より高速かつ柔軟な Transformer 画像のかすみ除去ネットワーク
この記事では、ICCV 2023 の論文を共有しMB-TaylorFormer: Multi-branch Efficient Transformer Expanded by Taylor Formula for Image Dehazing、より高速で柔軟な Transformer 画像のかすみ除去ネットワークを紹介します。
-
論文リンク: https://arxiv.org/abs/2308.14036
-
コードリンク: https://github.com/FVL2020/ICCV-2023-MB-TaylorFormer
抽象的な
この記事では、画像のかすみ除去タスクを効果的かつ効率的に実行できる、MB-TaylorFormer と呼ばれる新しいマルチブランチ線形 Transformer ネットワークを紹介します。
MB-TaylorFormer は次の貢献を行っています。
-
テイラー展開に基づく線形 Transformer ネットワークは、ピクセル間の長距離関係をモデル化します。MSAR モジュールは、softmax-attention の Taylor 展開のエラーを修正するために導入されました。
-
マルチブランチおよびマルチスケール構造を通じて、マルチスケールの受容野、マルチレベルの意味情報、およびより柔軟な受容野の形状を備えたトークンを抽出します。
-
パフォーマンスが向上し、計算量が減り、ネットワークが軽量になります。
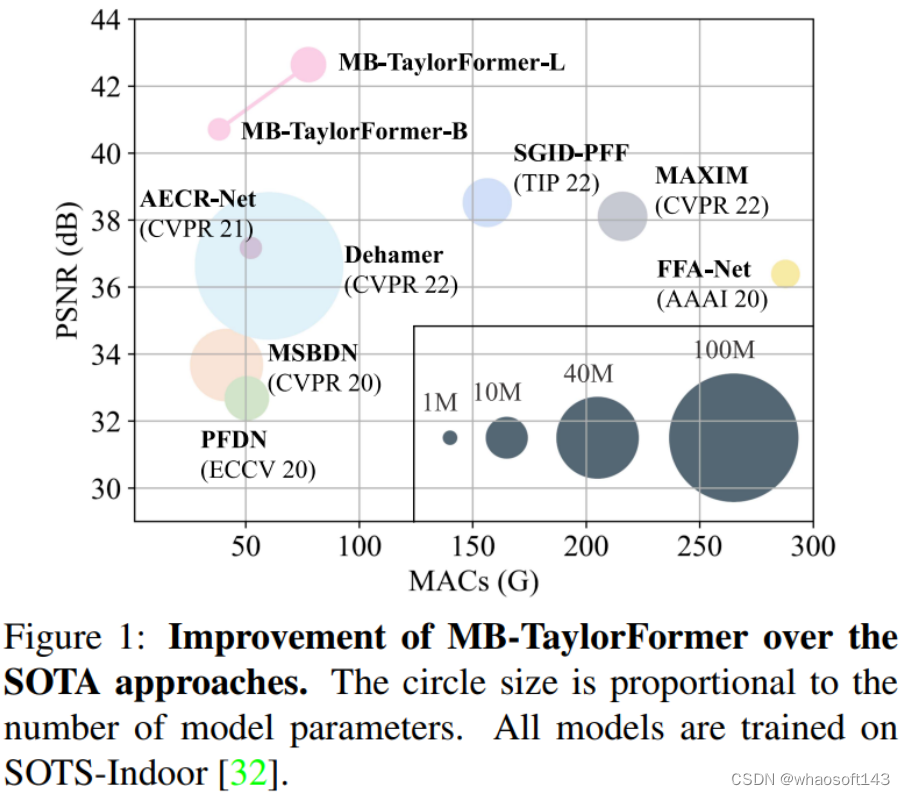
複数のかすみ除去データセット (ITS、OTS、O-HAZE、Dense-Haze) で実験を行います。実験結果は、MB-TaylorFormer が非常に低いパラメーターと計算複雑さで他の SOTA ソリューションよりも優れたパフォーマンスを発揮することを示しています。さらに、雨と雪の除去の実験結果は、MB-TaylorFormer が同様に効果的であることを示しています。
方法
ネットワーク アーキテクチャ 上の図は、この記事で提案する MB-TaylorFormer の 3 つのコア モジュールを示しています。マルチスケール パッチ エンベディング (図 2.b)、Taylor 拡張セルフアテンション (図 2.c)、MSAR モジュール (図 2.d) です。 )。
上の図は、この記事で提案する MB-TaylorFormer の 3 つのコア モジュールを示しています。マルチスケール パッチ エンベディング (図 2.b)、Taylor 拡張セルフアテンション (図 2.c)、MSAR モジュール (図 2.d) です。 )。
マルチスケールパッチの埋め込み
NLP 分野と比較して、ビジュアル トークンは規模が非常に柔軟です。既存の研究では、パッチの埋め込みでカーネル サイズが固定された畳み込みが採用されており、その結果、ビジュアル トークンのスケールが 1 つになる可能性があります。この問題を解決するために、次の 3 つの特徴を持つ新しいマルチスケール パッチ エンベディングを設計しました。
-
マルチスケール受容野
-
マルチレベルの意味情報
-
柔軟な受容野形状。
具体的には、異なるスケールのコンボリューション カーネルを使用して複数の並列変形可能コンボリューション (DCN) を設計することで、次の図に示すように、パッチ エンベディングが粗いおよび細かい視覚的マーカーを生成し、柔軟な表現機能を備えられるようにします。より大きな受容野を取得するために 3*3 畳み込みの複数の層を積み重ねることから着想を得て、より豊富なサンプリング ポイントを取得するために小さな畳み込みカーネルを備えた複数の DCN を積み重ねました。これにより、ネットワークの深さが増し、マルチレベルのセマンティック情報が提供されるだけでなく、パラメータと計算負荷の軽減にも役立ちます。さらに、DCN に 2 つの小さな変更も追加しました。
-
オフセットを切り詰めることにより、トークンはローカルエリアにさらに重点を置きます。
-
深さ方向の分離可能畳み込み戦略と同様に、DCN の各部分を深さ方向の畳み込みと点ごとの畳み込みに分解する深さ方向の分離可能変形畳み込み (DSDCN) を提案します。

テイラーは複数の頭の自己注意を拡張しました
オリジナルの Transformer の Self-attention 表現は次のとおりです。
 T-MSA には次の 3 つの利点があります。
T-MSA には次の 3 つの利点があります。
-
分割窓による受容野の減少に限定されない
-
