アプリケーションシステムでは、データアクセスを高速化するために、頻度の高いデータを「キャッシュ」 (Redis、MongoDB)に入れてデータベースへの負担を軽減します。
オペレーティング システムでは、ディスク IO を削減するために、「バッファプール」メカニズムが導入されています。
ストレージ システムとして、MySQL にはパフォーマンスを向上させ、ディスク IO を削減するためのバッファ プール メカニズムもあります。構造図は次のとおりです。
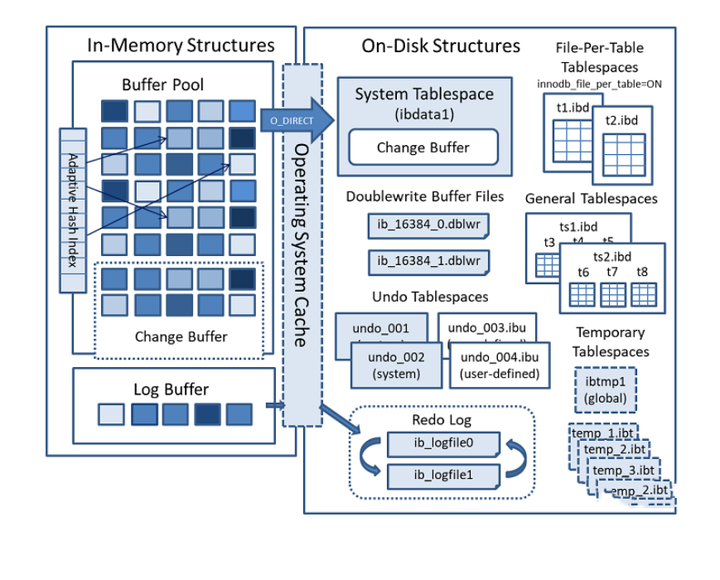
「上記の構造図は、バッファ プールが InnoDB メモリ構造の 4 つの主要コンポーネントの 1 つであることを示しています。これは MySQL のサーバー層に属さず、InnoDB ストレージ エンジン層のバッファ プールです。」したがって、MySQL 8.0で削除された「クエリキャッシュ」機能とは異なります。
1. バッファプールとは何ですか?
「バッファ プールは [バッファ プール、BP と略記されます]。BP は、最もホットなデータ ページ (データ ページ) とインデックス ページ (インデックス ページ) をキャッシュする単位としてページ ページを使用します。ページ ページのデフォルト サイズは 16K です。 BP はリンク リスト データ構造を使用します。ページの管理」。
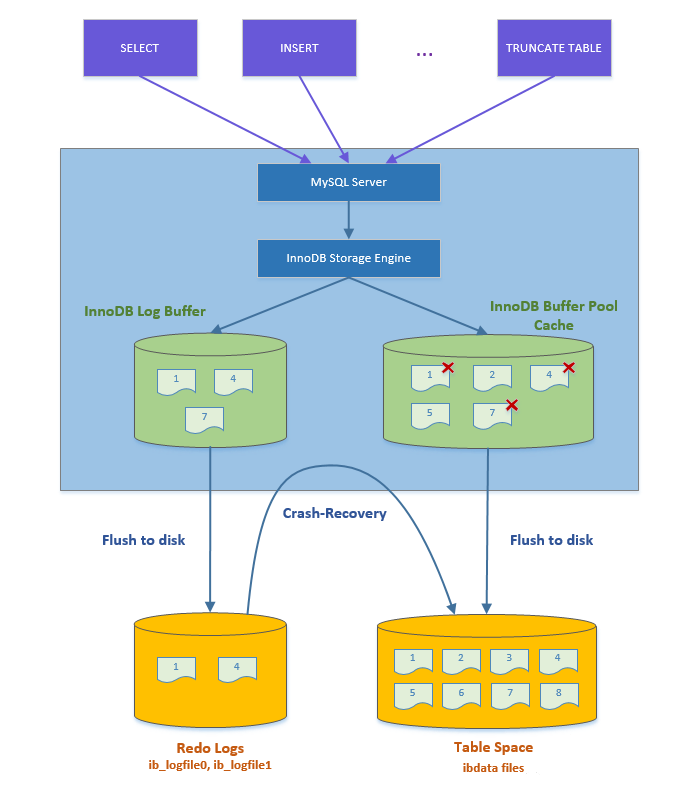
上の図は innoDB 内のバッファー プールの場所を示しており、その場所からそのワークフローを大まかに知ることができます。
すべてのデータ ページの読み取りおよび書き込み操作は、バッファ プールを通じて実行する必要があります。
Innodb の読み取り操作では、最初にデータのデータ ページがbuffer_pool に存在するかどうかを確認し、存在しない場合はディスクからバッファ プールにページを読み取ります。
Innodb の書き込み操作は、まずデータとログをバッファ プールとログ バッファに書き込み、次にバックグラウンド スレッドがバッファの内容を一定の頻度でディスクにフラッシュします。「このフラッシュ メカニズムはチェックポイントと呼ばれます。」
書き込み操作のトランザクション耐久性は、REDO ログ ディスクの配置によって保証され、バッファ プールは読み取りおよび書き込みの効率を向上させる目的でのみ使用されます。
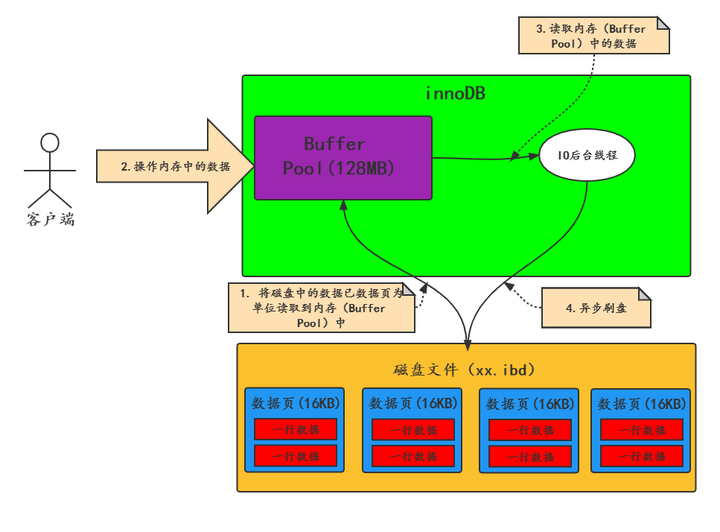
「バッファ プールはテーブル データとインデックス データをキャッシュし、ディスク上のデータをバッファ プールにロードし、アクセスごとのディスク IO を回避し、アクセスを高速化します。」
