用紙情報
タイトル: 競争力のあるコラボレーション: 奥行き、カメラモーション、オプティカルフロー、モーションセグメンテーションの
教師なし共同学習 著者: Anurag Ranjan、Varun Jampani、Lukas Balles
出典: CVPR
時間: 2019
コードアドレス: https://github.com/anuragranj/cc
抽象的な
私たちは、低レベル視覚における相互に関連するいくつかの問題、つまり単一ビューの深度予測、カメラの動き推定、オプティカル フロー、および静止シーンと移動領域へのビデオのセグメンテーションの教師なし学習に取り組みます。
私たちの主な洞察は、これら 4 つの基本的な視覚問題が幾何学的制約を通じて結合されているということです。したがって、それらを一緒に解決する方法を学ぶと、解決策が相互に強化されるため、問題が単純化されます。幾何学的形状をより明確に活用し、シーンを静止領域と移動領域にセグメント化することで、以前の作品を上回りました。
この目的を達成するために、複雑な問題を解決するために複数の特殊なニューラル ネットワークの調整されたトレーニングを容易にするフレームワークである競合コラボレーションを導入します。競争的コラボレーションは期待値の最大化とよく似ていますが、ニューラル ネットワークは、静的領域または移動領域に対応するピクセルを解釈する競合者として、またピクセルを静的または独立して移動するものとして割り当てる修飾子を介して協力者として機能します。私たちの新しいアプローチは、これらすべての問題を共通のフレームワークに統合し、同時に、移動オブジェクトと静的背景へのシーンのセグメンテーション、カメラの動き、静的シーン構造の深さ、および移動オブジェクトのオプティカル フローに関する理由付けを行います。私たちのモデルは監視なしでトレーニングされ、すべての部分問題に関して教師なし共同手法の中で最先端のパフォーマンスを達成します。

導入
この論文では、単一ビューの奥行き予測、カメラの動き推定、オプティカル フロー、動きのセグメンテーションという4 つの問題について検討します。これまでの研究では、実際のデータ [5] と合成データ [4] を使用した監視を通じてこれらの問題に対処してきました。ただし、合成データと実際のデータの間には常に現実のギャップがあり、実際のデータは制限されているか不正確です。
アプローチ。教師なし共同学習の問題に対処するために、ネットワークが特定の目標を達成するために協力し、競争することを学習する一般的なフレームワークである競合コラボレーション (CC) を導入します。私たちの特定のシナリオでは、競争力のあるコラボレーションは、2 人のプレーヤーがリソースをめぐって競合する 3 人用のゲームであり、3 人目のプレーヤー (ホスト) が監督します。
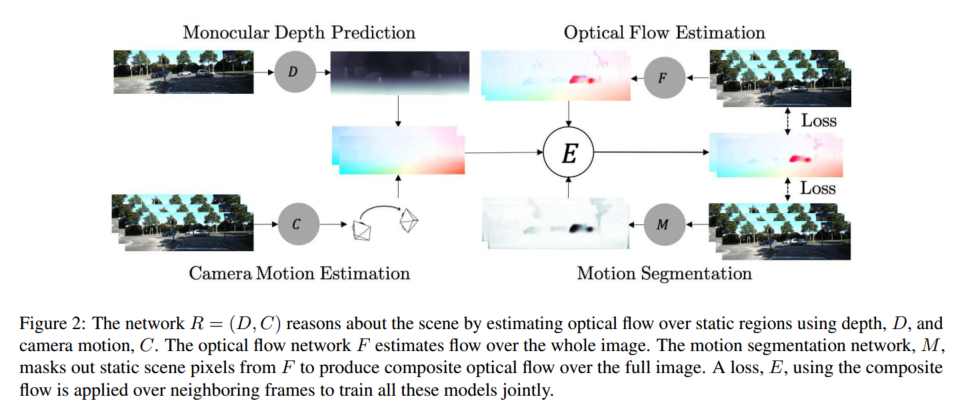
図 2 に示すように、フレームワークに 2 つのアクター、つまり静的シーン再構成器R = (D, C) R = (D, C)を導入します。R=( D 、C )は深度 D とカメラの動き C を使用して静的なシーンのピクセルについて推論し、動き領域再構成器 F は独立した動き領域内のピクセルについて推論します。2 人のプレイヤーは、画像シーケンス内の静止シーンと移動領域のピクセルについて推論して、トレーニング データを奪い合います。この競技は、静止シーンとモーション領域をセグメント化し、トレーニング データをプレーヤーに配布するモーション セグメンテーション ネットワーク M によって主催されます。ただし、公正な競争を確保するためにモデレータにもトレーニングが必要です。したがって、プレーヤー R と F は協力して、トレーニング サイクルの交互の段階で静的領域と移動領域を正しく分類できるようにホスト M をトレーニングします。この一般的なフレームワークは本質的に期待値最大化 (EM) に似ていますが、ニューラル ネットワーク トレーニング用に特別に定式化されています。
要約すると、私たちの貢献は次のとおりです。
