Article directory
-
- Lightweight
- Small target detection
- Related papers
- Views on combining lightweight and small goals
Lightweight
Why study lightweight neural networks?
With the rapid development of deep neural networks and smart mobile devices, lightweight design of network structures has gradually become a cutting-edge and popular research direction. The essence of lightweighting is to optimize storage space and increase operating speed while maintaining the accuracy of deep neural networks. At present, research on lightweight deep learning networks mainly focuses on manually designed lightweight networks and automatic lightweight networks based on neural network structure search.
Development status:
How to minimize model delay and storage space while maintaining the accuracy of the neural network model as much as possible is a hot issue in current research. The existing manually designed lightweight methods with better performance not only consume a lot of human resources, but also require rich deep learning experience to make all performance indicators meet the requirements. (The following paper is about using the existing lightweight model [efficientNet] as the backbone network + feature fusion technology to achieve good results in target detection, and the amount of parameters and calculations are very small). The lightweight method based on neural network structure search only focuses on improving the accuracy of the neural network model, but ignores the limitations of the underlying hardware equipment. The efficient model obtained in this way has high hardware requirements.
Mainly learn from the following three aspects:
- 1. Compress the trained model: knowledge distillation, weight quantification, pruning, attention transfer
- 2. Directly trained lightweight networks: MobileNet (1, 2, 3), shuffleNet (1, 2), squeezeNet, EfficientNet, Xception, NasNet
- 3. Accelerated convolution operations: im2col, low-rank decomposition, CUDA acceleration
1 Manually designed lightweight method
1.1 Group of convolutions
Group convolution performs group convolution on the input feature map by channel, and then connects the results of the group convolution by channel to obtain the final output feature, which has a lightweight effect. (In 2012, AlexNet innovatively used group convolution and trained one network on two hardware devices due to limitations of hardware devices). However, group convolution also has limitations, which will cause the information between feature maps to be unsmooth. The output feature map does not contain the information of all input feature maps. The subsequent channel rearrangement proposed by shuffleNet can solve this problem.

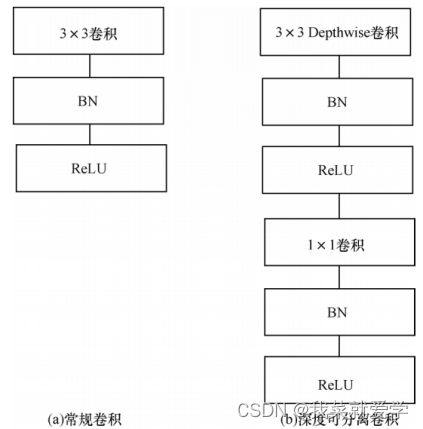
1.2 Depthwise separable convolution
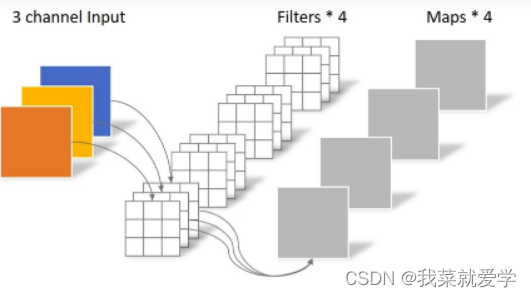
Depthwise convolution uses convolution kernels to convolve input features by channels, that is,
the convolution kernel of the first channel is convolved with the input features of the first channel. After Depthwise convolution obtains the spatial information of the feature, it performs Pointwise convolution on the obtained output feature, that is, using a 1×1 convolution kernel to convolve the output of Depthwise convolution to obtain the information between different channels in the feature. This combination achieves a lightweight effect.

1.3 MobileNet based on depthwise separable convolution
The basic idea of MobileNetv1 is to use depthwise separable convolution instead of conventional convolution, and use depthwise convolution to replace the filters in traditional convolution for feature extraction.
