コロケーションは、リソースの使用率を向上させ、コストを削減するソリューションとして、業界で一般的に認識されています。クラウドネイティブ化、コスト削減、効率向上の過程で、iQiyi はビッグデータのオフライン コンピューティング、オーディオおよびビデオ コンテンツの処理、その他のワークロードをオンライン ビジネスとうまく融合させ、段階的な利益を達成しました。この記事では、ビッグデータを例に、混在導入システムを0から1へ導入する実践的なプロセスを紹介します。
背景
iQIYI ビッグ データは、運営上の意思決定、ユーザーの増加、広告配信、ビデオの推奨、検索、社内のメンバーシップなどの重要なシナリオをサポートし、ビジネスにデータ駆動型のエンジンを提供します。ビジネス需要の拡大に伴い、必要なコンピューティング リソースの量は日々増加しており、コスト管理とリソース供給はより大きなプレッシャーに直面しています。
iQIYI のビッグ データ コンピューティングは、オフライン コンピューティングとリアルタイム コンピューティングの 2 つのデータ処理リンクに分かれています。そのうちの 1 つは次のとおりです。
-
オフライン コンピューティングには、Spark ベースのデータ処理、Hive ベースの時間レベルまたは日レベルのデータ ウェアハウス構築、および対応するレポート クエリと分析が含まれます。このタイプの計算は通常、毎日早朝に始まり、前日のデータを計算します。朝。毎日 0 ~ 8 時は、コンピューティング リソースの需要がピークとなる時間帯です。クラスターの合計リソースが不足することが多く、タスクがキューに入れられてバックログされることが多く、その結果、大量のアイドル時間が発生します。資源の無駄遣い。
-
リアルタイム コンピューティングには、Kafka + Flink に代表されるリアルタイム データ ストリーム処理が含まれ、比較的安定したリソース要件があります。
ビッグデータ リソースの利用のバランスをとるために、オフライン コンピューティングとリアルタイム コンピューティングを組み合わせることにより、日中のリソースの無駄な浪費がある程度軽減されましたが、それでも効果的に山を切り、谷を埋めることはできませんでした。ビッグデータ コンピューティング リソースの全体的な利用状況は依然として「日中の谷と早朝のピーク」という潮汐現象を図 1 に示しています。
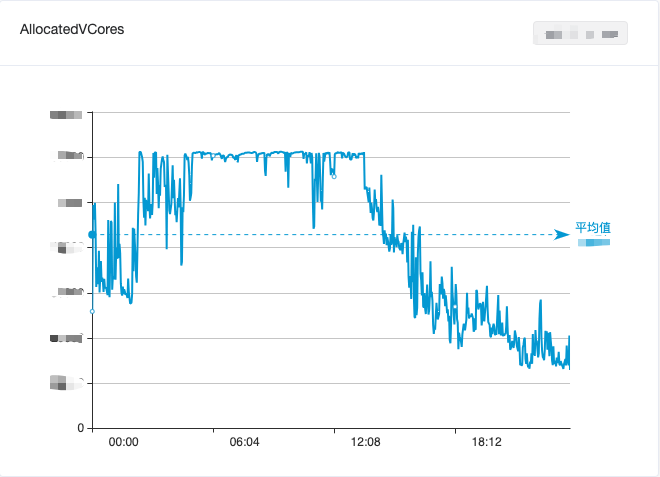
図 1. 1 日以内のビッグ データ コンピューティング クラスターの CPU 使用率の変化
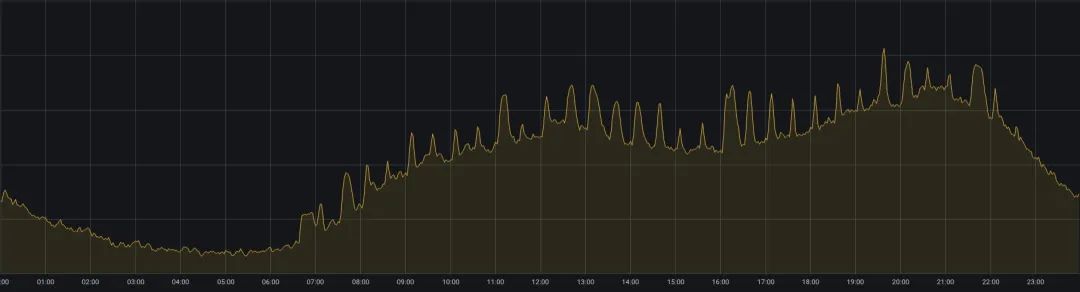
iQiyi のオンライン ビジネスは、サービス品質とリソース使用率のバランスという別の問題に直面しています。オンライン ビジネスは主に iQiyi ビデオ再生などのシナリオに対応しており、正午と夕方にビデオを視聴するユーザーが増加し、リソース使用量には「日中にピークがあり、早朝に谷」という潮汐現象が見られます (図 2 を参照)。 。ピーク時のサービス品質を確保するために、オンライン ビジネスは通常、より多くのリソースを予約するため、リソースの使用率が非常に不十分になります。
図 2. 1 日以内のオンライン ビジネス クラスターの CPU 使用率の変化
