序文
Broker モジュールには多くの内容が含まれており、この記事では主に次の技術的なポイントを紹介します。
- ブローカーの起動プロセス分析
- メッセージストレージの設計
- メッセージ書き込みプロセス
- ハイライト分析: NRS と NRC の関数番号設計
- ハイライト分析: 同期二重書き込みパフォーマンスが数倍向上した CompletableFuture
- ハイライト分析: Commitlog を書き込むときにリエントラント ロックまたはスピン ロックを使用しますか?
- ハイライト分析: ゼロコピー テクノロジ MMAP により、ファイルの読み取りおよび書き込みパフォーマンスが向上します。
- ハイライト分析: オフヒープ メモリ メカニズム
ブローカーの起動プロセス
Brokerの起動フローチャートは以下の通りです
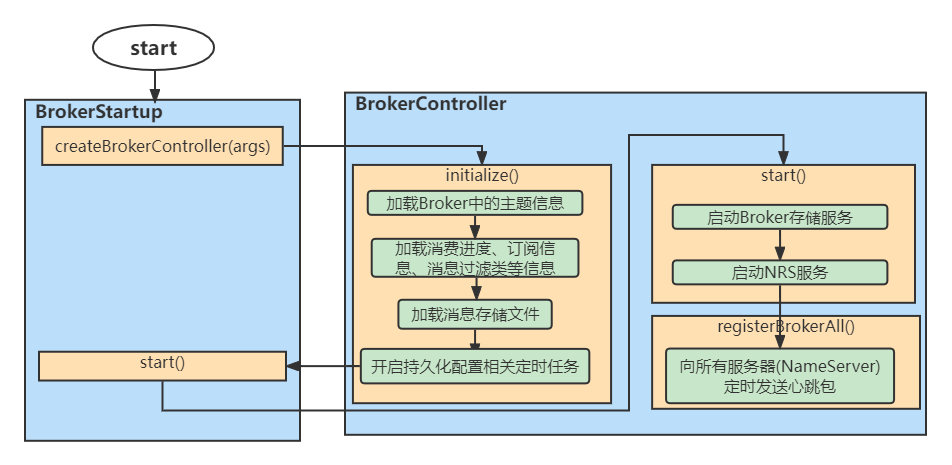
- サーバーに保存されている構成情報、消費者の消費の進行状況、消費者のサブスクリプション情報などをロードします。これらの設定情報は、ブローカーがシャットダウンされる前にサーバーに自動的に保存されますが、これは単にシャットダウンする前にブローカーの設定を復元するためのものです。
- メッセージ ストレージ ファイル MessageStore コンポーネントをロードします。このコンポーネントは MappedFileQueue を作成することでメッセージを保存します。この MappedFileQueue は、CommitLog、ConsumeQueue、Index およびその他のファイルによって保存されるファイルが配置されるフォルダーのコード内のマッピングです。
- BrokerController コントローラーを作成して開始します。これにより、ブローカーを開始およびシャットダウンするためのいくつかのプロセッサーとマネージャーが作成され、メッセージの送受信やその他の操作が処理されます。
ブローカーメッセージストレージの設計
Kafka のファイルのレイアウトはトピック/パーティションに基づいています。各パーティションには物理フォルダーがあります。ファイルの順次書き込みはパーティション ファイル レベルで実装されます。Kafka クラスター内に数百または数千のトピックがあり、各トピックに数百のトピックがある場合メッセージが高い同時実行性で書き込まれると、その IO 操作は分散しているように見えます (分散したメッセージ配置戦略は激しいディスク IO 競合を引き起こし、ボトルネックになります)。その操作はランダム IO、つまり Kafka の IO パフォーマンスと同等です。トピックとパーティションの数が増加すると、書き込みパフォーマンスは最初は向上し、その後低下します。
RocketMQ はメッセージ書き込み時に究極のシーケンシャル書き込みを追求しており、トピックに関係なくすべてのメッセージがコミットログファイルにシーケンシャルに書き込まれ、トピックやパーティションの数が増えても順序性が影響されません。メッセージ送信側とコンシューマー側が共存するシナリオでは、トピックの数が増えると Kafka のスループットは急激に低下しますが、RocketMQ のパフォーマンスは安定しています。したがって、Kafka はトピックとコンシューマが比較的少ないビジネス シナリオに適していますが、RocketMQ はトピックとコンシューマが多数あるビジネス シナリオにより適しています。
ファイルデザインの保存
RocketMQ によって主に保存されるファイルには、Commitlog ファイル、ConsumeQueue ファイル、および IndexFile が含まれます。RocketMQ はすべてのトピックのメッセージを同じファイルに保存し、メッセージ送信時にファイルが順番に書き込まれるようにし、メッセージ送信の高パフォーマンスと高スループットを確保するために最善を尽くします。しかし、一般的なメッセージミドルウェアはメッセージトピックに基づいたサブスクリプション機構であるため、メッセージトピックに応じたメッセージの取得には大きな不便さをもたらします。メッセージ消費の効率を向上させるために、RocketMQ では ConsumeQueue メッセージ キュー ファイルが導入されており、各メッセージ トピックには複数のメッセージ消費キューが含まれており、各メッセージ キューにはメッセージ ファイルがあります。RocketMQ では IndexFile インデックス ファイルも導入されており、その主な設計コンセプトはメッセージ取得パフォーマンスの高速化であり、メッセージ属性に基づいて Commitlog ファイルからメッセージを迅速に取得できます。全体は次のとおりです。
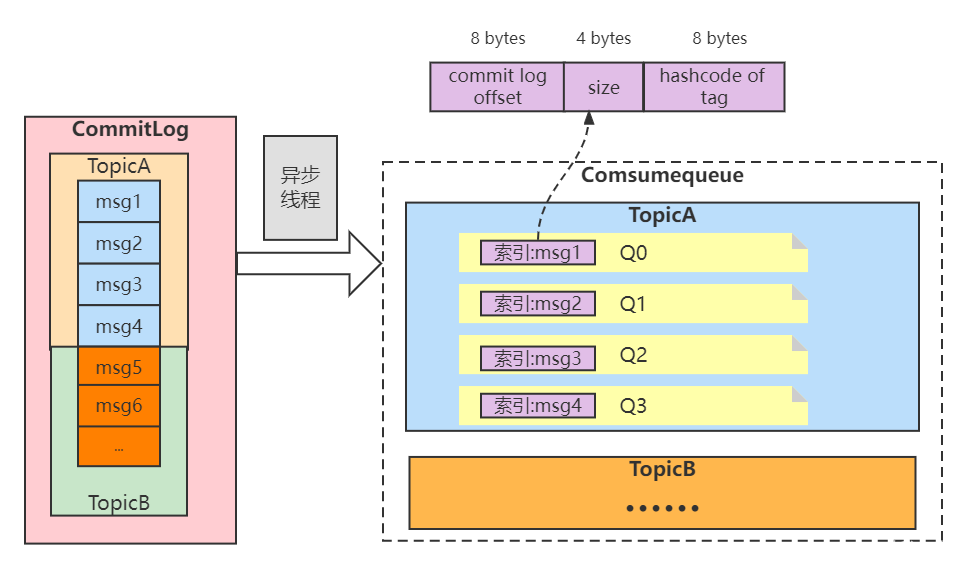
- CommitLog: メッセージ ストレージ ファイル。すべてのメッセージ トピックのメッセージは CommitLog ファイルに保存されます。
- ConsumeQueue: メッセージ消費キュー。メッセージは CommitLog ファイルに到達すると、メッセージ コンシューマーによる消費のためにメッセージ消費キューに非同期的に転送されます。
- IndexFile: メッセージのインデックス ファイル。主にメッセージのキーとオフセットの対応を格納します。
メッセージストレージ構造