As an improved network of MobileNet, MobileNetv2 introduces the residual idea of ResNet network, and at the same time solves the defect of neuron deactivation caused by the extensive use of ReLU activation function in conventional ResNet. If you don't want ReLU to lose information due to "erasing 0", make all input values positive. But if the input values are all positive, it becomes a linear transformation of the identity mapping. The neural network can fit due to non-linear activation, so expand the redundant dimensions, "erase 0" to remove redundant information, and then use ReLU non-linear activation.
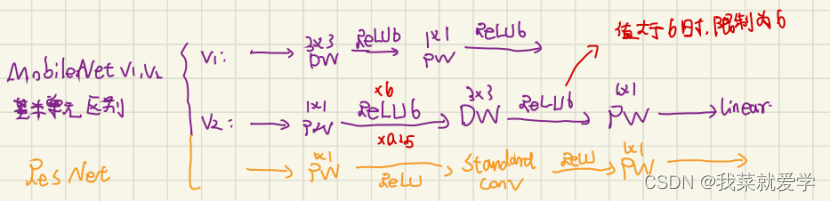
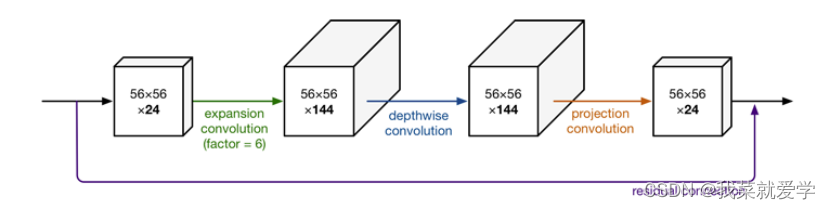
Shortcut of the bottleneck structure:
If the number of input channels is the same as the number of output channels or the step size is set to 1, the block with the residual will be taken.
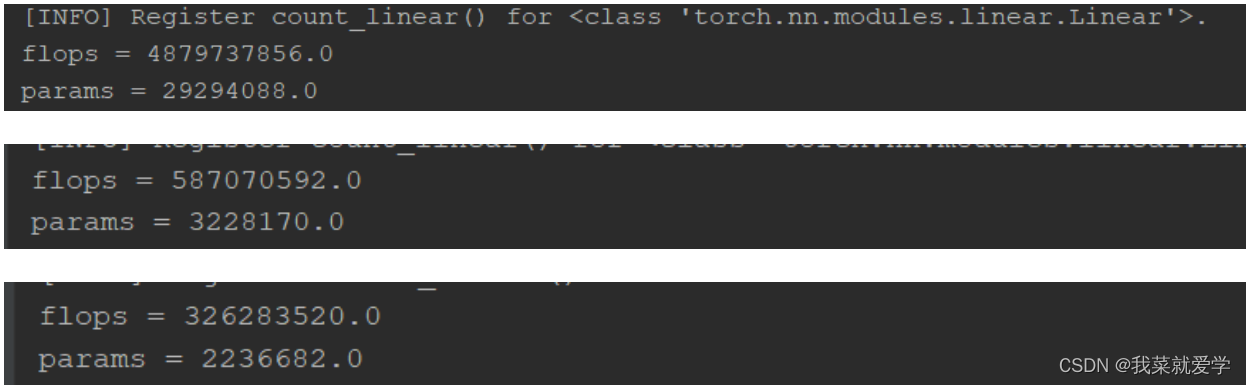
The following is a comparison of the parameters and calculation amount of ordinary convolution, MobileNetv1, and MobileNetv2 tested on the CIFAR10 data set:
MobileNetV3 is an architecture based on neural structure search, which is a model developed through alchemy. The network structure is based on MnasNet implemented by NAS, and also uses the inverted residual structure of depth-separable convolution and linear bottleneck. The activation function uses h-wish.
