基本的な紹介
概要
2 つのホスト間の距離が比較的長い場合 (数十、数百キロ、さらには数千キロ離れているなど) 、別のタイプのネットワーク構造、つまり広域ネットワークが必要になります。WAN には厳密な定義はありません。通常、広範囲 (都市の範囲をはるかに超えた)をカバーする長距離の単一ネットワークを指します。いくつかのノード スイッチと、これらのスイッチを接続する高速リンクで構成されます。インターネットは、2 つ以上のコンピュータ ネットワークを相互接続することによって形成されます。異なるネットワークの「相互接続」が最大の特徴です。

リモート LAN はルーターを介してWANに接続され、広い範囲をカバーするインターネットを形成します。
- WAN は、ノード スイッチを使用してホストを接続する単一のネットワークです。インターネットはルーターを使用して複数のネットワークを接続します。パケット転送の観点から見ると、ノード スイッチとルーターは同様の動作原理を持っています。
- ノード スイッチは単一のネットワーク内でパケットを転送し、ルーターは複数のネットワークで構成されるインターネット内でパケットを転送します。WAN (または LAN )上にあるホストがネットワーク内で通信する場合、使用する必要があるのはそのネットワークの物理アドレスのみです。
ネットワーク相互接続を実現する中継装置を中継装置または中継システムといいます。
中間デバイスのレベルに応じて、次のタイプの中間デバイスがあります。
- 物理層の中間装置-リピータ(リピータ)
- データリンク層の中間デバイス-ブリッジまたはブリッジ
- ネットワーク層の中間デバイス-ルーター
- ネットワーク層上の中間デバイス-ゲートウェイ
中継システムがリピータまたはブリッジである場合、通常はネットワーク相互接続とはみなされません。これはネットワークを拡張しただけなので、やはりネットワークです。
ゲートウェイを使用してネットワーク相互接続を実装します。N個のネットワークが相互接続されている場合、2 つのネットワークごとにプロトコル コンバータが必要となるため、N個のネットワークには最大N ( N-1 )個のプロトコル コンバータが必要になります。ゲートウェイの設計を簡素化するために、インターネットの概念が提案されています。インターネットの概念を使用する場合、ネットワークとインターネット プロトコル間の相互変換を実現するだけで済みます。N 個のネットワーク相互接続の場合、2 N個のプロトコル コンバータで十分です。インターネットはこのアプローチを採用しています。相互接続に参加しているすべてのコンピュータ ネットワークは、同じインターネット プロトコル IP を使用します。そして、相互接続に参加するコンピュータネットワークは、仮想的な相互接続ネットワークを形成することに相当する。

仮想相互接続ネットワークの意味
- いわゆる仮想相互接続ネットワークは、論理相互接続ネットワークでもあり、これは、相互接続されたさまざまな物理ネットワークの異質性がもともと客観的に存在することを意味しますが、IPプロトコルを使用して、これらの異なる性能のネットワークをユーザーごとに異なるものにすることができるように見えます。統合されたネットワーク。
- IP プロトコルを使用した仮想相互接続ネットワークをIPネットワークと呼ぶこともあります。
- 仮想相互接続ネットワークを使用する利点は、インターネット上のホストが通信するときに、相互接続の特定のネットワークの異種混合の詳細を見ることなく、あたかもネットワーク上で通信しているかのように見えることです。
- このグローバルIPネットワークの上位層でTCPプロトコルを使用すると、現在のインターネットとなります。
この問題をネットワーク層からのみ考える場合、IPデータグラムはネットワーク層で送信されると想像できます。

サービスと機能
コンピュータネットワークの分野では、ネットワーク層がトランスポート層にどのようなサービスを提供すべきか(「コネクション型」か「コネクションレス」か)、長期にわたる議論が巻き起こっています。議論の本質は次のとおりです:コンピュータ通信における信頼性の高い配信に責任を負うのは誰ですか?それはネットワークですか、それともエンド システムですか?
- 電気通信ネットワークの成功経験に基づいて、ネットワークに信頼性の高い配信を担当させ、コネクション指向の通信方式を採用します。仮想回線を確立して、双方間の通信に必要なすべてのネットワーク リソースを確保します。信頼性の高い伝送ネットワーク プロトコルが使用されている場合、送信されたパケットはエラーなく順番に宛先に到達できます。
- ネットワーク層が信頼性の高い配信を提供しない場合は、ルーターの設計を簡素化し、エンドツーエンドの信頼できる通信をトランスポート層が担当します。これはインターネットでデータグラムを使用するという設計上のアイデアであり、多くの利点があります。
仮想回線サービス
仮想回線サービスは、すべてのパケットが宛先システムに順番に到達できるように、ネットワーク層によってトランスポート層に提供される信頼性の高いデータ送信方法です。
仮想回線サービスを実行する場合、2 つのエンド システム間にサービスを提供する仮想回線が存在します。仮想回線は単なる論理接続です。パケットはストア アンド フォワード方式でこの論理接続に沿って送信されます。実際に物理接続は確立されません。回線交換電話通信では、最初に実際の接続が確立されます。したがって、パケット交換仮想接続は回線交換接続と似ていますが、まったく同じではありません。

データグラムサービス