使用率を向上させるために、iQiyi が開発した前世代のコンテナ プラットフォームは CPU 静的オーバーブッキング戦略を採用しました。この方法は使用率の向上に大きな効果がありますが、コア機能などの要因によって制限され、単一のサービス間の中断を避けることはできません。時折発生するリソース競合の問題により、オンライン ビジネス サービスの品質が不安定になることもあり、この問題はまだ適切に解決されていません。
クラウドネイティブ化の進展に伴い、iQiyiコンテナプラットフォームは徐々にKubernetes(以下「K8s」)テクノロジースタックに移行してきました。近年、共同デプロイメントに関連する多くのオープンソース プロジェクトが K8s コミュニティに登場しており、業界でもいくつかの共同デプロイメントの実践が行われています [1] 。このような背景から、コンピューティング プラットフォーム チームは、作業の方向性を「静的オーバーブッキング」から「動的なオーバーブッキング + 混合展開」に調整しました。
最も典型的なオフライン ビジネスであるビッグ データは、コロケーションの実装を試みる先駆者です。一方で、ビッグデータは大容量で比較的安定したコンピューティング リソース要件を備えていますが、他方では、ビッグ データ ビジネスとオンライン ビジネスはさまざまな側面で相補的な効果を達成でき、コロケーションによってリソースの使用率を完全に向上させることができます。
上記の分析に基づいて、iQiyi コンピューティング プラットフォーム チームとビッグ データ チームはコロケーションの検討を開始しました。
混合ロケーションプランの設計
iQiyi ビッグ データ システムは、オープン ソースの Apache Hadoop エコシステム上に構築されており、コンピューティング リソース スケジューリング システムとして YARN を使用しています。オンライン ビジネスは、2 つの異なるリソース スケジューリング システムをどのように接続するかが最初に解決する必要があります。コロケーション ソリューション。
業界には通常、次の 2 つのソリューションが共存しています。
-
オプション 1: K8 でビッグ データ ジョブ (Spark、Flink など、MapReduce はサポートされていません) を直接実行し、そのネイティブ スケジューラを使用します。
-
オプション 2: K8 上で YARN の NodeManager (以下「NM」と呼びます) を実行します。ビッグ データ ジョブは引き続き YARN を通じてスケジュールされます。
慎重に検討した結果、次の 2 つの主な理由により、オプション 2 を選択しました。
-
現在、社内のビッグ データ コンピューティング ジョブの大部分は YARN に基づいてスケジュールされており、強力なスケジューリング機能 (マルチテナント マルチキュー、ラック認識)、優れたスケジューリング パフォーマンス (5k+ コンテナ/秒)、および完全なセキュリティ メカニズムを備えています。 (Kerberos、委任トークン)、MapReduce、Spark、Flink などのほぼすべてのビッグ データ コンピューティング フレームワークをサポートします。 2014 年の YARN の導入以来、iQiyi ビッグ データ チームは、開発、運用と保守、コンピューティング ガバナンスなどのために、YARN を中心とした一連のプラットフォームを構築し、内部ユーザーに便利なビッグデータ開発プロセスを提供してきました。したがって、YARN API との互換性は、ハイブリッド ソリューションを選択する際の重要な考慮事項の 1 つです。