CommitLog は物理ファイルの形式で保存されます。各 Broker の CommitLog は、マシン上のすべての ConsumeQueue によって共有されます。CommitLog では、メッセージの保存長は固定されていません。RocketMQ は、CommitLog に順次書き込もうとするいくつかのメカニズムを採用していますが、ランダムに読み取られます。コミットログ ファイルのデフォルトのサイズは lG です。デフォルトのサイズは、ブローカ構成ファイルで mapedFileSizeCommitLog 属性を設定することによって変更できます。
Commitlog ファイルのストレージの論理ビューは次のとおりです。各メッセージの最初の 4 バイトには、メッセージの全長が格納されます。ただし、メッセージの保存長は固定されていません。

ConsumeQueue は、データベースのインデックス ファイルに似たメッセージの論理キューであり、物理ストレージを指すアドレスを格納します。各トピックの各メッセージ キューには、対応する ConsumeQueue ファイルがあります。
ConsumeQueue はメッセージ エントリを保存します。ConsumeQueue メッセージ エントリの取得を高速化し、ディスク領域を節約するために、各 ConsumeQueue エントリにはメッセージの完全な情報は保存されません。メッセージ エントリは次のとおりです。

ConsumeQueue は Commitlog ファイルのインデックス ファイルであり、その構築メカニズムは、メッセージが Commitlog ファイルに到達すると、専用スレッドがメッセージ転送タスクを生成し、メッセージ消費キュー ファイル (ConsumeQueue) と後述のインデックス ファイルを構築します。このように設計されたストレージ メカニズムには次の利点があります。
- CommitLog は順次書き込みを行うため、書き込み効率が大幅に向上します。
- これはランダム読み取りですが、オペレーティング システムのページキャッシュ メカニズムを使用してディスクからバッチで読み取り、キャッシュとしてメモリに保存することで、以降の読み取りを高速化できます。同時に、ConsumeQueue 内の各メッセージのインデックスは固定長であるため、メッセージ消費の時間計算量が O(1) のままであることも保証できます。
