2022-CVPR-ビデオ Swin トランスフォーマー
ビデオ スイング トランスフォーマー
まとめ
ビジョン分野では、CNN から Transformer へのモデリングの移行が見られ、純粋な Transformer アーキテクチャが主要なビデオ認識ベンチマークで最高の精度を達成しています。これらのビデオ モデルは、空間次元と時間次元の両方でブロックをグローバルに接続する Transformer レイヤー上に構築されます。この論文では、ビデオ トランスフォーマーにおけるローカル誘導バイアスを提唱します。これにより、自己注意をグローバルに計算できるようになり、時空間分解を使用した場合でも、以前の方法と比較して速度と精度のトレードオフが向上します。提案されたビデオ アーキテクチャの局所性は、Swin Transformer事前トレーニングされた画像モデルの力を活用し続けながら、それを画像ドメイン設計に適応させることによって実現されます。当社のアプローチは、アクション認識を含む幅広いビデオ認識ベンチマークで最先端の精度を達成します (Kinetics-400 では 84.9 トップ 1 の精度、Kinetics-600 では 85.9 トップ 1 の精度で、事前の約 20 分の 1 を削減) -トレーニング データと 3 倍小さいモデル サイズ)および時間モデリング(SomethingSomething v2 で 69.6 のトップ 1 精度)。
1 はじめに
畳み込みベースのバックボーン アーキテクチャは、コンピュータ ビジョンにおけるビジュアル モデリングを長い間支配してきました [14、18、22、24、32、33]。ただし、画像分類の現在のバックボーン アーキテクチャは、畳み込みニューラル ネットワーク (CNN) から Transformer [8、28、34] へモデリングの移行が進んでいます。この傾向は、標準の Transformer エンコーダ [38] を使用して、重複しない画像パッチ上の空間関係をグローバルにモデル化する Vision Transformer (ViT) [8、34] の導入から始まりました。画像に関する ViT の大きな成功は、ビデオ認識タスク用の Transformer ベースのアーキテクチャの研究につながりました[1、3]。
以前の畳み込みモデルでは、ビデオのバックボーン アーキテクチャは、タイムライン上のモデリングを拡張することによって、画像のバックボーン アーキテクチャから単純に適応されていました。たとえば、3D コンボリューション [35] は、オペレーター レベルでの関節の空間的および時間的モデリングのための 2D コンボリューションを直接拡張したものです。共同時空間モデリングは経済的ではなく、最適化も容易ではないため、より優れた速度と精度のトレードオフを達成するために、空間領域と時間領域の分解が提案されています [30、41]。Transformer ベースのビデオ認識の最初の試みでは、エンコーダの分解 [1] またはセルフアテンションの分解 [1、3] による分解方法も採用されました。これにより、パフォーマンスを大幅に低下させることなく、モデルのサイズが大幅に削減されることが示されています。
この論文では、ビデオ認識用の純粋な Transformer バックボーン アーキテクチャを提案し、その効率が因数分解モデルの効率を上回ることを発見しました。これは、ビデオ固有の時空間局所性を利用することによって行われます。つまり、時空間距離が互いに近いピクセルほど、相互に相関する可能性が高くなります。この特性により、完全な時空間的自己注意は、ローカルで計算された自己注意によってよく近似でき、その結果、計算量とモデル サイズが大幅に節約されます。
我々は、画像理解のための汎用視覚的バックボーンとして最近導入された Swin Transformer [28] の時空間適応を通じてこのアプローチを実装します。Swin Transformer は、空間的局所性と誘導バイアスを組み合わせて、レベルと並進の不変性を実現します。Video Swin Transformer と呼ばれる私たちのモデルは、元の Swin Transformer の階層構造に厳密に従いますが、ローカル アテンションの計算範囲を空間領域のみから時空間領域に拡張します。ローカル アテンションは重なり合わないウィンドウ上で計算されるため、元の Swin Transformer のシフト ウィンドウ メカニズムも時空間入力を処理するために再定式化されます。
私たちのアーキテクチャは Swin Transformer から適応されているため、大規模な画像データセットで事前トレーニングされた強力なモデルを使用して簡単に初期化できます。ImageNet-21K で事前トレーニングされたモデルを使用すると、興味深いことに、バックボーン アーキテクチャの学習速度は、ランダムに初期化されたヘッドの学習速度よりも小さくする必要があることがわかります(たとえば、0.1 倍)。その結果、バックボーンは新しいビデオ入力に適応するにつれて、事前トレーニングされたパラメータとデータを徐々に忘れていき、一般化が向上します。この観察は、事前トレーニングされた重みをより効果的に利用する方法に関するさらなる研究への道を示しています。
提案手法は、Kinetics400/Kinetics-600 での動作認識ビデオ認識タスクと、SomethingSomething v2 (略称 SSv2) での時間モデリングで優れたパフォーマンスを示します。ビデオアクション認識については、Kinetics-400 で 84.9% のトップ 1 精度、Kinetics-600 で 85.9% のトップ 1 精度は、以前の最良の結果 (ViViT [1]) より +0.1 ポイントわずかに高く、モデル サイズが小さくなりました ( Swin-L のパラメータは 2 億、ViViT-H のパラメータは 6 億 4,750 万)、事前トレーニング データ セットは小規模です(ImageNet-21K 対 JFT-300M)。SSv2 での時間モデリングでは、69.6% というトップ 1 の精度を達成し、以前の最先端技術 (MViT [9]) よりも +0.9 ポイント向上しました。
2.関連作品
コンピュータ ビジョンでは、畳み込みネットワークが長い間標準的なバックボーン アーキテクチャでした。3D モデリングに関しては、C3D [35] は 3D 畳み込みを備えた 11 層のディープ ネットワークを設計する先駆的な研究です。I3D [5] の研究では、Inception V1 の 2D 畳み込みを 3D 畳み込みにインフレートし、ImageNet で事前にトレーニングされた重みで初期化すると、大規模な Kinetics データセットで良好な結果が得られることが示されています。P3D [30]、S3D [41]、および R(2+1)D [37] では、もつれを解いた空間的および時間的畳み込みが、元の 3D 畳み込みよりも優れた速度と精度のトレードオフを達成することが判明しました。畳み込みベースの方法の可能性は、畳み込み演算子の小さな受容野によって制限されます。自己注意メカニズムを使用すると、より少ないパラメータとより低い計算コストで受容野を拡張でき、ビジョン トランスフォーマーのビデオ認識のパフォーマンスを向上させることができます。