-
K8s にはバッチ スケジューラがありますが、十分に成熟しておらず、スケジューリング パフォーマンス (<1,000 コンテナ/秒) にボトルネックがあり、ビッグ データ シナリオのニーズをサポートするには十分ではありません。
K8s レベルでは、双方がコロケーション リソースを管理および使用するための標準インターフェイスのセットを必要とします。コミュニティには、Alibaba のオープンソースKoordinator [2]、Tencent のオープンソース FinOps プロジェクト Crane [3]、ByteDance のオープンソース プロジェクト Katalyst [4] など、多くの優れたプロジェクトがあります。その中で、Koordinator は、Dragon Lizard オペレーティング システム (iQiyi が試みている CentOS の代替手段の 1 つ) との「自然な」適応性を備えており、オンライン ビジネス負荷監視、アイドル リソースのオーバーコミットメント、タスク階層型スケジューリング、およびオフライン ワークロード QoS 保証を実現するために連携できます。 、など、iQiyi のニーズを満たします。
上記のテクノロジー選択に基づいて、綿密な変換を通じて YARN NM をコンテナ化し、K8s Pod で実行しました。これにより、Koordinator の動的に変化する超解像度コンピューティング リソースをリアルタイムで感知することができ、それによって水平および垂直の自動拡張と縮小が実現されます。混合リソースの利用を最大化します。
共存スケジューリング戦略の進化
ビッグ データとオンライン ビジネスのコロケーションは、複数の技術進化段階を経てきました。これについては、以下で詳しく紹介します。
ステージ 1: 夜間の時分割多重化
ソリューションを迅速に検証するために、まず K8s Pod 上で NM のコンテナ化変換を完了し (この段階では Koordinator は使用されていません)、それをエラスティック ノードとして既存の Hadoop クラスターに拡張しました。ビッグ データ レベルでは、これらの K8 NM は、他の物理マシン上の NM とともに YARN によって均一にスケジュールされます。これらのエラスティック ノードは毎日定期的に開始および停止し、0 時から 9 時までの間のみ実行されます。
現時点で 20 件以上の改修を完了しました。主な改修ポイントは次の 5 つです。
改善点1:固定IPプール
従来の NM は物理マシンにデプロイされ、マシンの IP とドメイン名は固定されており、ノードがノードに参加できるように YARN ResourceManager (以下、「RM」と呼びます) 上でノードのホワイトリスト (スレーブ ファイル) が構成されます。集まる。同時に、YARN クラスターは Kerberos を使用してセキュリティ認証を実装します。展開前に、キータブ ファイルを Kerberos KDC で生成し、NM ノードに配布する必要があります。
