
- これは、2020 年に arxiv に投稿された自己教師あり暗画像強調に関する記事です。その後の教師なし暗画像強調の多くの論文がそれを引用し、それと比較します。
- この記事では、ベイズ確率の観点から retinex の公式を次のように分析しています。
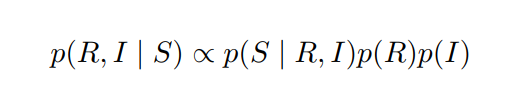
したがって、方程式の右側の 3 つの確率の最大化は、それぞれ 3 つの損失関数によって導かれます。 最初の項は、記事では
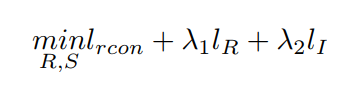
L1 として定義されています。非常に一般的な損失:
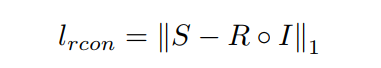
第 2 項は、暗い画像の輝度成分 (HSV 色空間では V) のヒストグラム等化結果 F(S) と、R の輝度成分の L1 距離および平滑化損失として定義されます。 R の第 3 項は次のように定義されます。 ネットワーク構造は次のとおりです。
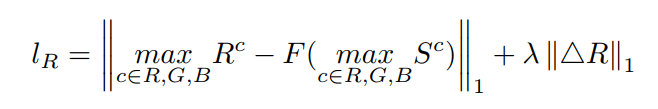
図
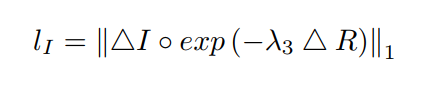
に示すように:
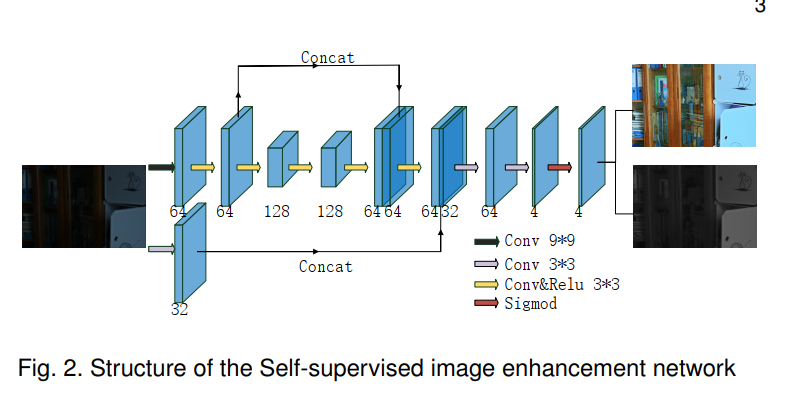
- この記事では、最初にダウンサンプリングしてからアップサンプリングするネットワークではノイズを除去できるが、画像がぼやけてしまうと提案しています。
- LOLの実画像485枚を使用したトレーニング、パッチサイズは48*48です
- この記事では、実際には、トレーニング時間が異なると同じ結果を達成できないことにも言及しました。

- 同時に記事は、トレーニングで使用できる写真は 1 枚だけであることも提案しました。LOL の 15 個のテスト セットで、トレーニング セットとして 1 つを選択し、10,000 エポックでトレーニングし、これらの 15 枚の画像でテストすると、効果は依然として非常に良好です。さらに、単一の画像でトレーニングする場合、反復回数が増加しても、ネットワークによって生成される結果にアーティファクトは表示されません。これは、アーティファクトがネットワーク設計によって引き起こされていないことを示しています (したがって、指は確率的勾配降下法とデータを指します)セット?):
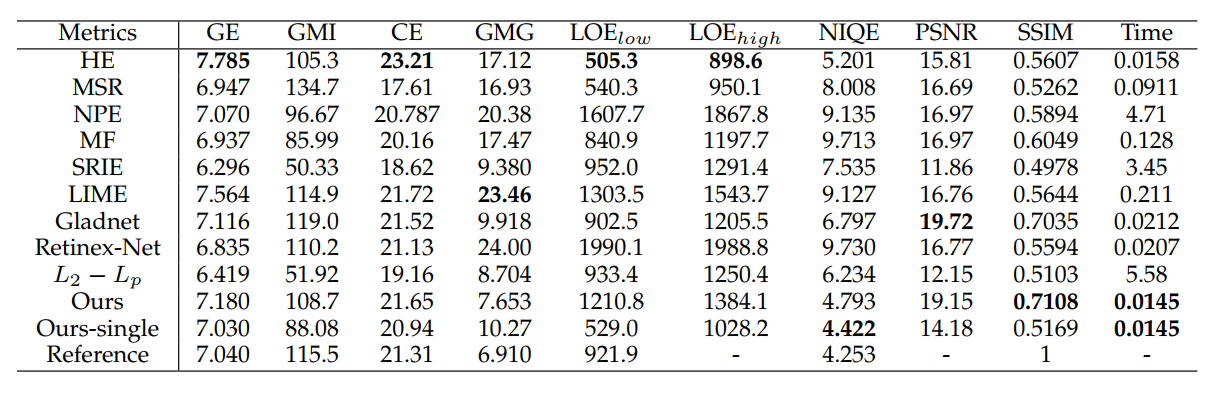
ビジュアルも良さそうです:
