予測には、数値フィッティング、線形回帰、重回帰、時系列、ニューラル ネットワークなどが含まれます。
単変量時系列予測の場合: モデルには AR、MA、ARMA、ARIMA が含まれます。一般に、ARIMA はすべてを表すことができます。
データとコードのリンク:データと Jupyter ファイル
今後 10 年間の米国の GDP の変化の予測を列として考えてみましょう。
目次
2 番目のステップは、定常シーケンス分析を実行することです。
3 番目のステップは、不安定なシーケンスの差分演算を実行することです。
4 番目のステップは、モデルの順序付け、モデルの選択、およびフィッティングを実行することです。
ARIMA のフローチャートは次のとおりです。

最初のステップはデータをインポートすることです。
予測対象の変数のデータを観察し、雑多なデータを削除し、サイズや型などのデータ自体の属性を取得します。
import pandas as pd,numpy as np
from matplotlib import pyplot as plt
#加载数据,sheet_name指定excel表的数据页面,header指定指标column属性,loc去除杂数据,可选:parse_dates=[''],index_col='',use_cols=['']
df=pd.read_excel('./data/time1.xls',sheet_name='数据',header=1).loc[1:,:]
#DateFrame索引重置
df=df.set_index('DATE')#df.set_index('DATE',inplace=True)
#查看前5行
print(df.head(5))
#查看列索引
print(df.columns)#print(df.keys())
#查看表的维度
print(df.shape)
#查看行索引
print(df.index)
#np.array() array1.reshape(,) df.values.astype(int).tolist() np.vstack((a1,a2)) np.hstack((a1,a2)) round() iloc
#时间索引拆分
# dates=pd.date_range(start='1991-01-01',end='2007-08-01',freq='MS')#日期取值和格式转换,MS代表每月第一天
# years=[d.strftime('%Y-%m') for d in dates][0:200:25]
# years.append('2007-09')結果は次のとおりです。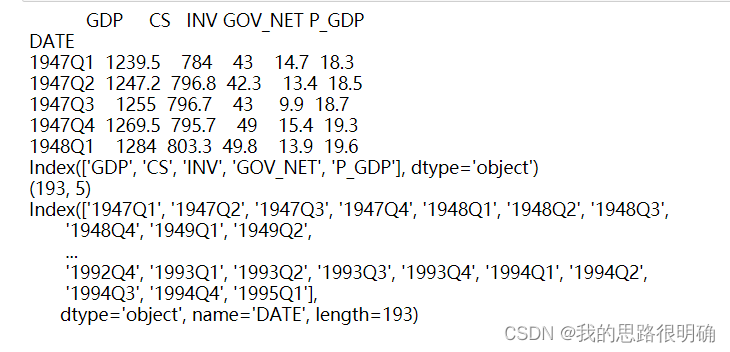
2 番目のステップは、定常シーケンス解析を実行することです。
私たちが研究・分析する時系列、つまりパネルデータは、それが広範囲に定常である場合にのみ研究の意味を持ちますが、それが非定常系列である場合には、解析を実行する前にその差分を定常系列に変換する必要があります。厳密に定常的なシーケンスの場合、特性は変化しません。つまり、シーケンスはホワイト ノイズ シーケンスであり、そのようなシーケンスには研究上の意義はありません。
したがって、ここで GDP 時系列データを取得した後、まず元のシーケンスに対して LB 統計量を使用してホワイト ノイズ検定を実行します。p 値が有意水準 a=0.05 未満の場合、元のシーケンスは a であると見なされます。非ホワイト ノイズ シーケンス。研究にとって意味があります。