1.4 ShuffleNet
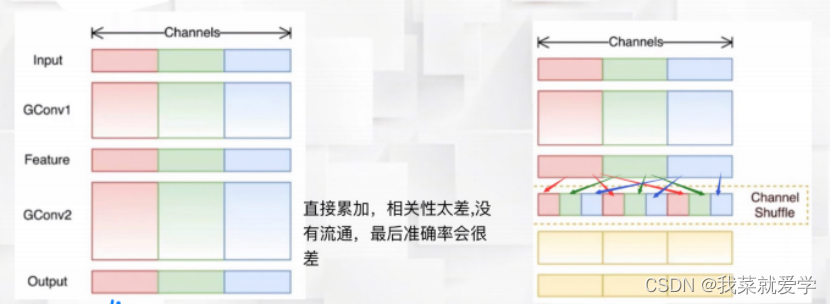
ShuffleNet is an extremely efficient network that can run on mobile devices such as mobile phones. The biggest limitation of conventional group convolution is that there is no information exchange between different groups during the training process, which will significantly reduce the feature extraction capability of the deep neural network. Therefore, a large number of 1×1 Pointwise (associated between channels) convolutions are used in MobileNet to make up for this defect, while ShuffleNet uses channel transformation to solve this problem. The core idea of channel transformation is to randomly and evenly scramble the feature map obtained after group convolution on the channel, and then perform the group convolution operation. This ensures that the input features for the next group convolution operation come from the previous group convolution. different groups in the product. (yolov7 mentioned before also used this idea)
Grouping principle: Assume that 12 data in one dimension are input, divided into 3 groups, each group has 4 values. For grouping rearrangement, first increase the dimension of this matrix, reconstruct 3 rows and 4 columns, and then transpose the matrix to obtain 4 rows and 3 columns, then install row expansion.
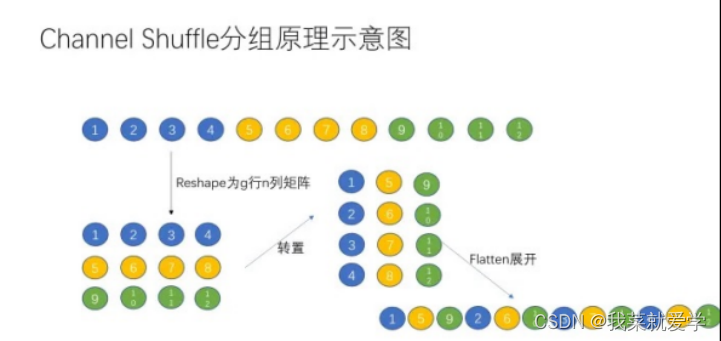
1.5 ShuffleNet V2
Before ShuffleNetV2 was proposed, the common indicator for measuring model complexity in lightweight networks was floating-point operations per second (FLOPS). FLOPS represents computing power, which is an indirect indicator for network performance evaluation, because computing power is not completely equivalent to running speed. Through experiments, it can be found that there is a difference in the running speed of two models with the same FLOPS. The reasons for this difference include GPU and memory usage (MAC).
-
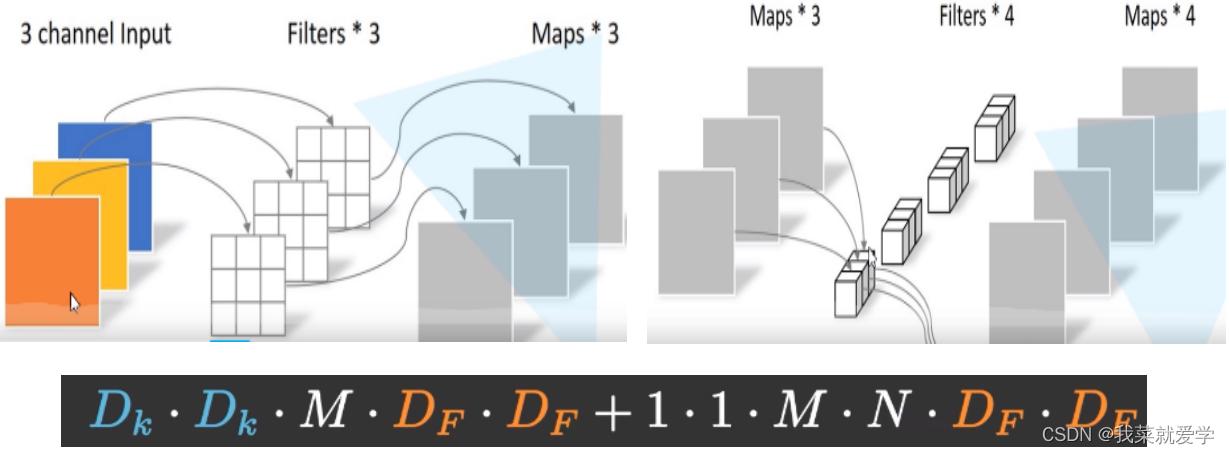
1) Try to use the same number of convolution kernels as the number of input feature channels to minimize memory usage. Taking the Pointwise convolution mentioned above in the depthwise separable convolution as an example, assuming that the input feature size is h×w×cin and the number of output channels is cout, then in the Pointwise convolution we can get:

Only when c1 = c2, MAC takes the minimum value, and this theoretical analysis is also confirmed by experiments.
