1. Python クローラーの概要
クローラーの実際的な要件は非常に厳しいです。クローラーは多くの場合、商用 Web サイトや政府 Web サイトのコンテンツをクロールする必要があり、これらの Web サイトはいつでも更新される可能性があります。さらに、ネットワーク上の理由や Web サイトのクローラー対策メカニズムもクローラー コードのデモンストレーションに干渉します。
1.1 クローラーの使用
Web クローラー: インターネット情報を一定のルールに従って自動的に巡回するプログラム。
まずお聞きしますが、今は「ビッグデータ時代」と言われていますが、そのデータはどこから来るのでしょうか?
企业产生的用户数据:百度指数、アリババ指数、新浪微博指数数据平台购买数据:大唐、国雲データ市場政府/机构公开的数据:中華人民共和国国家統計局のデータ、世界銀行の公的データ、および国連のデータ。数据管理咨询公司:マッキンゼー、アクセンチュア、アイリサーチ爬取网络数据: 必要なデータが市場で入手できない場合、または購入する気がない場合は、クローラー エンジニアを採用/なり、自分で生計を立てるという選択肢もあります。Lagou.com Python クローラー ジョブ
1.2 適用方向
1、2、1 検索エンジンをカスタマイズする
クローラーを学習すると
検索エンジンのクローラーの動作原理を深く理解したい、またはプライベート検索エンジンを開発したいと考えている友人もいますが、現時点ではクローラーを学ぶことが非常に必要です。簡単に言うと、クローラーの作成方法を学べば、クローラーを使用してインターネットから情報を自動的に収集し、それに応じて保存または処理できるようになります。特定の情報を取得する必要がある場合は、収集されたファイルから取得するだけで済みます。検索を実行するために、プライベート検索エンジンが実装されています。もちろん、情報をクローリングする方法、情報を保存する方法、単語をセグメント化する方法、相関関係を計算する方法などを設計する必要があります。クローラ技術は主に情報クローリングの問題を解決します。
1、2、2 SEO の最適化
多くの SEO 実践者にとって、クローラーを学習することで、検索エンジン クローラーの動作原理をより深く理解できるようになり、検索エンジンの最適化をより適切に実行できるようになります。検索エンジンの原理 明らかに、検索エンジンの最適化を実行するときに自分と敵を知り、すべての戦いで勝利できるように、検索エンジン クローラーの動作原理もマスターする必要があります。
1、2、3 データ分析
ビッグデータの時代では、データ分析を行うためにはまずデータソースが必要ですが、クローラーを学習することでより多くのデータソースを取得できるようになり、これらのデータソースを目的に応じて収集し、多くの無関係なデータを削除することができます。
在进行大数据分析或者进行数据挖掘的时候,数据源可以从某些提供数据统计的网站获得,也可以从某些文献或内部资料中获得,但是这些获得数据的方式,有时很难满足我们对数据的需求,而手动从互联网中去寻找这些数据,则耗费的精力过大。此时就可以利用爬虫技术,自动地从互联网中获取我们感兴趣的数据内容,并将这些数据内容爬取回来,作为我们的数据源,从而进行更深层次的数据分析,并获得更多有价值的信息。
1、2、4 仕事を探しています
雇用の観点から見ると
有些朋友学习爬虫可能为了就业或者跳槽。从这个角度来说,爬虫工程师方向是不错的选择之一,因为目前爬虫工程师的需求越来越大,而能够胜任这方面岗位的人员较少,所以属于一个比较紧缺的职业方向,并且随着大数据时代的来临,爬虫技术的应用将越来越广泛,在未来会拥有很好的发展空间。
1.3 Python クローラーを使用する理由
- PHP: PHP は世界で最高の言語です。!しかし、これを行うために生まれてきたわけではなく、マルチスレッドや非同期処理のサポートがあまり良くなく、同時処理能力も弱いです。クローラーは、速度と効率に関して比較的高い要件を備えたツール プログラムです。PHPは効率が良くなったと言われていますが、まだまだコミュニティ環境がPythonに追いついていません。
- Java: エコシステムは非常に完全であり、Python クローラーの最大の競合相手です。しかし、Java 言語自体は扱いにくく、コード量も膨大です。リファクタリングのコストは比較的高く、変更を加えるとコードに多数の変更が発生します。クローラーは多くの場合、コレクション コードを変更する必要があります。結局のところ、人生は短いのです。。。。
- C/C++: 動作効率は比類のないものです。しかし、学習と開発のコストは高くつきます。小さなクローラー プログラムを作成するには半日以上かかる場合があります。一言で要約すると、C++ を使用してクローラー プログラムを開発しないのはなぜでしょうか。毛が抜けて人が死ぬからです。
- Python: 美しい構文、簡潔なコード、高い開発効率、および多くのモジュールをサポートします。関連する HTTP 要求モジュールと HTML 解析モジュールは非常に豊富です。クローラーの開発を非常に簡単にする Scrapy および Scrapy-redis フレームワークもあります。また、リソースが非常に豊富で、Python は非同期もサポートしており、非同期ネットワーク プログラミングにも非常に適しています。将来の方向性は、クローラ プログラムに非常に適した非同期ネットワーク プログラミングです。!
