GCD とキューの簡単な概要については、「[iOS] GCD 学習」を参照してください。
この記事では主にGCDでのメソッドを紹介します。
バリアメソッド:dispatch_barrier_async
場合によっては、2 セットの操作を非同期で実行する必要があり、最初の操作セットが完了した後でのみ、2 番目の操作セットの実行を開始できます。もちろん、操作グループには 1 つ以上のタスクを含めることもできます。これには、 2 つの操作
グループ内のメソッドの使用dispatch_barrier_async. フェンス
dispatch_barrier_asyncメソッドは、指定されたタスクを非同期キューに追加する前に、同時キューに以前に追加されたすべてのタスクが実行されるのを待ちます。次に、dispatch_barrier_asyncメソッドによって追加されたタスクが実行された後、タスクは非同期キューに追加され、実行が開始されます。ボスのブログにある図は非常に鮮やかです。具体的な図は次のとおりです。
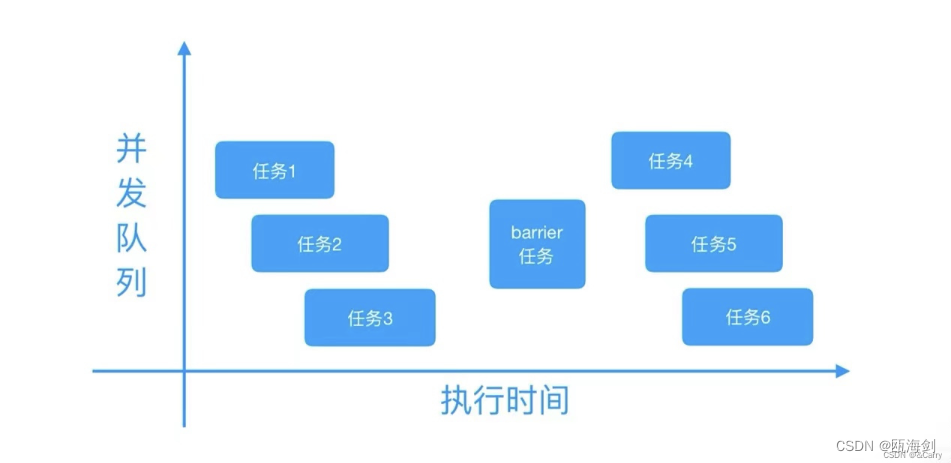
フェンス メソッドのコード使用例は次のとおりです。
- (void) barrier {
dispatch_queue_t queue = dispatch_queue_create("net.testQueue", DISPATCH_QUEUE_CONCURRENT);
dispatch_async(queue, ^{
// 追加任务 1
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"1---%@",[NSThread currentThread]); // 打印当前线程
});
dispatch_async(queue, ^{
// 追加任务 2
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"2---%@",[NSThread currentThread]); // 打印当前线程
});
dispatch_barrier_async(queue, ^{
// 追加任务 barrier
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"barrier---%@",[NSThread currentThread]);// 打印当前线程
});
dispatch_async(queue, ^{
// 追加任务 3
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"3---%@",[NSThread currentThread]); // 打印当前线程
});
dispatch_async(queue, ^{
// 追加任务 4
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"4---%@",[NSThread currentThread]); // 打印当前线程
});
}
結果:
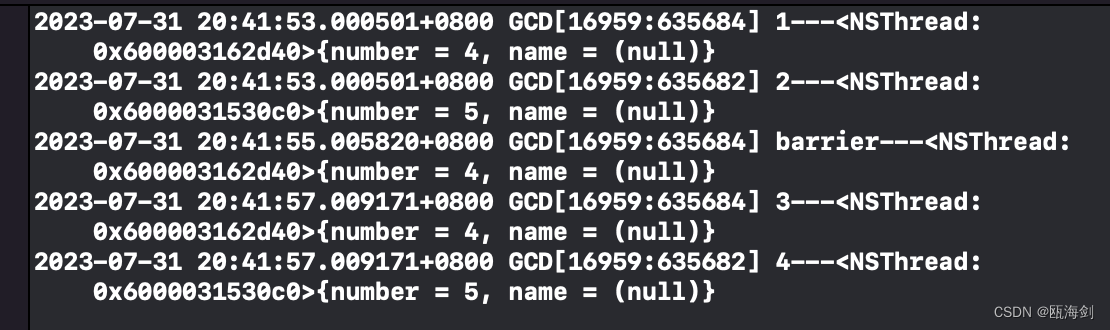
フェンスの前で操作を行った後、フェンスの操作を行い、最後にフェンスの後ろで操作を行います。
GCD の同期フェンスと非同期フェンス
以前に非同期フェンス + 単一キューを検討したとき、フェンスは同じキューに対してのみ機能しました。
それでは、異なるキュー内のタスクに対してどのようなインターセプトが行われるのでしょうか?
