QLoRA を使用して Llama 2 を微調整するのは私たちが使用する一般的な方法ですが、微調整中にさまざまな問題が発生するため、この記事では、詳細なコメントの形でいくつかのよくある質問に対する回答を提供してみます。質問はコード固有のものであり、ほとんどのコメントは関連するオープンソース ライブラリと使用されるメソッドとクラスの問題に対処しています。

ライブラリのインポート
大規模なモデルの場合、まず、馴染みのない Python ライブラリがいくつか存在します。
!pip install -q peft==0.4.0 bitsandbytes==0.40.2 transformers==4.31.0 trl==0.4.7
最初に、accelerate、peft、bitsandbytes、transformers、および trl をインストールする必要があります。トランスフォーマーを除いて、他のライブラリは馴染みのないものです
Transformers はここで最も古いライブラリであり、PyPI (2.0.0) の最も古いバージョンは 2019 年に遡ります。これは、huggingface によってリリースされたライブラリであり、テキスト、画像、音声 (hugs の API からダウンロード) の機械学習モデルに簡単にアクセスできます。また、モデルをトレーニングおよび微調整し、これらのモデルを HuggingFace モデル センターと共有する機能も提供します。Pytorch や Tensorflow のようにニューラル ネットワークの抽象化レイヤーとモジュールを最初から構築するのではなく、このライブラリは、モデルに特化して最適化されたトレーニング API と推論 API を提供します。Transformer は、ほとんどの最新の LLM をロードして使用できるため、LLM 微調整のための重要な Python ライブラリの 1 つです。
bitsandbytes は比較的新しいライブラリで、PyPI の最初のバージョンは 2021 年にリリースされました。これは、CUDA カスタム関数の軽量ラッパーであり、特に 8 ビット オプティマイザー、行列乗算、および量子化用に設計されています。主に、モデル、特に llm およびTransformers モデルの最適化および定量化のための機能を提供します。また、8 ビット Adam/AdamW、SGD モメンタム、LARS、LAMB などの関数も提供します。bitsandbytes の目標は、8 ビット演算による効率的な計算とメモリ使用を可能にして、llm をよりアクセスしやすくすることです。8 ビットの最適化および量子化技術を活用することで、モデルのパフォーマンスと効率を向上させることができます。RTX 3090 などの小型のコンシューマ GPU で llm を実行すると、メモリのボトルネックが発生します。そこで人々は、llm の実行に必要なメモリ要件を削減するための重み量子化手法を研究してきました。bitsandbytes の考え方は、モデルの重みの浮動小数点精度を、FP32 のようなより大きな精度の点から Int8 (4x4 Float16) のようなより小さな精度の点まで定量化することです。abmax やゼロ点量子化など、FP32 を Int8 に量子化する手法はありますが、これらの手法には限界があるため、bitsandbytes ライブラリの作成者は LLM.int8() 論文と 8 ビット オプティマイザを共同執筆しました。 llm メソッドに効率的な量子化を提供します。そのため、bitsandbytes ライブラリによって提供される量子化テクノロジのおかげで、コンシューマ グレードの GPU でより大きなモデルを微調整することができるようになります。
Peft を使用すると、微調整のために LLM (またはその一部) を作業メモリにロードする際のメモリ要件を軽減できます。AlexNet のようなニューラル ネットワークの下位層をフリーズしてから、新しいタスクで分類層を完全に微調整する必要がある、より小さな深層学習モデルを使用する転移学習手法とは異なり、これは llm を使用して行われます。チューニングは巨大です。Parameter Efficient Fine-Tuning (PEFT) メソッドは、16 GB VRAM を提供する T4 GPU など、メモリに制約のあるデバイスでの要約や質問応答などのダウンストリーム タスクに llm を適応させる一連のメソッドです。Peft を介して LLM の一部を微調整しても、完全な微調整に匹敵する結果を得ることができます。たとえば、LoRA と Prefix Tuning は非常に成功しています。これらの微調整メソッドを提供する HuggingFace ライブラリである peft ライブラリは、2023 年 1 月に開発された新しいライブラリです。この記事では、llm を量子化するための低ランク適応または微調整手法である QLoRA を使用します。
trl は別の HuggingFace ライブラリです。trl は実際には 2021 年にリリースされましたが、普及したのは 2023 年 1 月でした。TRLとはTransformer Reinforcement Learningの略で、トランスフォーマー強化学習のことです。LLM のトレーニングと微調整のさまざまなステップでさまざまなアルゴリズムの実装を提供します。これには、教師あり微調整ステップ (SFT)、報酬モデリング ステップ (RM)、および近接ポリシー最適化 (PPO) ステップが含まれます。trl には依存関係として peft もあるため、peft メソッド (例: LoRA) で SFT トレーナーを使用することが可能です。