1、3、1 Python クローラー
Python を使用して Baidu URL をクロールするクローラーを作成する
2. 爬虫類
2.1 クローラーの分類
2、1、1 通用爬虫
一般的な Web クローラーは、検索エンジン クロール システム (Baidu、Google、Sogou など) の重要な部分です。主な目的は、インターネット上の Web ページをローカル コンピュータにダウンロードして、インターネット コンテンツのミラー バックアップを作成することです。検索エンジンに検索サポートを提供します。
検索エンジンの仕組み:
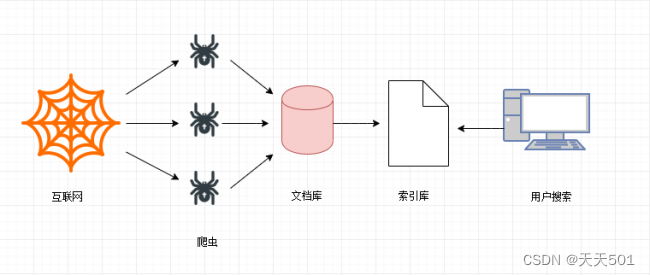
- ステップ 1: Web ページをクロールする
検索エンジンは、何千もの Web サイトからデータをクロールします。
- ステップ 2: データストレージ
検索エンジンは、クローラーを通じて Web ページをクロールし、データを元のページ データベース (つまり、ドキュメント ライブラリ) に保存します。ページ データは、ユーザーのブラウザで取得した HTML とまったく同じです。
- ステップ 3: 検索サービスと Web サイトのランキングを提供する
検索エンジンは、クローラーによってクロールバックされたページに対して、中国語の単語の分割、ノイズの除去、インデックス処理などのさまざまな前処理ステップを実行します。
検索エンジンは情報を整理して処理した後、ユーザーにキーワード検索サービスを提供し、関連情報をユーザーに表示します。表示する際にランク付けされます。
検索エンジンの制限:
-
検索エンジンは、特定の詳細な情報ではなく、Web ページ全体をクロールします。
-
検索エンジンは、顧客のニーズに合わせた検索結果を提供できません。
2、1、2 クローラーに焦点を当てる
このような一般的なクローラの状況に対応して、集中型クローラ技術が広く利用されています。集中型クローラーは、「特定の主題のニーズに合わせた」Web クローラー プログラムです。一般的な検索エンジン クローラーとの違いは、集中型クローラーは、Web ページをクロールするときにコンテンツを処理およびフィルターし、クロールのみが確実に行われるようにすることです。ニーズに関連した Web ページ データ。
コースの次の部分では、クローラーに焦点を当てます。
2.2ロボットプロトコル
ロボットは、Web サイトとクローラーの間の合意です。シンプルで直接的な txt 形式のテキストを使用して、対応するクローラーに許可されたアクセス許可を伝えます。つまり、robots.txt は、Web サイトにアクセスするときに最初に表示されるファイルです。検索エンジン。検索スパイダーがサイトを訪問すると、まずサイトのルート ディレクトリに robots.txt が存在するかどうかを確認し、存在する場合はファイルの内容に基づいてアクセス範囲を決定します。存在しません、すべて 検索スパイダーは、パスワードで保護されていない Web サイト上のすべてのページにアクセスできます。--百度百科事典
ロボット プロトコルは、クローラー プロトコル、ロボット プロトコルなどとも呼ばれます。正式名は「ロボット排除プロトコル」です。Web サイトはロボット プロトコルを使用して、どのページがクロール可能でどのページがクロールできないかを検索エンジンに伝えます。例:
タオバオ: https://www.taobao.com/robots.txt
百度: https://www.baidu.com/robots.txt
3. リクエストとレスポンス
HTTP 通信は、クライアント要求メッセージとサーバー応答メッセージの 2 つの部分で構成されます。
ブラウザが HTTP リクエストを送信するプロセス:
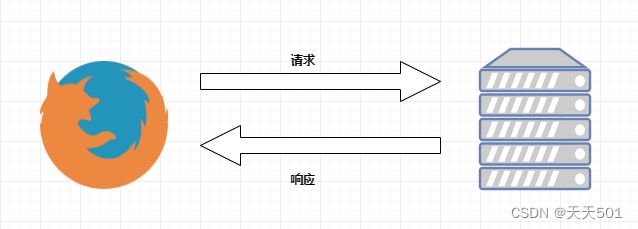
- ブラウザに URL https://www.baidu.com を入力すると、ブラウザは https://www.baidu.com の HTML ファイルを取得するためのリクエスト リクエストを送信し、サーバーはレスポンス ファイル オブジェクトを に送り返します。ブラウザ。
- ブラウザは応答内の HTML を分析し、画像ファイル、CSS ファイル、JS ファイルなど、他の多くのファイルを参照していることを発見します。ブラウザは自動的にリクエストを再度送信して、画像、CSS ファイル、または JS ファイルを取得します。
