1.メッセージキューの詳細説明
メッセージ キュー (メッセージ キュー) は分散システムの重要なコンポーネントです。その一般的な使用シナリオは次のように簡単に説明できます: 結果をすぐに取得する必要はないが、同時実行性を制御する必要がある場合、メッセージ キューがほぼ必要になります。いつ
主に解決するのは、アプリケーションの結合、非同期メッセージング、トラフィックの削減、その他の問題です。高いパフォーマンス、高可用性、拡張性、そして結果的に一貫したアーキテクチャを実現します。大規模分散システムには欠かせないミドルウェアです。
現在実稼働環境で最も一般的に使用されているメッセージ キューには、ActiveMQ、 RabbitMQ、ZeroMQ、Kafka、MetaMQ、RocketMQ などが含まれます。
1. メッセージキューの 2 つのモデル
1.1. ポイントツーポイントモデル
各メッセージには受信者 ( Consumer )が 1 つだけあります。メッセージが送信されると、メッセージ キューには存在しません。
送信者と受信者の間に依存関係はありません。送信者がメッセージを送信した後は、受信者が実行されているかどうかは関係ありません。かどうかは、以下には影響しません。

1.2. パブリッシュおよびサブスクライブモデル
各メッセージには複数のサブスクライバを含めることができ、
各サブスクライバはトピックのすべてのメッセージを受信できます。

2 つのモデルの違い:メッセージを複数回消費できるかどうか
サブスクライバーが 1 つだけの場合、2 つのモデルは基本的に同じであるため、パブリッシュ/サブスクライブ モデルは機能レベルでキュー モデルと互換性があります。
2. メッセージキューは分散トランザクションを実装します
厳密なトランザクション実装には、アトミック性、一貫性、分離性、耐久性の 4 つの ACID プロパティがあります。
アトミック性:トランザクション操作は分割できません。すべて成功するかすべて失敗します。そのうちの半分は成功し、半分は失敗します。一貫性 :
時点でトランザクションの実行が完了する前に、読み取られるデータは更新前のデータである必要があり、更新後に読み取られるデータは更新後のデータである必要があります。 分離 : トランザクションの実行は、他のトランザクション (内部の操作) によって干渉されませ
ん。トランザクションと使用されるデータ。データは進行中の他のトランザクションから分離されており、同時に実行されるトランザクションは互いに干渉することはできません。) 耐久性
:トランザクションが送信されると、後続の操作や障害はトランザクションの結果に影響を与えません。
分散システムでは、データの一貫性を単独で達成することは非常に困難であるため、通常は最終的な一貫性の達成のみが保証されます。より一般的な分散トランザクションの実装には次のものがあります。
1)、2PC ( Two-phase Commit ) 二相コミット
2)、TCC ( Try-confirm-Cancel )
3)、トランザクションメッセージ
3. メッセージキュー分散トランザクションの実装
KafkaとRocketMQ は両方ともトランザクション関連の関数を提供します。注文を例として実装方法を見てみましょう。
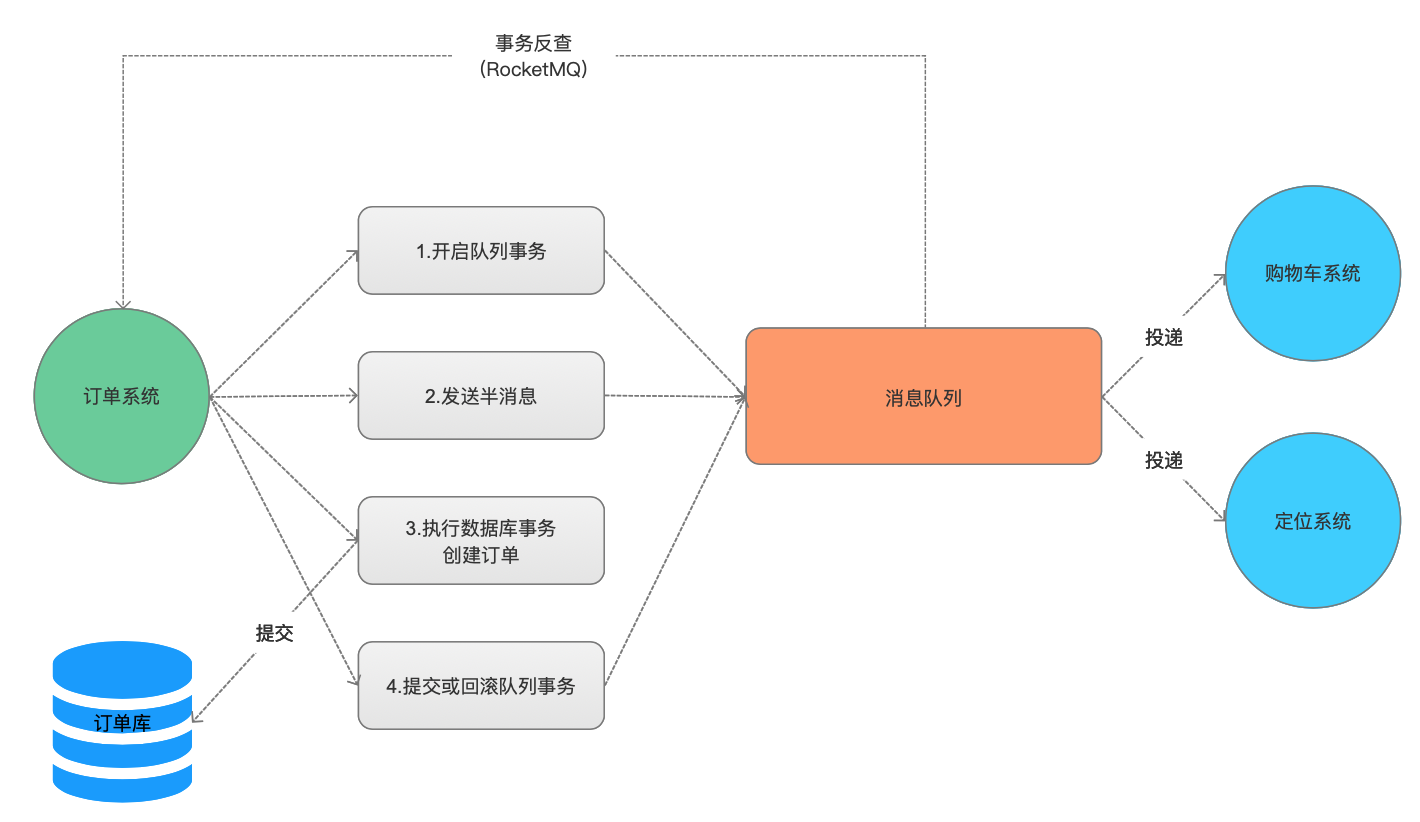
KafkaとRocketMQ はどちらもトランザクション関連の機能を提供します。コア:ハーフ メッセージと
ハーフ メッセージ:このハーフ メッセージは、メッセージの内容が不完全であることを意味するのではなく、トランザクションが送信される前に、メッセージがコンシューマーには見えないことを意味します ( sendMessageInTransaction )
(1) メッセージキューの適用シナリオ(または機能)
アプリケーション シナリオは、非同期処理、アプリケーションの切り離し、トラフィックの切断、メッセージ通信などに分かれています。最も重要なものは、非同期処理、アプリケーションの切り離し、トラフィックの切断です。
1.非同期処理
シナリオ: ユーザー登録後、登録メールと登録情報を送信する必要がありますが、従来の方法にはシリアル方式とパラレル方式の 2 つがあります。
従来のモデルの欠点:一部の重要でないビジネス ロジックが同期的に実行されるため、時間がかかりすぎる
ミドルウェア モデルの利点:メッセージをメッセージ キューに書き込み、重要でないビジネス ロジックが非同期で実行されるため、応答。
1.1. シリアルモード
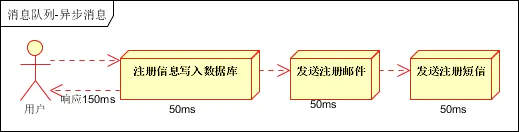
登録情報がデータベースに正常に書き込まれると、登録メールが送信され、続いて登録 SMS が送信され、すべての作業が完了すると、図に示すように情報がクライアントに返されます。
1.2. 並列方式
登録情報がデータベースに正常に書き込まれると、登録メールと登録 SMS が同時に送信されます。すべてのタスクが実行された後、情報がクライアントに返されます。シリアル モードと比較して、パラレル モードは実行効率を向上させ、実行時間を短縮できます。
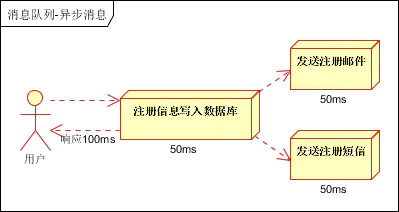
3 つの操作すべてに 50ms の実行時間が必要であるとします。ネットワーク要因を除くと、最後の実行は完了します。単位時間内に CPU によって処理されるリクエストの数が同じであるため、シリアル モードでは 150 ms が必要ですが、パラレル モードでは 100 ms が必要です。: CPU 1 秒ごとのスループットを 100 回とすると、シリアルモードで 1 秒間に実行できるリクエスト数は 1000/150 となり、7 倍未満になります。パラレル モードは 1000/100、つまり 10 倍です。
従来のシリアルおよびパラレル方式ではシステムのパフォーマンスによって制限されることがわかります。この問題をどのように解決すればよいでしょうか?
