目次
2. 単語周波数ベクトル/tf_idf のトレーニング パラメーターを初期化します。
3. CountVectorizer のトレーニングとアプリケーション関数
5. TfidfTransformer のトレーニングおよびアプリケーション関数
6. TfidfTransformer のトレーニングとアプリケーション関数
tf-idf は文体特徴抽出によく使われる統計手法の 1 つであり, テキスト分類タスクに適しています. この記事では tf-idf を原理から詳細に説明し, パラメータの詳細な説明と実際の実装を説明します. この記事をマスターすると,簡単に始めて、テキストデータの分類に使用できます。
1. 原則
tf は単語頻度(特定のテキストに単語が出現する回数 / テキスト内のすべての単語の数) を表し、idf は逆テキスト頻度(コーパス内に特定の単語を含むテキストの数の逆数) を表します。ログ)、tf-idf は単語頻度 * 逆ドキュメント頻度を表します。tf-idf は、単語の重要性はテキスト内に出現する回数に応じて直接増加しますが、同時に単語の頻度に反比例して減少すると信じています。コーパス全体におけるその出現。
idf 式は次のとおりです。ここで、k は特定の単語を含むテキストの数、n はコーパス全体のテキストの数です。
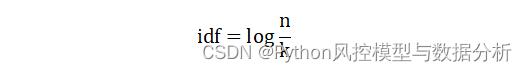
最大値/最小値を回避する Smooth IDF (smooth_idf=True)
2.実戦
sklearnで提供されるテキスト処理メソッド
(1) CountVectorizer : テキスト文書のコレクションを単語頻度/文字頻度行列に変換し、トークン化 (文字レベル + 単語レベルのセグメンテーション)、N グラム、ストップ ワードの削除、高頻度単語のフィルタリング、および出現カウント (頻度統計)
(2) TfidfTransformer : 単語頻度/文字頻度行列を標準化された tf 行列または tf-idf 行列に変換します. Tf は単語頻度を表し、tf-idf は単語頻度と逆文書頻度の積を表します. テキスト分類によく使用されます.
(3) TfidfVectorizer: 元のドキュメント コレクションを tf-idf 特徴行列に直接変換し、 CountVectorizer とTfidfTransformerのすべての関数を1 つのモデルに結合します。
実際の適用結果は次のとおりです (1 グラム + 2 グラム)。
この記事では、実際の例を使用して、これらのカテゴリの使用方法と機能を説明するとともに、さまざまなニーズでの自己使用を容易にするための詳細なパラメーターの説明を示します。

1. ガイドパッケージ
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer,TfidfTransformer,TfidfVectorizer2. 単語周波数ベクトル/tf_idf のトレーニング パラメーターを初期化します。
関数の組み合わせの問題により、TfidfVectorizer パラメーター = CountVectorizer パラメーター + TfidfTransformer パラメーターとなるため、初期化パラメーター関数はパラメーターの 3 つの部分を要約し、パラメーター ラベルを設定して、返される必要があるパラメーター ディクショナリを決定します。
def init_params(label='TfidfVectorizer'):
params_count={
'analyzer': 'word', # 取值'word'-分词结果为词级、'char'-字符级(结果会出现he is,空格在中间的情况)、'char_wb'-字符级(以单词为边界),默认值为'word'
'binary': False, # boolean类型,设置为True,则所有非零计数都设置为1.(即,tf的值只有0和1,表示出现和不出现)
'decode_error': 'strict',
'dtype': np.float64, # 输出矩阵的数值类型
'encoding': 'utf-8',
'input': 'content', # 取值filename,文本内容所在的文件名;file,序列项必须有一个'read'方法,被调用来获取内存中的字节;content,直接输入文本字符串
'lowercase': True, # boolean类型,计算之前是否将所有字符转换为小写。
'max_df': 1.0, # 词汇表中忽略文档频率高于该值的词;取值在[0,1]之间的小数时表示文档频率的阈值,取值为整数时(>1)表示文档频数的阈值;如果设置了vocabulary,则忽略此参数。
'min_df': 1, # 词汇表中忽略文档频率低于该值的词;取值在[0,1]之间的小数时表示文档频率的阈值,取值为整数时(>1)表示文档频数的阈值;如果设置了vocabulary,则忽略此参数。
