1 トレーニングセット ex6data1.mat の可視化
トレーニングセット関数plotData.mをプロットします。
関数プロットデータ(X, y)
% LotData(X, y) データをプロットします。
% 入力パラメータ: X 入力特性行列、行数はサンプル数、列数は 2、各行は 2 次元点
% y は特徴ベクトルを出力します。行数はサンプル数、列数は 1、各要素の値は 0 または 1 です。
% 出力結果: サンプルの出力特性ベクトルが 1 の場合は「+」でマークされ、0 の場合は「o」でマークされます。
%
% 新しい図を作成
形; 持続する;
% 正の例と負の例のインデックスを見つける
pos = 検索(y == 1); neg = find(y == 0);
% プロットの例
プロット(X(pos, 1), X(pos, 2), 'k+','LineWidth', 1, 'MarkerSize', 5);
Lot(X(neg, 1), X(neg, 2), 'ko', 'MarkerFaceColor', 'y','MarkerSize', 5);
控えてください。
エンドファンクション
トレーニング セット視覚化スクリプト LinearSVM.m のコードの最初の部分
%% 初期化
クリア ; すべて閉じます。clc
%% =============== パート 1: データのロードと視覚化================
fprintf('データのロードと視覚化 ...\n')
% ファイル ex6data1.mat からロードすると、環境内に X および y 変数値があることがわかります。
ロード('ex6data1.mat');
% トレーニングセットデータをプロットする
プロットデータ(X, y);
fprintf('プログラムは一時停止しました。続行するには Enter キーを押してください。\n');
一時停止;
の結果
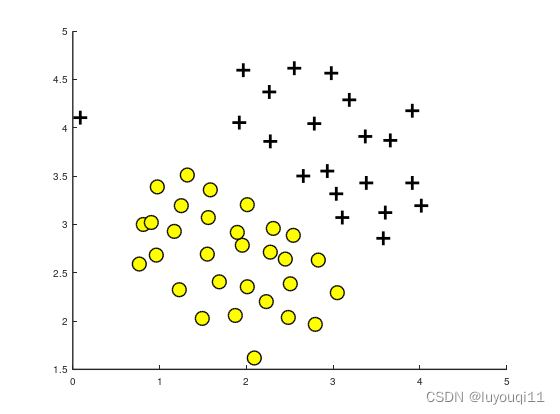
ここでのデータセットは 2 つのカテゴリに分類されており、外れ値点 (0.1、4.1) があるため、この偏差点が SVM の決定境界に影響を与えることがわかります。
2 SVM リニア カーネル LinearKernel.m
関数 sim = LinearKernel(x1, x2)
% LinearKernel(x1, x2) は、x1 と x2 の間の線形カーネルを返します。
% 入力パラメータ: x1、x2 列ベクトル。x1 と x2 が一貫した次元を持つ列ベクトルであることを確認します。
% 戻り値: 列ベクトル x1、x2 の sim 内積
%
x1 = x1(:); x2 = x2(:);
% カーネルを計算します
sim = x1' * x2; % 内積
終わり
3 トレーニング関数 svmTrain.m
関数 [モデル] = svmTrain(X, Y, C, kernelFunction, ...
tol、max_passes)
% svmTrain は、SMO アルゴリズムの簡易バージョンを使用して SVM 分類器をトレーニングします。
% 入力: X トレーニング行列、行数はサンプル数、列数は入力特徴の数です。
% y トレーニング セットの出力特徴ベクトルは、1 と 0 を含む列ベクトルです。行数はサンプル数であり、列数は 1 です。
% C 標準 SVM 正則化パラメータ。
% kernelFunction トレーニング用のカーネル関数
% tol は、等しい浮動小数点数を決定するために使用される許容値です。
% max_passes は、(アルファ値を変更せずに) アルゴリズムが終了するまでのデータセットの反復回数を制御します。
%戻り値: モデルトレーニングモデル
%
%注: これは、サポート ベクター マシンのトレーニングに使用される SMO アルゴリズムの簡易バージョンです。
% 実際には、SVM 分類器をトレーニングする場合は、次のような最適化されたパッケージを使用することをお勧めします。
% LIBSVM (http://www.csie.ntu.edu.tw/ ~ cjlin / LIBSVM /)
% SVMLight (http://svmlight.joachims.org/)
%デフォルトの tol 値と max_passes を設定します
if ~exist('tol', 'var') || 空(トール)
tol = 1e-3;
エンドイフ
if ~exist('max_passes', 'var') || isempty(max_passes)
max_passes = 5;
エンドイフ
% トレーニングセットのパラメータ
m = size(X, 1); % サンプル数
n = size(X, 2); % 入力フィーチャの数
% 出力特徴ベクトル内の値 0 の要素を -1 に置き換えます。
Y(Y==0) = -1;
% トレーニング モデル内の変数を初期化します。
アルファ = ゼロ (m, 1);
b = 0;
E = ゼロ(m, 1);
パス = 0;
そして = 0;
L = 0;
H = 0;