データセットは以前のインストール パッケージのリストには含まれていませんでしたが (これはトランスフォーマーの依存関係であるため)、データセット ライブラリは Huggingface エコシステムのもう 1 つの重要な部分です。HuggingFace がホストする多くの公開データセットに簡単にアクセスできるため、独自のデータセットやデータローダーを作成する時間を節約できます。
上記のライブラリは、LLM を使用するあらゆる作業に不可欠です。これらのライブラリがどのように連携するかをまとめた簡単な図を次に示します。
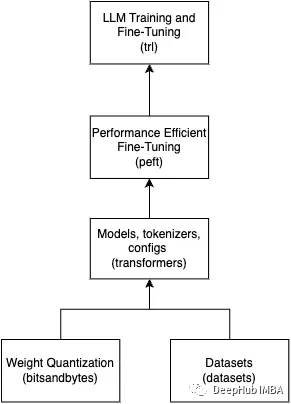
インポートを見てみましょう
import os
import torch
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
pipeline,
logging,
)
from peft import LoraConfig, PeftModel
from trl import SFTTrainer
インポートの分析を続けましょう
Torch は私たちがよく知っている深層学習ライブラリです。ここでは torch の低レベル関数は必要ありませんが、transformers と trl に依存しています。ここでは、torch を使用して dtype (データ型) を取得する必要があります。 torch.Float16 として実行し、GPU ツールの機能を確認します。
load_dataset はデータセットをロードしますが、HuggingFace データセット ハブからローカルにダウンロードします。つまり、これはオンライン ローダーですが、効率的でシンプルであり、必要なコードは 1 行だけです。
dataset = load_dataset(dataset_name, split="train")
モデルが多数あるため、トランスフォーマー ライブラリは、事前トレーニングされたモデルの名前/パスを与える Auto クラスと呼ばれるクラスのセットを提供し、正しい構造を自動的に推論し、関連するモデルを取得できます。AutoModelForCausalLM は、因果言語モデリングのモデルを読み込むために使用される一般的な Auto クラスです。
トランスフォーマーの場合、HuggingFace は 2 種類の言語モデリング (因果関係とマスキング) を提供します。因果言語モデルには、一連のトークン内の次のトークンを予測して、入力データと意味的に類似したテキストを生成する GPT-3 と Llama が含まれます。AutoModelForCausalLM クラスは、モデル センターから因果モデルを取得し、モデルの重みをロードして、モデルを初期化します。from_pretrained() メソッドがこれを行います。
model_name = "NousResearch/Llama-2-7b-chat-hf"
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map=device_map
)
AutoTokenizer はテキスト データをトークン化します。これは、タガー クラスを明示的に指定せずに、さまざまなモデルのタガーを初期化して使用する便利な方法を提供します。これは汎用 Auto クラスでもあるため、指定されたモデル名またはパスに基づいて適切なトークナイザーを自動的に選択できます。トークナイザーは、入力テキストをトークンに変換します。トークンは、NLP モデルで使用されるテキストの基本単位です。また、パディング、切り捨て、アテンション マスキングなどの追加機能も提供します。AutoTokenizer は、NLP タスクのテキスト データをトークン化するプロセスを簡素化します。以下では AutoTokenizer が初期化されていることがわかります。後で SFTTrainer を使用して、初期化された AutoTokenizer をパラメーターとして受け取ります。
model_name = "NousResearch/Llama-2-7b-chat-hf"
# Load LLaMA tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
BitsAndBytesConfig では、前述したように、量子化にビットサンドバイトを使用します。トランスフォーマー ライブラリは最近 bitsandbytes の完全サポートを追加したため、BitsandBytesConfig を使用して、LLM.int8、FP4、NF4 などの bitsandbytes によって提供される量子化方法を構成できるようになりました。量子化構成を AutoModelForCausalLM イニシャライザに渡し、モデルの重みをロードするときに量子化メソッドが直接使用されるようにします。
#bits and byte config
bnb_config = BitsAndBytesConfig(
load_in_4bit=use_4bit,
bnb_4bit_quant_type=bnb_4bit_quant_type,
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=use_nested_quant,
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config, #pass to AutoModelForCausalLM
device_map=device_map
)
TrainingArguments は非常にシンプルです。SFTTrainer のすべてのトレーニング パラメーターを保存するために使用されます。SFFTrainer はさまざまなタイプのパラメーターを受け入れ、TrainingArguments は、関連するすべてのトレーニング パラメーターをデータ クラスに整理して、コードをクリーンで整理された状態に保つのに役立ちます。
