在当今的大数据时代,数据的处理和管理变得越来越复杂。特别是在分布式系统中,如何保证数据的一致性和完整性,是一个巨大的挑战。这就引出了我们今天要探讨的主题——分布式事务处理。分布式事务处理是一种技术,它能够在分布式系统中协调和管理事务,以确保数据的一致性和完整性。然而,实现有效的分布式事务处理并非易事,它涉及到许多复杂的问题和挑战,如网络延迟、系统故障、数据不一致等。在本文中,我们将深入探讨分布式事务处理的理论和实践,包括其基本原理、主要技术、实际应用,以及面临的挑战和可能的解决方案。我们希望通过这篇文章,帮助读者更深入地理解分布式事务处理,以及它在现代计算中的重要性。
1、分布式事务简介
1.1、分布式系统基础概述
分布式系统是由多个计算机节点通过网络连接,协同完成任务的系统。这些节点共享同一份数据,需要解决数据一致性、系统可用性、容错性等问题。分布式系统的主要挑战包括:数据一致性问题、节点通信问题、故障恢复问题等。
相关概念:
- 数据一致性:在分布式系统中,数据可能会被复制到多个节点上,当数据在一个节点上发生变化时,需要将这个变化同步到所有其他的节点上,以保证所有节点看到的数据是一致的;
- 系统可用性:分布式系统需要能够在节点失败的情况下继续提供服务。这通常需要通过冗余和负载均衡等技术来实现;
- 容错性:分布式系统需要能够处理节点的故障,当一个节点发生故障时,系统需要能够自动恢复,继续提供服务;
- 节点通信:分布式系统中的节点需要通过网络进行通信,这可能会引入延迟,影响系统的性能。此外,网络也可能会发生故障,导致节点之间的通信中断;
- 故障恢复:当分布式系统中的一个或多个节点发生故障时,系统需要能够自动检测并恢复这些故障,以保证系统的正常运行。
这些都是分布式系统设计和实现中需要解决的关键问题。
1.2、事务处理基础概述
事务是一个或多个数据操作的序列,它作为一个整体被执行,包括提交和回滚操作。事务需要满足 ACID(原子性、一致性、隔离性、持久性)四个特性。在单一数据库系统中,事务处理相对简单,数据库管理系统(DBMS)可以控制所有的操作,保证 ACID 特性。
事务需要满足ACID四个特性,具体解释如下:
- 原子性(Atomicity):事务中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
- 一致性(Consistency):事务必须保证数据库的状态从一个一致状态转变为另一个一致状态。一致状态的定义依赖于数据库的业务规则。
- 隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行。
- 持久性(Durability):已被提交的事务对数据库的修改是永久的,即使发生系统故障也不会丢失。
在单一数据库系统中,数据库管理系统(DBMS)可以通过锁和日志等机制来控制所有的操作,保证事务的ACID特性。然而,在分布式环境中,由于数据可能分布在多个节点上,事务处理就变得更加复杂。
1.3、分布式事务
当事务涉及到分布式系统中的多个节点时,就形成了分布式事务。分布式事务需要在多个节点之间保持数据的一致性,同时还要尽可能地提高系统的可用性和性能。这就需要使用一些特殊的技术和协议,如两阶段提交(2PC)、三阶段提交(3PC)、TCC(Try-Confirm-Cancel)等。
分布式事务处理是分布式系统和事务处理技术相结合的产物,它在很大程度上决定了分布式系统的性能和可靠性。
2、2PC协议与3PC协议介绍
2.1、两阶段提交协议
两阶段提交(2PC)是一种经典的分布式事务协议,它通过引入一个协调者来协调所有参与者的操作,确保所有参与者要么都提交事务,要么都不提交,从而保证了系统的一致性。
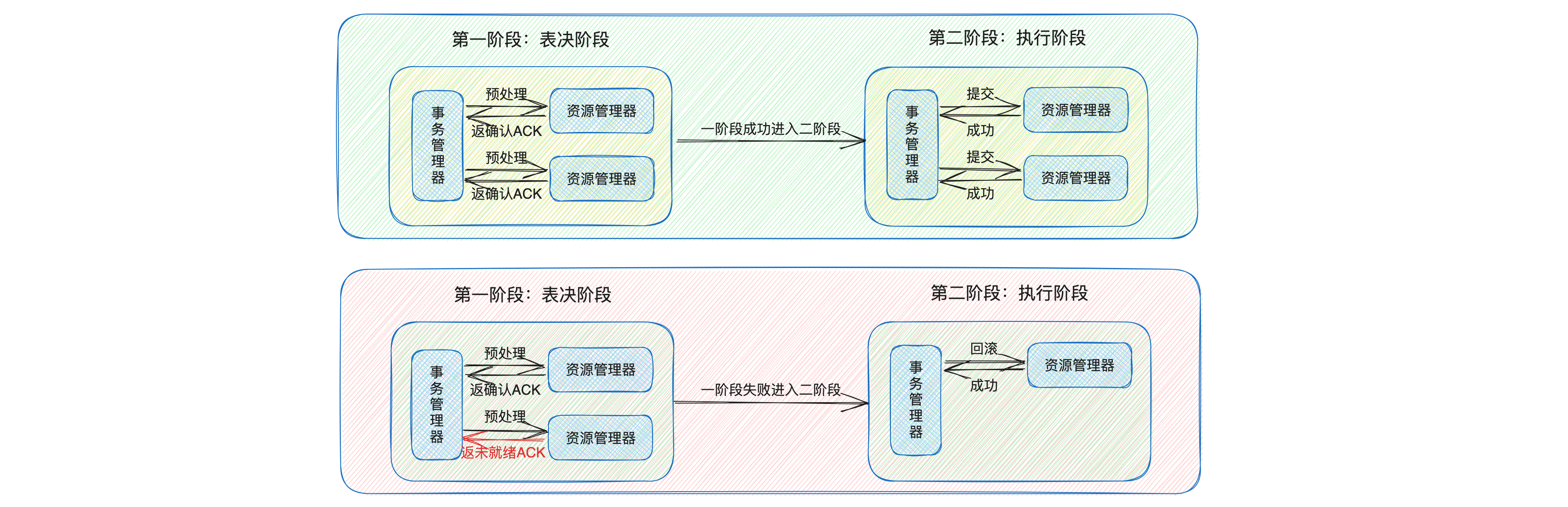
两阶段提交协议的过程可以分为两个阶段:
- 预提交阶段(表决阶段):在这个阶段,协调者向所有的参与者发送预提交请求,参与者接收到请求后,执行事务操作,并将操作结果反馈给协调者。如果所有的参与者都反馈操作成功,那么协调者决定进入下一阶段,否则,协调者向所有的参与者发送中止事务的请求;
