目的
分散システムログの場合、各サーバーノードの Web サービスが独自のログファイルを生成するため、ログを統合したりトラブルシューティングしたりする場合、各ノードに移動してログファイルを 1 つずつ表示する必要があり、面倒です。したがって、ログ収集を保管およびクエリのために 1 つの場所に配置するソリューションが必要です。これはelk+kafkaを使用して解決できます。
Elk (elasticsearch、logstash、kibana) の頭字語。Elasticsearch は収集されたログ データの保存に使用され、logstash はログの収集を担当し、kibana は es の視覚的な分析およびクエリ ツールとして使用されます。
原理
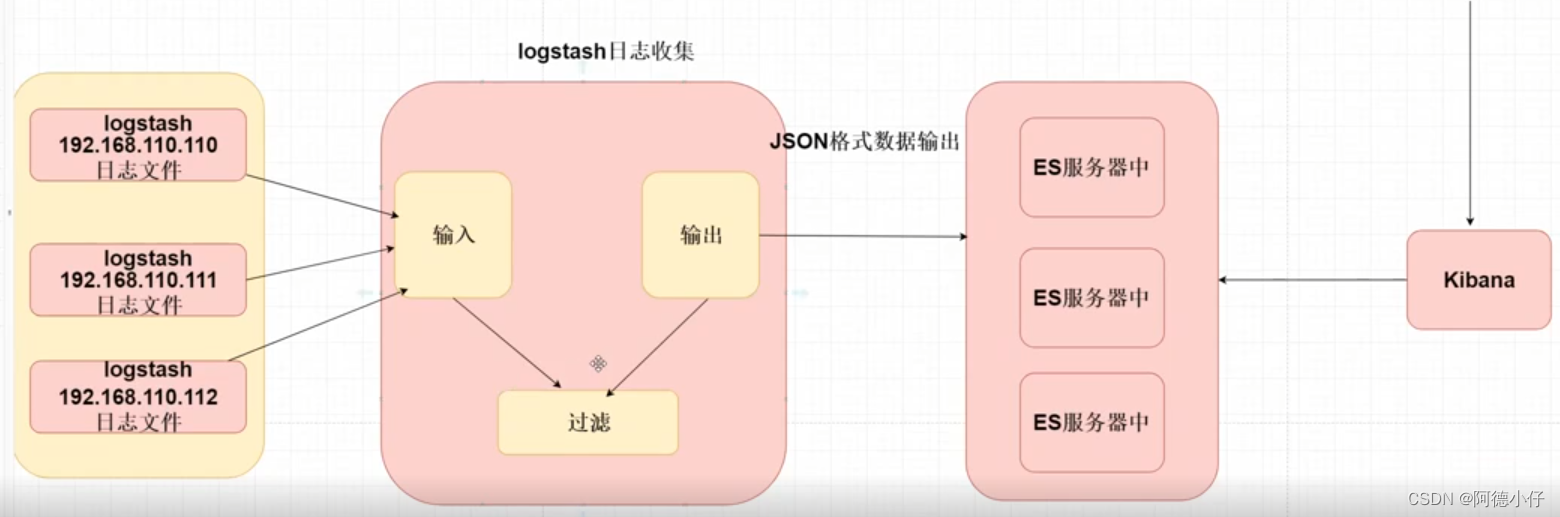
eIk がログを収集する原理:
1. Logstash は各サーバーにインストールする必要があります
2. Logstash は、特定のログ ファイルを永続的に読み取るように構成する必要があります。
3.logstash はログ ファイルを json 形式にフォーマットし、es に出力します。
4. 開発者は kibana を使用して es に接続し、保存されたログの内容をクエリします。
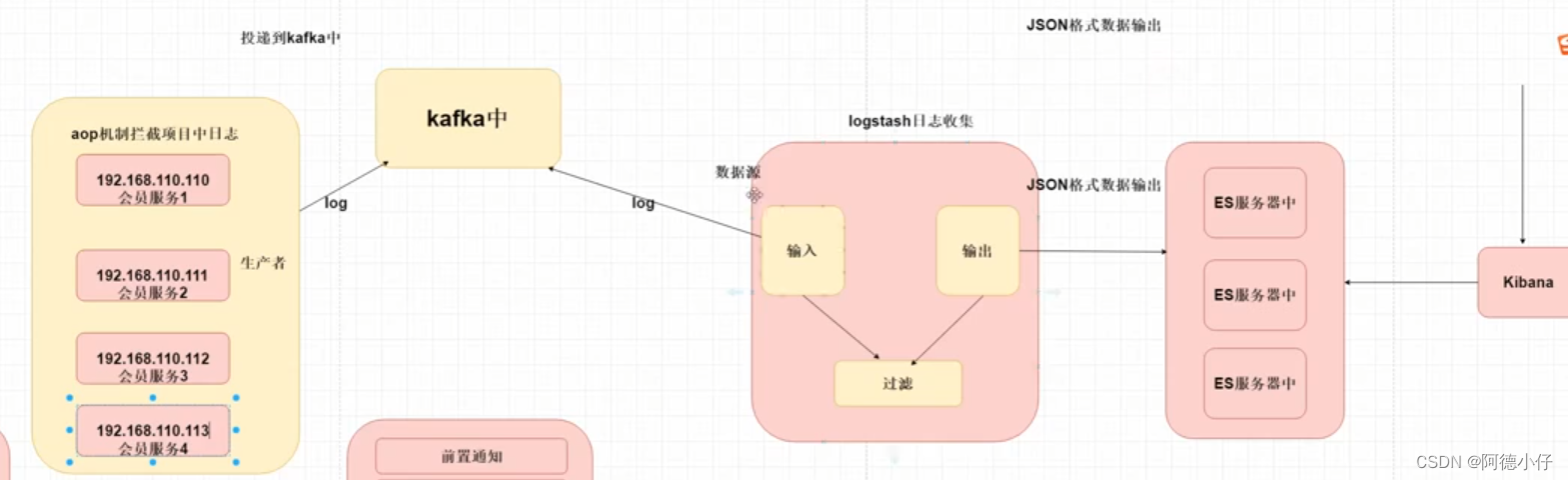
elk+kafka 原理:
1. springboot プロジェクトは、aop に基づいてシステム内のログをインターセプトします。
Log(エラーログ)
エラーログ:例外通知
リクエストおよびレスポンスのログ情報 -- 先行またはラップされた通知。
2. ログを kafka に送信しますプロセスは非同期である必要があることに注意してください。
3.Logstash データ ソース --- kafka は、ログ メッセージの内容を取得するために kafka のトピックをサブスクライブします。
4. ログメッセージの内容をesに出力し、保存する
5. 開発者は Kibana を使用して ElasticSeach に接続し、ストレージ ログの内容をクエリします。
Elk+kafkaの環境構築
ElaticsearchとkibanaのインストールにはDockerを使用しますが、自分でインストールパッケージをダウンロードしてインストールすることもできます。
エラティックサーチ
elasticsearch のインストール
1. ES イメージの問題をダウンロード
docker pull elasticsearch
2. ESdocker を実行 run -it --name elasticsearch -d -p 9200:9200 -p 9300:9300 -p 5601:5601 elasticsearch
3. テスト走行結果
http://192.168.163.129:9200/
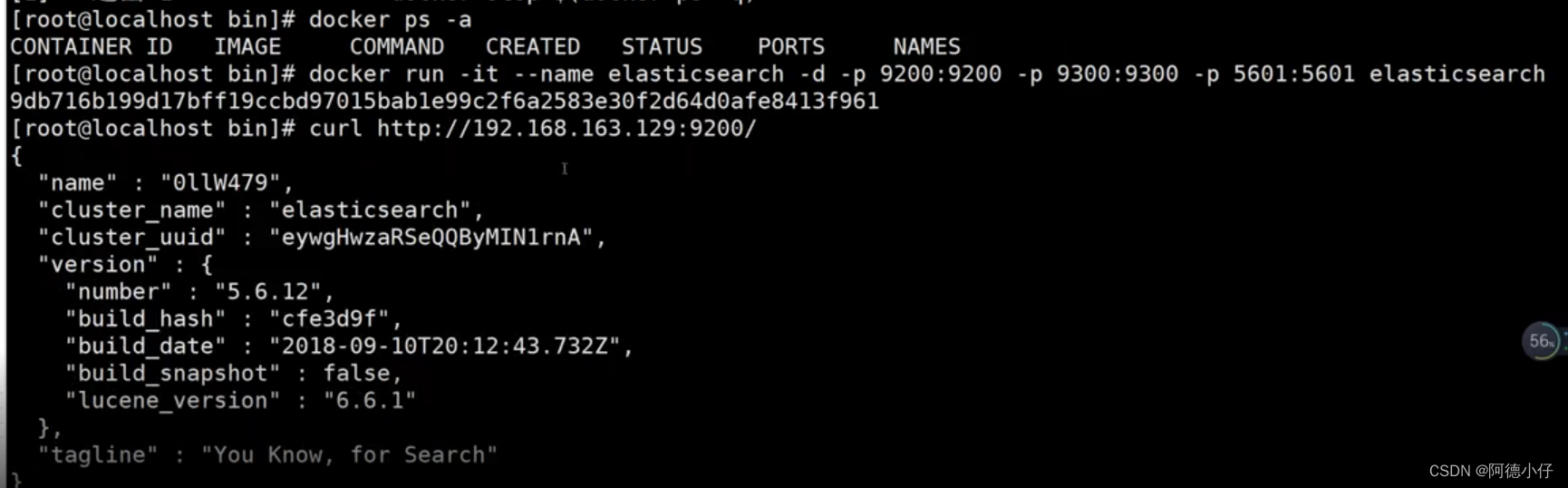
以下のエラーが発生した場合は、作成したesコンテナが競合しているため、既存のesコンテナを削除するか、イメージの名前を変更する必要があります。

ログスタッシュ
Logstash は、リアルタイム パイプライン機能を備えたオープンソース データ収集エンジンです。Logstash は、異なるデータ ソースからのデータを動的に統合し、選択した宛先にデータを正規化します。
Logstash 入力データ ソース:、ローカル ファイル、Kafka、Redis、mysql
Logstash 出力データ ソース: Es、Mongdb、Redis、Mysql
インストール手順:
1. logstash-6.4.3.tar.gz をサービスにアップロードします
2.tar -zxvf logstash-6.4.3.tar.gz
3.cd logstash-6.4.3
4.bin/logstash-plugin logstash-input-kafka をインストールします
5.bin/logstash-plugin logstash-output-elasticsearch をインストールします
設定ファイル mylog.conf:

起動する:

キバナ
docker run -it -d -e ELASTICSEARCH URL=http://127.0.0.1:9200 --name kibana --network=container:elasticsearch kibana
