステップ 2 -美的モデルのトレーニング: AI の美的基準に基づいて美的判断モデルを育成し、機械が自動的に判断して採点できるようにします。
ステップ 3 -美的モデルを適用する:美的モデルの機能に基づいて、淘宝 AI 画像生成モデルの最適化とアップグレードをガイドします。
ステップ 4 - タオバオ スタイル モデルのアップグレード:スタイル標準に基づいてタオバオ スタイル モデル ライブラリを確立し、販売者が豊富で多様なスタイル モデルから選択できるようにします。タオバオスタイルのモデルを作成します。

基準の枠組みは「画像」の構成要素に基づいて定義され、同時に「 AI によって生成された特徴」に焦点を当てて美的基準を構築します。
画像構成:物体の形状/環境/構図/光と影/テクスチャ
AI生成の特徴:要素の信頼性とシーンの合理性
AI の美的基準: 5 つのガイドライン、19 の基準



美的モデルの目標: 自動機械スコアリングと画像判定の精度を向上させます。
-
正解率:同じ写真に対して美的AIスコアリングと手動スコアリングを実施し、人間と機械のスコアの重複率を算出します。
▐没入型体験

当社の AI 美的評価モデルは、マルチモーダル美的事前トレーニングとマルチタスク微調整学習方法を採用しています。これを行うことの利点は次のとおりです。
私たちのモデルはパラメータが少ないため、トレーニングの反復が速く、推論速度が速く、審美性の高い画像を迅速にスクリーニングでき、さまざまな生成モデルの生成効果を評価することもできるため、手動によるアノテーションとレビューのコストが削減されます。
美的スコアのみを出力するモデルと比較して、私たちのモデルは生成された画像の異常な属性を出力できるため、解釈可能性が高くなります。
-
私たちのモデルによって出力された異常な属性は、画像復元のための事前識別子として使用でき、異常に生成された画像マーキングの生成モデルを最適化するためにも使用できます。
▐トレーニングプロセス
-
採点ルールを策定:AI生成画像の採点仕様(5段階)、オリジナル画像審査の採点ルール(3段階)。 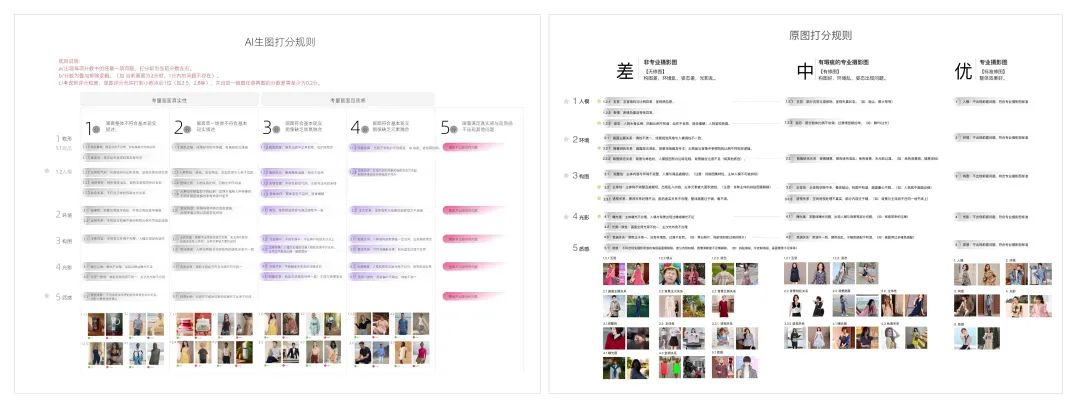