- 提交阶段:在这个阶段,协调者向所有的参与者发送提交请求,参与者接收到请求后,提交事务,并释放在预提交阶段占用的资源。
两阶段提交协议虽然可以保证分布式事务的一致性,但是它也有一些缺点,比如同步阻塞问题和单点故障问题。
- 同步阻塞问题:在两阶段提交协议中,所有的参与者在等待其他参与者和协调者的响应时,都会进入阻塞状态。这会导致系统的性能下降;
- 单点故障问题:在两阶段提交协议中,协调者是一个关键的角色,它需要协调所有的参与者来完成事务。如果协调者发生故障,那么可能会导致整个事务无法完成。
因此,在实际的系统设计中,可能需要根据具体的业务需求和系统特性,选择更适合的分布式事务协议,如三阶段提交(3PC)协议、TCC(Try-Confirm-Cancel)模型等。这些协议和模型在一定程度上解决了两阶段提交协议的问题,提高了系统的性能和可靠性。
2.2、三阶段提交协议
三阶段提交(3PC)是对两阶段提交(2PC)的改进,主要是为了解决 2PC 中的阻塞问题。
3PC 协议将 2PC 的表决阶段分为了两个阶段:询问阶段(CanCommit)和 预提交阶段(PreCommit),然后再加上最后的 提交阶段(DoCommit),共三个阶段。
- 询问阶段(CanCommit):这个阶段类似于 2PC 的表决阶段,协调者向所有的参与者发送 CanCommit 请求,询问它们是否可以提交事务。每个参与者接收到 CanCommit 请求后,只是进行事务的预执行,并不会锁定资源,然后再回复协调者它是否可以提交事务。
- 预提交阶段(PreCommit):如果在 CanCommit 阶段,所有的参与者都回复了可以提交事务,那么协调者就向所有的参与者发送 PreCommit 请求,让它们准备提交事务。参与者在接收到 PreCommit 请求后,会锁定事务操作的资源,然后再回复协调者已经准备好提交事务。
- 提交阶段(DoCommit):如果在 PreCommit 阶段,所有的参与者都回复了已经准备好提交事务,那么协调者就向所有的参与者发送 DoCommit 请求,让它们提交事务。如果有任何一个参与者在 PreCommit 阶段回复了不能提交事务,那么协调者就向所有的参与者发送回滚请求,让它们回滚事务。
在 3PC 协议中,协调者和参与者都设置了超时机制,这样即使协调者发生故障,参与者也不会一直阻塞等待,而是在超时后自动提交或回滚事务,从而避免了长时间的阻塞。这是 3PC 协议相对于 2PC 协议的一个主要优点。
然而,这种机制也可能导致数据一致性问题。例如,如果由于网络原因,协调者发送的中断响应没有及时被参与者接收到,那么参与者在等待超时之后可能会执行提交操作,而其他接收到中断响应并执行回滚的参与者的数据就会和这个参与者的数据不一致。这是 3PC 协议的一个主要缺点。
因此,可以说 2PC 是一个强一致性协议,而 3PC 则通过牺牲一定的数据一致性来提高系统的可用性。在实际的系统设计中,需要根据系统的需求和特点,权衡一致性和可用性之间的关系,选择合适的分布式事务协议。
3、Paxos算法
3.1. Paxos アルゴリズムの概要
Paxos アルゴリズムは、分散システムにおける一貫性の問題を解決するために、1990 年に Leslie Lamport によって提案されたメッセージ パッシングベースの一貫性アルゴリズムです。Paxos アルゴリズムにより、分散システムでは、一部のノードに障害が発生した場合でも、確実に合意に達することができます。
Paxos アルゴリズムのプロセスは、複数ラウンドの 2 段階の提出プロセスとして見ることができます。ただし、2 フェーズ コミット プロトコルとは異なり、Paxos アルゴリズムでは新しい提案者がプロセスに参加することができますが、2 フェーズ コミット プロトコルでは許可されません。さらに、Paxos アルゴリズムには集中型のコーディネーターが存在せず、すべてのノードがプロポーザーとして機能できるため、ノード障害に対処する際に Paxos アルゴリズムがより柔軟で堅牢になります。
3.2. Paxos アルゴリズムの主な役割
Paxos アルゴリズムには、提案者、承認者、学習者の 3 つの主要な役割があります。
- 提案者: 提案者の主なタスクは、提案番号と提案値を含む提案を開始することです。提案者は、各提案の番号が一意であることを確認する必要があります。
- アクセプタ: アクセプタは提案の投票者であり、提案者が発行した提案に投票します。受信者は、同じ投票ラウンドで 1 つの提案のみを受け入れるようにする必要があります。
- 学習者: 学習者の主なタスクは、受け入れられた提案を学習することです。提案が受信者の半数以上に受け入れられた場合、その提案はシステムによって受け入れられたとみなされ、学習者はその提案を学習する必要があります。
Paxos アルゴリズムのプロセスでは、最初に提案者が提案を開始し、次に受け入れ者がその提案に投票し、最後に学習者が受け入れられた提案を学習します。このプロセスを通じて、Paxos アルゴリズムは分散システムで合意に達することができます。
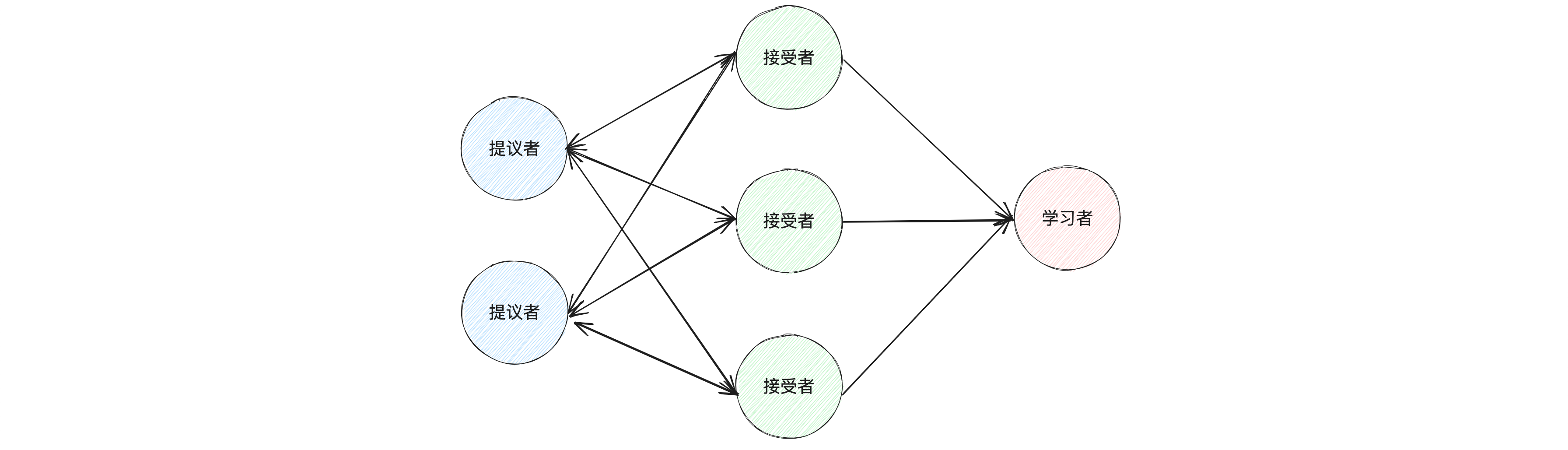
基本的なPaxosアルゴリズムでは、ノードはこれらの3つの役割を同時に再生できます。たとえば、Googleのぽっちゃりシステムでは、各ノードは提案者、アクセプター、学習者の両方です。これにより、システムの耐障害性が向上し、一部のノードに障害が発生した場合でも、システムは正常に実行できます。
关于提案:在 Paxos 算法中,提案(Proposal)是由提议者(Proposer)发起的,用于在分布式系统中达成一致性决定。一个提案主要包含两部分内容:提案编号(Proposal Number)和提案值(Proposal Value)。
- 提案编号(Proposal Number):这是一个全局唯一的编号,用于标识不同的提案。在 Paxos 算法中,提案编号需要满足两个条件:一是每个提议者发起的每个新提案的编号都必须大于该提议者之前发起的所有提案的编号;二是每个提案编号都必须是全局唯一的,即不同提议者发起的提案不能有相同的编号;
- 提案值(Proposal Value):这是提案的具体内容,即提议者希望系统达成一致的决定。
3.3、Paxos算法-准备阶段
准备阶段(Prepare)。在这个阶段,提议者(Proposer)选择一个提案编号,并将其发送给所有的接受者(Acceptor)。接受者收到提案编号后,如果该编号比它之前看到的所有提案编号都大,那么它就会接受这个提案编号,并向提议者返回之前接受的提案信息。
接下来我们举一个例子:我们假设客户端 1 的提案编号为 1,客户端 2 的提案编号为 5,并假设节点 A、B 先收到来自客户端 1 的准备请求,节点 C 先收到来自客户端 2 的准备请求。
在准备阶段,首先客户端 1、2 作为提议者,分别向所有接受者发送包含提案编号的准备请求:
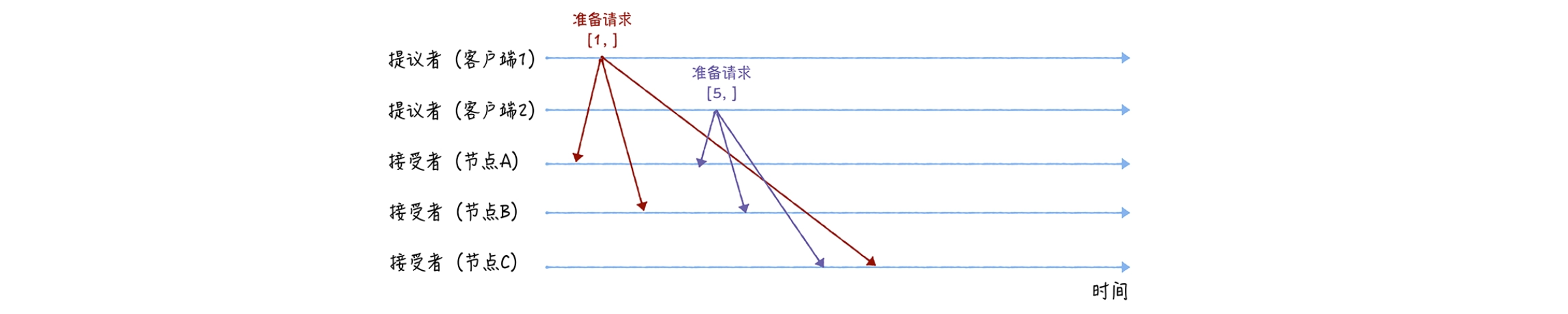
Ps:需要注意的是,在准备请求中是不需要指定提议的值的,只需要携带提案编号就可以了
接着,当节点 A、B 收到提案编号为 1 的准备请求,节点 C 收到提案编号为 5 的准备请求后,将进行这样的处理:
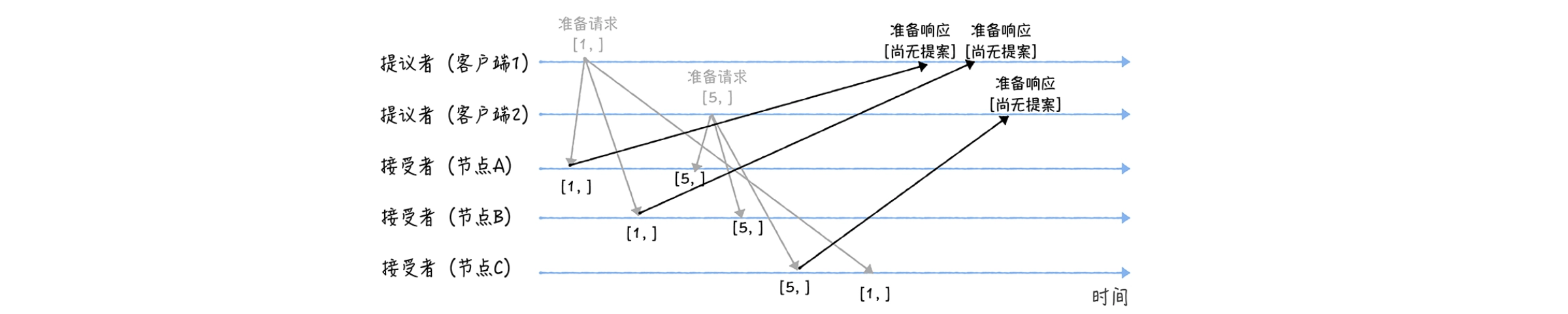
对于节点 A、B,由于之前没有通过任何提案,所以返回一个"尚无提案"的响应。也就是说节点 A 和 B 在告诉提议者,我之前没有通过任何提案呢,并承诺以后不再响应提案编号小于等于 1 的准备请求,不会通过编号小于 1 的提案;
节点 C 也是如此,它将返回一个"尚无提案"的响应,并承诺以后不再响应提案编号小于等于 5 的准备请求,不会通过编号小于 5 的提案
另外,当节点 A、B 收到提案编号为 5 的准备请求,和节点 C 收到提案编号为 1 的准备请求的时候,将进行这样的处理过程:
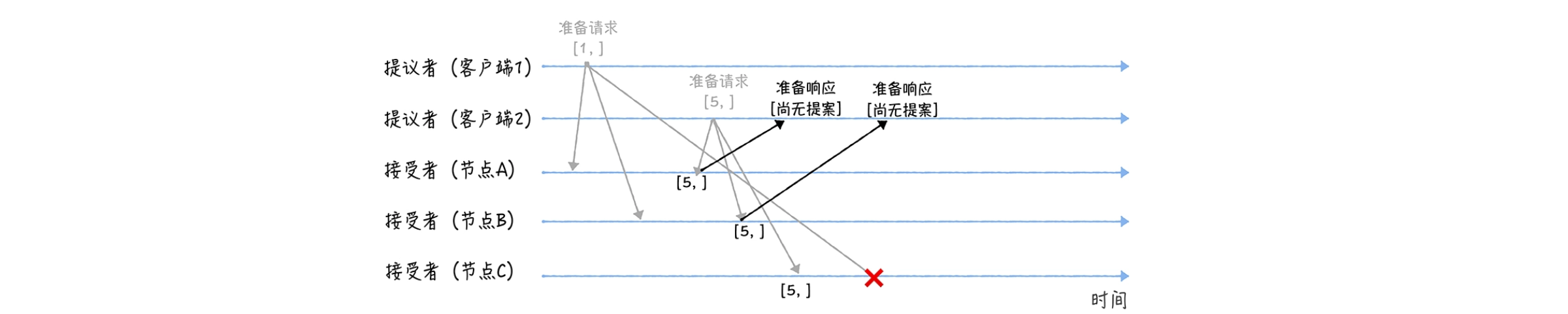
