
著者の頭の中では、メッセージ キュー、キャッシュ、サブデータベースとサブテーブルは、高同時実行性ソリューションの三剣士です。
これまでのキャリアの中で、ActiveMQ、RabbitMQ、Kafka、RocketMQ などのよく知られたメッセージ キューを使用してきました。
この記事では、著者が自身の実体験を組み合わせて、メッセージ キューの 7 つの古典的なアプリケーション シナリオを紹介します。
1 非同期とデカップリング
筆者はかつて、電子商取引会社でユーザー登録、照会、変更などの基本的な機能を提供するユーザーサービスを担当していました。ユーザーが正常に登録したら、テキスト メッセージをユーザーに送信する必要があります。
この図では、新しいユーザーの追加とテキスト メッセージの送信がすべてユーザー センター サービスに含まれています。この方法の欠点は明らかです。
-
SMS チャネルは十分に安定しておらず、テキスト メッセージの送信に約 5 秒かかるため、ユーザー登録インターフェイスに非常に時間がかかり、フロントエンドのユーザー エクスペリエンスに影響を与えます。
-
SMS チャネル インターフェイスが変更された場合は、ユーザー センター コードを変更する必要があります。ただし、ユーザー センターは基幹システムです。オンラインにアクセスするときは常に注意が必要です。コア以外の機能がコア システムに影響を与えるため、これは非常に厄介に感じられます。
この問題を解決するために、作者はメッセージ キューを使用してメッセージ キューを再構築しました。

-
非同期
ユーザー センター サービスはユーザー情報を正常に保存した後、メッセージ キューにメッセージを送信し、結果をすぐにフロントエンドに返します。これにより、時間がかかり、ユーザー エクスペリエンスに影響を与えるという問題を回避できます。
-
デカップリング
タスク サービスはメッセージを受信すると、SMS サービスを呼び出して SMS を送信します。これにより、コア サービスが非コア機能から分離され、システム間の結合が大幅に軽減されます。
2 ピーク除去
同時実行性の高いシナリオでは、突然のリクエストのピークによってシステムが不安定になりやすくなります。たとえば、データベースにアクセスする大量のリクエストがデータベースに大きな負荷をかけたり、システムのリソース (CPU や IO) がボトルネックになったりする可能性があります。 。
著者はかつて神州の自家用車注文チームに勤務していましたが、注文の乗客ライフサイクル中に、注文変更操作はまず注文キャッシュを変更し、次に注文発行サービスがメッセージを消費して注文かどうかを判断します。注文情報が正常であれば(故障の有無など)、注文データが正しければデータベースに保存されます。

リクエストのピークに直面したとき、コンシューマーの同時実行性はしきい値の範囲内にあり、消費速度は比較的均一であるため、実際にリクエストのピークに直面している注文システムのプロデューサーには大きな影響はありません。フロントエンドもより安定します。
3 メッセージバス
いわゆるバスは、マザーボード内のデータ バスに似ており、データを送信および対話する機能を備えており、当事者は直接通信せず、バスを標準の通信インターフェイスとして使用します。
著者はかつて宝くじ会社の注文チームに勤務していましたが、宝くじの注文のライフサイクルでは、作成、サブ注文の分割、チケットの発行、賞金の計算などの多くのステップを経ました。各リンクは異なるサービス処理を必要とし、各システムには独自の独立したテーブルがあり、ビジネス機能は比較的独立しています。すべてのアプリケーションが注文マスター テーブル内の情報を変更する必要がある場合、非常に混乱するでしょう。
したがって、会社のアーキテクトは<font color="red">ディスパッチ センター</font>のサービスを設計しました。ディスパッチ センターは注文情報を保持しますが、サブサービスとは通信せず、メッセージ キューと発券ゲートウェイ システムを介して通信します。賞金計算サービスなどの情報の送信および交換。
メッセージ バスのアーキテクチャ設計により、システムがより分離され、各システムが独自の役割を実行できるようになります。
4 遅延したタスク
ユーザーが Meituan アプリで注文し、すぐに支払いを行わなかった場合、注文の詳細を入力する際にカウントダウンが表示され、支払い時間を過ぎると注文は自動的にキャンセルされます。
非常に洗練された方法は、メッセージ キューからの遅延メッセージを使用することです。
注文サービスは注文を生成した後、遅延メッセージをメッセージ キューに送信します。メッセージキューは、メッセージが支払い期限に達すると、メッセージをコンシューマに配信します。コンシューマがメッセージを受信した後、注文ステータスが支払い済みであるかどうかを判断し、支払いが完了していない場合は、注文をキャンセルするロジックが実行されます。