YARN のホワイトリストとセキュリティ認証メカニズムに適応するために、独自に構築されたクラスターに対して独自に開発された静的 IP 機能を使用し、対応する K8s StaticIP リソースを使用して、Pod と IP 間の対応関係を同時に記録します。また、独自に開発した StaticIP CRD をクラスターにデプロイし、静的 IP ごとに StaticIP リソースを作成します。これにより、YARN に自社構築クラスターと同じ使用法を持つ固定 IP プールが提供されます。 。 NM の起動時に必要な設定をすぐに取得できるように、固定 IP プール内の IP に基づいて DNS レコードとキータブ ファイルを事前に作成します。
変革ポイント 2: Elastic YARN オペレーター
ユーザーにエラスティック ノードの導入を意識させないように、既存の Hadoop YARN クラスターにエラスティック NM を追加しました。その後の混合デプロイメントにおける動的に認識されるリソースの複雑さを考慮して、Elastic NM のライフサイクルをより適切に管理するために、自社開発の Elastic YARN Operator を選択しました。
この段階で、Elastic YARN Operator によってサポートされる戦略は次のとおりです。
-
按需启动:应对离线任务的突发流量,包括寒暑假、节假日、重要活动等场景
-
周期性上下线:利用在线服务每天凌晨的资源利用率低谷期,运行大数据任务
改造点 3:Node Label - 弹性与固定资源隔离
由于 Flink 等大数据实时流计算任务是 7x24 小时不间断常驻运行的,对 NM 的稳定性的要求比批处理更高,弹性 NM 节点的缩容或资源量调整会使得流计算任务重启,导致实时数据波动。为此,我们引入了 YARN Node Label 特性 [5],将集群分为固定节点(物理机 NM)和弹性节点(K8s NM)。批处理任务可以使用任意节点,流任务则只能使用固定节点运行。
此外,批处理任务容错的基础在于 YARN Application Master 的稳定性。我们的解决方案是,给 YARN 新增了一个配置,用于设置 Application Master 默认使用的 label,确保 Application Master 不被分配到弹性 NM 节点上。这一功能已经合并到社区:
YARN-11084
、
YARN-11088
。
改造点 4:NM Graceful Decommission
我们采用了弹性节点固定时间上下线,来对在离线资源进行削峰填谷。弹性 NM 的上线由 YARN Operator 来启动,一旦启动完成,任务就可被调度上。弹性 NM 的下线则略微复杂些,因为任务仍然运行在上面,我们需要尽可能保证任务在下线的时间区间内已经结束。
例如我们周期性部署策略为:0 - 8 点弹性 NM 上线,8 - 9 点为下线时间区间,9 - 24 点为节点离线状态。通过使用 YARN graceful decommission [6] 的机制,将增量 container 请求避免分配到 decommissioning 的节点上,在下线时间区间内等待任务缓慢结束即可。