当节点 A、B 收到提案编号为 5 的准备请求的时候,因为提案编号 5 大于它们之前响应的准备请求的提案编号 1,而且两个节点都没有通过任何提案,所以它将返回一个"尚无提案"的响应,并承诺以后不再响应提案编号小于等于 5 的准备请求,不会通过编号小于 5 的提案;
当节点 C 收到提案编号为 1 的准备请求的时候,由于提案编号 1 小于它之前响应的准备请求的提案编号 5,所以丢弃该准备请求,不做响应。
Ps:在 Paxos 算法的过程中,提议者首先会在准备阶段(Prepare 阶段)发送一个带有提案编号的准备请求给所有的接受者。如果接受者没有接受这个提案,可能是因为这个提案编号小于接受者之前接受的提案编号。此时,提议者需要选择一个新的、更大的提案编号,然后重新发起准备请求。
3.4、Paxos算法-接受阶段
接受阶段(Accept)。在这个阶段,提议者根据接受者的反馈,选择一个提案值,然后将提案编号和提案值一起发送给所有的接受者。接受者收到提案后,如果提案编号不小于它之前接受的所有提案编号,那么就接受这个提案。
紧接着上面的例子
在接受阶段,首先客户端 1、2 在收到大多数节点的准备响应之后,会分别发送接受请求:
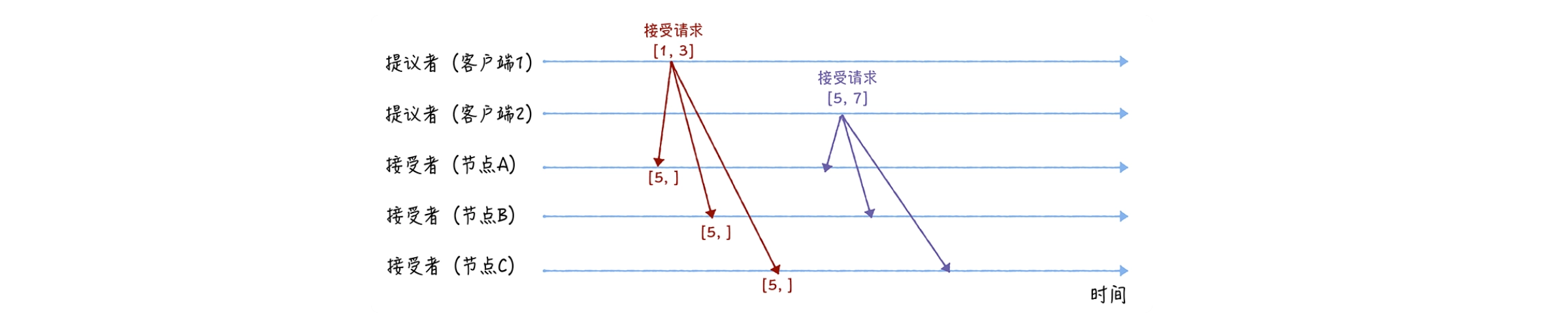
当客户端 1 收到大多数的接受者(节点 A、B)的准备响应后,根据响应中提案编号最大的提案的值,设置接受请求中的值。因为该值在来自节点 A、B 的准备响应中都为空,所以就把自己的提议值 3 作为提案的值,发送接受请求 [1, 3];
当客户端 2 收到大多数的接受者的准备响应后(节点 A、B 和节点 C),根据响应中提案编号最大的提案的值,来设置接受请求中的值。因为该值在来自节点 A、B、C 的准备响应中都为空,所以就把自己的提议值 7。作为提案的值,发送接受请求 [5, 7]。
当三个节点收到 2 个客户端的接受请求时,会进行这样的处理:
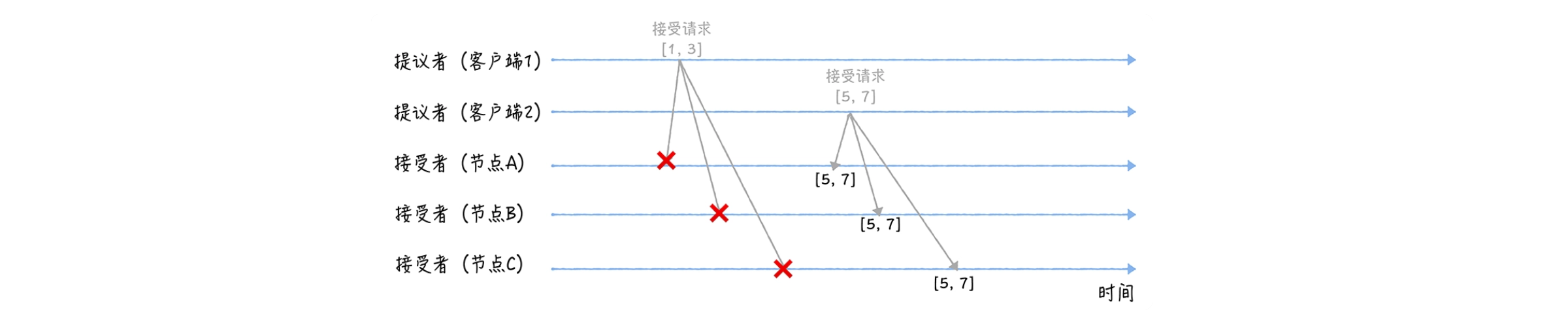
当节点 A、B、C 收到接受请求 [1, 3] 的时候,由于提案的提案编号 1 小于三个节点承诺能通过的提案的最小提案编号 5,所以提案 [1, 3] 将被拒绝;
当节点 A、B、C 收到接受请求 [5, 7] 的时候,由于提案的提案编号 5。不小于三个节点承诺能通过的提案的最小提案编号 5,所以就通过提案 [5, 7],也就是接受了值 7,三个节点就 X 值为 7 达成了共识。
Ps:如果在接受阶段(Accept 阶段),提议者发送的带有提案编号和提案值的接受请求没有被任何接受者接受,那么提议者同样需要选择一个新的、更大的提案编号,然后重新发起接受请求。
通过这种方式,Paxos 算法可以确保即使有提案没有被接受,提议者也可以通过重新提交提案,最终达成一致性决定。所以,提议者的提案不会被丢弃,而是会被重新提交,直到被接受。
Ps:如果集群中有学习者,当接受者通过了一个提案时,就通知给所有的学习者。当学习者发现大多数的接受者都通过了某个提案,那么它也通过该提案,接受该提案的值。
3.5、关于Multi-Paxos算法
Multi-Paxos 是 Paxos 算法的一种优化版本,它在 Basic Paxos 的基础上进行了改进,以提高系统的性能和可用性。
在 Basic Paxos 中,每次只能对一个决定进行一致性协商,每个决定都需要经过两个阶段:准备阶段和接受阶段。这意味着每次决定都需要进行至少两轮的消息传递,这在网络延迟较大或者需要频繁进行一致性决定的场景下,可能会导致性能问题。
Multi-Paxos は、リーダーの概念を導入することにより、メッセージ送信の数を減らし、システムのパフォーマンスを向上させます。マルチパクソスではリーダーが選出され、リーダーは提案を提案する責任を負います。他のノードがリーダーの提案を受け入れた後は、リーダーが失敗しない限り、リーダーからの後続のすべての提案を受け入れます。これにより、最初の提案は準備段階と承認段階を経る必要があり、それ以降の提案は承認段階を経るだけで済むため、メッセージの送信回数が削減されます。
