Python サードパーティ ライブラリの概要
知識ポイント
- サードパーティライブラリの入手とインストール
- スクリプト プログラムを実行可能プログラムに変換するサードパーティ ライブラリ: PyInstaller ライブラリ (必須)
- サードパーティ ライブラリ: jieba ライブラリ (必須)、wordcloud ライブラリ (オプション)
ナレッジマップ
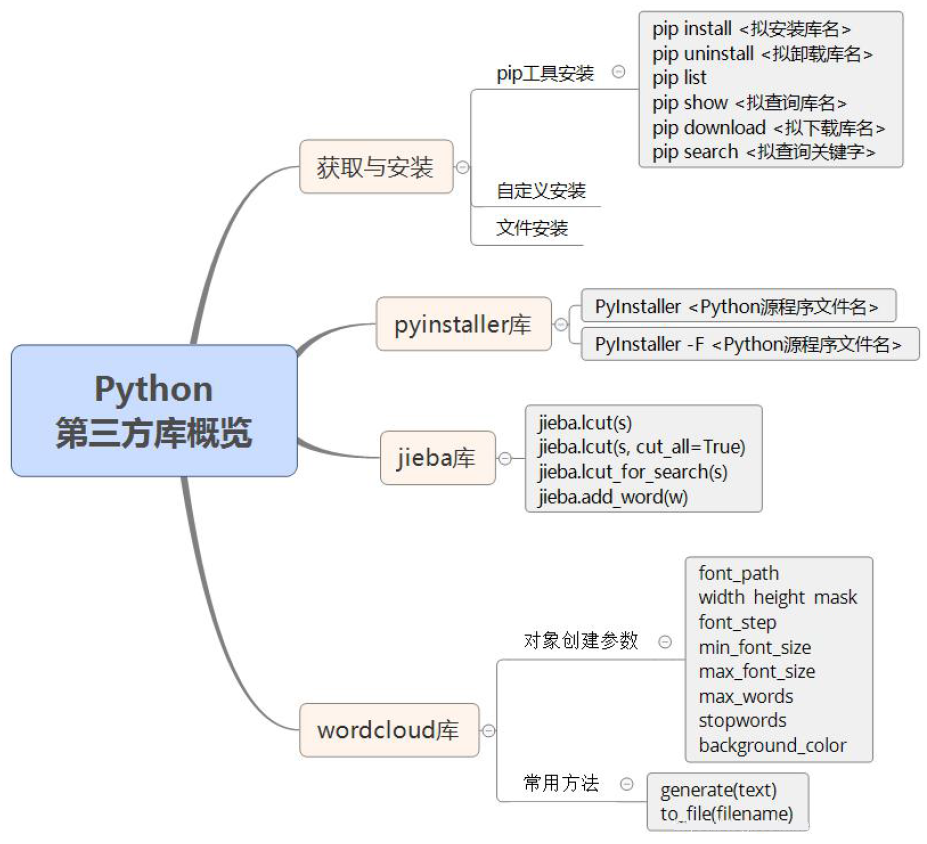
1. Python サードパーティ ライブラリの入手とインストール
Python サードパーティ ライブラリには、インストールの柔軟性と容易さに応じて、pip ツールのインストール、カスタム インストール、ファイル インストールの 3 つの方法があります。
1.1 pipツールのインストール
- Python サードパーティ ライブラリをインストールする最も一般的に使用され効率的な方法は、pip ツールを使用することです。pip は、Python によって公式に提供および保守されているオンラインのサードパーティ ライブラリ インストール ツールです。
pip install <インストールするライブラリの名前>
:\>pip install pygame
...
