
1. 背景の紹介
GoldenEye PAAS データ サービスは、同じインジケーター サービス契約を実装する一連のデータ サービスです。各サービスは、生成されるインジケーターのテーマに従って分割されています。たとえば、リアルタイム トランザクション サービスは、リアルタイム トランザクション インジケーターのクエリを提供します。財務オフライン サービスは、オフライン財務指標のクエリを提供します。GoldenEye PAAS データ サービスは、GoldenEye APP、GoldenEye PC、およびさまざまな内部大画面のデータ クエリのニーズをサポートします。企業がデータに関する正しい洞察と意思決定を行うには、PAAS ベースのデータ サービスによって提供されるデータの正確性を確保する必要があります。
ビジネス要件の迅速な反復に伴い、データ サービスではクエリの口径、クエリのディメンション、クエリ インジケーターを調整する必要が生じることが多いため、各要件の反復の品質を確保するには、効率的な自動回帰テスト手法が必要です。PAAS データ サービスの自動テストは、いくつかの問題に直面しています。
リクエスト シナリオの多様性とインジケーター サービス プロトコルの特殊性に対応して、GoldenEye PAAS データ サービス専用の DIFF ツールを実装しました。オンライン トラフィックを記録し、テスト環境とオンライン環境で再生し、返された結果を比較することで、リクエストの再生効率と比較結果の誤検知の問題が特に最適化されました。この方法では、オンライン クエリ シナリオを完全にカバーし、手動でリクエスト シナリオを構築する際の手動介入を削減し、十分に効率的な自動回帰テスト機能を提供して、研究開発の自己テストを強化できます。
一定期間の構築と反復を経て、GoldenEye の PAAS ベースのデータ サービス DIFF ツールは、リアルタイム取引、オフライン取引、オフライン金融という GoldenEye の 3 つのサービスをカバーするようになり、月間平均 DIFF 実行回数は 40 回を超えました。
次の記事では、GoldenEye PAAS ベースのデータ サービス DIFF ツールの構築で遭遇する課題と実際の経験を紹介します。
2. 問題点とアイデア
2.1 PAAS プロトコルの呼び出しの難しさ
GoldenEye PAAS サービスはすべて同じインジケーター サービス プロトコルを実装しており、リクエスト パラメーターは複雑なネストされたオブジェクトであり、基準コレクション内の各フィルター条件オブジェクトは Jackson の @JsonSubTypes アノテーションを使用して多態性解析を実装します。JSF チームの http 呼び出しドキュメントによると、複雑なネストされたオブジェクトを含むインターフェイスを呼び出すには、各ネストされたオブジェクトに "@type": "パッケージ パス + クラス名" を追加する必要があり、JSON.toJSONString (インスタンス、 SerializerFeature.WriteClassName)を使用することが推奨されています。) は、次の図に示すように、型特性を持つ JSON 文字列を生成します。生成する前に、Jackson を使用してリクエスト パラメーターをインスタンス オブジェクトに逆シリアル化する必要があります。Python スクリプトでこの種の JSF インターフェイスを呼び出すために http メソッドを使用する場合は、各フィルター条件の実装クラスを自分で識別する必要があります。PAAS データ サービス JSF インターフェイスの便利な呼び出しを実現するために、Java で書かれたDIFFツールが誕生しました。

2.2 主な課題
Java で書かれた DIFF ツールは、PAAS ベースのデータ サービス インターフェイス呼び出しの問題を解決できますが、既存の DIFF スクリプトを実際に使用すると、次の 2 つの課題に直面します。
2.2.1 リクエストの再生効率の問題