CLI アプリケーションに便利な、TrainingArguments のパラメーター パーサーを作成するための HfArgumentParser など、TrainingArguments で使用できる優れたユーティリティ クラスもいくつかあります。
#TrainingArguments
training_arguments = TrainingArguments(
output_dir=output_dir,
num_train_epochs=num_train_epochs,
per_device_train_batch_size=per_device_train_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
optim=optim,
save_steps=save_steps,
logging_steps=logging_steps,
learning_rate=learning_rate,
weight_decay=weight_decay,
fp16=fp16,
bf16=bf16,
max_grad_norm=max_grad_norm,
max_steps=max_steps,
warmup_ratio=warmup_ratio,
group_by_length=group_by_length,
lr_scheduler_type=lr_scheduler_type,
report_to="tensorboard"
)
微調整が完了したら、推論にパイプラインを使用します。「画像分類」、「テキスト要約」など、さまざまなパイプライン タスクのリストを選択できます。タスクに使用するモデルを選択することもできます。カスタマイズのために、トークン化や特徴抽出などの何らかの形式の前処理を実行するパラメーターを追加することもできます。
pipe = pipeline(task="text-generation", model=model, tokenizer=tokenizer, max_length=200)
トランスフォーマーから最後にインポートされるのはログです。これはログ システムであり、コードをデバッグするときに非常に役立ちます。
logging.set_verbosity(logging.CRITICAL)
peft ライブラリからインポートされた LoraConfig データ クラスは構成クラスであり、主に PeftTuner のインスタンスである LoraModel を初期化するために必要な構成を保存します。この設定を SFTTrainer に渡し、SFTTrainer はそれを使用して適切なチューナーを初期化します。
# Load LoRA configuration
peft_config = LoraConfig(
lora_alpha=lora_alpha,
lora_dropout=lora_dropout,
r=lora_r,
bias="none",
task_type="CAUSAL_LM",
)
PeftModel では、微調整に peft メソッド (LoRA など) を使用したら、LoRA アダプタの重みをディスクに保存し、使用時にメモリにロードし直す必要があります。PEFT モジュールによって微調整された重みは、基本モデルの重みとは別のものです。PeftModel を使用すると、base_model の重みを新しく微調整されたアダプターの重みとマージ (調整) するオプションもあり、完全な新しいモデルが得られます。PeftModel.from_pretrained() はアダプターの重みをメモリーからロードし、merge_and_unload() メソッドはそれらをbase_modelとマージします。
# Reload base_model in FP16 and merge it with LoRA weights
base_model = AutoModelForCausalLM.from_pretrained(
model_name,
low_cpu_mem_usage=True,
return_dict=True,
torch_dtype=torch.float16,
device_map=device_map,
)
model = PeftModel.from_pretrained(base_model, new_model)
model = model.merge_and_unload()
最後のインポートは SFTTrainer です。SFTTrainer は、transformer Trainer クラスのサブクラスです。Trainer は、機能モデルのトレーニングのための一般化 API です。これに基づいて、SFTTrainer はパラメーターの微調整のサポートを追加します。教師あり微調整ステップは、指示に従うなどの下流タスク用に Llama などの因果言語モデルをトレーニングする際の重要なステップです。
SFTTrainer は PEFT をサポートしているため、LoRA では SFTTrainer を使用します。SFTTrainer は、LoRA を使用して監視付き微調整を実行します。次に、トレーナーを実行し (train())、重みを保存します (save_pretrained())。
#Initialize the SFTTrainer object
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_config,
dataset_text_field="text",
max_seq_length=max_seq_length,
tokenizer=tokenizer,
args=training_arguments,
packing=packing,