Self-attention / Transformers は CNN を補完します。NLNet [40] は、視覚認識タスクのピクセルレベルの長距離依存性をモデル化するために自己注意を採用した最初の研究です。GCNet [4] は、NLNet の精度の向上は主にそのグローバル コンテキスト モデリングによるものであると観察しており、そのため、NL ブロックを、NLNet と同等のパフォーマンスを備えながらもパラメーターと計算量が少ない軽量のグローバル コンテキスト ブロックに簡素化します。対照的に、DNL [43] は、共有されたグローバル コンテキストを維持しながら、異なるピクセルに対して異なるコンテキストを学習できる分解されたエンタングルメント設計を通じて、この劣化問題を軽減しようとしています。これらすべてのメソッドは、長距離の依存関係をモデル化するための CNN に補完的なコンポーネントを提供します。私たちの研究では、純粋な Transformer ベースのメソッドが自己注意の力をより完全に捉え、優れたパフォーマンスにつながることを示しています。
ビジョントランスフォーマー。CNN から Transformers へのコンピューター ビジョン バックボーン アーキテクチャの変換は、最近 Vision Transformer (ViT) [8、34] によって始まりました。この先駆的な研究は、その有用性を向上させることを目的としたその後の研究につながりました。DeiT [34] はいくつかのトレーニング戦略を統合しており、ViT がより小さな ImageNet1K データセットを効率的に使用できるようにしています。Swin Transformer [28] はさらに、局所性、階層性、および変換の不変性に対する帰納的バイアスを導入し、さまざまな画像認識タスクの一般的なバックボーンとして機能できるようにします。
画像 Transformers の大成功により、ビデオベースの認識タスクのための Transformer ベースのアーキテクチャの研究が行われるようになりました [1、3、9、25、29]。VTN [29] は、事前トレーニングされた ViT の上に時間的注意エンコーダを追加することを提案しています。これにより、ビデオアクション認識で優れたパフォーマンスが得られます。TimeSformer [3] は、時空間的注意の 5 つの異なるバリエーションを研究し、強力な速度と精度のトレードオフを達成するために因数分解された時空間的注意を提案しています。ViViT [1] は、事前トレーニングされた ViT モデルの空間的および時間的注意の 4 つの分解設計を検証し、Kinetics データセットで最先端のパフォーマンスを達成する VTN のようなアーキテクチャを提案しています。MViT [9] は、ゼロからトレーニングされたビデオ認識用のマルチスケールのビジュアル Transformer であり、計算量を削減するために時空間モデリングに注目することで SSv2 上で最先端の結果を達成します。これらの研究はすべて、グローバルな自己注意モジュールに基づいています。この論文では、最初に時空間局所性を研究し、次に時空間局所性バイアスを持つ Video Swin Transformer がさまざまなビデオ認識タスクにおいて他のすべての Visual Transformer よりも優れていることを実験的に実証します。
3.ビデオスイングトランスフォーマー
3.1. 全体的なアーキテクチャ
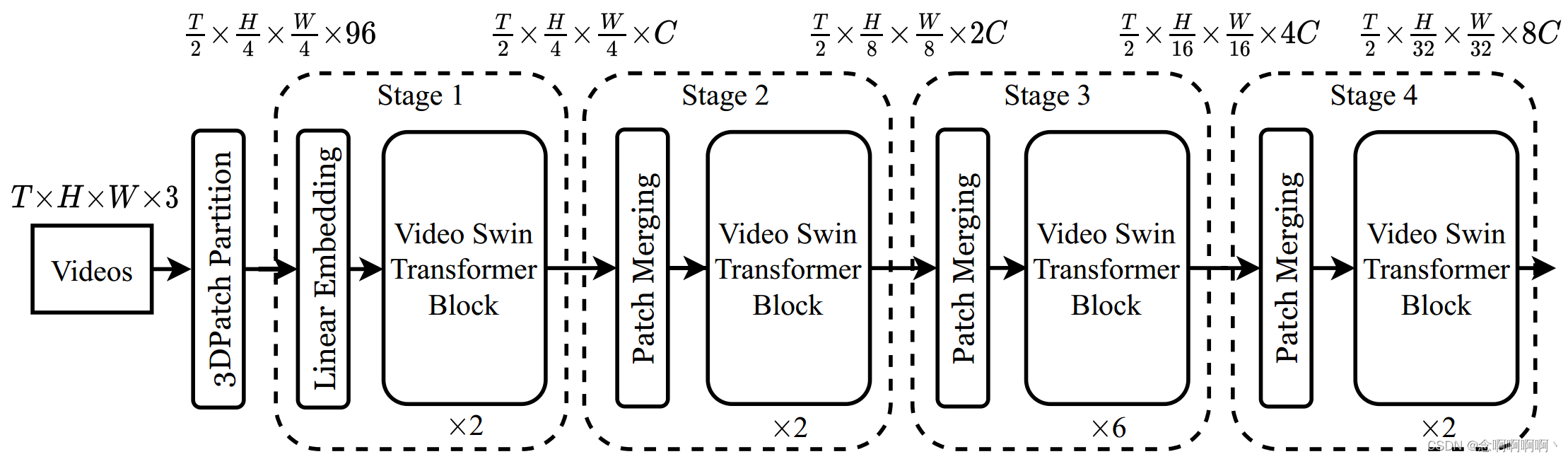
提案されているビデオ Swin Transformer の全体的なアーキテクチャを図 2 に示します。図 2 には、その小型バージョン (Swin-T) が示されています。入力ビデオのサイズは、T × H × W × 3 T\times H\times W\times3として定義されます。T×H×W×3 、 TT著Tフレームで構成され、各フレームにはH × W × 3 H\times W\times3 がH×W×3ピクセル。Video Swin Transformer では、サイズ 2×4×4×3 の各 3D ブロックをトークンとして扱います。したがって、3D パッチ分割層はT 2 × H 4 × W 4 \frac{T}{2}\times\frac{H}{4}\times\frac{W}{4} を取得2T×4H×4W3D トークン、各パッチ/トークンは 96 次元の特徴で構成されます。次に、線形埋め込みレイヤーを適用して、各トークンの特徴をCCに投影します。C は任意の次元を表します。
既存の手法 [11、12、30、41] に従って、時間次元に沿ったダウンサンプリングは行いません。これにより、元の Swin Transformer [28] の階層構造に厳密に従うことができます。Swin Transformer は 4 つのステージで構成され、各ステージのパッチ マージ層で 2 倍の空間ダウンサンプリングを実行します。パッチ マージ レイヤーは、空間的に隣接する 2×2 パッチの各セットのフィーチャを連結し、線形レイヤーを適用して、連結されたフィーチャをその寸法の半分に投影します。たとえば、第 2 段階の線形層は、各トークンの 4C 次元の特徴を 2C 次元に投影します。
アーキテクチャの主なコンポーネントは Video Swin Transformer ブロックで、標準の Transformer 層のマルチヘッド セルフ アテンション (MSA) モジュールを 3D シフト ウィンドウ ベースのマルチヘッド セルフ アテンション モジュール (導入) に置き換えることによって構築されます。セクション 3.2 を参照)、他のコンポーネントは変更しないでください。具体的には、Video Transformer ブロックは、3D シフト ウィンドウ ベースの MSA モジュールとフィードフォワード ネットワーク、つまり中央に GELU 非線形性を備えた 2 層 MLP で構成されます。レイヤ正規化 (LN) は各 MSA モジュールと FFN の前に適用され、残りの接続は各モジュールの後に適用されます。Video Swin Transformer ブロックの計算式は式 (1) で与えられます。
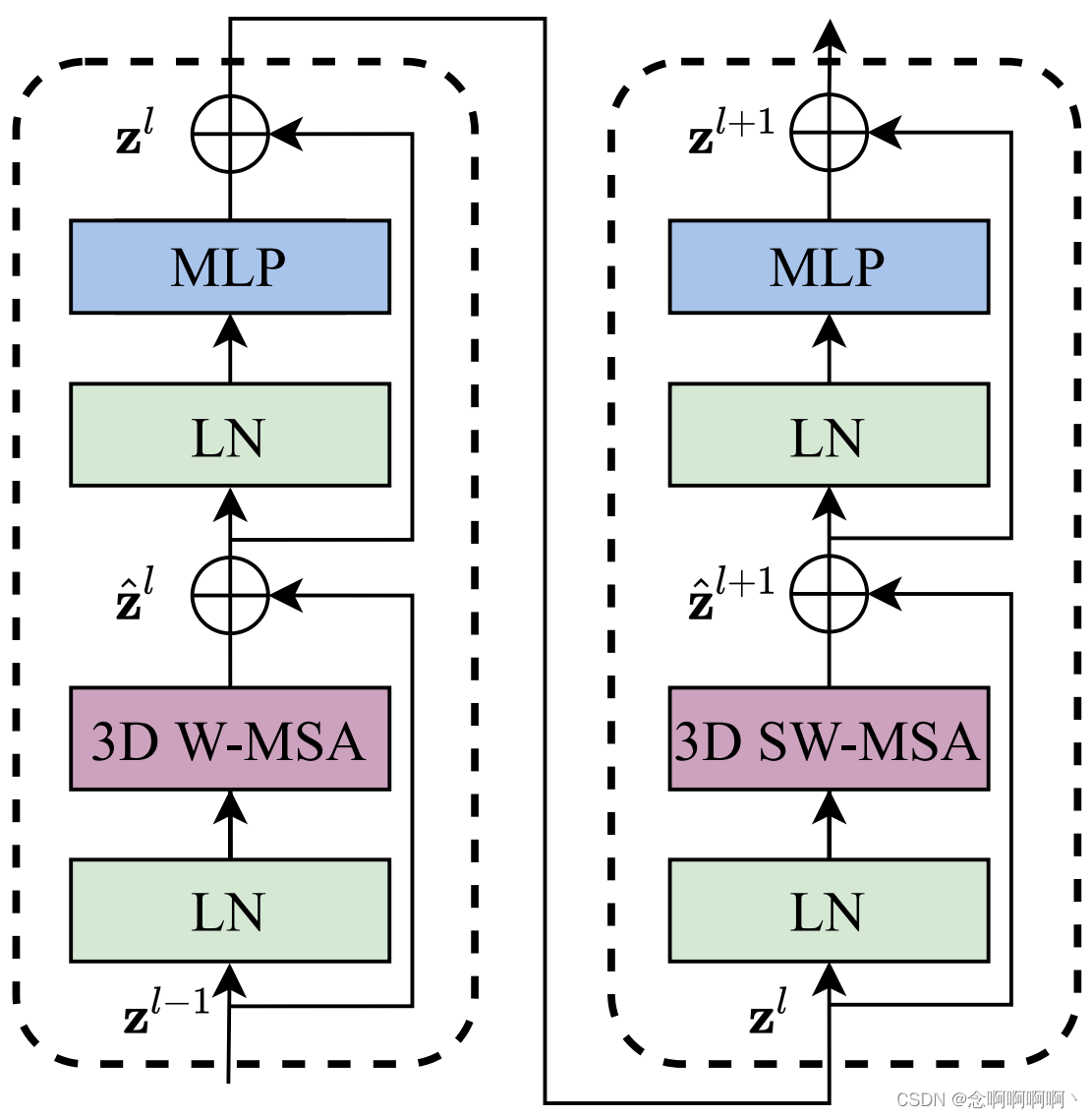
3.2. 3D 変換ウィンドウに基づく MSA モジュール