シングルスレッド再生
記録されたリクエストのインターフェイス呼び出しと結果の比較は、リクエスト リストをトラバースする単一のスレッドによって実装されます。単一のリクエストがオンライン環境とテスト環境のインターフェイスを正常に呼び出した後、返された結果が比較されます。比較が完了した後でのみ実行してください。次のリクエストに戻ります。しかし実際には、前のリクエストの再生と次のリクエストの間に呼び出しシーケンスはありません。リクエストの再生に単一のスレッドを使用するこの方法では、実行効率が大幅に低下し、diff 実行時間が長すぎます。
同期呼び出しインターフェース
さらに、オンライン環境とテスト環境のインターフェイスの呼び出しは同期されており、ある環境のインターフェイスが結果を返した後、次のインターフェイスが呼び出されます。同様に、2 つの環境のインターフェイス呼び出し間に依存関係はありません。1 つの環境インターフェイスの戻り値は、次のインターフェイスの呼び出しに影響しません。必要なのは、両方の環境インターフェイス呼び出しに戻り値があることを確認することだけです。次に、結果を比較します。
2.2.2 比較結果における誤検知の問題
インデックスが矛盾しています
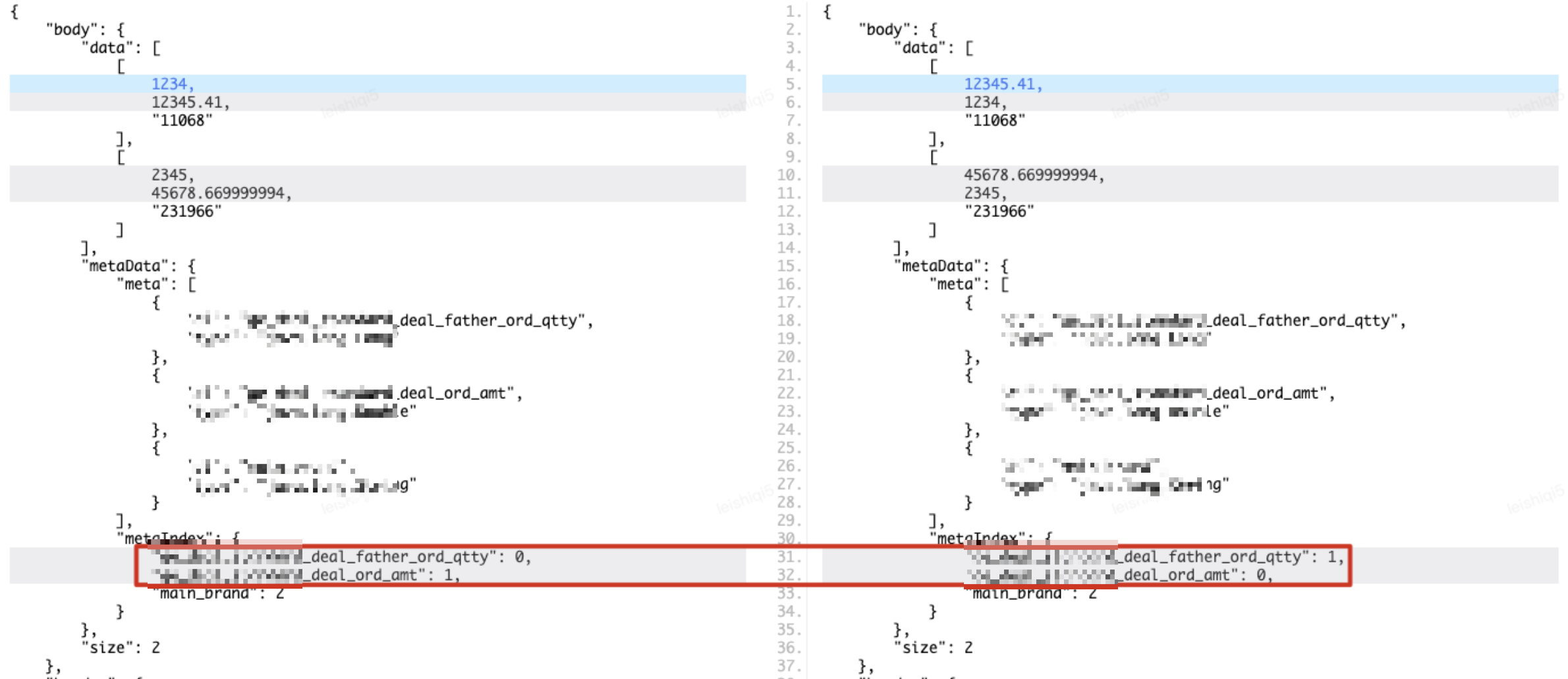
PAAS プロトコルのリターン パラメーター構造は次のとおりです。body.data データ セットが最も多くの情報要素を持ち、主な比較対象であることがわかります。meteData.metaIndex データ インデックスは、各値によって表される特定のフィールドを定義します。データセットのサブ要素の名前、たとえば、[1234,12345.41,"11068"] の 3 つの値は、それぞれトランザクションの親注文量、トランザクション金額、メイン ブランド ID を表します。2 つの環境インターフェイスの戻り値のフィールド名のインデックスが一致していないが、インデックスに従って実際に取得されたフィールド名に対応する値が同じ場合、この場合、比較のためにデータ コレクションのサブコレクションを直接走査します。と、異なる結論が得られますが、実際には、2 つの戻り値は一貫しているため、以下の図に示すように、比較結果で誤検知が発生します。
順序なし配列
一貫性のないフィールド名インデックスに加えて、比較の際に誤検知が発生する可能性があるほか、データ セット データの各サブコレクションの順序が狂っている可能性があります。この例のリターン パラメーター データでは、最初のサブコレクションにはメイン ブランド「11068」の 2 つのインジケーターが含まれ、2 番目のサブコレクションにはメイン ブランド「231966」の 2 つのインジケーターが含まれています。インターフェイス、1 つのサブコレクションのメイン ブランドは「231966」、2 番目のサブコレクションのメイン ブランドは「11068」です。この場合、直接走査して比較すると、比較結果に違いが生じますが、実際には、これは誤検知でもあります。

2.3. 解決策のアイデア
2.3.1 リクエスト再生効率の問題を解決するためのトラバーサルリクエスト中の同時実行とトラフィック再生中の非同期
メインチャレンジの分析から、DIFF 実行の消費時間 = 再生する必要があるリクエストの数 * (2 つの環境でのインターフェイス呼び出しの消費時間 + 比較の消費時間) であることがわかります。 。時間のかかる分割式から、並列再生の要求と非同期インターフェイス呼び出しの 2 つの方向で DIFF 実行の効率を最適化できることがわかります。
2.3.2 比較結果の誤検知の問題を解決するために、フィールドインデックスの統合と二次ソートが実装されています
PAAS プロトコルの戻りパラメーターの構造では、比較結果で誤検知をゼロにするために、2 つの環境の戻り値フィールドのインデックスを統一し、データ セット内のサブコレクションの順序を確実に統一する必要があります。 , そのため、戻り値の結果を比較するときに、コントラスト異常は発生しません。