データグラム サービスは、ネットワーク層によって提供される、シンプル、柔軟、コネクションレス型のベストエフォート型の配信サービスです。インターネットで採用されました。
- ネットワークは、パケットを送信する前に接続を確立する必要はありません。各パケット (つまり、IPデータグラム)は完全な宛先アドレス情報を運び、その前後のパケット(番号は付けられていない)に関係なく、異なるルートを通じて独立して送信されます。
- ネットワーク層はサービス品質の保証を提供しません。各パケットは異なるルートを通過し、宛先システムに到達するまでにかかる時間も異なるため、送信されたパケットは間違っていたり、失われたり、繰り返されたり、順番が狂ったり(順番どおりに宛先に到着したりすること)する可能性があります。パケット送信の制限時間は保証されません。
ベストエフォート型サービスを提供するメリット
- 伝送ネットワークはエンドツーエンドの信頼性の高い伝送サービスを提供しないため、ネットワーク内のルータは比較的単純かつ安価に作成できます(電気通信ネットワークのスイッチと比較して) 。
- ホスト(エンド システム)内のプロセス間の通信の信頼性が必要な場合、ネットワークのホスト内のトランスポート層が責任を負います(エラー処理、フロー制御などを含む) 。
- ネットワークのコストは大幅に削減され、動作モードは柔軟で、さまざまなアプリケーションに適応できます。
- インターネットが今日の規模にまで発展したことは、この設計思想の正しさを完全に証明しています。

H1 から H2 に送信されたパケットは、異なるパスに沿って送信される可能性があります
| プロジェクト |
仮想回線サービス |
データグラムサービス |
| デザインのアイデア |
信頼性の高い通信はネットワークの責任です |
信頼性の高い通信はユーザーホストの責任です |
| エンドツーエンド接続 |
必要 |
不要 |
| 宛先アドレス |
接続を確立するときにのみ使用され、各グループは仮想回線番号を使用します。 |
各パケットには完全な宛先アドレスが含まれている必要があります |
| パケット転送 |
すべてのパケットは、確立された同じ(仮想)ルートに従って送信されます |
各パケットは送信のために独立してルーティングされます |
| ノード障害 |
仮想回線内の障害のあるノードは機能しません |
障害が発生したノードではパケットが失われる可能性があり、一部のルートが変更される場合もあります。 |
| グループ化の順序 |
順番に送って順番に受け取る |
順番に送信しますが、必ずしも順番に受信するとは限りません |
| エンドツーエンドのエラー制御とフロー制御 |
ネットワークまたはユーザーホストが責任を負います |
ユーザーホストの責任者 |
インターネットプロトコルIPv4
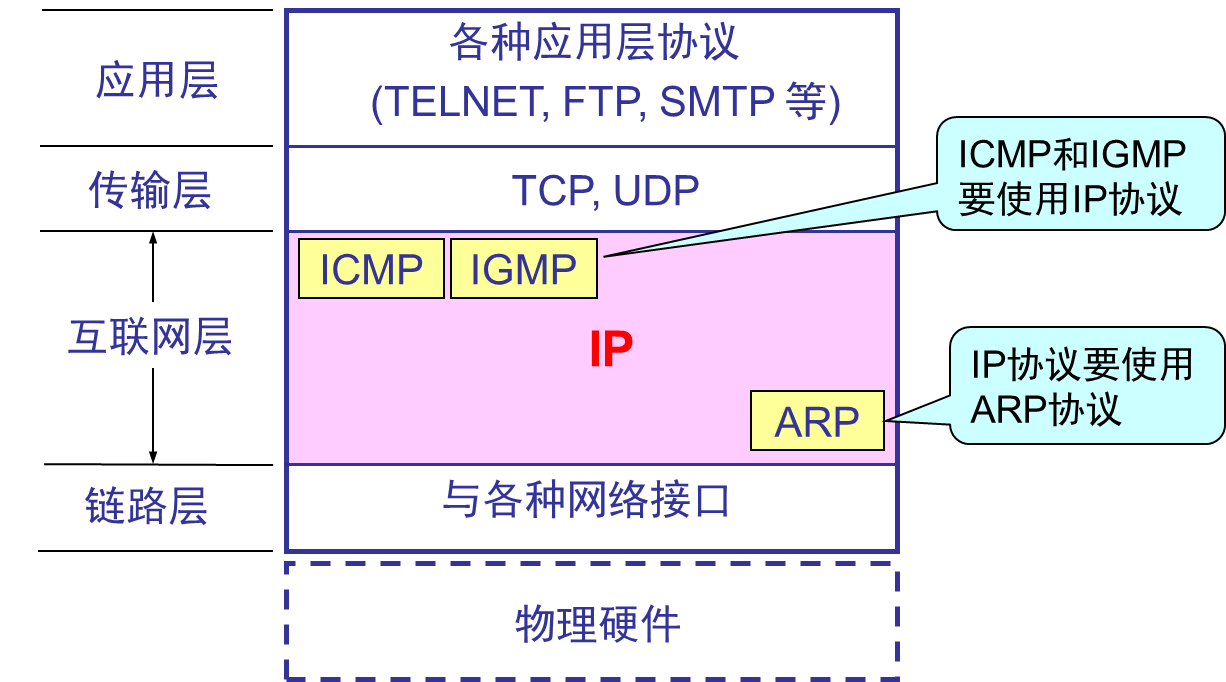
インターネット プロトコル IP は、TCP/IPシステムの 2 つの重要なプロトコルのうちの 1 つです。IPv4 は最終的にはIPv6に置き換えられますが、依然として現在使用されている最も重要なインターネット プロトコルです。IP と組み合わせて使用されるプロトコルは3 つあります。
- アドレス解決プロトコルARP (アドレス解決プロトコル)
- インターネット制御メッセージ プロトコルICMP (インターネット制御メッセージ プロトコル)
- インターネット グループ管理プロトコルIGMP (インターネット グループ管理プロトコル)
インターネットプロトコルIPとそのサポートプロトコル
機密IPアドレス
IPv4プロトコルの主な特徴
- IPv4 プロトコルは、コネクションレス型のパケット送信サービスを提供しますが、サービスの品質は保証されません(つまり、送信されるパケットのエラー、損失、重複、順序の乱れなどは保証されません) 。
- IPv4 プロトコルは、ポイントツーポイントのネットワーク層通信プロトコルです。
- Pv4 プロトコルは、物理ネットワークの違いからトランスポート層を保護します。ネットワーク層はIPプロトコルを使用して、統合されたIPパケットをトランスポート層に提供します。これにより、さまざまな異種ネットワークの相互接続が容易になります。
IP アドレスとその割り当て
- インターネット全体を単一の抽象的なネットワークとして考えてください。IPアドレスは、インターネットに接続されている各ホスト(またはルーター)に世界中で一意の識別子(長さ32 ビット)を割り当てます。
- P アドレスは、Internet Corporation for Assigned Names and Numbers ( ICANN )によって割り当てられます。
IPアドレスのアドレス指定方法
IP アドレス指定は 2 つの段階を経ます。
- IPアドレスを分類します。これは最も基本的なアドレス指定方法であり、対応する標準プロトコルが1981 年に採用されました。機密IPアドレスに存在する問題に基づいて、サブネット分割と可変長サブネット分割の概念が1985 年に提案されました。これは、最も基本的な分類アドレス指定方法を改良したものです。
- 未分類の IPアドレス。1993 年に、新しい分類アドレス指定方法が提案され、推進され、適用されてきました。
いわゆる「機密 IPアドレス」は、IPアドレスをいくつかの固定カテゴリに分割することです。各タイプのアドレスは 2 つの固定長フィールドで構成されます。フィールドの 1 つは、特定のホストを識別するネットワーク番号net-idです(または router )接続されたネットワーク番号。もう 1 つのフィールドはホスト番号host-idで、このタイプのネットワーク内のホスト(または router )の番号を識別します。nこの 2 レベル構造のIPアドレスは、次のように記録できます。IPアドレス::= {<ネットワーク番号>, <ホスト番号>}