重要ではないビジネス ロジックを非同期で処理するにはメッセージ キューを導入する必要があり、その結果のプロセスは次のようになります。
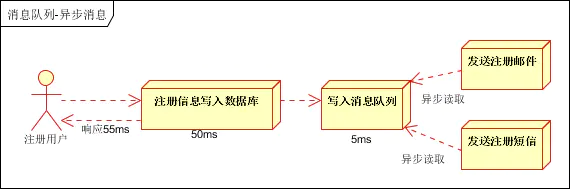
上記の処理により、ユーザーの応答時間は基本的にユーザーデータをデータベースに書き込む時間と同等となり、登録メール送信後、登録SMS送信後、実行結果をメッセージキューに書き込んで返すことができます。メッセージ キューの書き込みにかかる時間は非常に短く、高速なので、ほとんど無視できます。これにより、システム スループットも 20QPS (1 秒あたりのクエリ レート) に向上します。これは、シリアル モードの 3 倍近く、2 倍になります。パラレルモードの2倍です。
QPS: 1 秒あたりのクエリ レート。指定された期間内に特定のクエリ サーバーが処理するトラフィック量の尺度です。
インターネットでは、ドメイン ネーム システム サーバー マシンのパフォーマンスを測定するために 1 秒あたりのクエリ レートがよく使用されます。これは、フェッチ/秒に対応するQPSであり、1 秒あたりの応答要求の数であり、最大スループット容量です。 。
2.アプリケーションのデカップリング
シナリオ: あるシステム A は他のシステム (つまり、メソッドの呼び出し) を処理する必要があります。他のシステムが変更されたり、新しいシステムが追加されたりすると、システム A も変更されます。この場合、結合度は比較的高く、より多くのシステムが変更されます。面倒な。
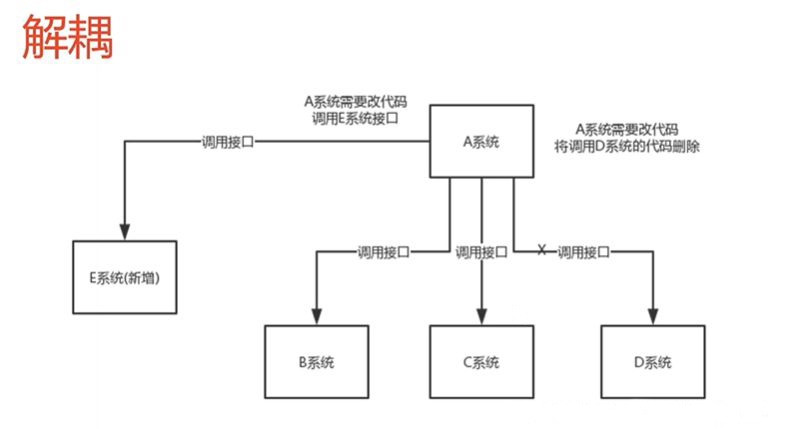
ミドルウェア パターン: メッセージ キューを使用してこの問題を解決する
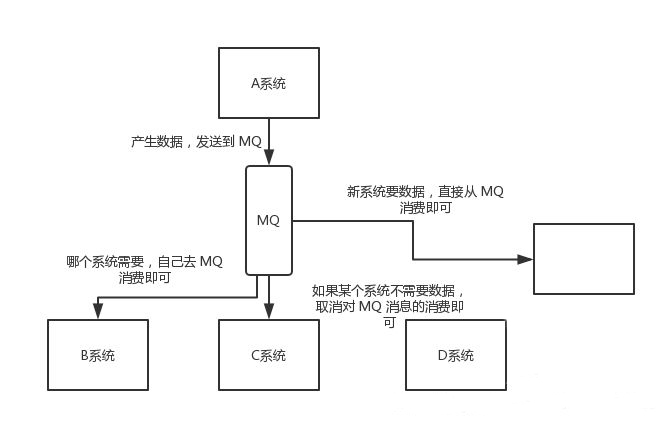
A システムは生成されたデータをメッセージ キューに送信し、他のシステムはメッセージ キューに移動して消費するため、他のシステムの削減または追加は A システムとはほとんど関係なく、デカップリング機能を実現します。
3.トラフィックのシャープ化
たとえば、製品フラッシュセールビジネスのシナリオでは、通常、トラフィックが急激に増加し、過剰なトラフィックによりアプリケーションがクラッシュします。この問題を解決するには、通常、アプリケーション フロントエンドにメッセージ キューを追加する必要があります。
1)、イベントに参加する人の数を制御できます。
2)、短期間で高トラフィックによって引き起こされるアプリケーションへの大きな負荷を軽減できます。
処理方法は図のようになります。
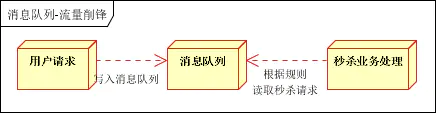
1)ユーザーリクエストを受信した後、サーバーはまずメッセージキューに書き込みます。
このとき、メッセージキュー内のメッセージ数が最大数を超えた場合、ユーザーのリクエストは直接拒否されるか、エラーページが返されます。フラッシュセールルールを作成し、その後の処理を実行します。
4.メッセージ通信
ログ処理とは、Kafka アプリケーションなどのログ処理でメッセージ キューを使用して、大量のログ送信の問題を解決することを指します。
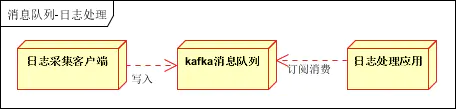
ログ収集クライアント:ログ データの収集、スケジュールされた書き込み、Kafka キューへの書き込みを担当します
Kafka メッセージ キュー:ログ データの受信、保存、転送を担当します ログ
処理アプリケーション: Kafka キュー内のログ データのサブスクライブと使用を担当します
(2) メッセージキューを使用する場合のデメリット
1. システムの可用性が低下する:システムの可用性がある程度低下します。MQ に参加する前は、メッセージの損失や MQ のハングアップなどについて考える必要はありません。しかし、MQ を導入した後は、それについて考慮する必要があります。
2. システムの複雑さの増加: MQ に参加した後は、メッセージが繰り返し消費されないようにすること、メッセージ損失に対処すること、メッセージ配信の順序を確保すること、その他の問題を確認する必要があります。
3. 一貫性の問題:メッセージ キューは非同期を実現でき、メッセージ キューによってもたらされる非同期により、実際にシステムの応答速度が向上します。しかし、メッセージの実際の消費者がメッセージを正しく消費しなかったらどうなるでしょうか? これにより、データの不整合が発生します。
(3) 共通メッセージキュー
| 一般的なメッセージキューの比較 |
|---|
| アクティブMQ | ラビットMQ | ロケットMQ | カフカ | |
| 開発言語 | ジャワ | アーラン | ジャワ | スカラ |
| 単一マシンのスループット | レベル10,000 | レベル10,000 | 10万レベル | 10万レベル |
| 適時性 | ミリ秒レベル | 私たちのレベル | ミリ秒レベル | msレベル以内 |
| 可用性 | 高 (マスター/スレーブ アーキテクチャ) | 高 (マスター/スレーブ アーキテクチャ) | 非常に高い (分散アーキテクチャ) | 非常に高い (分散アーキテクチャ) |
| 特徴 | 多くの企業で使用されている成熟した製品。より多くのドキュメントがあり、さまざまなプロトコルを適切にサポートしています。 | Erlang に基づいて開発されており、強力な同時実行機能、非常に優れたパフォーマンス、低遅延、豊富な管理インターフェイスを備えています。 | MQ は比較的完全な機能と優れた拡張性を備えています | MQ の主要な機能のみがサポートされており、メッセージ クエリやメッセージ トレースバックなどの一部の機能は提供されていませんが、結局のところ、ビッグ データ向けに準備されており、ビッグ データの分野で広く使用されています。 |
上記の比較に基づいて、次の結論が導き出されます。
1)中小企業のソフトウェア会社の場合は、RabbitMQ を
選択することをお勧めします。アーラン言語は本質的に同時実行性が高いという特徴があり、その管理インターフェイスは非常に使いやすいためです。ことわざにあるように、蕭何も成功者であり、蕭何は失敗者です。RabbitMQはオープンソースですが、中国でErlangをカスタマイズして開発できるプログラマーが何人いるでしょうか? 幸いなことに、RabbitMQコミュニティは非常に活発で、開発プロセス中に発生したバグを解決できます。これは中小企業にとって非常に重要です。Kafka が考慮
されていない理由は、中小企業のソフトウェア会社がそれほど優れていないためです。インターネット企業なのでデータ量はそれほど多くない メッセージミドルウェアは比較的機能が充実しているものが望ましいため、Kafka ではrocketmqを除外しているrocketmqを考慮しない理由は、 rocketmqが Alibaba によって作成されているためであるアリババがrocketmqの保守を放棄した場合、小規模中規模企業は通常、rocketmqのカスタマイズ開発を実行するための人員を割くことができないため、推奨しません。
2)大規模なソフトウェア会社は、特定のアプリケーションに基づいてrocketMQとkafka のどちらかを選択する必要があります
。大規模なソフトウェア会社には、分散環境を構築するのに十分な資金と十分な量のデータがあります。rocketMQについては、大手ソフトウェア会社もrocketMQのカスタマイズ開発に人材を投入できますが、結局のところ、 JAVAソース コードを変更する能力を持っている人が中国にはまだかなりの数います。kafkaに関しては、ビジネスシーンにもよりますが、ログ収集機能があれば間違いなくkafkaが第一候補となります。どちらを選択するかは、使用シナリオによって異なります。
(4) メッセージキューの高可用性
rcoketMQクラスターには、図に示すように、マルチマスターモード、マルチマスターおよびマルチスレーブの非同期レプリケーション モード、およびマルチマスターおよびマルチスレーブの同期デュアル書き込みモードがあります。