1) 私たちは、特定の目標を達成するためにネットワークが競合者および協力者として機能する教師なし学習フレームワークである競合コラボレーションを導入します。
2) このフレームワークを使用してネットワークを共同トレーニングすると、パフォーマンスに相乗効果があることを示します。
3) 私たちの知る限り、私たちの方法は、奥行き、カメラの動き、オプティカル フローなどの低レベルの情報を使用して、監視なしでセグメンテーション タスクを解決する最初の方法です。
4) 教師なし手法による単一ビューの深度予測とカメラの動き推定において最先端のパフォーマンスを達成します。シーン ジオメトリに関する推論のための教師なし手法で最先端のオプティカル フロー パフォーマンスを実現し、完全に教師なしのモーション セグメンテーションのための最初のベースラインを導入します。
5) MNIST [19] および SVHN [25] の数値に関する混合領域学習を使用して、私たちの方法の収束特性を分析し、その一般化についての直観を与えます。
競争力のあるコラボレーション
ここでのコンテキストでは、競争的コラボレーションは、図 3 に示すように、モデレーターが監督するリソースをめぐって競い合う 2 人のプレーヤーからなる 3 人用のゲームとして定式化されます。
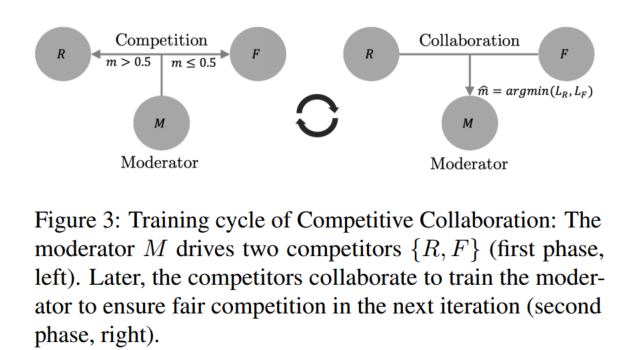
ラベルのないトレーニング データセットD = D i : i ∈ ND = {D_i : i ∈ \mathbb{N}} を考えます。D=D私は:私∈N、これは 2 つの素なセットに分割できます。2 人のプレーヤー {R, F} がこのデータをリソースとして取得するために競合し、各プレーヤーは損失を最小限に抑えるために D を分割しようとします。パーティションはホストの出力m = M (D i), m ∈ [0, 1] Ω m = M(D_i), m ∈ [0, 1]^Ω で構成されます。メートル=M ( D私は)、m∈[ 0 ,1 ]Ωレギュレーション、Ωは競合他社の出力ドメインです。競合するプレーヤーは、損失関数LR、LF L_R、L_FLR、Lふ、各プレーヤーがグループではなく自分自身に最適化できるようにします。この問題を解決するために、トレーニング サイクルは 2 つのフェーズに分かれています。
最初の段階では、モデレータ ネットワーク M を修正し、

モデレータ M を最小化します。ただし、モデレータ M もトレーニングする必要があります。これはトレーニング サイクルの第 2 段階で発生します。
プレーヤー {R、F} はコンセンサスを形成し、トレーニング サイクルの次の段階でデータを正しく割り当てるようにモデレーター M をトレーニングします。コラボレーションフェーズでは、を最小限に抑えることで競合他社を修正し、モデレータをトレーニングします
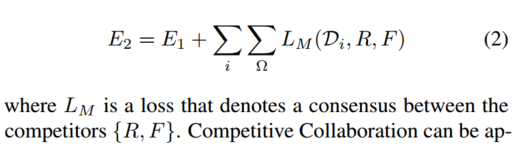
。
深度、カメラモーション、オプティカルフロー、モーションセグメンテーションを共同学習するというコンテキストで、
最初のアクター R = (D, C) は、シーン内の静的領域について推論するための深度ネットワークとカメラ モーション ネットワークで構成されます。
2 番目のアクター F は、移動領域を推測するオプティカル フロー ネットワークです。
競技者をトレーニングするために、動きセグメンテーション ネットワーク M は、静止ピクセルではネットワーク (D、C) を選択し、動き領域に属するピクセルでは F を選択します。
競合により、(D, C) が静的部分のみを推論し、移動ピクセルによってトレーニングが台無しになることが防止されます。同様に、F のトレーニング損失に静的ピクセルが現れるのを防ぎ、それによって動き領域でのパフォーマンスが向上します。トレーニング サイクルの第 2 フェーズでは、出場者 (D、C) と F が協力して、ホスト M をトレーニングするための損失として使用されるコンセンサスを形成することで、静的なシーンと移動領域について推論します。