このうち、::= は「として定義されている」を表します。
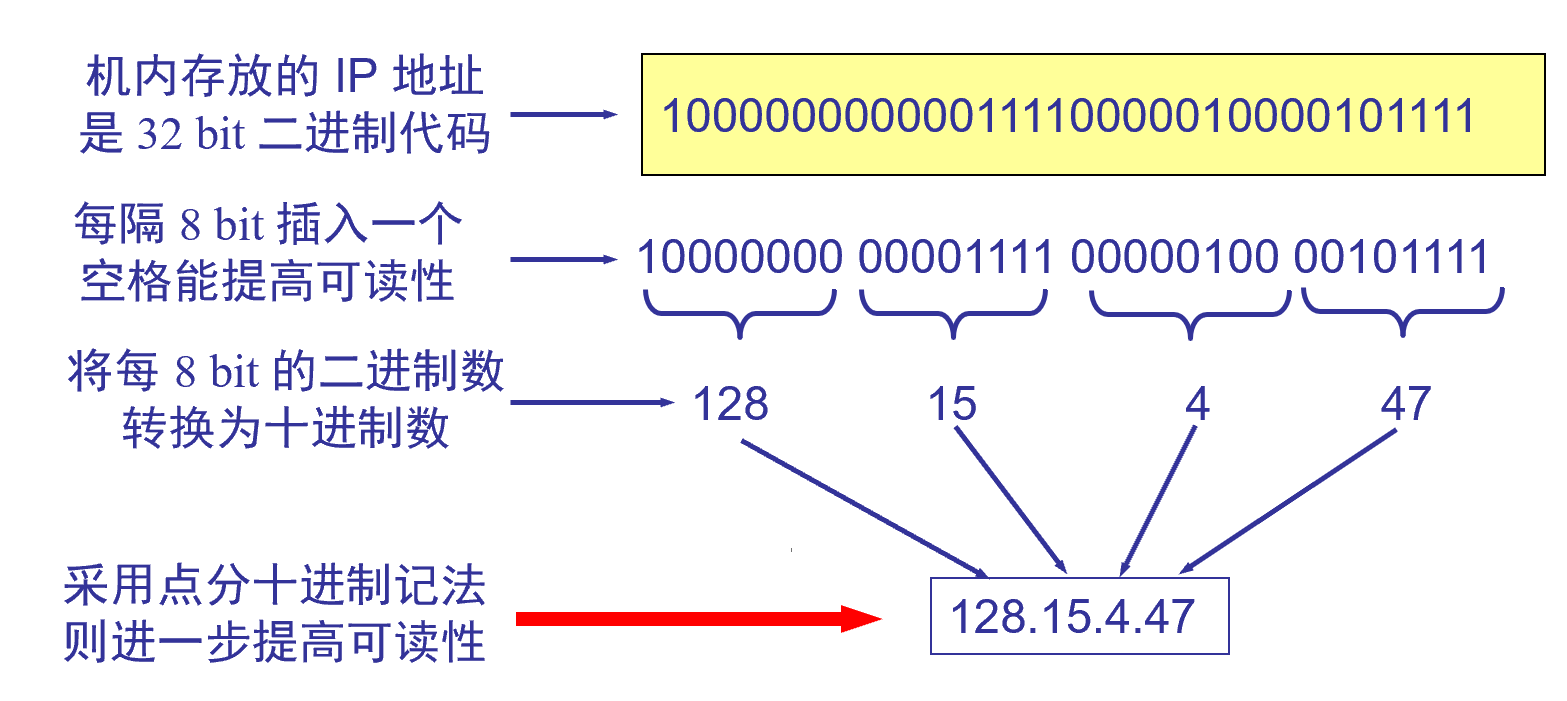
IPv4アドレス形式
IPアドレスの表現-ドット付き 10 進表記
IPアドレスのカテゴリを特定する
2 進数表記のアドレスが指定された場合、最初の数桁はアドレスの種類を示すために使用されます。

- A、00000001 00001011 00001011 11101111 A类
- B. 110 00001 10000011 00011011 11111111クラスC
- C. 10 100111 11011011 10001011 01101111クラスB
- D. 11110 011 10011011 11111011 00001111クラスE
アドレスがドット付き 10 進表記の場合、最初のバイトで表される 10 進数に従ってアドレスの種類が決まります。クラスAは0 ~127 、クラスBは128 ~191 、クラスCは192 ~223 、クラスDは224 ~239 、クラスEは240 ~255 。
- A. 227.12.14.87クラスD
- B. 193.14.56.22クラスC
- C. 14.23.120.8クラスA
- D. 252.5.15.111クラスE
- E.134.11.78.56クラスB
特別なIPアドレス
- すべて 0 のネットワーク番号は、このネットワークを指します。
- ネットワーク番号とホスト番号がすべて 1 の場合、ネットワークはブロードキャストされます(ルーターはネットワークを転送しません) 。
- クラス A ネットワーク アドレス127 は、ローカル ソフトウェア ループバック テストに使用される予約アドレスです。
- ホスト番号がすべて 1 の場合は、このネットワーク番号を持つすべてのホストにブロードキャストすることを意味します。
| 住所 カテゴリー |
割り当て可能な ネットワークの最大数 |
最初に割り当て可能なネットワーク番号 |
最後に割り当て可能なネットワーク番号 |
各ネットワークに存在できるホストの最大数 |
アドレス空間全体の約 % |
| あ |
12 5(2 7 -3) |
1 |
126 |
16777214(2 24 -2) |
50% |
| B |
16367(2 16 -17) |
128.1 |
191.255 |
65534(2 16 -2) |
25% |
| C |
2096895(2 21 -257) |
192.0.1 |
223.255.255 |
254(2 8 -2) |
12.5% |
IPアドレスのいくつかの重要な特性
- IP アドレスは階層的なアドレス構造です。ホスト(またはルーター)の地理的位置に関する情報は反映されません。各IPアドレスは、ネットワーク番号とホスト番号の 2 つの部分で構成されます。このアドレス構造の利点は、P アドレス管理機関がIPアドレスを割り当てる際にネットワーク番号(第 1 レベル)のみを割り当て、残りのホスト番号(第 2 レベル)はネットワーク番号を取得する装置が割り当てることです。これにより、IPアドレスの管理が容易になります。ルーターは、宛先ホストが接続されているネットワーク番号に基づいて (宛先ホスト番号を考慮せずに)パケットを転送するだけなので、ルーティング テーブルの項目数が大幅に削減され、ルーティング テーブルが占有する記憶領域が削減されます。
- IP アドレスは、ホスト(またはルーター)とリンクのインターフェイスを指定します。ホストが 2 つのネットワークに同時に接続されている場合、ホストは同時に 2 つの対応する IP アドレスを持っている必要があり、そのネットワーク番号net-idは異なっている必要があります。この種類のホストは、マルチホームホストと呼ばれます。ルーターは少なくとも 2 つのネットワークに接続する必要があるため、ルーターには少なくとも 2 つの異なるIPアドレスも必要です。
- ネットワーク番号net-idが割り当てられたすべてのネットワークは、小規模なローカル エリア ネットワークであっても、地理的に広いエリアをカバーするワイド エリア ネットワークであっても、同等のステータスを持ちます。
- インターネットの観点によれば、ネットワークは同じネットワーク番号を持つホストの集合です。リピータまたはブリッジによって接続された複数の LAN は、すべて同じネットワーク番号net-idを持つため、依然として 1 つのネットワークです。
サブネット
第 3 レベルの IPアドレスの構成
元の IPアドレス設計は十分に合理的ではなく、主に次の点に反映されています。
- IPアドレスの使用には無駄が多く、アドレス空間の利用率が非常に低いです。たとえば、10BASE-Tで許可されるホストの数は1024ですが、クラスBアドレスを申請する必要があるため、 64510 個のアドレスが無駄になり、アドレス空間の使用率はわずか1.56%になります。
- 2 レベルの IPアドレスは十分な柔軟性がありません。あるユニットでは、部門ごとにネットワークを分割する必要がありますが、 2 レベルのIPアドレス構造にはこの点に関する規定がありません。
- 物理ネットワークに基づいてネットワーク番号を割り当てる方法では、ルーティング テーブルのエントリがますます多くなり、ネットワーク パフォーマンスを向上させるのは容易ではありません。
1985 年以降、IPアドレスの形式に「サブネット番号フィールド」が追加され、 IPアドレスの構造が 2 層構造から 3 層構造に変更されました。この方法はサブネット化と呼ばれます。