% データセットが小さいため、カーネル行列を事前計算します。
% (実際には、このコードを使用する代わりに、大規模なデータ セットを適切に処理できる最適化された SVM パッケージを使用してください)
% ここでは、SVM トレーニングの実行を高速化するために、ベクトル化されたカーネルの最適化されたバージョンを実装しました。
if strcmp(func2str(kernelFunction), 'linearKernel')
% 線形カーネルのベクトル化された計算。
% これは、サンプルの各ペアでカーネルを計算することと同等です。
K = X*X';
elseif strfind(func2str(kernelFunction), 'gaussianKernel')
% ベクトル化された RBF カーネル
% これは、サンプルの各ペアでカーネルを計算することと同等です。
X2 = 合計(X.^2, 2);
K = bsxfun(@plus, X2, bsxfun(@plus, X2', - 2 * (X * X')));
K = カーネル関数(1, 0) .^ K;
それ以外
% カーネル行列を事前計算します
% ベクトル化がされていないため、次の操作が遅くなる可能性があります
K = ゼロ(m);
i = 1:mの場合
j = i:m の場合
K(i,j) = kernelFunction(X(i,:)', X(j,:)');
K(j,i) = K(i,j); %行列は対称です
エンドフォー
エンドフォー
エンドイフ
% 電車
fprintf('\nトレーニング ...');
ドット = 12;
while パス < max_passes、
num_changed_alphas = 0;
i = 1:mの場合、
% (2) を使用して、Ei = f(x(i)) - y(i) を計算します。。
% E(i)=b +sum (X(i, :)*(repmat(alphas.*Y,1,n).*X)')- Y(i);
E(i) = b + sum (alphas.*Y.*K(:,i)) - Y(i);
if ((Y(i)*E(i)<-tol && alphas(i)< C) || (Y(i)*E(i)>tol && alphas(i)>0)),
実際には、多くのヒューリスティックを使用して i と j を選択できます。
% この簡略化されたコードでは、それらをランダムに選択します。
j = ceil(m * rand());
while j == i, % i であることを確認してください \neq j
j = ceil(m * rand());
老人
% (2) を使用して Ej = f(x(j)) - y(j) を計算します。
E(j) = b + sum (alphas.*Y.*K(:,j)) - Y(j);
% 古いアルファを保存します
alpha_i_old = alphas(i);
alpha_j_old = alphas(j);
% (10) または (11) で L と H を計算します。
if (Y(i) == Y(j))、
L = max(0, alphas(j) + alphas(i) - C);
H = min(C, alphas(j) + alphas(i));
それ以外
L = max(0, alphas(j) - alphas(i));
H = min(C, C + alphas(j) - alphas(i));
エンドイフ
(L == H) の場合、
% 次の i に進みます。
続く;
エンドイフ
% (14) を通じてηを計算します。
η = 2 * K(i,j) - K(i,i) - K(j,j);
(イータ >= 0) の場合、
% 次の i に進みます。
続く;
エンドイフ
% (12) と (15) を使用してアルファの新しい値を計算し、クリップします。
alphas(j) = alphas(j) - (Y(j) * (E(i) - E(j))) / η;
% クリップ
alphas(j) = 最小 (H, alphas(j));
alphas(j) = 最大 (L, alphas(j));
% アルファの変化が重要かどうかを確認します
if (abs(alphas(j) - alpha_j_old) < tol)、
% 次の i に進みます。
% とにかく置き換える
alphas(j) = alpha_j_old;
続く;
エンドイフ
% (16) を使用して、alpha i の値を決定します。
alphas(i) = alphas(i) + Y(i)*Y(j)*(alpha_j_old - alphas(j));
% (17) と式 (18) をそれぞれ使用して b1 と b2 を計算します。
b1 = b - E(i) ...
- Y(i) * (alphas(i) - alpha_i_old) * K(i,j)' ...
- Y(j) * (alphas(j) - alpha_j_old) * K(i,j)';
b2 = b - E(j) ...
- Y(i) * (alphas(i) - alpha_i_old) * K(i,j)' ...