- すべてのファイルが正常にダウンロードされると、Web ページが HTML 構文構造に従って完全に表示されます。
実際、クローラー技術を学習してデータをクロールするとき、それはサーバーにデータを要求し、サーバーの応答データを取得するプロセスでもあります。
4. クロム開発者ツール
異なる Web サイトをクロールする場合、各 Web サイトのページの実装は異なるため、各 Web サイトを分析する必要があります。一般的な分析方法はありますか? クロールと分析に関する私の「ルーチン」を共有しましょう。特定の Web サイトで、ページの分析とデータのクロールに最もよく使用するツールはChrome デベロッパー ツールです。
Chrome 开发者工具是一套内置于 Google Chrome 中的 Web 开发和调试工具,可用来对网站进行迭代、调试和分析。因为国内很多浏览器内核都是基于 Chrome 内核,所以国产浏览器也带有这个功能。例如:UC 浏览器、QQ 浏览器、360 浏览器等。
次に、Chrome デベロッパー ツールの優れた機能をいくつか見てみましょう。
4.1 要素パネル(要素)
[要素] パネルを使用して、キャプチャしたいページ レンダリング コンテンツが配置されているタグ、使用する CSS 属性 (例: class="middle") などを表示できます。たとえば、Zhihu ホームページの動的なタイトルをキャプチャしたい場合は、ページを右クリックして [検査] を選択し、Chrome デベロッパー ツールの要素パネルに入ります。
この方法により、ページ上の DOM ノードをすばやく見つけて、関連する解析ステートメントを抽出できます。マウスをノードに移動し、マウスを右クリックして「コピー」を選択すると、Xpath や CSS セレクターなどのコンテンツ解析ライブラリの解析ステートメントをすばやくコピーできます。
4.2 コンソールパネル
コンソール パネル (Console) は、JS および DOM オブジェクトの情報を表示するために使用される別のウィンドウです。
クローラーコースの js 復号トピックでは、コンソール関数を使用して js コードをデバッグおよび実行します。
4.3 リソースパネル(ソース)
現在の Web ページのすべてのソース ファイルは、[リソース パネル (ソース)] ページで表示できます。
左側の列では、ソース ファイルがツリー構造で表示されていることがわかります。
中央の列のこの場所を使用して、JS コードをデバッグします。
右側にはブレークポイントのデバッグ リボンがあります。
以降のjs復号化ではリソースパネルの機能を利用します。
4.4 ネットワークパネル(ネットワーク)
[ネットワーク] パネルには、時間のかかる詳細なデータ、HTTP 要求および応答ヘッダー、Cookie など、ページ上のすべてのネットワーク操作に関する情報が記録されます。これは通常パケット キャプチャと呼ばれるものです。
4、4、1 ツールバー
ネットワークログの記録を停止する
デフォルトでは、開発者ツールがオンになっている限り、すべてのネットワーク リクエストが記録され、もちろん、記録は [ネットワーク] パネルに表示されます。赤はオン、灰色はオフを意味します。
クリア
すべてのデータをクリアします。再分析するたびに、以前のデータをクリアする必要があります。
フィルター
パケットフィルター。赤は開いていることを意味し、青は閉じていることを意味します。
Ajax を使用して開始された非同期リクエスト、写真、ビデオなどをフィルタリングするなど、一部の HTTP リクエストをフィルタリングするためによく使用されます。
最大のペインは「リクエスト テーブル」と呼ばれ、取得されたすべての HTTP リクエストがリストされます。デフォルトでは、このテーブルは古いリソースが先頭にくるように時系列に並べ替えられます。リソースの名前をクリックすると、詳細情報が表示されます。
リクエストテーブルパラメータ:
- **all:*すべてのリクエストデータ (画像、ビデオ、オーディオ、JS コード、CSS コード)
- **XHR: **XMLHttpRequest の略称は、ajax テクノロジーの中核であり、頻繁に分析されるコンテンツを動的に読み込みます。
- **CSS: **css スタイル ファイル
- **JS: **JavaScript ファイル。js 復号化によってよく分析されるページです。