- バッファプールとはメモリ領域のことであり、「ディスクアクセスを軽減する仕組み」**です。
- データベースの読み取りと書き込みは、UNDO ログ/REDO ログ/REDO ログ バッファ/binlog と併用されるバッファ プール上で実行され、データは後でハードディスクにフラッシュされます。
- バッファ プールのデフォルト サイズは 128M で、データ ページ (16KB) をキャッシュするために使用されます。
show variables like 'innodb_buffer%';
バッファプールはInnoDBのデータキャッシュで、「インデックスページ」や「データページ」をキャッシュするほか、アンドゥページ、挿入キャッシュ、アダプティブハッシュインデックス、ロック情報などが含まれます。
"バッファ プール内のほとんどのページはデータ ページ (インデックス ページを含む) です。 "
「Innodb には、REDO ログを保存するためのログ バッファもあります。 」
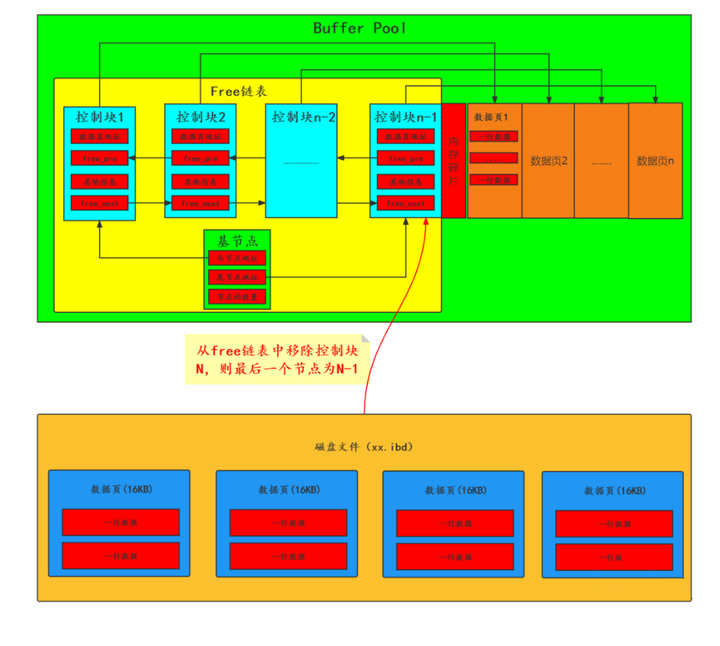
2. バッファプール制御ブロック
データ ページはバッファ プールにキャッシュされます。データ ページのサイズは、ディスク上のデフォルトのデータ ページ サイズ (16K) と同じです。キャッシュ ページをより適切に管理するために、バッファ プールには「データ記述領域」があります。
「InnoDB は、キャッシュされたデータ ページごとに個別の領域を作成し、データ ページが属するテーブル スペース、データ ページ番号、バッファ プール内のキャッシュ ページのアドレス、リンク リストなどのデータ ページのメタデータ情報を記録します。ノード情報、一部のロック情報、LSN情報などが含まれるこの領域をコントロールブロックと呼びます。
「コントロール ブロックとキャッシュ ページは 1 対 1 に対応しています。両方ともバッファ プールに格納されます。コントロール ブロックはバッファ プールの前に格納され、キャッシュ ページはバッファ プールの後ろに格納されます。」バッファプール。」
制御ブロックはキャッシュ ページ サイズの約 5% (約 16 * 1024 * 0.05 = 819 バイト) を占めます。
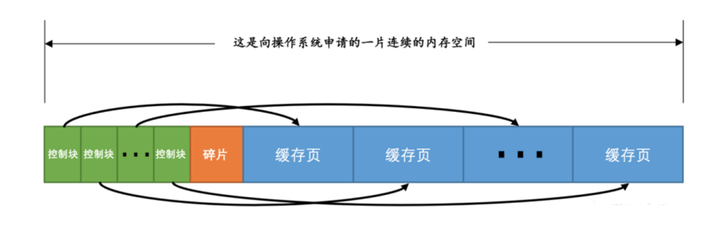
上図はコントロールブロックとデータページの対応関係を示したもので、コントロールブロックとデータページの間に断片的なスペースがあることが分かります。
ここで疑問が生じるかもしれません。なぜ空間が断片化されているのでしょうか?