フィールド インデックスの統合実装は比較的単純で、ある環境インターフェイスの戻り値のフィールド インデックス metaIndex に基づいて、別の環境インターフェイスの戻り値内のデータ サブコレクション内の各値の位置を再配置して、次のことを保証します。データ サブコレクション内の各値が走査され、対応するフィールド名は一貫しています。
二次ソートは、データのサブセット間の順序の問題を解決することです。「二次」に重点を置いているのは、サブセットに複数の値が含まれる可能性があるためです。値が 1 つだけソートされている場合、サブセットは完全に保証されませんしたがって、サブセット間の順序を安定させ、比較結果の信頼性を確保するために、ソートの基礎としてサブセット内の複数の値を選択する二次ソーターを実装する必要があります。
3. 全体構成

4. 設計のコアポイント
4.1 リクエストの再生効率の最適化
4.1.1 再生前に重複排除をリクエストする
データ サービス DIFF ツールを構築する前の 1 つの目標は、「すべての再生リクエストを意味のあるものにする」ことでした。読み取り専用データ クエリ サービスの場合、毎日大量のリクエストが繰り返されます。リクエストが重複排除されていない場合、再生リクエストの大部分が繰り返されます。このようなリクエストは再生と DIFF に使用されますが、これらのリクエストは使用されません。リソースを浪費するだけで、最終的な比較結果の概要を妨げるだけであり、まだ意味がありません。したがって、再生を要求する前に重複排除処理が必要となる。
最初に、DIFF ツールによって採用されるリクエスト パラメータの重複排除メソッドは HashSet メソッドです。トラフィックを再生するためにインターフェイスを呼び出す前に、リクエストの重複排除は HashSet に保存されます。重複排除が完了した後、HashSet はトラフィックの再生のために走査され、 DIFF実行。この方法は効果的に重複を削除できますが、実際の使用では、diff を必要とするリクエストの数が多すぎる場合、またはリクエスト パラメータが大きすぎる場合 (指定された 2000 SKU の財務指標のクエリなど)、HashSet の重複排除効率は次のようになります。 50,000 個の大きなリクエストのトラバーサル重複排除には 10 分以上かかり、多くのメモリが消費されます。DIFF を実行するパイプライン コンテナのメモリが小さい場合、DIFF の実行は直接失敗します。
リクエストの重複排除効率を向上させるため、ブルームフィルター方式を採用して重複排除を実現しています HashSet方式に比べて占有メモリが少なく、重複の有無の判定効率も比較的高いため、重複排除運用に適しています大量のデータ。
for (int i = 0; i < maxLogSize; i++) {
String reqParam = fileAccess.readLine();
if (bloomFilter.mightContain(reqParam)){
//请求重复,跳过此请求
countDownLatch.countDown();
continue;
}else {
bloomFilter.put(reqParam);
}
//请求不重复,执行接口调用和DIFF
}4.1.2 リクエストを横断する際の同時実行性
リクエストをトラバースするときは、execute() メソッドを使用してリクエストの再生タスクと DIFF 実行タスクをスレッド プールに送信します。各リクエストは独立したタスクを生成し、タスクは並行して実行されるため、DIFF プロセス全体の実行効率が向上します。DIFF は、再生と結果の比較の各リクエストが完了した後に、比較の差分の要約と表示を実行する必要があるため、メインスレッドをブロックして、すべての再生比較タスクのサブスレッドが終了するのを待ってから、要約を実行するメインスレッドを開始する必要があります。差異結果の分析。