フェンス法の重要な部分については、さまざまな状況を試してみましょう。
非同期フェンス + 単一シリアル キュー:
(非同期実行+シリアルキュー自体は作成された新規スレッドのみでタスク追加順にキューイングされて実行されるため、この場合バリアを追加するのは実は無意味です)
- (void) asyncBarrierAndOneSerial {
dispatch_queue_t queue = dispatch_queue_create("net.testQueue", DISPATCH_QUEUE_SERIAL);
dispatch_async(queue, ^{
// 追加任务 1
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"1---%@",[NSThread currentThread]); // 打印当前线程
});
dispatch_async(queue, ^{
// 追加任务 2
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"2---%@",[NSThread currentThread]); // 打印当前线程
});
dispatch_barrier_async(queue, ^{
// 追加任务 barrier
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"barrier---%@",[NSThread currentThread]);// 打印当前线程
});
dispatch_async(queue, ^{
// 追加任务 3
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"3---%@",[NSThread currentThread]); // 打印当前线程
});
dispatch_async(queue, ^{
// 追加任务 4
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"4---%@",[NSThread currentThread]); // 打印当前线程
});
}
結果:
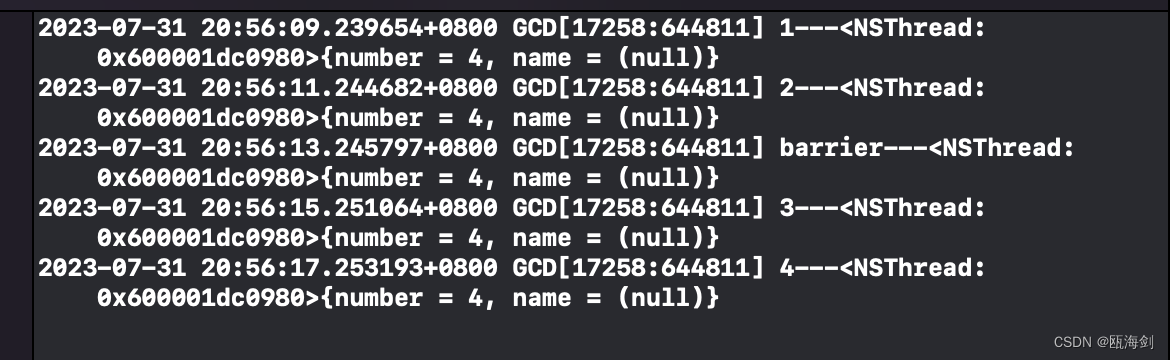
非同期フェンス + 単一の並列キュー:
(この状況は上で説明しました)
同期バリア + 単一シリアル キュー:
- (void)syncBarrierAndOneSerial {
dispatch_queue_t queue = dispatch_queue_create("net.testQueue", DISPATCH_QUEUE_SERIAL);
dispatch_async(queue, ^{
// 追加任务1
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"1--%@", [NSThread currentThread]); // 打印当前线程
});
dispatch_async(queue, ^{
// 追加任务2
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"2--%@", [NSThread currentThread]); // 打印当前线程
});
dispatch_barrier_sync(queue, ^{
// 追加任务 barrier
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"2--%@", [NSThread currentThread]); // 打印当前线程
});
dispatch_async(queue, ^{
// 追加任务3
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"3--%@", [NSThread currentThread]); // 打印当前线程
});
dispatch_async(queue, ^{
// 追加任务4
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"4--%@", [NSThread currentThread]); // 打印当前线程
});
}
結果:
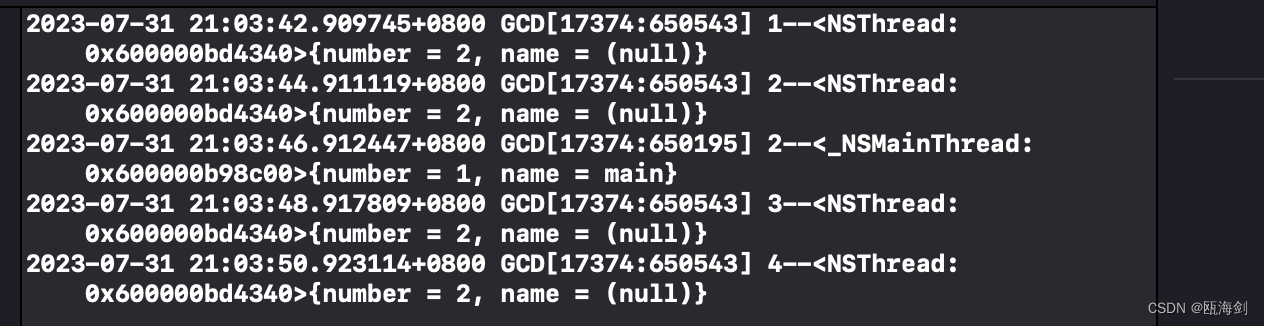
シリアルキューでは、同期実行でも非同期実行でも、すべてキューに入れられて順番に1つずつ実行されていることがわかります。
同期フェンス + 単一の並列キュー:
- (void)syncBarrierAndOneConcurrent {
dispatch_queue_t queue = dispatch_queue_create("net.testQuquq", DISPATCH_QUEUE_CONCURRENT);
dispatch_async(queue, ^{
// 追加任务1
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"1--%@", [NSThread currentThread]); // 打印当前线程
});
dispatch_async(queue, ^{
// 追加任务2
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"2--%@", [NSThread currentThread]); // 打印当前线程
});
dispatch_barrier_sync(queue, ^{
// 追加barrier
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"barrier--%@", [NSThread currentThread]); // 打印当前线程
});
dispatch_async(queue, ^{
// 追加任务3
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"3--%@", [NSThread currentThread]); // 打印当前线程
});
dispatch_async(queue, ^{
// 追加任务4
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"4--%@", [NSThread currentThread]); // 打印当前线程
});
}
操作結果:
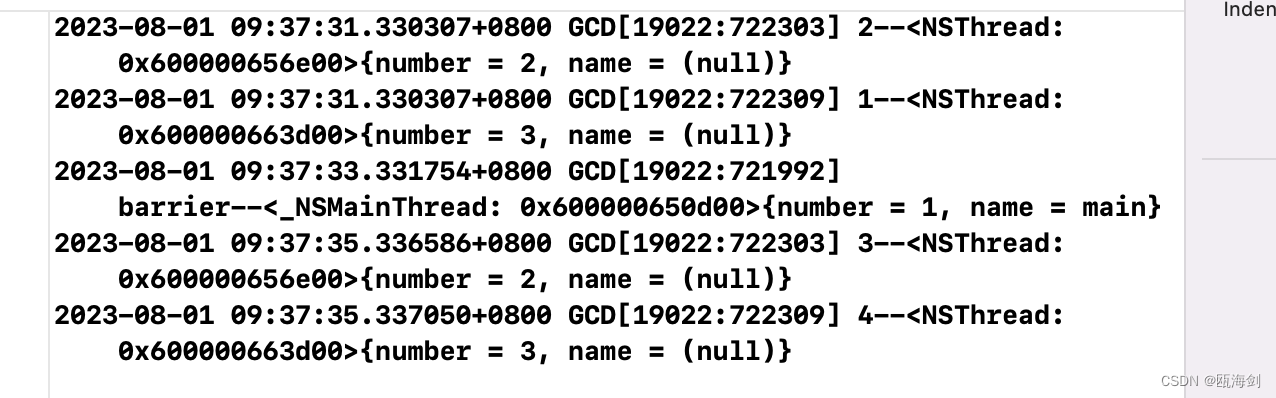
実際の実行結果は、フェンスの前のタスク グループ (つまり、タスク 1 とタスク 2) です。結果は、プログラムの実行開始から 2 秒後に同時に出力されます。その後、フェンス内のメソッドが個別に実行されます。最後の 2 秒では、結果が同時に出力されます。フェンスの後のタスク グループ (つまり、タスク 3 とタスク 4) が実行され、フェンスの前後のタスク グループのタスクは実行されます。すべて並列キュー内で非同期に実行されるため、実行が終了する順序は不確かです。
非同期フェンス + 複数のシリアル キュー:
- (void)asyncBarrierAndSerials {
dispatch_queue_t queue1 = dispatch_queue_create("net.testQueue1", DISPATCH_QUEUE_SERIAL);
dispatch_queue_t queue2 = dispatch_queue_create("net.testQueue2", DISPATCH_QUEUE_SERIAL);
dispatch_queue_t queue3 = dispatch_queue_create("net.testQueue3", DISPATCH_QUEUE_SERIAL);
dispatch_queue_t queue4 = dispatch_queue_create("net.testQueue4", DISPATCH_QUEUE_SERIAL);
dispatch_queue_t queue5 = dispatch_queue_create("net.testQueue5", DISPATCH_QUEUE_SERIAL);
dispatch_async(queue1, ^{
// 追加任务1
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"1---%@", [NSThread currentThread]); // 打印当前线程
});
dispatch_async(queue2, ^{
// 追加任务2
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"2---%@", [NSThread currentThread]); // 打印当前线程
});
dispatch_barrier_async(queue3, ^{
// 追加任务 barrier
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"barrier---%@", [NSThread currentThread]); // 打印当前线程
});
dispatch_async(queue4, ^{
// 追加任务4
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"4---%@", [NSThread currentThread]); // 打印当前线程
});
dispatch_async(queue5, ^{
// 追加任务5
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"5---%@", [NSThread currentThread]); // 打印当前线程
});
}
結果:

非同期フェンス+複数のシリアルキューの場合、各タスクはほぼ同時に実行され、5つのタスクの実行終了時刻は完全にランダムとなり、この時点でフェンスの意味はなくなります。
非同期フェンス + 複数の並列キュー:
非同期フェンス+複数の直列キューの場合、各タスクの実行終了時刻は完全にランダムであるため、非同期フェンス+複数の並列キューも完全にランダムであると考えられます。
- (void) asyncBarrierAndConcurrents {
dispatch_queue_t queueFirst = dispatch_queue_create("net.testQueueFirst", DISPATCH_QUEUE_CONCURRENT);
dispatch_queue_t queueSecond = dispatch_queue_create("net.testQueueSecond", DISPATCH_QUEUE_CONCURRENT);
dispatch_queue_t queueThird = dispatch_queue_create("net.testQueueThird", DISPATCH_QUEUE_CONCURRENT);
dispatch_queue_t queueFourth = dispatch_queue_create("net.testQueueFourth", DISPATCH_QUEUE_CONCURRENT);
dispatch_queue_t queueFifth = dispatch_queue_create("net.testQueueFifth", DISPATCH_QUEUE_CONCURRENT);
dispatch_async(queueFirst, ^{
// 追加任务 1
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"1---%@",[NSThread currentThread]); // 打印当前线程
});
dispatch_async(queueSecond, ^{
// 追加任务 2
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"2---%@",[NSThread currentThread]); // 打印当前线程
});
dispatch_barrier_async(queueThird, ^{
// 追加任务 barrier
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"barrier---%@",[NSThread currentThread]);// 打印当前线程
});
dispatch_async(queueFourth, ^{
// 追加任务 3
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"3---%@",[NSThread currentThread]); // 打印当前线程
});
dispatch_async(queueFifth, ^{
// 追加任务 4
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"4---%@",[NSThread currentThread]); // 打印当前线程
});
}
結果:

同期フェンス + 複数のシリアル キュー:
- (void) syncBarrierAndSerials {
dispatch_queue_t queueFirst = dispatch_queue_create("net.testQueueFirst", DISPATCH_QUEUE_SERIAL);
dispatch_queue_t queueSecond = dispatch_queue_create("net.testQueueSecond", DISPATCH_QUEUE_SERIAL);
dispatch_queue_t queueThird = dispatch_queue_create("net.testQueueThird", DISPATCH_QUEUE_SERIAL);
dispatch_queue_t queueFourth = dispatch_queue_create("net.testQueueFourth", DISPATCH_QUEUE_SERIAL);
dispatch_queue_t queueFifth = dispatch_queue_create("net.testQueueFifth", DISPATCH_QUEUE_SERIAL);
dispatch_async(queueFirst, ^{
// 追加任务 1
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"1---%@",[NSThread currentThread]); // 打印当前线程
});
dispatch_async(queueSecond, ^{
// 追加任务 2
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"2---%@",[NSThread currentThread]); // 打印当前线程
});
dispatch_barrier_sync(queueThird, ^{
// 追加任务 barrier
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"barrier---%@",[NSThread currentThread]);// 打印当前线程
});
dispatch_async(queueFourth, ^{
// 追加任务 3
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"3---%@",[NSThread currentThread]); // 打印当前线程
});
dispatch_async(queueFifth, ^{
// 追加任务 4
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"4---%@",[NSThread currentThread]); // 打印当前线程
});
}
結果:

この場合、フェンス、タスク 1、タスク 2 がほぼ同時に実行され、結果が最初に出力されます (各フェンスが最初に結果を出力します)。ただし、同期されたフェンスがメインスレッドを占有しているため、結果はフェンスが終了した後、タスク 3 と 4 は、フェンス内のタスクが完了するまで待機してから実行を開始できます。
同期フェンス + 複数の並列キュー:
- (void) syncBarrierAndConcurrents {
dispatch_queue_t queueFirst = dispatch_queue_create("net.testQueueFirst", DISPATCH_QUEUE_CONCURRENT);
dispatch_queue_t queueSecond = dispatch_queue_create("net.testQueueSecond", DISPATCH_QUEUE_CONCURRENT);
dispatch_queue_t queueThird = dispatch_queue_create("net.testQueueThird", DISPATCH_QUEUE_CONCURRENT);
dispatch_queue_t queueFourth = dispatch_queue_create("net.testQueueFourth", DISPATCH_QUEUE_CONCURRENT);
dispatch_queue_t queueFifth = dispatch_queue_create("net.testQueueFifth", DISPATCH_QUEUE_CONCURRENT);
dispatch_async(queueFirst, ^{
// 追加任务 1
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"1---%@",[NSThread currentThread]); // 打印当前线程
});
dispatch_async(queueSecond, ^{
// 追加任务 2
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"2---%@",[NSThread currentThread]); // 打印当前线程
});
dispatch_barrier_sync(queueThird, ^{
// 追加任务 barrier
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"barrier---%@",[NSThread currentThread]);// 打印当前线程
});
dispatch_async(queueFourth, ^{
// 追加任务 3
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"3---%@",[NSThread currentThread]); // 打印当前线程
});
dispatch_async(queueFifth, ^{
// 追加任务 4
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"4---%@",[NSThread currentThread]); // 打印当前线程
});
}
結果:
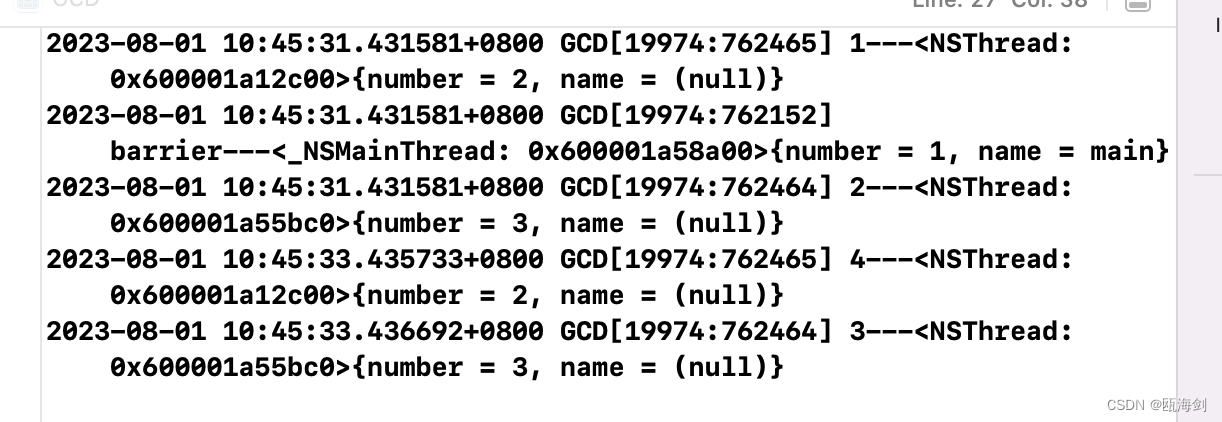
実際の動作では、タスク1、タスク2、フェンスが同時に実行を開始し、3つの実行がいつ終了するかは不確定ですが、フェンスがメインスレッドを占有しているため、タスク3とタスク4は実行可能です。フェンスの実行が完了した後、実行が開始されるまで待機するだけです。