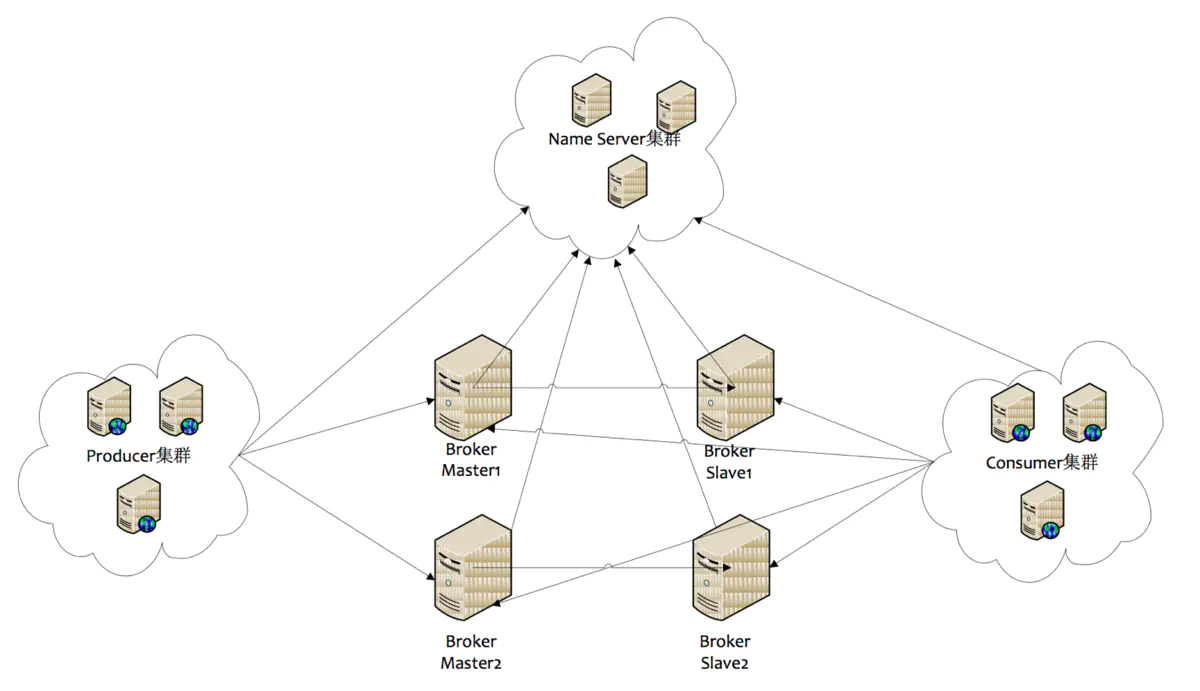
プロデューサーは、NameServerクラスター内の (ランダムに選択された) ノードの 1 つとの長い接続を確立し、定期的にNameServerからトピックのルーティング情報を取得し、トピックサービスを提供するブローカー マスターとの長い接続を確立し、定期的にハートビートをブローカーに送信します。プロデューサーはメッセージをブローカー マスターにのみ送信できますが、コンシューマーは異なります。トピックサービスを同時に提供するマスターおよびスレーブとの長期接続を確立します。ブローカー マスターまたはブローカーからのメッセージをサブスクライブできます。スレーブ。
カフカ
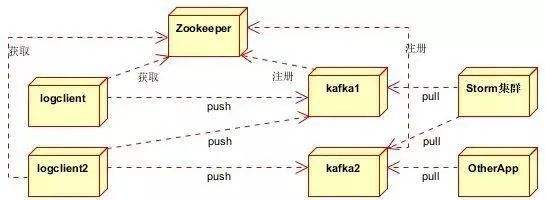
一般的なKafkaクラスターには、複数のプロデューサー( Webフロントエンドによって生成されたページ ビュー、サーバー ログ、システムCPU、メモリなど)、いくつかのブローカー( Kafka は水平拡張をサポートしています。一般に、ブローカーの数が増えるほど) が含まれます。 、クラスターのスループット レートが高くなります。 )、いくつかのConsumer Group、およびZookeeperクラスター。Kafka は、 Zookeeperを使用してクラスター構成の管理、リーダーの選出、コンシューマー グループの変更時の再バランスを行います。プロデューサーはプッシュモードを使用してブローカーにメッセージをパブリッシュし、コンシューマーはプルモードを使用してブローカーからのメッセージをサブスクライブおよび消費します。
RabbitMQ:通常のクラスター モードとミラー クラスター モードもありますが、ここでは詳しく説明しません。
(5) メッセージの繰り返し消費
繰り返し消費される理由:コンシューマがメッセージを消費するとき、消費が完了した後、メッセージ キューに確認メッセージが送信されます。メッセージ キューは、メッセージが消費されたことを認識し、メッセージ キューからメッセージを削除します。 。それは、異なるメッセージ キューが異なる形式の確認情報を送信するというだけです。たとえば、 RabbitMQ はACK確認メッセージを送信し、RocketMQ はCONSUME_SUCCESS成功フラグを返します。Kafkaには実際にはoffsetの概念があります。簡単に言うと、すべてのメッセージにはoffsetがあります。kafka はメッセージを消費した後、オフセットを送信して、メッセージが消費されたことをメッセージ キューに知らせる必要があります。繰り返し消費される理由は何ですか? ネットワーク送信やその他の障害により、確認情報がメッセージ キューに送信されず、メッセージ キューがメッセージを消費したことを認識できず、メッセージが他のコンシューマに再度配信されるためです。 。
解決策:
1. たとえば、次のメッセージが表示され、データベースに対して挿入操作を実行するとします。それは簡単です。このメッセージに一意の主キーを与えます。そうすれば、たとえ繰り返し消費があったとしても、主キーの競合が発生し、データベース内のダーティ データが回避されます。2. 例: このメッセージを受け取って、redis を実行し
た場合set 操作を実行すると、何度設定しても結果が同じになるため、簡単で解決する必要がありません。set 操作は冪等操作とみなされます。 3. サードパーティのメディアを準備し
ます。消費記録。redis を例に挙げると、メッセージにグローバル ID を割り当てます。メッセージが消費される限り、<id, message> が KV 形式で redis に書き込まれます。消費者は消費を開始する前に、まず Redis に消費記録があるかどうかを確認できます。
(6) 消費の性的感染
各タイプの MQは、プロデューサでのデータの損失、メッセージ キューでのデータの損失、およびコンシューマでのデータの損失という3 つの観点から分析する必要があります。
ラビットMQ
1. プロデューサーがデータを失う
プロデューサーがデータを失うという観点から見ると、RabbitMQ は、プロデューサーがメッセージを失わないようにするためのトランザクションモードと確認モードを提供します。
トランザクションメカニズムとは、メッセージを送信する前にトランザクションを開き ( channel.txSelect() )、その後メッセージを送信することを意味します。送信処理の場合 トランザクションで例外が発生した場合、トランザクションはロールバックされます( channel.txRollback() )、送信が成功した場合はトランザクションが送信されます( channel.txCommit() )
。デメリットはスループットが低下することです。したがって、確認モードは主に運用環境で使用されます。チャネルが確認モードに入ると、チャネル上で公開されたすべてのメッセージに一意のID (1 から始まる)が割り当てられます。メッセージが一致するすべてのキューに配信されると、rabbitMQ はプロデューサーにAckを送信します(これにより、プロデューサーは、メッセージが宛先キューに正しく到着したことを知ることができます。rabiitMQ がメッセージの処理に失敗した場合は、 Nackメッセージが送信され、操作を再試行できます。
2. メッセージキューのデータが失われる
メッセージ キューでデータが失われる状況に対処するには、通常、永続ディスクの構成を有効にします。この永続性構成は、確認メカニズムと組み合わせて使用でき、メッセージがディスクに永続化された後、プロデューサーに Ack シグナルを送信できます。このようにして、メッセージがディスクに永続化される前にRabbitMQが終了した場合、プロデューサーはAckシグナルを受信できず、自動的に再送信されます
。それでは、メッセージを永続化するにはどうすればよいでしょうか?それは実際には非常に簡単です。次の 2 つの手順に従うだけです。 :
1.キューの永続化 フラグ耐久性は **true に設定され、** は耐久性キューを表します
2.メッセージ送信時にdeliveryMode =2を設定します このようにdeliveryMode =2を
設定すると、 rabbitMQがハングしてもデータは再起動すれば元に戻せます。
3. 消費者がデータを失う
一般に、消費者は自動確認メッセージ モードを使用するため、データを失います。このモードでは、コンシューマーはメッセージの受信を自動的に確認します。このとき、rahbitMQ はメッセージを即座に削除しますが、この場合、コンシューマーが例外に遭遇してメッセージの処理に失敗すると、メッセージは失われます。解決方法としては、手動でメッセージを確認するだけです
。
2.RabbitMQのインストール
1. Erlang をインストールする
Erlang の公式ダウンロード:ダウンロード - Erlang/OTP
[root@servers ~]# yum -y install make gcc gcc-c++ kernel-devel m4 ncurses-devel openssl-devel
[root@servers ~]# tar xvf otp_src_24.2-rc1.tar.gz
[root@servers ~]# cd otp_src_24.2
[root@servers otp_src_24.2]# ./configure --prefix=/usr/local/erlang --with-ssl -enable-threads -enable-smmp-support -enable-kernel-poll --enable-hipe --without-javac
[root@servers otp_src_24.2]# make && make install
[root@servers otp_src_24.2]# vim /etc/profile
................ 在最后加入
........