一般に、マルチパクスはメッセージ送信の数を減らし、基本的なPaxosに基づいてリーダーの概念を導入することにより、システムのパフォーマンスと可用性を向上させます。
4. RAFTアルゴリズム
4.1. Raft アルゴリズムの概要
Raft アルゴリズムは、2013 年に Diego Ongaro と John Ousterhout によって提案された Multi-Paxos アルゴリズムに基づくコンセンサス アルゴリズムであり、Lambert の Multi-Paxos のアイデアに基づいて簡略化および制限されており、たとえば、ログが連続的でなければならないことが要求されます。リーダー、フォロワー、候補者の 3 つの状態のみを定義するため、Raft アルゴリズムの理解と実装が Multi-Paxos よりも簡単になります。
したがって、Raft アルゴリズムは、現在の分散システム開発で推奨されるコンセンサス アルゴリズムとなっています。Paxos アルゴリズムを使用するほとんどのシステム (Cubby、Spanner など) は、Raft アルゴリズムがリリースされる前、他に選択肢がなかったときに開発されました。現在、ほとんどの新しいシステム (Etcd、Consul、CockroachDB など) は Raft アルゴリズムを使用することを選択しています。
Raft アルゴリズムの主な機能は次のとおりです。
- 理解と実装が簡単: Paxos アルゴリズムと比較して、Raft アルゴリズムはよりシンプルかつ直観的であり、理解と実装が容易です。
- 強力なリーダー: Raft アルゴリズムには明確なリーダーが存在し、すべての決定はリーダーによって行われるため、意思決定プロセスが簡素化されます。
- ログの一貫性: Raft アルゴリズムでは、すべてのレプリケーション ノードのログが一貫している必要があり、これによりシステムの一貫性が確保されます。
- 3つの状態:RAFTアルゴリズムのノードには、リーダー、フォロワー、候補の3つの状態しかありません。これにより、状態の移行がより明確かつシンプルになります。
上記の特性により、Raft アルゴリズムは分散システム開発で広く使用されており、Etcd、Consul、CockroachDB などの多くの新しい分散システムで Raft アルゴリズムの使用が選択されています。
4.2。ラフトアルゴリズムの主な役割
Raft アルゴリズムには、リーダー、フォロワー、候補者の 3 つの主要な役割があります。
- リーダー: リーダーは、すべてのクライアント インタラクション、ログ レプリケーション、その他の重要なタスクの処理を担当し、他のすべてのサーバーはリーダーからエントリをコピーします。
- フォロワー:フォロワーは主にリーダーからログエントリを受け取り、それを独自のログに書き込みます。フォロワーはクライアントのリクエストを直接処理することはできませんが、リーダーにリクエストを転送することはできます。
- 候補者:フォロワーが一定の期間リーダーからメッセージを受け取らない場合、候補者になる可能性があります。候補者は他のノードから投票を要求し、ノードの大部分から投票を受けた場合、それは新しいリーダーになります。
RAFTアルゴリズムでは、すべてのノードが初期状態のフォロワーです。フォロワーがリーダーから鼓動を受け取らない場合、それは候補者になり、選挙を開始します。新しいリーダーが選出されると、ネットワークは安定した状態に戻ります。
4.2. Raft アルゴリズムによるリーダー選出のプロセス
ラフトアルゴリズムの選挙プロセスには、主に次の手順が含まれています。
-
選挙を開始する:フォロワーがしばらくの間リーダーから鼓動を受け取らない場合、それは候補者になり、新しい選挙を開始します。この期間はしばしば選挙のタイムアウトと呼ばれ、複数のノードが同時に選挙を開始するのを防ぐためにランダム化されます。
-
投票を要求する: 候補者はまず自分の任期番号 (Term Number) を増やし、次に投票要求 (RequestVote) メッセージを他のすべてのノードに送信します。
