記事ディレクトリ
1. はじめに
最近のプロジェクトで Elasticsearch を使用する必要があるので、その使用方法を簡単に学びに行きました。特定の高度な機能の一部は当面表示できず、機能は現在少し制限されていますが、いくつかの基本的なニーズはまだ表示できます満たした。そこで、それを整理し、欠点を指摘できればと思い、記事を書きました。
2. Elasticsearchのインストールと設定
3. Spring Boot と Elasticsearch を統合する
1. 依存関係と構成ファイルを追加する
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
spring:
elasticsearch:
rest:
uris: 127.0.0.1:9200 #可配置多个,以逗号间隔举例: ip,ip
connection-timeout: 1
read-timeout: 30
2. Elasticsearchデータモデルの作成
import com.fasterxml.jackson.annotation.JsonFormat;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.DateFormat;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import java.util.Date;
/**
* @BelongsProject: spring-elas
* @BelongsPackage: com.example.springelas.elas.entity
* @Author: gepengjun
* @CreateTime: 2023-09-07 09:16
* @Description: TODO
* @Version: 1.0
*/
@Data
@Document(indexName = "book",createIndex = true)
public class Book {
@Id
@Field(type = FieldType.Text)
private String id;
@Field(analyzer="ik_max_word")
private String title;
@Field(analyzer="ik_max_word")
private String author;
@Field(type = FieldType.Double)
private Double price;
@JsonFormat(pattern = "yyyy-MM-dd'T'HH:mm:ss")
@Field(type = FieldType.Date,format = DateFormat.custom, pattern = "8uuuu-MM-dd'T'HH:mm:ss")
private Date createTime;
@Field(type = FieldType.Date,format = DateFormat.time)
private Date updateTime;