チャネル間のセルフ アテンションではなく、グローバル ピクセル セルフ アテンションを実行します。
-
一般的なカーネル関数法と比較して、数値的にはSoftmax-attentionに近いです。
マルチスケールの注意力の洗練
テイラー展開の残りを無視することによって生じる避けられない誤差のため、 実験
実験
主な結果
 上の表は、MB-TaylorFormer と他の SOTA モデルの比較を示しています。
上の表は、MB-TaylorFormer と他の SOTA モデルの比較を示しています。
-
合成データセット (SOTS-Indoor、SOTS-Outdoor) では、MB-TaylroFormer-B はそれぞれ 40.71dB と 37.42dB の指標を達成し、MB-TaylroFormer-L はそれぞれ 42.64dB と 38.09dB の指標を達成しました。これは、以前よりも優れています。 SGID -PFF 38.52dB および 30.20dB
-
実際のデータセット (O-HAZE および Dense-Haze) では、MB-TaylroFormer-L および MB-TaylroFormer-B は、以前の最良のソリューション Dehamer をそれぞれ 0.20dB および 0.04dB 上回りました。
-
他のソリューションと比較して、MB-TaylorFormer-B は計算量とパラメータ量が少なく、インジケーターが多くなっています。
 上の図は、合成データ セットと実際のデータの視覚効果の比較を示しており、MB-TaylorFormer は影の細部をより適切に復元するだけでなく、アーティファクトや色かぶりを効果的に回避していることがわかります。
上の図は、合成データ セットと実際のデータの視覚効果の比較を示しており、MB-TaylorFormer は影の細部をより適切に復元するだけでなく、アーティファクトや色かぶりを効果的に回避していることがわかります。
アブレーション研究
 マルチスケールパッチ埋め込みとマルチブランチ構造の検討
マルチスケールパッチ埋め込みとマルチブランチ構造の検討
表 2 は、さまざまなパッチの埋め込みとさまざまなブランチ番号の影響を調べたもので、単一のブランチをベースラインとして、次のこと がわかります。
-
同様のパラメーターと浮動小数点計算では、単一ブランチよりもマルチブランチの方が優れています。
-
マルチスケール受容野 (Dirated Conv-P) は、シングルスケール受容野 (Conv-P) と比較して +0.35dB の改善をもたらします。
-
マルチレベル意味情報 (Conv-S) は、マルチレベル意味情報なし (Dirated Conv-P) と比較して +0.27dB の改善をもたらします。
-
より柔軟な受容野形状 (DSDCN-S) は、固定受容野形状 (Conv-S) と比較して +1.67dB の改善をもたらします。
マルチスケール注意力改良モジュールの有効性
表 3 は、MSAR モジュールの設計により、非常に軽量な設計で TaylorFormer のパフォーマンスを効果的に向上できることを示しています。
他のリニアセルフアテンションモジュールとの比較
表 4 は、T-MSA とさまざまな線形変圧器を比較することにより、曇り除去タスクにおける T-MSA の有効性を示しています。
近似誤差の解析
近似誤差の影響を検証するために、Swin ウィンドウ内で Softmax-attention の Taylor 展開を実行しましたが、softmax-attention を高次に展開すると、より良い数値が得られるため、パフォーマンスが向上することがわかりました。注意マップのランクは高くなります。
注: Swin のウィンドウは 8 であるため、N>>d の性質はありません。したがって、表 5 の実験における MAC の計算量は行列乗算の結合法則から導出されるものではありません。
研究室紹介
中山大学知能工学部のFrontier Vision Laboratory (FVLホームページ: https://fvl2020.github.io/fvl.github.com/) は、同校のJin Zhi准教授によって建設および維持されています。この研究室は現在、画像/ビデオの品質向上、ビデオのエンコードとデコード、3D 再構築、非接触の人間のバイタルサインのモニタリングなどの分野の研究に重点を置いています。ビデオ画像の取得と送信から、拡張およびサービスのバックエンド アプリケーションまでのサイクル全体を最適化するように設計されています。目標は、共通の概念と軽量なメソッドを開発することです。