サブネットを分割するための基本的な考え方
- サブネットの分割は純粋に組織内の内部問題であり、組織外のネットワークに対しては完全に透過的です。
- サブネットの分割方法は、ホスト番号フィールドの最初の数ビットをサブネット番号フィールドとして使用し、 IPアドレス ∷ = {<ネットワーク番号> , <サブネット番号> , <ホスト番号>}
- 他のネットワークからユニットのネットワーク内のホストに送信されるすべての IPデータグラムは、 IPデータグラムの宛先ネットワーク番号に従って、ユニットのネットワークに接続されているルータに送信されます。IPデータグラムを受信した後、ルーターは宛先ネットワーク番号net-idとサブネット番号subnet-idに基づいて宛先サブネットを見つけます。最後に、IPデータグラムは宛先ホストに直接配信されます。
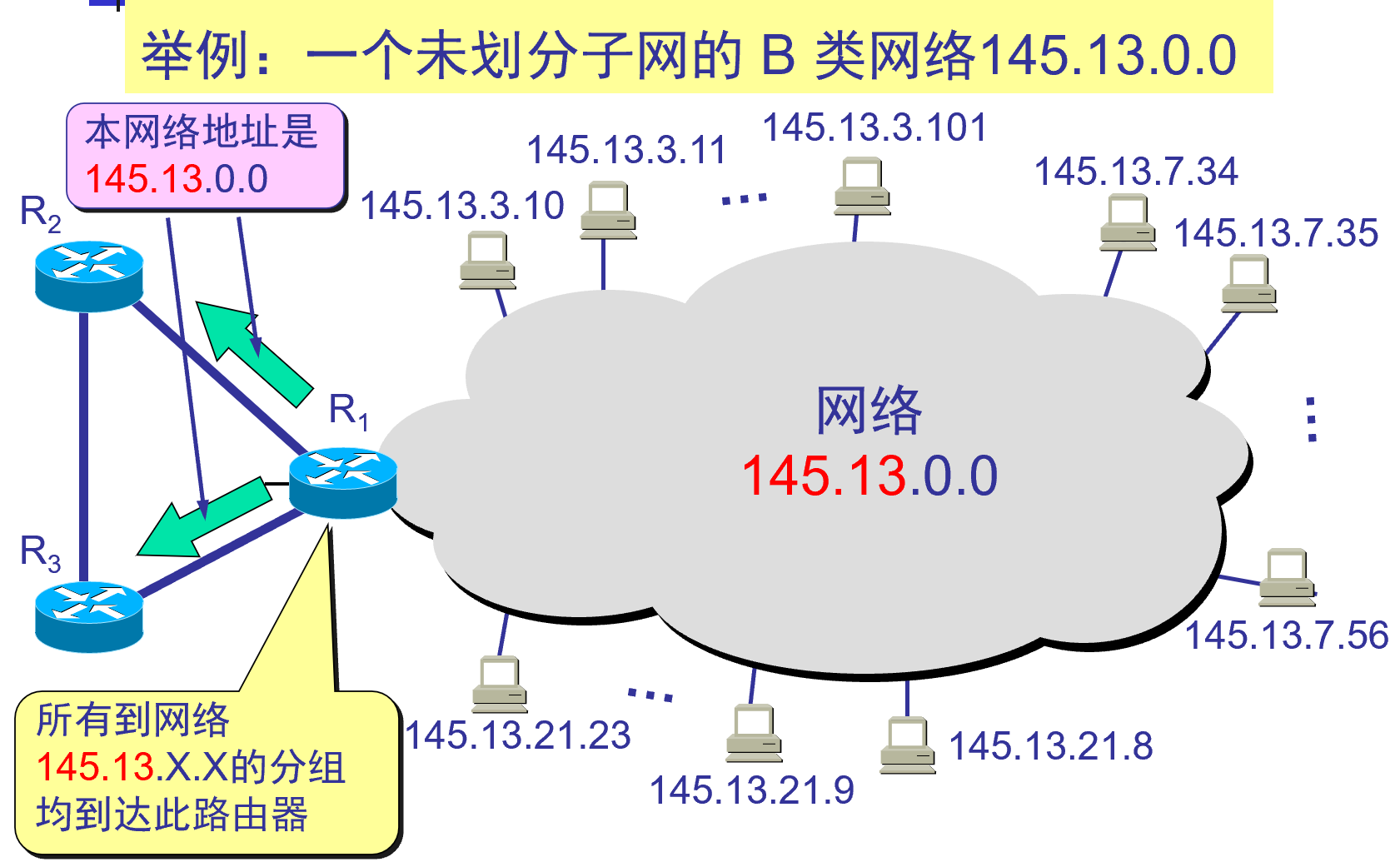
例: サブネット化されていないクラスBネットワーク145.13.0.0
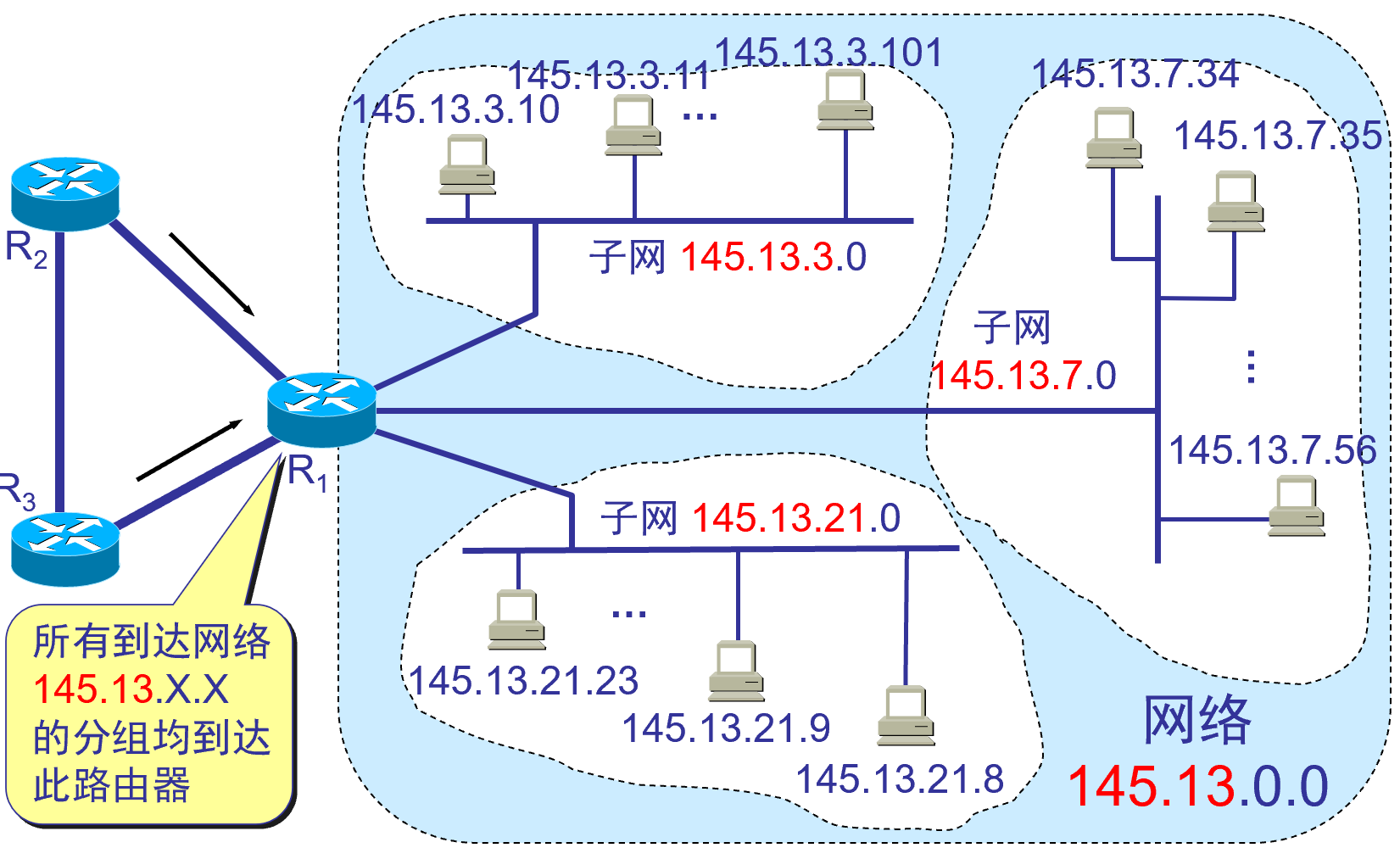
3 つのサブネットに分割されても、外部に対しては 1 つのネットワークのままです。
サブネットマスク
- IP アドレス自体やデータグラムのヘッダーにはサブネット分割に関する情報が含まれていないため、送信元ホストまたは宛先ホストが接続されているネットワークがサブネットに分割されているかどうかをIPデータグラムのヘッダーから判断することはできません。
- サブネットの分割を知るにはどうすればよいですか? サブネット マスクの概念は、サブネットを分割するために使用されます。サブネットマスクを使用すると、IPアドレスのサブネット部分を簡単に見つけることができます。
TCP/IPシステムでは、サブネット マスクは、一連の連続した「 1」とそれに続く一連の連続した「0」で構成される32ビットの 2 進数であると規定されています。ここで、「1」はIPアドレスのネットワーク番号フィールドとサブネット番号フィールドに対応し、「 0」はIPアドレスのホスト番号フィールドに対応します。
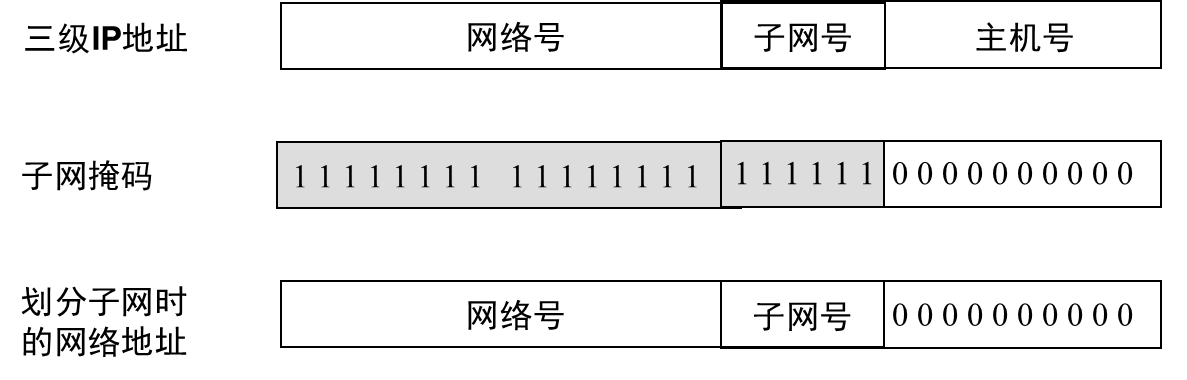
サブネット マスクは、ドット 10 進表記 ( 255.255.0.0)またはネットワーク プレフィックス (またはスラッシュ)表記( 135.41.0.0/16)を使用します。
IPアドレスとサブネットマスクのフィールドの関係
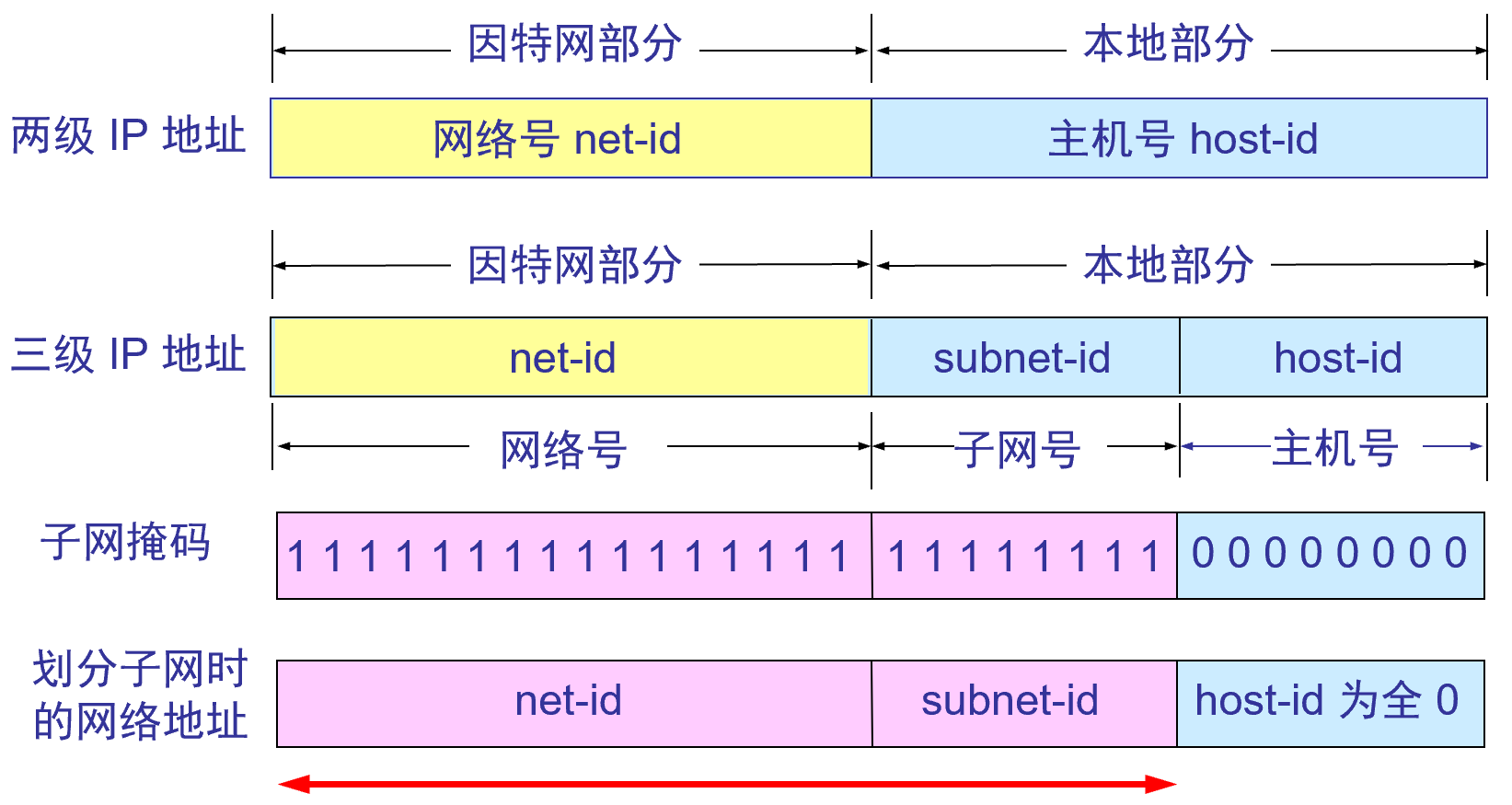
(IPアドレス) AND (サブネット マスク) =ネットワーク アドレス
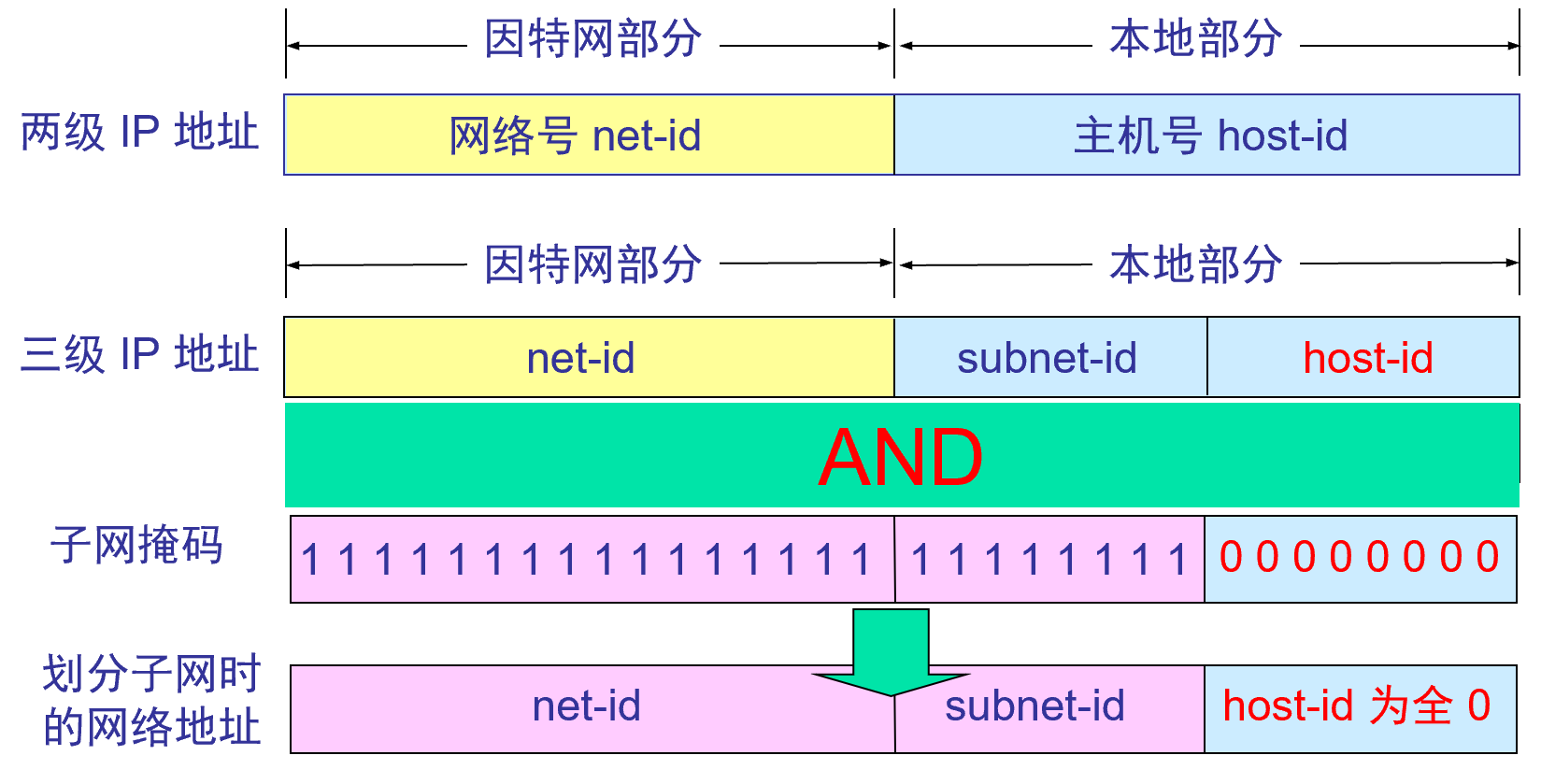
サブネット マスクは、ネットワークまたはサブネットの重要な属性です。インターネット標準では、すべてのネットワークがルーティング テーブルに含まれるサブネット マスクを持つ必要があると規定されています。
サブネット化の概念は、サブネット化されていない状況にも適用されます。サブネット化されていないネットワークは、デフォルトのサブネット マスクを使用できます。サブネット マスクを使用すると、ルーターのルーティング アルゴリズムが簡素化されます。
クラスA 、B 、およびC IPアドレスのデフォルトのサブネット マスク

サブネット化の長所と短所
- 長所-柔軟性の向上。
- 欠点-ネットワークに接続できるホストの総数が減少します。たとえば、クラスBアドレスは最大65,534 のホストに接続できますが、 4 つのサブネットに分割された後の実際の接続ホスト数は32,764になります。これは、 [RFC950] でサブネット番号をすべて0またはすべてにすることはできないと規定されているためです。1秒。
可変長サブネット
サブネット化の本来の目的は、クラスベースのネットワークを同じサイズの複数のサブネットに分割することです。実際、異なるサイズのサブネットを作成すると、IP アドレスの無駄を避けることができます。サイズの異なるサブネットを分割することを可変長サブネット分割といいます。
可変長サブネット化は、異なる長さのサブネット マスクを使用してサブネット番号フィールドを割り当てる技術です。異なるサブネット マスクを使用して、分割されたサブネットをさらに異なるサイズのネットワークに分割することで、IP アドレス リソースの使用率が向上します。
可変長サブネット化の例
クラスB IPアドレス136.48.0.0を持つネットワークは、 32,000 のホストを収容できる1 つのサブネット、 2,000 のホストを収容できる15 のサブネット、および254 のホストを収容できる8 つのサブネットとして構成する必要があります。
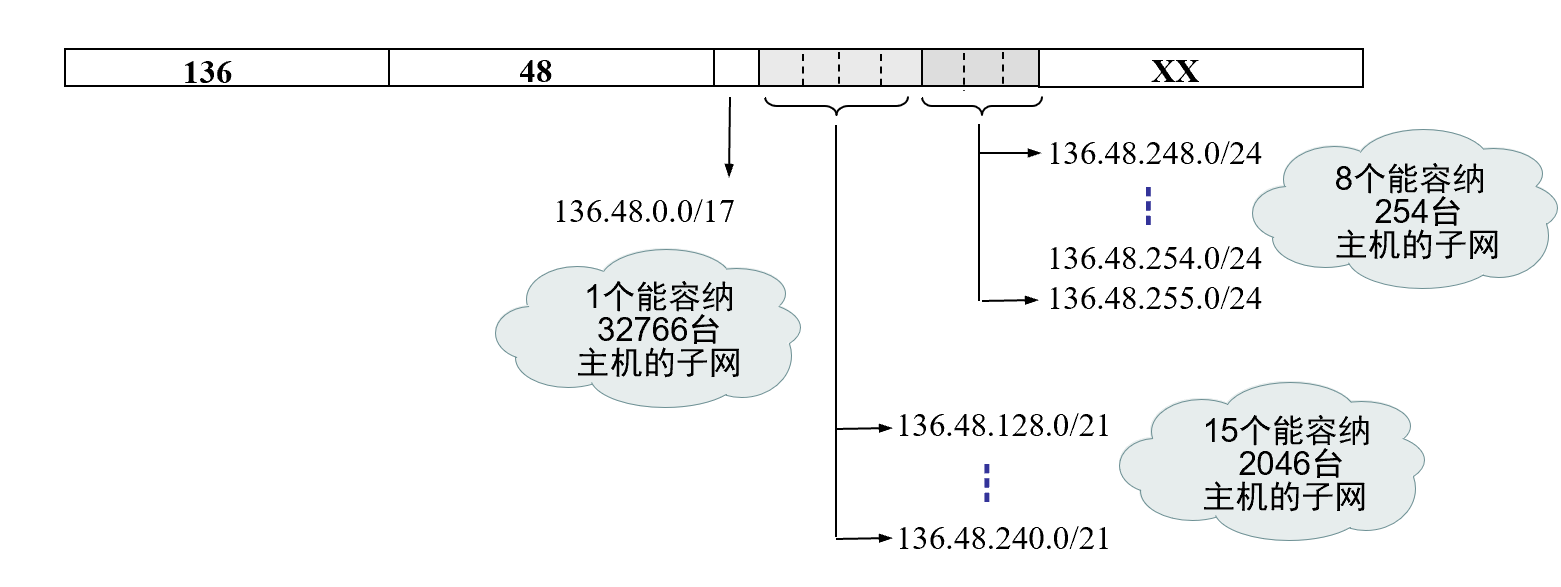
未分類のアドレス指定
サブネットという概念は、本来のIPアドレスの無理な設計による衝突を軽減し、また、可変長サブネットという概念は、IPアドレスを実際に利用する際のユーザーのニーズにも応えます。しかし、これらの対策はインターネットの開発過程で遭遇する困難を根本的に軽減するものではありません。
1992 年、インターネットは解決が必要な 3 つの緊急の問題に直面しました。 ① 1992 年にはクラスBアドレスが半分以上割り当てられていました。②インターネット基幹ネットワーク上のルーティングテーブルの項目数が飛躍的に増加します。③ 2011 年2月、IANA はIPv4アドレスが枯渇したと発表しました。