動画には時間的な次元もあるため 、画像と比較して、動画を表現するにはより多くの入力トークンが必要になります。したがって、グローバル セルフ アテンション モジュールは、膨大な計算コストとメモリ コストが発生するため、ビデオ タスクには適していません。ここでは、Swin Transformer に従って、ローカル誘導バイアスをセルフ アテンション モジュールに導入します。これは、後にビデオ認識に効果的であることが示されました。
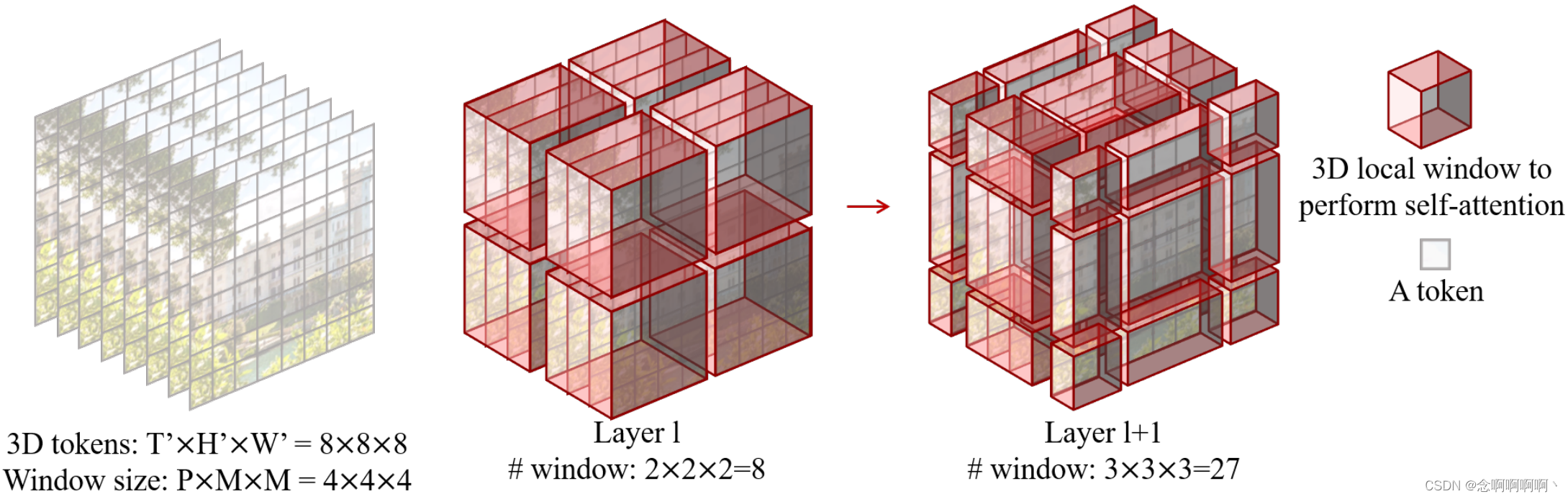
重なり合わない 3D ウィンドウでのマルチヘッドセルフアテンション。オーバーラップしない各 2D ウィンドウのマルチヘッド セルフ アテンション (MSA) メカニズムは、画像認識に効果的かつ効率的であることが証明されています。ここでは、ビデオ入力を処理するためにこの設計を直接拡張します。T ' × H ' × W ' T^\prime\times H^\prime\times W^\primeで与えられます。T』×H』×W' 3D マーカーとP × M × MP\times M\times MP×M×ビデオ入力を重複しない方法で均等に分割するように配置されたMの 3D ウィンドウ サイズで構成されるビデオ。つまり、入力トークンは⌈ T ′ P ⌉ × ⌈ H ′ M ⌉ × ⌈ W ′ M ⌉ \left\lceil\frac{T^\prime}{P}\right\rceil\times\left\ に分割されます。 lceil\frac{H^\prime}{M}\right\rceil\times\left\lceil\frac{W^\prime}{M}\right\rceil⌈PT「⌉×⌈MH「⌉×⌈MW「⌉オーバーラップしない 3D ウィンドウ。たとえば、図 3 に示すように、8 × 8 × 8 の場合、8×8×88×8×8トークンサイズと4×4×4 4×4×44×4×ウィンドウ サイズ4 、 llレイヤーlのウィンドウの数は2 × 2 × 2 = 8 2×2×2=82×2×2=8.そして、マルチヘッドセルフアテンションが各 3D ウィンドウで実行されます。
3Dシフトウィンドウ。マルチヘッド セルフ アテンション メカニズムは、重なり合わない各 3D ウィンドウに適用されるため、異なるウィンドウ間の接続が不足し、アーキテクチャの表現能力が制限される可能性があります。したがって、重複しないウィンドウに基づいてセルフ アテンションの効率的な計算を維持しながら、クロスウィンドウ接続を導入することを目的として、Swin Transformer の移動 2D ウィンドウ メカニズムを 3D ウィンドウに拡張します。
入力 3D トークンの数がT ' × H ' × W ' T^\prime\times H^\prime\times W^\prime であると仮定します。T』×H』×W'、各 3D ウィンドウのサイズはP × M × MP\times M\times MP×M×M、連続する 2 つの層の場合、最初の層のセルフアテンション モジュールは従来のウィンドウ分割戦略を使用して、⌈ T ′ P ⌉ × ⌈ H ′ M ⌉ × ⌈ W ′ M ⌉ \left\lceil\frac{ T ^\prime}{P}\right\rceil\times\left\lceil\frac{H^\prime}{M}\right\rceil\times\left\lceil\frac{W^\prime}{M} \右\rceil⌈PT「⌉×⌈MH「⌉×⌈MW「⌉オーバーラップしない 3D ウィンドウ。第 2 層のセルフ アテンション モジュールでは、ウィンドウ パーティションの構成が時間軸、高さ、幅の軸に沿って ( P 2 , M 2 , M 2 ) \ left(\frac{P}{2},\ によって移動されます) \frac{M}{2}、\ \frac{M}{2}\right)(2P、 2M、 2M)トークン。
図 3 の例を使用してこれを説明します。入力サイズは8 × 8 × 8 8×8×88×8×8、ウィンドウ サイズは4 × 4 × 4 4×4×44×4×4.有料道路l層は通常のウィンドウ分割を採用し、ll層lのウィンドウの数は2 × 2 × 2 = 8 2×2×2=82×2×2=8.l + 1の場合l+1私+ウィンドウの移動に伴うレベル1 ( P 2 , M 2 , M 2 ) = ( 2 , 2 , 2 ) \left(\frac{P}{2},\ \frac{M}{2},\ \frac {M}{2}\right)=\left(2,\ 2,\ 2\right)(2P、 2M、 2M)=( 2 、 2 、 2 )マーカーの場合、ウィンドウの数は3 × 3 × 3 = 27 3×3×3=27 に3×3×3=27.ウィンドウの数は増加しましたが、[28] のシフト構成の効率的なバッチ計算に従うことができるため、最終的に計算されたウィンドウの数は依然として8 88。
移位窗口分区この方法 を使用すると、2 つの連続する Video Swin Transformer ブロックは次のように計算されます。
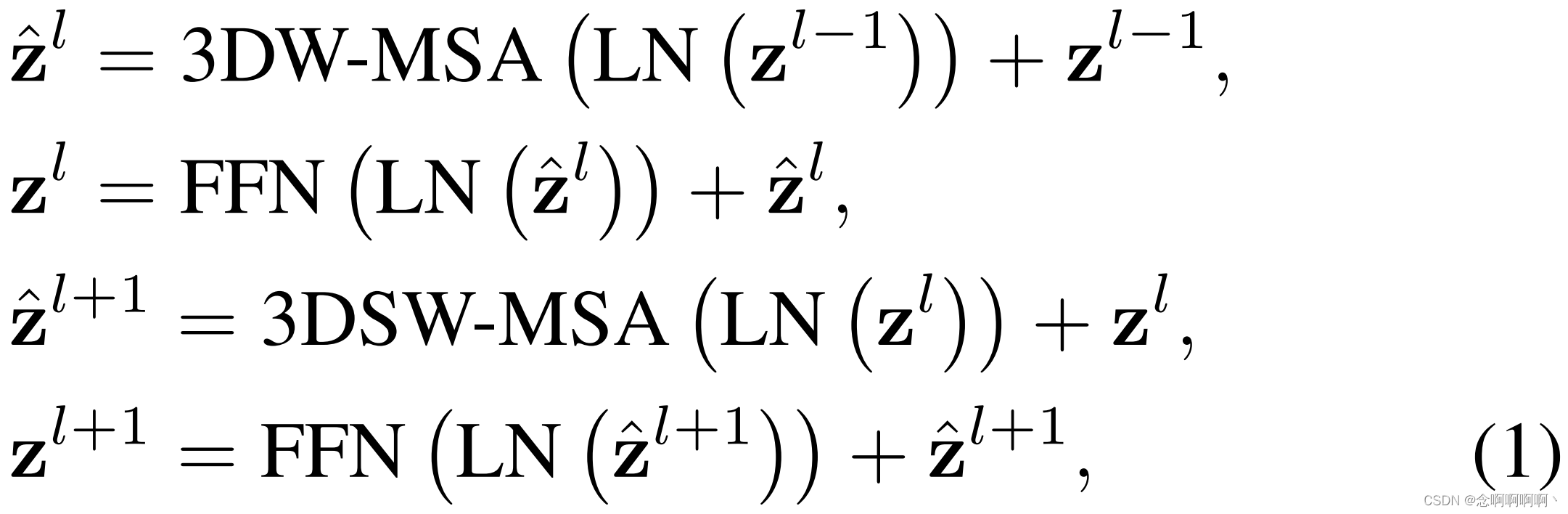
その中z ^ l {\hat{\mathbf{z}}}^lz^l和zl \mathbf{z}^lzlはそれぞれブロックlll の3D(S)WMSA モジュールと FFN モジュールの出力機能、3DW-MSA と 3DSW-MSA はそれぞれ、従来のウィンドウ分割テーブル構成とシフトされたウィンドウ分割テーブル構成を使用した 3D ウィンドウに基づくマルチヘッドセルフアテンションを表します。
画像認識 [28] と同様に、この 3D シフト ウィンドウは、前の層の隣接する重複しない 3D ウィンドウ間の接続を導入します。これは、Kinetics 400/600 でのアクション認識や SSv2 での時間モデリングなど、いくつかのビデオ認識タスクで有効であることが後に示されます。
3D相対位置ずれ。これまでの多くの研究 [2、16、17、31] では、自己注意の計算に各頭部の相対位置バイアスを含めることが有利であることが示されています。したがって、次の各ヘッドの 3 次元相対位置偏差 B ∈ RP 2 × M 2 × M 2 B\in\mathbb{R}^{P^2\times M^2\times M^2} を導入します [28 ]B∈RP2 ×M2 ×M2のための
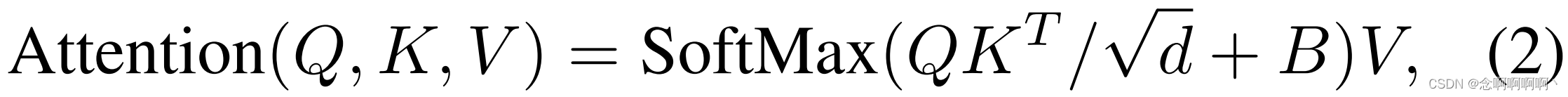