但是在我们集群中,批处理任务大部分是 Spark 3.1.1 版本,因为 Spark 申请的 YARN container 是作为 task 的 executor 来使用,在大部分情况下,1 个小时的下线区间往往是不够的。因此我们引入了 SPARK-20624 的一系列优化 [7],通过 executor 响应 YARN decommission 事件来将 executor 尽可能快速退出。
改造点 5:引入 Remote Shuffle Service - Uniffle
Shuffle 作为离线任务中的重要一环,我们采用 Spark ESS on NodeManager 的部署模式。但在引入弹性节点后,因为弹性 NM 生命周期短,无法保证在 YARN graceful decommmission 的时间区间内,任务所在节点的 shuffle 数据被消费完,导致作业整体失败。
基于这一点,我们引入了 Apache Uniffle (incubating) [8] 实现 remote shuffle service 来解耦 Spark shuffle 数据与 NM 的生命周期,NM 被转变为单纯的计算,不存储中间 shuffle 数据,从而实现 NM 快速平滑下线。
另外一方面,弹性 NM 挂载的云盘性能一般,无法承载高 IO 和高并发的随机读写,同时也会对在线服务产生影响。通过独立构建高性能 IO 的 Uniffle 集群,提供更快速的 shuffle 服务。
爱奇艺作为 Uniffle 的深度参与者,贡献了 100+ 改进和 30+ 特性,包括 Spark AQE 优化 [9] 、Kerberos 的支持 [10] 和超大分区优化 [11] 等。
阶段二:资源超分
在阶段一,我们仅使用 K8s 资源池剩余未分配资源实现了初步的混部。为了最大限度地利用空闲资源,我们引入 Koordinator 进行资源的超分配。
我们对弹性 NM 的资源容量采用了固定规格限制:10 核 batch-cpu、30 GB batch-memory(batch-cpu 和 batch-memory 是 Koordinator 超分出来的扩展资源),NM 保证离线任务使用的资源总量不会超过这些限制。
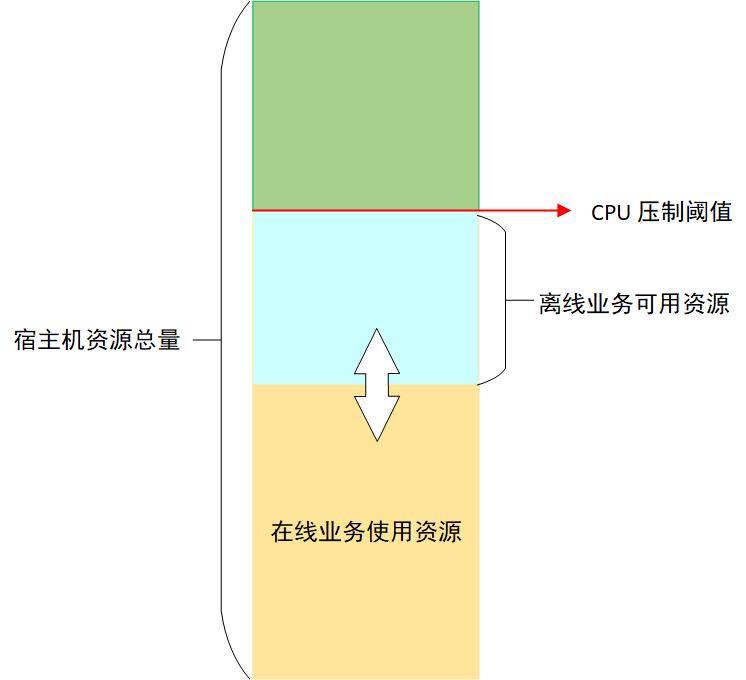
为了保证在线业务的稳定性,Koordinator 会对节点上离线任务能够使用的 CPU 进行压制 [12],压制结果由压制阈值和在线业务 CPU 实际用量(不是 request 请求)的差值决定,这个差值就是离线业务能够使用的最大 CPU 资源,由于在线业务 CPU 实际使用量不断变化,所以离线业务能够使用的 CPU 也在不断变化,如图 3 所示:
对离线任务的 CPU 压制保证了在线业务的稳定性,但是离线任务执行时间就会被拉长。如果某个节点上离线任务被压制程度比较严重,就可能会导致等待的发生,从而拖慢整体任务的运行速度。为了避免这种情况,Koordinator 提供了基于 CPU 满足度的驱逐功能 [13],当离线任务使用的 CPU 被压制到用户指定的满足度以下时,就会触发离线任务的驱逐。离线任务被驱逐后,可以调度到其他资源充足的机器上运行,避免等待。
在经过一段时间的测试验证后,我们发现在线业务运行稳定,集群 CPU 7 天平均利用率提升了 5%。但是节点上的 NM Pod 被驱逐的情况时有发生。NM 被驱逐之后,RM 不能及时感知到驱逐情况的发生,会导致失败的任务延迟重新调度。为了解决这个问题,我们开发了 NM 动态感知节点离线 CPU 资源的功能。