)
# Train model
trainer.train()
# Save trained model
trainer.model.save_pretrained(new_model)
引用のため画像もまとめました
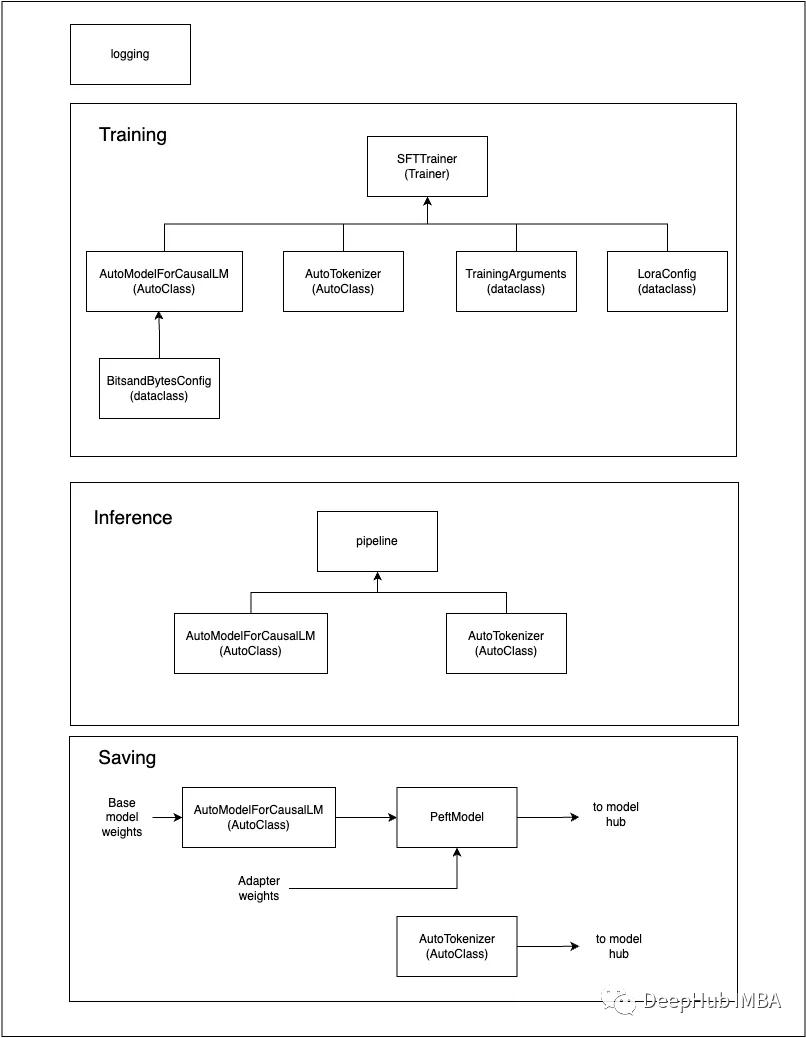
トレーニングパラメータ
これで、Llama 2 (または任意の LLM) を調整するためにどのライブラリが必要かがわかり、これらのライブラリでどのようなクラスが必要かがわかり、これらのクラスが何を行うのかがわかりました。以下は、以前にインポートされたパラメータの紹介です。
モデルとデータセットの名前:
# The model that you want to train from the Hugging Face hub
model_name = "NousResearch/Llama-2-7b-chat-hf"
# The instruction dataset to use
dataset_name = "mlabonne/guanaco-llama2-1k"
# Fine-tuned model name
new_model = "llama-2-7b-miniguanaco"
モデル名、データセット名、および新しいモデル。これらの名前は、HuggingFace モデルの形式とそのハブ上のデータセット名に従います。
birushuo 名前を「NousResearch/ Llama-2-7b-chat-hf」とします。名前の最初の部分は研究機関であり、HuggingFace アカウントの名前です。2 番目の部分はモデル名 lama-2- です。 7b-チャット-hf。モデルの命名に関する推奨事項は、一意のモデル名 (lama-2)、主要パラメーター情報 (7b)、およびモデルの動作に関するその他の有用な情報 (chat-hf) などの有用な情報を含むわかりやすい名前をモデルに付けることです。 )。new_model 名 llama-2-7b-miniguanaco にも同じルールが見られます。これは、ミニチューニングされたモデルに割り当てた名前です。miniguanaco で微調整されたデータセットの名前がここに追加されます。
QLoRAパラメータ:
# LoRA attention dimension
lora_r = 64
# Alpha parameter for LoRA scaling
lora_alpha = 16
# Dropout probability for LoRA layers
lora_dropout = 0.1
使用するパラメータは、r (lora_r)、lora_alpha、lora_dropout です。これらのパラメータは LoRA にとって最も重要です。その理由を理解するには、LoRA 論文を深く理解する必要があります。ここでは簡単な要約のみを説明します。
ニューラル ネットワークでは、バックプロパゲーション アルゴリズムが期待値と実際の値の間の誤差を計算し、この誤差を使用してデルタを計算します。デルタは、ニューラル ネットワーク内の重みが e に寄与するものです。ニューラル ネットワークの初期重み W0 がある場合、誤差 e については、delta_W0 = ΔW を計算します。次に、ΔW を使用して重み W0 +ΔW を更新し、誤差 e を減らします。LoRA は、W0 + ΔW = W0 + BA となるように、ΔW を 2 組の低ランク行列 A および B に分解することを提案しています。完全な ΔW 更新を使用する代わりに、より小さい低ランク更新行列 BA を使用します。これにより、より低い計算要件で同じ効率を達成することができます。ΔW のサイズが (d × k) (W0 のサイズ) の場合、ΔW を次元 (d × r) と (r × k) の 2 つの行列 B と A に分解します。ここで、r はランクです。
LoraConfig のパラメータ r (lora_r) は、更新行列 BA の形状を決定するランクです。論文によれば、小さなランクを設定しても良い結果が得られるとのことです。W0 を更新するとき、学習率として機能するスケーリング係数 α を使用して BA の影響を制御できます。スケール係数は 2 番目のパラメーター (lora_alpha) です。最後に、正則化のための典型的なドロッププットである lora_dropput を設定します。
BitsandBytes パラメータ:
# Activate 4-bit precision base model loading
use_4bit = True
# Compute dtype for 4-bit base models
bnb_4bit_compute_dtype = "float16"
# Quantization type (fp4 or nf4)
bnb_4bit_quant_type = "nf4"
# Activate nested quantization for 4-bit base models (double quantization)
use_nested_quant = False
QLoRA と呼ばれる LoRA の量子化バージョンを使用しています。これは、LoRA の微調整で量子化を使用し、前述した更新重み (および量子化できる他の操作) に量子化を適用することを意味します。
パラメーター use_4bit (6 行目) は、忠実度の高い 4 ビット トリミングを使用するために True に設定されています。このトリミングは、LLM.int8 論文で導入された 8 ビット量子化よりも低いメモリ要件を達成するために、後に QLoRA 論文で導入されました。