メインスレッドとサブスレッド間の呼び出しタイミング要件を満たすために、CountDownLatch カウンタが使用されます。最大リクエスト数 n は初期化時に設定されます。サブスレッドが終了するたびに、カウンタは 1 ずつデクリメントされます。が 0 になると、待機していたメインスレッドが起動し、差分結果を集計します。
これにも、スレッド プールの拒否ポリシーの問題が関係します。スレッド プールのデフォルトの AbortPolicy ポリシーを使用するが、例外をキャッチせず、例外処理中にカウンタを 1 つ減らす場合、スレッド プールが新しいタスクを受け入れることができない場合、CountDownLatch カウンタは0 になることはなく、メインスレッドは常にブロックされ、DIFF プロセスは決して終了しません。DIFF がスムーズに実行され、異常な状況でも比較結果を出力できるようにするため、またすべてのリクエストを確実に再生および比較できるようにするために、ここでは CallerRunsPolicy を使用して、拒否されたタスクを実行のために呼び出し元に返します。
//初始化计数器
CountDownLatch countDownLatch = new CountDownLatch(maxLogSize);
log.info("开始读取日志");
for (int i = 0; i < maxLogSize; i++) {
String reqParam = asciiFileAccess.readLine();
if (bloomFilter.mightContain(reqParam)){
//有重复请求,跳出本次循环,计数器减一
countDownLatch.countDown();
continue;
}else {
bloomFilter.put(reqParam);
}
//向线程池提交回放和对比任务
threadPoolTaskExecutor.execute(() -> {
try {
//执行接口调用和返回结果对比
}
} catch (Exception e) {
} finally {
//子线程一次执行完成,计数器减一
countDownLatch.countDown();
}
});
}
//阻塞主线程
countDownLatch.await();
//等待计数器为0后,开始汇总对比结果4.1.3 再生要求時の非同期
JSF は、CompletableFuture<T> オブジェクトを返すインターフェイスの非同期呼び出しメソッドを提供します。thenCombine メソッドを簡単に使用して、テスト環境インターフェイスとテスト環境インターフェイス呼び出しの戻り値を結合し、戻り値の比較を実行して、比較結果。
//测试环境接口异步请求
CompletableFuture<UResData> futureTest = RpcContext.getContext().asyncCall(
() -> geTradeDataServiceTest.fetchBizData(param)
);
//线上环境接口异步请求
CompletableFuture<UResData> future = RpcContext.getContext().asyncCall(
() -> geTradeDataServiceOnline.fetchBizData(param)
);
//使用thenCombine对futureTest和future执行结果合并处理
CompletableFuture<ResCompareData> resultFuture = futureTest.thenCombine(future, (res1, res2) -> {
//执行对比,返回对比结果
return resCompareData;
});
//获取对比结果的值
return resultFuture.join();4.2 誤報率の最適化
4.2.1 フィールドインデックスの統合