前述したように、データページのサイズは 16KB、コントロールブロックは約 800 バイトであるため、すべてのコントロールブロックとデータページを分割すると、コントロールブロックとキャッシュページのペアに十分ではない領域が残る可能性があります。部分 それは単なる余分な断片化されたスペースです。バッファー プールのサイズが適切に設定されている場合、断片化は発生しない可能性があります。
3. バッファプールの管理
「バッファ プールには、LRU リンク リスト、フリー リンク リスト、フラッシュ リンク リストの 3 つのリンク リストがあります。InnoDB は、これら 3 つのリンク リストを使用してデータ ページの更新と削除を制御します。」
3.1 バッファプールの初期化
「Mysql サーバーを起動するときは、バッファ プールの初期化プロセスを完了する必要があります。つまり、バッファ プールのメモリ空間を割り当て、それを制御ブロックとキャッシュ ページのいくつかのペアに分割します。」
- 「領域の申請」 Mysqlサーバーが起動すると、設定されたバッファプールサイズ(innodb_buffer_pool_size)に基づいて、バッファプールのメモリ領域としてオペレーティングシステムに「連続メモリ領域の申請」を行います。ここで適用されるメモリ空間が innodb_buffer_pool_size よりも大きくなる理由は、主に各キャッシュ ページの制御ブロックも格納されるためです。
- 「領域の分割」メモリ領域の適用が完了すると、データベースは、デフォルトのキャッシュ ページ サイズの 16KB と、対応する制御ブロック サイズの約 800 バイトに従って、バッファ プール内のいくつかの「制御ブロック」に分割されます。 & バッファページ] 右」**。
領域分割後のバッファプールのキャッシュページはすべて空であり、データの追加、削除、変更、確認が行われると、そのデータに対応するページがディスクファイルから読み出されて配置されます。バッファに格納され、プール内のキャッシュ ページに格納されます。
3.2 無料リンクリスト
「バッファプールが最初に初期化されるとき、内部のデータページと制御ブロックは空です。」読み取りと書き込みが実行されると、ディスクのデータページがバッファプールのデータページにロードされます。 BufferPool の中央 データがハードディスクに保存された後、これらのデータ ページは再び解放されます。
上記のプロセスで問題が発生します。どのデータ ページが空で、どのデータ ページにデータがあるかをどのように知ることができますか。空のデータ ページを見つけることによってのみ、データを書き込むことができます。1 つの方法は、すべてのデータ ページを走査することです。経験によると、 , 一般的に言えば、その全体を横断する限り、追求するプログラマにとっては間違いなく耐えられないことになりますが、innoDB の開発者は間違いなくさらに耐えられないことになるため、無料のリンク リストがあります。
3.2.1 フリーリンクリストとは何ですか?