-
2) Pay attention to element-level operations. Although activation functions (such as ReLU) and feature map addition (add) have a small impact on floating point computing power, they will have a large impact on memory usage.
-
3) Excessive use of group convolution will also increase MAC, pay attention to the number of groups.
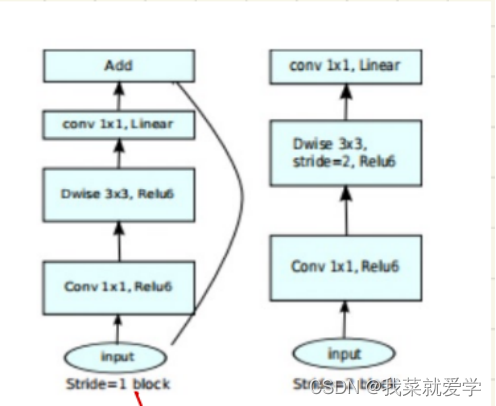
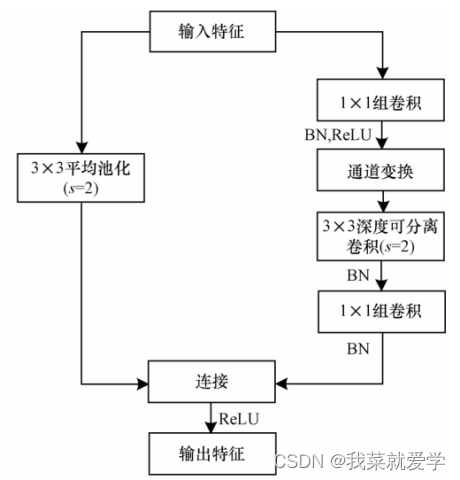
In the ShuffleNetv1 module, a large number of 1x1 group convolutions are used, which will increase the MAC. In addition, v1 uses a bottleneck layer similar to ResNet, with different numbers of input and output channels (here proposed by MobileNetv2), which violates the input and output The principle of consistent channel number. The structure of ShuffleNet V2 is shown in the figure below. Channel separation essentially divides the input features into two parts by channel, one part has the number of channels c', and the other part has c - c'. The left branch is equivalent to the identity mapping and corresponds to the Shortcut in the residual network. The right branch contains three consecutive convolution operations and satisfies the principle that the input feature and output feature channels are the same.
