文字列は、次のように一対の単一引用符で囲まれた有限長の文字シーケンスです。「文字列」
は C++ として理解できます ストリング文字列 string
基本操作


S t r As sign 、 S t r Compar e 、 S t r L e n g th 、 Con c a t 、 Sub S t r i n g StrAssign、StrCompare、StrLength、Concat、SubStringStrAssi gn、StrCom pare,StrLen gth、Conca t、SubStr g は基本操作集
固定長の順次ストレージ表現
#define MAXSTRLEN 255 // 用户可在255以内定义最大串长
typedef unsigned char Sstring[MAXSTRLEN + 1]; // 0号单元存放串的长度
char 配列を使用して文字列をシミュレートしますが、配列の長さが配列の先頭に配置される点が異なります。
文字列の実際の長さは、次の範囲内で任意に設定できます。この事前定義された長さ。事前定義された長さを超える場合、意味のある長さの文字列値が破棄されます。これは「切り捨て」と呼ばれます
基本操作
Status SubString(SString &Sub, SString S, int pos, int len) {
// 用Sub返回串S的第pos个字符起长度为len的子串。
//其中,1≤pos≤StrLength(S)且0≤len≤StrLength(S)-//pos+1 。
if ( pos<1 || pos>S[0] || len<0 || len>S[0]-pos+1 )
return ERROR;
Sub[1..len] = S[pos..pos+len-1];
Sub[0] = len; return OK;
}//SubString
S[0]-pos+1 に注意してください。这里需要+1
ヒープ割り当てストレージ表現
typedef struct {
char *ch; // 若是非空串,则按串长分配存储区,否则ch为NULL
int length; // 串长度
} HString;
通常、C言語で提供される文字列型はこの格納メソッドに実装されます。システムは、関数 malloc() および free() を使用して、文字列値スペースを動的に管理し、新しく生成された各文字列に記憶域を割り当てます。文字列値によって共有される記憶域は「ヒープ」と呼ばれます。 C 言語の文字列は null 文字で終了し、文字列の長さは暗黙の値になります。简而言之:通过malloc(),free()为串动态分配存储空间
基本操作
Status StrInsert(HString &S, int pos, HString T) {
// 1≤pos≤StrLength(S)+1。
//在串S的第pos个字符之前插入T
if (pos<1 || pos>S.length+1 ) return ERROR;
// pos不合法
if (T.length) {
//T非空,则重新分配空间,插入T
if (!(S.ch = (char *) realloc ( S.ch, ( S.length+T.length ) * sizeof ( char ))))
exit (OVERFLOW);
for ( i=S.length-1;i>=pos-1; --i)
//为插入T而腾出位置
S.ch[i+T.length] = S.ch[i];
S.ch[pos-1..pos+T.length-2] = T.ch[0..T.length-1]; //插入T
S.Length += T.length;
}
return OK;
} // StrInsert
このステップではS.ch[pos-1..pos+T.length-2]に注目してください。これらの詳細はあまり目立たないと思います
ここではi=S.length-1、なぜなら、 pos によって与えられる観点は、配列が 1 から始まり l e n g th length であるということです。lengt h の保存 [ 1 ] … … [ 長さ ] [1]……[長さ] [1]……[length],而实际上堆分配的串的存储应该是从0开始的 [ 0 ] … … [ l e n g t h − 1 ] [0]……[length-1] [0]……[leng たは−1]
r e a l o c ( ) realloc()realloc( )
- size の値が 0 の場合、free(ptr) を呼び出すことと同じになり、ptr が指すメモリ空間を解放します。
- 受信 ptr が NULL でなく、size が最初に割り当てられたメモリ サイズより大きい場合、以前に割り当てられたメモリ スペースを size バイトまで拡張しようとします。現在のメモリが size バイトに拡張するのに十分でない場合、新しいメモリ空間が再割り当てされ、元のメモリ空間のデータが新しいメモリ空間にコピーされ、最後に元のメモリ空間が解放され、新しいメモリ空間が返されます。 。 住所。
- 受信 ptr が NULL ではなく、サイズが最初に割り当てられたメモリ サイズ以下の場合は、元のメモリ領域を指定されたサイズまで削減してみます。元のメモリ空間が大きすぎる場合、超過分はメモリ管理システムに返されます。