Installing collected packages: pygame
Successfully installed pygame-1.9.2b1
- pip は Python サードパーティ ライブラリの最も重要なインストール方法であり、サードパーティ ライブラリの 90% 以上をインストールできます。ただし、一部のサードパーティ製ライブラリは pip で一時的にインストールできないため、現時点では他のインストール方法が必要です。
- pip ツールはオペレーティング システムにも関連しています。Mac OS X や Linux などのオペレーティング システムでは、pip ツールはほぼすべての Python サードパーティ ライブラリをインストールできます。Windows オペレーティング システムでは、一部のサードパーティ ライブラリは引き続きインストールする必要があります。他の方法でインストールされます。
1.2 カスタムインストール
- カスタム インストールとは、サードパーティ ライブラリによって提供される手順と方法に従ってインストールすることを指します。サードパーティのライブラリには、ライブラリのコードとドキュメントを保守するためのホームページがあります。科学計算用の numpy を例に挙げると、開発者が管理する公式ホームページは次のとおりです。
http://www.numpy.org/
- 次のように Web ページを参照してダウンロード リンクを見つけます。
http://www.scipy.org/scipylib/download.html
- 次に、指示に従ってインストールします。
1.3 ファイルのインストール
- このようなサードパーティ ライブラリのインストールの問題を解決するために、カリフォルニア大学アーバイン校は、Python ユーザーが Windows で直接インストールできるサードパーティ ライブラリ ファイルを入手できるようにするためのページを提供しています。リンク アドレスは次のとおりです。
http://www.lfd.uci.edu/~gohlke/pythonlibs/
- ここではscipyを例に挙げますが、まず上記ページからscipyライブラリに該当するコンテンツを探します。ダウンロードする .whl ファイルを選択します。ここでは、Python 3.5 バージョンのインタープリタと 32 ビット システムに適した対応するファイルを選択します: scipy-0.17.1-cp35-cp35m-win32.whl。ファイルを D:\pycodes にダウンロードします。ディレクトリ。
- 次に、pip コマンドを使用してファイルをインストールします。
:\>pip install D:\pycodes\scipy-0.17.1-cp35-cp35m-win32.whl
Processing d:\pycodes\scipy-0.17.1-cp35-cp35m-win32.whl
Installing collected packages: scipy
Successfully installed scipy-0.17.1
1.4 Python サードパーティ ライブラリの入手とインストール
- 上記 3 つのインストール方法では、通常、pip ツールを使用してインストールすることをお勧めしますが、インストールに失敗した場合は、カスタム インストールまたはファイル インストールを選択してください。また、ネットワークを使用せずに Python サードパーティ ライブラリをインストールする必要がある場合は、ファイル インストール方法を直接使用してください。このうち .whl ファイルは、ネットワーク状況に応じて pip download コマンドで取得できます。
1.5 pip ツールの使用法
- pip -h を実行すると、pip の一般的に使用されるサブコマンドがリストされます。
:\>pip -h
Usage:
pip <command> [options]
Commands:
install Install packages.
download Download packages.
uninstall Uninstall packages.
freeze Output installed packages in requirements format.
list List installed packages.
show Show information about installed packages.
search Search PyPI for packages.
wheel Build wheels from your requirements.
hash Compute hashes of package archives.
completion A helper command used for command completion
help Show help for commands.
- pip は、install、download、uninstall、list、list、search などの一連のインストールおよびメンテナンスのサブコマンドをサポートします。
- pip の uninstall サブコマンドは、インストールされているサードパーティ ライブラリをアンインストールできます。形式は次のとおりです。
pip uninstall <アンインストールするライブラリの名前>
- pip の list サブコマンドは、現在のシステムにインストールされているサードパーティ ライブラリを一覧表示できます。形式は次のとおりです。
ピップリスト
- pip の show サブコマンドは、インストールされているライブラリの詳細情報を次の形式で一覧表示します。
pip show <クエリ対象のライブラリの名前>
- pip の download サブコマンドは、サードパーティ ライブラリのインストール パッケージをダウンロードできますが、インストールはできません。形式は次のとおりです。
ピップダウンロード
- pip の search サブコマンドは、オンラインの概要内のライブラリ名またはキーワードを検索できます。形式は次のとおりです。
pip search <検索するキーワード>
- インストーラーという単語を含むライブラリのクエリを例にとると、実行結果は次のようになります。
:\>pip search installer
winbrew (1.1.7) - Native package installer for Windows
pygitflow-avh (1.2.0) - Pythonic Installer for Git Flow
(AVH Edition).