-
オリジナルのマネキン画像の美学を評価する機能: マネキン、環境、構成、光と影、テクスチャなどの画質の好みに基づいて、オリジナルのマネキン画像の特殊な美的モデルが美的レイヤリング用にトレーニングされます。 。フィルタリング可能な美観の低いタイプには、ぼやけた画像、白枠のある画像やテクスチャ、不完全または切り取られた人間の顔、大きくブロックされた人体、劣悪な背景または劣悪な全体的な美観などが含まれます。 -
AIGC RAW画像の美的評価能力:AIGC RAW画像の美的評価は、主にキャラクターを含む生画像を対象とし、絵の合理性と絵の統合性の2つの観点からスコアを作成します。 5 つの主要な基準と 19 の標準要件に基づいて分析し、同時に生のグラフの異常な属性をマークします。私たちのモデルが現在サポートしている異常な属性には、人物と背景の異常な統合(空中にぶら下がっているキャラクター、貧弱な背景のテクスチャなど)、手の異常、顔の異常、手足の異常、その他の異常などが含まれます。出力される美的スコアの範囲は以下のとおりです。 1点から5点まで。 
図: AIGC 生画像の美的評価によって予測されたさまざまな美的スコアの画像
合理的なトレーニング: 高品質のデータを確保するために、人間と機械の間で複数回のマッチング検証を行います。
1回の採点テスト:3人の平均点をとりデータを蓄積し、客観的な採点を行います。相違点セクションでは、相違点によってもたらされる特定の問題点を再解釈します。再度検証を行ってください。さまざまな人々による規範の解釈が一貫していて安定していることを確認します (5 ポイント システム)。
2回のAI採点検証:3人の平均スコアを取得し、機械で校正し、スコアに差があった場合、その差の具体的な問題点を再解釈し、人間の問題か機械の問題かを明らかにします。両者が徐々に一貫していることを確認し、機械の理解を確実にします。 (AI判定モデルの初版が利用可能になってから開始となります)。