ERLANG_HOME=/usr/local/erlang
PATH=$ERLANG_HOME/bin:$PATH
export ERLANG_HOME
export PATH
保存
root@servers ~]# source /etc/profile
[root@servers ~]# erl #验证是否安装成功
Erlang/OTP 24 [erts-12.0] [source] [64-bit] [smp:1:1] [ds:1:1:10] [async-threads:1]
Eshell V12.0 (abort with ^G)
1>
ctrl + C 退出 如果一次没有退出就多按几次
2. RadditMQ をインストールする
RabbitMQ をダウンロード: https://github.com/rabbitmq/rabbitmq-server/releases/tag/v3.9.12
[root@servers ~]# xz -d rabbitmq-server-generic-unix-3.9.12.tar.xz
[root@servers ~]# tar xf rabbitmq-server-generic-unix-3.9.12.tar
[root@servers ~]# cp -rf rabbitmq_server-3.9.12 /usr/local/
[root@servers ~]# cd /usr/local/
[root@servers local]# mv rabbitmq_server-3.9.12 rabbitmq
[root@servers local]# cd rabbitmq/sbin/
[root@servers sbin]# ./rabbitmq-plugins enable rabbitmq_management #开启管理页面插件
Enabling plugins on node rabbit@C7--13:
rabbitmq_management
The following plugins have been configured:
rabbitmq_management
rabbitmq_management_agent
rabbitmq_web_dispatch
Applying plugin configuration to rabbit@C7--13...
The following plugins have been enabled:
rabbitmq_management
rabbitmq_management_agent
rabbitmq_web_dispatch
set 3 plugins.
Offline change; changes will take effect at broker restart.
サービスの開始とシャットダウン
[root@servers sbin]# ./rabbitmq-server #启动,ctrl + c 退出及关闭
[root@servers sbin]# ./rabbitmq-server -detached #在后台启动服务
[root@servers sbin]# ./rabbitmqctl stop #关闭服务
管理者アカウントを追加する
バックグラウンドで起動した後にユーザーを追加する
添加用户格式: ./rabbitmqctl add_user 用户名 密码
[root@servers sbin]# ./rabbitmqctl add_user admin 123.com
Adding user "admin" ...
Done. Don't forget to grant the user permissions to some virtual hosts! See 'rabbitmqctl help set_permissions' to learn more.
分配用户标签格式: ./rabbitmqctl add_user_tags 用户名 管理员标签[administrator]
[root@servers sbin]# ./rabbitmqctl set_user_tags admin administrator
Setting tags for user "admin" to [administrator] ...
アクセステスト
前に設定したユーザー: admin とパスワード: 123.com を入力してログインします。
3. RabbitMQの詳しい説明
(1) AMQP の概要
RabbitMQは、アドバンスト メッセージキュー プロトコル ( AMQP プロトコル) を実装するオープン ソースのメッセージ ブローカー ソフトウェア (メッセージ指向ミドルウェアとも呼ばれます)です。RabbitMQサーバーはErlang言語で記述されており、クラスタリングとフェイルオーバーは Open Telecommunications Platform フレームワーク上に構築されています。すべての主要なプログラミング言語には、プロキシ インターフェイスと通信するクライアント ライブラリがあります。
AMQPプロトコル: Advanced Message Queuing Protocol は、アプリケーション層プロトコルのオープン標準であり、メッセージ指向ミドルウェア向けに設計されています。メッセージ ミドルウェアは、主にコンポーネント間の分離に使用されます。メッセージの送信者はメッセージ コンシューマの存在を知る必要はなく、その逆も同様です。プロトコルの主な機能は、メッセージ指向、キュー、ルーティング (ポイントツーを含む) です
AMQP。 Secure
RabbitMQ は、オープン ソースのAMQP実装です。サーバーはErlang言語で書かれており、 Python、 Ruby、 .NET、 Java、 JMS、 Cなどのさまざまなクライアントをサポートしています。、 PHP、 ActionScript、 XMPP、 STOMPなどに対応しており、 AJAXをサポートしています。分散システムでメッセージを保存および転送するために使用され、使いやすさ、拡張性、高可用性の点で優れたパフォーマンスを発揮します。
| AMQP 3 層プロトコル | |
|---|---|
| モジュール層 | プロトコルの最上位に位置し、主にクライアントが呼び出すためのいくつかのコマンドを定義します。クライアントはこれらのコマンドを使用して独自のビジネス ロジックを実装できます。たとえば、クライアントは queue.declare を通じてキューを宣言し、consume を使用できます。キュー内のメッセージを取得するコマンド。 |
| セッション層 | 主に、クライアントのコマンドをサーバーに送信し、サーバーの応答をクライアントに返すことを担当し、クライアントとサーバー間の通信の信頼性、同期メカニズム、およびエラー処理を提供します。 |
| トランスポート層 | 主にバイナリ データ ストリームを送信し、フレーム処理、チャネル多重化、エラー検出、およびデータ表現を提供します。 |
(2) 機能
| 保存して転送する | 複数のメッセージ送信者、単一のメッセージ受信者 |
|---|---|
| 分散トランザクション | 複数のメッセージ送信者、複数のメッセージ受信者 |
| 公開購読する | 複数のメッセージ送信者、複数のメッセージ受信者 |
| コンテンツベースのルーティング | 複数のメッセージ送信者、複数のメッセージ受信者 |
| ファイル転送キュー | 複数のメッセージ送信者、複数のメッセージ受信者 |
| ポイントツーポイント接続 | 単一のメッセージ送信者、単一のメッセージ受信者 |
(3) 用語の説明
AMQP モデル ( AMQP Model) |
AMQP準拠のサーバーが提供する必要がある主要なエンティティとセマンティクスによって表される論理フレームワーク。この仕様で定義されているセマンティクスを実装するために、クライアントはAMQPサーバーを制御するコマンドを送信できます。 |
|---|---|
接続( Connection) |
TCP/IPソケット接続などのネットワーク接続 |
セッション( Session) |
エンドポイント間の名前付き会話。セッションコンテキスト内では、「1 回だけ」配信されることが保証されます |
チャンネル( Channel) |
多重接続内の独立した双方向データ フロー チャネル。セッションに物理的な伝送媒体を提供する |
クライアント( Client) |
AMQP接続またはセッションのイニシエーター。AMQPは非対称であり、クライアントはメッセージを生成および消費し、サーバーはこれらのメッセージを保存およびルーティングします。 |
サーバー( Server) |
クライアント接続を受け入れ、AMQPメッセージ キューとルーティング機能を実装するプロセス。「メッセージブローカー」とも呼ばれます |
エンドポイント( Peer) |