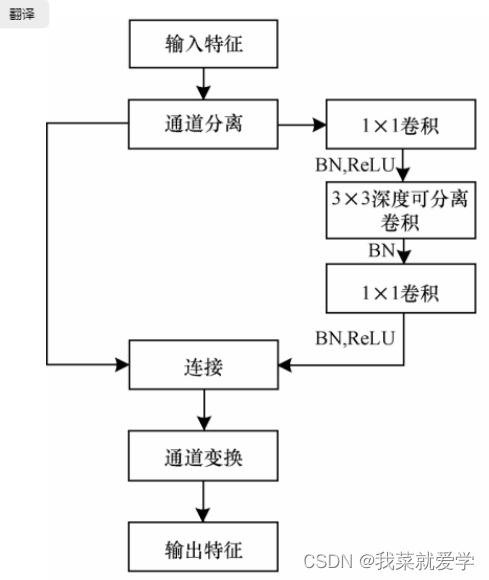
Improved baseline network based on Octave convolution
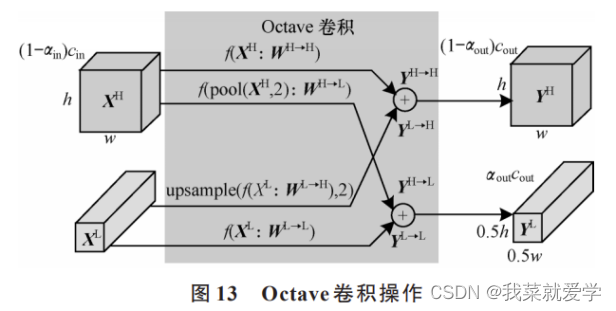
Different information in the picture is transmitted at different frequencies, which is mainly divided into high-frequency information and low-frequency information. Among them: high-frequency is usually used for detail encoding, and high-frequency information represents the detailed features in the picture; low-frequency is usually used for global encoding, and low-frequency The information represents global features in the image, i.e. features that change more slowly at lower spatial resolutions.
The feature map between convolutional layers can be viewed as a mixed feature map of high-frequency information and low-frequency information. In the traditional convolution method, both high-frequency information and low-frequency information are stored in the same way, which will cause storage redundancy and increase computational costs for the low-frequency information. Octave convolution is a new convolution method proposed to solve this problem. It factors the feature map according to different frequencies, stores and operates the information of different frequencies differently, and then exchanges information between the information of different frequencies. .
In the input feature map of Octave convolution, when αin =0 and αout = 0, Octave convolution is equivalent to conventional convolution. When αin = 0 and αout ≠ 0, it means that when the input feature map is a conventional convolution feature map, it is converted into an Octave feature map for ordinary convolution, which is usually applied to the first layer of Octave convolution. When αin ≠ 0 and αout ≠ 0, it means that the Octave convolution operation is performed when the input is the Octave feature map, which is usually applied to the middle layer of Octave convolution. When αin ≠ 0 and αout = 0, it means that Octave convolution is required to obtain the traditional feature map. Its function is to obtain the traditional feature map after convolution of the Octave feature map. It is usually applied to the last layer of Octave convolution.
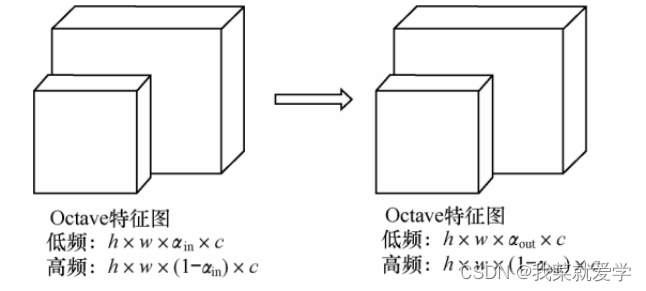
Octave convolution usually stores and processes low-frequency information and high-frequency information separately. If information exchange between different frequency information cannot be realized, network performance will be greatly affected. When obtaining high-frequency information, perform conventional convolution operations on the high-frequency information in the input feature map, and at the same time upsample the low-frequency information, and combine the two to obtain the high-frequency information after convolution. When obtaining low-frequency information, perform conventional convolution operations on the low-frequency information in the input feature map, and perform pooling on the high-frequency information at the same time. The two are combined to obtain the low-frequency information after convolution.