- 完全なシーケンシャル書き込みを保証するには、中間構造体 ConsumeQueue が必要です。ConsumeQueue にはオフセット情報のみが格納されるため、サイズが制限されます。実際には、ほとんどの ConsumeQueue は完全にメモリに読み込むことができるため、この中間構造体が動作速度を向上させます。は非常に高速であり、これはメモリの読み取り速度と考えることができます。さらに、CommitLog と ConsumeQueue の間の一貫性を確保するために、CommitLog には Consume Queues、メッセージ キー、タグなどのすべての情報が保存されます。ConsumeQueue が失われた場合でも、commitLog を通じて完全に復元できます。
インデックスファイル
Index には、メッセージ クエリを高速化するために使用されるインデックス ファイルが格納されます。メッセージ消費キュー RocketMQ は、トピックやメッセージに基づいてメッセージを取得する速度を向上させるために、メッセージ サブスクリプション用に特別に構築されたインデックス ファイルであり、ハッシュ インデックス メカニズム、特にハッシュ スロットとハッシュ競合のリンク リスト構造を使用します。
構成
config フォルダーには、トピックやコンシューマーなどの関連情報が保存されます。トピックと消費者グループに関連する情報はここにあります。
ブローカーメッセージの書き込みプロセス
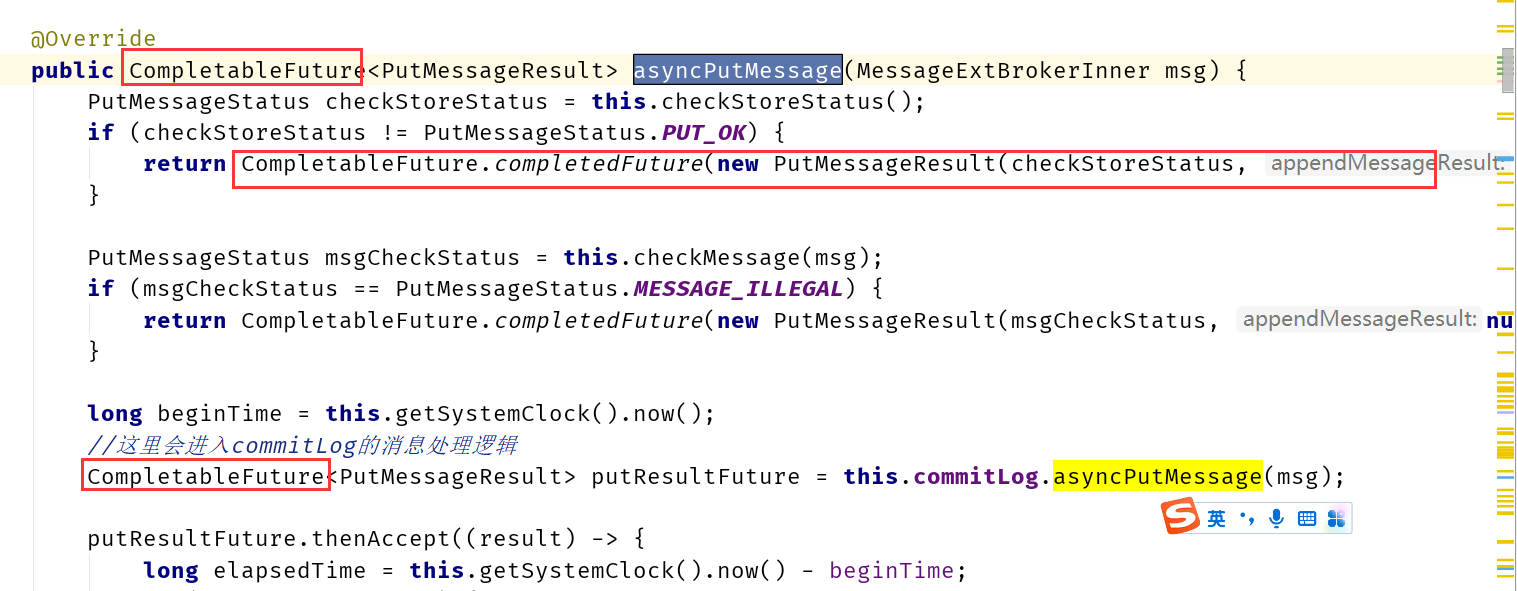
RocketMQ は Netty を使用してネットワークを処理し、ブローカーがメッセージの書き込みリクエストを受信すると、SendMessageProcessor クラスの processRequest メソッドに入ります。

最後に、DefaultMessageStore クラスに asyncPutMessage メソッドを入力してメッセージを保存します。

次に、メッセージは commitlog クラスの asyncPutMessage メソッドに入り、メッセージを保存します。

ストレージ設計全体の階層は非常に明確で、大まかな階層は次のとおりです。
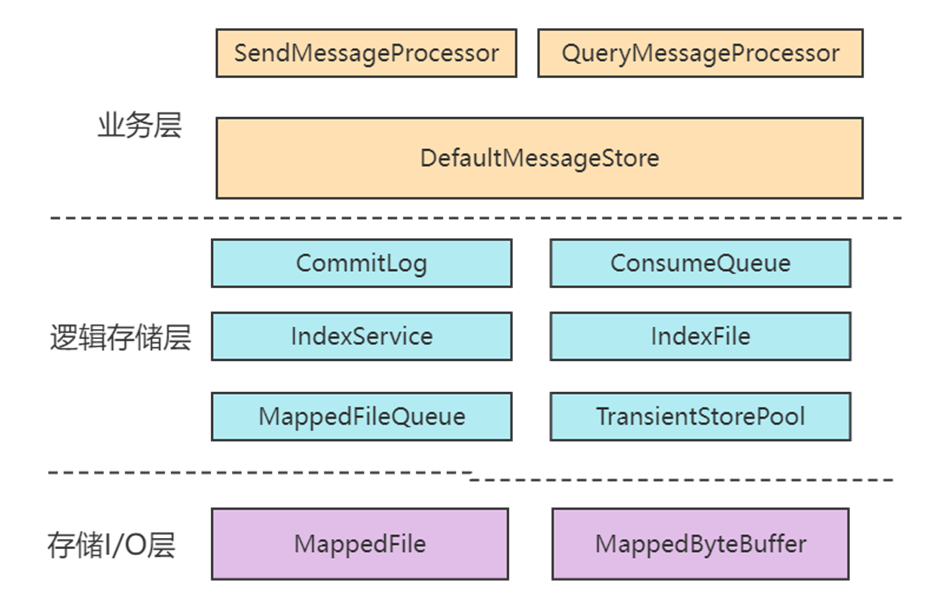
ブローカー設計のハイライト
NRSとNRCの機能番号設計
RocketMQ は通信に Netty を使用し、RemotingCommand と NettyRemotingClient という 2 つのコア クライアント クラスがあります。
RemotingCommand は主に、メッセージ ヘッダー、メッセージのシリアル化と逆シリアル化などのメッセージ アセンブリを処理します。
NettyRemotingClient は主に、同期、非同期、一方向、登録、その他の操作を含むメッセージ送信を処理します。