AMQP会話のいずれかの当事者。AMQP接続は 2 つのエンドポイントで構成されます (1 つはクライアント、もう 1 つはサーバー) |
パートナー ( Partner) |
2 つのエンドポイント間の対話を説明する場合、「パートナー」という用語は「他の」エンドポイントの省略形として使用されます。たとえば、エンドポイント A とエンドポイント B を定義します。これらが通信する場合、エンドポイント B はエンドポイント A のパートナーとなり、エンドポイント A はエンドポイント B のパートナーになります。 |
フラグメント セット ( Assembly) |
論理的な作業単位を形成する、順序付けられたセグメントの集合 |
セグメント( Segment) |
フラグメント セットの完全なサブユニットを形成する、順序付けられたフレームのコレクション |
フレーム( Frame) |
AMQPトランスポートのアトミック単位。フレームはセグメント内の任意のフラグメントです |
コントロール( Control) |
一方向命令。AMQP仕様では、これらの命令の送信は信頼できないと想定しています。 |
コマンド( Command) |
確認が必要な命令AMQP仕様では、これらの命令の送信が信頼できるものであると規定されています。 |
例外( Exception) |
1つ以上のコマンドを実行するときに発生する可能性のあるエラーステータス |
クラス ( Class) |
特定の機能を記述するために使用されるAMQPコマンドまたはコントロールのバッチ |
メッセージヘッダー ( Header) |
メッセージデータの属性を説明する特別なセクション |
メッセージ本文 ( Body) |
包含应用程序数据的一种特殊段。消息体段对于服务器来说完全透明——服务器不能查看或者修改消息体 |
消息内容(Content) |
包含在消息体段中的的消息数据 |
交换器(Exchange) |
服务器中的实体,用来接收生产者发送的消息并将这些消息路由给服务器中的队列 |
交换器类型(Exchange Type) |
基于不同路由语义的交换器类 |
消息队列(Message Queue) |
一个命名实体,用来保存消息直到发送给消费者 |
绑定器(Binding) |
消息队列和交换器之间的关联 |
绑定器关键字(Binding Key) |
绑定的名称。一些交换器类型可能使用这个名称作为定义绑定器路由行为的模式 |
路由关键字(Routing Key) |
一个消息头,交换器可以用这个消息头决定如何路由某条消息 |
持久存储(Durable) |
一种服务器资源,当服务器重启时,保存的消息数据不会丢失 |
临时存储(Transient) |
一种服务器资源,当服务器重启时,保存的消息数据会丢失 |
持久化(Persistent) |
服务器将消息保存在可靠磁盘存储中,当服务器重启时,消息不会丢失 |
非持久化(Non-Persistent) |
服务器将消息保存在内存中,当服务器重启时,消息可能丢失 |
消费者(Consumer) |
一个从消息队列中请求消息的客户端应用程序 |
生产者(Producer) |
一个向交换器发布消息的客户端应用程序 |
虚拟主机(Virtual Host) |
一批交换器、消息队列和相关对象。虚拟主机是共享相同的身份认证和加密环境的独立服务器域。客户端应用程序在登录到服务器之后,可以选择一个虚拟主机 |
(四)、RabbitMQ的工作流程
消息队列有三个概念: 发消息者、消息队列、收消息者。RabbitMQ 在这个基本概念之上, 多做了一层抽象, 在发消息者和队列之间, 加入了交换器 (Exchange)。这样发消息者和消息队列就没有直接联系,转而变成发消息者把消息发给交换器,交换器根据调度策略再把消息转发给消息队列
消息生产者并没有直接将消息发送给消息队列,而是通过建立与Exchange的Channel,将消息发送给Exchange。Exchange根据路由规则,将消息转发给指定的消息队列。消息队列储存消息,等待消费者取出消息。消费者通过建立与消息队列相连的Channel,从消息队列中获取消息
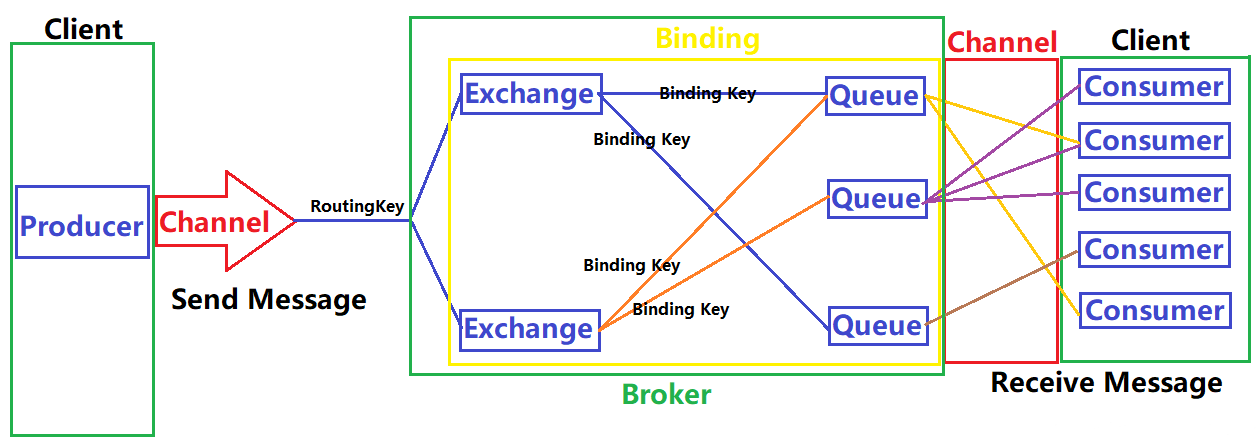
| Producer(消息的生产者) | 向消息队列发布消息的客户端应用程序 |
|---|---|
| Channel(信道) | 多路复用连接中的一条独立的双向数据流通道。信道是建立在真实的TCP连接内的虚拟连接,复用TCP连接的通道 |
| Routing Key(路由键) | 消息头的一个属性,用于标记消息的路由规则,决定了交换机的转发路径。最大长度255 字节 |
| Broker | RabbitMQ Server,服务器实体 |
| Binding(绑定) | 用于建立Exchange和Queue之间的关联。一个绑定就是基于Binding Key将Exchange和Queue连接起来的路由规则,所以可以将交换器理解成一个由Binding构成的路由表 |
| Exchange(交换器|路由器) | 提供Producer到Queue之间的匹配,接收生产者发送的消息并将这些消息按照路由规则转发到消息队列。交换器用于转发消息,它不会存储消息 ,如果没有 Queue绑定到 Exchange 的话,它会直接丢弃掉 Producer 发送过来的消息。交换器有四种消息调度策略,分别是fanout, direct, topic, headers |
| Binding Key(绑定键) | Exchange与Queue的绑定关系,用于匹配Routing Key。最大长度255 字节 |
| Queue(消息队列) | 存储消息的一种数据结构,用来保存消息,直到消息发送给消费者。它是消息的容器,也是消息的终点。一个消息可投入一个或多个队列。消息一直在队列里面,等待消费者连接到这个队列将消息取走。需要注意,当多个消费者订阅同一个Queue,这时Queue中的消息会被平均分摊给多个消费者进行处理,而不是每个消费者都收到所有的消息并处理,每一条消息只能被一个订阅者接收 |
| Consumer(消息的消费者) | 从消息队列取得消息的客户端应用程序 |
| Message(消息) | 消息由消息头和消息体组成。消息体是不透明的,而消息头则由一系列的可选属性组成,这些属性包括routing-key(路由键)、priority(消息优先权)、delivery-mode(是否持久性存储)等 |
(五)、Exchange消息调度策略
交换器的功能主要是接收消息并且转发到绑定的队列,交换器不存储消息,在启用ack模式后,交换器找不到队列会返回错误
调度策略是指Exchange在收到生产者发送的消息后依据什么规则把消息转发到一个或多个队列中保存。调度策略与三个因素相关:Exchange Type(Exchange的类型),Binding Key(Exchange和Queue的绑定关系),消息的标记信息(Routing Key和headers)
Exchange根据消息的Routing Key和Exchange绑定Queue的Binding Key分配消息。生产者在将消息发送给Exchange的时候,一般会指定一个Routing Key,来指定这个消息的路由规则,而这个Routing Key需要与Exchange Type及Binding Key联合使用才能最终生效
在Exchange Type与Binding Key固定的情况下(一般这些内容都是固定配置好的),我们的生产者就可以在发送消息给Exchange时,通过指定Routing Key来决定消息流向哪里
交换器的四种消息调度策略:fanout, direct, topic, headers
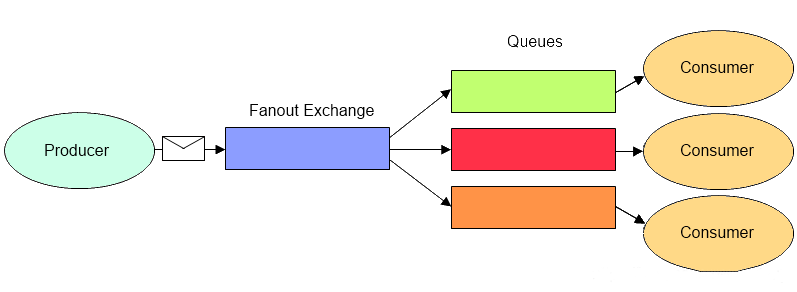
1、Fanout (订阅模式**/**广播模式)
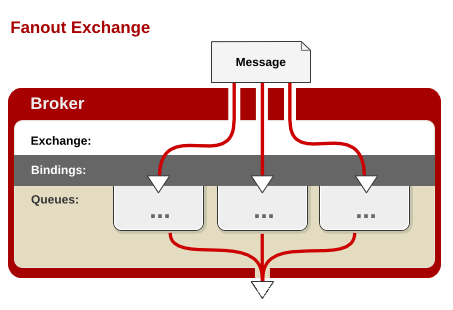
交换器会把所有发送到该交换器的消息路由到所有与该交换器绑定的消息队列中。订阅模式
与Binding Key和Routing Key无关,交换器将接受到的消息分发给有绑定关系的所有消息队列队列(不论Binding Key和Routing Key是什么)。类似于子网广播,子网内的每台主机都获得了一份复制的消息。Fanout交换机转发消息是最快的
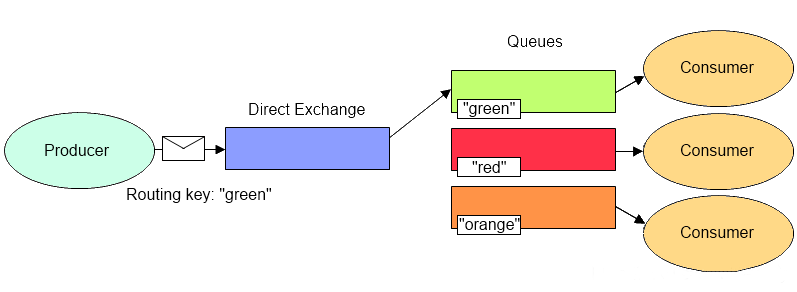
2、Direct(路由模式)
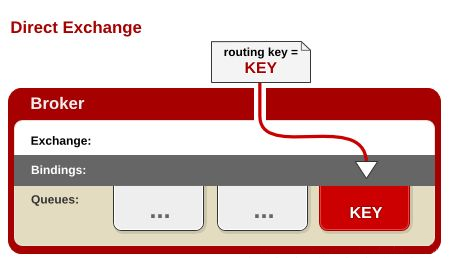
精确匹配:当消息的Routing Key与 Exchange和Queue 之间的Binding Key完全匹配,如果匹配成功,将消息分发到该Queue。只有当Routing Key和Binding Key完全匹配的时候,消息队列才可以获取消息。Direct是Exchange的默认模式
RabbitMQ默认提供了一个Exchange,名字是空字符串,类型是Direct,绑定到所有的Queue(每一个Queue和这个无名Exchange之间的Binding Key是Queue的名字)。所以,有时候我们感觉不需要交换器也可以发送和接收消息,但是实际上是使用了RabbitMQ默认提供的Exchange