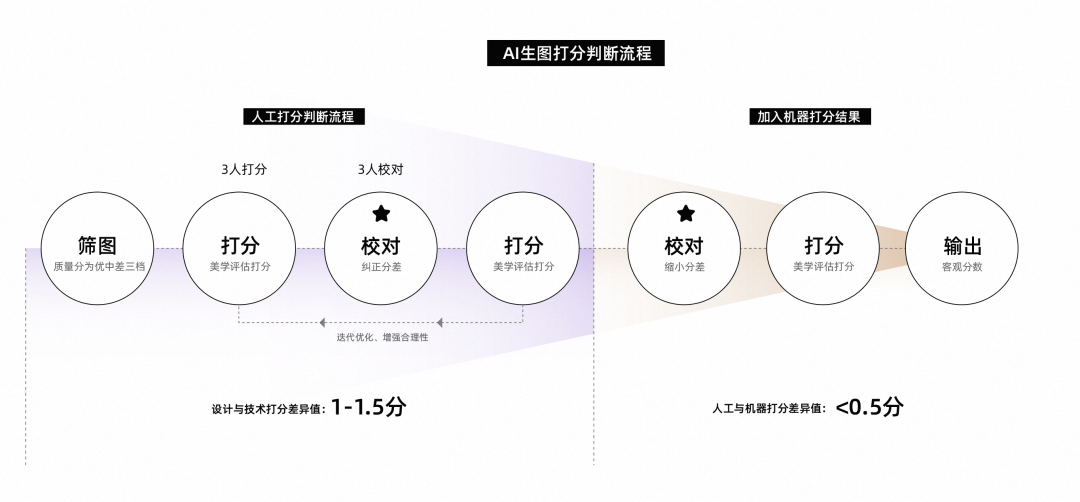
技術的枠組み
AIGC 生図面の美的評価: デザイナーが定義した 5 つの美的基準に基づいて、5 つの品質レベルにマッピングされます。同時に生成されたデータを帰納的に分析し、正常、人物と背景の融合異常、手の異常、顔の崩れ、身体の異常、その他の異常の5大属性をまとめました。品質レベルと属性理由を組み合わせて美的評価プロンプトワードを形成し、これをマルチモーダル事前トレーニングモデルの入力として使用します。損失関数は美的スコア回帰損失と属性理由マルチラベル分類損失を使用します。
オリジナルのマネキン画像の美的評価: CLIP は、画質、色、照明、構成、抽象的な概念などの美的評価の観点から、良い/悪いを分類する優れたゼロショット機能を備えています。そこで、事前トレーニングの段階で、CLIPの画像エンコーダーを抽出することでバックボーンの美的表現能力を向上させます。微調整段階では、改善されたバックボーンを使用して、正規化された美的スコアを予測します。損失関数は、モデルのパフォーマンスと堅牢性を向上させるために、L1 損失とバイナリ クロスエントロピー損失によって重み付けされます。モデルのトレーニングが完了した後、さまざまなしきい値を選択することで、さまざまな美的レベルを持つ人体モデルの画像をレイヤー化できます。
▐テスト段階
-
多用途性の調整: Qianniu プラットフォーム上で、淘宝網の内部 [Qianniu インテリジェント モデル] と淘宝網の外部サードパーティ モデルをテストします。同じタイプのマネキンが評価され、互換性があることが判明しましたが、大きな違いがありました。特定の画像の問題をクロールする場合、アップロードされた元の画像の品質が精度に影響を与えることがわかりました。公平性を確保するには、テスト アトラスの標準を開発する必要があります。 -
機械採点の信頼性:正解率は毎週ある程度変動しますが、モデルの条件に基づいて標準的なテストセットが構築されます。 AIおよび手動採点用の標準テストセット1,200問を使用(原画の難易度がAIの判定に影響することを考慮し、テストセットを1:1:1の割合で易・中・難の3段階に分けている) 。 -