遅延実行メソッド:dispatch_after
指定した時間 (たとえば、3 秒) 後にタスクを実行する必要がある場合がよくあります。この状況は、メソッドを使用して実現できますGCD。dispatch_after
dispatch_afterこのメソッドは指定された時間の後に処理を開始するのではなく、指定された時間の後にタスクをメインキューに追加することに注意してください。厳密に言えば、この時間は絶対に正確ではありませんが、タスクの実行を大まかに遅らせたい場合には、dispatch_afterこの方法は非常に効果的です。
- (void)after {
NSLog(@"currentThread---%@", [NSThread currentThread]); // 打印当前线程
NSLog(@"asyncMain---begin");
dispatch_after(dispatch_time(DISPATCH_TIME_NOW, (int64_t)(2.0 * NSEC_PER_SEC)), dispatch_get_main_queue(), ^{
// NSEC_PER_SEC是一个宏定义,通常用于表示一秒钟所包含的纳秒数。
// 2.0 秒后异步追加任务代码到主队列,并开始执行
NSLog(@"after---%@", [NSThread currentThread]); // 打印当前线程
NSLog(@"asyncMain---willEnd");
});
}
結果:

具体的な実行状況は次のとおりです。最初に合計が出力されasyncMain---begin、2 秒後に合計がafter---<_NSMainThread: 0x60000110c900>{number = 1, name = main}順番に出力されますasyncMain---willEnd。
GCD ワンタイム コード (1 回だけ実行):dispatch_once
dispatch_onceシングルトンを作成する場合、またはプログラム全体で 1 回だけ実行されるコードがある場合は、GCD メソッドを使用します。このメソッドを使用すると、プログラムの実行中に特定のコードが 1 回だけ実行されるようになり、dispatch_onceマルチスレッド環境でもdispatch_onceスレッドの安全性が保証されます。
/**
* 一次性代码(只执行一次)dispatch_once
*/
- (void)once {
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
// 只执行 1 次的代码(这里面默认是线程安全的)
});
}
GCD 高速反復メソッド:dispatch_apply
通常はループ トラバーサルを使用しますforが、GCD高速な反復方法が提供されますdispatch_apply。dispatch_apply指定されたタスクを指定されたキューに指定された回数追加し、すべてのキューの実行が完了するまで待機します。
シリアルキューで使用するとdispatch_apply、forループのように順番に同期的に実行されます。しかし、これは迅速な反復の重要性を反映していません。
非同期実行には同時キューを使用できます。たとえば、この0~5番号をたどる場合、要素を 1 つずつ取り出して 1 つずつたどるのがループ方法です。複数の数値を複数のスレッドで同時に (非同期的に) 反復処理できます。6fordispatch_apply
もう 1 つのポイントは、シリアル キューにあるかコンカレント キューにあるかに関係なく、dispatch_applyすべてのタスクが実行されるまで待機するという点で、これはキュー グループ内の同期操作やdispatch_group_waitメソッドと似ています。
- (void)apply {
dispatch_queue_t queue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0);
NSLog(@"apply---begin");
dispatch_apply(6, queue, ^(size_t iteration) {
NSLog(@"%zd---%@", iteration, [NSThread currentThread]);
});
NSLog(@"apply---end");
}
実行結果は次のとおりです。
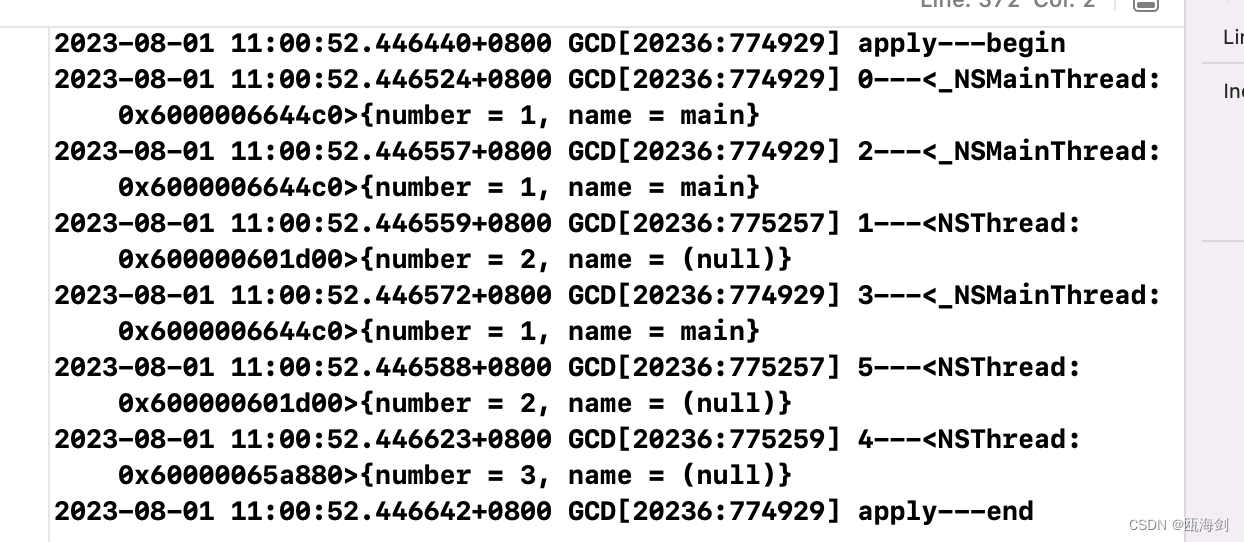
タスクは同時キュー内で非同期に実行されるため、各タスクの実行時間は変動し、最終的な終了順序も変動します。ただし、最後に apply-end を実行する必要があります。これは、dispatch_apply メソッドがすべてのタスクが完了するまで待機するためです。
GCD キュー グループ:dispatch_group
場合によっては、時間のかかる 2 つのタスクを非同期で実行し、時間のかかる 2 つのタスクが完了したらメイン スレッドに戻ってタスクを実行するというニーズが発生することがあります。この時点では、GCD のキュー グループを使用できます。
キューグループを呼び出すときは、dispatch_group_asyncまずタスクをキューに入れてから、そのキューをキューグループに入れます。または、キュー グループdispatch_group_enterと呼び出しキュー グループをdispatch_group_leave組み合わせて使用し、指定されたスレッドに戻ってタスクを実行します。または、現在のスレッドに戻って下方向の実行を続行するために使用します (現在のスレッドがブロックされます)。dispatch_group_asyncdispatch_group_notifydispatch_group_wait
ディスパッチグループ通知
groupのタスクの完了ステータスを監視します。すべてのタスクが完了したら、タスクを に追加しgroupて実行します。
- (void)group {
dispatch_queue_t queue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0);
dispatch_group_t group = dispatch_group_create();
dispatch_group_async(group, queue, ^{
NSLog(@"blk0");
});
dispatch_group_async(group, queue, ^{
NSLog(@"blk1");
});
dispatch_group_async(group, queue, ^{
NSLog(@"blk2");
});
