Article directory
Preface
This article implements the RegNet network structure based on chainer, builds the chainer version based on the torch structure, and calculates the parameters of RegNet.
Code
def _mcfg(**kwargs):
cfg = dict(se_ratio=0., bottle_ratio=1., stem_width=32)
cfg.update(**kwargs)
return cfg
def generate_width_depth(wa, w0, wm, depth, q=8):
"""Generates per block widths from RegNet parameters."""
assert wa > 0 and w0 > 0 and wm > 1 and w0 % q == 0
widths_cont = np.arange(depth) * wa + w0
width_exps = np.round(np.log(widths_cont / w0) / np.log(wm))
widths_j = w0 * np.power(wm, width_exps)
widths_j = np.round(np.divide(widths_j, q)) * q
num_stages, max_stage = len(np.unique(widths_j)), width_exps.max() + 1
assert num_stages == int(max_stage)
assert num_stages == 4
widths = widths_j.astype(int).tolist()
return widths, num_stages
def adjust_width_groups_comp(widths: list, groups: list):
"""Adjusts the compatibility of widths and groups."""
groups = [min(g, w_bot) for g, w_bot in zip(groups, widths)]
# Adjust w to an integral multiple of g
widths = [int(round(w / g) * g) for w, g in zip(widths, groups)]
return widths, groups
class ConvBNAct(chainer.Chain):
def __init__(self, in_c: int, out_c: int, kernel_s: int = 1, stride: int = 1, padding: int = 0, groups: int = 1, act= ReLU()):
super(ConvBNAct, self).__init__()
self.layers = []
self.layers += [('conv',L.Convolution2D(in_channels=in_c, out_channels=out_c, ksize=kernel_s, stride=stride, pad=padding, groups=groups, nobias=True))]
self.layers += [('bn',BatchNormalization(out_c))]
if act is not None:
self.layers += [('_relu',ReLU())]
with self.init_scope():
for n in self.layers:
if not n[0].startswith('_'):
setattr(self, n[0], n[1])
def forward(self, x):
for n, f in self.layers:
if not n.startswith('_'):
x = getattr(self, n)(x)
else:
x = f.apply((x,))[0]
return x
class RegHead(chainer.Chain):
def __init__(self, in_unit: int = 368, out_unit: int = 1000, output_size: tuple = (1, 1), drop_ratio: float = 0.25):
super(RegHead, self).__init__()
self.layers = []
self.layers += [('avg_pool2d',functools.partial(F.average, axis=(2, 3)))]
self.layers += [('avg_pool2d',functools.partial(F.flatten))]
if drop_ratio > 0:
self.layers += [("_dropout1",Dropout(drop_ratio))]
self.layers += [('fc',L.Linear(in_unit,out_unit))]
with self.init_scope():
for n in self.layers:
if not n[0].startswith('_'):
setattr(self, n[0], n[1])
def forward(self, x):
for n, f in self.layers:
print(n)
if not n.startswith('_'):
x = getattr(self, n)(x)
else:
x = f.apply((x,))[0]
return x
class SqueezeExcitation(chainer.Chain):
def __init__(self, input_c: int, expand_c: int, se_ratio: float = 0.25):
super(SqueezeExcitation, self).__init__()
squeeze_c = int(input_c * se_ratio)
self.layers = []
self.layers += [('mean',functools.partial(F.mean, axis=(2, 3)))]
self.layers += [('fc1',L.Convolution2D(expand_c, squeeze_c, 1))]
self.layers += [('_relu1',ReLU())]
self.layers += [('fc2',L.Convolution2D(squeeze_c, expand_c, 1))]
self.layers += [('_relu2',Sigmoid())]
with self.init_scope():
for n in self.layers:
if not n[0].startswith('_'):
setattr(self, n[0], n[1])
def forward(self, x):
scale = x
for n, f in self.layers:
if not n.startswith('_'):
scale = getattr(self, n)(scale)
else:
scale = f.apply((scale,))[0]
return scale * x
class Bottleneck(chainer.Chain):