VLSMに基づいて、 IETF は上記の問題を解決するクラスレス アドレッシング方式を開発しました。クラスレス アドレッシング方式の正式名称はCIDR (Classless Inter-Domain Routing)で、その新しい文書はRFC 4632です。
CIDRの主な設計思想
CIDR は、IPアドレスを分類してサブネットを分割するというこれまでの概念を取り消し、分類されたアドレスのネットワーク番号とサブネット番号をさまざまな長さの「ネットワーク プレフィックス(network- pfefix )」で置き換えます。
IPアドレス ∷ ={<ネットワークプレフィックス> , <ホスト番号>}
CIDR は、同じネットワーク プレフィックスを持つ連続した IP アドレス ブロックを「CIDRアドレス ブロック」に結合します。CIDRアドレスブロックは、その開始アドレスとブロック内のアドレスの数で表すことができます。たとえば、136.48.32.8/20 は、特定のCIDRアドレス ブロック内のアドレスを表します。
未分類のアドレス指定の表現
CDIR は、ネットワーク プレフィックス表記(またはスラッシュ表記)を使用します。つまり、IPアドレスの後にスラッシュ「/ 」と数字を追加します。この数字は、 IPアドレスを表す136.48.52.36などのネットワーク プレフィックスの桁数です。最初の20桁はネットワーク プレフィックスです。
CIDR は他のいくつかの表現も使用します。1 つは、ドット付き 10 進法の下位桁の連続する「 0」を省略することです ( 20.0.0.0/10など) 。これは20/10と表現できます。もう 1 つは、 00010100 00*のように、ネットワーク プレフィックスの後にアスタリスク「*」を追加する方法です。アスタリスクはネットワーク プレフィックスの前にあり、アスタリスクはIPアドレスのホスト番号を表します。
CIDR アドレス ブロックの例
- 136.48.32.8/20 は、この32ビットIPアドレスで、最初の20桁がネットワーク プレフィックス、最後の12桁がホスト番号であることを意味します。各アドレス ブロックには合計212 個のアドレスがあり、その開始アドレスは136.48.32.0です。
- アドレスブロックの開始アドレスを示す必要がない場合、このようなアドレスブロックを略して「/20アドレスブロック」と呼ぶこともある。
- 136.48.32.0/20 アドレス ブロックの最小アドレス: 136.48.32.0 、最大アドレス: 136.48.47.255 。
- すべて 0またはすべて1のホスト番号アドレスは通常は使用されません。
136.48.32.8/20アドレス ブロックには2 12アドレスが含まれます

ルート集約_
CIDRアドレス ブロックには多くのアドレスを含めることができ、ルーティング テーブル エントリもアドレス ブロックで表すことができます。この種のアドレス集約は、ルート集約と呼ばれます。ルート集約は、ルーティング テーブルを短縮するだけでなく、ルーティング テーブルを検索する時間を短縮し、それによってインターネットのパフォーマンスも向上します。ルート集約は、スーパーネット化とも呼ばれます。
CIDR はサブネットの概念を使用しませんが、依然として「マスク」という用語を使用します(単にサブネット マスクとは呼ばれません) 。たとえば、/20アドレス ブロックの場合、そのマスクは20個の連続する1です。スラッシュ表記の数字は、マスク内の1の数です。
スーパーネットを構築する
「含まれるアドレス数」には、オール0、オール1のアドレスが含まれる。表内のK は2 10 (つまり1024)を表します。ネットワーク プレフィックスが13未満または27を超えるアドレスは、あまり使用されません。CIDRアドレス ブロック内のアドレスの数は、2の整数乗である必要があります。
- プレフィックス長が 23ビット以下のCIDRアドレス ブロックには、複数のクラスCアドレスに相当するアドレスが含まれます。これらのクラスCアドレスは一緒になってスーパーネットを形成します。
- ネットワーク プレフィックスが短いほど、そのアドレス ブロックに含まれるアドレスの数が多くなります。3 レベルの IPアドレス構造では、サブネットの分割によりネットワーク プレフィックスが長くなります。
- CIDR を使用してスーパーネットを構築するには、関連するルーターとそのプロトコルがサポートされている必要があります。
CIDRアドレス ブロックを使用する最大の利点
- IPv4アドレス空間をより効率的に割り当てることができます。たとえば、組織には900 個のIPアドレスが必要です。CIDRが使用されない場合、ISP はユニットに 1 つのクラスBアドレスまたは4 つのクラスCアドレスを割り当てることができます。ただし、 CIDRを使用すると、ISP はユニットにアドレス ブロック208.18.128.0/22を割り当てることができます。これには、 4 つの連続する/24アドレスブロックに相当する1024 個のIPアドレスが含まれます。
- ネットワークの地理的位置に従ってアドレス ブロックを割り当てることができるため、ルーティング テーブルが占有するスペース、つまりルーティング テーブルのエントリ数を大幅に削減できます。
住所解釈と住所変換
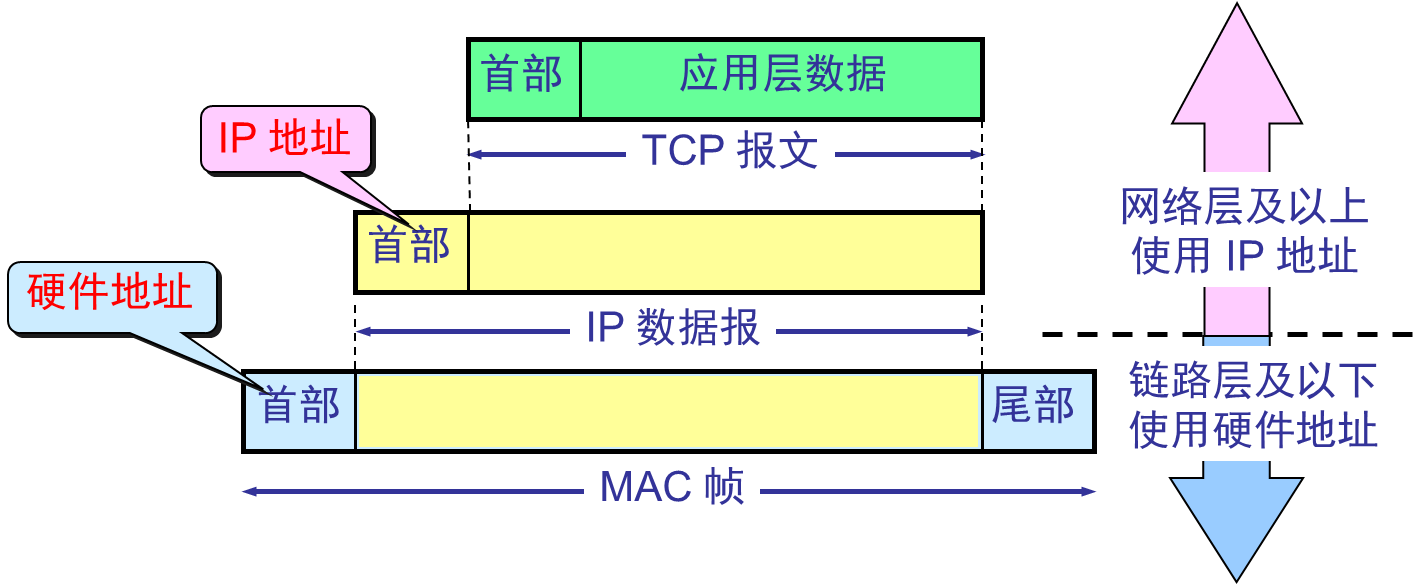
IPアドレスとハードウェアアドレスの違い
例: 2 つのルーターを使用して 3 つの LAN を相互接続する
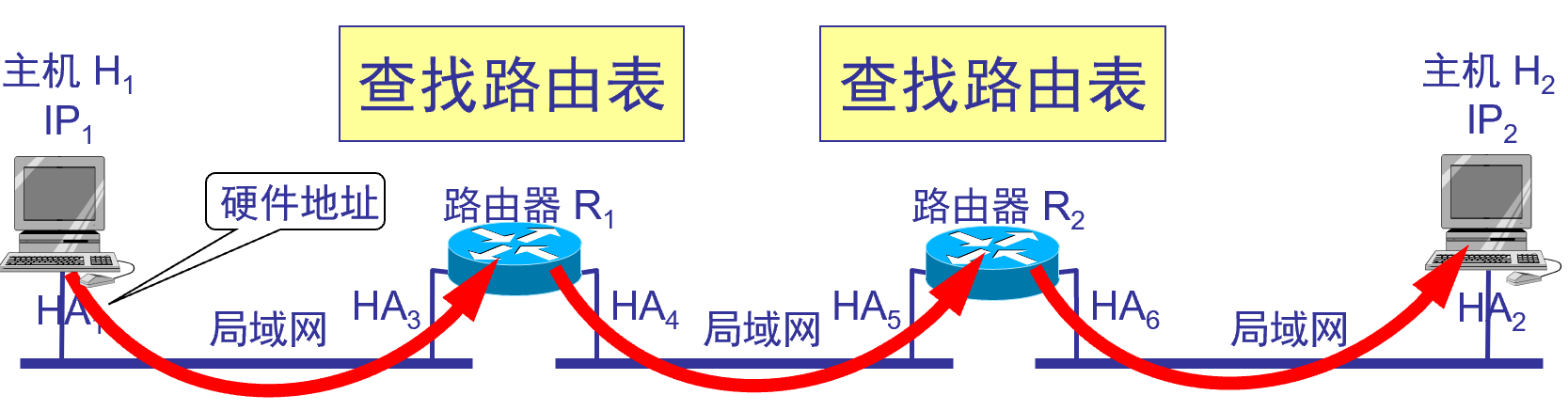