RocketMQ メッセージには多くの種類があるため、メッセージ送信には関数番号に似た設計が使用されます。クライアントはメッセージを送信するときに、関数に対応するコードを定義し、サーバーはコードのビジネス プロセスに対応するビジネス プロセスを登録します。
例: プロデューサー クライアント コードから、NRC コードにジャンプします: NettyRemotingClient
MQClientAPIImpl クラスの sendMessage() 内
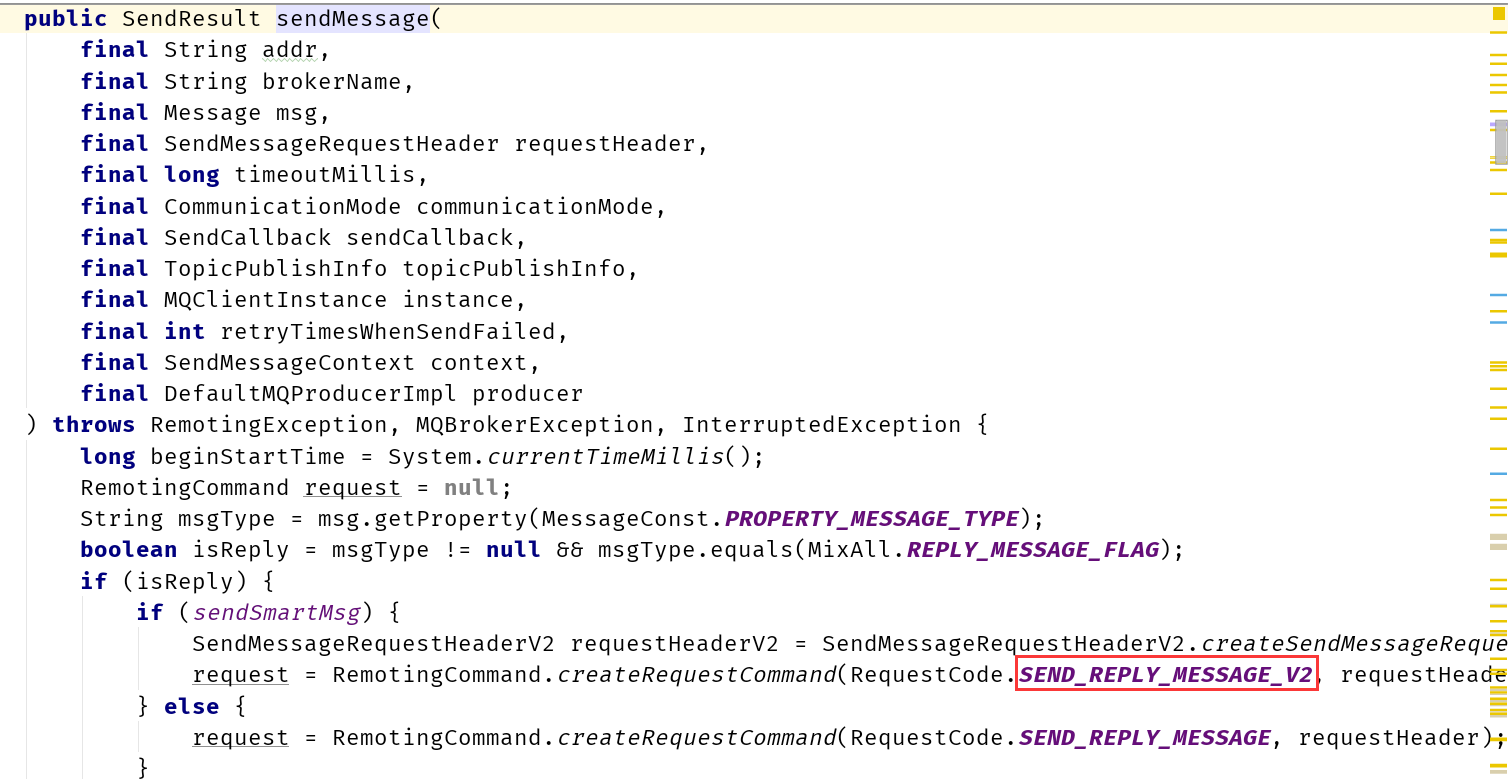
NettyRemotingClientクラス
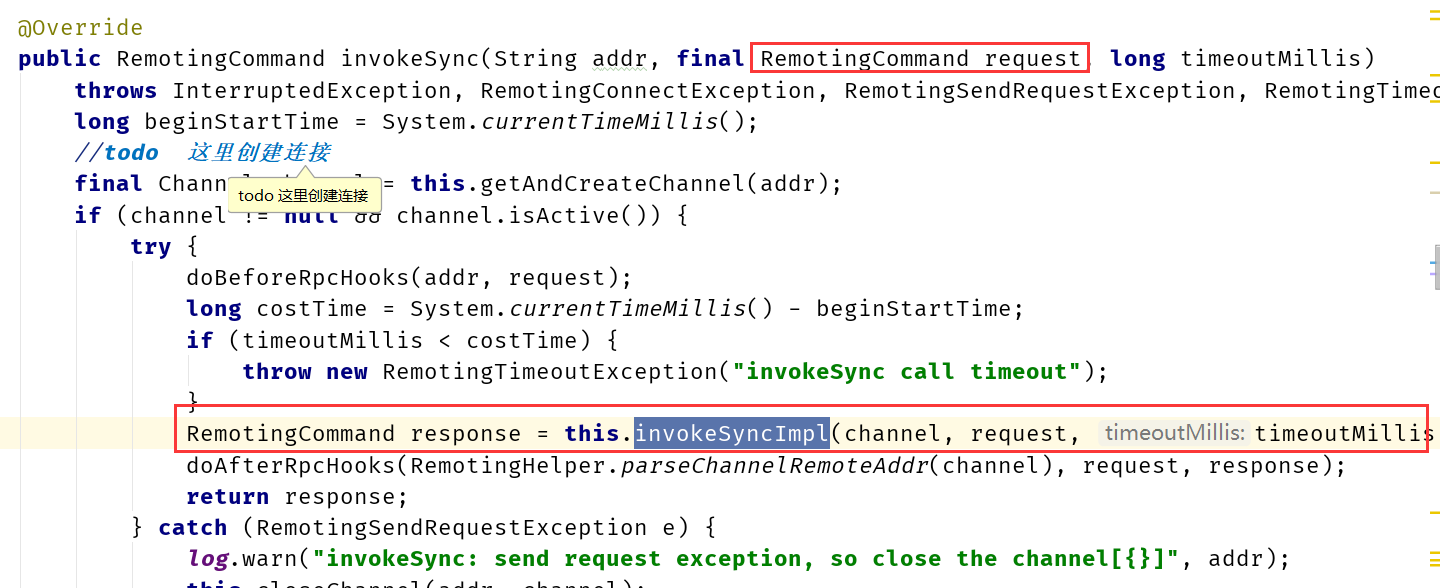
 NRS では、サーバーが処理する必要がある ExecutorService を NRS コンポーネントに登録するだけで済みます。
NRS では、サーバーが処理する必要がある ExecutorService を NRS コンポーネントに登録するだけで済みます。
起動プロセスのBrokerControllerクラスのinitialize()内
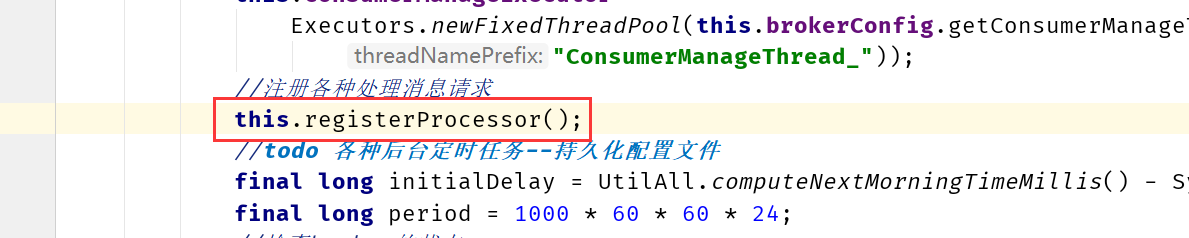
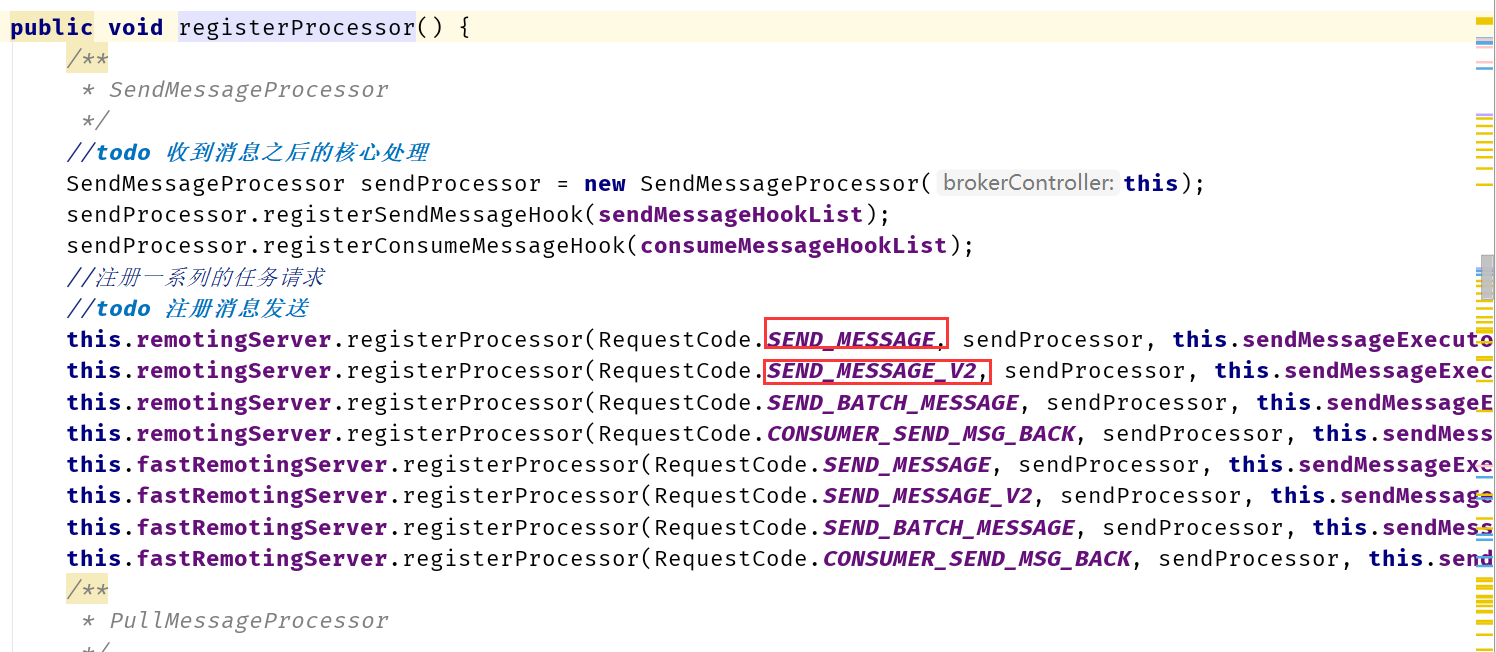
注: 関数番号の設計はクライアントとサーバー間で 1 対 1 ではなく、サーバー側では、多くの場合、異なる関数番号が 1 つの処理タスクにマップされることがあります。
CompletableFuture の同期二重書き込みパフォーマンスが数倍向上
RocketMQ4.7.0 以降、RocketMQ は Java の非同期プログラミング インターフェイス CompletableFuture を広範囲に使用します。特にブローカー側でメッセージを受信して処理する場合。
例: DefaultMessageStore クラスの asyncPutMessage メソッド
Future インターフェイスは、デザイン パターンにおける Future モードの実装です。リクエストまたはタスクに時間がかかる場合は、メソッド呼び出しを非同期に変更でき、メソッドはすぐに戻り、タスクはメイン スレッド以外の他のスレッドを使用して非同期で実行されます。スレッドが実行され、メインスレッドは実装を続行します。計算結果を取得する必要がある場合は、データを取得します。
マスター/スレーブ マスター/スレーブ アーキテクチャでは、マスター ノードとスレーブ ノード間のデータ同期/レプリケーションには、同期二重書き込みと非同期レプリケーションの 2 つのモードがあります。同期二重書き込みとは、マスターがメッセージをディスクに正常に配置した後、メッセージが正常に送信されたことをクライアントに通知する前に、スレーブ ノードが正常にコピーするまで待機する必要があることを意味します (複数のスレーブがある場合は、1 つだけ正常にコピーします)。