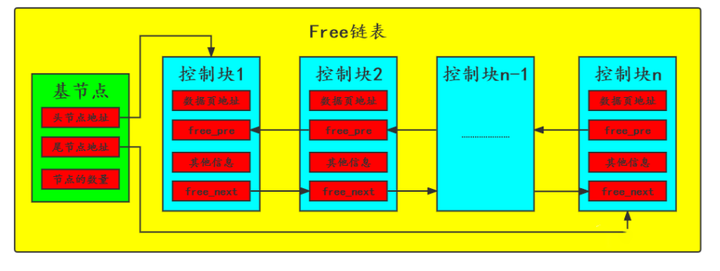
「フリーリンクリストは、フリーリンクリストです。これは、基本ノードといくつかのサブノードで構成される双方向リンクリストです。フリーデータページに対応する制御ブロック情報を記録します。」次のように
-
無料リンク リストの役割: 無料のキャッシュ ページを見つけるのに役立ちます
-
「ベースノード」
-
「これは、別途適用されたメモリ空間(約 40 バイトを占有)です。バッファ プールの連続メモリ空間にはありません。 」
-
リンク リスト内の子ノードの先頭ノードのアドレスと末尾ノードのアドレス、および現在のリンク リスト内のノードの数などの情報が含まれます。
-
「子ノード」
-
「各ノードは、空きキャッシュ ページの制御ブロックです。つまり、キャッシュ ページが空きである限り、その制御ブロックは空きリンク リストに配置されます。」
-
各制御ブロックには、free_pre (前のノードを指す) と free_next (次のノードを指す) の 2 つのポインターがあります。
フリー リンク リストの目的は、バッファ プール内のデータ ページを記述することであるため、次の図に示すように、フリー リンク リストとデータ ページの間には 1 対 1 の対応関係があります。
上図はフリーデータページを記録するフリーリンクリストの対応関係を示したものですが、このコントロールブロックがバッファプールに1コピー、フリーリンクリストに1コピーあると誤解される可能性があります。メモリ内に同一のコントロールが存在する ブロック「そう思ったら、完全に間違っています。 」
"誤解"
フリー リンク リスト自体は、実際にはバッファ プール内の制御ブロックで構成されています。前述したように、各制御ブロックには 2 つのポインタ free_pre/free_next があり、それぞれ前のフリー リンク リストと次のフリー リンク リストのノードを指します。ノード。"
「バッファ プール内の制御ブロックは、2 つのポインタを介してすべての制御ブロックをフリー リンク リストに文字列化できます。図面をよりわかりやすくするために、フリー リンク リストの別のコピーを描画して、それらの間のポインタを表しました。関係。"
「これに基づくと、実際の関係図は次のようになります。」 :
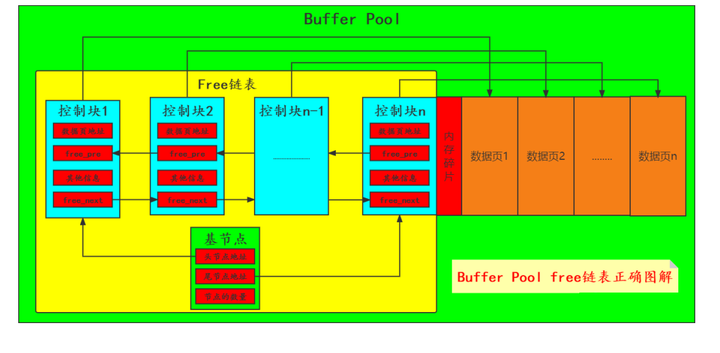
ここで両方の絵が描かれている理由は、インターネット上の多くのブログで描かれている絵が上記と同様であり、「バッファプールやフリーリンクリストに制御ブロックがあるかのような誤解を与えるからです」とのこと。私も最初はそんな疑問を抱いたので、ここに解説し記録しておきます。
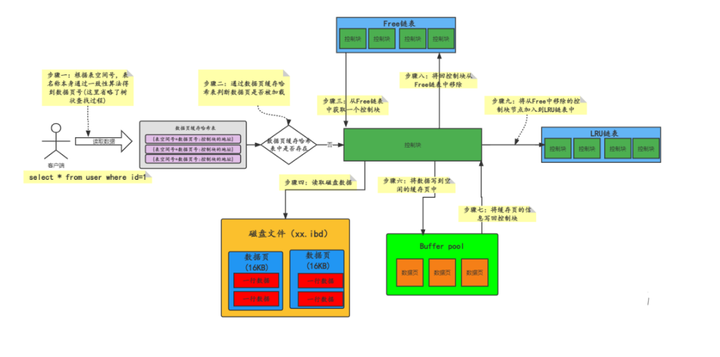
3.2.2 ディスクページをBufferPoolのキャッシュにロードするプロセス
フリー リンク リストを通じてディスク ページを BufferPool キャッシュにロードするには、次の 3 つの手順のみが必要です。
"第一歩"
「空き制御ブロックと対応するバッファ ページを空きリストから取得します。 」
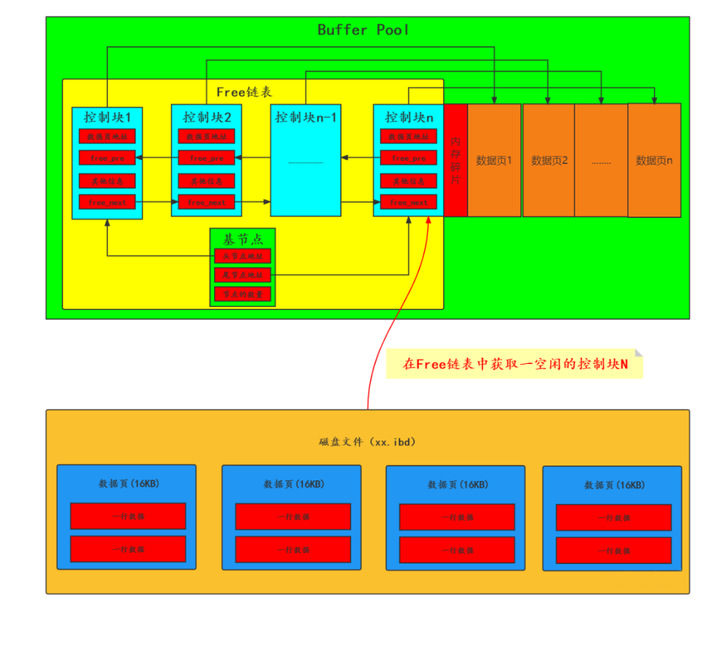