- Y(j) * (alphas(j) - alpha_j_old) * K(j,j)';
% (19) を使用して b を計算します。
if (0 < alphas(i) && alphas(i) < C)、
b = b1;
elseif (0 < alphas(j) && alphas(j) < C),
b = b2;
それ以外
b = (b1+b2)/2;
エンドイフ
num_changed_alphas = num_changed_alphas + 1;
エンドイフ
エンドフォー
if (num_changed_alphas == 0)、
パス = パス + 1;
それ以外
パス = 0;
エンドイフ
fprintf('.');
ドット = ドット + 1;
ドット > 78 の場合
ドット = 0;
fprintf('\n');
エンドイフ
存在する場合('OCTAVE_VERSION')
fflush(標準出力);
エンドイフ
老人
fprintf(' 完了! \n\n');
% モデルを保存します
idx = アルファ > 0;
モデル.X= X(idx,:);
モデル.y= Y(idx);
モデル.カーネル関数 = カーネル関数;
モデル.b= b;
モデル.alphas= alphas(idx);
model.w = ((alphas.*Y)'*X)';
エンドファンクション
4 線形 SVM 決定境界関数の可視化 VisualizeBoundaryLinear.m
関数 VisualizeBoundaryLinear(X, y, モデル)
% VisualizeBoundaryLinear は、サポート ベクター マシンによって学習された線形決定境界を描画します
% 入力: X トレーニング行列、行数はサンプル数、列数は入力特徴の数です。
% y トレーニング セットの出力特徴ベクトルは、1 と 0 を含む列ベクトルです。行数はサンプル数であり、列数は 1 です。
% model svmTrain 関数によって取得されたモデル
w = モデル.w;
b = モデル.b;
xp = linspace(min(X(:,1)), max(X(:,1)), 100);
yp = - (w(1)*xp + b)/w(2);
プロットデータ(X, y);
持続する;
プロット(xp, yp, '-b');
控える
エンドファンクション
5 線形 SVM スクリプト LinearSVM.m コードの 2 番目の部分
%% ==================== パート 2: 線形 SVM トレーニング ====================
% 次のコードは、データセット上で線形サポート ベクター マシンをトレーニングし、学習された決定境界をプロットします。
% ファイル ex6data1.mat からロードすると、環境内に X および y 変数値があることがわかります。
ロード('ex6data1.mat');
fprintf('\n線形 SVM をトレーニング中 ...\n')
% 決定境界がどのように変化するかを確認するには、以下の C 値を変更してみてください (たとえば、C = 1000 を試してください)。
C = 1;
モデル = svmTrain(X, y, C, @linearKernel, 1e-3, 20);
VisualizeBoundaryLinear(X, y, モデル);
fprintf('プログラムは一時停止しました。続行するには Enter キーを押してください。\n');
一時停止;
ロード('ex6data1.mat');
fprintf('\n線形 SVM をトレーニング中 ...\n')
% 決定境界がどのように変化するかを確認するには、以下の C 値を変更してみてください (たとえば、C = 1000 を試してください)。
C = 100;
モデル = svmTrain(X, y, C, @linearKernel, 1e-3, 20);
VisualizeBoundaryLinear(X, y, モデル);
6 LinearSVM.m スクリプトの実行結果
ここでは、スクリプトは最初に C=1 の場合の分類状況を読み込みます。逸脱点が判定境界を下回っており、効果が良くないことがわかります (下図の左側)。コード内で C=100 に変更した後、出力は下の図の右側にあります。C=100 は正則化係数 λ を小さくし、コスト関数における特徴量 x の前半の重みを大きくすることに相当するため、すでに乖離点が境界を超えていることがわかります。
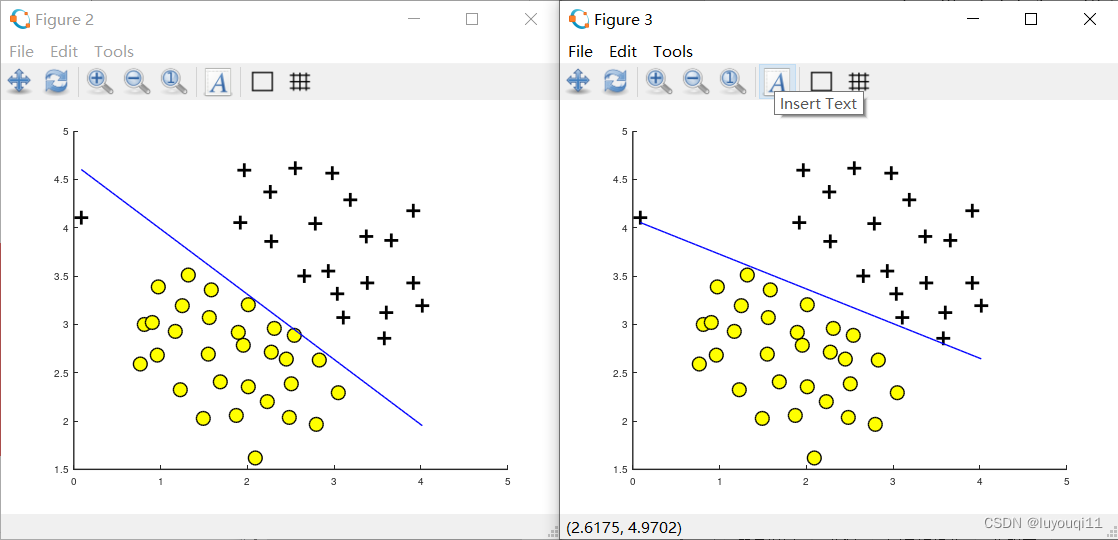
左側の図では、C = 1 で、SVM は 2 つのデータの間隔の間に決定境界を配置し、データ ポイントを誤ってさらに左に分割します。
右側の画像では、C = 100 で、SVM はすべてのサンプルを正しく分類していますが、この決定境界はデータに自然には適合しません。