-
投票: 他のノードは、投票を要求するメッセージを受信した後、以前に投票したことがなく、候補者のログが少なくとも自分のものと同じくらい新しい場合、その候補者に投票します。
-
票の獲得: 候補者が選挙ラウンドで過半数のノードから票を獲得すると、その候補者が新しいリーダーになります。
-
リーダーになる: リーダーになった後、新しいリーダーは他のノードにハートビート メッセージを送信して、自分が新しいリーダーであることを伝えます。
通过这个过程,Raft 算法可以在领导者发生故障的情况下,选举出新的领导者,保证系统的正常运行。
为了方便理解,我以图例的形式演示一个典型的领导者选举过程。
首先,在初始状态下,集群中所有的节点都是跟随者的状态。

Raft 算法实现了随机超时时间的特性。也就是说,每个节点(Node)等待领导者节点心跳信息的超时时间间隔(Timeout)是随机的。通过上面的图片你可以看到,集群中没有领导者,而节点 A 的等待超时时间最小(150ms),它会最先因为没有等到领导者的心跳信息,发生超时。
这个时候,节点 A 就增加自己的任期编号(Term Number),并推举自己为候选人,先给自己投上一张选票(Vote),然后向其他节点发送请求投票 RPC 消息,请它们选举自己为领导者。
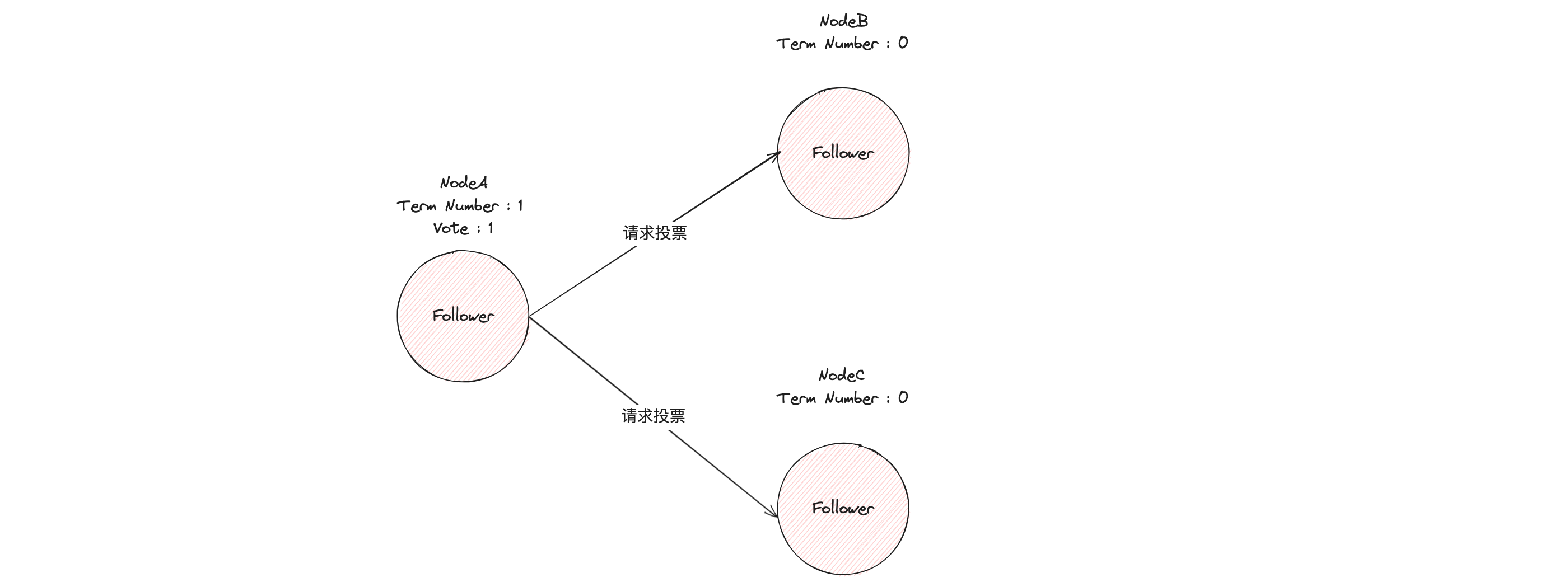
如果其他节点接收到候选人 A 的请求投票 RPC 消息,在编号为 1 的这届任期内,也还没有进行过投票,那么它将把选票投给节点 A,并增加自己的任期编号。
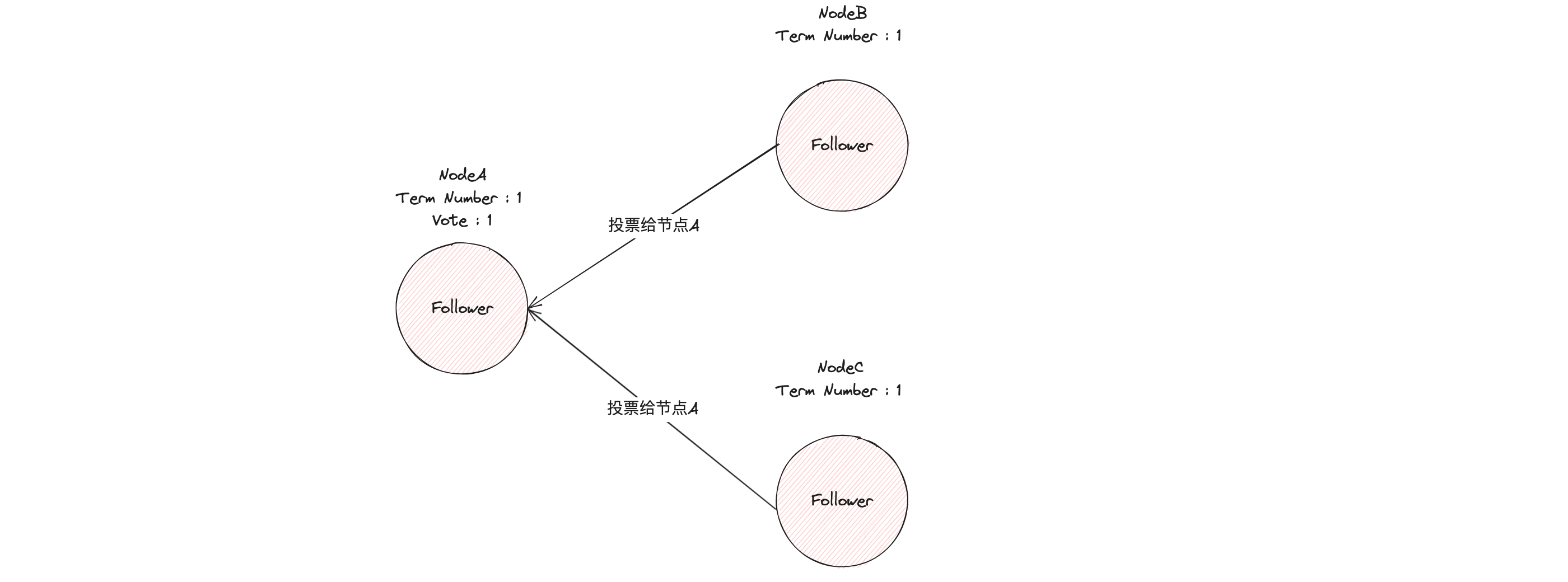
如果候选人在选举超时时间内赢得了大多数的选票,那么它就会成为本届任期内新的领导者。

节点 A 当选领导者后,他将周期性地发送心跳消息,通知其他服务器我是领导者,阻止跟随者发起新的选举,篡权。
4.3、Raft算法选举过程的相关定义
Raft算法选举过程的一些相关定义:
- 节点间通讯:在 Raft 算法中,节点间的通讯主要通过远程过程调用(RPC)来实现。主要的 RPC 包括请求投票(RequestVote)和附加日志(AppendEntries)。
- 任期:在 Raft 算法中,任期(Term)是一个逻辑时钟,用来区分不同的选举周期。每当开始新一轮的选举,任期号就会增加。任期号也用于防止过期的信息造成的干扰。
- 选举规则:在 Raft 算法的选举过程中,有两个主要的规则。一是,一个节点只能投票给第一个向它请求投票的候选人,并且这个候选人的日志至少和自己一样新。二是,一个候选人必须获得大多数节点的选票,才能成为新的领导者。
- 随机超时时间:在 Raft 算法中,随机超时时间是用来触发新一轮选举的。当一个跟随者在超时时间内没有收到领导者的心跳,它就会变成候选人,开始新一轮的选举。这个超时时间是随机的,以防止多个节点同时开始选举。
4.4、Raft算法日志结构
Raft 算法通过日志复制(Log Replication)来完成分布式事务处理。
在 Raft 算法中,日志项(Log Entry)是一种关键的数据结构,它主要包含以下部分:
- 指令(Command):这是由客户端发送给领导者的操作请求,比如添加一个新的键值对;
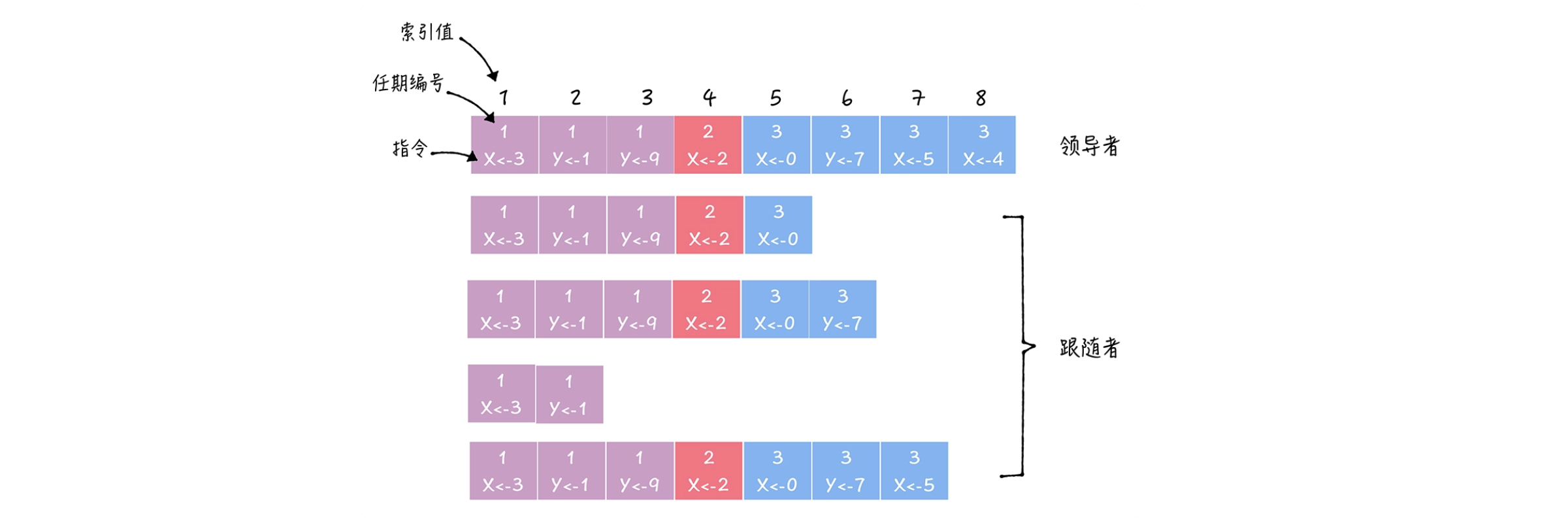
- 索引值(Log Index):这是一个唯一的数字,用于标识这个日志项在日志中的位置。索引是按照日志项被添加到日志的顺序递增的;
- 任期编号(Term):这是一个数字,用于标识这个日志项是在哪个任期中添加的。任期编号可以用于判断日志项的新旧。
通过这种结构,Raft 算法的日志可以保存系统中的所有操作,并保证这些操作在所有的节点上都能按照相同的顺序执行,从而实现系统的一致性。
4.5、Raft算法日志复制
可以把 Raft 的日志复制理解成一个优化后的二阶段提交(将二阶段优化成了一阶段),减少了一半的往返消息,也就是降低了一半的消息延迟。那日志复制的具体过程是什么呢?