"ステップ2"
「ディスク上のデータ ページを対応するキャッシュ ページに読み取り、同時に関連する記述データをキャッシュ ページの制御ブロックに書き込みます (例: ページが配置されているテーブル スペース、ページ番号、その他の情報) )。」
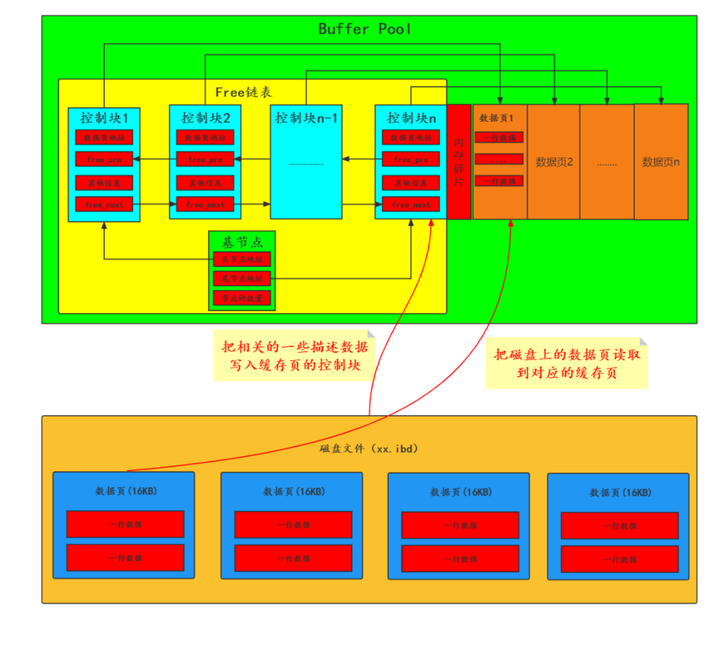
「ステップ3」
「リンク リストから制御ブロックに対応する空きリンク リスト ノードを削除すると、バッファ ページが使用されたことを示します。 」
- 以下では、疑似コードを使用して、制御ブロックがフリー リンク リスト ノードからどのように削除されるかを説明します。制御ブロックの構造は次のとおりであると仮定します。
/**
* 控制块
*/
publicclass CommandBlock {
/**
* 控制块id,也就是自己,可以理解为当前控制块的地址,
*/
private String blockId;
/**
* Free链表中当前控制块的上一个节点地址
*/
private String freePre;
/**
* Free链表中当前控制块的下一个节点地址
*/
private String freeNext;
}
制御ブロック n-1 があり、その前のノードが記述データ ブロック n-2、次のノードが記述データ ブロック n であるとすると、そのデータ構造は次のようになります。
/**
* 控制块 n-1
*/
publicclass CommandBlock {
/**
* 控制块id,也就是自己,可以理解为当前控制块的地址 block_n-1,
*/
blockId = block_n-1;
/**
* Free链表中当前控制块的上一个节点地址 block_n-2
*/
freePre = block_n-2;
/**
* Free链表中当前控制块的下一个节点地址 block_n
*/
freeNext = block_n;
}
上の図では、制御ブロック N を使用しています。これをフリー リンク リストから削除するには、block_n-1 の freeNext を null に設定するだけで済みます。これにより、block_n はリンク リストへの参照を失います。
/**
* 控制块 n-1
*/
publicclass CommandBlock {
/**
* 控制块id,也就是自己,可以理解为当前控制块的地址 block_n-1,
*/
blockId = block_n-1;
/**
* Free链表中当前控制块的上一个节点地址 block_n-2
*/
freePre = block_n-2;
/**
* Free链表中当前控制块的下一个节点地址 block_n
*/
freeNext = null;
}
3.2.3 データ ページがキャッシュされているかどうかを確認する方法
ディスク ページが Free を介してバッファ プールのキャッシュ ページにロードされることは理解しています。すべてのデータをディスクから読み取って、Free リンク リストを介してキャッシュ ページに書き込むことはできません。データ ページがすでに存在している可能性があります。では、データ ページをキャッシュする必要があるかどうかを判断するにはどうすればよいでしょうか?