フィールド インデックスの統合の核心は、 2 つの戻り値間の同じフィールド名インデックス間のマッピング関係を見つけることです。たとえば、戻り値 A のフィールド名 a のインデックス Index1 は、戻り値 B のフィールド名 a のインデックス Index2 に対応します。 。すべてのマッピング関係が見つかった後、戻り値配列 B 内のフィールドの順序が並べ替えられます。
List<List<Object>> tmp = new ArrayList<>();
int elementNum = metaIndex1.size();
HashMap<Integer, Integer> indexToIndex = new HashMap<>(elementNum);
//获取索引映射关系
for (int i = 0; i < elementNum; i++) {
String indicator = getIndicatorFromIndex(i, metaIndex2);
Integer index = metaIndex1.get(indicator);
indexToIndex.put(i, index);
}
//根据映射关系重新排放字段,生成新的数据集合
for (List<Object> dataElement : data2) {
List<Object> tmpList = new ArrayList<>();
Object[] objects = new Object[elementNum];
for (int i = 0; i < dataElement.size(); i++) {
objects[indexToIndex.get(i)] = dataElement.get(i);
}
Collections.addAll(tmpList, objects);
tmp.add(tmpList);
}4.2.2 データセットの二次ソート
データセット データには複数のサブセットが含まれており、各サブセットは属性値とインジケーターの組み合わせです。サブコレクション間の順序付けを実現するには、すべての属性フィールドのインデックスを検索し、すべての属性フィールドの値を並べ替え基準として使用する二次ソーターを実装する必要があります。
一般に、属性フィールドのデータ型は String 型ですが、属性値として sku_id を使用した場合、sku_id が返すデータ型は Long 型になるなど特殊な場合もあります。二次ソーターの汎用性と信頼性を実現するには、まず String 型フィールドをすべて使用してソートし、次に Long 型フィールドを使用してソートします (String 型フィールドがない場合は、Long 型フィールドをすべてソートします)。
List<Integer> strIndexList = new ArrayList<>();
List<Integer> longIndexList = new ArrayList<>();
// 保存所有String和Long类型字段的索引
for (int i = 0; i < size; i++) {
if (data.get(0).get(i) instanceof String) {
strIndexList.add(i);
}
if (data.get(0).get(i) instanceof Long || data.get(0).get(i) instanceof Integer) {
longIndexList.add(i);
}
}
//首选依据String类型字段排序
if (!strIndexList.isEmpty()) {
//初始化排序器
Comparator<List<Object>> comparing = Comparator.comparing(o -> ((String) o.get(strIndexList.get(0))));
for (int i = 1; i < strIndexList.size(); i++) {
int finalI = i;
//遍历剩余String字段,实现任意长度次级排序器
