青い文字をクリックしてください

私たちに従ってください
AI TIME は、あらゆる AI 愛好家の参加を歓迎します。
著者について

張庚偉
シドニー工科大学の博士課程の学生、研究の方向性は継続学習です
タイトル
低速学習と分類器の調整による事前トレーニング済みモデルの継続的な学習
簡単な紹介
継続的学習研究の目標は、逐次到着するデータから学習するモデルの能力を向上させることです。既存の仕事のほとんどはゼロから学習することを前提に構築されていますが、事前トレーニングの利点を組み込む取り組みが増えています。ただし、事前トレーニングによって提供される一般化を維持しながら、各増分タスクで事前トレーニングの知識を適応的に利用する方法は未解決の問題のままです。この研究では、事前トレーニング済みモデルでの継続的学習 (CLPM) の広範な分析を実施し、主要な課題が進行性の過学習問題にあると考えています。学習率を選択的に下げることで表現層への問題の影響をほぼ解決できることを観察し、分類層をさらに改善するためにクラス分布をモデル化して調整する、分類子アライメントによるスローラーナー (SLCA) と呼ばれるシンプルだが非常に効果的な方法を提案します。さまざまなシナリオにわたって、私たちの方法は CLPM に比べて大幅な改善をもたらします (たとえば、Split CIFAR-100、Split ImageNet-R、Split CUB-200、および Split Cars-196 でそれぞれ 49.76%、50.05%、44.69%)。 %)、したがって、最先端の方法を大幅に上回ります。このような強力なベースラインに基づいて、その後の研究を促進するための主要な要因と有望な方向性の詳細な分析を提供します。
論文リンク: https://arxiv.org/pdf/2303.05118.pdf
コードリンク: https://github.com/GengDavid/SLCA
01
背景
継続的学習は、順次到着するデータを学習し、モデルを段階的に更新することを特徴とします。ただし、ニューラル ネットワークの設計自体が、「壊滅的な忘却問題」と呼ばれる継続的な学習における課題につながります。これは、モデルが新しいタスクを学習するときに、元のタスクのデータが存在しないという事実に反映されています。そのため、モデルが古いタスクで失敗し、パフォーマンスが大幅に低下します。
この問題に対する現在の主流の解決策は 3 つあります。正則化により、ネットワーク パラメーターを更新するときに制限が追加されるため、新しいタスクを学習するときにネットワークが以前の知識に影響を与えることはありません。リプレイは、モデルが新しいタスクを学習する間に元のタスクからの少量のデータを混合するため、モデルは古いタスクを考慮しながら新しいタスクを学習できます。ネットワーク アーキテクチャは、モデルのトレーニング中にネットワーク内のパラメーターを分離して、新しい知識の更新が古い知識に干渉する可能性を減らします。
一方、事前トレーニングされたモデルは、下流タスクのトレーニングにとって非常に重要です。現時点で最も基本的な方法は、トレーニング モデルを微調整することです。ビジュアル キュー チューニング、アダプター チューニング、LoRA、SSF など、パラメータを効率的にチューニングするための方法もあります。これらは、個別の下流タスクを微調整するよりも優れています。
02
問題の定式化
スクラッチから学習するのとは対照的に、事前トレーニングされたモデルで継続的に学習する場合、θrps は事前トレーニングされたモデルのデータセットで事前トレーニングされ、その後、一連の新しいデータセットでこのモデルを使用して更新されます。事前トレーニング モデルの導入後、「壊滅的な忘却問題」は「進行性過学習」問題に拡張できます。直面する課題は、事前トレーニング データ Dpt から得られた一般化をどのようにして確実に活用するかということです。継続的な学習プロセス中の知識の忘却の問題も考慮しながら、継続的な学習のプロセスの保持に重点を置きます。
03
最近の作品