notouch (0.3) - Notouch Physical Machine
Installer Automation Service
2. PyInstaller ライブラリの概要
- PyInstaller は、Windows、Linux、Mac OS X などのオペレーティング システムで Python ソース ファイルを直接実行可能な実行可能ファイルにパッケージ化できる、非常に便利なサードパーティの Python ライブラリです。
- ソースファイルをパッケージ化することで、Python がインストールされていない環境でも Python プログラムを実行したり、独立したファイルとして簡単に配布・管理したりできます。
:\>pip install PyInstaller
3. PyInstaller ライブラリとプログラムのパッケージ化
- PyInstaller ライブラリを使用して Python ソース ファイルをパッケージ化するのは非常に簡単で、使用方法は次のとおりです。
:>PyInstaller <Python ソースプログラムファイル名>
- 実行後、ソースファイルが存在するディレクトリに dist と build の 2 つのフォルダーが生成されます。最終的なパッケージャーは、ソース ファイルと同じ名前のディレクトリ内の dist 内にあります。
- 次のように、-F パラメーターを使用して、Python ソース ファイルから独立した実行可能ファイルを生成できます。
:>PyInstaller -F <Python ソースプログラムファイル名>
:\>PyInstaller -F SnowView.py
- 実行後、依存ライブラリを持たない SnowView.exe ファイルが dist ディレクトリに作成され、実行すると雪のエフェクトが表示されます。
- PyInstaller にはいくつかの共通パラメータがあります
| パラメータ | 関数 |
|---|---|
| -h、--ヘルプ | ヘルプを見る |
| -クリーン | パッケージ化プロセス中に一時ファイルをクリーンアップする |
| -D、--onedir | デフォルト値、dist ディレクトリを生成 |
| -F、--onefile | dist フォルダーには独立したパッケージング ファイルのみが生成されます |
| -i <アイコンファイル名.ico> | パッケージャーが使用するアイコン(アイコン)ファイルを指定します |
4. jiebaライブラリの概要
- 中国語テキストの単語はスペースや句読点で区切られていないため、中国語および類似の言語には重要な「単語の分割」の問題が存在します。
- jieba (「stutter」) は、Python の重要なサードパーティの中国語単語分割関数ライブラリです。
:\>pip install jieba
- jieba library の単語分割原理は、中国語語彙データベースを使用して、分割対象のコンテンツと単語分割語彙データベースを比較し、グラフ構造と動的計画法を通じて最も確率の高い語句を見つけます。jieba は、単語の分割に加えて、カスタム中国語単語を追加する機能も提供します。
- jieba ライブラリは 3 つの単語分割モードをサポートしています: 精密モード (文を最も正確に切り出し、テキスト分析に適しています)、フル モード (文内の単語に形成できるすべての単語をスキャンします。これは非常に高速ですが)あいまいさを解決できません。検索エンジン モードは、正確なモードに基づいて長い単語を再分割して再現率を向上させ、検索エンジンの単語の分割に適しています。
- 中国語の単語の分割の場合、jieba ライブラリに必要なコードは 1 行だけです。
>>>import jieba
>>>jieba.lcut("全国计算机等级考试")
Building prefix dict from the default dictionary ...
Loading model from cache C:\AppData\Local\Temp\jieba.cache
Loading model cost 1.001 seconds.
Prefix dict has been built succesfully.