阶段三:从夜间分时复用到全天候实时弹性
与其触发 Koordinator 的驱逐操作,不如让 NM 主动感知节点上离线资源的变化,在离线资源充足时,调度较多任务,离线资源不足时,停止调度任务,甚至主动杀死一些离线 container 任务,避免 NM 被 Koordinator 驱逐。
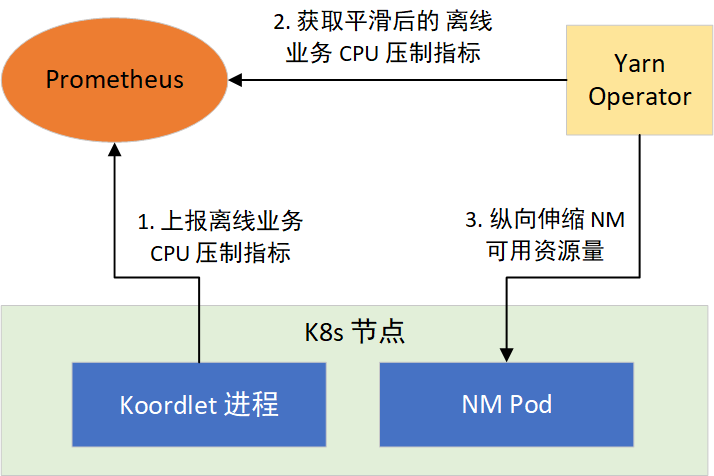
根据这个思路,我们通过 YARN Operator 动态感知节点所能利用的资源,来纵向伸缩 NM 可用资源量。分两步实现:1)提供离线任务 CPU 压制指标;2)让 NM 感知 CPU 压制指标,采取措施。如图 4 所示:
CPU 压制指标
Koordinator 的 Koordlet 组件,运行于 K8s 的节点上,负责执行离线任务 CPU 压制、Pod 驱逐等操作,它以 Prometheus 格式提供了 CPU 压制指标,经过采集后就可以通过 Prometheus 对外提供。CPU 压制指标默认每隔 1 秒更新 1 次,会随着在线业务负载的变化而变化,波动较大。而 Prometheus 的指标抓取周期一般都大于 1 秒,这会造成部分数据的丢失,为了平滑波动,我们对 Koordlet 进行了修改,提供了 1 min、5 min、10 min CPU 压制指标的均值、方差、最大值和最小值等指标供 NM 选择使用。
YARN Operator 动态感知和纵向伸缩
在 NM 常驻的部署模式下,YARN Operator 提供了新的策略。通过在 YARN Operator 接收到当前部署的节点 10 min 内可利用的资源指标,用来决策是否对所在宿主机上的 NM 进行纵向伸缩。
对于扩容,一旦超过 3 核,则向 RM 进行节点的资源更新。扩容过程如图 5 所示:
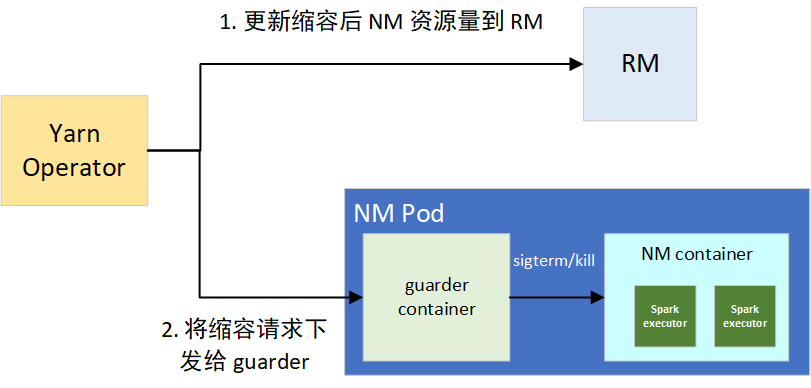
缩容的话,如果抑制率控制在 10% 以内的波动,我们默认忽略。一旦超过阈值,则会触发缩容操作,分为两个步骤:1)更新节点在 RM 上的可用资源,用来堵住增量的 container 分配需求;2)将缩容请求下发给 NM 的 guarder sidecar 容器,来对部分资源超用的 container 的平滑和强制下线,避免因占用过多 CPU 资源导致整个 NM 被驱逐。
guarder 在拿到目标可用资源后,会对当前所有的 YARN container 进程进行排序,包括框架类型、运行时长、资源使用量三者,决策拿到要 kill 的进程。在 kill 前,会进行 SIGPWR 信号的发送,用来平滑下线任务,Spark Executor 接收到此信号,会尽可能平滑退出。缩容过程如图 6 所示:
通常节点的资源量变动幅度不是很大,且 NM 可使用的资源量维持在较高的水平(平均有 20 core),部分 container 的存活周期为 10 秒级,因此很快就能降至目标可用资源量值。涉及到变动幅度频繁的节点,通过 guarder 的平滑下线和 kill 决策,container 失败数非常低,从线上来看,按天统计平均 force kill container 数目为 5 左右,guarder 发送的平滑下线信号有 500+,可以看到效果比较好。
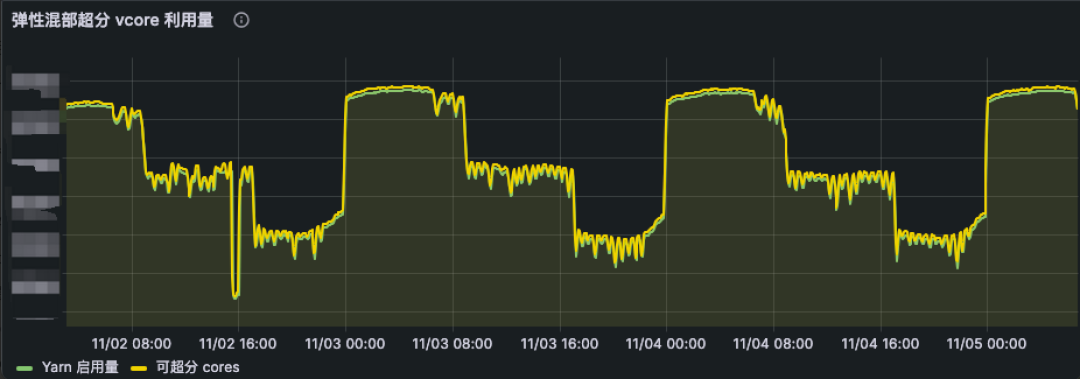