/**
* 1. Jackson日期时间序列化问题:
* Cannot deserialize value of type `java.time.LocalDateTime` from String "2020-06-04 15:07:54": Failed to deserialize java.time.LocalDateTime: (java.time.format.DateTimeParseException) Text '2020-06-04 15:07:54' could not be parsed at index 10
* 解决:@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss")
* 2. 日期在ES存为long类型
* 解决:需要加format = DateFormat.custom
* 3. java.time.DateTimeException: Unable to obtain LocalDate from TemporalAccessor: {DayOfMonth=5, YearOfEra=2020, MonthOfYear=6},ISO of type java.time.format.Parsed
* 解决:pattern = "uuuu-MM-dd HH:mm:ss" 即将yyyy改为uuuu,或8uuuu: pattern = "8uuuu-MM-dd HH:mm:ss"
* 参考:https://www.elastic.co/guide/en/elasticsearch/reference/current/migrate-to-java-time.html#java-time-migration-incompatible-date-formats
*/
}
3. Elasticsearch ウェアハウス インターフェイスを定義する
public interface ESBookRepository extends ElasticsearchRepository<Book, String> {
List<Book> findByTitleOrAuthor(String title, String author);
@Highlight(fields = {
@HighlightField(name = "title"),
@HighlightField(name = "author")
})
@Query("{\"match\":{\"title\":\"?0\"}}")
SearchHits<Book> find(String keyword);
}
4. Elasticsearch データ操作を実装する
@Service
public class ESBookImpl {
@Autowired
ESBookRepository esBookRepository;
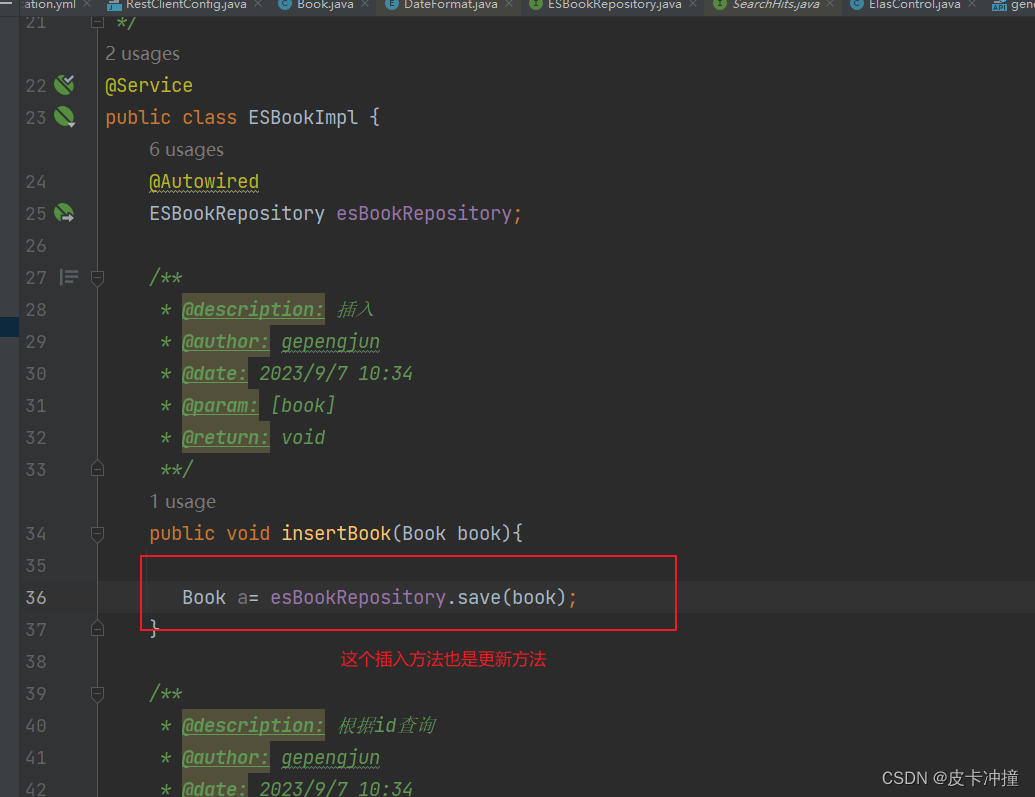
public void insertBook(Book book){
Book a= esBookRepository.save(book);