「データベースは、テーブルスペース番号 + データページ番号をキーとし、キャッシュページ制御ブロックのアドレスを値として持つデータページキャッシュハッシュテーブルを提供します。」
#注意:value是控制块的地址,不是缓存页地址
{
表空间号+数据页号:控制块的地址}
データ ページを使用する場合、まずデータ ページ キャッシュ ハッシュ テーブルを検索します。見つかった場合は、その値に基づいて制御ブロックが直接検索され、次に制御ブロックに基づいてキャッシュ ページが検索されます。見つからない場合は、キャッシュ ページが検索されます。 、ディスク データ ページが読み書きされ、キャッシュされ、最後にデータ ページ キャッシュ ハッシュ テーブルに書き込まれます。
「このプロセスでは、ステートメントが実行される場合、通常は次のプロセスを経ます。」
- SQL ステートメント内のデータベース名とテーブル名によって、ロードされるデータ ページがどのテーブル スペースにあるかを知ることができます。
- 「テーブルスペース番号に従って、テーブル名自体が一貫性アルゴリズムを通じてインデックスルートノードのデータページ番号を取得します。 」
- 次に、ルート ノードのデータ ページ番号に基づいて次のレベルのデータ ページが見つかり、データ ページ キャッシュ ハッシュ テーブルから対応するキャッシュ ページ アドレスを取得できます。
- キャッシュ ページは、キャッシュ ページ アドレスを通じてバッファ プール内で見つけることができます。
重要な誤解! !!重要な誤解! !!重要な誤解! !!重要なことを 3 回言います。上記の一貫性のあるハッシュ アルゴリズムは、データ ディクショナリ内の [[現在検索されているデータのデータ ページ番号ではなく、ルート ノードのページ番号] を参照します。] ルート ノードのページを取得するときこの番号を指定すると、B+tree を介してレイヤーごとに検索します。次のレイヤーを見つける前に、データ キャッシュ ハッシュ テーブルを介してバッファ プールに移動し、このレイヤーのデータ ページが存在するかどうかを確認します。存在しない場合は、ディスクからロードされます。
3.3 LRUリンクリスト
LRU リンク リストを理解する前に、まず 2 つの問題について考えます。
- 最初の質問: 前述したように、データ ページがディスクからバッファ プールに読み取られるとき、対応する制御ブロックは空きリンク リストから削除されます。では、この制御ブロックは削除された後どこに配置されるのでしょうか?
- 2 番目の質問: バッファ プールのサイズは 128MB です。バッファ プール内のすべての空きデータ ページにデータが読み込まれた後、新しいデータはどのように処理されるべきですか?
上記の問題は両方とも、解決するには LRU リンク リストが必要です。これら 2 つの質問を含む LRU リンク リストを見てみましょう。
3.3.1 LRU リンクリストとは何ですか?
バッファ プールは InnoDB に付属するキャッシュ プールです。データの読み書きはバッファ プールで行われ、バッファ プール内のデータ ページが操作されます。ただし、バッファ プールのサイズには制限があります (デフォルトは 128MB)。頻繁にアクセスされるデータの一部はバッファ プールに残ることが予想されますが、アクセス頻度の低いデータの一部は解放され、他のデータをキャッシュするためにデータ ページを解放することが予想されます。
これに基づいて、InnoBD は、頻繁にアクセスされるデータをリンク リストの先頭に配置し、ほとんどアクセスされないデータをリンク リストの最後に配置する LRU (Least Recent Used) アルゴリズムを採用しています。十分なスペースがない場合、スペースを空けるために末尾から削除する必要があります。」
「LRU リンク リストは本質的に制御ブロックで構成されています。 」
3.3.2 LRUリンクリストの書き込み処理
「データベースがデータ ページをディスクからバッファ プールにロードすると、一部の変更情報も制御ブロックに書き込まれ、制御ブロックはフリー リンク リストから切り離され、LRU リンク リストに追加されます。 」プロセスは次のとおりです。