ここでQ , K , V ∈ RPM 2 × d Q,\ K,\ V\in\mathbb{R}^{PM^2\times d}質問、 K 、 V∈R午後_2 ×dはクエリ、キー、値の行列、d はクエリと主要な特徴の次元、PM2 は 3D ウィンドウ内のマーカーの数です。各軸に沿った相対位置は[ − P + 1 , P − 1 ] \left[-P+1,\ P-1\right][ − P+1 、 P−1 ] (時間) または[ − M + 1 , M − 1 ] \left[-M+1,\ M-1\right][ − M+1 、 M−1 ] (高さまたは幅) の場合、より小さいサイズのバイアス行列B ^ ∈ R ( 2 P − 1 ) × ( 2 M − 1 ) × ( 2 M − 1 ) \hat{ B}\in\mathbb{R }^{\left(2P-1\right)\times\left(2M-1\right)\times\left(2M-1\right)}B^∈R( 2 P − 1 ) × ( 2 M − 1 ) × ( 2 M − 1 )、BBBの値はB ^ \hat{B}B^。
3.3. 構造変数
[28] に続いて、 Video Swin Transformer の 4 つの異なるバージョン を紹介しました。これらのモデル バリアントのアーキテクチャ上のハイパーパラメータは次のとおりです。
- Swin-T:C=96 C=96C=96、層の数= { 2 , 2 , 6 , 2 } =\left\{2,\ 2,\ 6,\ 2\right\}={ 2 、 2 、 6 、 2 }
- Swin-S:C=96 C=96C=96、層の数= { 2 , 2 , 18 , 2 } =\left\{2,\ 2,\ 18,\ 2\right\}={ 2 、 2 、 18 、 2 }
- Swin-B:C=128 C=128C=128、層の数= { 2 , 2 , 18 , 2 } =\left\{2,\ 2,\ 18,\ 2\right\}={ 2 、 2 、 18 、 2 }
- Swin-L:C=192 C=192C=192、層の数= { 2 , 2 , 18 , 2 } =\left\{2,\ 2,\ 18,\ 2\right\}={ 2 、 2 、 18 、 2 }
ここでCCCは1段目の隠れ層のチャネル数を表します。これら 4 つのバージョンは、基本モデルのサイズと計算量のそれぞれ約 0.25 倍、0.5 倍、1 倍、および 2 倍です。デフォルトでは、ウィンドウ サイズはP=8 P=8P=8およびM = 7 M=7M=7.各ヘッダーのクエリ次元はd = 32 d=32d=32 では、各 MLP の拡張層はα = 4 \alpha=4ある=4。
3.4. 事前トレーニング済みモデルからの初期化
私たちのアーキテクチャは Swin Transformer [28] から適応されているため、私たちのモデルは大規模なデータセット上の強力な事前トレーニング済みモデルによって初期化できます。オリジナルの Swin Transformer と比較すると、Video Swin Transformer の 2 つの構成ブロックのみが形状が異なります。最初の段階の線形埋め込み層と、Video Swin Transformer ブロックの相対位置バイアスです。
私たちのモデルでは、入力トークンは時間次元 2 に拡張されるため、線形埋め込み層の形状は元の Swin の48 × Cから変化します。48×C は96 × C 96 × Cになります96×C._ _ ここでは、事前トレーニングされたモデルから重みを直接 2 回コピーし、出力の平均と分散を変更しないように行列全体に 0.5 を乗算します。相対位置オフセット行列の形状は( 2 P − 1 , 2 M − 1 , 2 M − 1 ) (2P − 1, 2M − 1 , 2M − 1) です。( 2P _−1 、2M_ _−1 、2M_ _−1 )ですが、元の Swin では( 2 M − 1 , 2 M − 1 ) (2M−1, 2M−1)( 2M_ _−1 、2M_ _−1 )。各フレーム内で相対位置偏差を同じにするために、事前学習済みモデルの行列をコピーします2 P − 1 2P−12P _−( 2 P − 1 , 2 M − 1 , 2 M − 1 ) (2P−1, 2M−1, 2M−1) を得るのに1回( 2P _−1 、2M_ _−1 、2M_ _−1 )形状を初期化します。
4. 実験
4.1. 設定
データセット。人間の行動認識には、広く使用されている Kinetics [20] データセットの 2 つのバージョン、Kinetics400 と Kinetics-600 を使用します。Kinetics-400 (K400) は、400 の人間の行動カテゴリーにおける約 240,000 のトレーニング ビデオと 20,000 の検証ビデオで構成されています。Kinetics-600 (K600) は K400 の拡張であり、600 の人間のアクション カテゴリからの約 370,000 のトレーニング ビデオと 28.3,000 の検証ビデオが含まれています。時間モデリングには、174 カテゴリの 168.9K のトレーニング ビデオと 24.7K の検証ビデオが含まれる人気の SomethingSomething V2 (SSv2) [13] データセットを利用します。すべての方法について、当社は最先端の認識精度に従い、トップ 1 およびトップ 5 の認識精度を報告します。
実装の詳細。K400 および K600 の場合、コサイン減衰学習率スケジューラーと 2.5 エポックの線形ウォームアップを使用して、30 エポックに対して AdamW [21] オプティマイザーを採用します。バッチ サイズ 64 を使用します。バックボーンは事前トレーニングされたモデルから初期化され、ヘッドはランダムに初期化されるため、バックボーンの学習率を 0.1 倍するとパフォーマンスが向上することがわかります (表 7 を参照)。具体的には、ImageNet の事前トレーニング済みバックボーンとランダムに初期化されたヘッドの初期学習率は、それぞれ 3e-5 と 3e-4 に設定されます。特に明記されていない限り、すべてのモデル バリアントについて、タイム ストライド 2 および空間サイズ 224 × 224 を使用して、各フルレングスのビデオから 32 フレームのクリップをサンプリングし、16 × 56 × 56 の入力 3D トークンが生成されます。[28] 以降、より大きな確率的深さ [19] と重み減衰がより大きなモデルに使用されます (Swin-T、Swin-S、Swin-B ではそれぞれ 0.1、0.1、0.3 の確率的深さ)。 , 0.05 の重量減衰。推論のために、4 × 3 ビューを使用する [1] に従い、ビデオが時間次元で 4 つのクリップに均一にサンプリングされ、各クリップの短い空間エッジが 224 ピクセルにスケーリングされます。 × 224 クロップで長い空間軸をカバーします。最終スコアは、すべてのビューの平均スコアとして計算されます。スクラッチからトレーニングする実験では、[9] のコード ベースを採用し、その設定とハイパーパラメーターに従って、時間次元 8 で Swin を非常に小さくトレーニングします。テスト ビュー 5×1 での精度も報告します。