通信パスは次のとおりです。 H 1 → R 1によって転送 → R 2によって転送→ H 2
データの流れをプロトコルスタックレベルから見る
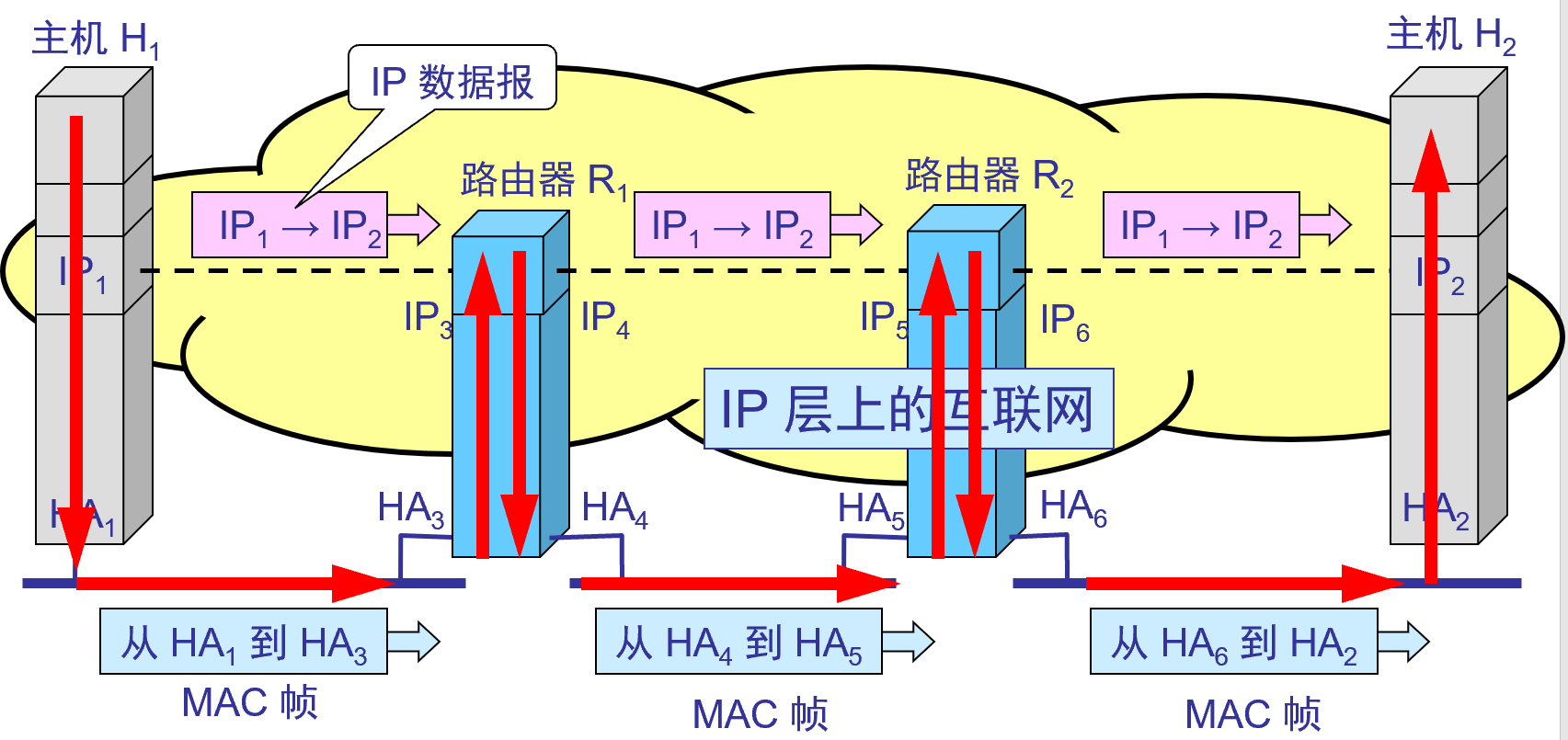
仮想 IP 層からの IPデータグラムの流れを見る
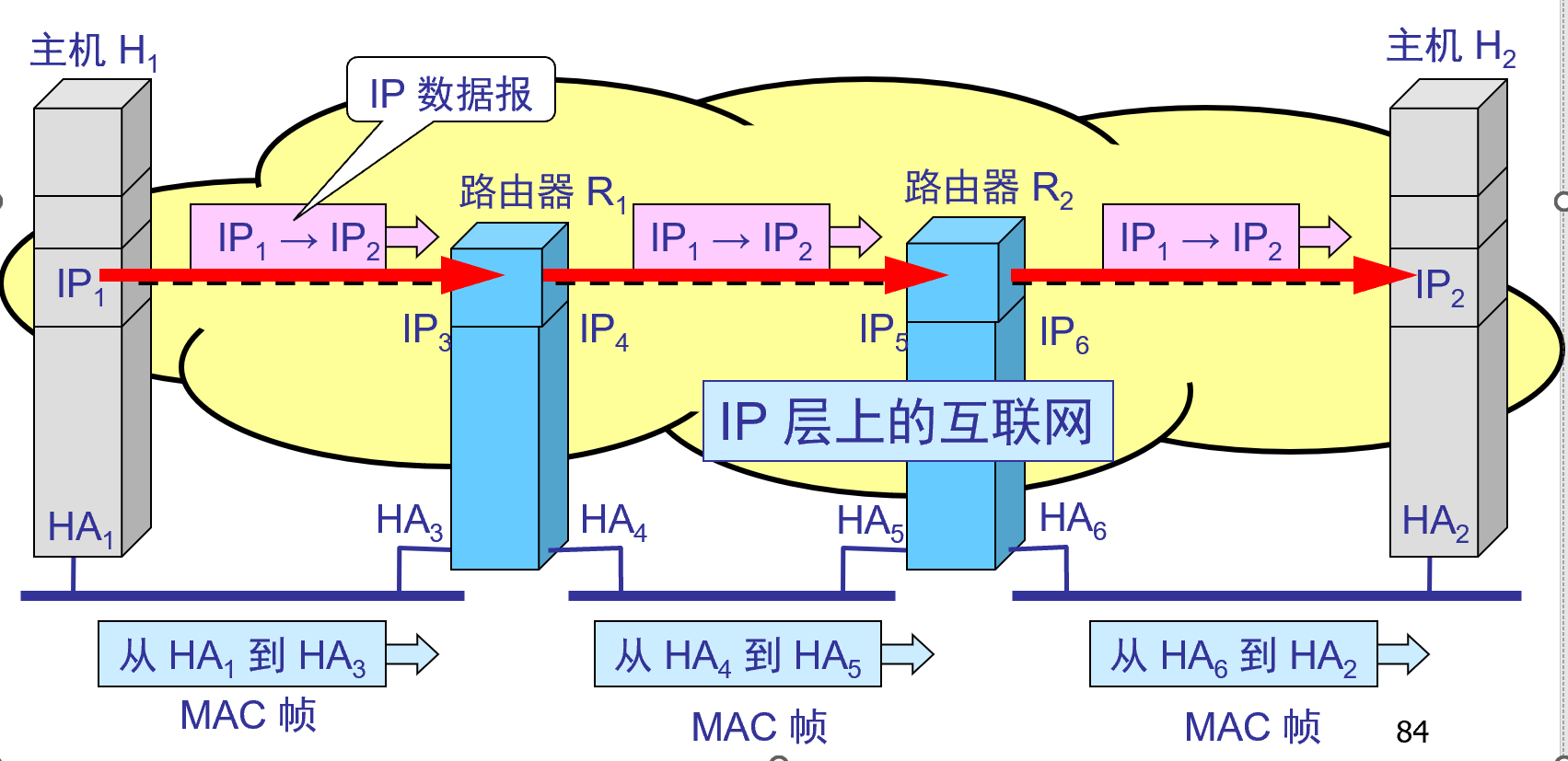 リンク上の MACフレームの流れを監視する
リンク上の MACフレームの流れを監視する

IP層が抽象化されているインターネット上では、 IPデータグラムのみが表示されます。図中のIP 1 → IP 2は、送信元アドレスIP 1から宛先アドレスIP 2までを意味します。2 つのルータの IP アドレスは、IPデータグラムのヘッダーには現れません。
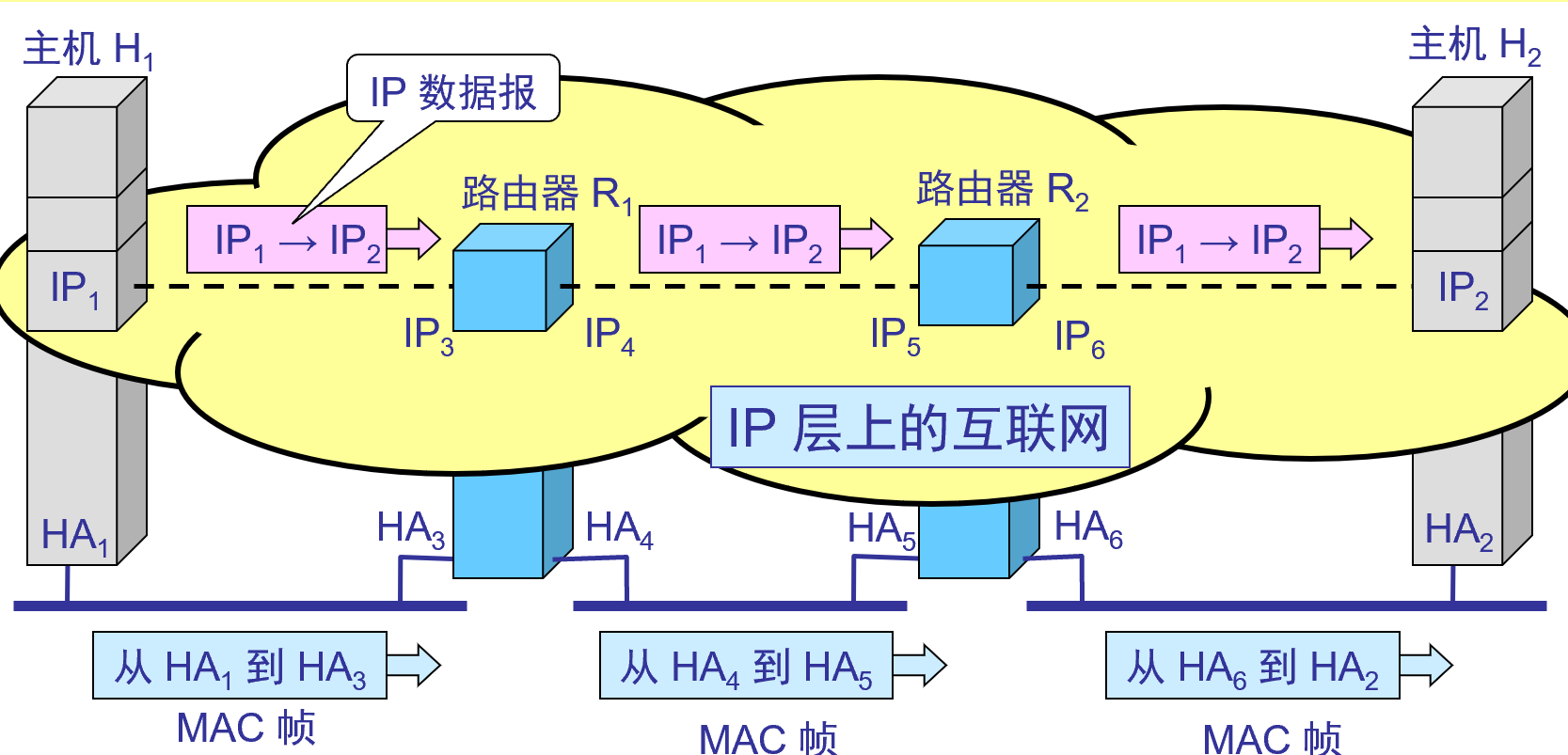
- IPデータグラムのヘッダには送信元局のIPアドレスが存在しますが、ルータは宛先局のIPアドレスのネットワーク番号に基づいて経路選択を行うだけです。
- 特定の物理ネットワークのリンク層では、MACフレームのみが表示され、IPデータグラム( MACフレームにカプセル化されている)は表示されません。MACフレームの送信中、ヘッダーに埋められるハードウェア アドレスHA xは異なります。
- 相互接続されたネットワークのハードウェア アドレス システムはさまざまですが、IPレベルでのインターネットの抽象化により、下位層の非常に複雑な詳細が保護されます。この問題を抽象ネットワーク レベルで議論することで、統一された抽象IPアドレスを使用したホスト間通信、またはホストとルーター間の通信を研究できるようになります。
アドレス解決プロトコル ARP
ネットワーク層でどのようなプロトコルが使用されても、実際のネットワークのリンク上でデータ フレームを送信する際には、最終的にはハードウェア アドレスが使用されます。
IP アドレス(32ビット)とハードウェア アドレス(48ビット)の間には単純なマッピングはありません。ARPプロトコルはIPアドレスと物理アドレスの間のマッピングを解決し、RARPプロトコルは物理アドレスとIPアドレスの間のマッピングを解決します。
各ホストには ARPキャッシュ(キャッシュ)が装備されており、ローカル エリア ネットワーク上の各ホストおよびルーターのIPアドレスからハードウェア アドレスへのマッピング テーブルが格納されます。
ホスト A がローカル エリア ネットワーク上のホストBにIPデータグラムを送信したい場合、ホスト A はまずARPキャッシュにホストBのIPアドレスがあるかどうかを確認します。存在する場合、対応するハードウェア アドレスが取得され、そのハードウェア アドレスがMACフレームに書き込まれ、MACフレームが LAN を介してそのハードウェア アドレスに送信されます。それ以外の場合、ホストはARPプロトコルを実行します。
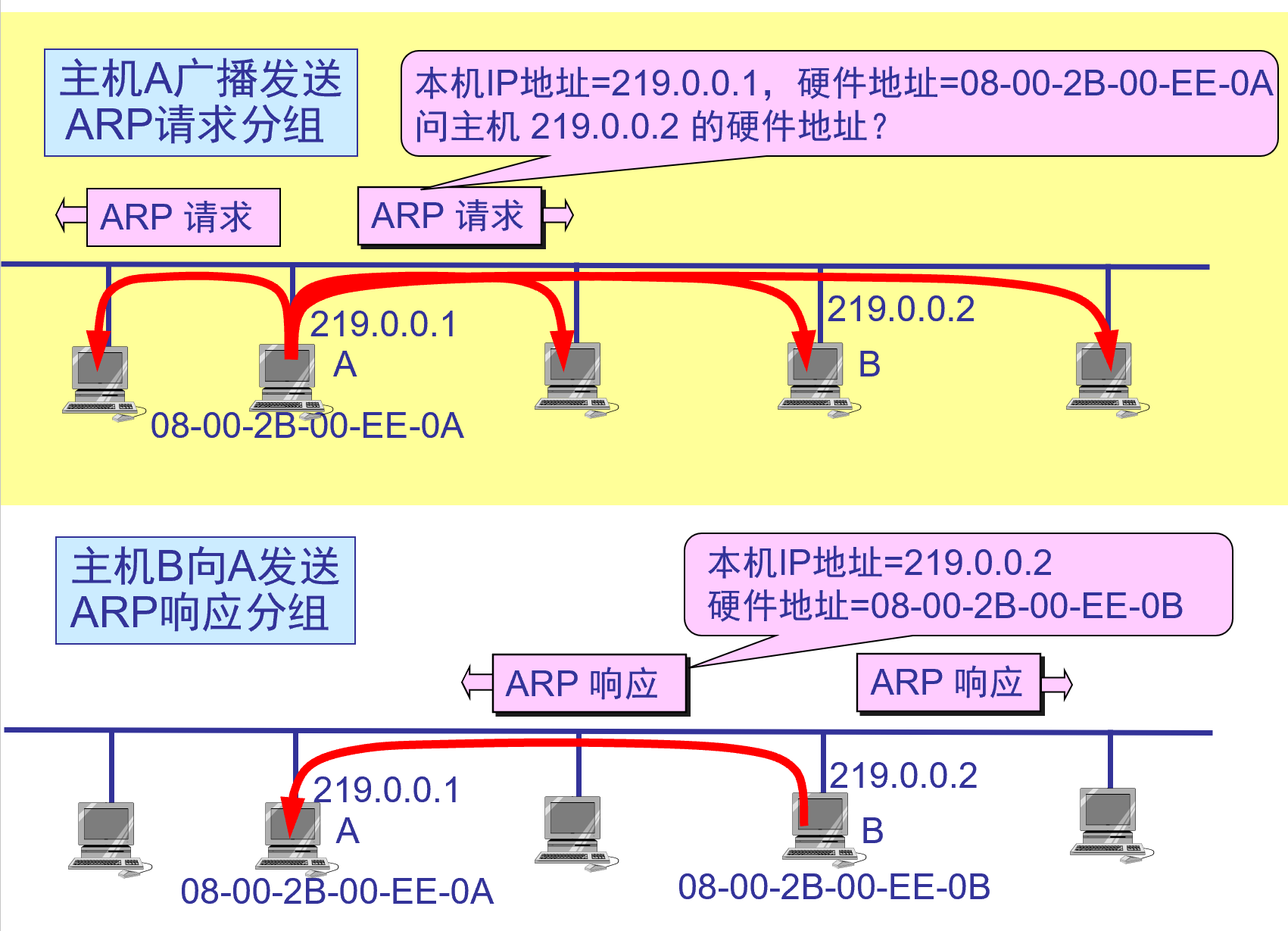
ARPキャッシュ
- キャッシュの目的は、ネットワーク上のトラフィック量を削減することです。キャッシュが使用されない場合、ネットワーク上のホストは通信するためにブロードキャスト モードで ARP 要求パケットを送信する必要があり、ネットワーク上のトラフィックが大幅に増加します。キャッシュを使用すると、取得したアドレス マッピングを後で使用できるように保存できます。
- ARP は、キャッシュに保存されている「 IPアドレス-ハードウェア アドレス」マッピング テーブルの生存時間( 10 分など)を設定します。生存時間を超えたエントリは削除されます。削除されたテーブル エントリは原則なく再確立され、前述のように宛先ホストのハードウェア アドレスを見つけるプロセスも通過する必要があります。
ARP は、同じ LAN上のホスト(またはルーター)のIPアドレスとハードウェア アドレス間のマッピングの問題を解決します。ホストまたはルーターがネットワーク上の既知のIPアドレスを持つ別のホストまたはルーターと通信している限り、 ARPプロトコルはIPアドレスをリンク層で必要なハードウェア アドレスに自動的に解決します。
探している宛先ホストと送信元ホストが同じ LAN 上にない場合は、ARPを介してローカル エリア ネットワーク上のルーターのハードウェア アドレスを見つけて、そのルーターにパケットを送信して、ルーターはパケットを次のサーバー、つまりネットワークに転送します。残りは次のネットワークが行います。
IPアドレスからハードウェア アドレスへの解決は自動的に実行され、このアドレス解決プロセスはユーザーに対して透過的です。
ARP を使用する場合の4 つの典型的な状況
- 送信者は、このネットワーク上の別のホストに IP データグラムを送信したいホストです。このとき、宛先ホストのハードウェア アドレスを見つけるためにARPが使用されます。
- 送信者は、別のネットワーク上のホストに IP データグラムを送信したいホストです。このとき、ARPを使用して、このネットワーク上のルーターのハードウェア アドレスを見つけます。残りの部分はルーターが行います。
- 送信者はルーターで、このネットワーク上のホストに IP データグラムを転送したいと考えています。このとき、宛先ホストのハードウェア アドレスを見つけるためにARPが使用されます。
- 送信者は、IP データグラムを別のネットワーク上のホストに転送するルーターです。このとき、ARPを使用してネットワーク上の別のルーターのハードウェア アドレスを見つけます。残りの部分はルーターが行います。
通信にハードウェア アドレスを使用しないのはなぜでしょうか?