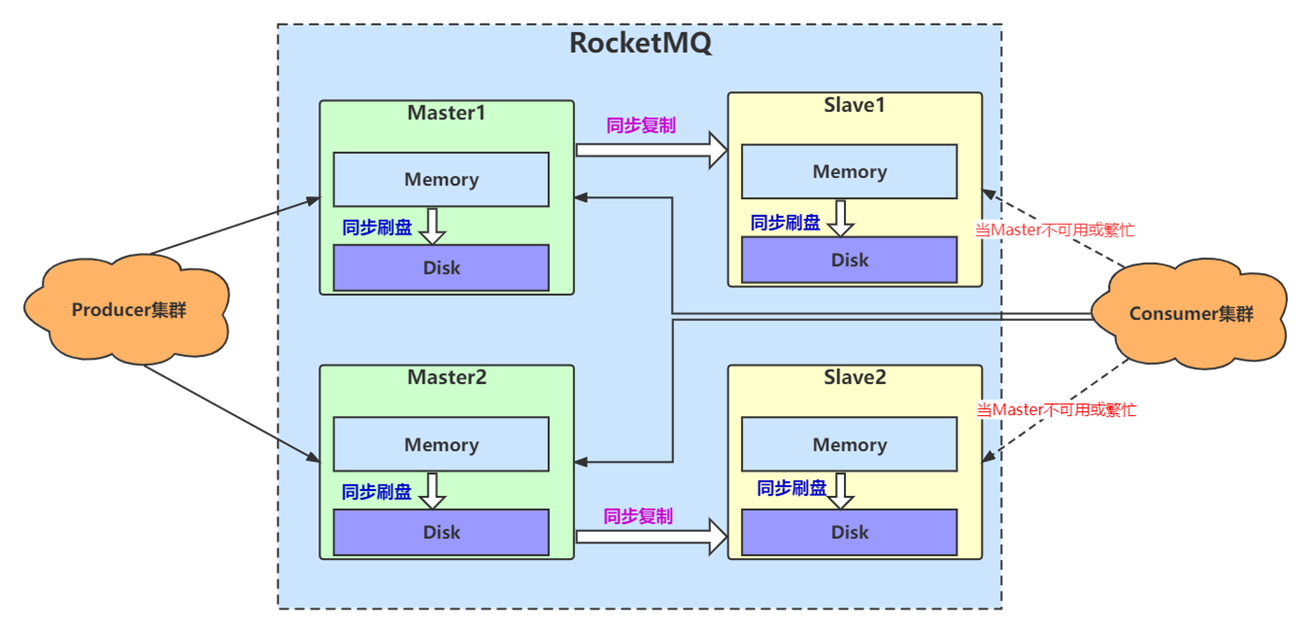
RocketMQ 4.7.0 以降では、CompletableFuture を合理的に使用して同期二重書き込みのパフォーマンスを最適化し、メッセージの処理を合理化し、ブローカーのメッセージ受信能力を大幅に向上させます。
Commitlog を書き込むときにリエントラント ロックまたはスピン ロックを使用しますか?
RocketMQ は、メッセージを CommitLog に書き込むときにロック メカニズムを使用します。つまり、同時に 1 つのスレッドのみが CommitLog ファイルに書き込むことができます。CommitLog では 2 つのロックが使用されます。1 つはスピン ロック、もう 1 つはリエントラント ロックです。ソースコードは次のとおりです。

ロックの種類は個別に設定できます。RocketMQ 公式ドキュメントの最適化に関する提案: 非同期ディスク ブラッシングにはスピン ロックを使用し、同期ディスク ブラッシングにはリエントラント ロックを使用することをお勧めします。ブローカー構成項目 useReentrantLockWhenPutMessage を調整します (デフォルトは false)。
ディスクを同期的にブラッシングすると、ロックの競合が激しくなり、より多くのスレッドがブロックされてロックを待機することになります。スピン ロックを使用すると、大量の CPU 時間が無駄になるため、「同期ディスクには再入可能ロックを使用することをお勧めします」ブラッシング。」
非同期ディスク ブラッシングは、一定の間隔でディスクをブラッシングします。ロックの競合は激しくなく、ロックを待って多数のスレッドがブロックされることはありません。ロックが待機している場合、時折、スピンして短時間待機します。コンテキストの切り替えを実行しないため、スピンが使用されます。ロックの方が適切です。
ゼロコピーテクノロジー MMAP によりファイルの読み取りおよび書き込みパフォーマンスが向上
ゼロコピー(英語: Zero-copy )テクノロジーとは、コンピュータが操作を実行する際に、CPU が最初にあるメモリ位置から別の特定の領域にデータをコピーする必要がないことを意味します。この手法は、ネットワーク上でファイルを転送するときに CPU サイクルとメモリ帯域幅を節約するために一般的に使用されます。MMAP はゼロコピー テクノロジの一種です。