このフレームワーク内で、深度、カメラモーション、オプティカルフロー、モーションセグメンテーションの教師なし共同推定を定式化します。
表記
奥行き、カメラの動き、オプティカル フロー、動きのセグメンテーションをそれぞれ推定するためのネットワークを表すために、{Dθ、Cφ、Fψ、Mχ} を使用します。添字 {θ、φ、ψ、χ} はネットワーク パラメーターです。簡潔にするために、いくつかの場所で添え字を省略します。ターゲットフレーム I と時間的に隣接する参照フレーム I-、I+ を持つ画像シーケンス I-、I、I+ を考えてみましょう。一般に、隣接するフレームが多数存在する可能性があります。私たちの実装では、Cφ と Mχ に 5 フレームのシーケンスを使用しますが、簡単にするために、メソッドの説明には 3 フレームを使用します。
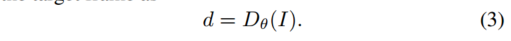
各参照フレーム I-、I+ のカメラの動き e を推定するのと同じように、ターゲット フレームの深度を推定します。ターゲット フレーム I も
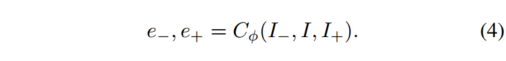
同様に、ターゲット画像の静止シーンと移動領域への分割を推定します。静的シーンのオプティカル フローは、カメラの動きと深さによってのみ定義されます。これは通常、シーンの構造を指します。モバイルエリアには専用の遊び場があります。ターゲット イメージとリファレンス イメージの各ペアに対応するセグメンテーション マスクは、次の式で与えられます。 ここで、
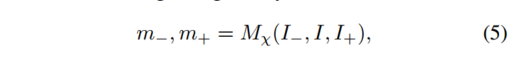
m − , m + ∈ [ 0 , 1 ] Ω m_−, m_+ \in [0, 1]^Ωメートル−、メートル+∈[ 0 ,1 ]Ω は、空間ピクセル領域 Ω 内の静的領域の確率を表します。
最後に、ネットワーク Fψ はオプティカル フローを推定します。Fψ は一度に 2 つの画像を処理し、それぞれ u-、u+、後方および前方のオプティカル フローを推定するときにそれらの重みを共有します。
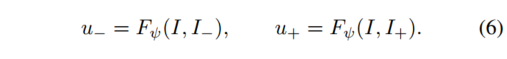
損失
組み合わせることでエネルギーを最小限に抑えます
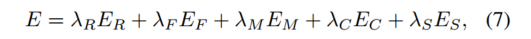
ネットワーク パラメーター {Dθ、Cφ、Fψ、Mχ} を学習します。ここで、{λR、λF、λM、λC、λS} は各エネルギー項の重みです。
ER E_RER 和 E F E_F Eふ項は、静的領域と移動領域をそれぞれ再構成するときに、2 つの競合他社が最小化する目的です。データの獲得競争は新興市場によって引き起こされています。
より大きな重みλ M λ_M私Mより多くのピクセルを静的シーン再構成器に駆動します。EC E_CEC言葉はコラボレーションを促進し、ES E_SES滑らかさの正則化です。
静的シーンアイテムER E_RER次のように、静的なシーンのピクセルの測光損失を最小限に抑えます。
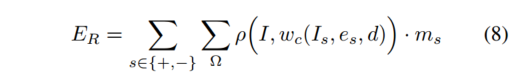
ここで、Ω は空間ピクセル領域、ρ はロバスト誤差関数、wc w_cです。wc深度 d とカメラの動き e に基づいて、参照フレームをターゲット フレームに向かってワープします。同様に、EF E_FEふ移動領域での測光損失の最小化構造類似性損失 (SSIM) [34] としても知られる第 2 項
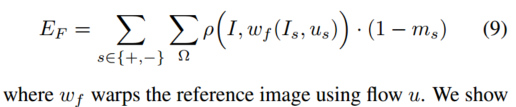
としてロバスト誤差 ρ(x, y) を計算します

。これは、以前の研究 [22、37] で報告されており、以下で使用されます。μ x 、σ x μ^x、σ^xメートルx、pxはピクセル近傍の局所平均と分散です。ここで、c 1 = 0.0 1 2 、c 2 = 0.0 3 2、c_1 = 0.01^2、c_2 = 0.03^2c1=0.0 12、c2=0.0 32。