bnb_4bit_compute_dtype (行 9) を設定します。これは、計算が実行されるデータ型 (float16) です。つまり、重みは 4 ビット量子化を通じて保存されますが、計算は依然として 16 ビットまたは 32 ビットで行われます。
QLoRA 論文によると、bnb_4bit_quant_type (12 行目) を使用すると、nf4 は理論的および経験的に優れたパフォーマンスを示します。
パラメータ use_nested_quant は False に設定され、bnb_4bit_use_double_quant に渡されます。このモデルでは、最初の量子化の後に 2 回目の量子化を有効にし、パラメータあたりさらに 0.4 ビットを節約します。
上記のパラメータの一部は QLoRA 論文で提供されているものです。詳細について知りたい場合は、論文または過去の記事を参照してください。
この記事の計算に NF4 量子化 FP16 (float16) 精度を選択すると、Colab T4 GPU (16 GB VRAM) のメモリ制限がなくなるはずです。簡単な計算をしてみましょう。Llama-2-7B (70 億パラメータ) と FP16 (量子化なし) を使用すると、7B × 2 バイト = 14 GB (必要な VRAM) が得られます。4 ビット量子化を使用すると、7B × 0.5 バイト = ~ 4GB (必要な VRAM) が得られます。
トレーニングパラメータ:
# Output directory where the model predictions and checkpoints will be stored
output_dir = "./results"
# Number of training epochs
num_train_epochs = 1
# Enable fp16/bf16 training (set bf16 to True with an A100)
fp16 = False
bf16 = False
# Batch size per GPU for training
per_device_train_batch_size = 4
# Batch size per GPU for evaluation
per_device_eval_batch_size = 4
# Number of update steps to accumulate the gradients for
gradient_accumulation_steps = 1
# Maximum gradient normal (gradient clipping)
max_grad_norm = 0.3
# Initial learning rate (AdamW optimizer)
learning_rate = 2e-4
# Weight decay to apply to all layers except bias/LayerNorm weights
weight_decay = 0.001
# Optimizer to use
optim = "paged_adamw_32bit"
# Learning rate schedule (constant a bit better than cosine)
lr_scheduler_type = "constant"
# Ratio of steps for a linear warmup (from 0 to learning rate)
warmup_ratio = 0.03
# Group sequences into batches with same length
# Saves memory and speeds up training considerably
group_by_length = True
# Save checkpoint every X updates steps
save_steps = 25
# Log every X updates steps
logging_steps = 25
Output_dir (6 行目): ここに設定がモデルの予測とチェックポイント (ログも含む) を保存します。
num_train_epochs (9 行目): トレーニング ラウンド
fp16 と bf16 (12 行目と 13 行目): QLoRA がすでに存在するため混合精度トレーニングを使用しないため、両方を false に設定します。
per_device_train_batch_size と per_device_eval_batch_size (16 行目と 19 行目): 両方とも 4 に設定します。十分なメモリがあれば、より大きなバッチ サイズ (>8) を設定でき、トレーニングが高速化されます。
Gradient_accumulation_steps (行 22): 「勾配累積」は、モデルの重みが実際に更新される前に実行される前方および後方パス (更新ステップ) の数を指します。順方向および逆方向の各パス中に、勾配が計算され、データのバッチ全体にわたって蓄積されます。指定されたステップ数の勾配を累積した後、バックパスが実行され、これらのステップにわたる平均勾配が計算され、それに応じてモデルの重みが更新されます。このアプローチは、より大きなバッチ サイズを効率的にシミュレートするのに役立ち、前方および後方パスごとのメモリ要件を削減します。
max_gradient_norm (行 25): 勾配のノルム (大きさ) が特定のしきい値 (max_grad_norm パラメーターで指定) を超える場合、勾配クリッピングによって勾配が減少します。勾配ノルムが max_grad_norm より大きい場合、勾配はスケールダウンされ、勾配ノルムがすでに max_grad_norm を下回っている場合、スケーリングは適用されません。max_grad_norm のより高い値から始めて、複数のトレーニング反復にわたって徐々に値を下げることをお勧めします。