def __init__(self, in_c: int, out_c: int, stride: int = 1, group_width: int = 1, se_ratio: float = 0., drop_ratio: float = 0.):
super(Bottleneck, self).__init__()
self.layers = []
self.layers += [('conv1',ConvBNAct(in_c=in_c, out_c=out_c, kernel_s=1))]
self.layers += [('conv2',ConvBNAct(in_c=out_c, out_c=out_c, kernel_s=3, stride=stride, padding=1, groups=out_c // group_width))]
if se_ratio > 0:
self.layers += [('se',SqueezeExcitation(in_c, out_c, se_ratio))]
self.layers += [('conv3',ConvBNAct(in_c=out_c, out_c=out_c, kernel_s=1, act=None))]
if drop_ratio > 0:
self.layers += [("_dropout1",Dropout(drop_ratio))]
self.downsample=[]
if (in_c != out_c) or (stride != 1):
self.downsample += [('downsample1',ConvBNAct(in_c=in_c, out_c=out_c, kernel_s=1, stride=stride, act=None))]
with self.init_scope():
for n in self.layers:
if not n[0].startswith('_'):
setattr(self, n[0], n[1])
for n in self.downsample:
if not n[0].startswith('_'):
setattr(self, n[0], n[1])
def forward(self, x):
shortcut = x
for n, f in self.layers:
if not n.startswith('_'):
x = getattr(self, n)(x)
else:
x = f.apply((x,))[0]
for n, f in self.downsample:
if not n.startswith('_'):
shortcut = getattr(self, n)(shortcut)
else:
shortcut = f.apply((shortcut,))[0]
x += shortcut
x = F.relu(x)
return x
class RegStage(chainer.Chain):
def __init__(self, in_c: int, out_c: int, depth: int, group_width: int, se_ratio: float):
super(RegStage, self).__init__()
self.layers = []
for i in range(depth):
block_stride = 2 if i == 0 else 1
block_in_c = in_c if i == 0 else out_c
name = "b{}".format(i + 1)
self.layers += [(name,Bottleneck(in_c=block_in_c, out_c=out_c, stride=block_stride, group_width=group_width, se_ratio=se_ratio))]
with self.init_scope():
for n in self.layers:
if not n[0].startswith('_'):
setattr(self, n[0], n[1])
def forward(self, x):
for n, f in self.layers:
if not n.startswith('_'):
x = getattr(self, n)(x)
else:
x = f.apply((x,))[0]
return x
class RegNet(chainer.Chain):
cfgs = {
"regnetx_200mf": _mcfg(w0=24, wa=36.44, wm=2.49, group_w=8, depth=13),
"regnetx_400mf": _mcfg(w0=24, wa=24.48, wm=2.54, group_w=16, depth=22),
"regnetx_600mf": _mcfg(w0=48, wa=36.97, wm=2.24, group_w=24, depth=16),
"regnetx_800mf": _mcfg(w0=56, wa=35.73, wm=2.28, group_w=16, depth=16),
"regnetx_1.6gf": _mcfg(w0=80, wa=34.01, wm=2.25, group_w=24, depth=18),
"regnetx_3.2gf": _mcfg(w0=88, wa=26.31, wm=2.25, group_w=48, depth=25),
"regnetx_4.0gf": _mcfg(w0=96, wa=38.65, wm=2.43, group_w=40, depth=23),
"regnetx_6.4gf": _mcfg(w0=184, wa=60.83, wm=2.07, group_w=56, depth=17),
"regnetx_8.0gf": _mcfg(w0=80, wa=49.56, wm=2.88, group_w=120, depth=23),
"regnetx_12gf": _mcfg(w0=168, wa=73.36, wm=2.37, group_w=112, depth=19),
"regnetx_16gf": _mcfg(w0=216, wa=55.59, wm=2.1, group_w=128, depth=22),
"regnetx_32gf": _mcfg(w0=320, wa=69.86, wm=2.0, group_w=168, depth=23),
"regnety_200mf": _mcfg(w0=24, wa=36.44, wm=2.49, group_w=8, depth=13, se_ratio=0.25),
"regnety_400mf": _mcfg(w0=48, wa=27.89, wm=2.09, group_w=8, depth=16, se_ratio=0.25),
"regnety_600mf": _mcfg(w0=48, wa=32.54, wm=2.32, group_w=16, depth=15, se_ratio=0.25),
"regnety_800mf": _mcfg(w0=56, wa=38.84, wm=2.4, group_w=16, depth=14, se_ratio=0.25),
"regnety_1.6gf": _mcfg(w0=48, wa=20.71, wm=2.65, group_w=24, depth=27, se_ratio=0.25),