RocketMQ の最下層は、commitLog や ConsumerQueue などのディスク ファイルの読み取りおよび書き込み操作に mmap テクノロジを使用します。具体的には、コード内では、JDK の NIO の MapperByteBuffer の map() 関数を使用して、最初にディスク ファイル (CommitLog ファイル、consumerQueue ファイル) をメモリにマップします。
mmap テクノロジが使用されていない場合、IO 操作に最も伝統的で基本的な通常のファイルを使用すると、データのコピーが複数発生します。たとえば、ディスクからカーネル IO バッファにデータを読み取り、次にカーネル IO バッファからユーザー プロセスのプライベート領域にデータを読み取ることで、データを取得できます。
MMAP メモリ マッピングは、ハード ディスク上のファイルの場所をアプリケーション バッファにマッピングします (1 対 1 の対応を確立します)。mmap() はファイルをユーザー空間に直接マッピングするため、実際のファイルはこのマッピング関係に従って読み取られます。ファイルをハードディスクからユーザー空間に直接コピーします。データ コピーは 1 回だけ実行され、ファイルの内容はハードディスクからカーネル空間のバッファにコピーされません。
mmap テクノロジには、アドレス マッピング プロセス中のファイル サイズに制限があり、1.5G ~ 2G です。そのため、RocketMQ は、単一の commitLog ファイルのサイズを 1GB に、consumseQueue ファイルのサイズを 5.72MB に制御します。読み書き、メモリマッピングが便利です。
Broker起動時のMMAP関連のソースコードは以下のとおりです。

プロデューサがメッセージを送信するとき、MMAP 関連メッセージのソース コードは次のように記述されます。

オフヒープメモリメカニズム
通常の状況では、RocketMQ は MMAP メモリ マッピングを使用し、メッセージは運用中にメモリ マップされたファイルに書き込まれ、消費中に再び読み取られます。ただし、RocketMQ はメカニズムも提供します。オフヒープ メモリ メカニズム: TransientStorePool、短期ストレージ プール (オフヒープ メモリ)。
オフヒープメモリの有効化
オフヒープ メモリを有効にするには、構成ファイル Broker.conf を変更する必要があります: transientStorePoolEnable=true
同時に、オフヒープ メモリ バッファーが有効になっている場合は、クラスター モードが非同期ディスク フラッシュ モードであり、ブローカーがマスター ノードである必要があります。この制限は、ソース コードを表示すると確認できます。