//dispatch_group_notify会等到group中的处理全部结束时再开始执行
//在group中的处理全部结束时,将第三个参数(block)追加到第二个参数所对应的queue中
dispatch_group_notify(group, dispatch_get_main_queue(), ^{
NSLog(@"done");
});
}
操作結果:

マルチスレッド同時実行時はグループに追加したキューの実行結果時間が不確実なため、印刷順序はランダムになります(理論上はそうなりますが、特にタスクの実行順序は投入順序に影響される可能性があります)複数のタスクが同じキューに送信された場合。)。
ディスパッチグループ待機
さらに、dispatch_group_wait(group, DISPATCH_TIME_FOREVER);2 番目のパラメータをdispatch_time_t型として使用することもでき、group待機処理を完了するようにカスタマイズできます。
dispatch_group_wait現在のスレッドを一時停止し (現在のスレッドをブロックし)、指定されたgroupタスクが完了するのを待ってから実行を続行するために使用されます。
dispatch_group_waiwait に tを付けないと、 groupin の処理自体が非同期であるため、groupin の処理が完了する前に他のタスクが実行されてしまいます。
- (void)groupWait {
dispatch_queue_t queue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0);
dispatch_group_t group = dispatch_group_create();
dispatch_group_async(group, queue, ^{
NSLog(@"blk0");
});
dispatch_group_async(group, queue, ^{
NSLog(@"blk1");
});
dispatch_group_async(group, queue, ^{
NSLog(@"blk2");
});
NSLog(@"YES!!");
// dispatch_group_wait(group, DISPATCH_TIME_FOREVER);
}
結果:

グループ内の処理が完了する前に、print YES!! オペレーションが実行されたことがわかります。
そしてこのように:
- (void)groupWait {
dispatch_queue_t queue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0);
dispatch_group_t group = dispatch_group_create();
dispatch_group_async(group, queue, ^{
NSLog(@"blk0");
});
dispatch_group_async(group, queue, ^{
NSLog(@"blk1");
});
dispatch_group_async(group, queue, ^{
NSLog(@"blk2");
});
dispatch_group_wait(group, DISPATCH_TIME_FOREVER);
NSLog(@"YES!!");
}
結果:

groupのすべての処理が完了した後に印刷YES!!操作が実行されることがわかります。
dispatch_group_wait関連するコード実行の出力結果からわかります。すべてのタスクが完了した後、dispatch_group_wait後続の操作が実行されます。ただし、使用するとdispatch_group_wait現在のスレッドがブロックされます。
ディスパッチグループ入力、ディスパッチグループ退出
dispatch_group_enterタスクが追加され、未完了タスクの数 + 1 にgroup等しい 1 回実行されることをマークします。タスクが終了することをマークし、未完了タスクの数 - 1に等しい 1 回実行されます。未完了タスクの数in は 0 です。ブロックが解除されるときのみ、に追加されたタスクが実行されます。group
dispatch_group_leavegroupgroupgroupdispatch_group_waitdispatch_group_notifydispatch_group_enterdispatch_group_leavegroup
- (void)groupWithEnterAndLeave {
// 首先 需要创建一个线程组
dispatch_group_t group = dispatch_group_create();
// 任务1
dispatch_group_enter(group);
void (^blockFirst)(int) = ^(int a){
NSLog(@"任务%d完成!", a);
dispatch_group_leave(group);
};
blockFirst(1);
// 任务2
dispatch_group_enter(group);
void (^blockSecond)(int) = ^(int a){
NSLog(@"任务%d完成!", a);
dispatch_group_leave(group);
};
blockSecond(2);
// 全部完成
dispatch_group_notify(group, dispatch_get_main_queue(), ^(){
NSLog(@"全部完成");
});
}
結果:

タスク 1 とタスク 2 が完了した後でのみ、完了したすべてのタスクが実行されることがわかります。
関連するコードの実行結果からわかります。のタスクは、すべてのタスクが完了した後にのみ実行されますdispatch_group_enter。ここでの組み合わせは実際には と同等です。dispatch_group_leavedispatch_group_notifydispatch_group_enter、dispatch_group_leavedispatch_group_async
ただし、dispatch_group_enterと はdispatch_group_leaveペアで使用する必要があります。
dispatch_group_leaveへの呼び出しよりも への呼び出しの方が多い場合dispatch_group_enter、プログラムはそうしますcrash。
GCD セマフォ:dispatch_semaphore