機械スコアリングの厳格なテスト:調整されたスコアリング モデルは、新しく生成された画像を自動的にスコアリングし、人間のスコアと比較します。 

目標: 美的モデルを使用して、淘宝 AI 大型モデルの良好な描画率を向上させます。
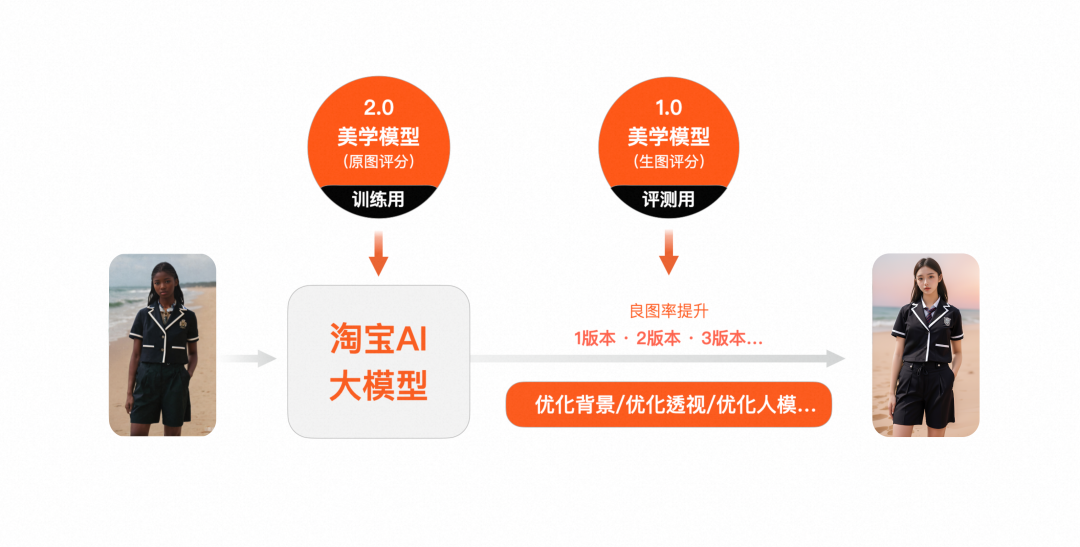
▐美的モデル バージョン 1.0 - AI 画像評価機能の適用:
-
目標:美的モデルを使用して、淘宝網生成モデルを評価し、画像のスコアリングと画像の問題を特定し、特定された画像の問題を修復します。 -
判断能力:画像にスコアを付け (1 ~ 5 ポイント)、良い画像と悪い画像を選別し、その後のモデルの最適化提案をガイドできます。 -
認識能力:現在、5 つの主要な画面属性をフィードバックできます。 (1.手の異常。2.人物が背景と同化していない。3.顔の異常。4.体の異常。5.その他)。 -
修复能力:AIGC生成人物时画好的手一直是难点,人的手部自由度高且姿态复杂多变、图中占比小且细节多,导致画手的成功率不高。特别地,在实际业务中,由于用户上传的图片手部细节不明显或者手中拿着物品等复杂场景,在进行换模特换背景时,生成模型往往不能学到手部的准确细节特征导致画出不好的手。我们探索全新的手部修复技术方案。由 AI美学评价模型判断生成异常的手,对异常的手,利用3D手部状态重建模型保持正确的手指数量与手的形状,同时能够自适应生成图像中所需的手势。基于我们内部基底模型,融合Text Embedding,根据重建后的手部姿态重新绘制正常的手。经过反复调试参数和场景适配,我们的手部修复方案在业务数据上测试,修复成功率超过50%,可大幅度提高整体的生图良图率。手部修复的case如下:

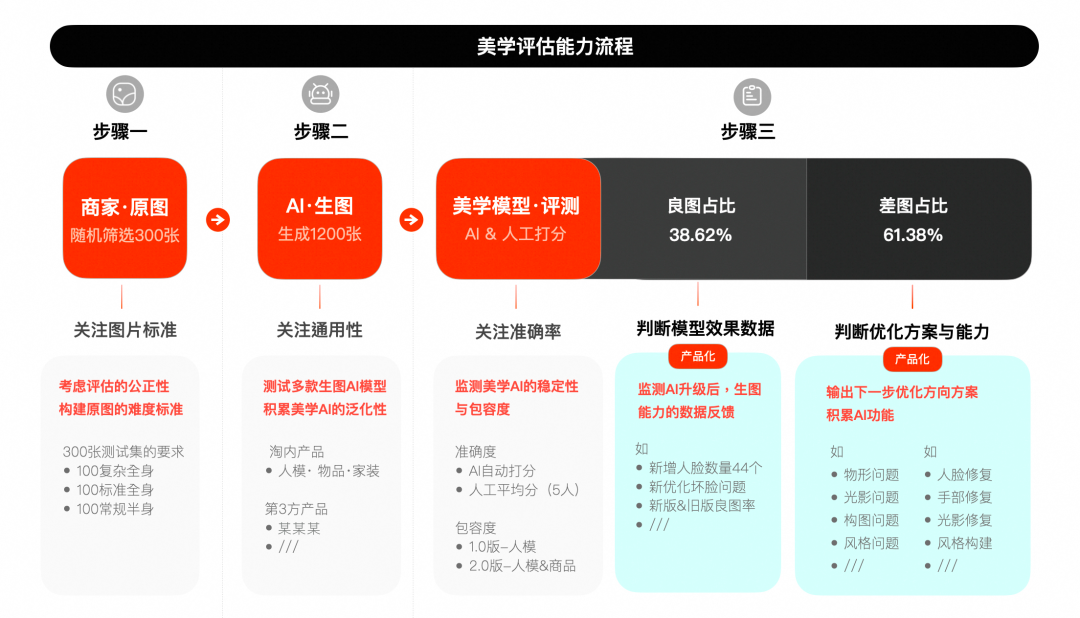
▐ 美学模型2.0版本-应用原图评测能力
目标:调优淘宝基地模型,目前有混杂的原图数据集,数据集质量参差不齐,需要进行有效的筛选优化。