3、Topic (通配符模式)
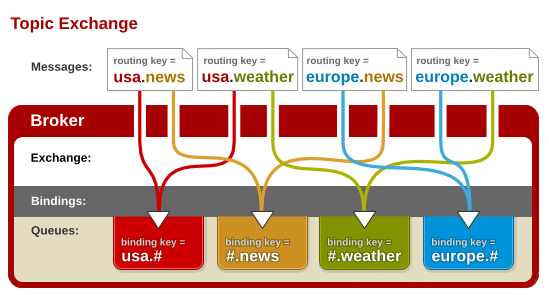
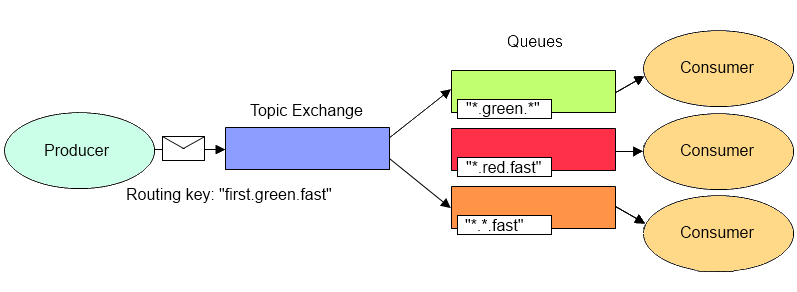
按照正则表达式模糊匹配:用消息的Routing Key与 Exchange和Queue 之间的Binding Key进行模糊匹配,如果匹配成功,将消息分发到该Queue
Routing Key是一个句点号“. ”分隔的字符串(我们将被句点号“. ”分隔开的每一段独立的字符串称为一个单词)。Binding Key与Routing Key一样也是句点号“. ”分隔的字符串。Binding Key中可以存在两种特殊字符“ * ”与“#”,用于做模糊匹配,其中“*”用于匹配一个单词,“#”用于匹配多个单词(可以是零个)
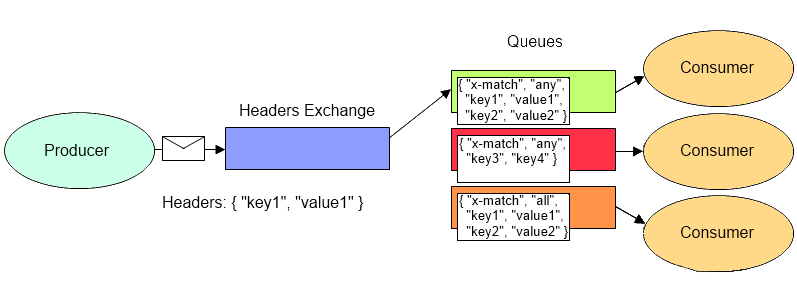
4、Headers(键值对模式)
Headers不依赖于Routing Key与Binding Key的匹配规则来转发消息,交换器的路由规则是通过消息头的Headers属性来进行匹配转发的,类似HTTP请求的Headers
在绑定Queue与Exchange时指定一组键值对,键值对的Hash结构中要求携带一个键“x-match”,这个键的Value可以是any或all,代表消息携带的Hash是需要全部匹配(all),还是仅匹配一个键(any)
当消息发送到Exchange时,交换器会取到该消息的headers,对比其中的键值对是否完全匹配Queue与Exchange绑定时指定的键值对;如果完全匹配则消息会路由到该Queue,否则不会路由到该Queue。Headers交换机的优势是匹配的规则不被限定为字符串(String),而是Object类型
(六)、RPC(Remote Procedure Call,远程过程调用)
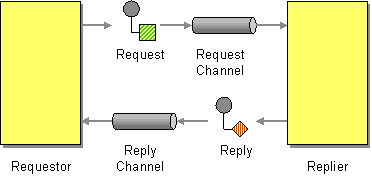
MQ本身是基于异步的消息处理,前面的示例中所有的生产者(P)将消息发送到RabbitMQ后不会知道消费者(C)处理成功或者失败(甚至连有没有消费者来处理这条消息都不知道)
但实际的应用场景中,我们很可能需要一些同步处理,需要同步等待服务端将我的消息处理完成后再进行下一步处理。这相当于RPC(Remote Procedure Call,远程过程调用)。在RabbitMQ中也支持RPC
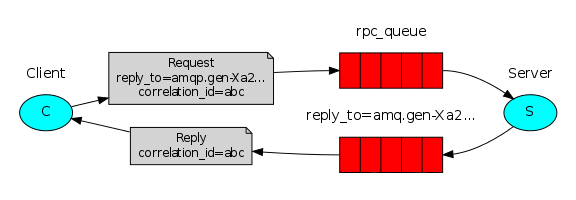
RabbitMQ中实现RPC的机制是:
1、客户端发送请求(消息)时,在消息的属性(MessageProperties,在AMQP协议中定义了14个属性,这些属性会随着消息一起发送)中设置两个值replyTo(一个Queue名称,用于告诉服务器处理完成后将通知我的消息发送到这个Queue中)和correlationId(此次请求的标识号,服务器处理完成后需要将此属性返还,客户端将根据这个id了解哪条请求被成功执行了或执行失败)
2、服务器端收到消息并处理
3、服务器端处理完消息后,将生成一条应答消息到replyTo指定的Queue,同时带上correlationId属性
4、客户端之前已订阅replyTo指定的Queue,从中收到服务器的应答消息后,根据其中的correlationId属性分析哪条请求被执行了,根据执行结果进行后续业务处理
(七)、消息确认:Message acknowledgment
在实际应用中,可能会发生消费者收到Queue中的消息,但没有处理完成就宕机(或出现其他意外)的情况,这种情况下就可能会导致消息丢失。为了避免这种情况发生,我们可以要求消费者在消费完消息后发送一个回执给RabbitMQ,RabbitMQ收到消息回执(Message acknowledgment)后才将该消息从Queue中移除;如果RabbitMQ没有收到回执并检测到消费者的RabbitMQ连接断开,则RabbitMQ会将该消息发送给其他消费者(如果存在多个消费者)进行处理。这里不存在Timeout概念,一个消费者处理消息时间再长也不会导致该消息被发送给其他消费者,除非它的RabbitMQ连接断开
这里会产生另外一个问题,如果我们的开发人员在处理完业务逻辑后,忘记发送回执给RabbitMQ,这将会导致严重的问题,Queue中堆积的消息会越来越多,消费者重启后会重复消费这些消息并重复执行业务逻辑
如果我们采用no-ack的方式进行确认,也就是说,每次Consumer接到数据后,而不管是否处理完成,RabbitMQ会立即把这个Message标记为完成,然后从queue中删除了
(八)、消息持久化:Message durability
如果我们希望即使在RabbitMQ服务重启的情况下,也不会丢失消息,我们可以将Queue与Message都设置为可持久化的(durable),这样可以保证绝大部分情况下我们的RabbitMQ消息不会丢失。但依然解决不了小概率丢失事件的发生(比如RabbitMQ服务器已经接收到生产者的消息,但还没来得及持久化该消息时RabbitMQ服务器就断电了),如果我们需要对这种小概率事件也要管理起来,那么我们要用到事务
(九)、分发机制
我们在应用程序使用消息系统时,一般情况下生产者往队列里插入数据时速度是比较快的,但是消费者消费数据往往涉及到一些业务逻辑处理导致速度跟不上生产者生产数据。因此如果一个生产者对应一个消费者的话,很容易导致很多消息堆积在队列里。这时,就得使用工作队列了。一个队列有多个消费者同时消费数据
工作队列有两种分发数据的方式: 轮询分发(Round-robin)和 公平分发(Fair dispatch)
轮询分发:队列给每一个消费者发送数量一样的数据
公平分发: 消费者设置每次从队列中取一条数据,并且消费完后手动应答,继续从队列取下一个数据
1、轮询分发:Round-robin dispatching
如果工作队列中有两个消费者,两个消费者得到的数据量一样的,并不会因为两个消费者处理数据速度不一样使得两个消费者取得不一样数量的数据。但是这种分发方式存在着一些隐患,消费者虽然得到了消息,但是如果消费者没能成功处理业务逻辑,在RabbitMQ中也不存在这条消息。就会出现消息丢失并且业务逻辑没能成功处理的情况
2、公平分发:Fair dispatch
消费者设置每次从队列里取一条数据,并且关闭自动回复机制,每次取完一条数据后,手动回复并继续取下一条数据。与轮询分发不同的是,当每个消费都设置了每次只会从队列取一条数据时,并且关闭自动应答,在每次处理完数据后手动给队列发送确认收到数据。这样队列就会公平给每个消息费者发送数据,消费一条再发第二条,而且可以在管理界面中看到数据是一条条随着消费者消费完从而减少的,并不是一下子全部分发完了。采用公平分发方式就不会出现消息丢失并且业务逻辑没能成功处理的情况
(十)、事务
对事务的支持是AMQP协议的一个重要特性。假设当生产者将一个持久化消息发送给服务器时,因为consume 命令本身没有任何Response返回,所以即使服务器崩溃,没有持久化该消息,生产者也无法获知该消息已经丢失。如果此时使用事务,即通过txSelect()开启一个事务,然后发送消息给服务器,然后通过txCommit() 提交该事务,即可以保证,如果txCommit()提交了,则该消息一定会持久化,如果txCommit() 还未提交即服务器崩溃,则该消息不会服务器接收。当然Rabbit MQ 也提供了txRollback() 命令用于回滚某一个事务
(十一)、Confirm机制
使用事务固然可以保证只有提交的事务,才会被服务器执行。但是这样同时也将客户端与消息服务器同步起来,这背离了消息队列解耦的本质。Rabbit MQ提供了一个更加轻量级的机制来保证生产者可以感知服务器消息是否已被路由到正确的队列中——Confirm。如果设置channel为confirm状态,则通过该channel发送的消息都会被分配一个唯一的ID,然后一旦该消息被正确的路由到匹配的队列中后,服务器会返回给生产者一个Confirm,该Confirm包含该消息的ID,这样生产者就会知道该消息已被正确分发。对于持久化消息,只有该消息被持久化后,才会返回Confirm。Confirm机制的最大优点在于异步,生产者在发送消息以后,即可继续执行其他任务。而服务器返回Confirm后,会触发生产者的回调函数,生产者在回调函数中处理Confirm信息。如果消息服务器发生异常,导致该消息丢失,会返回给生产者一个nack,表示消息已经丢失,这样生产者就可以通过重发消息,保证消息不丢失。Confirm机制在性能上要比事务优越很多。但是Confirm机制,无法进行回滚,就是一旦服务器崩溃,生产者无法得到Confirm信息,生产者其实本身也不知道该消息是否已经被持久化,只有继续重发来保证消息不丢失,但是如果原先已经持久化的消息,并不会被回滚,这样队列中就会存在两条相同的消息,系统需要支持去重