"regnety_3.2gf": _mcfg(w0=80, wa=42.63, wm=2.66, group_w=24, depth=21, se_ratio=0.25),
"regnety_4.0gf": _mcfg(w0=96, wa=31.41, wm=2.24, group_w=64, depth=22, se_ratio=0.25),
"regnety_6.4gf": _mcfg(w0=112, wa=33.22, wm=2.27, group_w=72, depth=25, se_ratio=0.25),
"regnety_8.0gf": _mcfg(w0=192, wa=76.82, wm=2.19, group_w=56, depth=17, se_ratio=0.25),
"regnety_12gf": _mcfg(w0=168, wa=73.36, wm=2.37, group_w=112, depth=19, se_ratio=0.25),
"regnety_16gf": _mcfg(w0=200, wa=106.23, wm=2.48, group_w=112, depth=18, se_ratio=0.25),
"regnety_32gf": _mcfg(w0=232, wa=115.89, wm=2.53, group_w=232, depth=20, se_ratio=0.25)
}
def _build_stage_info(self,cfg: dict):
wa, w0, wm, d = cfg["wa"], cfg["w0"], cfg["wm"], cfg["depth"]
widths, num_stages = generate_width_depth(wa, w0, wm, d)
stage_widths, stage_depths = np.unique(widths, return_counts=True)
stage_groups = [cfg['group_w'] for _ in range(num_stages)]
stage_widths, stage_groups = adjust_width_groups_comp(stage_widths, stage_groups)
info = []
for i in range(num_stages):
info.append(dict(out_c=stage_widths[i], depth=stage_depths[i], group_width=stage_groups[i], se_ratio=cfg["se_ratio"]))
return info
def __init__(self,
model_name='regnetx_200mf',
channels: int = 3,batch_size=4,image_size=224,
num_classes: int = 1000,**kwargs):
super(RegNet, self).__init__()
self.image_size = image_size
self.layers = []
# RegStem
stem_c = self.cfgs[model_name]["stem_width"]
self.layers += [('stem',ConvBNAct(channels, out_c=stem_c, kernel_s=3, stride=2, padding=1))]
output_size = int((self.image_size-3+2*1)/2+1)
# build stages
input_channels = stem_c
stage_info = self._build_stage_info(self.cfgs[model_name])
for i, stage_args in enumerate(stage_info):
stage_name = "s{}".format(i + 1)
self.layers += [(stage_name, RegStage(in_c=input_channels, **stage_args))]
input_channels = stage_args["out_c"]
output_size = int((output_size-3+2*1)/2+1)
# RegHead
# self.layers += [('reg_head',RegHead(in_unit=input_channels, out_unit=num_classes))]
self.layers += [('_avgpool',AveragePooling2D(ksize=output_size,stride=1,pad=0))]
self.layers += [('_reshape',Reshape((batch_size,input_channels)))]
self.layers += [('fc',L.Linear(input_channels, num_classes))]
with self.init_scope():
for n in self.layers:
if not n[0].startswith('_'):
setattr(self, n[0], n[1])
def __call__(self, x):
for n, f in self.layers:
origin_size = x.shape
if not n.startswith('_'):
x = getattr(self, n)(x)
else:
x = f.apply((x,))[0]
print(n,origin_size,x.shape)
if chainer.config.train:
return x
return F.softmax(x)
Note that this class is the implementation process of RegNet. Note that the forward propagation process of the network is divided into training and testing.
During the training process, x is returned directly, and during the testing process, softmax is entered to obtain the probability.
Calling method
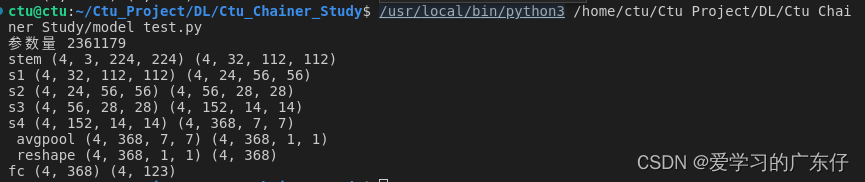
if __name__ == '__main__':
batch_size = 4
n_channels = 3
image_size = 224
num_classes = 123
model = RegNet(num_classes=num_classes, channels=n_channels,image_size=image_size,batch_size=batch_size)
print("参数量",model.count_params())
x = np.random.rand(batch_size, n_channels, image_size, image_size).astype(np.float32)
t = np.random.randint(0, num_classes, size=(batch_size,)).astype(np.int32)
with chainer.using_config('train', True):
y1 = model(x)
loss1 = F.softmax_cross_entropy(y1, t)