Status SubString(HString& Sub, HString S, int pos, int len) {
// 用 Sub 返回串 S 的第 pos 个字符起长度为 len 的子串
if (pos < 1 || pos > S.length || len < 0 || len > S.length - pos + 1) return ERROR;
if (Sub.ch) free(Sub.ch); // 释放旧空间
if (!len) {
Sub.ch = NULL;
Sub.length = 0; // 空子串
} else {
Sub.ch = (char*)malloc(len * sizeof(char)); // 完整子串
for (int i = 0; i < len; i++) Sub.ch[i] = S.ch[pos + i - 1];
Sub.length = len;
}
return OK;
} // SubString
特別な状況に注意を払い、特別な判断を下すべきであることを依然として強調する必要がある。
文字列のブロックチェーンストレージ表現
リンク リストは文字列値を格納するために使用されます。文字列のデータ要素は文字であるため、リンク リストに格納すると、通常は 1 つまたは複数の文字をノードに格納できます。

#define CHUNKSIZE 80 // 可由用户定义的块大小
typedef struct Chunk {
char ch[CHUNKSIZE];
struct Chunk* next;
} Chunk;
typedef struct {
Chunk *head, *tail; // 串的头和尾指针
int curlen; // 串的当前长度
} LString;
実際のアプリケーションでは、問題のニーズに応じてノードのサイズを設定できます。
例: 編集システムでは、テキスト編集領域全体が文字列と見なされ、各行はノードを形成する部分文字列と見なされます。つまり、同じ行内の文字列は固定長構造 (80 文字) を使用し、行はポインターで接続されます。
文字列パターンマッチングアルゴリズム
単純なパターンマッチング
int Index(SString S, SString T, int pos) {
// 返回子串 T 在主串 S 中第 pos 个字符之后的位置。若不存在,
// 则函数值为 0。其中,T 非空,1 <= pos <= StrLength(S)。
i = pos;
j = 1;
while (i <= S[0] && j <= T[0]) {
// 0 下标存储字符串长度
if (S[i] == T[j]) {
++i;
++j; // 继续比较后继字符
} else {
i = i - j + 2;
j = 1; // 指针后退重新开始匹配
}
}
if (j > T[0]) return i - T[0];
else return 0;
} // Index
关于 i = i − j + 2 i = i - j + 2 私=私−j+2 の意味: マッチング中に不一致が発生した場合、ポインタを変更する必要があります i i i 和 j j j 同時に、1 つ前の位置に戻ってから一致させ、残りの部分を一致させます。現在のポインタ i はすでに前の j − 1 j - 1 j−1 文字なので、 i を j 分前に進める必要があります − 1 - 1 −1 位,再加上 2 2 2,即可保证 i i i はちょうど 1 位置戻り、 j j j 再次匹配。
このような場所の詳細は、細心の注意を払う価値があります。虽然暂时还不知道考试会不会扣这方面的细节,但是自己写代码的时候,也需要避免越界访问
時間計算量は次のとおりです: O(m*n)
KMPアルゴリズム
int Index_KMP(SString S, SString T, int pos) {
// 利用模式串 T 的 next 函数求 T 在主串 S 中第 pos 个字符之后的位置的 KMP 算法。
// 其中,T 非空,1 ≤ pos ≤ StrLength(S)
int next[MAXSIZE];
GetNext(T, next);
int i = pos;
int j = 1;
while (i <= S[0] && j <= T[0]) {
// 0 下标存储字符串长度
if (j == 0 || S[i] == T[j]) {
++i;
++j; // 继续比较后继字符
} else {
j = next[j]; // 模式串向右移动
}
}
if (j > T[0]) {
return i - T[0] + 1; // 匹配成功
} else {
return 0;
}
} // Index_KMP
このアルゴリズムは少し複雑です
説明
その中で、試験 次へ next数组要自己弄出来
void GetNext(SString T, int* next) {
int i = 1;
int j = 0;
next[1] = 0;
while (i < T[0]) {
if (j == 0 || T[i] == T[j]) {
++i;
++j;
next[i] = j;
} else {
j = next[j];
}
}
}
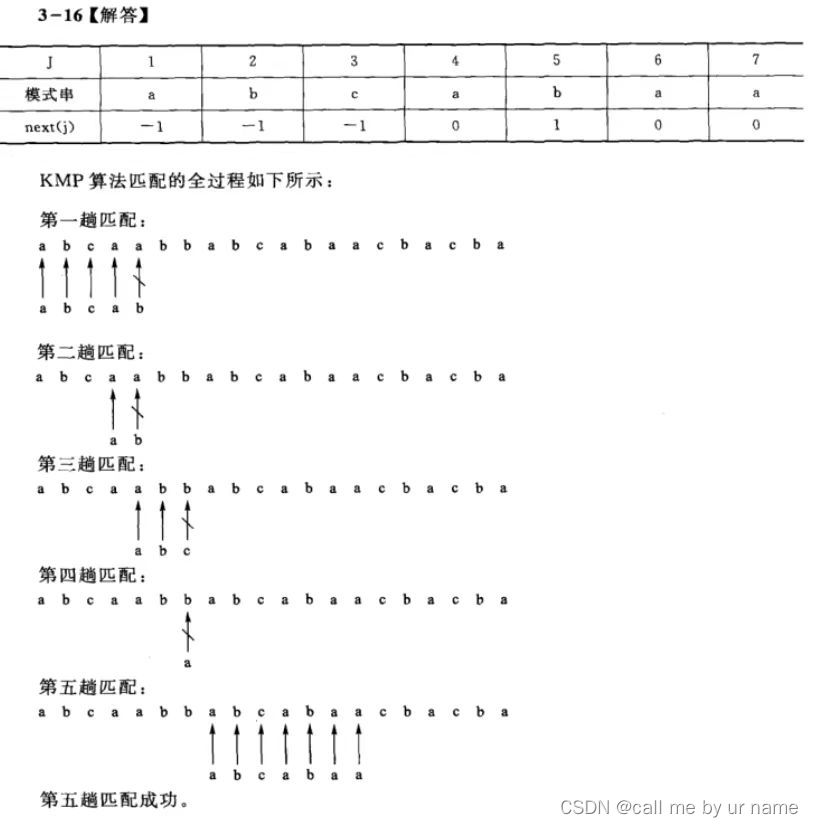
エクササイズ
KMPマッチ