(十二)、Alternate Exchange(代替交换器)
Alternate Exchange是Rabbitmq自己扩展的功能,不是AMQP协议定义的
创建Exchange指定该Exchange的Alternate Exchange,发送消息的时候如果Exchange没有成功把消息路由到队列中去,这就会将此消息路由到Alternate Exchange属性指定的Exchange上了。需要在创建Exchange时添加alternate-exchange属性。如果Alternate Exchange也没能成功把消息路由到队列中去,这个消息就会丢失。可以触发publish confirm机制,表示这个消息没有确认
创建交换器时需要指定如下属性
Map<String,Object> argsMap = new HashMap<>();
argsMap.put(“alternate-exchange”,“Alternate Exchange Name”);
(十三)、TTL(生存时间)
RabbitMQ允许您为消息和队列设置TTL(生存时间)。 可以使用可选的队列参数或策略完成(推荐使用后一个选项)。 可以为单个队列,一组队列或单个消息应用消息TTL
设置消息的过期时间
MessageProperties messageProperties = new MessageProperties();
messageProperties.setExpiration(“30000”);
设置队列中消息的过期时间
在声明一个队列时,可以指定队列中消息的过期时间,需要添加x-message-ttl属性
Map<String, Object> arguments = new HashMap<>();
arguments.put(“x-message-ttl”,30000);
如果同时制定了Message TTL,Queue TTL,则时间短的生效
(十四)、Queue Length Limit(队列长度限制)
可以设置队列中消息数量的限制,如果测试队列中最多只有5个消息,当第六条消息发送过来的时候,会删除最早的那条消息。队列中永远只有5条消息
使用代码声明含有x-max-length和x-max-length-bytes属性的队列
Max length(x-max-length) 用来控制队列中消息的数量
如果超出数量,则先到达的消息将会被删除掉
Max length bytes(x-max-length-bytes) 用来控制队列中消息总的大小
如果超过总大小,则最先到达的消息将会被删除,直到总大小不超过x-max-length-byte为止
Map<String, Object> arguments = new HashMap<>();
arguments.put(“x-max-length”,3); #表示队列中最多存放三条消息
Map<String, Object> arguments = new HashMap<>();
arguments.put(“x-max-length-bytes”,10); #队列中消息总的空间大小
(十五)、Dead Letter Exchange(死信交换器)
在队列上指定一个Exchange,则在该队列上发生如下情况
1、 消息被拒绝(basic.reject or basic.nack),且requeue=false
2、 消息过期而被删除(TTL)
3、 消息数量超过队列最大限制而被删除
4、 消息总大小超过队列最大限制而被删除
就会把该消息转发到指定的这个exchange
需要定义了x-dead-letter-exchange属性,同时也可以指定一个可选的x-dead-letter-routing-key,表示默认的routing-key,如果没有指定,则使用消息原来的routeing-key进行转发
当定义队列时指定了x-dead-letter-exchange(x-dead-letter-routing-key视情况而定),并且消费端执行拒绝策略的时候将消息路由到指定的Exchange中去
我们知道还有二种情况会造成消息转发到死信队列
一种是消息过期而被删除,可以使用这个方式使的rabbitmq实现延迟队列的作用。还有一种就是消息数量超过队列最大限制而被删除或者消息总大小超过队列最大限制而被删除
(十六)、priority queue(优先级队列)
声明队列时需要指定x-max-priority属性,并设置一个优先级数值
消息优先级属性
MessageProperties messageProperties = new MessageProperties();
messageProperties.setPriority(priority);
如果设置的优先级小于等于队列设置的x-max-priority属性,优先级有效
如果设置的优先级大于队列设置的x-max-priority属性,则优先级失效
创建优先级队列,需要增加x-max-priority参数,指定一个数字。表示最大的优先级,建议优先级设置为1~10之间
发送消息的时候,需要设置priority属性,最好不要超过上面指定的最大的优先级
如果生产端发送很慢,消费者消息很快,则有可能不会严格的按照优先级来进行消费
1、发送的消息的优先级属性小于设置的队列属性x-max-priority值,则按优先级的高低进行消费,数字越高则优先级越高
2、送的消息的优先级属性都大于设置的队列属性x-max-priority值,则设置的优先级失效,按照入队列的顺序进行消费
3、 费端一直进行监听,而发送端一条条的发送消息,优先级属性也会失效
RabbitMQ不能保证消息的严格的顺序消费
(十七)、延迟队列
延迟队列就是进入该队列的消息会被延迟消费的队列。而一般的队列,消息一旦入队了之后就会被消费者马上消费
延迟队列多用于需要延迟工作的场景
最常见的是以下两种场景:
1、 消费
如:用户生成订单之后,需要过一段时间校验订单的支付状态,如果订单仍未支付则需要及时地关闭订单
用户注册成功之后,需要过一段时间比如一周后校验用户的使用情况,如果发现用户活跃度较低,则发送邮件或者短信来提醒用户使用
2、延迟重试
如:消费者从队列里消费消息时失败了,但是想要延迟一段时间后自动重试
我们可以利用RabbitMQ的两个特性,一个是Time-To-Live Extensions,另一个是Dead Letter Exchanges。实现延迟队列
Time-To-Live Extensions
RabbitMQ允许我们为消息或者队列设置TTL(time to live),也就是过期时间。TTL表明了一条消息可在队列中存活的最大时间,单位为毫秒。也就是说,当某条消息被设置了TTL或者当某条消息进入了设置了TTL的队列时,这条消息会在经过TTL秒后“死亡”,成为Dead Letter。如果既配置了消息的TTL,又配置了队列的TTL,那么较小的那个值会被取用
Dead Letter Exchange
刚才提到了,被设置了TTL的消息在过期后会成为Dead Letter。其实在RabbitMQ中,一共有三种消息的“死亡”形式:
1、消息被拒绝。通过调用basic.reject或者basic.nack并且设置的requeue参数为false
2、消息因为设置了TTL而过期
3、消息进入了一条已经达到最大长度的队列
如果队列设置了Dead Letter Exchange(DLX),那么这些Dead Letter就会被重新publish到Dead Letter Exchange,通过Dead Letter Exchange路由到其他队列
四、RabbitMQ配置
(一)、RabbitMQ 常用命令
1、Vhost虚拟机
每个RabbitMQ服务器都能创建虚拟主机(virtual host),简称vhost。每个vhost本质上是一个独立的小型RabbitMQ服务器,拥有自己独立的队列、交换器及绑定关系等,并且它拥有自己独立的权限,RabbitMQ默认创建vhost为 / ”
创建vhost
rabbitmqctl add_vhost {
vhost}
查看所有vhost
rabbitmqctl list_vhosts
删除指定vhost
rabbitmqctl delete_vhost {
vhost}
2、用户管理
在RabbitMQ中,用户是访问控制的基本单元,且单个用户可以跨越多个vhost进行授权
创建用户
rabbitmqctl add_user {
username} {
password}
修改密码
rabbitmqctl change_password {
username} {
password}
清除密码
rabbitmqctl clear_password {
username}
验证用户
rabbitmqctl authenticate_user {
username} {
password}
删除用户
rabbitmqctl delete_user {
username}
用户列表
rabbitmqctl list_users
3、权限管理