comparing = comparing.thenComparing(n -> ((String) n.get(strIndexList.get(finalI))));
}
for (int i = 0; i < longIndexList.size(); i++) {
int finalI = i;
comparing = comparing.thenComparingLong(n -> Long.parseLong(n.get(longIndexList.get(finalI)).toString()));
}
sortedList = data.stream().sorted(comparing).collect(Collectors.toList());
}4.3 PAAS データサービスの DIFF 効果
リクエストの再生効率と誤警報率を最適化した後、データ サービスの DIFF 実行の時間消費と比較結果は、オンラインになる前の既存の研究開発セルフテストと回帰のニーズを満たすことができます。以下の図は、GoldenEye 取引リアルタイム サービスの DIFF レポートを示しています。4 つの作業スレッドの構成では、40,000 件のリクエストが重複排除された後、リクエストの再生には 570 秒かかりました。比較結果でも、データの違いが明確に示されています。データの差異の調査を容易にするために、差異の比較結果を表示するときに、インデックスに基づいて差異の値に対応するフィールド名を手動で検索することを避けるために、フィールド名が値の前に結合されます。

5. 実装
5.1 データサービステストアクセスパイプライン
パイプラインは、ダウンロード コード アトム、コンパイル アトム、シェル カスタム スクリプト アトムを提供しており、これら 3 つのアトムは DIFF タスクの実行をトリガーできます。このパイプラインの機能を利用して、DIFF ツールの機能が GoldenEye GoldenEye のリアルタイム取引およびオフライン データ サービスの取引のテスト アクセス パイプラインに導入されました。テスト アクセス パイプラインには、テスト ブランチ コードのコンパイルと JDOS デプロイメント、トラフィックの再生と実行結果の比較、DIFF プロセス中のインターフェイス テスト カバレッジ統計が含まれます。DIFF テストのためのオンライン トラフィックの再生を通じて、トランザクション オフライン サービスとリアルタイム サービス コードの回線カバレッジはそれぞれ 51% と 65% に達しました。

トランザクションオフラインサービステストアクセスパイプライン
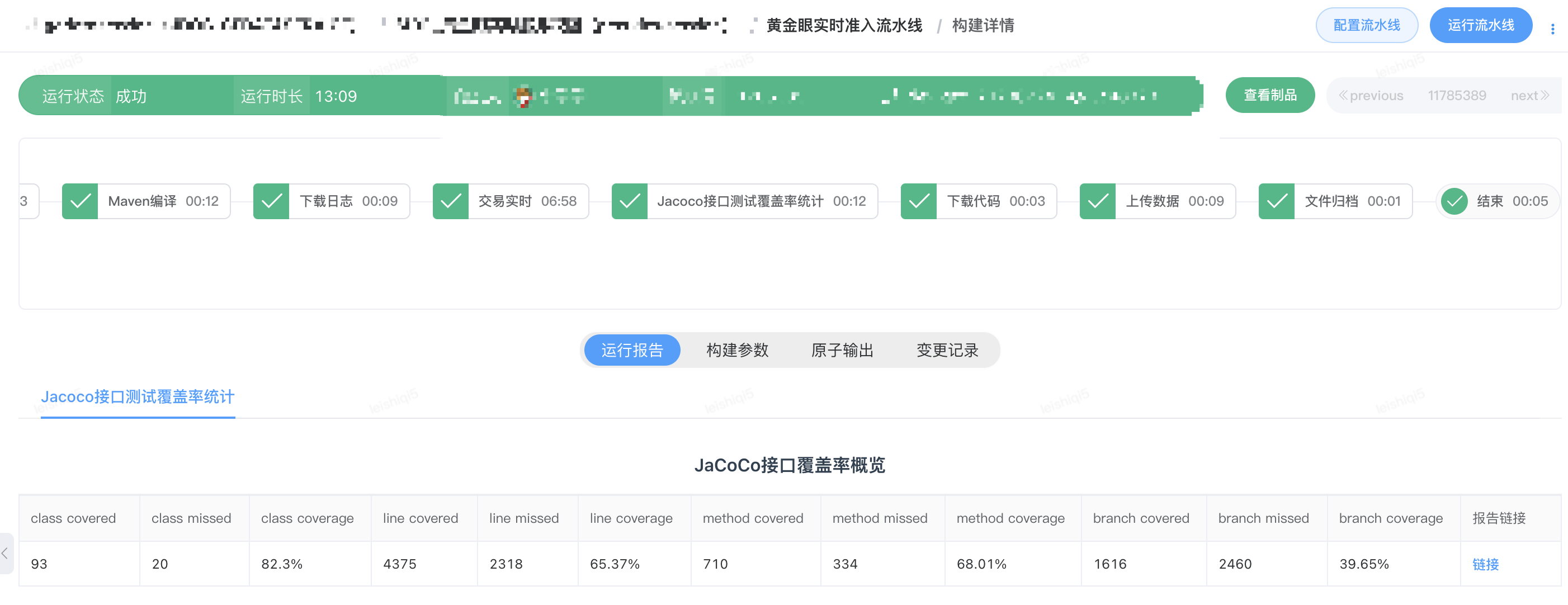
トランザクション リアルタイム サービス テスト アクセス パイプライン
5.2 効率を向上させるためのサービス研究開発セルフテスト
テスト受付パイプラインで役割を果たす DIFF ツールに加えて、研究開発のセルフテストを強化して効率を向上させるために DIFF を手動でトリガーできるパイプラインもセットアップしました。現在、DIFF パイプラインは、トランザクション オフライン サービス、リアルタイム トランザクション サービス、金融オフライン サービスを含む GoldenEye PAAS の複数のデータ サービスに実装されており、以下の図は、これら 3 つのデータ サービスの DIFF パイプラインの月間実行時間を示しています。 9 月の累積実行時間は、66 回 DIFFです。

*データソース: パイプライン実行傾向統計
現在、DIFF ツールには、差異率しきい値のカスタマイズ、キーワードのフィルターと除外、フィルター条件のカスタマイズ、インジケーター サービスの PAAS リクエストのインジケーターのリクエストの機能がすでに備わっています。インジケーター サービスに対する PAAS ベースのリクエストに対するこのカスタマイズ機能は、日々の需要の反復と技術変革において一定の役割を果たします。