['全国', '计算机', '等级', '考试']
5. jieba ライブラリと中国語の単語の分割
- jieba.lcut(s) は、最も一般的に使用される中国語単語分割関数であり、精密モードで使用されます。つまり、文字列を等しい中国語句に分割し、返される結果はリスト タイプです。
>>>import jieba
>>>ls = jieba.lcut("全国计算机等级考试Python科目")
>>>print(ls)
['全国', '计算机', '等级', '考试', 'Python', '科目']
- jieba.lcut(s, Cut_all = True) はフル モードで使用されます。つまり、文字列のすべての可能な単語セグメントがリストされ、返される結果は最大の冗長性を備えたリスト タイプです。
>>>import jieba
>>>ls = jieba.lcut("全国计算机等级考试Python科目", cut_all=True)
>>>print(ls)
['全国', '国计', '计算', '计算机', '算机', '等级', '考试',
'Python', '科目']
- jieba.lcut_for_search(s) は検索エンジン モードを返します。最初に正確なモードが実行され、次に長い単語がさらに分割されて最終結果が得られます。
>>>import jieba
>>>ls = jieba.lcut_for_search("全国计算机等级考试Python科目")
>>>print(ls)
['全国', '计算', '算机', '计算机', '等级', '考试', 'Python', '科
目']
- 検索エンジン モードは短い単語を優先して検索します。この方法にはある程度の冗長性がありますが、その冗長性はフル モードよりも低くなります。
- 冗長性を生じさせずにテキストを正確に分割したい場合は、正確モードである jieba.lcut(s) 関数を選択することしかできません。テキストをより正確に分割し、可能な分割結果を見逃さないようにしたい場合は、フル モードを選択してください。使い方がわからない場合は、検索エンジンモードを使用できます。
- jieba.add_word() 関数は、名前が示すように、新しい単語を jieba 語彙に追加するために使用されます。
>>>import jieba
>>>jieba.add_word("Python科目")
>>>ls = jieba.lcut("全国计算机等级考试Python科目")
>>>print(ls)
['全国', '计算机', '等级', '考试', 'Python科目']
6. Wordcloud ライブラリの概要
- ワード クラウドは、単語を基本単位として使用し、テキスト内での単語の出現頻度に応じてさまざまなサイズでデザインされ、さまざまな視覚効果を生み出し、「キーワード クラウド」または「キーワード レンダリング」を形成し、読者がテキストだけで理解できるようにします。 「一目」の目的。
- wordcloud ライブラリは、テキストに基づいてワード クラウドを生成するために特別に使用される Python サードパーティ ライブラリであり、非常に一般的で興味深いものです。
- Wordcloud ライブラリをインストールするには、Windows cmd コマンド ラインで次のコマンドを使用します。
:\>pip install wordcloud
- wordcloud ライブラリの使用方法は非常に簡単で、文字列を例にとります。このうち 3 行目のワード クラウドの生成に必要な記述は 1 行だけで、ワード クラウドは画像として保存できます。
>>>from wordcloud import WordCloud
>>>txt='I like python. I am learning python'
>>>wordcloud = WordCloud().generate(txt)
>>>wordcloud.to_file('testcloud.png')
<wordcloud.wordcloud.WordCloud object at 0x000001583E26D208>
7. ワードクラウドライブラリとビジュアルワードクラウド
- ワードクラウドを生成するとき、ワードクラウドはデフォルトでスペースまたは句読点を区切り文字として使用してターゲットテキストを分割します。中国語テキストの場合、単語分割処理はユーザーが完了する必要があります。一般的な手順は、最初にテキストをセグメント化し、次にスペースで結合してから、wordcloud ライブラリ関数を呼び出すことです。
import jieba
from wordcloud import WordCloud
txt = '程序设计语言是计算机能够理解和识别用户操作意图的一种交互体系,它按
照特定规则组织计算机指令,使计算机能够自动进行各种运算处理。'
words = jieba.lcut(txt) # 精确分词
newtxt = ' '.join(words) # 空格拼接
wordcloud = WordCloud(font_path="msyh.ttc").generate(newtxt)
wordcloud.to_file('词云中文例子图.png') # 保存图片
- WordCloud ライブラリの中核は WordColoud クラスであり、すべての関数は WordCloud クラスにカプセル化されています。これを使用する場合は、WordColoud クラスのオブジェクトをインスタンス化し、そのgenerate(text) メソッドを呼び出してテキストをワード クラウドに変換する必要があります。
- WordCloud オブジェクト作成の共通パラメータ
| パラメータ | 関数 |
|---|---|
| フォントパス | フォント ファイルへのフルパスを指定します。デフォルトはなしです。 |
| 幅 | 画像の幅を生成します、デフォルトは 400 ピクセルです |
| 身長 | 画像の高さを生成します、デフォルトは 200 ピクセルです |
| マスク | ワード クラウドの形状、デフォルトはなし、つまり正方形のグラフ |
| min_font_size | ワード クラウド内の最小のフォント サイズ、デフォルト サイズ 4 |
| フォントステップ | フォント サイズのステップ間隔、デフォルトは 1 |
| min_font_size | ワード クラウド内の最大のフォント サイズ、デフォルトはなし、高さに応じて自動的に調整されます |
| max_words | ワード クラウド チャート内の最大単語数、デフォルトは 200 |
| ストップワード | 除外単語リスト、除外単語はワードクラウドに表示されません |
| 背景色 | 画像の背景色、デフォルトは黒 |
- WordCloudクラスの共通メソッド
| 方法 | 関数 |
|---|---|
| 生成(テキスト) | テキストテキストからワードクラウドを生成 |
| to_file(ファイル名) | ワード クラウドを filename という名前のファイルとして保存します |
- 以下では、不思議の国のアリスを例として、パラメーターとメソッドの使用法を示します。

from wordcloud import WordCloud
from scipy.misc import imread
mask = imread('AliceMask.png')
with open('AliceInWonderland.txt', 'r', encoding='utf-8') as file:
text = file.read()
wordcloud = WordCloud(background_color="white", \
width=800, \
height=600, \
max_words=200, \
max_font_size=80, \
mask = mask, \
).generate(text)
# 保存图片
wordcloud.to_file('AliceInWonderland.png')
- このうち、scipy.misc import imread の行は、AliceMask.png を nd-array 型として読み取るために使用され、後でマスク パラメーターに渡されて使用されます。(このライブラリ関数は scipy ライブラリに属しており、pip は wordcloud ライブラリをインストールするときに依存ライブラリを自動的にインストールします。)
8. 分析例:「紅楼夢」に登場する人物のワードクラウド
- 『紅楼夢』は数百人の個性豊かなキャラクターが登場する大作です。この古典的な作品を読むたびに、私は次の質問について考えます。この本の中で最も多く登場する登場人物は誰ですか? Python を使用してこの質問に答えてみましょう。
- 文字の出現統計には語彙統計が含まれます。中国語の記事では、単語頻度統計を実行するために単語の分割が必要であり、それには jieba ライブラリの使用が必要です。
# CalStoryOfStone.py
import jieba
f = open("红楼梦.txt", "r")
txt = f.read()
f.close()
words = jieba.lcut(t)
counts = {}
for word in words:
if len(word) == 1: #排除单个字符的分词结果
continue
else:
counts[word] = counts.get(word,0) + 1
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)
for i in range(15):
word, count = items[i]
print ("{0:<10}{1:>5}".format(word, count))
- まずランキング上位15語を出力し、プログラムを実行すると出力結果は以下のようになります。
>>>
宝玉 3748
什么 1613
一个 1451
贾母 1228
我们 1221
那里 1174
凤姐 1100
王夫人 1011
你们 1009
如今 999
说道 973
知道 967
老太太 966
起来 949
姑娘 941
- 英語の単語頻度統計と同様に、「what」や「one」などの無関係な単語を除外する必要があります。
# CalStoexcludes = {"什么","一个","我们","那里","你们","如今", \
"说道","知道","老太太","起来","姑娘","这里", \
"出来","他们","众人","自己","一面","太太", \
"只见","怎么","奶奶","两个","没有","不是", \