learning_rate (行 28): AdamW の学習率。AdamW は、人気のある Adam オプティマイザーの亜種です。これは、Adam オプティマイザーと重み減衰正則化の技術を組み合わせたものです。
Weight_decay (行 31): L2 正則化または重み正則化とも呼ばれる重み減衰は、モデルがトレーニング データに過剰適合するのを防ぐために、機械学習や深層学習で一般的に使用される正則化手法です。これは損失関数にペナルティ項を追加することで機能します。AdamW と重み減衰の使用は理にかなっています。なぜなら、重み減衰は、過学習を防止し、事前トレーニングからの知識を保持しながらモデルが新しいタスクに確実に適応できるようにするため、微調整中に特に役立ちます。
optim (行 34): AdamW オプティマイザーを使用すると、「paged_adamw_32bit」は AdamW オプティマイザーの特定の実装またはバリアントであるようです。彼に関する情報が見つかりません。そのため、これに関する情報をお持ちの場合は、コメントに残してください。 、 ありがとう!
lr_scheduler_type (行 37): 通常、深層学習モデルのトレーニング中に学習率スケジューラーを使用して、時間の経過とともに学習率を調整します。
Warmup_ratio (行 40): ここでは、「warmup_ratio」を 0.03 に設定します。エポックごとに 250 のトレーニング ステップがあるため、ウォームアップ フェーズは最初の 8 ステップ (250 の 3%) まで続き、その間、学習率は 0 から指定された初期値 2e-4 まで直線的に増加します。ウォームアップ フェーズは、トレーニングを安定させ、勾配の爆発を防ぎ、モデルが効果的に学習を開始できるようにするためによく使用されます。
group_by_length (行 44): このパラメータを True に設定すると、トレーニングが高速化されます。group_by_length が True に設定されている場合、トレーニング データセット内のほぼ同じ長さのサンプルが同じバッチにグループ化されます。これは、同様の長さのシーケンスがグループ化され、必要なパディングが削減されることを意味します。これは、バッチにはより類似した長さのシーケンスが含まれることになり、適用されるパディングの量が最小限に抑えられることを意味します。一般に、バッチのサイズが一定である場合、GPU 処理の効率が向上し、トレーニング時間が短縮されます。これは、LSTM の時代から行われてきた高速化の手法です。
save_steps とlogging_steps (47行目と50行目): ここでは両方のパラメータが25に設定され、トレーニング情報の記録とチェックポイントの保存の間隔ステップを制御します。
SFTTrainer パラメータ:
max_seq_length = None
# Pack multiple short examples in the same input sequence to increase efficiency
packing = False
最後のパラメータは SFTTrainer に固有です。
max_seq_length: max_seq_length を None に設定すると、シーケンスの最大長制限を課すことがなくなります。固定長に切り詰めたりパディングしたくないため、max_seq_length を None に設定すると、データ内に存在する完全なシーケンス長を使用できるようになります。
パッキング: ドキュメントによると、ConstantLengthDataset はこのパラメーターを使用してデータセットのシーケンスをパックします。ConstantLengthDataset のコンテキストでパッキングを False に設定すると、複数の短いサンプルを処理するときの効率が向上します。これはデータセットの場合です。パッキングを False に設定すると、ConstantLengthDataset で複数の短いサンプルを 1 つの入力シーケンスにパックし、それらを効果的に組み合わせることができます。これにより、大量のパディングの必要性が減り、メモリの使用と計算がより効率的になります。
データセット、ベースモデル、タガーをロードします。
device_map = {"": 0}
# Load dataset (you can process it here)
dataset = load_dataset(dataset_name, split="train")
# Load tokenizer and model with QLoRA configuration
compute_dtype = getattr(torch, bnb_4bit_compute_dtype)
bnb_config = BitsAndBytesConfig(
load_in_4bit=use_4bit,
bnb_4bit_quant_type=bnb_4bit_quant_type,
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=use_nested_quant,
)
# Check GPU compatibility with bfloat16
if compute_dtype == torch.float16 and use_4bit:
major, _ = torch.cuda.get_device_capability()
if major >= 8:
print("=" * 80)
print("Your GPU supports bfloat16: accelerate training with bf16=True")