たとえば、GoldenEye 取引リアルタイム サービスのクエリ エンジンは Elasticsearch から Doris に切り替えられましたが、この変換には多くの DIFF 回帰テスト作業が必要でした。この過程で、研究開発では、Elasticsearch と Doris の重複排除指標 (サブアイテムの数量など) の計算方法にいくつかの違いがあることが判明し、その結果、2 つのエンジンを使用してクエリされた重複排除指標の差異率は、他の非重複排除インジケーターのインジケーター (金額など)、これは最終的な比較結果の表示を妨げ、真に異なるリクエストを検出するのに役立ちません。この問題を解決するために、インジケーター サービス PAAS ベースのリクエスト インジケーターをカスタマイズする機能を提供します。非重複排除インジケーターのみをクエリするように再生リクエストを設定して、重複排除インジケーターの干渉を回避し、回帰テストの進行を促進できます。 。
6. まとめ
この記事では、データ サービス DIFF ツールの構築中に GoldenEye データ品質チームが直面した DIFF 効率と比較結果の信頼性という 2 つの主要な問題を紹介し、上記 2 種類の問題と対応するソリューションと実装における実際の経験についても詳しく説明します。それぞれに挑戦します。
6.1 カスタマイズされた DIFF ツールの利点
JD.com の社内のプロフェッショナルな記録および再生プラットフォームである R2 と比較すると、当社の DIFF ツールは、トラフィック記録、リンク追跡、多用途性、その他の機能の点ではるかに不十分または欠如しています。ただし、PAAS データ サービスの DIFF カスタマイズの観点から見ると、リクエストのカスタマイズと比較のプロセスで DIFF ツールによって行われる最適化は、現在このユニバーサル プラットフォームではサポートされていません。
6.2 今後の展望
現在、自動回帰テストには DIFF ツールが使用されていますが、GoldenEye トレーディング オフライン サービスとリアルタイム サービスのインターフェイス テストのコード ライン カバレッジ率は約 50% であり、毎日のオンライン クエリ シナリオではすべてのコード ブランチをカバーできないことがわかります。DIFF テストのコード ライン カバレッジを改善するために、後でカバレッジ レポートを分析して、オンライン クエリでカバーされていないシナリオを見つけ、リクエストのユース ケースの固定セットを形成することを検討します。オンライン トラフィックと固定リクエストの両方のユースケースをバックし、DIFF テストの行カバレッジを向上させるために設定します。
Lei Jun: Xiaomi の新しいオペレーティング システム ThePaper OS の正式版がパッケージ化されました。Gome App の抽選ページのポップアップ ウィンドウは創設者を侮辱しています。Ubuntu 23.10 が正式にリリースされました。金曜日を利用してアップグレードするのもいいでしょう! Ubuntu 23.10 リリース エピソード: ヘイトスピーチが含まれていたため、ISO イメージが緊急に「リコール」されました 23 歳の博士課程の学生が Firefox で 22 年間続いた「ゴーストバグ」を修正しました RustDesk リモート デスクトップ 1.2.3 がリリースされましたWayland を強化して TiDB 7.4 をサポート リリース: MySQL 8.0 と正式互換. Logitech USB レシーバーを取り外した後、Linux カーネルがクラッシュしました. マスターは Scratch を使用して RISC-V シミュレータをこすり、Linux カーネルを正常に実行しました. JetBrains が Writerside ツールを開始しました技術文書の作成に。著者: JD Retail Lei Shiqi
出典:JD Cloud Developer Community 転載の際は出典を明記してください