次に、時系列図を描き、GDP の時系列の定常性を主観的に判断します。明らかな傾向がある場合は非定常系列であり、明らかな傾向がない場合、または定常性の判断が難しい場合は、ルート統計は、ADF ユニットが静止しているかどうかを判断するのに役立ちます。ADF 統計量については、統計量の値を比較して判断することも、p 値を比較して判断することもできます。たとえば、有意水準が a=0.05 の場合、変数の ADF 統計量が ADF よりも小さい場合、 a=0.05 の統計量の場合、変数に対応する時系列が定常シーケンスであることを示します。より直接的な方法は、変数の p 値が 0.05 未満の場合にのみ、それも a=0.05 であると判断することです。静止シーケンス。
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
plt.rc('font',family='SimHei')
plt.style.use('ggplot')
df.plot(secondary_y=['CS','INV','P_GDP','GOV_NET'])#单个指标时序图 df['CS'].plot()
plt.xlabel('Date')
plt.ylabel('Value')
plt.title('Time Series Plot')
#plt.grid()
plt.show()
from statsmodels.tsa.stattools import adfuller# ADF检验
for i in df.columns:
data=df[i]
print(f'{i}的单位根检验')
result = adfuller(data)#默认情况下,regression参数为'c',表示使用包含截距项的回归模型。
print('ADF Statistic: %f' % result[0])#ADF统计量
print('p-value: %f' % result[1])#p值
print('Critical Values:')#在置信水平下的临界值
for key, value in result[4].items():
print('\t%s: %.3f' % (key, value))
print()コードの結果:


3 番目のステップは、非定常シーケンスの差分演算を実行することです。
一般に、時系列の差が 3 次を超えることはありません。元のデータに対して差分演算を実行し、時系列図の 2 番目のステップと ADF ユニット ルート テスト演算を繰り返します。差分シーケンスが 3 次であることが判明した場合は、定常シーケンス、差の次数を記録します。ここでは、GDP の差の次数は 1 であり、定常シーケンス テストに合格しています。微分されたシーケンスに対して再度ホワイト ノイズ テストを実行し、非ホワイト ノイズ シーケンスとして合格した場合は、次のステップに進みます。
#差分时序图
diff_data = df.diff(periods=1).dropna()# 创建一阶差分的时间序列,加上dropna()后续不需要执行[1:]
#print(diff_data)
diff_data.plot()
plt.xlabel('Date')
plt.ylabel('Value')
plt.title('Time Series Plot')
#plt.grid()
plt.show()
for i in diff_data.columns:
data=diff_data[i]#Series索引选取,一阶差分第一个数据为NA
print(f'{i}的单位根检验')
result = adfuller(data)#结果对应位置的数据需要自己判断是什么含义
print('ADF Statistic: %f' % result[0])#ADF统计量
print('p-value: %f' % result[1])#p值
print('Critical Values:')#在置信水平下的临界值
for key, value in result[4].items():
print('\t%s: %.3f' % (key, value))
print()
from statsmodels.stats.diagnostic import acorr_ljungbox
#这里为一阶差分后的平稳序列进行白噪声检验,lags为1,否则lags为0,这里拿上述的GDP指标进行
lags = [1,4,8,16,32]
print('差分序列的白噪声检验结果为:'+'\n',acorr_ljungbox(diff_data['GDP'], lags)) # 返回统计量和p值,这里的lags对应差分阶数
print('原始数据序列的白噪声检验结果为:'+'\n',acorr_ljungbox(df['GDP'], lags))コードの結果は次のとおりです。
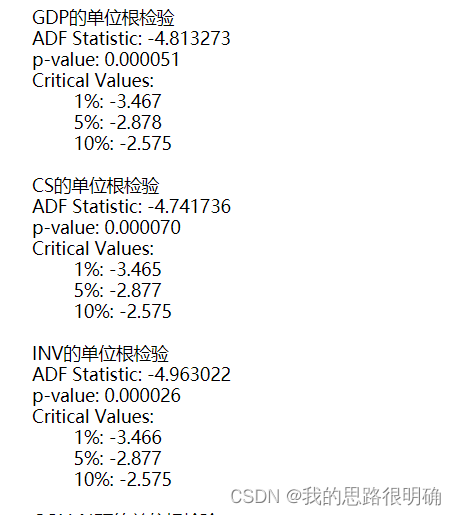
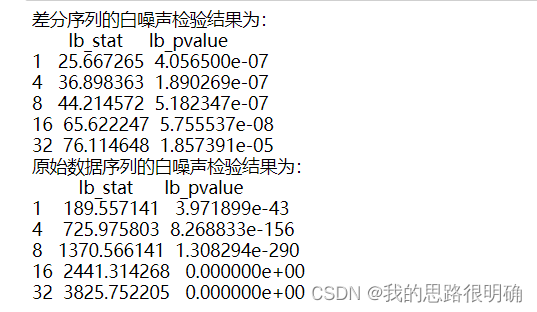
4 番目のステップは、モデルの順序付け、モデルの選択、フィッティングを実行することです。
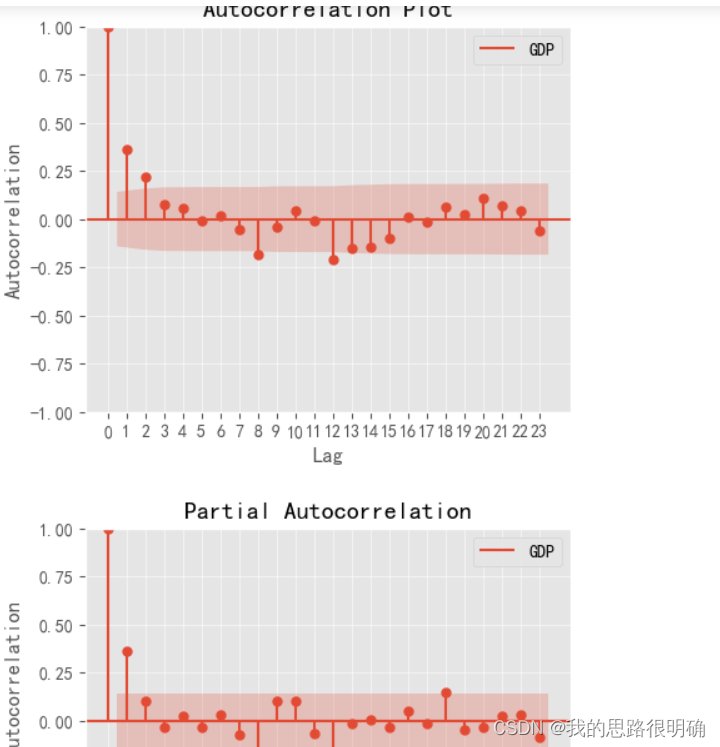
モデルの次数を決定するには、まず自己相関図と偏自己相関図を使用して次の予備判定を行います。 自己相関係数 部分自己相関係数 差分
AR
テーリング p 次打ち切り 0
MA q 次打ち切り テーリング 0
ARMA テーリング テーリング 0
ARIMAテーリング テーリング d
つまり、上記のモデルはすべて ARIMA (p, d, q) を使用して実装できます AR、MA、および ARMA はすべて ARIMA の特殊なケースです。
テーリングとトランケーションに関する経験的判断:
テーリング: 負の指数関数が単調に 0 に収束する、またはコサイン減衰を示す
; トランケーション: 0 まで急速に減衰し、0 付近で変動する;
トランケーションはテーリングが 0 に近づくよりも早く 0 に近づきます。トランケーションは大幅に増加しません。後の段階では
チャートを使用して予備的な判断を行った後も、モデルの次数を正確に決定できない場合は、AIC および BIC 基準を使用して判断や最適化を支援できます。たとえば、モデルの次数は 2、1、4、または 3、1、3 である可能性があると判断します。現時点ではわかりません。最初に ARIMA (2、1、4) を実行しても問題ありません。後続のモデルが有意であることを確認します。テストとパラメーター テストの両方が合格した場合は、ARIMA(2,1,4) を直接使用して予測を行って結論を導き出すことができますが、ARIMA( などの近くの順序をいくつか試すこともできます。 3,1,3)、ARIMA (2,1,3) なども合格しましたが、ARIMA (3,1,3) の AIC 値と BIC 値が最も小さい、つまりモデルの方が適合度が高い精度が高く、比較的最適なモデルです。このステップはモデルの最適化です。