System.out.println(a);
}
public Book queryBook(String keyWord){
return esBookRepository.findById(keyWord).get();
}
}
4. 基本的なクエリとインデックスの操作
1. データの挿入と更新
2. データとインデックスの削除
/**
* @description: 根据id删除
* @author: gepengjun
* @date: 2023/9/7 10:35
* @param: [keyWord]
* @return: void
**/
public void deleteBook(String keyWord){
esBookRepository.deleteById(keyWord);
// esBookRepository.delete(book); //可通过实体删除
}
まず、spring が提供する findAll メソッドですべてのデータを取得し、

delete メソッドを呼び出して ID に従って削除すると、
ID 1 のデータがなくなっていることがわかります。
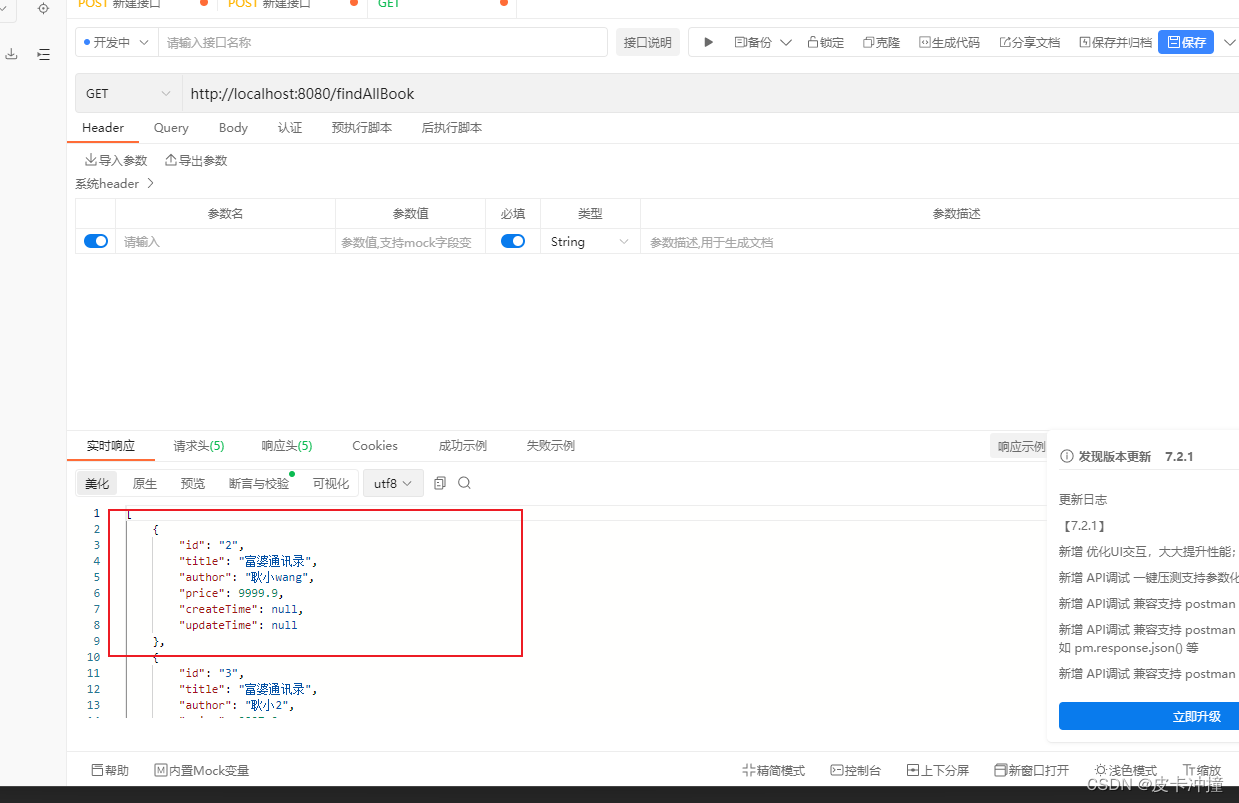
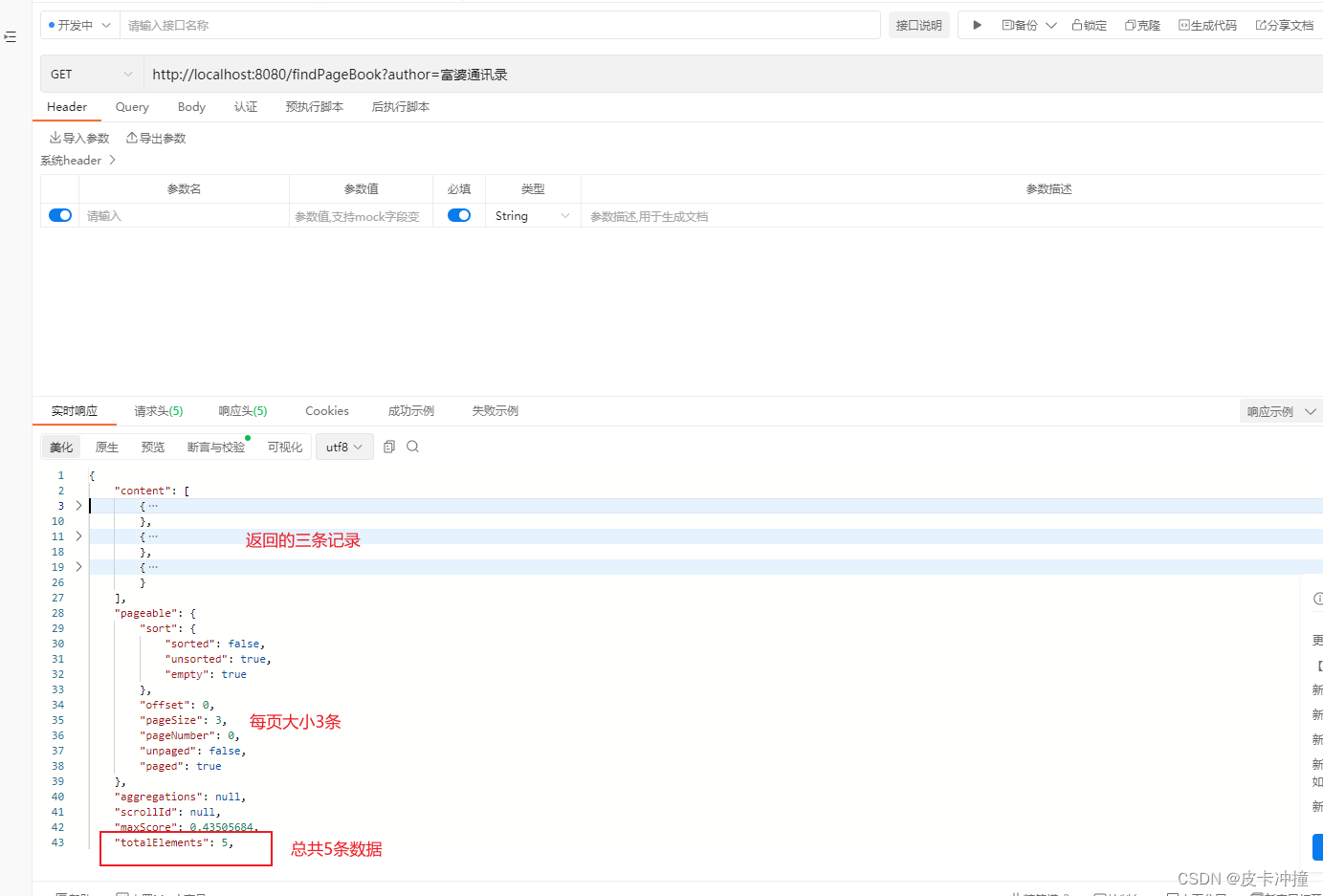
3. 条件付きクエリとページング クエリ
Elasticsearch ウェアハウスでページング クエリ メソッドを定義する
Page<Book> findByTitle(String title, Pageable pageable);
ビジネスカプセル化クラスでこのメソッドを呼び出します。
public Object pageBook(String author){
Pageable pageable= PageRequest.of(0, 3);
return esBookRepository.findByTitle(author,pageable);
}
最後に、コントロールでそれを呼び出すと、実行が確認できます。
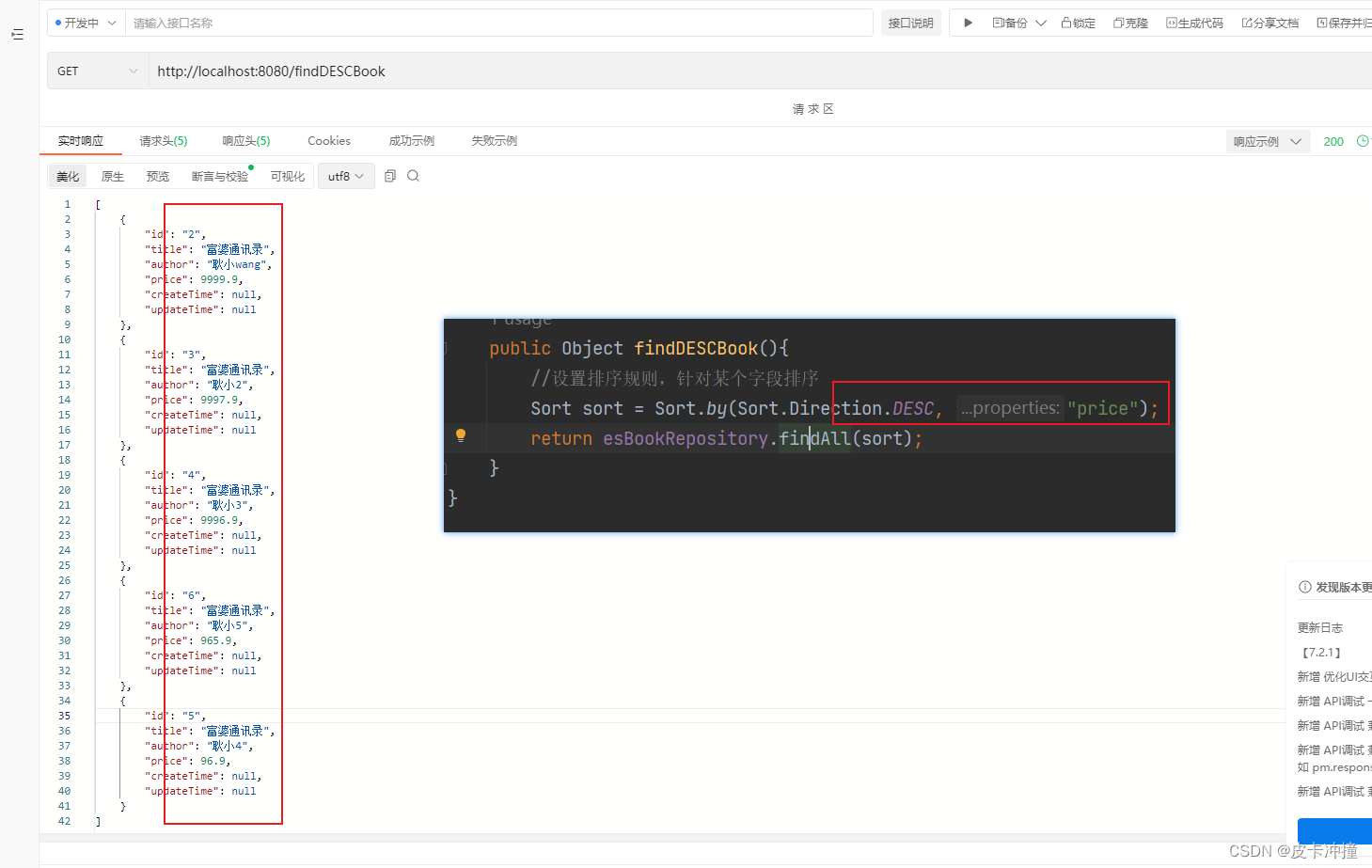
4. 並べ替えと集計のクエリ
選別
これはすべてのクエリの並べ替えです。条件付きクエリに基づいて並べ替える必要がある場合は、上記のページングを参照して自分で設定できます。
public Object findDESCBook(){
//设置排序规则,针对某个字段排序
Sort sort = Sort.by(Sort.Direction.DESC, "price");
return esBookRepository.findAll(sort);
}
価格フィールドで並べ替え
集計クエリ
この集計クエリにはまだいくつかの小さな欠陥があります。
@Autowired
private ElasticsearchOperations elasticsearchOperations;
/**
* @description: 聚合查询
* @author: gepengjun
* @date: 2023/9/7 11:37