L2P [1] や DualPrompt [2] などの近年の研究では、モデル汎化能力の損失の問題を解決するためにプロンプト テクノロジが導入されました。しかし実際には、プロンプトも共有されており、忘れてしまうという問題が依然として残っています。以前の研究の実験結果から判断すると、プロンプトベースの方法は微調整ベースの方法よりも優れています。しかし、この研究では、私たちの調査結果はそうではないことを示唆しています。
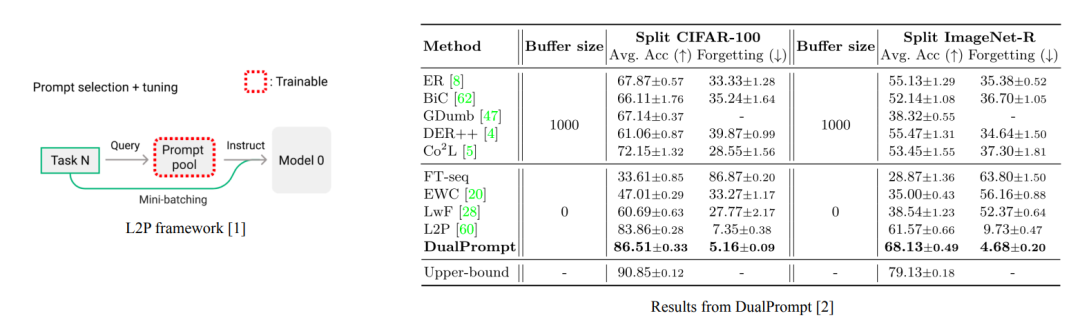
04
事前トレーニングされたモデルでの継続的な学習
必要なのはSlow Learnerだけ(ほぼ)?
この記事では、まず、継続学習の設定で事前トレーニングを追加した後、微調整ベースの手法がヒントベースの手法より遅れる理由を探ります。鍵は学習率にあり、比較的大きな学習率を使用すると従来のベースラインのパフォーマンスが大幅に制限されることがわかりました。従来のベースラインのパフォーマンスは、θrps に対してはるかに小さい学習率 (0.0001、SGD オプティマイザー) を使用し、θcls に対してわずかに大きい学習率 (0.01) を使用すると、大幅に改善できます。
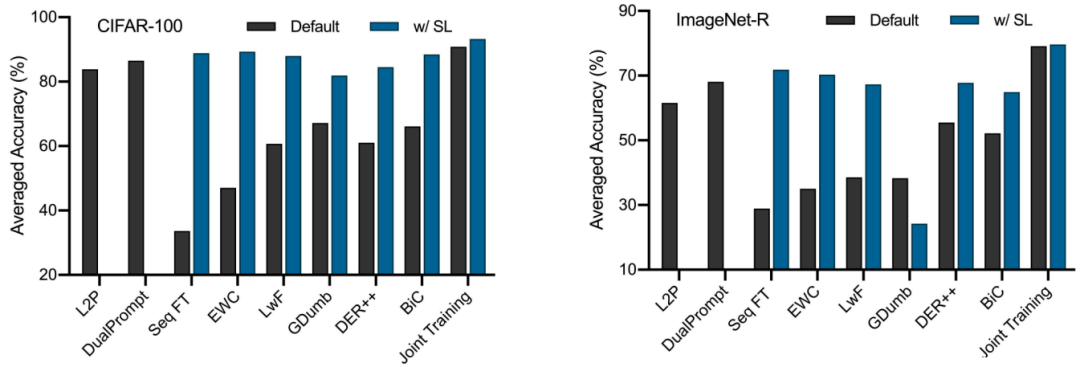
事前トレーニングパラダイムの効果
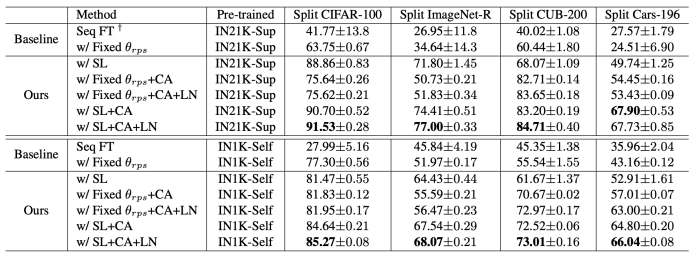
さらに、下流の継続的な学習に対する事前トレーニング パラダイムの影響を評価します。図に示されているように、自己教師あり事前トレーニングは、ラベル要件と上流の連続学習の点ではより現実的ではありますが、多くの場合、教師あり事前トレーニングよりも Seq FT と共同トレーニングの間でパフォーマンスの差が大きくなります。
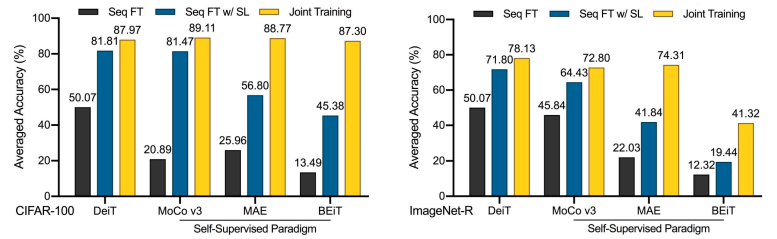
表現のさらなる評価
次に、表現層をさらに検証し、すべての増分タスクを学習した後、継続的に学習された表現層を使用してすべてのカテゴリの追加の分類器を共同トレーニングすると、モデル全体の共同トレーニングのパフォーマンスにほぼ達し、継続的に学習するプレゼンテーションよりもはるかに優れていることがわかりました。レイヤー分類子。低速学習法を使用すると、プレゼンテーション層の漸進的過学習の問題はほぼ解決されており、分類器にはまだ改善の余地が多くあることがわかります。
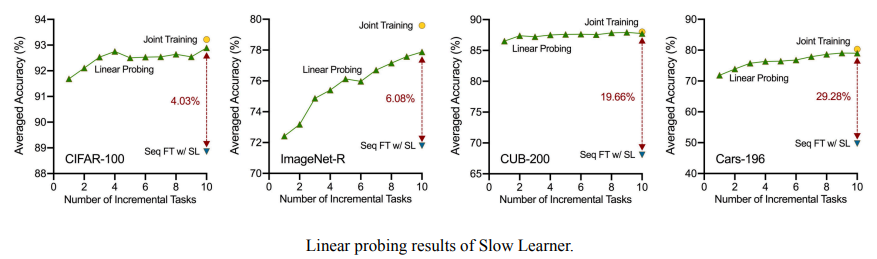
分類子アライメントを使用したスローラーナー
上記の現象が発生する理由は、各タスクの分類器が独立して学習され、テストではすべてのカテゴリに対して一意の分類結果が必要となるため、継続的な学習によって得られる分類器が最適ではなくなるためです。そこで、さらに分類子アライメントモジュールを提案します。具体的な方法は、トレーニング プロセス中の各タスクの終了時に特徴の平均と共分散を計算して保存することです。テスト前に、特徴の統計を使用してガウス分布を構築し、この分布に従って各カテゴリの特徴がサンプリングされ、最後に分類器が均一に微調整され、分類器を調整するという目的が達成されます。
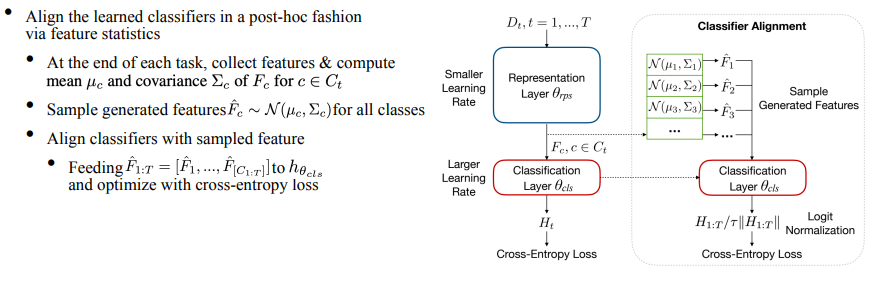
さらに、分類器は各タスクに収束するようにトレーニングされるため、分類器をさらにトレーニングすると過剰適合の問題が発生します。具体的には、分類器の出力ロジットは各クラスに対応した予測値を持ち、それを単位ベクトルを掛けたモジュールの形で記述します。最適化にクロスエントロピー損失を使用すると、モジュール長が大幅に増加し、過学習につながるため、ICML'22 のロジット正規化 [3] の研究を借用し、動的温度項を追加して、CE 損失によってのみ変化するようにしました。ベクトルの方向を調整することで、過学習の問題を軽減します。
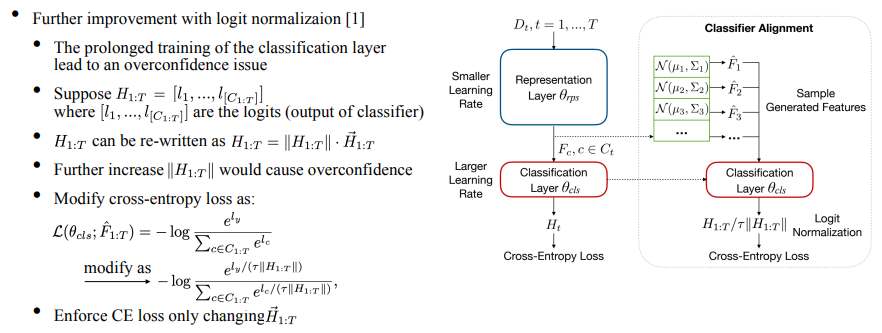
このメソッドの全体的なアルゴリズム フローを次の図に示します。