在这个过程中,领导者(Leader)首先将日志项复制到其他的跟随者(Follower),然后等待大多数的跟随者确认。一旦大多数的跟随者都已经确认,领导者就会将这个日志项应用到自己的状态机,并返回成功给客户端。
这个过程中的一个关键优化是,领导者不直接通知跟随者提交日志项。而是通过日志复制或心跳消息,让跟随者知道领导者的日志提交位置。当跟随者接收到领导者的心跳消息或新的日志复制消息后,就会将这个日志项应用到自己的状态机。
这个优化降低了处理客户端请求的延迟,将二阶段提交优化为了一阶段提交,降低了一半的消息延迟。这是 Raft 算法实现分布式一致性的一个重要机制。
日志复制的过程主要包括以下步骤:
- クライアントはリクエストを送信します。クライアントに新しい操作リクエストがある場合、そのリクエストはリーダー (リーダー) に送信されます。
- リーダーはログ エントリを追加します。クライアントのリクエストを受信した後、リーダーはそのリクエストを新しいログ エントリとして自分のログに追加します。
- リーダーコピーログエントリ:リーダーは、新しいログエントリを他のフォロワー(フォロワー)にコピーします。
- フォロワーはログ エントリを書き込みます。リーダーからレプリケーション リクエストを受信した後、フォロワーは新しいログ エントリを自身のログに書き込みます。
- リーダーはログ エントリをコミットします。ほとんどのフォロワーが新しいログ エントリを書き込んだ場合、リーダーはログ エントリをコミット済みとしてマークし、そのログ エントリを自身のステート マシンに適用します。
- リーダーは、ログ エントリを送信するようにフォロワーに通知します。リーダーは、ログ エントリが次のハートビート メッセージで送信されたことをフォロワーに伝え、フォロワーはこのログ エントリを自身のステート マシンにも適用する必要があります。
このプロセスを通じて、Raft アルゴリズムは、システム内のすべてのノードが同じ操作を認識し、同じ順序で実行することを保証し、それによってシステムの一貫性を実現します。
4.6. Raftメンバーの変更
Raft アルゴリズムでは、メンバーの変更は重要かつ複雑なプロセスです。メンバー変更プロセス中に 2 人のリーダーが出現することを避けるために、Raft アルゴリズムはジョイント コンセンサス (Joint Consensus) 方式を採用しています。
共同コンセンサス方式では、Raft アルゴリズムは最初に古いノードと新しいノードを含む新しい構成を作成します。次に、リーダーはこの新しい構成をログ エントリとしてログに追加し、このログ エントリを他のノードに複製します。ほとんどの古いノードと新しいノードが新しい構成を作成すると、リーダーはこの構成を送信し、それを自身のステート マシンに適用します。最後に、リーダーは他のノードに新しい構成が送信されたことを伝え、他のノードも新しい構成を自身のステート マシンに適用する必要があります。
このプロセスにより、メンバーシップの変更中に、古いノードと新しいノードのほとんどが新しい構成を受け入れた場合にのみ、システムが新しい構成に切り替わることが保証されます。これにより、メンバー変更時にリーダーが 2 名になることが回避されます。
さらに、共同コンセンサス方式は実装が難しいため、Raft アルゴリズムを改良したシングルサーバー変更が登場し、メンバー変更のプロセスを簡素化できますが、システムの一貫性を確保するために追加のメカニズムが必要です。 。
5. その他の分散トランザクション モデル
5.1、TCC模型
TCC模型:TCC(Try-Confirm-Cancel)模型是一种两阶段提交的补偿型事务模型。在 TCC 模型中,事务分为两个阶段:尝试阶段(Try)和确认阶段(Confirm)。在尝试阶段,事务会预留必要的系统资源。在确认阶段,事务会真正地执行操作,并释放预留的资源。如果在确认阶段发生错误,事务会执行取消阶段(Cancel),撤销在尝试阶段执行的操作。
TCC(Try-Confirm-Cancel)模型作为一种两阶段提交的补偿型事务模型,主要包含以下三个阶段:
- Try 阶段:这个阶段主要是对业务系统进行检查以及预留必要的业务资源;
- Confirm 阶段:这个阶段主要是对 Try 阶段预留的业务资源进行确认,Try 阶段执行成功则 Confirm 阶段必须要能够成功。这个阶段如果失败会重试,直到成功或者达到最大重试次数;
- Cancel 阶段:这个阶段主要是在业务执行失败,进行业务的回滚,取消 Try 阶段预留的业务资源。同 Confirm 阶段,这个阶段如果失败会重试,直到成功或者达到最大重试次数。
TCC 模型的优点是可以提供较好的业务一致性保证,而且它是在应用层面进行控制,不依赖底层数据库等中间件的支持。但是,TCC 模型的缺点是需要修改业务代码,为每个操作提供 Try、Confirm 和 Cancel 三个操作,增加了开发的复杂性。
5.2、SAGA模型
SAGA模型:SAGA 是一种长寿命事务的处理模型。在 SAGA 模型中,一个长寿命事务被分解为一系列的子事务,这些子事务可以独立地执行,并且可以在不同的时间点执行。如果一个子事务失败,SAGA 会执行一系列的补偿操作,撤销已经执行的子事务。这种模型适合处理长寿命事务和分布式事务。
SAGA模型主要包含以下三个步骤:
- 拆分事务:将一个长事务拆分为多个子事务,每个子事务都可以独立完成并提交。
- 执行事务:按照一定的顺序执行这些子事务。如果所有的子事务都执行成功,那么整个长事务就执行成功。
- 補償トランザクション: サブトランザクションの実行中にサブトランザクションが失敗した場合は、補償操作を実行する必要があります。報酬操作は、データの一貫性を確保するために正常に実行されたサブトランザクションをロールバックすることです。
SAGA モデルの利点は、長時間のトランザクションとサービス オーケストレーションを処理でき、2PC や 3PC のような基盤となるデータベースなどのミドルウェアのサポートに依存する必要がないことです。ただし、SAGA モデルの欠点は、サブトランザクションごとに補償操作を提供する必要があり、開発の複雑さが増大することです。同時に、補正操作が失敗した場合、データの不整合が発生する可能性があります。
5.3. ZABモデル
ZAB(Zookeeper Atomic Broadcast)モデルは、Zookeeperが使用する一貫性プロトコルです。ZABプロトコルは、主にすべてのサーバーの状態の一貫性を確保するために使用されます。特に、リーダーがクラッシュしてサービス状態の一貫性を確保するために新しいリーダーが選出された場合。ZABプロトコルには、クラッシュリカバリとメッセージブロードキャストの2つの基本モードが含まれています。
- クラッシュ リカバリ: リーダーがクラッシュするか、ネットワークが分断されると、ZooKeeper はクラッシュ リカバリ モードに入ります。このモードでは、残りのノードが新しいリーダーを選出します。新しいリーダーが選出された後、他のノードと同期して、すべてのノードの状態が一貫していることを確認する必要があります。