* @param: []
* @return: java.lang.Object
**/
public Object findAggregationBOOK(String title){
Pageable pageable= PageRequest.of(0, 3);
TermsAggregationBuilder builder1 = AggregationBuilders.terms("taxonomy").field("title.keyword");
//构建查询
NativeSearchQuery build = new NativeSearchQueryBuilder()
.addAggregation(builder1)
.withPageable(pageable)
.build();
SearchHits<Book> search = elasticsearchOperations.search(build, Book.class);
for (SearchHit<Book> bookSearchHit : search) {
System.out.println(bookSearchHit.getContent());
}
Aggregations aggregations = search.getAggregations();
Map<String, Aggregation> asMap = aggregations.getAsMap();
return asMap;
}

アプリケーションシナリオ
集計クエリは、大量のデータから意味のある概要情報や統計結果を抽出するために使用できる Elasticsearch の重要な機能です。以下は、Elasticsearch の集計クエリのいくつかの一般的なアプリケーション シナリオの概要です。
-
データ分析と統計: 集計クエリでは、平均、合計、最大値、最小値などの計算など、大量のデータの統計と分析を実行できます。これを使用して、レポート、プロットを生成したり、複雑なデータ分析タスクを実行したりできます。
-
グループ統計: 集計クエリを使用すると、指定されたフィールドに基づいてデータをグループ化し、各グループの統計を計算できます。たとえば、電子商取引では、販売データを製品カテゴリごとにグループ化し、カテゴリごとの売上または販売数量を取得できます。
-
ネストされた集計: Elasticsearch は、より複雑な統計および分析のニーズを実現するために、複数の集計操作を一緒にネストすることをサポートしています。複数レベルのネストされた集計を構築することで、データ間の関係をドリルダウンして、より詳細な洞察を得ることができます。
-
時間分析: 集計クエリは時系列データ分析に非常に役立ちます。指定された時間間隔に従ってデータをバケット化し、各期間内で統計分析操作を実行できます。たとえば、アクセス ログ データを時間、日、週、または月ごとに分析できます。
-
バケット分析: バケット集計は、データをさまざまなバケットまたは間隔に分割する集計方法です。バケット条件は範囲、用語一致、またはスクリプトを通じて定義でき、各バケットに対して統計分析を実行できます。