GCDのセマフォは、Dispatch Semaphoreカウントを保持する信号を指します。高速道路の料金所の手すりと同じです。通れる場合は手すりを開け、通れない場合は手すりを閉めます。ではDispatch Semaphore、この関数を完了するために count が使用されます。count が 0 未満の場合は、待機する必要があり、パスできません。カウントが 0 または 0 より大きい場合、待ち時間なしで通過できます。カウントが 0 より大きく、カウントが 1 減少する場合、待つ必要はなく通過できます。Dispatch Semaphore次の 3 つの方法が提供されています。
dispatch_semaphore_create: を作成しSemaphore、信号の総量を初期化します。dispatch_semaphore_signal: 信号を送信し、信号の合計量を加算します1。dispatch_semaphore_wait: セマフォの総量を 1 減らすことができます。セマフォの総量が 0 未満の場合は待ち続けます (スレッドをブロックします)。それ以外の場合は正常に実行できます。
注: セマフォを使用する前提は、どのスレッドを待機する (ブロックする) 必要があるか、どのスレッドを実行し続けたいかを判断してから、セマフォを使用することです。
Dispatch Semaphore実際の開発では主に以下の用途に使用されます。
- スレッドの同期を維持し、非同期実行タスクを同期実行タスクに変換します。
- スレッドの安全性を確保し、スレッドをロックします。
Dispatch Semaphoreスレッドの同期
開発中に、時間のかかるタスクを非同期で実行し、非同期実行の結果を使用して追加の操作を実行する必要が生じることがあります。つまり、非同期実行タスクを同期実行タスクに変換することに相当します。
次に、スレッド同期を使用して、Dispatch Semaphoreワンステップ実行タスクを同期実行タスクに変換します。
- (void)semaphoreSync {
NSLog(@"currentThread---%@", [NSThread currentThread]); // 打印当前线程
NSLog(@"semaphore---begin");
dispatch_queue_t queue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0);
dispatch_semaphore_t semaphore = dispatch_semaphore_create(0);
__block int number = 0;
dispatch_async(queue, ^{
// 追加任务 1
[NSThread sleepForTimeInterval:2]; // 模拟耗时操作
NSLog(@"1---%@", [NSThread currentThread]); // 打印当前线程
number = 100;
dispatch_semaphore_signal(semaphore);
});
dispatch_semaphore_wait(semaphore, DISPATCH_TIME_FOREVER);
NSLog(@"semaphore---end,number = %d", number);
}
結果:

semaphore---end実行number = 100;後に出力されることがわかります。そして出力結果はnumber100になります。全体の実行シーケンスは次のとおりです。
semaphore最初に作成されたとき、カウントは 0 です。
非同期実行後、タスク 1 は待機せずにキューに追加され、dispatch_semaphore_waitメソッドが実行されます (semaphoreマイナス 1)。この時点でsemaphore == -1、現在のスレッドは待機状態になります (以下の内容は非同期です)。実行すると、追加したタスク 1 のみが実行されます)、dispatch_semaphore_signal操作によってセマフォのカウントが ``>=0 になるまで、スレッドは通常の動作を再開しません。
その後、非同期タスク 1 が実行を開始します。タスク 1 の実行後dispatch_semaphore_signal、合計セマフォが 1 増加します。このときsemaphore == 0、ブロックされていたスレッド (メイン スレッド) が実行を再開し、
最終的に出力されますsemaphore---end,number = 100
。これにより、スレッドの同期が達成され、非同期実行タスクが同期実行タスクに変換されます。
ディスパッチ セマフォのスレッド セーフティとスレッド同期 (スレッドのロック)
スレッド セーフ: コードが配置されているプロセスで複数のスレッドが同時に実行されている場合、これらのスレッドがこのコードを同時に実行する可能性があります。各実行の結果がシングルスレッド実行の結果と同じであり、他の変数の値が予想どおり同じである場合、それはスレッドセーフです。
各スレッドにグローバル変数と静的変数の読み取り操作のみがあり、書き込み操作がない場合、一般に、このグローバル変数はスレッドセーフです。複数のスレッドが同時に書き込み操作 (変数の変更) を実行する場合、通常、スレッドの同期を考慮してください。そうしないと、スレッドの安全性が影響を受ける可能性があります。
スレッドの同期: スレッド A とスレッド B が連携して動作していることがわかります。スレッド A がある程度実行されると、スレッド B の特定の結果に依存するため、スレッド B を停止して実行するように通知し、スレッド B は指示どおりに実行します。を実行し、その結果をスレッド A に渡し、スレッド A は操作を続行します。
簡単な例は、2 人が一緒にチャットしている場合です。不明瞭な聴覚(操作の競合)を避けるために、2 人が同時に話すことはできません。1 人が話し終わるまで待って (1 つのスレッドが操作を終了します)、もう 1 人が話し始めます (別のスレッドが操作を再開します)。
次に、電車の切符の販売方法をシミュレートし、NSThread スレッド セーフを実装し、スレッド同期の問題を解決します (サンプルは Big Brother Blog から借用しました)。
シーン: 合計 50 枚の鉄道切符があり、鉄道切符の販売窓口は 2 つあります。1 つは北京の鉄道の切符販売窓口、もう 1 つは上海の鉄道の切符販売窓口です。鉄道チケットは在庫がなくなり次第、両方の窓口で同時に販売します。
スレッドセーフではありません (セマフォを使用しません)
まず、スレッド セーフを考慮していないコードを見てみましょう。
@interface ViewController ()