テストの実行結果
http://192.168.163.129:5601/app/kibana#
カフカ
Linux 環境を使用している場合は、ここではウィンドウ バージョンを使用します。インストールについて自分で学ぶことができます
Kafka は Zookeeper に依存しているため、最初に zk をインストールする必要があります。


デモコード
Springboot フレームワーク、AOP 事前通知を使用してリクエスト情報を Kafka に収集する方法を示します。

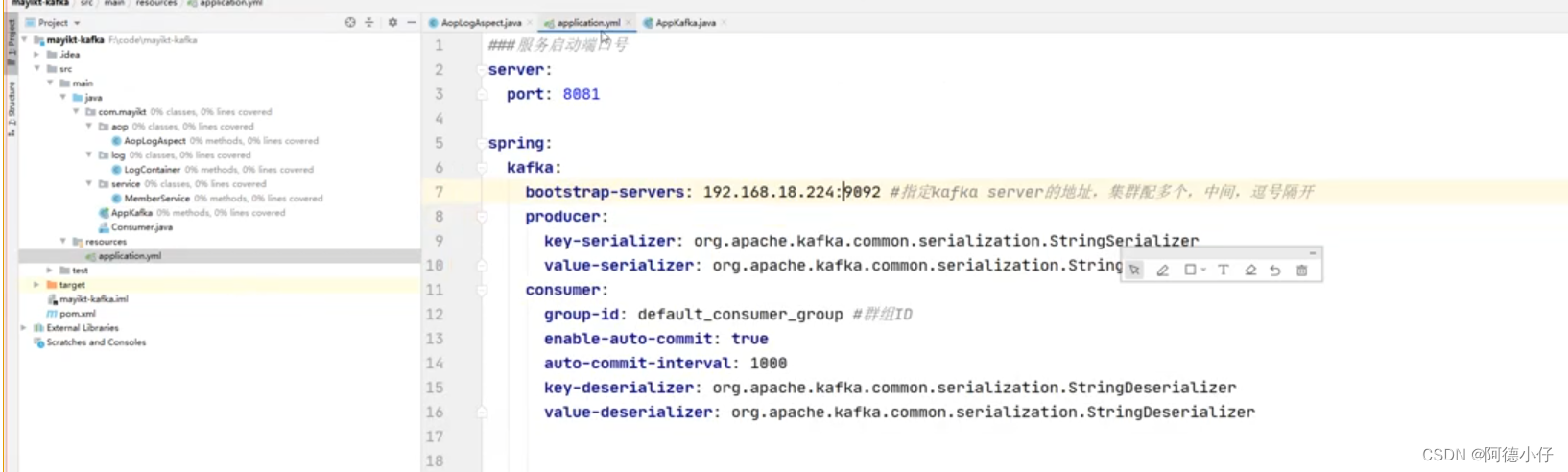
Kafka の Spring-Boot 構成情報:
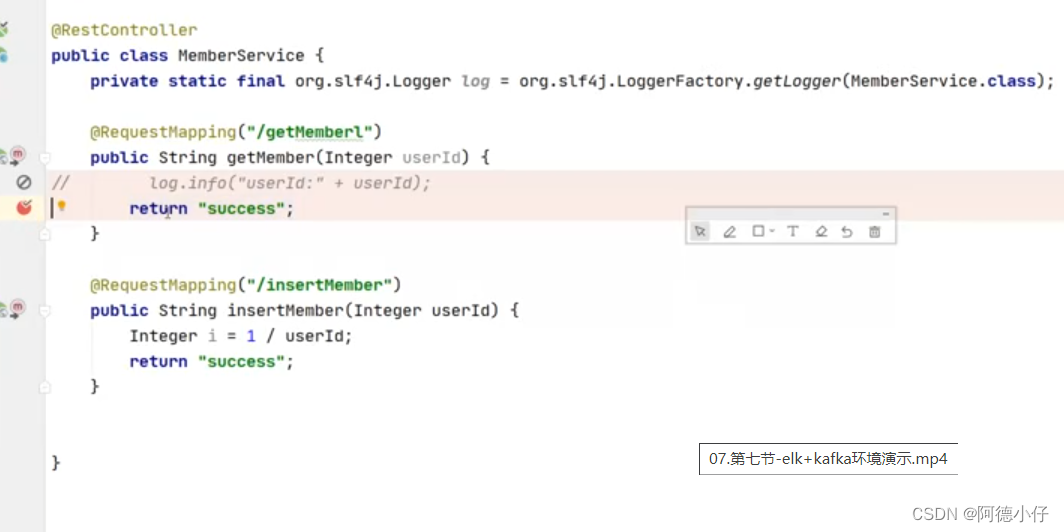
ブラウザ アクセス: 127.0.0.1:8881/project name/getMeberl、aop 事前通知はリクエスト情報をカプセル化し、kafka に配信します。Logstash は自動的に kafka からデータを取得し、es に保存します。保存されたデータを表示するには kibana を使用します。 、写真のような:
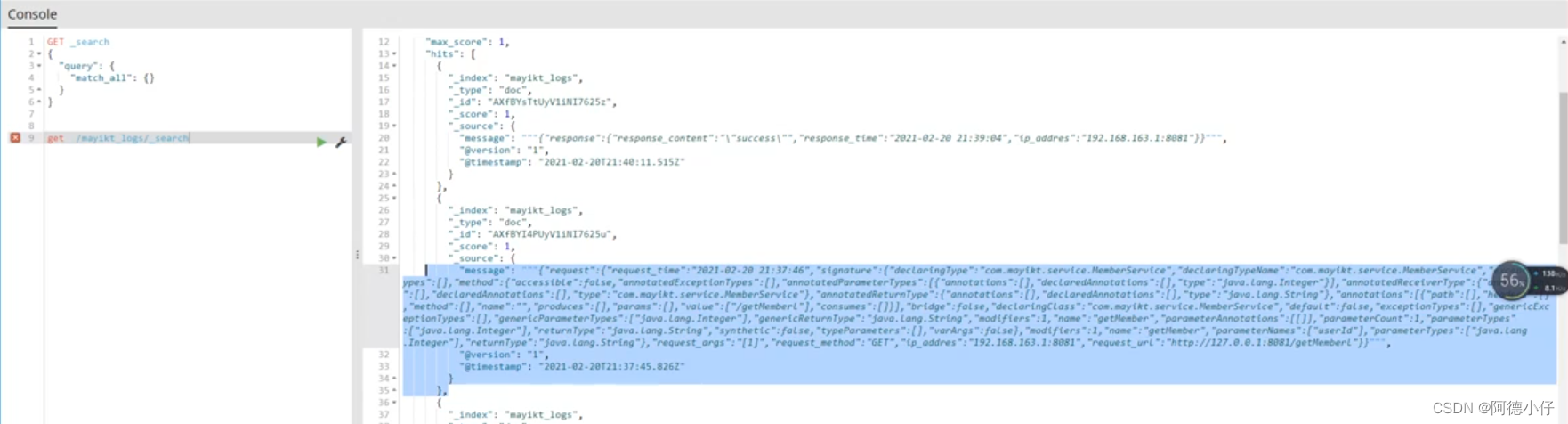
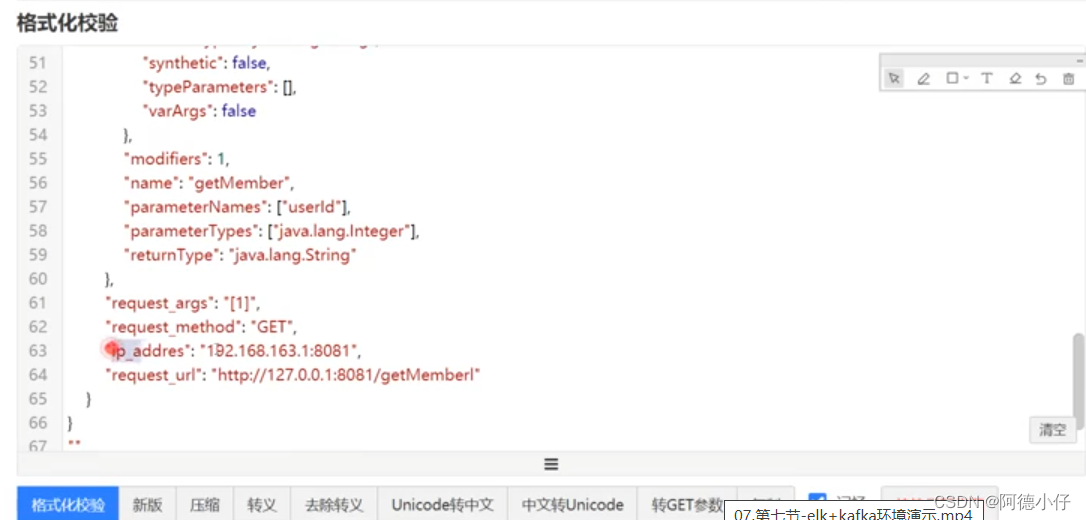
コピーして書式設定ツールに入れます
ログの保存に es を使用する理由
es は検索サーバーであり、最下層はLucene に基づいており、転置インデックスをサポートしており、検索効率が特に優れています。ビジネス ニーズに基づいて、 Mongdb、Redis、Mysqlの選択を検討できます。Flume がビッグデータのストレージ、分析、統計のためにデータを HDFS に収集する方法については、後ほど記事が更新される予定です。
Elk を Kafka と組み合わせる必要がある理由
1. 単純に elk を使用する場合、サーバー ノードの拡張には各サーバーに Logstash をインストールする必要があり、手順は比較的冗長です。
2. Logstash はローカル ログ ファイルを読み取ります。これは、ローカル ディスク IO パフォーマンスに一定の影響を与える可能性があります。
最適化
図からわかるように、リクエストが AOP をトリガーし、事前通知でメッセージが Kafka に送信されますが、Kafka に異常やネットワークジッターが発生した場合、メインプロセスのリクエスト応答効率とその有無に影響を及ぼします。例外。したがって、データをメモリ キューに入れてからスレッドを開き、別のスレッドでループしてメモリ キューからデータを kafka にフェッチする必要がありますが、これはリクエストとレスポンスの通常の実行には影響しません。