プロセス全体を整理してみましょう。
- 「ステップ 1: テーブルスペース番号に基づいて、テーブル名自体が整合性アルゴリズムを通じてデータページ番号を取得します (ツリー検索プロセスはここでは省略されます)」
- 「ステップ 2: データ ページがデータ ページ キャッシュ ハッシュ テーブルを通じてロードされているかどうかを確認する」
- 「ステップ 3: フリー リストからコントロール ブロックを取得する」
- 「ステップ 4: ディスク データを読み取る」
- 「ステップ 6: 空きキャッシュ ページにデータを書き込む」
- 「ステップ 7: キャッシュ ページ情報を制御ブロックに書き戻す」
- 「ステップ 8: 空きリストからリターン制御ブロックを削除する」
- 「ステップ 9: フリーから削除されたコントロール ブロック ノードを LRU リンク リストに追加する」
3.3.3 LRUリンクリストの削除メカニズム
「LRU アルゴリズムの設計上の考え方は、リンク リストの先頭のノードが最も最近使用されたノードであり、リンク リストの末尾のノードが最も長い間使用されていないノードであるということです。十分なスペースがない場合、スペースを解放するために、最も長い間使用されていない端のノードが削除されます。」
「LRU アルゴリズムの目的は、アクセスされたキャッシュ ページを可能な限り上位にランク付けできるようにすることです。 」
- 「LRUアルゴリズムの設計思想」
- アクセスされたページがバッファプールにある場合、そのページに対応する制御ブロックは、LRUリンクリストの先頭ノードに移動されます。
- アクセスされたページがバッファ プールにない場合、制御ブロックを LRU リンク リストの先頭に置くことに加えて、LRU リンク リストの末尾のノードも削除する必要があります。
- 「LRUの導入プロセス」
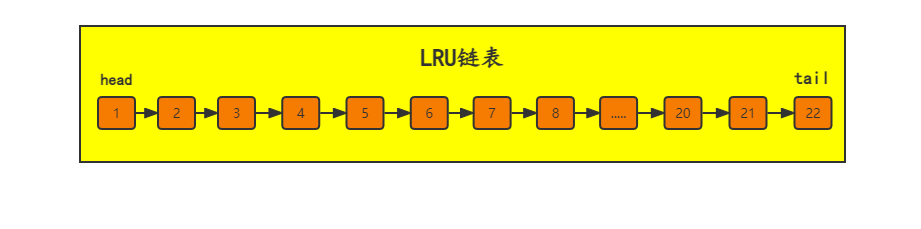
- データ アクセスがあり、データ ページ 23 にアクセスします。データ ページ 23 はバッファ プールにないため、ディスクがロードされた後、最後のページ 22 が削除され、次に 23 が先頭にロードされます。リンクされたリスト。
- このとき、データページ7がアクセスされるが、これはデータページ7がリンクリスト内にある、つまりバッファプール内にあるため、データページ7をリンクリストの先頭に直接移動することができる。
- 下図に示すように、LRU リンク リストの長さは 22 で、ノードは 1 から 22 までのデータ ページ制御ブロックです。初期状態は次のとおりです。
以上が LUR リンク リストの実装プロセスですが、この方法は MySQL にとって問題があるため、MySQL では LRU リンク リストの単純な実装を直接使用せず、いくつかの改良を加えています。と説明します。
3.4 リンクされたリストをフラッシュする
前に説明したように、**「データの読み取りと書き込みは、最初にバッファー プール内のキャッシュ ページ上で動作し、次にバックグラウンド スレッドを通じてダーティ ページをディスクに書き込み、それらをディスクに永続化します。つまり、ダーティ ページをフラッシュします。」ページ「** .
「ダーティ ページ: 書き込み操作を実行するとき、最初にキャッシュ ページが更新されます。このとき、キャッシュ ページとディスク ページのデータは不一致になります。これは多くの場合ダーティ ページと呼ばれます。」
ダーティ ページが生成されるため、ディスクを更新する必要があります (これは多くの場合ダーティと呼ばれます)。どのキャッシュ ページをフラッシュする必要があるかを判断するにはどうすればよいですか? また、キャッシュされたすべてのページについて 100 年間ディスクを更新したり、ページを 1 つずつ走査して比較したりすることもできません。この方法は絶対にお勧めできません。この場合、リンク リストをフラッシュする必要があります。
3.4.1 フラッシュリンクリストとは何ですか?