デフォルトのメッセージストア。DefaultMessageStore()


オフヒープ メモリのフローチャートから、オフヒープ メモリにメッセージを書き込むには明らかにもう 1 つのステップが必要であることがわかります。そのため、オフヒープ メモリ バッファの設定は非同期にする必要があります。
オフヒープバッファプロセス
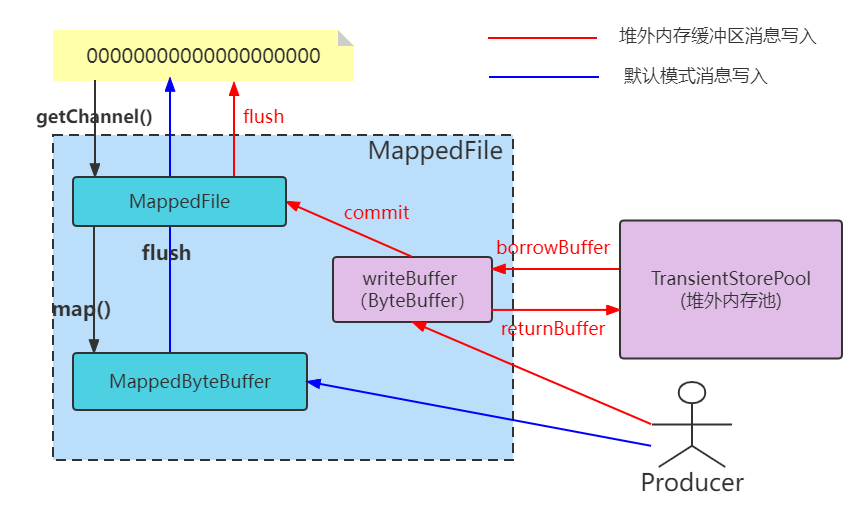
RocketMQ は、データを一時的に保存するために別の ByteBuffer メモリ キャッシュ プールを作成します。データは最初にメモリ マップに書き込まれ、その後、コミット スレッドによってメモリからターゲット物理ファイルに対応するメモリ マップにデータが定期的にコピーされます。RocketMQ がこのメカニズムを導入する主な理由は、プロセスがメモリをディスクにスワップしないように、現在のオフヒープ メモリをメモリ内にロックしたままにするメモリ ロックを提供することです。同時に、オフヒープ メモリであるため、この設計では頻繁な GC を回避できます。
オフヒープメモリバッファリングの意味
デフォルト モード (Mmap+PageCache) では、すべての読み取りおよび書き込みメッセージが pageCache (MappedByteBuffer クラス) を経由します。この方法では、読み取りと書き込みはすべてページキャッシュ内で行われるため、必然的にロックの問題が発生します。および書き込み操作では、ページ フォールト割り込みの削減、メモリ ロック、汚染されたページのライトバックが行われます)。
オフヒープバッファを使用する場合、DirectByteBuffer(オフヒープメモリ)+PageCacheの2層アーキテクチャにより、メッセージの読み書き分離を実現します。メッセージ書き込み時はDirectByteBufferがオフヒープメモリに書き込まれ、読み出しメッセージは最も重要なことは、PageCache (MappedByteBuffer クラス) です。利点は、メモリ操作でブロックされやすい多くの領域を回避し、ページ フォールト割り込み、メモリ ロック、汚染されたページのライトバックの削減など、待ち時間を短縮できることです。 。
したがって、オフヒープ バッファを使用する方が比較的良いですが、確実に一定量のメモリが必要です。サーバーのメモリが不足している場合、このモードはお勧めできません。同時に、オフヒープ バッファも必要です。ディスクは使用できます(データの書き込みが 2 つのステップに分かれているため、同期ディスク フラッシュの遅延は比較的大きくなります)。