背景:目前原图数据集来源核心是两部分:视觉中国和淘宝模特图。
视觉中国的摄影图核心是供给给新闻稿做新闻配图,因此大量的图片为了营造故事性对人物和场景有独特的表达。淘宝模特图商家已经做了后期处理,有些诸如模特的处理已经比较夸张。
筛选优质原图:通过原图判定模型,筛选优质摄影图,调优自研模型等数据集效果。提升生图的良图率。(如多人混乱、背景混乱,场景融合感等效果可提升)。
收集专业摄影原图:目前通过设计团队搜集优质的摄影模特图。-
1.0版本的AI美学评价模型影响生成模型,使生成模型自适应对齐人类偏好:AI美学评价可用于指导基于扩散的生成模型,不仅指导生成模型要生成高美学图像,也需要减少生成低美学图像的概率。为了解决这个问题,我们利用AI美学评价模型在低美学异常生成图像加上异常属性标签,增强模型学习异常生成图像概念的能力,可以在推理阶段避免。

第四步:升级淘宝风格模型
▐ 风格的背景情况
目前风格选择的丰富性不足,生图的场景和人物集中在特定的几个类型上。原先对于风格的设定采用穷举的方式。如背景生成的场景基本上是泳池、花园、商场、海滩、森林、雪山。
因为原图本身的来源关系,图片的地域场景特色基本是西式。诸如东南亚的海滩、欧式花园、美式商场、美式泳池、北欧雪山。
因为采用穷举的方式,导致工具的选择项过多,体验比较复杂,商家使用过程中会选择困难,采用不断尝试的方式。
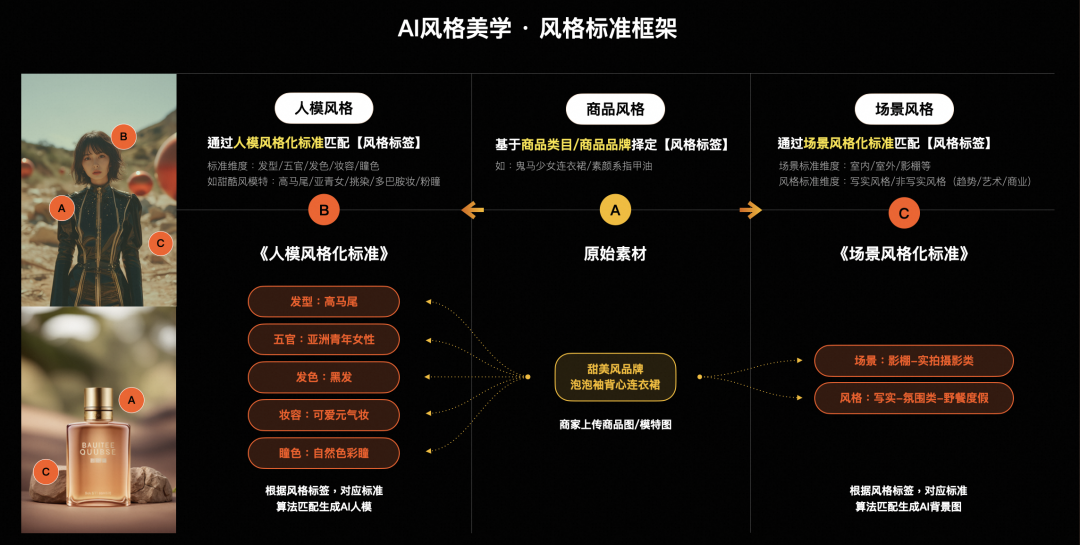
▐ 风格的框架设定
-
对应美学标准的五大原则。进行细分的穷举,作为组合因子。 -
风格类型分为平台品牌风格、趋势热点风格、经典艺术风格三类。 -
基于风格趋向进行因子组合。形成风格的多元组合。

▐ 风格标准的运用
▐ 后续计划
美学标准:发布淘宝AI美学标准,联动中国美术学院完成。
风格标准:风格化标准完善,建立淘宝独有的风格体系。同时在产品侧进行测试。
-
产品能力:发布 AI paas产品能力,联动千牛产品团队部署上线,提供给集团相关自研AI与第三方AI进行服务,也同步提升兼容性。
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。