05
実験のセットアップ
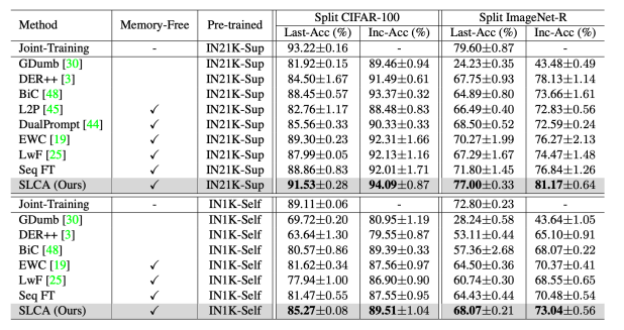
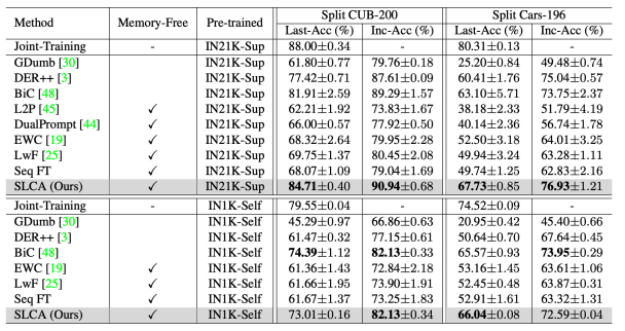
Split CIFAR-100、Split ImageNet-R、Split CUB-200、Split Cars-196 の 4 つのベンチマークで検証しました。各ベンチマークでは、異なる検証次元が考慮されます (以下の表を参照)。各データセットを 10 個のタスクに分割してトレーニングし、評価指標には Last-Acc (主要な評価指標、最後のタスクを学習した後のすべてのタスクにおけるモデルの平均精度) と Inc-Acc が含まれます。