在离线 CPU 资源感知功能全面上线后,NM Pod 被驱逐的情况基本消失。因此,我们逐步将混部时间由凌晨的 0 点至 8 点,扩展到全天 24h 运行,并根据在线业务负载分布情况,在一天的不同时段采用不同的 CPU 资源超分比,从而实现全天候实时弹性调度策略。伴随着全天 24h 的稳定运行,集群 CPU 利用率再度提升了 10%。从线上混部 K8s 集群来看(如图 7 所示),弹性 NM 的 vcore 使用资源量(绿线)也是动态贴合可超分的资源(黄线)。
阶段四:提升资源超分率
为了提供更多的离线资源,我们开始逐步调高 CPU 资源的超分比,而 NM Pod 被驱逐的情况再次发生了,这一次的原因是内存驱逐。我们将物理机器的内存超分比设置为 90%,从集群总体情况看,物理机器上的内存资源比较充足,刚开始我们只关注了 CPU 资源,没有关注内存资源。而 NM 的 CPU 和内存按照 1:4 的比例来使用,随着 CPU 超分比的提高,YARN 任务需要的内存也在提升,最终当 K8s 节点内存使用量超过设定的阈值时,就会触发 Koordinator 的驱逐操作。
经过观察,我们发现内存驱逐在某些节点上发生的概率特别高,这些节点的内存比其他节点内存小,而 CPU 数量是相同的,因此这些节点在 CPU 超分比相同的情况下,更容易因为内存原因被驱逐,它们能提供的离线内存更少。因此,guarder 容器也需要感知节点的离线内存资源用量,并根据资源用量采取相应的措施,这个过程与 CPU 离线资源的感知一样的,不再赘述。
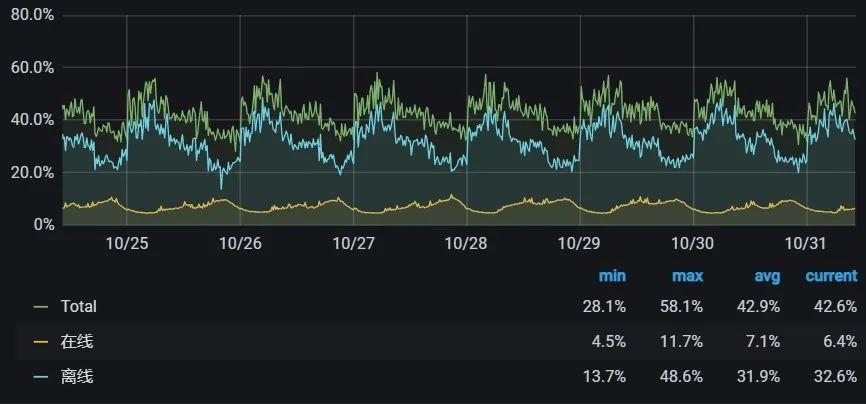
内存感知功能上线后,我们又逐步提升了 CPU 的超分比,当前在线业务集群的 CPU 利用率已经提升到全天平均 40%+、夜间 58% 左右。
效果
通过大数据离线计算与在线业务的混部,我们将在线业务集群 CPU 平均利用率从 9% 提升到 40%+,在不增加机器采购的同时满足了部分大数据弹性计算的资源需求,每年节省数千万元成本。
同时,我们也将这套框架应用到大数据 OLAP 分析场景,实现了 Impala/Trino on K8s 弹性架构,满足数据分析师日常动态查询需求,支持了寒暑假、春晚直播、广告 618 与双 11 等重要活动期间临时大批量资源扩容需求,保障了广告、BI、会员等数据分析场景的稳定、高效。
未来计划
当前,大数据离在线混部已稳定运行一年多,并取得阶段性成果,未来我们将基于这套框架进一步推进大数据云原生化:
-
完善离在线混部可观测性:建立精细化的 QoS 监控,保障在线服务、大数据弹性计算任务的稳定性。
-
加大离在线混部力度:K8s 层面,继续提高宿主机资源利用率,提供更多的弹性计算资源供大数据使用。大数据层面,进一步提升通过离在线混部框架调度的弹性计算资源占比,节省更多成本。
-
大数据混合云计算:目前我们主要使用爱奇艺内部的 K8s 进行混部,随着公司混合云战略的推进,我们计划将混部推广到公有云 K8s 集群中,实现大数据计算的多云调度。
-
探索云原生的混部模式:尽管复用 YARN 的调度器能让我们快速利用混部资源,但它也带来了额外的资源管理和调度开销。后续我们也将探索云原生的混部模式,尝试将大数据的计算任务直接使用 K8s 的离线调度器进行调度,进一步优化调度速度和资源利用率。
参考资料