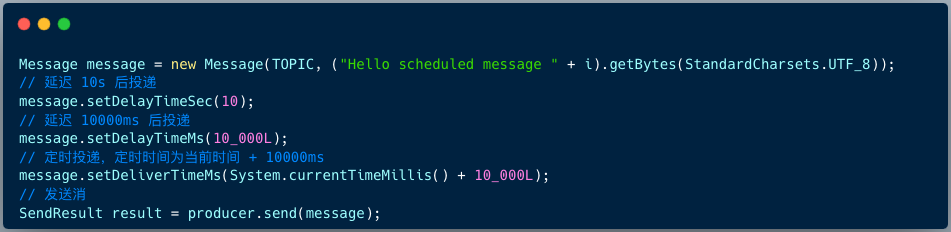
RocketMQ 4.X プロデューサーが遅延メッセージを送信するためのコードは次のとおりです。
Message msg = new Message();
msg.setTopic("TopicA");
msg.setTags("Tag");
msg.setBody("this is a delay message".getBytes());
//设置延迟level为5,对应延迟1分钟
msg.setDelayTimeLevel(5);
producer.send(msg);
RocketMQ 4.X バージョンは、デフォルトで 18 レベルの遅延メッセージをサポートします。これは、ブローカー側の messageDelayLevel 設定項目によって決定されます。

RocketMQ 5.X バージョンでは、メッセージの遅延をいつでもサポートします。クライアントは、メッセージの構築時に遅延時間またはタイミング時間を指定するための 3 つの API を提供します。
5 無線消費量
ブロードキャスト消費: ブロードキャスト消費モードを使用する場合、各メッセージはクラスター内のすべてのコンシューマーにプッシュされ、メッセージが各コンシューマーによって少なくとも 1 回消費されることが保証されます。
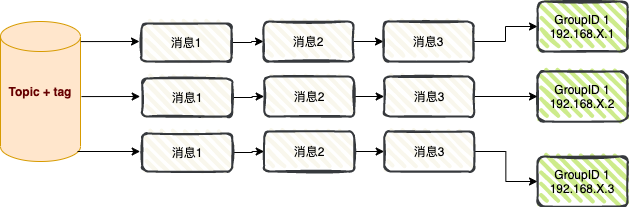
ブロードキャスト消費は主に、メッセージ プッシュとキャッシュ同期の2 つのシナリオで使用されます。
01 メッセージプッシュ
以下の図は、ユーザーが注文すると、配車システムが適切なアルゴリズムに基づいて注文をドライバーに配車します。 -end はディスパッチプッシュメッセージを受信します。
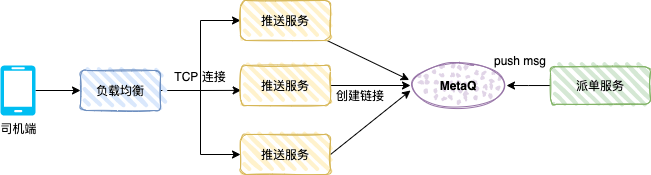
プッシュ サービスは TCP サービス (カスタム プロトコル) であり、メッセージ モードはブロードキャスト消費です。
ドライバーがドライバー APP を開いた後、APP は負荷分散とプッシュ サービスを通じて長い接続を作成し、プッシュ サービスは TCP 接続参照 (ドライバー番号や TCP チャネル参照など) を保存します。
ディスパッチ サービスはプロデューサーであり、ディスパッチ データを MetaQ に送信します。各プッシュ サービスは、ドライバーの TCP チャネルがローカル メモリに存在するかどうかを判断し、存在する場合はデータをサーバーにプッシュします。 TCP接続経由。
02 キャッシュ同期
同時実行性が高いシナリオでは、多くのアプリケーションがローカル キャッシュを使用してシステム パフォーマンスを向上させます。
ローカル キャッシュには、HashMap、ConcurrentHashMap、またはキャッシュ フレームワークの Guava Cache または Caffeine キャッシュを使用できます。