SSv2 の場合、60 エポックの長いトレーニングと 2.5 エポックの線形ウォームアップに AdamW [21] オプティマイザーを使用します。バッチサイズ、学習率、重み減衰はKineticsと同じです。[9] に続いて、ラベル スムージング、RandAugment [7]、ランダム消去 [44] などの強力な拡張機能を追加しました。また、比率 0.4 のランダムな深さを採用します [19]。[9] で行ったように、Kinetics-400 で事前トレーニングされたモデルを初期化として使用し、時間次元ウィンドウ サイズ 16 を使用します。推論のため、最終スコアは 1 × 3 ビューの平均スコアとして計算されます。
4.2. 最先端技術との比較
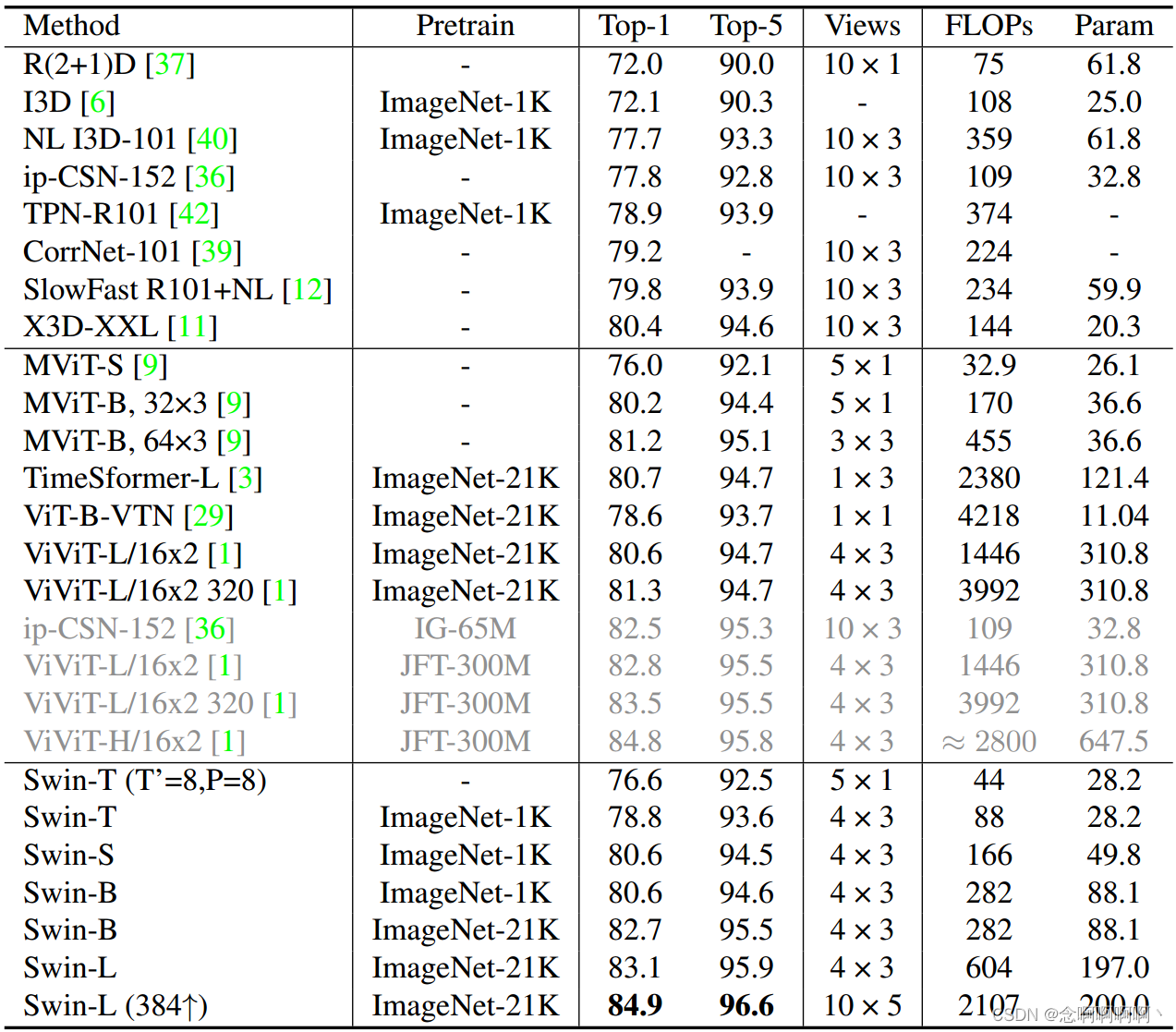
キネティクス-400。表 1 は、Kinetics-400 に基づく畳み込みおよびトランスフォーマーベースのバックボーンを含む、最先端のバックボーンとの比較を示しています。大規模な事前トレーニングを行わない最先端の Vision Transformer と比較すると、ImageNet-1K 事前トレーニングを備えた Swin-S は、同様のツールで最初からトレーニングされた MViT-B (32×3) [9] よりもわずかに優れたパフォーマンスを示します。計算コスト。最先端の ConvNet X3DXXL [11] と比較すると、Swin-S は同様の計算コストと少ない推論ビューの点でも優れています。SwinB の場合、ImageNet-21K の事前トレーニングは、ImageNet-1K で最初からトレーニングするよりも 2.1% の向上をもたらします。ImageNet21K の事前トレーニングにより、当社の Swin-L (384↑) は、同様の計算コストでトップ 1 の精度で ViViTL (320) を 3.6% 上回りました。ViViT-H (JFT-300M) よりもはるかに小さいデータセット (ImageNet-21K) で事前トレーニングされた当社の Swin-L (384↑) は、K400 上で 84.9% の最先端のパフォーマンスを達成します。
MViT [9] と公平に比較するために、ハイパーパラメーターを変更せずに SwinT を最初からトレーニングします。私たちの方法は、MViT [9] と比較して競合する結果を達成していますが、ゼロからのトレーニングには 200 エポックが必要であり、ブースティングを繰り返して 2 回繰り返される [15] ことに注意してください。これは、微調整セットアップよりも高価であり、トレーニング時間の約 13.3 倍です。
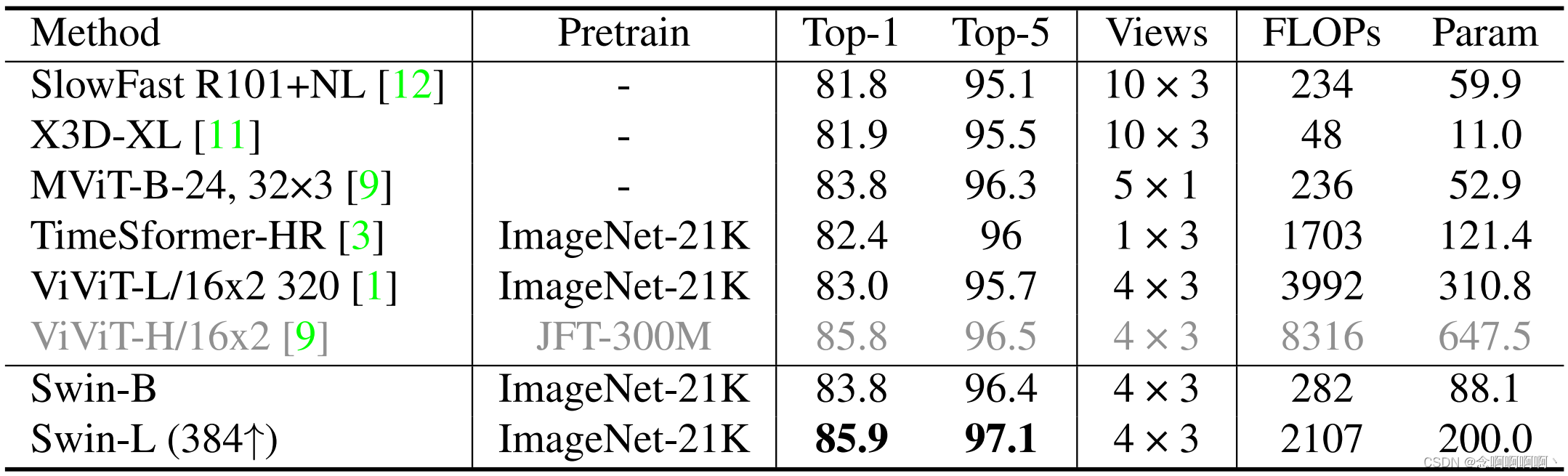
キネティクス-600。K600 の結果を表 2 に示します。K600 の観測結果は K400 の観測結果と同様です。ImageNet-21K 事前トレーニングを使用した最先端のものと比較すると、当社の Swin-L (384↑) は、同様の計算コストでトップ 1 の精度で ViViT-L (320) を 2.9% 上回っています。ViViT-H (JFT-300M) よりもはるかに小さいデータセット (ImageNet-21K) で事前トレーニングすることにより、Swin-L (384↑) は K600 で 85.9% という最先端の精度を達成します。
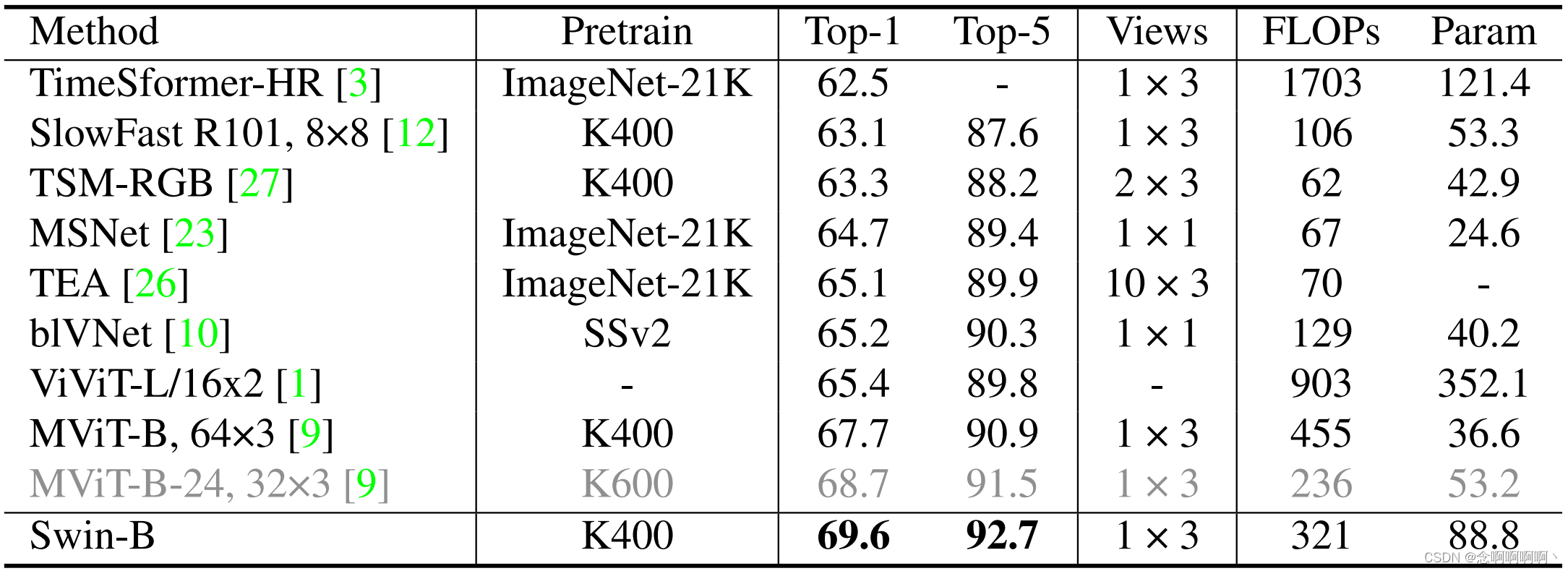
何か-何か v2。表 3 は、私たちの方法と SSv2 の最先端の方法を比較しています。MViT [9] に従い、K400 事前トレーニング済みモデルを初期化として使用します。K400 で事前トレーニングされたモデルを使用すると、Swin-B は 69.6% というトップ 1 の精度を達成し、K600 で事前トレーニングされた以前の最高のメソッド MViT-B-24 を 0.9% 上回りました。私たちの方法は、より大きなモデル (例: Swin-L)、より大きな入力解像度 (例: 3842)、およびより優れた事前トレーニング済みモデル (例: K600) を使用することでさらに改善できます。これらの試みは今後の課題として残しておきます。
4.3. アブレーション実験
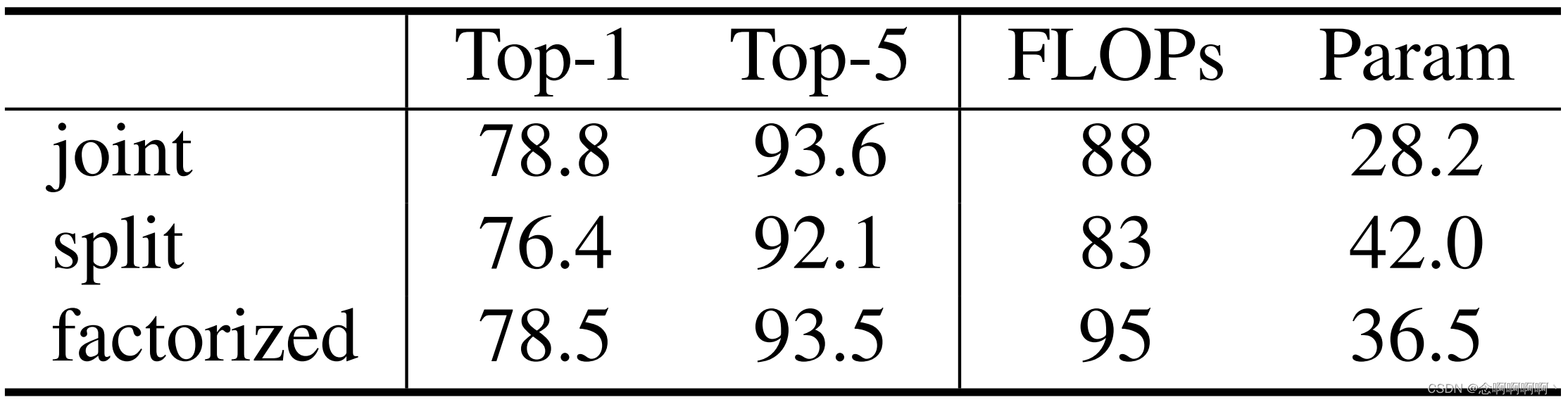
さまざまな空間的および時間的注意のデザイン。私たちは、時空間的注意の 3 つの主要なデザイン、つまり結合、分割、因数分解のバリアントを排除します。統合バージョンでは、各 3D ウィンドウ ベースの MSA レイヤーで時空間的注意を共同で計算します。これがデフォルト設定です。分割バージョンでは、ViViT [1] および VTN [29] で効果的であることが示されている、空間専用 Swin Transformer の上に 2 つの時間トランスフォーマー層が追加されます。分解されたバージョンでは、Swin Transformer の各空間限定 MSA 層の後に時間限定 MSA 層が追加されます。これは、TimeSformer [3] で効率的であることがわかっています。分解バージョンでは、事前トレーニングされた重みを持つバックボーンにランダムに初期化されたレイヤーを追加する悪影響を軽減するために、各時間専用 MSA レイヤーの最後にゼロに初期化された重み付けパラメーターを追加します。
結果を表4に示す。結合バージョンが最高の速度と精度のトレードオフを達成していることがわかります。これは主に、空間領域の局所性により、有効性を維持しながら結合バージョンの計算が削減されるためです。比較すると、ViT/DeiT に基づく統合バージョンは計算コストが高すぎます。分割バージョンはこのシナリオではうまく機能しません。このバージョンは事前トレーニングされたモデルから当然恩恵を受けることができますが、時間モデリングの点ではあまり効率的ではありません。分解バージョンでは比較的高いトップ 1 精度が得られますが、結合バージョンよりも多くのパラメーターが必要です。これは、分解バージョンでは各空間のみの注意層の後に時間のみの注意層があるのに対し、結合バージョンでは同じ注意層で空間と時間の両方の注意を実行するためです。
3D トークンの時間次元。私たちは、時間的にグローバルな方法で 3D トークンの時間次元に関するアブレーション研究を実施します。この場合、3D トークンの時間次元は時間ウィンドウ サイズと等しくなります。K400 および SSv2 での Swin-T の結果を表 5 に示します。一般に、時間次元が大きいほどtop1精度は高くなりますが、計算コストが高くなり、推論速度が遅くなります。SSv2 は、時間次元の増加からさらに恩恵を受けます。これは、 SSv2 の時間的依存性が高いためであると考えられます。