- メッセージ ブロードキャスト: リーダーが選出され、すべてのノードのステータスが一貫している場合、ZooKeeper はメッセージ ブロードキャスト モードに入ります。このモードでは、すべてのトランザクション要求がリーダーに転送されます。リーダーがトランザクション リクエストを処理するとき、最初にトランザクション リクエストを提案としてすべてのフォロワーにブロードキャストします。ほとんどのフォロワーが提案を受け入れたら、リーダーは提案を提出し、すべてのフォロワーに提案を提出するように通知します。
このように、ZAB プロトコルは分散環境におけるシステムの一貫性を確保できます。
ZAB (ZooKeeper Atomic Broadcast) プロトコルは、ZooKeeper で使用される一貫性プロトコルであり、次の利点があります。
-
強い一貫性: ZAB プロトコルは、分散環境内のすべてのノードが同じ状態を認識し、同じ順序で操作を実行できることを保証し、それによって強い一貫性を実現します。
-
フォールト トレランス: ZAB プロトコルは、新しいリーダーを選択し、すべてのノードのステータスを同期することで、リーダーがクラッシュした後にシステムの一貫性を復元できます。
-
高可用性:ZAB 协议通过在多个节点上复制状态,可以提供高可用性。即使部分节点崩溃,只要有大多数的节点还在运行,系统就可以继续提供服务。
-
顺序保证:ZAB 协议可以保证所有的事务请求都按照一定的全局顺序被执行。这对于需要顺序一致性的应用来说非常重要。
-
简单性:ZAB 协议的设计和实现都相对简单,易于理解和使用。
由于篇幅有限,本片文章不对 ZAB 做更多详细分析介绍…
6、分布式事务处理的实践、优化和未来发展
6.1、分布式事务处理实践
在实际的分布式系统中,处理分布式事务是一个重要的问题。以下是一些常用的开源框架和工具:
-
Seata:Seata 是阿里巴巴开源的一款分布式事务解决方案,提供了 AT、TCC、SAGA 和 XA 四种分布式事务模式。Seata 通过全局事务 ID XID 来协调微服务之间的事务,并通过 UndoLog 的方式来实现事务的回滚,在网络或者应用级别的故障时保证事务的一致性。
-
RocketMQ:RocketMQ 是阿里巴巴开源的一款消息中间件,它的分布式事务主要是通过半消息和回查机制来实现的。生产者发送半消息后,RocketMQ 会定期回查生产者,确认这个消息是否可以被消费。
-
Apache Kafka:Kafka 是一款开源的流处理平台,它通过 Exactly-Once Semantics 机制来保证分布式事务的一致性。Kafka 的事务是通过事务 ID 来标识的,生产者在开始一个事务时会向 Kafka 的事务协调器发送 InitProducerId 请求来获取事务 ID。
-
Apache Flink:Flink 是一款开源的流处理框架,它通过 Checkpoint 机制来保证分布式事务的一致性。Flink 的 Checkpoint 机制会定期保存系统的状态,当系统出现故障时,可以从最近的 Checkpoint 恢复。
以上这些框架和工具都提供了强大的分布式事务处理能力,可以根据实际的业务需求和系统环境选择合适的工具。
6.2、分布式事务处理的优化和改进
分散トランザクション処理では、最適化と改善は主に次の側面に焦点を当てます。
-
ロックの使用を減らす: ロックはトランザクションの一貫性を確保するための重要なメカニズムですが、ロックが多すぎるとシステムのパフォーマンスが低下します。したがって、トランザクションの設計と実行シーケンスを最適化することで、ロックの使用を減らし、システムの同時実行性を向上させることができます。
-
非同期およびバッチ処理: 分散トランザクションを処理する場合、ネットワーク通信は大きなオーバーヘッドになります。非同期通信とバッチ処理を使用して、ネットワーク通信の数と遅延を減らし、システムのパフォーマンスを向上させることができます。
-
最終的な整合性を使用する: シナリオによっては、特定のデータの不整合が許容されます。これらのシナリオでは、最終的にはベースプロトコルなどの一貫したプロトコルを使用して、2フェーズのコミットプロトコルなどの強力な一貫したプロトコルを置き換えて、システムパフォーマンスを改善できます。
-
補償トランザクションを使用する: 一部のシナリオでは、補償トランザクションを使用してトランザクションの失敗を処理できます。補償トランザクションは、トランザクションが失敗した後にシステムの一貫性を復元するためにいくつかの操作を実行できます。この方法ではシステムの信頼性を向上させることができますが、適切な補償操作の設計が必要です。
-
永続性とロギングを使用する: 永続性とロギングを通じて、システム クラッシュ後にトランザクションの状態を復元し、システムの一貫性を確保できます。同時に、ログを使用してシステムの問題を監視および診断することもできます。
実際のシステムでは、システムの特性やニーズに応じて、適切な最適化・改善手法を選択する必要があります。
6.3. 分散トランザクション処理の今後の展開
マイクロサービスとクラウド コンピューティングの発展に伴い、分散トランザクション処理の重要性がますます高まっています。以下に考えられる将来の開発傾向と研究の方向性をいくつか示します。
-
弾力性と適応性: システムの規模が拡大し、ビジネス要件が変化するにつれて、分散トランザクション処理はより弾力性と適応性が高く、システムの状態と負荷に応じてトランザクション処理戦略とパラメーターを動的に調整できる必要があります。
-
効率的でスケーラブル: データ量が増加するにつれて、分散トランザクション処理は効率的なパフォーマンスを維持しながら、より大きなトランザクションを処理できる必要があります。これには、並列および分散されたトランザクション処理アルゴリズムなど、より効率的なデータ構造とストレージテクノロジーなどの新しいアルゴリズムとテクノロジーが必要になる場合があります。
-
フォールトトレランスとリカバリ: システムの複雑さが増すにつれて、障害やエラーがより一般的になります。分散トランザクション処理には、トランザクションの一貫性を確保しながら障害が発生した場合に迅速に回復できる、より強力なフォールト トレランスと回復機能が必要です。
-
セキュリティとプライバシー: データのセキュリティとプライバシーの重要性が高まる中、分散トランザクション処理では、一貫性を確保しながらデータのセキュリティとプライバシーを保護する方法を検討する必要があります。
-
新しいコンピューティング モデル: 量子コンピューティングやエッジ コンピューティングなどの新しいコンピューティング モデルの開発に伴い、これらの新しいコンピューティング モデルの特性に適応するために、新しい分散トランザクション処理モデルとプロトコルが必要になる場合があります。
以上は分散トランザクション処理の今後の開発動向や研究の方向性として考えられるものですが、具体的な展開については技術やビジネスの発展を踏まえて判断する必要があります。