GhostNet based on Ghost features
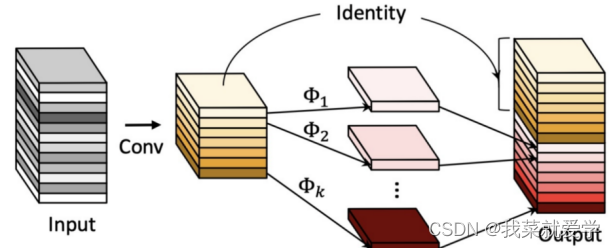
Research on lightweight methods of traditional deep neural networks mainly focuses on reducing the number of parameters and improving convolution methods. In 2020, HAN analyzed the feature maps of deep neural networks and found that the redundancy of feature maps in conventional convolution was rarely paid attention to in the neural network structure. In order to achieve lightweight network structure from the perspective of feature map redundancy, GhostNet was implemented. And born. As shown in the figure below, each pair of red, green and yellow is a similar feature map. If these similar feature maps can be implemented through cheap operation transformation, it is possible to achieve low computational complexity.

Here the author first uses 1 x 1 convolution for channel compression, and then depth-separable convolution generates similar feature maps and stacks them with the previous feature layers. This is similar to mobileNet, replacing traditional convolution with Ghost convolution block.
Lightweight method based on neural network structure search
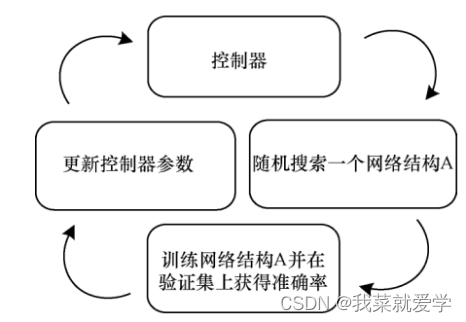
With the rapid development of reinforcement learning, lightweight methods based on neural network structure search have emerged.
The main purpose of neural network structure search is to use reinforcement learning methods to search for the most suitable hyperparameters in basic units in the search space, and then stack the searched basic units to obtain a lightweight network for neural network structure search.
Lightweight method based on automatic model compression
Model compression is mainly divided into two parts: fine-grained pruning and coarse-grained pruning. Fine-grained pruning modifies the redundant parts of the weights, while coarse-grained pruning compresses the entire area such as channels, rows, and blocks according to a certain sparsity rate.
- 1) Pruning
The essence of pruning is to prune unnecessary redundant weights and branches in the neural network, and only retain the weight parameters that are effective for the target task of the neural network. - 2) Weight sharing
Weight sharing uses the same set of parameters to avoid training and model redundancy caused by too many parameters. - 3) Weight quantization
Weight quantization aims to use smaller bit values to represent weights, which is probably to replace float32 with float8, in order to reduce the amount of storage. - 4) Huffman coding
Huffman coding is to use the two nodes with the lowest weight as the left and right subtrees to form a new node, and then select the two nodes with the lowest weight as the left and right subtrees to form a new node, and so on. Achieve the purpose of maximizing storage space saving based on frequency of use.
4 related papers
"Mobile-Former: Bridging MobileNet and Transformer (Connecting MobileNet and Transformer)" CVPR-2022: "Mobile Former: Bridging MobileNet and Transformer"
Mobile-Former is a parallel design of MobileNet and Transformer, with a two-way bridge in the middle. This structure takes advantage of MobileNet's Transformer in local processing and global interaction, and can simultaneously achieve two-way fusion of local and global features. Combined with the proposed lightweight cross-attention to model bridges, Mobile-Former is not only computationally efficient but also has stronger representation capabilities. It performs better than MobileNetV3 in low FLOP state.
Small target detection
Small Object Detection
refers to the detection of smaller target objects in images, which usually refers to objects whose size is less than 1/10 of the image size or smaller. COCO is an example, a target with an area of less than or equal to 1024 pixels.
Learning direction:
- 1) Method based on feature pyramid: This method captures feature information at different scales by building a feature pyramid, and then fuses feature information at different scales to improve the accuracy of target detection. Common methods based on feature pyramid include FPN (Feature Pyramid Network), SSD (Single Shot Detector), etc.