用户权限指的是用户对exchange,queue的操作权限,包括配置权限,读写权限。配置权限会影响到exchange,queue的声明和删除。读写权限影响到从queue里取消息,向exchange发送消息以及queue和exchange的绑定(bind)操作
RabbitMQ中,权限控制是以vhost为单位,创建用户时,将被指定至少一个vhost,默认的vhost是 “ / ”
授予权限
rabbitmqctl set_permissions [-p vhost] {
user}{
conf}{
write}{
read}
| 配置项 | 说明 |
|---|---|
| vhost | 授权用户访问指定的vhost |
| user | 用户名 |
| conf | 一个用于匹配用户在哪些资源上拥有可配置权限的正则表达式,例如:".*"表示全部 |
| write | 一个用于匹配用户在哪些资源上拥有可写权限的正则表达式 ,例如:".*"表示全部 |
| read | 一个用于匹配用户在哪些资源上拥有可读权限的正则表达式,例如:".*"表示全部 |
收回权限
rabbitmqctl clear_permissions [-p vhost] {username}
虚拟主机权限列表
rabbitmqctl list_permissions [-p vhost]
查看指定用户权限
rabbitmqctl list_user_permissions {username}
4、角色分配
rabbitmq的角色有5种类型
rabbitmqctl set_user_tags {
username} {
tag…}
User为用户名
Tag为角色名(对应的administrator,monitoring,policymaker,management,或其他自定义名称)
也可以给同一用户设置多个角色,例:
rabbitmqctl set_user_tags hncscwc monitoring policymaker
| 配置项 | 说明 |
|---|---|
| none其他 | 无任何角色,新创建的用户默认角色为none |
| management普通管理者 | 可以访问web管理页面,无法看到节点信息,也无法对策略进行管理 |
| policymaker策略制定者 | 包含management的所有权限,并可以管理策略和参数,但无法查看节点的相关信息 |
| monitoring监控者 | 包含management的所有权限,并可以看到所有连接(启用management plugin的情况下)、信道及节点相关信息(进程数,内存使用情况,磁盘使用情况等) |
| administartor超级管理员 | 包含minitoring的所有权限,并可以管理用户、虚拟主机、权限、策略、参数 |
5、Web端管理
RabbitMQ Management 插件可以提供Web界面来管理RabbitMQ中的虚拟主机、用户、角色、队列、交换器、绑定关系、策略、参数等,也可用于监控RabbitMQ服务的状态及一些统计信息
启动插件
rabbitmq-plugins enable rabbitmq_management
关闭插件
rabbitmq-plugins disable rabbitmq_management
插件列表:其中标记为[E*]为显示启动,其中标记为[e*]为隐式启动,开启此功能后需要重启服务才可以正式生效
rabbitmq-plugins list
6、RabbitMQ 管理
[root@servers sbin]# ./rabbitmq-server #启动,ctrl + c 退出及关闭
[root@servers sbin]# ./rabbitmq-server -detached #在后台启动服务
[root@servers sbin]# ./rabbitmqctl stop #关闭服务
[root@C7--13 sbin]# ./rabbitmq-server status #查看状态
7、查看队列列表
rabbitmqctl list_queues[-p vhost][queueinfoitem…]
| 返回列 | 说明 |
|---|---|
| name | 队列名称 |
| durable | 队列是否持久化 |
| auto_delete | 队列是否自动删除 |
| arguments | 队列参数 |
| policy | 应用到队列上的策略名称 |
| pid | 队列关联的进程ID |
| owner_pid | 处理排他队列连接的进程ID |
| exclusive | 队列是否排他 |
8、查看交换器列表
rabbitmqctl list_exchanges [-p vhost][exchangeinfoitem…]
| 返回列 | 说明 |
|---|---|
| name | 交换器名称 |
| type | 交换器类型 |
| durable | 交换器是否持久化 |
| auto_delete | 交换器是否自动删除 |
| internal | 是否是内置交换器 |
| arguments | 交换器的参数 |
| policy | 交换器的策略 |
9、查看绑定关系的列表
rabbitmqctl list_bindings [-p] [bindinginfoitem…]
| 返回列 | 说明 |
|---|---|
| source_name | 消息来源的名称 |
| source_kind | 消息来源的类别 |
| destination_name | 消息目的地的名称 |
| destination_kind | 消息目的地的种类 |
| routing_key | 绑定的路由键 |
| arguments | 绑定的参数 |
10、查看连接信息列表
rabbitmqctl list_connections [connectioninfoitem …]
| 返回列 | 说明 |
|---|---|
| pid | 与连接相关的进程ID |
| name | 连接名称 |
| port | 服务器端口 |
| host | 服务器主机名 |
| peer_port | 服务器对端端口。当一个客户端与服务器连接时,这个客户端的端口就是peer_port |
| peer_host | 服务器对端主机名称,或IP |
| ssl | 是否启用SSL |
| state | 连接状态,包括starting\tning\opening\running\flow\blocking\blocked\closing\closed |
| channels | 连接中的信道个数 |
| protocol | 使用的AMQP协议版本 |
| user | 与连接相关的用户名 |
| vhost | 与连接相关的vhost名称 |
| timeout | 连接超时时长,单位秒 |
11、查看信道列表
rabbitmqctl list_channels [channelinfoitem…]
| 返回列 | 说明 |
|---|---|
| pid | 与连接相关的进程ID |
| connection | 信道所属连接的进程ID |
| name | 信道名称 |
| number | 信道的序号 |
| user | 与连接相关的用户名 |
| vhost | 与连接相关的vhost名称 |
| transactional | 信道是否处于事务模式 |
| confirm | 信道是否处于 publisher confirm模式 |
| consumer_count | 信道中的消费者个数 |
| messages_unacknowledged | 已投递但是还未被ack的消息个数 |
| messages_uncommitted | 已接收但是还未提交事务的消息个数 |
| acks_uncommitted | 已ack收到但是还未提交事务的消息个数 |
| messages_unconfirmed | 已发送但是还未确认的消息个数 |
| perfetch_count | 消费者的Qos个数限制,0表示无上限 |
| global_prefetch_count | 整个信道的Qos个数限制 |
12、查看消费者列表
rabbitmqctl list_consumers [-p vhost]
| 返回列 | 说明 |
|---|---|
| arguments | 参数 |
| チャンネルピッド | チャネルプロセスID |
| 消費者タグ | 消費者マーク |
| プリフェッチ数 | コンシューマのQOS数の制限。0は上限なしを意味します |
| キュー名 | キュー名 |
(2) Webインターフェースの基本操作
1. ユーザーの追加

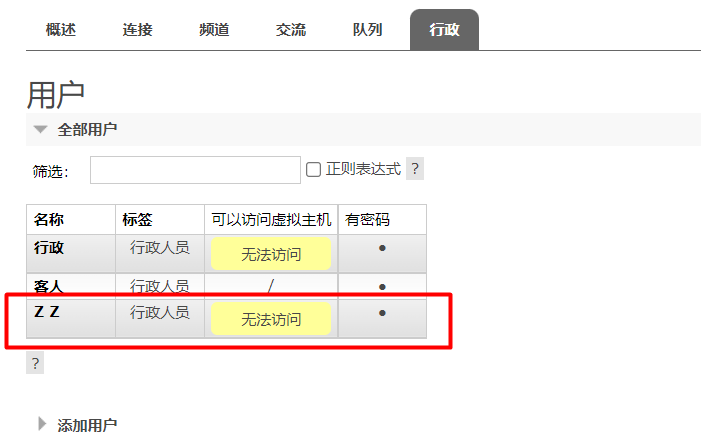
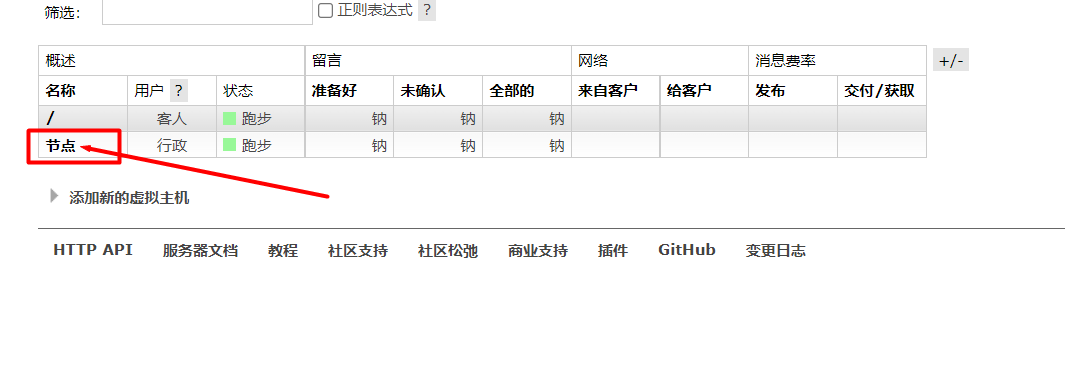
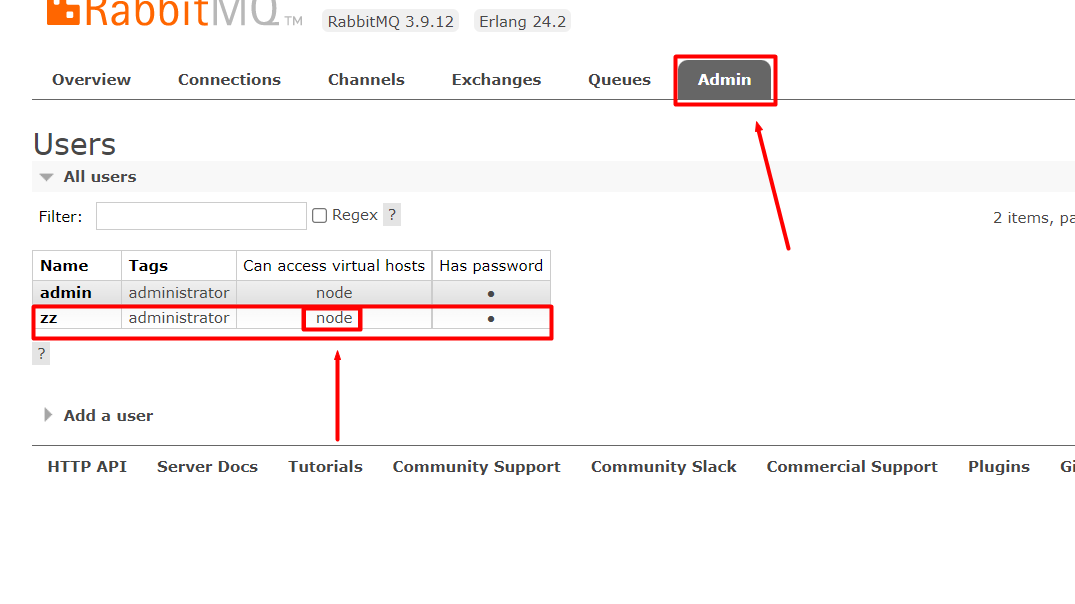
2. 仮想ホストを作成します。 3. ユーザーを仮想ホストにバインドします。
3. ユーザーを仮想ホストにバインドします。