付録 A.2 で説明されているように、ν(e, d) がカメラの動き e と深さ d によって引き起こされるオプティカル フローを表すものとします。コンセンサスロスEC E_CECコラボレーションは、ν(e, d) によって与えられる静的なシーン フローと Fψ によって与えられるオプティカル フロー推定との間のコンセンサスを達成することによって推進され、移動オブジェクトをセグメント化するために制約付きマスクが使用されます。

最初の指標関数は、ρ R = ρ ( I , wc ( I s , es , d ) ) ρ_R = ρ(I, w_c(I_s, e_s, d)) を比較することにより、競合他社へのマスクの割り当てを容易にします。rR=p (私、wc(私s、es、d ))和ρ F = ρ ( I , wf ( I s , us ) ) ρ_F = ρ(I, w_f (I_s, u_s))rふ=p (私、wふ(私s、あなたs))ピクセルの測光エラーを低減します。
2 番目のインジケータ関数では、静的シーン フロー ν(e,d) がオプティカル フロー u に近い場合、しきい値 λc により I = 1 が強制され、静的シーンを示します。記号 ∨ は、指標関数間の論理 OR を表します。R の測光誤差が F より小さい場合、または R の誘導流量が F の流量と類似している場合、コンセンサス ロスEC E_CECピクセルを静的としてマークすることをお勧めします。
最後に、平滑化項ES E_SES深さ、セグメンテーション、フローの正則化マトリックスとして機能します。

推論
深さ d とカメラの動き e は、ネットワーク出力から直接推測されます。動きセグメンテーションm * は、マスクネットワークM x の出力と、F x の静的フローおよびオプティカルフロー推定との間の一貫性から得られる。これは次式で与えられます。最初の
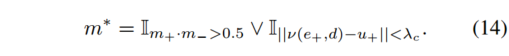
項は、前方参照フレームと後方参照フレームを使用して推定されたマスク確率の交差として Mχ をとります。
第 2 項は、R = (Dθ, Cφ) と Fψ から推定されたフロー間のコンセンサスを使用して、マスクについて推論します。
最終的なマスクは、2 つの項を結合することによって取得されます。
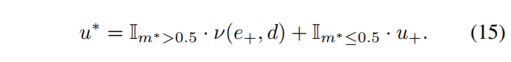
最後に、(I, I+) 間の完全なオプティカル フロー u* は、静的シーンと独立して移動する領域からのオプティカル フローの組み合わせであり、式 (7) の損失は再構成誤差を最小限に抑えるために定式化されます。2 つの競合製品、静的シーン再構成器 R = (Dθ, Cφ) と移動領域再構成器 Fψ は、この損失を最小限に抑えます。
再構成器 R は式 (8) を使用して静的シーンを推論し、再構成器 Fψ は移動領域に対して式 (9) を使用します。
調整は、式 (11) を使用してマスク ネットワーク Mx を通じて実現されます。
さらに、式 (12) を使用して R と F の間の協力を推進し、ネットワーク Mx をトレーニングします。
シーンが完全に静止していてカメラだけが動く場合、マスクは (Dθ、Cφ) によってシーン全体を強制的に再構成します。ただし、シーンの独立して移動する領域では (Dθ, Cφ) は間違っており、これらの領域は Fψ を使用して再構成されます。コンディショナー Mχ は、式 (12) に示すように、(Dθ, Cφ) と Fψ についてコンセンサスに達し、シーン内の静的部分と動的部分を推論することで、静的領域と動的領域を正しくセグメント化するようにトレーニングされます。
したがって、トレーニング サイクルは 2 つのフェーズに分かれています。
第 1 段階では、レギュレータ Mχ は、式 (8、9) を使用して 2 つのモデル (Dθ、Cφ) と Fψ の間の競合を駆動します。
第 2 段階では、プレイヤー (Dθ、Cφ) と Fψ が協力して、式 (11、12) を使用してレギュレータ Mχ をトレーニングします。