"不知","这个","听见"}
for word in excludes:
del(counts[word])
- 上位 5 単語を出力します。プログラムを実行すると、出力結果は次のようになります。
>>>
宝玉 3748
贾母 1228
凤姐 1100
王夫人 1011
贾琏 670
- 結果のワードクラウド効果と組み合わせて、ワードクラウドライブラリを使用して文字の出現統計をワードクラウドの形式で表示します
- 単語の分割には jieba ライブラリを使用します。違いは、単語の分割後の結果がスペースを含むテキストに再結合され、ワードクラウドによってさらに処理されることです。無関係な単語の除外は、ワードクラウドのストップワード パラメーターを使用して完了することもできます。
import jieba
from wordcloud import WordCloud
excludes = {"什么","一个","我们","那里","你们","如今", \
"说道","知道","老太太","起来","姑娘","这里", \
"出来","他们","众人","自己","一面","太太", \
"只见","怎么","奶奶","两个","没有","不是", \
"不知","这个","听见"}
f = open("红楼梦.txt", "r")
txt = f.read()
f.close()
words = jieba.lcut(txt)
newtxt = ' '.join(words)
wordcloud = WordCloud(background_color="white", \
width=800, \
height=600, \
font_path="msyh.ttc", \
max_words=200, \
max_font_size=80, \
stopwords = excludes, \
).generate(newtxt)
wordcloud.to_file('红楼梦基本词云.png')

- 出力結果には関係のない単語が多く、文字が鮮明でないことがわかります。これは、単語分割を直接使用しても期待される結果が得られないことを示しています。
- 文字の出現に関する予備的な統計結果と組み合わせると、max_words=200 パラメータを max_words=5 に変更して、出現数が最も多い上位 5 文字で構成されるワード クラウドを取得できます。

- ワードクラウド ライブラリには基本的な統計機能と並べ替え機能があり、単語の分割、統合、除外などの機能を使用できることがわかります。ワード クラウド設定パラメータを適切に調整すると、さまざまな視覚化効果が得られます。テキストでは良い結果が得られません。
まとめ
このトピックでは、Python サードパーティ ライブラリ プログラミングを使用したモジュール プログラミングのアイデアとコンピューティング エコロジーの理解と応用を紹介し、さらに jieba 語彙ライブラリを使用して中国語文書をセグメント化し、文書の単語頻度をさらにカウントする方法について説明します。
このトピックでは主に Python サードパーティ ライブラリに焦点を当て、サードパーティ ライブラリの入手方法とインストール方法を説明し、PyInstaller プログラム
パッケージ化機能、jieba 中国語単語分割機能、wordcloud を含む 3 つの特定のサードパーティ ライブラリの使用方法を詳しく紹介します。ワードクラウド可視化機能。「紅楼夢」のキャラクターの出現統計とワード クラウド効果の表示例を通じて、読者がこれら 3 つの Python サードパーティ ライブラリの具体的な使用方法を習得できるようにします。
パラメータ0をmax_words=5に変更し、出現回数の多い上位5文字からなるワードクラウドを取得します。
【外部リンク画像転送…(img-gBjtlgN4-1693102662329)】
- ワードクラウド ライブラリには基本的な統計機能と並べ替え機能があり、単語の分割、統合、除外などの機能を使用できることがわかります。ワード クラウド設定パラメータを適切に調整すると、さまざまな視覚化効果が得られます。テキストでは良い結果が得られません。
まとめ
このトピックでは、Python サードパーティ ライブラリ プログラミングを使用したモジュール プログラミングのアイデアとコンピューティング エコロジーの理解と応用を紹介し、さらに jieba 語彙ライブラリを使用して中国語文書をセグメント化し、文書の単語頻度をさらにカウントする方法について説明します。
このトピックでは主に Python サードパーティ ライブラリに焦点を当て、サードパーティ ライブラリの入手方法とインストール方法を説明し、PyInstaller プログラム
パッケージ化機能、jieba 中国語単語分割機能、wordcloud を含む 3 つの特定のサードパーティ ライブラリの使用方法を詳しく紹介します。ワードクラウド可視化機能。「紅楼夢」のキャラクターの出現統計とワード クラウド効果の表示例を通じて、読者がこれら 3 つの Python サードパーティ ライブラリの具体的な使用方法を習得できるようにします。
古書には中国や海外の有名な古典がたくさんありますが、「紅楼夢」以外に気になるコンテンツはありますか?単語頻度統計、文字統計、ワードクラウド効果、組み合わせパンチを使ってみよう!