「フラッシュ リンク リストの構造はフリー リンク リストの構造と非常に似ており、これもベース ノードと子ノードで構成されます。 」
- フラッシュ リンク リストは双方向リンク リストであり、リンク リスト ノードは変更されたキャッシュ ページ (更新されたキャッシュ ページ) に対応する制御ブロックです。
- フラッシュ リンク リストの役割: フラッシュする必要があるダーティ ページとキャッシュ ページを見つけるのに役立ちます。
- 「ベースノード」:フリーリンクリストと同様に、最初のノードと最後のノードを結び付け、記述情報のブロックが何ブロックあるかを格納します。
- 「子ノード」
- 「各ノードは、ダーティ ページに対応する制御ブロックです。つまり、キャッシュ ページが変更されている限り、その制御ブロックはフラッシュ リンク リストに配置されます。」
- 各制御ブロックには、pre (前のノードを指す) と next (次のノードを指す) の 2 つのポインターがあります。
前述したように、制御ブロックは実際にはバッファ プール内にあります。制御ブロックは上位ノードと下位ノードの参照を通じてリンク リストを形成するため、子ノードを見つけるにはベース ノードを 1 つずつたどるだけで済みます。クリーニングする必要があるデータ ページです。」
3.4.2 フラッシュリンクリスト書き込み処理
データを書き込むとき、ディスク IO の効率が非常に遅いことがわかっているため、MySQL はディスクを直接更新せず、次の 2 つの手順を実行します。
- 最初のステップ: バッファー プール内のデータ ページを更新する (メモリ操作)。
- ステップ 2: 更新操作を REDO ログに順次書き込みます (ディスク順次書き込み操作)。
この効率が最も高い。REDO ログを 1 秒あたり数万回連続して書き込むことは、大きな問題ではありません。
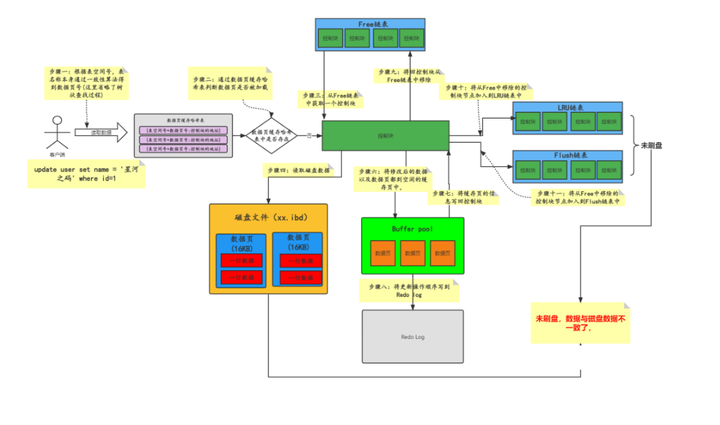
上図はデータページ更新時のフラッシュリンクリストの書き込み処理を説明していますが、実際には更新データがバッファプールにロードされていることを前提としています。事前に、このプロセスは最初にディスクを読み取りますか? 実際には、そうではありません。パフォーマンスを向上させ、ディスク IO を削減するために、MySQL は多くの最適化を行っています。データ ページがバッファ プールに存在しない場合、書き込みバッファ (変更バッファ) を使用して、更新操作の具体的な実装原理については、別の記事で詳しく説明します。
「コントロール ブロックがフラッシュ リンク リストに追加されると、バックグラウンド スレッドがフラッシュ リンク リストを横断して、ダーティ ページをディスクに書き込むことができます。 」
3.5 バッファプールデータページ
3 種類のリンク リストとその使用方法について学習したので、 「実際には、データを管理するためにバッファ プールには 3 種類のデータ ページとリンク リストがある」と要約できます。
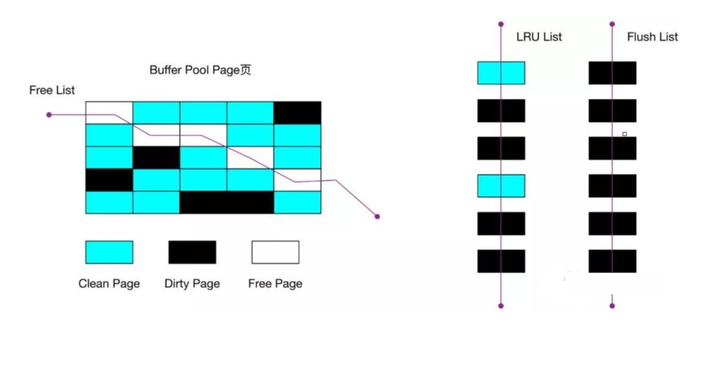
- フリー ページは、このデータ ページが使用されずに空であり、その制御ブロックがフリー リンク リストに配置されていることを意味します。
- 「クリーン ページ」とは、このデータ ページが使用され、データがキャッシュされ、その制御ブロックが LRU リンク リストに配置されていることを意味します。
- 「ダーティ ページ」とは、このデータ ページが [使用され] かつ [変更され] ており、データ ページ内のデータとディスク上のデータが一致していないことを意味します。ダーティ ページのデータがディスクに書き込まれ、メモリ データがディスク データと一致すると、そのページはクリーン ページになります。「ダーティ ページの制御ブロックは、LRU リンク リストとフラッシュ リンク リストの両方に存在します。 」
Linux C/C++ バックエンド サーバー開発学習教材、教育ビデオ、学習ロードマップ (教材には、C/C++、Linux、golang テクノロジー、Nginx、ZeroMQ、MySQL、Redis、fastdfs、MongoDB、ZK、ストリーミング メディア、CDN、P2P、 K8S、Docker、TCP/IP、コルーチン、DPDK、ffmpeg など)、必要に応じて、ラーニング エクスチェンジ グループ 739729163 を追加して受信できます。