ここでの順序設定と最適化は Python で次のように実装されています: q から (データ長/10)、p から 0 から (データ長/10) であり、通常、順序は (データ長/10) を超えません。 q*p モデル フィッティングを実行し、モデル フィッティング結果を使用して AIC と BIC の値を比較します。BIC 値が小さいほど、モデルが相対的に最適であると考えられ、モデルの次数を次数として使用します。最終モデルの組み合わせの順番です。
#生成自相关图,偏自相关图
from statsmodels.graphics.tsaplots import plot_acf,plot_pacf
fig, ax = plt.subplots(figsize=(5, 4))
plot_acf(diff_data['GDP'],ax=ax)#可以换成df的数据,这里用一阶差分数据得到平稳序列
ax.set_title("Autocorrelation Plot")
lags=list(range(24))
ax.set_xticks(lags)#这里把x坐标刻度变更精细,加网格图更方便,xticklabels替换标签
ax.set_xlabel("Lag")
ax.set_ylabel("Autocorrelation")
ax.grid(alpha=0.5)
plt.legend(['GDP'])#这里区别直接放入df.columns[i],如果是多字符如‘CS’,这样会被认为是一个序列,拆成C和S的图例
plt.show()
fig, ax = plt.subplots(figsize=(5, 4))
lags=list(range(24))
ax.set_xticks(lags)#这里把x坐标刻度变更精细,加网格图更方便,xticklabels替换标签
plot_pacf(diff_data['GDP'], ax=ax,method='ywm')#ywm替换默认的yw,去除警告
ax.set_xlabel('Lags')
ax.set_ylabel('Partial Autocorrelation')
ax.grid(alpha=0.5)
plt.legend(['GDP'])
plt.show()
import warnings
warnings.filterwarnings("ignore")
import statsmodels.api as sm
#diff_data['GDP'].values.astype(float),这里发现Serise的dtype为object,模型用的应该为float或者int类型,需要注意原数据的数据类型是否一致
Min=float('inf')
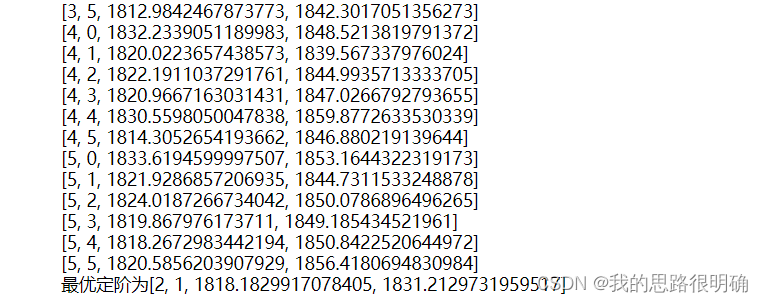
for i in range(0,6):#AIC,BIC最小找到p,q阶数来定阶,从0开始定阶是否可行??
for j in range(0,6):
result=sm.tsa.ARIMA(df['GDP'].values.astype(float),order=(i,1,j)).fit()
print([i,j,result.aic,result.bic])
if result.bic<Min:
Min=result.bic
best_pq=[i,j,result.aic,result.bic]
print(f'最优定阶为{best_pq}')コードの結果:
5 番目のステップは、モデルの結果分析とモデルのテストを実行することです。
モデルのテストは、モデル パラメーターのテストとモデルの有意性テストに分けられます。
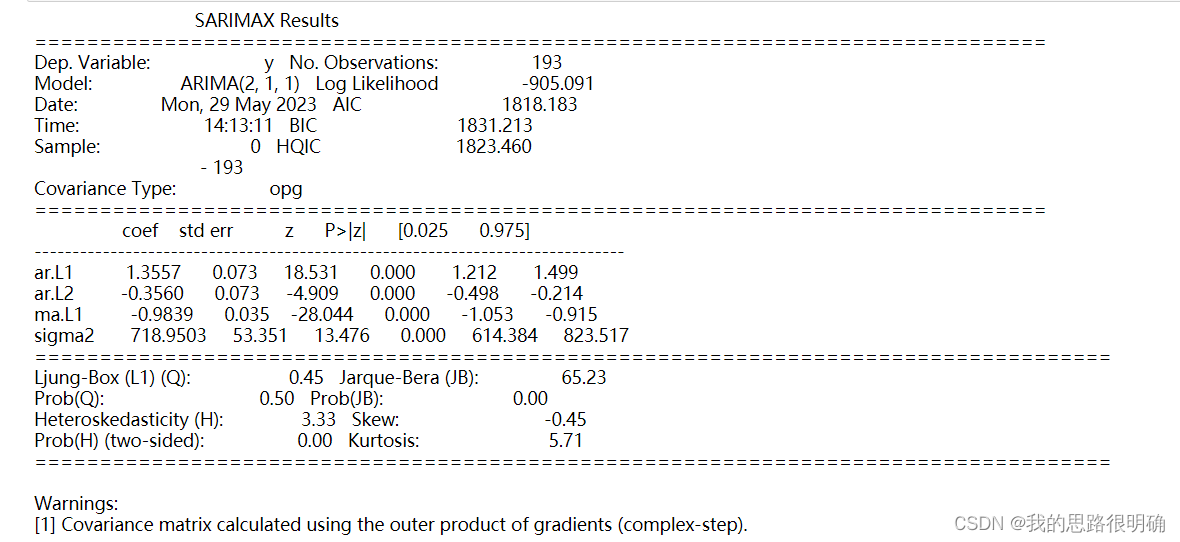
モデル有意性テスト: つまり、残差のホワイト ノイズ テストです。残差がホワイト ノイズ シーケンスの場合、つまり、元のシーケンス情報が完全に抽出されます。LB 統計を確認します。Python でのモデルの LB 統計結果が表示されます。は残差の LB 統計量です。p 値が 0.05 未満の場合、それは非ホワイト ノイズ シーケンスです。p 値が 0.05 より大きい場合、残差はホワイト ノイズ シーケンスであることを意味します。これは、私たちが望む結果。ここでは、モデルの残差値を個別に取り出したり、残差時系列図、QQ 図、正規分布図を自分で描いたり、ホワイト ノイズ テストを自分で実行して判断を支援したりできます。ホワイトノイズ系列は正規分布に従い、時系列図は滑らかに変動し、QQ図上の数値点は対角線付近にあります。
モデルのパラメーター テスト: 未知の各パラメーターが大幅に 0 であるかどうかをテストし、モデルが最も合理化されているかどうかをテストします。パラメーターが大幅にゼロでない場合は、近似モデルから削除して t 統計を確認できます。
モデル結果の部分説明:
const: 定数項
ar.L1: 自己回帰項の係数
ma.L1: 移動平均項の係数
sigma2:
各パラメーターの分散 P>|z|、a=0.05 未満の場合、帰無仮説パラメータが大幅に非ゼロである、つまりモデルを単純化する必要がないと考えられます。
Ljung-Box: LB 統計 ここで、LB の P 値は >0.95 である必要があることに注意してください。つまり、残差シーケンスはホワイト ノイズ シーケンスであると判断され、0.05 未満の場合、それはホワイト ノイズ シーケンスであると判断されます。非ホワイトノイズシーケンス。
ハルケ・ベラ: JB 統計の
不均一分散性検定の結果は分散が安定していることを示しています
Result=sm.tsa.ARIMA(df['GDP'].values.astype(float),order=(best_pq[0],1,best_pq[1])).fit()
print(Result.summary()) #显示模型的所有信息
print(len(Result.resid))
#print(Result.resid)这里观察到残差的第一项为原数据的1239.5,即差分数据不管第一项,这里需要调整残差的观测
#这里就可以观察到原始模型的结果LB统计量和这里的白噪声检验是一致的,p>0.05,即认为残差为白噪声序列,原序列信息提取充分。
lags = [1,4,8,16,32]
print('差分序列的白噪声检验结果为:'+'\n',acorr_ljungbox(Result.resid[1:], lags))
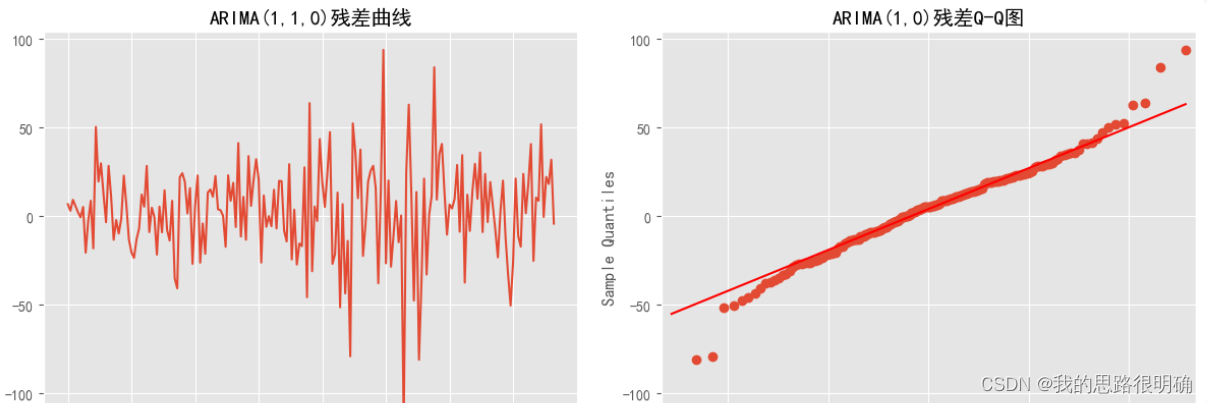
## 查看模型的拟合残差分布
fig = plt.figure(figsize=(12,5))
ax = fig.add_subplot(1,2,1)
plt.plot(Result.resid[1:])
plt.title("ARIMA(2,1,1)残差曲线")
## 检查残差是否符合正太分布
ax = fig.add_subplot(1,2,2)
