目次
ElasticSearch のインストールと導入
Elastic Stack の概要
Elastic Stack を聞いたことがない人は、ELK について聞いたことがあるはずです。実際、ELK は、Elasticsearch、Logstash、Kibana という 3 つのソフトウェアの略称です。開発の過程で、新しいメンバー Beats が加わりました。 Elastic Stack が形成されました。したがって、ELK は古い名前であり、Elastic Stack は新しい名前です。

Elastic Stack テクノロジー スタック全体には次のものが含まれます。
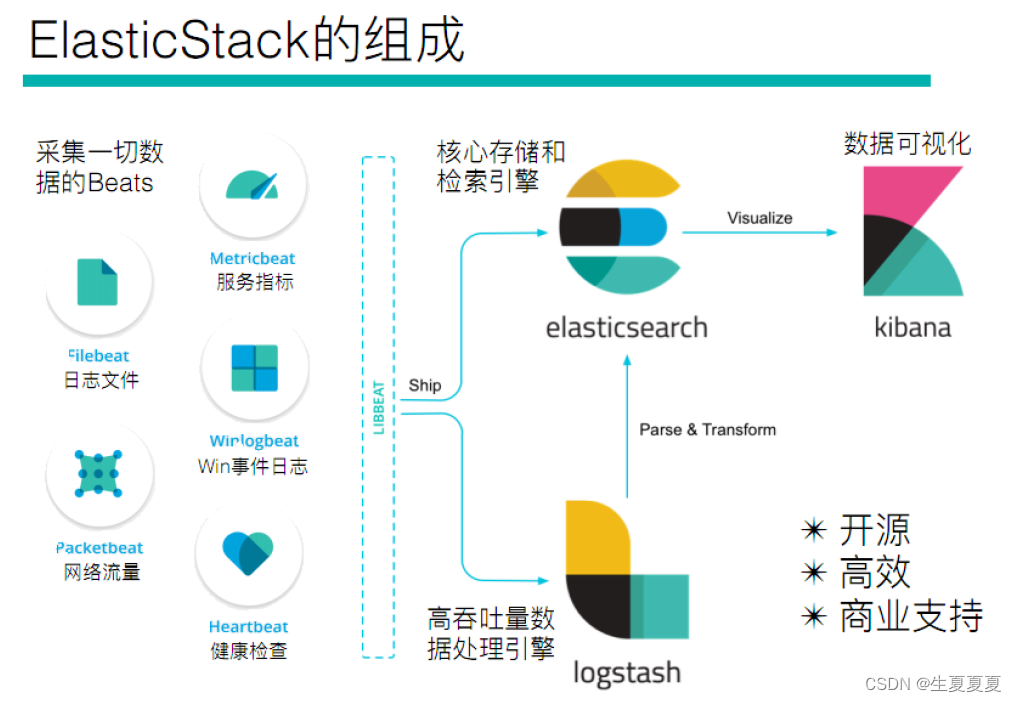
エラスティックサーチ
Java ベースのオープンソースの分散型検索エンジンで、分散型、ゼロ構成、自動検出、自動インデックス シャーディング、インデックス コピー メカニズム、Restful スタイル インターフェイス、複数のデータ ソース、自動検索読み込みなどの機能が含まれます。
ログスタッシュ
Logstash は Java に基づいており、ログを収集、分析、保存するためのオープンソース ツールです。
キバナ
Kibana は、nodejs をベースにしており、オープン ソースの無料ツールでもあり、
重要なデータ ログを要約、分析、検索できる Logstash および ElasticSearch 用のログ分析に適した Web インターフェイスを提供します。
ビート
Beats は、システム監視データを収集する Elastic 社のオープンソース エージェントです。監視対象サーバー上でクライアントとして実行されるデータ コレクターの総称です。Elasticsearch にデータを直接送信したり、Logstash 経由で Elasticsearch に送信したりすることができます。後続のデータ分析アクティビティを実行します。
ビートは次のもので構成されます。
- Packetbeat: ネットワーク トラフィック情報を監視および収集するためのネットワーク パケット アナライザーです。
- Filebeat: サーバーのログ ファイルを監視および収集するために使用されます。
- Metricbeat: Apache、MySQL、Nginx、その他のサービスを監視および収集できる外部システムの監視指標情報を定期的に取得できます。
実際にデータを収集できるのはBeatsとLogstashの両方ですが、現在はBeatsでデータ収集を行い、Logstashでデータの分割や加工を行うという方法が主流であり、Beatsが存在しない初期の頃はLogstashでデータ収集を行っていました。
ElasticSearch の使用を開始する
導入
ElasticSearch は、Lucene ベースの検索サーバーです。RESTful Web インターフェイスに基づいた分散マルチユーザー対応の全文検索エンジンを提供します。Java で開発され、Apache ライセンスの条件に基づいてオープン ソースとしてリリースされた Elasticsearch は、人気のあるエンタープライズ レベルの検索エンジンです。クラウド コンピューティングで使用するように設計されており、リアルタイム検索を実現でき、安定性、信頼性、高速性があり、インストールと使用が簡単です。
ElasticSearch は Elastic Stack の中核であり、さまざまな新たなユースケースを解決できる分散型 RESTful 検索およびデータ分析エンジンです。
ダウンロード
公式 Web サイトにアクセスしてダウンロードします: Elastic
対応するバージョンのデータを選択します。ここでは Linux を使用してインストールしているため、最初に ElasticSearch の Linux インストール パッケージをダウンロードします。