タイムウィンドウのサイズ。3D マーカーの時間次元を 16 に固定して、4/8/16 の時間ウィンドウ サイズでアブレーション研究を実行します。K400 で Swin-T を使用した結果を表 5 に示します。タイム ウィンドウ サイズ 8 の Swin-T は、タイム ウィンドウ サイズ 16 (時間グローバル) と比較して 0.3 のわずかなパフォーマンス低下しか生じないものの、計算量は相対的に 17% (88 対 106) 削減されることがわかります。 )。そこで、これを K400 のデフォルト設定として採用します。ただし、SSv2 では多くの場合、より多くの時間トークンとより大きな (グローバル) 時間ウィンドウが必要となるため、SSv2 データ セットのデフォルト設定として 16 個の時間トークンとグローバル ウィンドウを採用します。
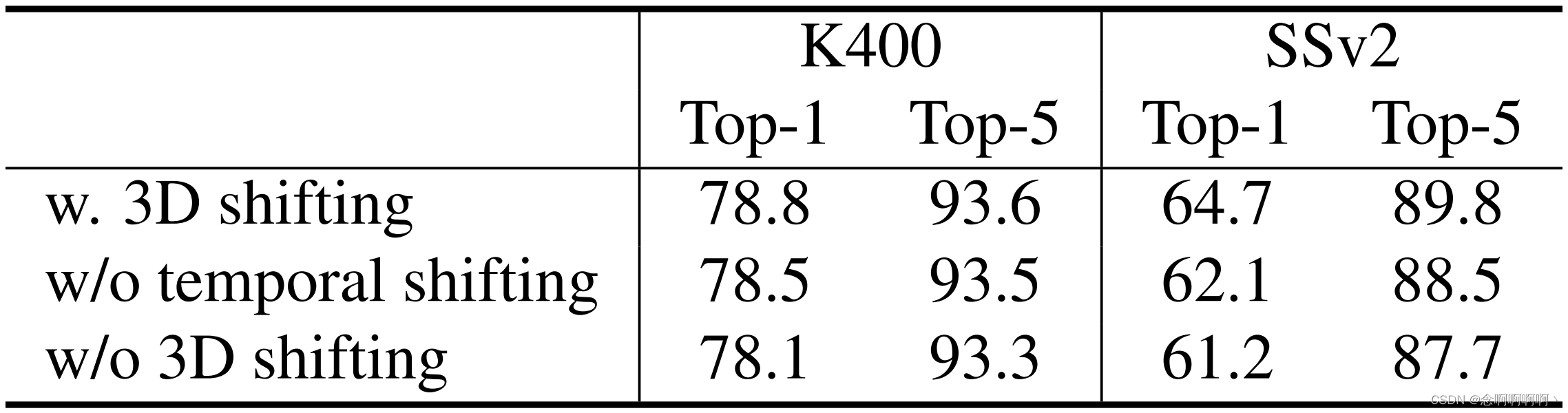
3D移動ウィンドウ。K400 および SSv2 の Swin-T での 3D シフト ウィンドウ法のアブレーションを表 6 に報告します。K400/SSv2 では、3D シフト ウィンドウでは +0.7% / +3.5% のトップ 1 精度が得られ、タイム シフト ウィンドウでは +0.3% / +2.6% が得られます。この結果は、重なり合わないウィンドウ間の接続を確立する際の 3D シフト ウィンドウ スキームの有効性を示しています。
背骨と頭の学習率の比率。表 7 は、背骨と頭の学習率の比率に関する興味深い発見を示しています。ImageNet1K/ImageNet-21K で事前トレーニングされたモデルを使用すると、ランダムに初期化されたヘッドに比べてバックボーン アーキテクチャの学習率が低く (たとえば、0.1 倍)、その結果、K400 でトップ 1 の精度が向上することがわかります。さらに、ImageNet-21K で事前トレーニングされたモデルはより強力であるため、 ImageNet-21K で事前トレーニングされたモデルを使用すると、この手法の恩恵をさらに受けられます。したがって、バックボーンは新しいビデオ入力をフィッティングするときに、事前にトレーニングされたパラメータとデータを徐々に忘れていき、より良い一般化を達成します。この観察は、事前トレーニングされた重みをより効果的に利用する方法に関するさらなる研究への道を示しています。

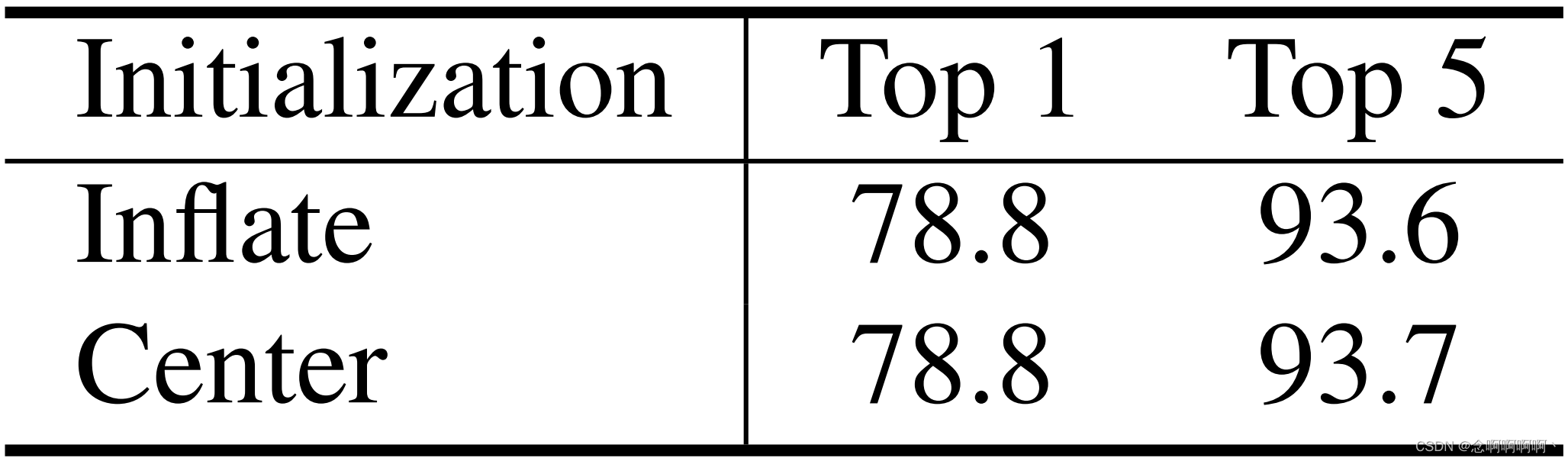
線形埋め込み層と 3D 相対位置偏差行列の初期化。ViViT [1] では、線形埋め込み層の中心初期化は拡張初期化よりも大幅に優れています。これにより、Video Swin Transformer のこれら 2 つの初期化方法に関するアブレーション研究を実施するようになりました。表 8 に示すように、驚くべきことに、K400 で ImageNet-1K 事前学習済みモデル 1 を使用すると、中心初期化を使用した Swin-T が拡張初期化を使用した Swin-T と同じパフォーマンスを達成し、78.8% のトップ 1 精度を達成したことがわかりました。この論文では、線形埋め込み層での通常の拡張初期化をデフォルトとします。
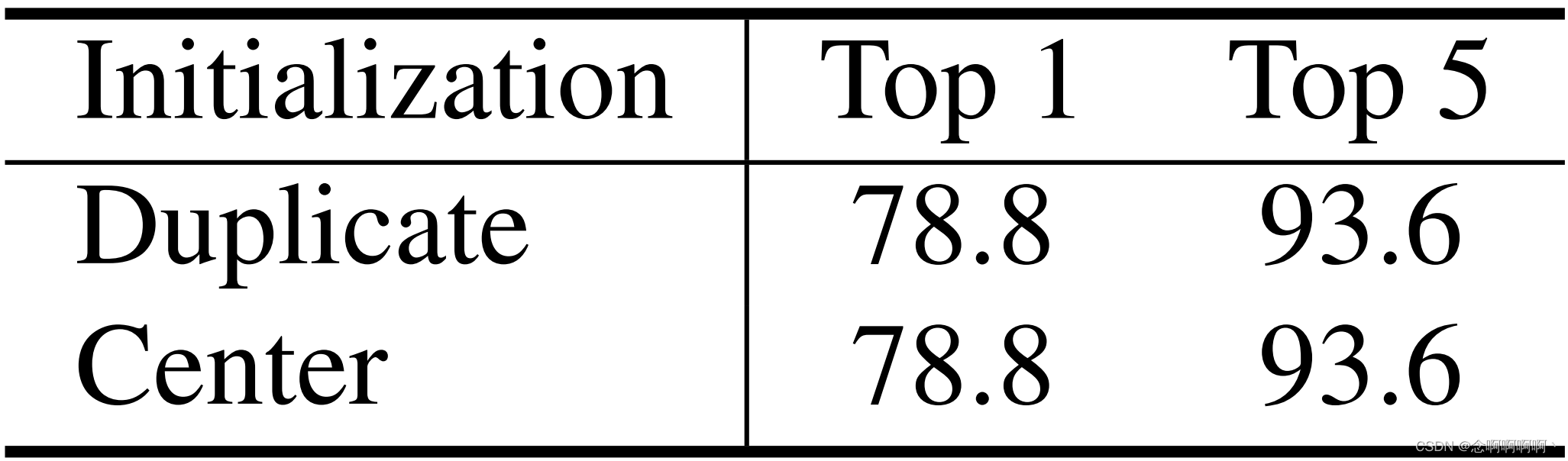
3D 相対位置偏差マトリックスについては、反復初期化または中心初期化という 2 つの異なる初期化オプションもあります。線形埋め込み層の中心初期化方法とは異なり、異なるフレーム間の相対位置偏差を小さな負の値 (例: -4.6) でマスクすることで 3D 相対位置偏差行列を初期化し、各マーカーが最初からのみ焦点を合わせるようにします。同じ枠内で。表 9 に示すように、K400 の Swin-T を使用した場合、どちらの初期化方法も同じトップ 1 精度 78.8% を達成したことがわかりました。デフォルトでは、3D 相対位置偏差行列の繰り返し初期化を使用します。
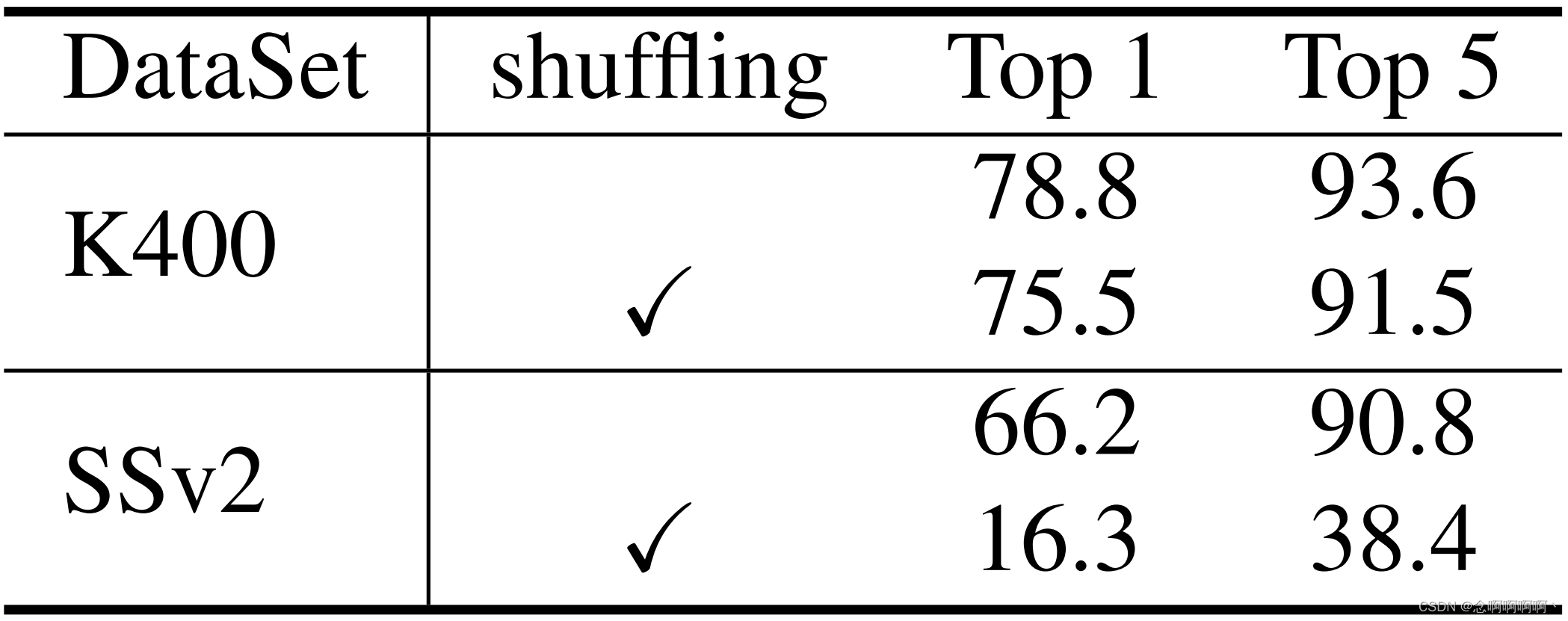
シャッフルフレーム推論。また、テスト中にフレームをランダムに変換することでビデオ モデルを評価しました [9]。その結果、K400 と SSv2 に対する影響が大きく異なることがわかりました。表 10 に示すように、フレーム変換により、トップ 1 の精度は K400 では 3.3%、SSv2 では 49.9% 減少します。SSv2 の大幅な減少は、SSv2 データセットでは時間モデリングにより多くの労力が必要であることを示しており、ビデオ Swin Transformer は、さまざまなデータセットの空間情報と時間情報をモデリングする際に、より優れたトレードオフを実現できます。
5。結論
我々は、時空間的な局所誘導バイアスに基づくビデオ認識のための純粋な Transformer アーキテクチャを提案します。このモデルは画像認識用に Swin Transformer を応用したものであるため、強力な事前トレーニング済み画像モデルの力を活用できます。提案された手法は、広く使用されている 3 つのベンチマーク、Kinetics-400、Kinetics-600、Something-Something v2 で最先端のパフォーマンスを達成します。Video Swin Transformer が将来の研究のためのシンプルで信頼できるベースラインとして機能することを願っています。。
参考文献
[1] Anurag Arnab、Mostafa Dehghani、Georg Heigold、Chen Sun、Mario Luciˇc、Cordelia Schmid. Vivit: ビデオ ビジョン トランスフォーマー. arXiv プレプリント arXiv:2103.15691, 2021. 1, 2, 5, 6, 7 , 8
[2] Hangbo Bao、Li Dong、Furu Wei、Wenhui Wang、Nan Yang、Xiaodong Liu、Yu Wang、Jianfeng Gao、Songhao Piao、Ming Zhou、他 Unilmv2: 統一言語モデル事前トレーニング用の擬似マスク言語モデル。機械学習に関する国際会議、642 ~ 652 ページ、PMLR、2020 年 4
[3] Gedas Bertasius、Heng Wang、および Lorenzo Torresani. ビデオの理解に必要なのは時空の注意だけですか? arXiv プレプリント arXiv:2102.05095、2021。 1、2、6、7
[4] 岳曹、許佳瑞、林スティーブン、方雲威、韓胡。Gcnet: 非ローカル ネットワークは、スクイーズ励起ネットワーク以降と出会います。IEEE/CVF International Conference on Computer Vision (ICCV) Workshops の議事録、2019 年 10 月。2
[5] Joao Carreira および Andrew Zisserman。Quo vadis、行動認識? 新しいモデルと動力学データセット。コンピューター ビジョンとパターン認識に関する IEEE 会議議事録、6299 ~ 6308 ページ、2017 年。2