- Img:画像画像ファイル
- フォント:フォントファイル(フォント反転)
- DOC:文書、文書の内容
- **WS: **WebSocket、Web 側のソケット データ通信。通常、一部のリアルタイム更新データに使用されます。
- **マニフェスト:** マニフェストを通じてキャッシュされたリソースを表示します。js ライブラリ ファイルなどの多くの情報を含めると、ファイルのアドレス、サイズ、
タイプが表示されます。
検索
検索ボックスでは、「ALL」に表示されるコンテンツを直接検索できます。一般的に使用されるデータの取得と JS の復号化
ログを保存する
ログを記録してください。複数のページにジャンプするコンテンツを分析する場合は、必ずチェックしてください。そうしないと、ページ上で新しいジャンプが発生したときに、すべての履歴データがクリアされます。ログを保存します。クローラーを実行するときにチェックする必要があります
キャッシュを無効にする
JavaScript ファイルと CSS ファイルのキャッシュをクリアして、最新のものを取得します。
データの URL を非表示にする
dataurl を非表示にするために使用されます。では、dataurl とは何ですか? 通常の img タグの従来の src 属性はリモート サーバー上のリソースを指定するため、ブラウザは外部リソースごとにプル リソース リクエストをサーバーに送信する必要があります。データ URL テクノロジーは、画像データを Base64 文字列形式でページに埋め込み、HTML と統合します。
Cookieをブロックしました
ブロックされた応答 Cookie を持つリクエストのみを表示します。このオプションはチェックしないでください。
ブロックされたリクエスト
ブロックされたリクエストのみを表示します。このオプションはチェックしないでください。
サードパーティのリクエスト
ページのソースとは異なるソースからのリクエストのみを表示します。このオプションはチェックしないでください。
4.5 リクエストの詳細:
リクエスト
ヘッダー: HTTP リクエストを表示するヘッダー。これにより、リクエスト メソッド、送信されるリクエスト パラメーターなどが確認できます。
-
一般的な
Request url : 実際にリクエストされた URL
Request Method : リクエストメソッド
Status Code : ステータスコード、成功時は 200 -
応答ヘッダー
サーバーによって更新された最新の Cookie データなど、サーバーが戻ったときに設定される一部のデータは、ここで変更されます。
-
リクエストヘッダー
リクエストボディ、データをリクエストできない理由は通常ここにあります。アンチピックリングもリクエスト本文のデータです。
Accept : サーバーが受信したデータ形式 (通常は無視されます)
Accept-Encoding : サーバーが受信したエンコーディング (通常は無視されます)
Accept-Language : サーバーが受信した言語 (通常無視されます)
Connection : 接続を維持します (通常無視されます)
Cookies : ID 情報である Cookie 情報です。VIP リソースのクロールには ID 情報が必要です。
Host : 要求されたホスト アドレス
User-Agent : ユーザー ID エージェント。サーバーがユーザーの一般情報を決定します。
Sec-xxx-xxx : その他 役に立たない情報、または偽造の可能性があります。特定の状況の詳細な分析*
プレビュー
プレビューはリクエスト結果のプレビューです。これは通常、要求された画像を表示するために使用されますが、画像 Web サイトを取得する場合にはより強力です。
応答
レスポンスはリクエストによって返される結果です。一般的なコンテンツは、Web サイト全体のソース コードです。リクエストが非同期リクエストの場合、返される結果の内容は通常、Json テキスト データです。
ブラウザは動的に読み込まれるため、このデータはブラウザで表示される Web ページと一致しない可能性があります。
イニシエータ
リクエストの開始によって呼び出されるスタック
タイミング
リクエストとレスポンスのスケジュール
HTTP通信の課外展開
https://mp.weixin.qq.com/s/aSwXVrz47lAvQ4k0o4VcZg