-
カーディナリティと重複排除のカウント: 集計クエリは、カーディナリティの統計と重複排除のカウントもサポートします。フィールド内の固有の値の数を見つけたり、フィールド内の重複した値をカウントしたりできます。
-
複数フィールドの統計: Elasticsearch では、1 回の集計操作で複数のフィールドの統計を使用できます。これは、複数のメトリクスまたはディメンションを同時に分析する場合に役立ちます。
5. 高度なクエリと全文検索
1. 複数フィールドのマッチングとあいまいクエリ
/**
* @description: 多字段匹配查询
* @author: gepengjun
* @date: 2023/9/7 15:40
* @param: [field1, field2]
* @return: java.util.List<com.example.springelas.elas.entity.Book>
**/
List<Book> findByAuthorOrPrice(String field1, String field2);
/**
* @description: 针对一个字段模糊查询
* @author: gepengjun
* @date: 2023/9/7 15:40
* @param: [pattern]
* @return: java.util.List<com.example.springelas.elas.entity.Book>
**/
List<Book> findByAuthorLike(String pattern);
2. 範囲クエリと正規表現クエリ
/**
* @description: 查询某一个字段根据正则表达式
* @author: gepengjun
* @date: 2023/9/7 15:41
* @param: [regexPattern]
* @return: java.util.List<com.example.springelas.elas.entity.Book>
**/
List<Book> findByAuthorRegex(String regexPattern);
//具体使用即使直接传入一个正则表达式
List<Book> entityList = esBookRepository.findByAuthorRegex("^abc.*");
3. 全文検索とハイライト表示
これがハイライトです
@Highlight(fields = {
@HighlightField(name = "title"),
@HighlightField(name = "author")
})
@Query("{\"match\":{\"title\":\"?0\"}}")
SearchHits<Book> find(String keyword);
6. まとめ
EL の使用は、私たちが使用する一部の ORM フレームワークと同じであるため、EL と対話するために Spring によって提供されるパッケージは data の下に配置されます。