[6] Joao Carreira および Andrew Zisserman。Quo vadis、行動認識? 新しいモデルと動力学データセット。コンピューター ビジョンとパターン認識に関する IEEE 会議議事録、6299 ~ 6308 ページ、2017 年。6
[7] Ekin D Cubuk、Barret Zoph、Jonathon Shlens、Quoc V Le。Randaugment: 検索スペースを削減した実用的な自動データ拡張。コンピューター ビジョンおよびパターン認識ワークショップに関する IEEE/CVF 会議議事録、702 ~ 703 ページ、2020 年。5 [8
] Alexey Dosovitskiy、Lucas Beyer、Alexander Kolesnikov、Dirk Weissenborn、Xiaohua Zhai、Thomas Unterthiner、Mostafa Dehghani、Matthias Minderer 、ゲオルグ・ハイゴールド、シルヴァン・ゲリー、ヤコブ・ウスコレイト、ニール・ハウルズビー。画像は 16x16 ワードの価値があります: 大規模な画像認識のためのトランスフォーマー。学習表現に関する国際会議にて、2021 年。1、2
[9] Haoqi Fan、Bo Xiong、Karttikeya Mangalam、Yanghao Li、Zhicheng Yan、Jitendra Malik、および Christoph Feichtenhofer。マルチスケールビジョントランスフォーマー。arXiv:2104.11227、2021. 2、5、6、7、8
[10] Quanfu Fan、Chun-Fu Chen、Hilde Kuehne、Marco Pistoia、David Cox。多ければ少ないほど: 大きな小さなネットワークと深さ方向の時間集約による効率的なビデオ表現を学習します。arXiv プレプリント arXiv:1912.00869、2019. 7
[11] Christoph Feichtenhofer。X3d: 効率的なビデオ認識のためのアーキテクチャを拡張します。コンピューター ビジョンとパターン認識に関する IEEE/CVF 会議議事録、203 ~ 213 ページ、2020 年。2、5、6
[12] Christoph Feichtenhofer、Haoqi Fan、Jitendra Malik、Kaiming He。ビデオ認識用の低速ネットワーク。コンピューター ビジョンに関する IEEE/CVF 国際会議議事録、6202 ~ 6211 ページ、2019 年。2、6、7
[13] Raghav Goyal、Samira Ebrahimi Kahou、Vincent Michalski、Joanna Materzynska、Susanne Westfal、Heuna Kim、Valentin Haenel、Ingo Fruend、Peter Yianilos、Moritz Mueller-Freitag、他 視覚的な学習と評価のための「何か」ビデオ データベース常識。コンピューター ビジョンに関する IEEE 国際会議議事録、5842 ~ 5850 ページ、2017 年。5
[14] Kaiming He、Xiangyu Zhang、Shaoqing Ren、および Jian Sun。画像認識のための深層残差学習。コンピューター ビジョンとパターン認識に関する IEEE 会議議事録、770 ~ 778 ページ、2016 年。1
[15] エラッド・ホッファー、タル・ベン=ヌン、イタイ・フバラ、ニヴ・ギラディ、トルステン・ヘフラー、ダニエル・サドリー。バッチを拡張する: インスタンスの繰り返しを通じて一般化を改善します。コンピューター ビジョンとパターン認識 (CVPR) に関する IEEE/CVF 会議議事録、2020 年 6 月。5
[16] Han Hu、Jiayuan Gu、Zheng Zhang、Jifeng Dai、および Yichen Wei。オブジェクト検出のための関係ネットワーク。コンピューター ビジョンとパターン認識に関する IEEE 会議議事録、3588 ~ 3597 ページ、2018 年。4
[17] Han Hu、Zheng Zhang、Zhenda Xie、Stephen Lin。画像認識のためのローカル関係ネットワーク。IEEE/CVF International Conference on Computer Vision (ICCV) の議事録、3464 ~ 3473 ページ、2019 年 10 月。4
[18] Gao Huang、Zhuang Liu、ローレンス・ヴァン・デル・マーテン、キリアン・Q・ワインバーガー。高密度に接続された畳み込みネットワーク。コンピューター ビジョンとパターン認識に関する IEEE 会議議事録、4700 ~ 4708 ページ、2017 年。1
[19] Gao Huang、Yu Sun、Zhuang Liu、Daniel Sedra、および Kilian Q Weinberger。確率論的な深さを持つ深いネットワーク。コンピューター ビジョンに関する欧州会議、646 ~ 661 ページ。Springer、2016 年。5
[20] Will Kay、Joao Carreira、Karen Simonyan、Brian Zhang、Chloe Hillier、Sudheendra Vijayanarasimhan、Fabio Viola、Tim Green、Trevor Back、Paul Natsev、他 動力学ヒューマン アクション ビデオ データセット。arXiv プレプリント arXiv:1705.06950、2017. 5
[21] Diederik P Kingma および Jimmy Ba。アダム: 確率的最適化の手法。arXiv プレプリント arXiv:1412.6980、2014. 5
[22] アレックス・クリジェフスキー、イリヤ・サツケヴァー、ジェフリー・E・ヒントン。ディープ畳み込みニューラル ネットワークによる Imagenet 分類。『神経情報処理システムの進歩』、1097 ~ 1105 ページ、2012 年。1
[23] Heeseung Kwon、Manjin Kim、Suha Kwak、および Minsu Cho。Motionsqueeze: ビデオ理解のためのニューラル モーション機能学習。European Conference on Computer Vision、345 ~ 362 ページ。Springer、2020. 7
[24] Yann LeCun、Leon Bottou、Yoshua Bengio、Patrick Haffner、他 文書認識に適用された勾配ベースの学習。IEEE 議事録、86(11):2278–2324、1998 年。1