- 世界中にはさまざまなネットワークがあるため、使用するハードウェア アドレスも異なります。これらの異種ネットワークが相互に通信できるようにするには、非常に複雑なハードウェア アドレス変換を実行する必要がありますが、これはほとんど不可能です。
- IP アドレス指定は、この複雑な問題を解決します。インターネットに接続されているすべてのホストは統一されたIPアドレスを持ち、ルータまたはホストのハードウェア アドレスを見つけるためのARPの呼び出しはコンピュータ ソフトウェアによって自動的に実行されるため、ホスト間の通信は同じネットワークに接続されているかのように簡単かつ便利です。 . 、この呼び出しプロセスはユーザーには見えません。
仮想プライベート ネットワークVPN
IPアドレスが不足しているため、組織が申請できるIPアドレスの数は、組織が所有するホストの数よりもはるかに少ないことがよくあります。
インターネットのセキュリティがあまり良くないことを考慮すると、組織内のすべてのホストを外部のインターネットに接続する必要はありません。
そこで、組織内のコンピュータ通信にもTCP/IPプロトコルが使用されていると仮定すると、原則として組織内でのみ使用されるコンピュータには、組織が独自のIPアドレスを割り当てることができるという考えがあります。
2種類のアドレス
- ローカル アドレス-組織内でのみ使用されるIPアドレス。インターネット管理機関に申請することなく、組織自体が割り当てることができます。
- グローバルアドレス-インターネット管理機関に適用する必要のある、世界で唯一のIPアドレス。
問題: 内部で使用されるローカル アドレスがインターネット上のIPアドレスと重複する可能性があり、その結果、アドレスが曖昧になります。
解決策: RFC1918 では、いくつかのプライベート アドレスが指定されています。プライベート アドレスはローカル アドレスとしてのみ使用でき、グローバル アドレスとしては使用できません。インターネット内のすべてのルーターは、宛先アドレスがプライベート アドレスであるデータグラムを転送しません。3 つのプライベート アドレス ブロック、つまりICANNによって予約された部分A 、B 、およびCクラス プライベート アドレスブロック。
- クラス A: 10.0.0.0 ~ 10.255.255.255 ;
- クラス B: 172.16.0.0 ~ 172.31.255.255 ;
- クラスC :192.168.0.0 ~192.168.255.255
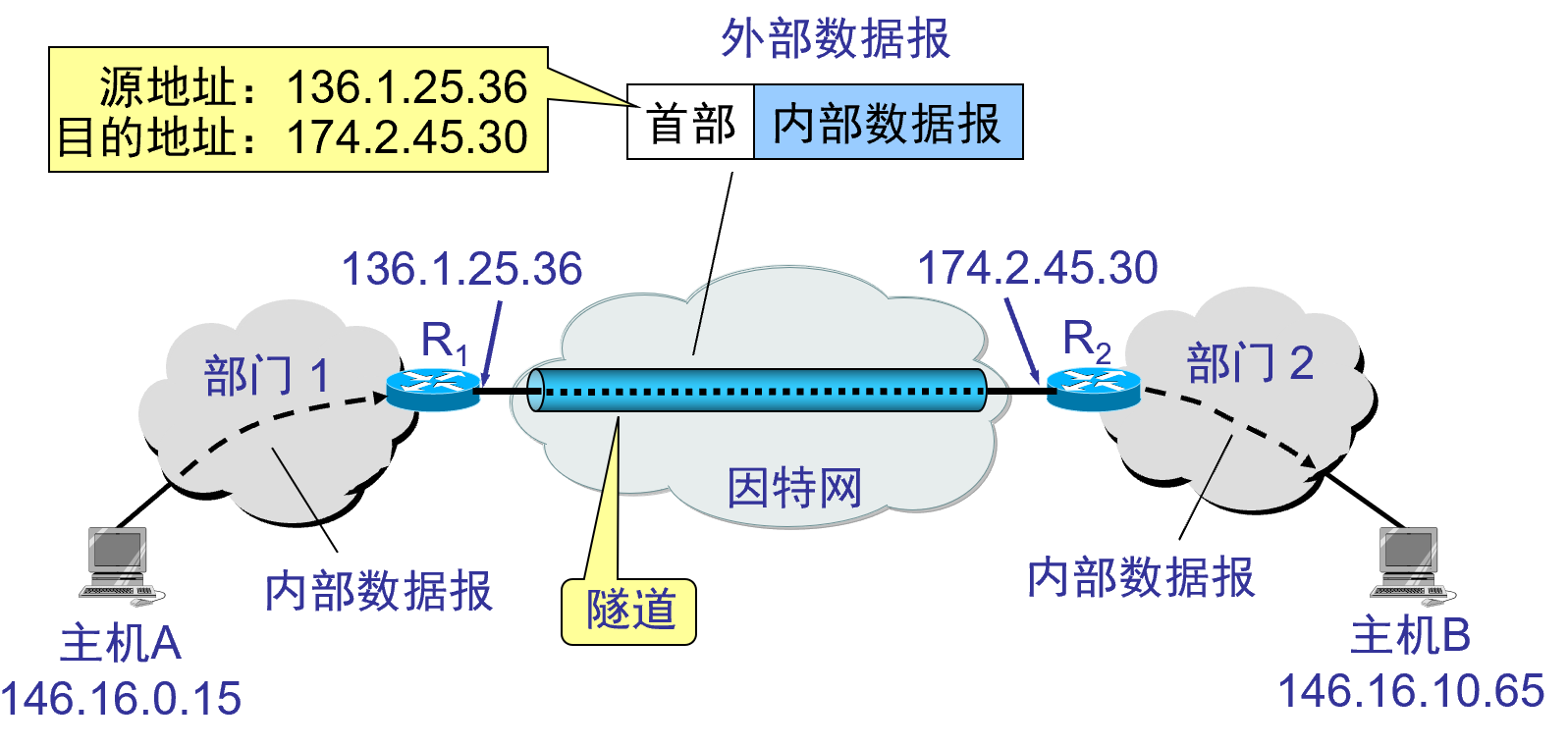
このような専用の IP アドレスを使用したプライベート ネットワークを、擬似プライベート ネットワークVPNと呼びます。仮想プライベート ネットワーク VPN は、基本ネットワーク上に構築された機能ネットワークです。一般的なプライベートネットワークの機能を利用者に提供しますが、それ自体が独立した物理ネットワークではなく、公衆網サービスプロバイダー(インターネット、ATM、FRなど)が提供するネットワークプラットフォーム上に構築されます。トンネル技術による論理ネットワーク。
仮想プライベート ネットワークには2 つの意味があります。1つは「仮想」です。これは、 VPNネットワーク全体上の 2 つのノード間の接続には、従来のプライベート ネットワークに必要なエンドツーエンドの物理リンクがなく、分散ネットワーク上で確立されるためです。幅広いパブリック ネットワークのプラットフォーム上で、2 つ目は「プライベート ネットワーク」です。各VPNユーザーは、一時的な「プライベート ネットワーク」から必要なリソースを取得できます。
仮想プライベートネットワーク構築時の注意点
- 異なる出口のプライベート ネットワーク間で通信が実行され、パブリック インターネットを通過する必要があり、機密性要件がある場合は、インターネットを通過するすべてのデータを暗号化する必要があります。
- 独自の VPN を構築するには、組織は拠点ごとに専用のハードウェアとソフトウェアを購入し、各拠点のVPNシステムが他の拠点のアドレスを認識できるように構成する必要があります。
バーチャルプライベートネットワークの特徴
- 費用も安く、支払う必要があるのは毎日のインターネット料金だけです。
- 最も一般的に使用されるネットワーク プロトコルに対する広範なサポートが得られます。
- 本人確認やデータ暗号化などの安心・安全な機能を備えています。
- 拡張と管理が簡単です。
仮想プライベート ネットワークの欠点
- 安全性。インターネットは信頼できる安全なネットワークではないため、データ送信のセキュリティを確保するには、ネットワーク上で送信されるデータを暗号化する必要があります。
- 管理性。VPN管理は、追加の旅費を避けるために、電気通信組織のニーズの急速な変化に対応できなければなりません。
- パフォーマンス。ISP はIPパケットを「ベストエフォート」ベースで配信しており、インターネット全体の送信パフォーマンスは保証されず、時々変化するため、追加のセキュリティ対策もパフォーマンスを大幅に低下させます。
トンネル技術を活用して仮想プライベートネットワークを実現
トンネルを確立するには 2 つの方法があります: 1 つは任意のトンネルであり、サーバー コンピュータまたはルーターがVPN要求を送信することで構成および作成できるトンネルを指します。もう 1 つは必須トンネルで、VPNサービス プロバイダーによって構成および作成されます。