print("=" * 80)
# Load base model
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map=device_map
)
model.config.use_cache = False
model.config.pretraining_tp = 1
# Load LLaMA tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.add_special_tokens({'pad_token': '[PAD]'})
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
# Load LoRA configuration
peft_config = LoraConfig(
lora_alpha=lora_alpha,
lora_dropout=lora_dropout,
r=lora_r,
bias="none",
task_type="CAUSAL_LM",
)
5 行目ではデータセットを読み込みます。次に、9 行目の gettr 関数を使用して、compute_dtype を torch.float16 に設定します。10 行目で、BitsandBytesConfig が初期化されます。
17 行目では、torch.cuda.get_device_capability() 関数を使用して、GPU と bfloat16 の互換性をチェックします。この関数は、CUDA 対応 GPU デバイスのコンピューティング能力を返します。コンピューティング機能は、GPU によってサポートされるバージョンと機能を示します。この関数は、GPU のメジャーおよびマイナーの計算能力バージョンを表す 2 つの整数 (メジャー、マイナー) のタプルを返します。メジャー バージョンはコンピューティング機能のメジャー バージョンを表し、マイナー バージョンはコンピューティング機能のマイナー バージョンを表します。たとえば、関数が (8,0) を返した場合、GPU の計算能力がバージョン 8.0 で、マイナーが 0 であることを意味します。GPU が bfloat16 と互換性がある場合、Bfloat16 は float16 よりも精度が高いため、compute_dtype を torch.Bfloat16 に設定します。
次に、AutoModelForCausalLM.from_pretrained を使用して基本モデルを読み込み、31 行目で model.config を設定します。use_cache は False で、キャッシュが有効な場合は変数が減少します。キャッシュを無効にすると、計算の実行順序にある程度のランダム性が導入され、微調整するときに役立ちます。
Model.config.pretraining_tp = 1 は 32 行目で設定されています。ここで、Llama 2 のヒントに従って、tp はテンソル並列処理を表します。
model.config.pretraining_tp = 1 に設定すると、1 以外の値を指定すると、線形層の計算はより正確になりますが、速度が遅くなり、元の確率とよりよく一致するはずです。
次に、model_name を使用して Llama タガーをロードするだけです。NousResearch/lama-2 のファイルを見ると、tokenizer.model ファイルがあることがわかります。model_name を使用して、AutoTokenizer はこのトークナイザーをダウンロードできます。
36 行目では、add_special_tokens({' Pad_token ': ' [PAD] '}) が呼び出されます。データセット内のテキストの長さは変化する可能性があり、バッチ内のシーケンスの長さも異なる可能性があるため、これも重要なコードです。バッチ内のすべてのシーケンスが同じ長さになるようにするには、短いシーケンスにパディング トークンを追加する必要があります。これらのフィラー タグは通常、何も意味しないタグです。
37 行目で、tokenizer.pad_token = tokenizer.eos_token を設定します。パッド トークンを EOS トークンと調整し、トークナイザー構成の一貫性を高めます。両方のトークン (pad_token と eos_token) は、シーケンスの終わりを示す役割を果たします。これを設定すると、トークン化とパディング ロジックが簡素化されます。
38 行目でパディング エッジを設定します。パディング エッジを右に設定すると、オーバーフローの問題が修正されます。
最後に 41 行目で、LoraConfig を初期化します。
電車
# Set training parameters
training_arguments = TrainingArguments(
output_dir=output_dir,
num_train_epochs=num_train_epochs,
per_device_train_batch_size=per_device_train_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
optim=optim,
save_steps=save_steps,
logging_steps=logging_steps,
learning_rate=learning_rate,
weight_decay=weight_decay,
fp16=fp16,
bf16=bf16,
max_grad_norm=max_grad_norm,
max_steps=max_steps,
warmup_ratio=warmup_ratio,
group_by_length=group_by_length,