[1] 一文看懂业界在离线混部技术. https://www.infoq.cn/article/knqswz6qrggwmv6axwqu
[2] Koordinator: QoS-based Scheduling for Colocating on Kubernetes. https://koordinator.sh/
[3] Crane: Cloud Resource Analytics and Economics in Kubernetes clusters. https://gocrane.io/
[4] Katalyst: a universal solution to help improve resource utilization and optimize the overall costs in the cloud. https://github.com/kubewharf/katalyst-core
[5] Apache Hadoop YARN - Node Labels. https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/NodeLabel.html
[6] Apache Hadoop YARN - Graceful Decommission of YARN Nodes. https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/GracefulDecommission.html
[7] Apache Spark - Add better handling for node shutdown. https://issues.apache.org/jira/browse/SPARK-20624
[8] Apache Uniffle: Remote Shuffle Service. https://uniffle.apache.org/
[9] Apache Uniffle - Support getting memory data skip by upstream task ids. https://github.com/apache/incubator-uniffle/pull/358
[10] Apache Uniffle - Support storing shuffle data to secured dfs cluster. https://github.com/apache/incubator-uniffle/pull/53
[11] Apache Uniffle - Huge partition optimization. https://github.com/apache/incubator-uniffle/issues/378
[12] Koordinator - CPU Suppress. https://koordinator.sh/docs/user-manuals/cpu-suppress/
[13] Koordinator - Eviction Strategy based on CPU Satisfaction. https://koordinator.sh/docs/user-manuals/cpu-evict/

本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。