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.8.0-linux-x86_64.tar.gz
スタンドアロン版のインストール
ElasticSearch は Root ユーザーによる直接操作をサポートしていないため、es ユーザーを作成する必要があります
# 添加新用户
useradd es
# 创建elk目录
cd /opt/elk
# 下载
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.8.0-linux-x86_64.tar.gz
# 解压缩
tar -zxvf elasticsearch-8.8.0-linux-x86_64.tar.gz
#重命名
mv elasticsearch-8.8.0 elsearch
先ほどは root ユーザーで操作したので、/soft フォルダーの所有権も es ユーザーに変更する必要があります。
chown es.es /opt/elk -R
その後、es ユーザーに切り替えて操作します
# 切换用户
su - es
次に、設定ファイルを変更できます
# 进入到 elsearch下的config目录
cd /opt/elk/elsearch/config
次に、次の構成を見つけます
#打开配置文件
vim elasticsearch.yml
#设置ip地址,任意网络均可访问
network.host: 0.0.0.0
#关闭安全功能
xpack.security.enable: true ==> xpack.security.enable: false
Elasticsearch では、network.host が localhost または 127.0.0.1 ではない場合、運用環境とみなされ、より高い環境要件が必要になります。テスト環境では満たせない可能性があります。通常、2 つの構成を変更する必要があります。次のように:
# 修改jvm启动参数
vim conf/jvm.options
#根据自己机器情况修改
-Xms128m
-Xmx128m
次に、2 番目の構成を変更します。これには、ホスト マシンに移動して構成する必要があります。
# 到宿主机上打开文件
vim /etc/sysctl.conf
# 增加这样一条配置,一个进程在VMAs(虚拟内存区域)创建内存映射最大数量
vm.max_map_count=655360
# 让配置生效
sysctl -p
エラスティックサーチを開始する
まずelsearchユーザーに切り替える必要があります
su - es
次に、bin ディレクトリに移動し、次のコマンドを実行します。
# 进入bin目录
cd /opt/elk/elsearch/bin
# 后台启动
./elasticsearch -d
正常に起動したら、次の URL にアクセスします。
http://192.168.40.150:9200/
以下の情報が表示されれば正常に起動されています。
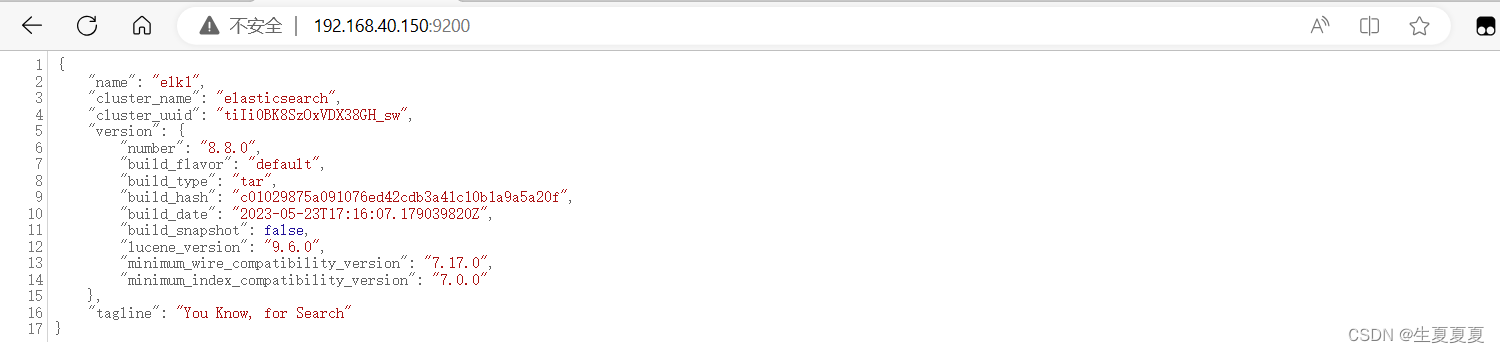
起動中に問題が発生した場合は、以下のエラー分析を参照してください~
エラー分析
エラー状態 1
以下のエラーメッセージが表示された場合
java.lang.RuntimeException: can not run elasticsearch as root
at org.elasticsearch.bootstrap.Bootstrap.initializeNatives(Bootstrap.java:111)
at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:178)
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:393)