06
全体的なパフォーマンス
この手法を他のベースライン手法と比較した実験結果を以下の図に示します。Split CIFAR-100 および Split ImageNet-R では、SL が分類器のアラインメントとロジットの助けを借りて継続学習のパフォーマンスを大幅に向上できることがわかります。私たちの方法は、L2P や DualPrompt よりもはるかに優れています。同様に、この記事で提案されている方法は、Split CUB-200 および Split Cars-196 データセットでの詳細な分類のパフォーマンスも優れています。
07
アブレーション研究
提案された方法について広範なアブレーション実験を実施し、表現層を更新する必要性を実証します。一方、提案された分類器の調整とロジスティック正規化の有効性をさらに実証します。
08
他の方法と組み合わせる
さらに既存の手法に Classifier Alignment を追加し、Classifier Alignment の有効性をさらに証明しました。

09
結論
第一に、私たちはこの研究の方向性を再考してベンチマークし、現在の進歩とテクノロジーのルートを再評価するためのシンプルだが非常に効果的なベースラインを提供します; 第二に、スローラーナーはプレゼンテーション層の漸進的な過学習の問題をほぼ解決できます 複合的な問題については、分類器の調整をさらに進めます分類層を改善します。最後に、将来の方向性に関しては、継続学習のためのより多くの事前トレーニング パラダイムを探索し、パラメーター効率の高い手法をより効果的に組み合わせ、上流の事前トレーニングと下流の継続学習を組み合わせることができます。
10
参照
[1] 継続的学習を促す学習、CVPR'22
[2] DualPrompt: リハーサル不要の継続的学習のための相補的プロンプト、ECCV'22
[3] ロジット正規化によるニューラル ネットワークの過信の軽減、ICML'22
主催: チェン・ヤン
レビュアー: 張庚偉
運ぶ
起きている
「原文を読む」をクリックすると00:22:07にジャンプします。
リプレイが見れます!
過去号のおすすめ記事

忘れずにフォローしてください!毎日新しい知識が得られます!
AI TIMEについて
AI TIME は 2019 年に設立され、科学的思索の精神を継承し、あらゆる階層の人々を招待して人工知能の理論、アルゴリズム、シナリオの応用の本質的な問題を探求し、アイデアの衝突を強化し、世界的な AI 学者を結びつけることを目的としています。業界の専門家や愛好家は、討論の形で人工知能と人類の未来の間の矛盾を探り、人工知能分野の未来を探ります。
AI TIMEはこれまでに国内外から1,300人以上の講演者を招き、600回以上のイベントを開催し、600万人以上が視聴しました。

私はあなたを知っています。
覗く
おお
~

クリックして元のテキストを読み 、リプレイを表示します。