上の図に示すように、アプリケーション A が RocketMQ コンシューマーとして開始された後、メッセージ モードはブロードキャスト消費に設定されます。インターフェイスのパフォーマンスを向上させるために、各アプリケーション ノードはディクショナリ テーブルをローカル キャッシュにロードします。
ディクショナリ テーブルのデータが変更されると、ビジネス システムを通じてメッセージが RocketMQ に送信され、各アプリケーション ノードがメッセージを消費してローカル キャッシュを更新します。
6 分散トランザクション
電子商取引のトランザクション シナリオを例にとると、注文に対するユーザーの支払いという中核的な操作には、下流の物流配送、ポイントの変更、ショッピング カートのステータスのクリアなど、複数のサブシステムの変更も含まれます。
![]()
1. 従来の XA トランザクション ソリューション: パフォーマンスが不十分
上記 4 つのブランチの実行結果の一貫性を確保するために、一般的なソリューションは XA プロトコルに基づく分散トランザクション システムによって実装されます。 4 つの呼び出しブランチを、4 つの独立したトランザクション ブランチを含む大きなトランザクションにカプセル化します。 XA分散トランザクションによるソリューションは、業務処理結果の正確性は満たせますが、最大のデメリットは、マルチブランチ環境では、下流ブランチ数が増えるとリソースのロック範囲が大きくなり、同時実行性が低下することです。システムのパフォーマンスはますます悪化します。
2. 通常のメッセージスキームに基づく: 一貫性を確保するのが難しい
![]()
このソリューションでは、メッセージの下流ブランチと注文システム変更のメインブランチで不一致が発生する傾向があります。次に例を示します。
- メッセージは正常に送信されましたが、注文は正常に実行されなかったため、トランザクション全体をロールバックする必要があります。
- 注文は正常に実行されましたが、メッセージは正常に送信されず、矛盾を発見するには追加の補償が必要でした。
- メッセージ送信のタイムアウトは不明であり、注文をロールバックする必要があるのか、それとも送信された注文を変更する必要があるのかを判断することはできません。
3. RocketMQ 分散トランザクション メッセージに基づく: 結果整合性をサポート
前述の通常のメッセージ ソリューションにおいて、通常のメッセージと注文トランザクションの一貫性が保証できない理由は、基本的に、通常のメッセージにはスタンドアロン データベース トランザクションのようなコミット、ロールバック、統合調整の機能がないためです。
RocketMQ に基づいて実装された分散トランザクション メッセージ機能は、通常のメッセージに基づいた 2 段階の送信機能をサポートします。 2 フェーズの送信をローカル トランザクションにバインドして、グローバルな送信結果の一貫性を実現します。
RocketMQ トランザクション メッセージは、分散シナリオにおけるメッセージ生成とローカル トランザクションの最終的な整合性の確保をサポートします。インタラクションのプロセスを次の図に示します。
![]()
1. プロデューサーはメッセージをブローカーに送信します。
2. ブローカーはメッセージの永続化に成功すると、メッセージが正常に送信されたことを確認するためにプロデューサに Ack を返します。この時点で、メッセージは「一時的に配信不能」としてマークされます。取引メッセージに記載しております。
3. プロデューサはローカル トランザクション ロジックの実行を開始します。
4. プロデューサは、ローカル トランザクションの実行結果に基づいて、二次確認結果(コミットまたはロールバック)をサーバーに送信します。ブローカーが確認結果を受信した後の処理ロジックは次のとおりです。
- 2 番目の確認結果はコミットです。ブローカーはセミトランザクション メッセージを配信可能としてマークし、コンシューマに配信します。
- 2 番目の確認結果はロールバックです。ブローカーはトランザクションをロールバックし、セミトランザクション メッセージをコンシューマに配信しません。
5. ネットワークが切断されたり、プロデューサー アプリケーションが再起動されたりする特殊な状況で、送信者が送信した二次確認結果をブローカーが受信しない場合、またはブローカーが受信した二次確認結果が不明ステータスの場合、修正後の一定期間、サービス 端末は、メッセージ プロデューサー、つまりプロデューサー クラスタ内のプロデューサー インスタンスからのメッセージ レビュー。
- プロデューサはメッセージ レビューを受信した後、メッセージに対応するローカル トランザクション実行の最終結果をチェックする必要があります。
- プロデューサは、チェックされたローカル トランザクションの最終ステータスに基づいて2 番目の確認を再度送信し、サーバーは依然としてステップ 4 に従ってハーフトランザクション メッセージを処理します。
7 データ転送ハブ
過去 10 年間で、KV ストレージ (HBase)、検索 (ElasticSearch)、ストリーミング処理 (Storm、Spark、Samza)、時系列データベース (OpenTSDB) などの特殊なシステムが登場しました。これらのシステムは単一の目標を念頭に置いて作成されており、そのシンプルさにより、汎用ハードウェア上に分散システムを構築することがより簡単かつコスト効率よくなります。
多くの場合、同じデータセットを複数の特殊なシステムに注入する必要があります。
たとえば、アプリケーション ログをオフライン ログ分析に使用する場合、個々のログ レコードの検索も不可欠です。メッセージ キューを使用して、それぞれの種類のデータを収集し、それらを独自の専用システムにインポートするための独立したワークフローを構築することは明らかに非現実的です。はデータ転送ハブとして機能し、同じデータを異なる専用システムにインポートできます。
ログ同期には主に、ログ収集クライアント、Kafka メッセージ キュー、バックエンド ログ処理アプリケーションという 3 つの主要な部分があります。
- ログ収集クライアントは、さまざまなユーザー アプリケーション サービスのログ データを収集する役割を担っており、ログをメッセージの形式で Kafka クライアントに「バッチ」および「非同期」で送信します。 Kafka クライアントはメッセージをバッチで送信および圧縮します。これは、アプリケーション サービスのパフォーマンスにほとんど影響を与えません。
- Kafka はログをメッセージ ファイルに保存し、永続性を提供します。
- Logstash などのログ処理アプリケーションは、Kafka でログ メッセージをサブスクライブして消費し、最終的にファイル検索サービスがログを取得するか、Kafka が体系的な保存と分析のために Hadoop などの他のビッグ データ アプリケーションにメッセージを渡します。

私の記事がお役に立ちましたら、「いいね!」、「読んでください」、「転送」していただければ、より質の高い記事を作成することができますので、よろしくお願いいたします。