sm.qqplot(Result.resid[1:], line='q', ax=ax)
plt.title("ARIMA(2,1,0)残差Q-Q图")
plt.tight_layout()
plt.show()
fig = plt.figure(figsize=(12,5))
Residual=pd.DataFrame(Result.resid[1:])
Residual.plot(kind='kde', title='密度')
plt.legend('')
plt.show()コードの結果は次のようになります。


6 番目のステップは、モデル予測を実行することです。
モデル予測とは、前述の比較的最適なモデルを使用して、以降の元のデータ変数に対応する値を予測することです。
なお、Python では、predict 関数で差分データを予測する場合、開始の開始と終了の終了に注意してください。たとえば、1 次差分データは 2 番目の観測値から始まり、対応する残差も後々
描画する場合は差分モデルの描画に注意が必要です。
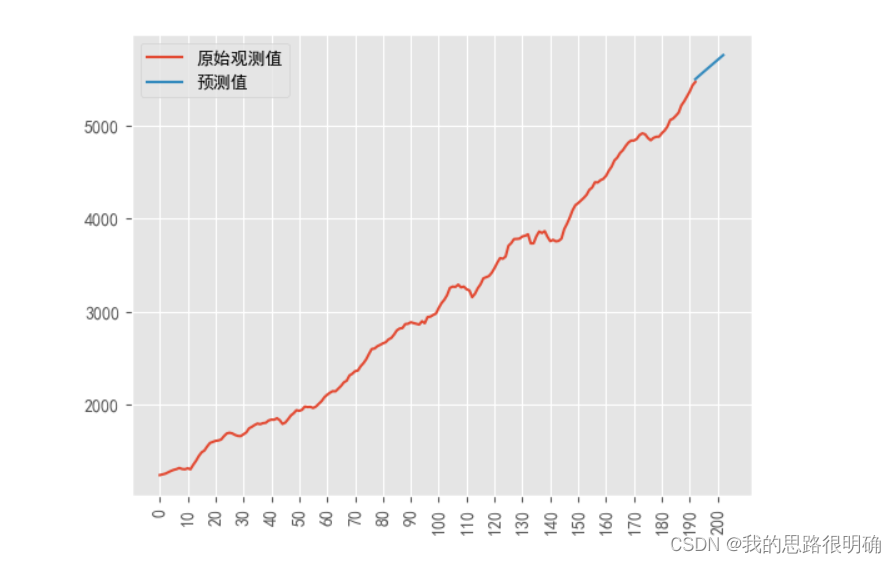
#预测,绘制原序列和预测序列值对比图
Predict=Result.predict(start=1, end=len(df['GDP'])-1+1+10); #不加参数默认0到n-1,要加预测个数在end后面N-1+预测n即可
#如果是一阶差分的序列预测,第一个数据已经差分消去了,应该start从第二个观测数据开始,即n=1;如果是0阶,则不需要按默认0到n-1
print(list(zip(range(193,203),Predict[-10:])))#打印预测值
plt.figure()
plt.plot(range(193),df['GDP'].values)#'o-k'
plt.plot(range(193+10),Predict)#'P--'
plt.legend(('原始观测值','预测值'))
plt.xticks(list(range(0,203,10)),rotation=90)
plt.show()
plt.figure()
plt.plot(range(193),df['GDP'].values)#'o-k'
plt.plot(range(192,193+10),Predict[-11:])#'P--'#接着原数据最后一个,进行拟合预测表示
plt.legend(('原始观测值','预测值'))
plt.xticks(list(range(0,203,10)),rotation=90)
plt.show()コードの結果:

PS: 自動化された AUTO-ARIMA の比較
import pmdarima as pm
# ## 自动搜索合适的参数
model = pm.auto_arima(df['GDP'].values,
start_p=1, start_q=1, # p,q的开始值
max_p=12, max_q=12, # 最大的p和q
d = 0, # 寻找ARMA模型参数
m=1, # 序列的周期
seasonal=False, # 没有季节性趋势
trace=True,error_action='ignore',
suppress_warnings=True, stepwise=True)
print(model.summary())
この分野については詳しく勉強していませんが、auto メソッドには長所と短所がありますが、コードを記述するためのアイデアを提供することもできます。