'max_features': None, # int或 None(默认值).设置int值时建立一个词汇表,仅用词频排序的前max_features个词创建语料库;如果设置了vocabulary,则忽略此参数。
'ngram_range': (1, 2), # 要提取的n-grams中n值范围的下限和上限,min_n <= n <= max_n。
'preprocessor': None, # 覆盖预处理(字符串转换)阶段,同时保留标记化和 n-gram 生成步骤。仅适用于analyzer不可调用的情况。
'stop_words': 'english', # 仅适用于analyzer='word'。取值english,使用内置的英语停用词表;list,自行设置停停用词列表;默认值None,不会处理停用词
'strip_accents': None,
'token_pattern': '(?u)\\b\\w\\w+\\b', # 分词方式、正则表达式,默认筛选长度>=2的字母和数字混合字符(标点符号被当作分隔符)。仅在analyzer='word'时使用。
'tokenizer': None, # 覆盖字符串标记化步骤,同时保留预处理和 n-gram 生成步骤。仅适用于analyzer='word'
'vocabulary': None, # 自行设置词汇表(可设置字典),如果没有给出,则从输入文件/文本中确定词汇表
}
params_tfidf={
'norm': None, # 输出结果是否标准化/归一化。l2:向量元素的平方和为1,当应用l2范数时,两个向量之间的余弦相似度是它们的点积;l1:向量元素的绝对值之和为1
'smooth_idf': True, # 在文档频率上加1来平滑 idf ,避免分母为0
'sublinear_tf': False, # 应用次线性 tf 缩放,即将 tf 替换为 1 + log(tf)
'use_idf': True, # 是否计算idf,布尔值,False时idf=1。
}
if label=='CountVectorizer':
return params_count
elif label=='TfidfTransformer':
return params_tfidf
elif label=='TfidfVectorizer':
params_count.update(params_tfidf)
return params_count3. CountVectorizer のトレーニングとアプリケーション関数
def CountVectorizer_train(train_data,params):
cv = CountVectorizer(**params)
# 输入训练集矩阵,每行表示一个文本
# 训练,构建词汇表以及词项idf值,并将输入文本列表转成VSM矩阵形式
cv_fit = cv.fit_transform(train_data)
return cv
def CountVectorizer_apply(model):
print('词汇表')
print(model.vocabulary_)
print('------------------------------')
print('特证名/词汇列表')
print(model.get_feature_names())
print('------------------------------')
print('idf_列表')
print(model.idf_)
print('------------------------------')
data=['Tokyo Japan Chinese']
print('{} 文本转化VSM矩阵'.format(data))
print(model.transform(data).toarray())
print('------------------------------')
print('转化结果输出为dataframe')
print(pd.DataFrame(model.transform(data).toarray(),columns=model.get_feature_names()))
print('------------------------------')
print('model参数查看')
print(model.get_params())
print('------------------------------')4、CountVectorizer使用
train_data = ["Chinese Beijing Chinese",
"Chinese Chinese Shanghai",
"Chinese Macao",
"Tokyo Japan Chinese"]
params=init_params('CountVectorizer')
cv_model=CountVectorizer_train(train_data,params)
CountVectorizer_apply(cv_model)
結果を見ると、VSM 行列は単語頻度統計ではなく、実際には tf-idf の結果であることがわかります。