- 2) Method based on attention mechanism: This method improves the detection performance of small targets by introducing an attention mechanism, such as SENet (Squeeze-and-Excitation Network), CBAM, SKNet, etc.
- 3) Method based on joint training: This method improves the detection performance of small targets through joint training, such as CornerNet, CenterNet, etc.
- 4) Method based on weakly supervised learning: This method reduces the need for annotated data by utilizing weakly supervised learning technology, such as WOD (Weakly Supervised Object Detection), etc.
- 5) Method based on enhanced data: This method improves the detection performance of small targets by increasing the diversity and difficulty of data, such as using data enhancement techniques (random cropping, color dithering), adding negative samples, etc.
Related papers
"RepPoints V2: Verification Meets Regression for Object Detection"
(CVPR 2021) "RepPoints V2: Verification Meets Regression for Object Detection"
This paper proposes an object detection method based on a combination of verification and regression, which is better able to detect small objects. This algorithm improves detection accuracy by introducing repeated points to represent objects while combining verification and regression. Traditional object detection methods usually use predefined anchor boxes to detect and locate objects. However, since the shapes and sizes of different targets vary greatly, it is often difficult to accurately detect and locate targets using a single anchor box. To solve this problem, this paper proposes a new object detection method named RepPoints V2. RepPoints V2 uses two key components to improve detection accuracy: the verification module and the regression module. The verification module can verify candidate targets, thereby reducing the false detection rate. The regression module can accurately locate candidate targets, thereby improving detection accuracy. Compared with traditional anchor box methods, RepPoints V2 is better able to adapt to targets of different sizes and shapes, thereby improving detection accuracy.
"Beyond NMS: Fast and Accurate Object Detection with Hard Positive
Generation" (CVPR 2021) "Beyond NMS: Fast and Accurate Object Detection with Hard Positive Generation"
This paper proposes a new target detection framework that can detect small targets faster and more accurately. This method reduces the number of false positive samples by introducing hard positive sample generation technology, thereby improving detection accuracy and speed. In traditional target detection methods, non-maximum suppression (NMS) is usually used to remove redundant detection results, thereby improving detection accuracy and efficiency. However, NMS methods sometimes excessively remove positive samples, resulting in reduced detection accuracy. In order to solve this problem, this paper proposes a new target detection method called Hard Positive Generation. The Hard Positive Generation method improves the coverage of positive samples by generating positive samples in the candidate boxes. When generating positive samples, the Hard Positive Generation method uses a classifier-like technique, that is, to classify positive samples from negative samples, thereby reducing the false detection rate. Compared with the traditional NMS method, the Hard Positive Generation method can detect targets more accurately, thereby improving detection accuracy.
Views on combining lightweight and small goals
In small target detection, since the size of the target is relatively small, the model needs to be efficient and accurate. At the same time, due to resource constraints, lightweight models can be better adapted to resource-limited environments such as embedded devices and mobile devices. Currently, some lightweight models for small target detection have been proposed. These models usually adopt some effective optimization strategies, such as depthwise separable convolution, channel attention and other techniques, to achieve efficient detection performance. In addition, some methods based on knowledge distillation are also applied to lightweight models to improve their performance.
- 1. YOLOv7-tiny: lightweight mode of yolov7.
- 2. EfficientDet: A target detection algorithm based on the EfficientNet network structure, using lightweight modules such as BiFPN and Swish, and optimizing the network architecture and training methods to achieve efficient small target detection.
- 3. CenterNet: A target detection algorithm based on center points, which uses a lightweight Hourglass network structure and Dilated Convolution module to improve detection accuracy and computing efficiency.
- 4. BlazeFace: A face detection algorithm based on the MobileNetV2 network structure, which uses lightweight network design and feature fusion methods to achieve real-time face detection.
- 5. "HR-RCNN: High-Resolution and Lightweight Networks for Object Detection" (CVPR 2021): This paper proposes a high-resolution lightweight object detection framework HR-RCNN, which uses depth-separable convolution, Technologies such as cross-layer connections and feature pyramids are used to improve detection performance and computational efficiency.