lr_scheduler_type=lr_scheduler_type,
report_to="tensorboard"
)
# Set supervised fine-tuning parameters
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_config,
dataset_text_field="text",
max_seq_length=max_seq_length,
tokenizer=tokenizer,
args=training_arguments,
packing=packing,
)
# Train model
trainer.train()
# Save trained model
trainer.model.save_pretrained(new_model)
TrainingArguments は、前に詳しく説明した仮パラメータを使用して 2 行目で初期化されます。次に、TrainingArguments は、説明した他の関連パラメーターとともに 30 行目で SFTTrainer に渡されます。
ここで追加された新しいパラメータは、27 行目の dataset_text_field=" text " です。dataset_text_field パラメーターは、データセット内のどのフィールドにモデルへの入力としてテキスト データが含まれるかを示すために使用されます。これにより、データセット ライブラリがこのフィールドのテキスト データに基づいて ConstantLengthDataset を自動的に作成できるようになり、データ準備プロセスが簡素化されます。
HuggingFace エコシステムは、舞台裏で多くの作業を自動化するライブラリの緊密なエコシステムです。
推論
logging.set_verbosity(logging.CRITICAL)
# Run text generation pipeline with our next model
prompt = "What is a large language model?"
pipe = pipeline(task="text-generation", model=model, tokenizer=tokenizer, max_length=200)
result = pipe(f"<s>[INST] {prompt} [/INST]")
print(result[0]['generated_text'])
6 行目、パイプラインの初期化。次に、7 行目のパイプを使用して、5 行目のプロンプトを使用して作成された入力テキストを渡します。シーケンスの開始を示すために使用し、ユーザー メッセージの開始と終了を示す制御トークンとして [INST] と [/INST] を追加します。
アダプターの重みを使用して基本モデルをリロードします
# Reload model in FP16 and merge it with LoRA weights
base_model = AutoModelForCausalLM.from_pretrained(
model_name,
low_cpu_mem_usage=True,
return_dict=True,
torch_dtype=torch.float16,
device_map=device_map,
)
model = PeftModel.from_pretrained(base_model, new_model)
model = model.merge_and_unload()
# Reload tokenizer to save it
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.add_special_tokens({'pad_token': '[PAD]'})
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
2 行目で AutoModelForCausalLM.from_pretrained を使用して、基本モデルを (再) ロードします。微調整する必要がなく、アダプターとマージするだけなので、量子化設定を行わずにこれを実行します。また、13 行目でトークナイザーをリロードし、13 ~ 14 行目で前に行ったのと同じ変更を加えます。
保存
最後に、微調整したモデルとそのタガーをローカルに保存するか、HuggingFace にアップロードします。
model.push_to_hub(new_model, use_temp_dir=False)
tokenizer.push_to_hub(new_model, use_temp_dir=False)
要約する
peft や tramsformers などのライブラリは、大規模モデル開発のワークフローを簡素化し、多くの専門知識がなくても大規模モデルを微調整できます。しかし、適切なモデルを取得するには長いプロセスが必要です。上記のコードと同様に、単純そうに見えて実際は複雑です。メソッドの原理を理解する必要があるだけでなく、各パラメータの意味を理解する必要もあります。紙。
ここで学んだことの多くは、LLM を微調整するタスクに適用できるため、この記事は良いスタートになります。Llama 2 の微調整については、パイプラインについて説明しましたが、微調整のパフォーマンスを適切に評価するにはどうすればよいですか?あまり費用をかけずに、より大きなモデル (70B) を調整できますか?より大きなデータセットを使用しますか?モデル?については次回以降の記事で紹介していきます。
https://avoid.overfit.cn/post/903a50f5e8ec469f890a1e8854d64716
著者: オグバン・ウゴット