[25] Xinyu Li、Yanyi Zhang、Chunhui Liu、Bing Shuai、Yi Zhu、Biagio Brattoli、Hao Chen、Ivan Marsic、Joseph Tighe。Vidtr: 畳み込みのないビデオ トランスフォーマー。arXiv プレプリント arXiv:2104.11746、2021. 2
[26] ヤン・リー、ビン・ジー、シンティエン・シー、ジャングオ・チャン、ビン・カン、そしてリミン・ワン。Tea: 行動認識のための時間的興奮と集約。コンピューター ビジョンとパターン認識に関する IEEE/CVF 会議議事録、909 ~ 918 ページ、2020 年。7
[27] Ji Lin、Chuang Gan、および Song Han。Tsm: ビデオを効率的に理解するための時間シフト モジュール。コンピューター ビジョンに関する IEEE/CVF 国際会議議事録、7083 ~ 7093 ページ、2019 年。7
[28] Ze Liu、Yutong Lin、Yue Cao、Han Hu、Yixuan Wei、Zheng Zhang、Stephen Lin、および Baining Guo。Swin トランスフォーマー: シフトされたウィンドウを使用する階層型ビジョン トランスフォーマー。arXiv プレプリント arXiv:2103.14030、2021. 1、2、3、4、5
[29] ダニエル・ナイマーク、オムリ・バー、マヤ・ゾハール、ドータン・アッセルマン。ビデオトランスフォーマーネットワーク。arXiv プレプリント arXiv:2102.00719、2021. 2、6、7
[30] Zhaofan Qiu、Ting Yao、および Tao Mei。擬似 3D 残差ネットワークを使用した時空間表現の学習。IEEE International Conference on Computer Vision の議事録、5533 ~ 5541 ページ、2017 年。1、2
[31] Colin Raffel、Noam Shazeer、Adam Roberts、Katherine Lee、Sharan Nanang、Michael Matena、Yanqi Zhou、Wei Li、および Peter J.リュー。統合されたテキストからテキストへの変換機能を使用して転移学習の限界を探ります。Journal of Machine Learning Research、21(140):1–67、2020。4
[32] K. Simonyan および A. Zisserman。大規模な画像認識のための非常に深い畳み込みネットワーク。学習表現に関する国際会議にて、2015 年 5 月 1
[33] クリスチャン・セゲディ、ウェイ・リュー、ヤンチン・ジア、ピエール・セルマネ、スコット・リード、ドラゴミル・アンゲロフ、ドゥミトル・エルハン、ヴィンセント・ヴァンホーク、アンドリュー・ラビノビッチ。畳み込みでさらに深くなります。コンピューター ビジョンとパターン認識に関する IEEE 会議議事録、1 ~ 9 ページ、2015 年。1
[34] Hugo Touvron、Matthieu Cord、Matthijs Douze、Francisco Massa、Alexandre Sablayrolles、および Herve J ´ egou。データ効率の高い画像変換と注意力による抽出をトレーニングします。arXiv プレプリント arXiv:2012.12877、2020. 1、2
[35] Du Tran、Lubomir Bourdev、Rob Fergus、Lorenzo Torresani、および Manohar Paluri。3D 畳み込みネットワークを使用して時空間特徴を学習します。コンピューター ビジョンに関する IEEE 国際会議議事録、4489 ~ 4497 ページ、2015 年。1、2
[36] デュ・トラン、ヘン・ワン、ロレンツォ・トレサーニ、マット・ファイズリ。チャネル分離畳み込みネットワークによるビデオ分類。コンピューター ビジョンに関する IEEE/CVF 国際会議議事録、5552 ~ 5561 ページ、2019 年。6
[37] Du Tran、Heng Wang、Lorenzo Torresani、Jamie Ray、Yann LeCun、および Manohar Paluri。行動認識のための時空間畳み込みを詳しく見てみましょう。コンピューター ビジョンとパターン認識に関する IEEE 会議議事録、6450 ~ 6459 ページ、2018 年 2、6
[38] Ashish Vaswani、Noam Shazeer、Niki Parmar、Jakob Uszkoreit、Llion Jones、Aidan N Gomez、Łukasz Kaiser、および Illiaポロスキン。必要なのは注意力だけです。『神経情報処理システムの進歩』、5998 ~ 6008 ページ、2017 年。1
[39] ヘン・ワン、ドゥ・トラン、ロレンツォ・トレサーニ、マット・ファイズリ。相関ネットワークを使用したビデオ モデリング。コンピューター ビジョンとパターン認識に関する IEEE/CVF 会議議事録、352 ~ 361 ページ、2020 年。6
[40] Xiaolong Wang、Ross Girshick、Abhinav Gupta、Kaiming He。非ローカルニューラルネットワーク。コンピューター ビジョンとパターン認識に関する IEEE 会議議事録、7794 ~ 7803 ページ、2018 年 2、6
[41] Saining Xie、Chen Sun、Jonathan Huang、Zhuowen Tu、および Kevin Murphy。時空間特徴学習の再考: ビデオ分類における速度と精度のトレードオフ。欧州コンピュータ ビジョン会議 (ECCV) の議事録、305 ~ 321 ページ、2018 年。1、2
[42] Ceyuan Yang、Yinghao Xu、Jianping Shi、Bo Dai、および Bolei Zhou. アクション認識のための時間ピラミッド ネットワーク. コンピューター ビジョンとパターン認識に関する IEEE/CVF 会議議事録、591 ~ 600 ページ、2020. 6
[ [43] Minghao ying、Zhuliang Yao、Yue Cao、Xiu Li、Zheng Zhang、Stephen Lin、および Han Hu. 絡み合った非ローカル ニューラル ネットワーク. 欧州コンピューター ビジョン会議 (ECCV) の議事録、2020. 2 [44
] Zhun Zhong、Liang Zheng、Guoliang Kang、Shaozi Li、および Yi Yang. ランダム消去データ拡張. Proceedings of the AAAI Conference on Artificial Intelligence、volume 34、pages 13001–13008、2020. 5