トンネルには 2 つのタイプがあります。 ① 点-点トンネル。トンネルはリモート ユーザー コンピュータから企業サーバーまで延長され、両側のデバイスがトンネルを確立し、2 点間のデータの暗号化と復号化を行います。②エンドツーエンドのトンネル。トンネルはファイアウォールなどのネットワーク エッジ デバイスで終端し、その主な機能は両端の LAN を接続することです。
IPデータグラム形式
IP データグラムはヘッダー部分とデータ部分で構成されます。
IPデータグラムのヘッダー
- ヘッダーの最初の部分は固定長 ( 20バイト)であり、すべてのIPデータグラムがこれを持たなければなりません。
- ヘッダーの固定部分の後には、オプションとパディング フィールド (可変長)が続きます。
- データ部分の長さも可変です
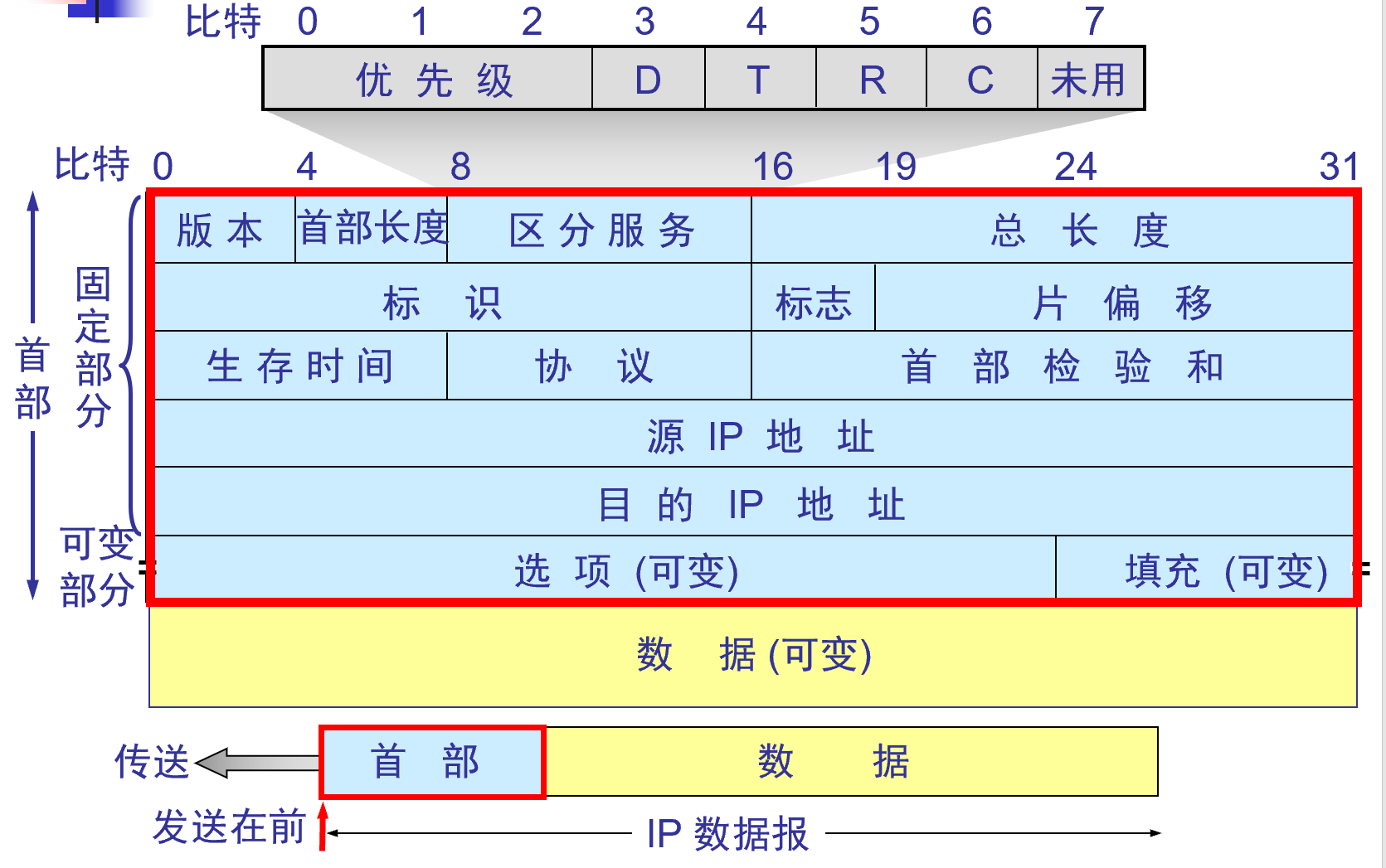
バージョン- 4桁の数字で、IPプロトコルのバージョンを示します。現在広く使用されているプロトコルのバージョン番号は4 (つまり、IPv4)です。通信する両方の当事者のプロトコル バージョンは一貫している必要があります。
ヘッダー長-データグラム ヘッダーの長さを示す 4 ビット。ヘッダ長で表現できる最大値は15単位( 1単位は4バイト)であるため、IPヘッダ長の最大値は60バイトとなります。ヘッダーの長さが4バイトの整数倍未満の場合、パディング フィールドを使用してそれを埋めることができます。
Differentiated Services -データグラムのサービス要件を示す 8 ビット。最初の 3 桁は優先度(0 ~7、0が最低)を表し、D 、T 、R 、Cはそれぞれ遅延、スループット、信頼性、ルーティング サービス料金の選択要件を表します。最後のビットは未使用です。このフィールドは、差別化されたサービスを使用する場合にのみ使用されます。
全長- 16ビット。データグラム全体(ヘッダーとデータを含む)の長さをバイト単位で表します。データグラムの最大長は65535バイト(64KB)です。合計の長さがデータリンク層の最大伝送単位MTUを超えてはなりません。データグラム長がMTUを超える場合にはフラグメント化する必要があり、このときの合計長とはフラグメント化後の各フラグメント(ヘッダーとデータを含む)の長さを指します。
識別- 16ビット。最終的に元のデータグラムに再構築されるデータグラムの各フラグメントに使用されます。これはカウンタであり、データグラムが生成されるたびにカウンタは1ずつインクリメントされ、その値が識別フィールドに割り当てられます。宛先ホストは、同じ識別フィールド値を持つ断片化されたデータグラムを正しく再構築(結合)します。
フラグ- 3桁 。現在意味があるのは最後の 2 桁のみです。最下位ビットはMF (More Fragment)として記録されます。MF = 1 は、後で「まだフラグメントが存在する」ことを意味します。MF = 0は、それが最後のフラグメントであることを意味します。下から 2 番目のビットはDF (Do n't Fragment)で、データグラムの断片化を許可するかどうかを制御するために使用されます。シャーディングはDF = 0の場合にのみ許可されます。
スライス オフセット- 13ビット。長いパケットが断片化された後の、元のパケット内の特定のスライスの相対位置を指します。つまり、宛先ホストがデータグラムを再構築できるように、ユーザー データ フィールドの先頭から相対的にフラグメントが始まる位置です。スライス オフセットは8バイト オフセット単位です。これは、各フラグメントの長さが8バイト(64ビット)の整数倍でなければならないことを意味します。
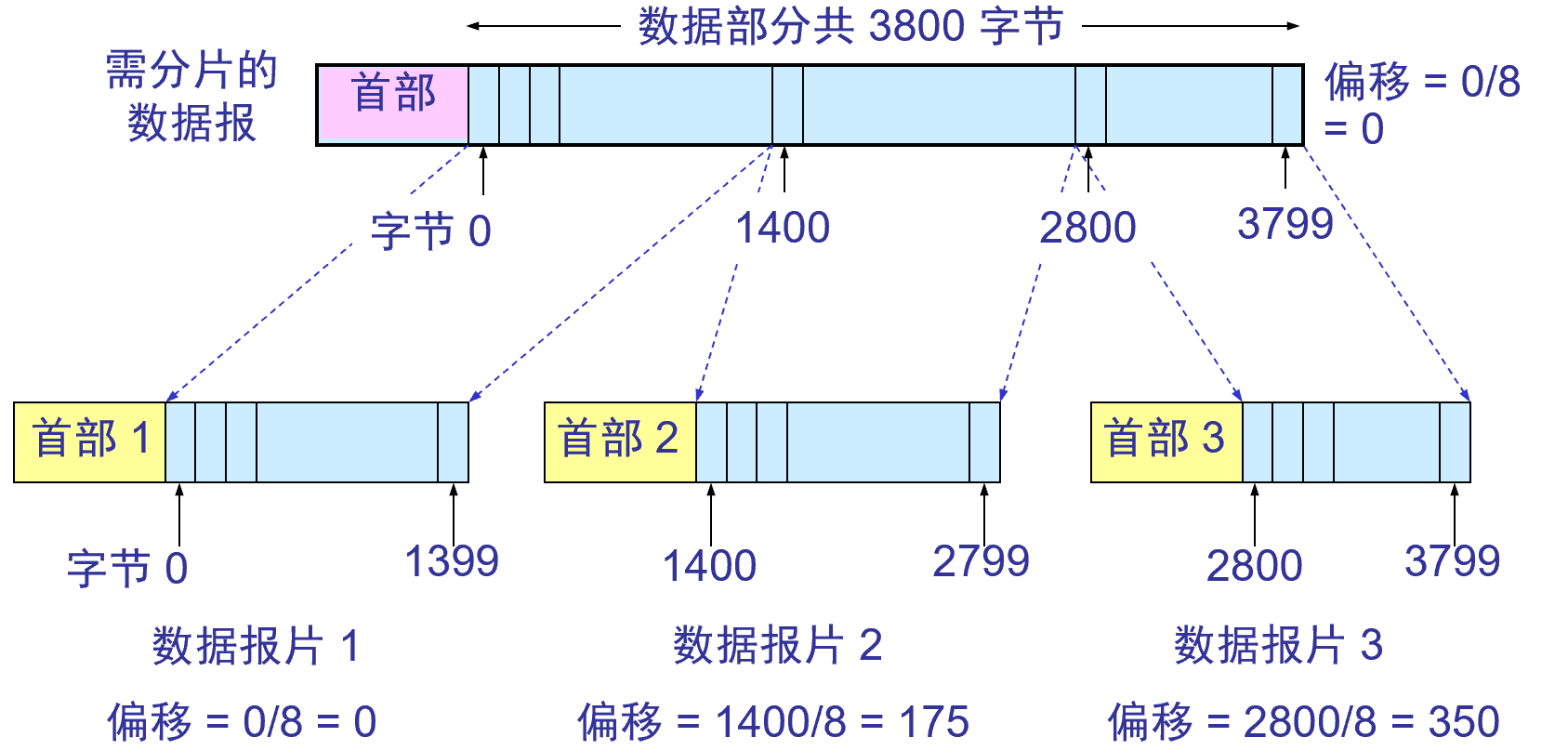
IPデータグラムの断片化の例:
- データグラムの全長は 3820バイト、データ部分の長さは3800バイト (固定ヘッダーを使用)であり、長さが1420バイト以下のデータグラム フラグメントに分割する必要があります。
- 固定ヘッダーの長さは 20バイトであるため、各データグラム フラグメントのデータ部分の長さは1400バイトを超えることはできません。
- したがって、3 つのデータグラム フラグメントに分割され、データ部分の長さはそれぞれ1400 バイト、1400 バイト、1000バイトになります。
- 元のデータグラム ヘッダーは各データグラム フラグメントのヘッダーにコピーされますが、関連するフィールドの値は変更する必要があります。
| 全長 |
ロゴ |
MF |
DF |
スライスオフセット |
|
| 生のデータグラム |
3820 |
12345 |
0 |
0 |
0 |
| データグラムフラグメント1 |
1420 |
12345 |
1 |
0 |
0 |
| データグラムフラグメント2 |
1420 |
12345 |
1 |
0 |
175 |
| データグラムフラグメント3 |
1020 |
12345 |
0 |
0 |
350 |
Time to Live - TTL (Time To Live)として記録される8ビットで、ネットワーク内のデータの寿命を示します。本来は秒単位でしたが、便宜上TTLの単位として「ホップ」が使用されるようになりました。データグラムがルーターを通過するたびに、そのTTL値は1ずつ減ります。TTL値が 0 に減ると、データグラムは破棄されます。