@property (nonatomic, assign) NSInteger ticketSurplusCount;
@end
/**
* 非线程安全:不使用 semaphore
* 初始化火车票数量、卖票窗口(非线程安全)、并开始卖票
*/
- (void)initTicketStatusNotSafe {
NSLog(@"currentThread---%@",[NSThread currentThread]); // 打印当前线程
NSLog(@"semaphore---begin");
self.ticketSurplusCount = 50;
// queue1 代表北京火车票售卖窗口
dispatch_queue_t queue1 = dispatch_queue_create("net.bujige.testQueue1", DISPATCH_QUEUE_SERIAL);
// queue2 代表上海火车票售卖窗口
dispatch_queue_t queue2 = dispatch_queue_create("net.bujige.testQueue2", DISPATCH_QUEUE_SERIAL);
__weak typeof(self) weakSelf = self;
dispatch_async(queue1, ^{
[weakSelf saleTicketNotSafe];
});
dispatch_async(queue2, ^{
[weakSelf saleTicketNotSafe];
});
}
/**
* 售卖火车票(非线程安全)
*/
- (void)saleTicketNotSafe {
while (1) {
if (self.ticketSurplusCount > 0) {
// 如果还有票,继续售卖
self.ticketSurplusCount--;
NSLog(@"%@", [NSString stringWithFormat:@"剩余票数:%ld 窗口:%@", self.ticketSurplusCount, [NSThread currentThread]]);
[NSThread sleepForTimeInterval:0.2];
} else {
// 如果已卖完,关闭售票窗口
NSLog(@"所有火车票均已售完");
break;
}
}
}
結果:

スレッドの安全性を考慮せず、 を使用しないとsemaphore、得られる票の数が無秩序になり、同じチケットが 2 回販売される可能性があり、これは明らかにニーズを満たしていないため、スレッドの安全性の問題を考慮する必要があります。
スレッド セーフティ (セマフォ ロックを使用)
スレッドセーフなコードを考慮してください。
@interface ViewController ()
@property (nonatomic, assign) NSInteger ticketSurplusCount;
@end
//创建一个全局信号量
dispatch_semaphore_t semaphoreLock;
/**
* 线程安全:使用 semaphore 加锁
* 初始化火车票数量、卖票窗口(线程安全)、并开始卖票
*/
- (void)initTicketStatusSafe {
NSLog(@"currentThread---%@",[NSThread currentThread]); // 打印当前线程
NSLog(@"semaphore---begin");
semaphoreLock = dispatch_semaphore_create(1);
self.ticketSurplusCount = 50;
// queue1 代表北京火车票售卖窗口
dispatch_queue_t queue1 = dispatch_queue_create("net.bujige.testQueue1", DISPATCH_QUEUE_SERIAL);
// queue2 代表上海火车票售卖窗口
dispatch_queue_t queue2 = dispatch_queue_create("net.bujige.testQueue2", DISPATCH_QUEUE_SERIAL);
__weak typeof(self) weakSelf = self;
dispatch_async(queue1, ^{
[weakSelf saleTicketSafe];
});
dispatch_async(queue2, ^{
[weakSelf saleTicketSafe];
});
}
/**
* 售卖火车票(线程安全)
*/
- (void)saleTicketSafe {
while (1) {
// 相当于加锁
dispatch_semaphore_wait(semaphoreLock, DISPATCH_TIME_FOREVER);
if (self.ticketSurplusCount > 0) {
// 如果还有票,继续售卖
self.ticketSurplusCount--;
NSLog(@"%@", [NSString stringWithFormat:@"剩余票数:%ld 窗口:%@", self.ticketSurplusCount, [NSThread currentThread]]);
[NSThread sleepForTimeInterval:0.2];
} else {
// 如果已卖完,关闭售票窗口
NSLog(@"所有火车票均已售完");
// 相当于解锁
dispatch_semaphore_signal(semaphoreLock);
break;
}
// 相当于解锁
dispatch_semaphore_signal(semaphoreLock);
}
}
結果:

アイデア: ここでは、このメカニズムを使用しますdispatch_semaphore。チケットを購入する操作は毎回非同期で実行されます。ただし、最初のチケットがまだ販売されておらず、2 番目のチケットの販売が開始されている場合、操作によってセマフォのカウントが発生しますdispatch_semaphore_wait。 - 1. スレッドは待機状態に入り、最初のチケットが販売された後の操作を待機しますdispatch_semaphore_signal。この操作によりセマフォ数 = 1 になり、スレッドが書き換えられて通常どおり実行を開始し、チケット販売の通常の処理が開始されます。 2 番目のチケット同様に、各チケット販売は、チケット販売プロセス全体の正確性を保証するために保護されます。
dispatch_semaphoreスレッドの安全性を考慮してこのメカニズムを使用した後、得られた投票数は正しく、混乱がないことがわかります。複数スレッドの同期の問題も解決しました。