5. TfidfTransformer のトレーニングおよびアプリケーション関数
def TfidfTransformer_train(train_data,params):
tt = TfidfTransformer(**params)
tt_fit = tt.fit_transform(train_data)
return tt
def TfidfTransformer_apply(model):
print('idf_列表')
print(model.idf_)
print('------------------------------')
data=[[1, 1, 0, 2, 1, 1, 0, 1]]
print('词频列表{} 转化VSM矩阵'.format(data))
print(model.transform(data).toarray())
print('------------------------------')
print('model参数查看')
print(model.get_params())
print('------------------------------')
train_data=[[1, 1, 1, 0, 1, 1, 1, 0],
[1, 1, 0, 1, 1, 1, 0, 1]]
params=init_params('TfidfTransformer')
tt_model=TfidfTransformer_train(train_data,params)
TfidfTransformer_apply(tt_model)6. TfidfTransformer のトレーニングとアプリケーション関数
def TfidfVectorizer_train(train_data,params):
tv = TfidfVectorizer(**params)
# 输入训练集矩阵,每行表示一个文本
# 训练,构建词汇表以及词项idf值,并将输入文本列表转成VSM矩阵形式
tv_fit = tv.fit_transform(train_data)
return tv
def TfidfVectorizer_apply(tv_model):
print('tv_model词汇表')
print(tv_model.vocabulary_)
print('------------------------------')
print('tv_model特证名/词汇列表')
print(tv_model.get_feature_names())
print('------------------------------')
print('idf_列表')
print(tv_model.idf_)
print('------------------------------')
data=['Tokyo Japan Chinese']
print('{} 文本转化VSM矩阵'.format(data))
print(tv_model.transform(data).toarray())
print('------------------------------')
print('转化结果输出为dataframe')
print(pd.DataFrame(tv_model.transform(data).toarray(),columns=tv_model.get_feature_names()))
print('------------------------------')
print('tv_model参数查看')
print(tv_model.get_params())
print('------------------------------')
train_data = ["Chinese Beijing Chinese",
"Chinese Chinese Shanghai",
"Chinese Macao",
"Tokyo Japan Chinese"]
params=init_params('TfidfVectorizer')
tv_model=TfidfVectorizer_train(train_data,params)
TfidfVectorizer_apply(tv_model)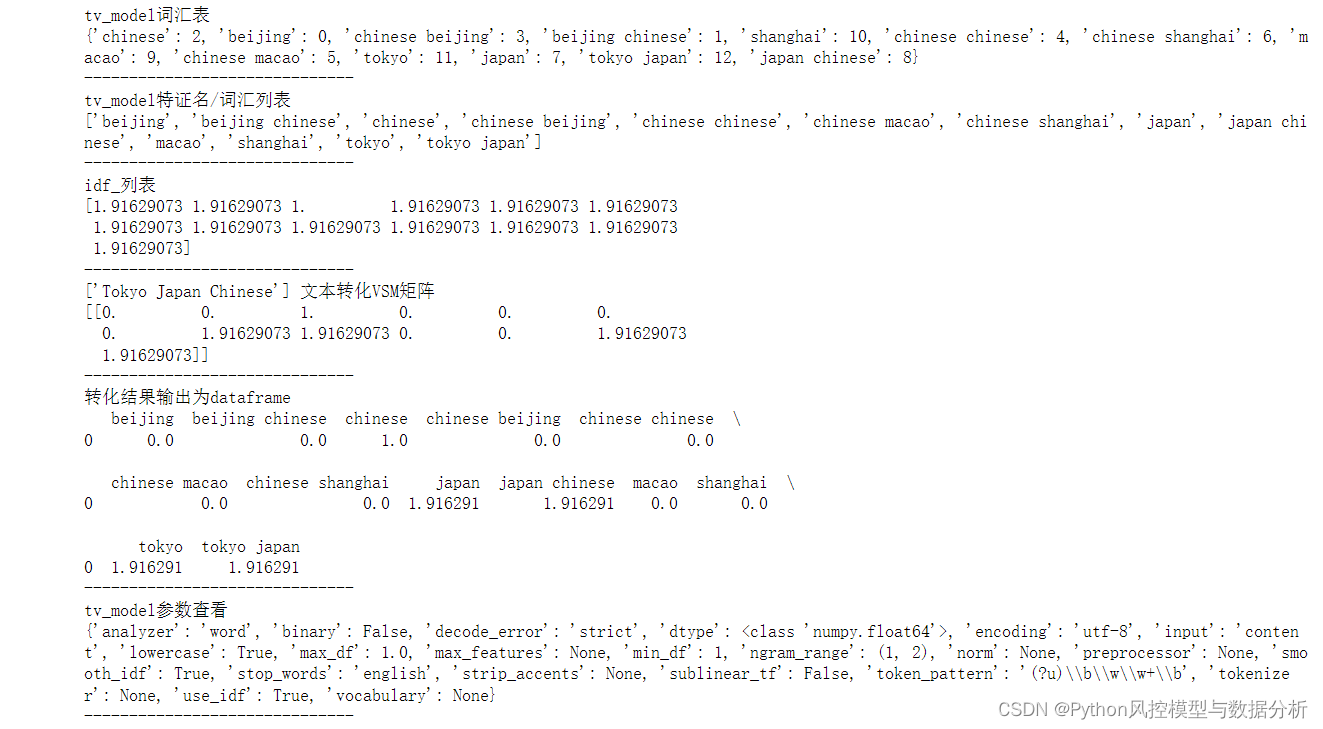
train_data の tf-idf 行列をデータフレーム結果に変換します
pd.DataFrame(tv_model.transform(train_data).toarray(),
columns=tv_model.get_feature_names())
3. 焦点を当てる
10年間の回り道を避ける
パブリックアカウントのPythonリスク管理モデルとデータ分析に注目して、tfidf実戦に返信してこの記事の.pyコードを取得し、何もしなくても直接呼び出してください。
注目に値しない理論、コード共有、無条件の出力が他にもあるでしょうか?