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:170)
at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:161)
at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:86)
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:127)
at org.elasticsearch.cli.Command.main(Command.java:90)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:126)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:92)
For complete error details, refer to the log at /soft/elsearch/logs/elasticsearch.log
[root@e588039bc613 bin]# 2020-09-22 02:59:39,537121 UTC [536] ERROR CLogger.cc@310 Cannot log to named pipe /tmp/elasticsearch-5834501324803693929/controller_log_381 as it could not be opened for writing
2020-09-22 02:59:39,537263 UTC [536] INFO Main.cc@103 Parent process died - ML controller exiting
これは、root 操作が使用できないため、elsearch ユーザーに切り替えていないことを意味します。
su - elsearch用户
エラーケース2
[1]:max file descriptors [4096] for elasticsearch process is too low, increase to at least[65536]
解決策: root ユーザーに切り替え、limits.conf を編集して次の内容を追加します。
vi /etc/security/limits.conf
# ElasticSearch添加如下内容:
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
エラーケース3
[2]: max number of threads [1024] for user [elsearch] is too low, increase to at least
[4096]
つまり、スレッドの最大数の設定が低すぎるため、4096 に変更する必要があります。
#解决:切换到root用户,进入limits.d目录下修改配置文件。
vi /etc/security/limits.d/90-nproc.conf
#修改如下内容:
* soft nproc 1024
#修改为
* soft nproc 4096
ElasticSearch-Head 視覚化ツール
ES は公式には ES 用のビジュアル管理ツールを提供していないため、バックグラウンド サービスのみを提供しています。elasticsearch-head は ES 用に開発されたページ クライアント ツールです。そのソース コードは Github でホストされており、アドレスは Portal です。
head では次のインストール方法が提供されます
- ソースコードのインストール、npm run start 経由で開始 (非推奨)
- docker 経由でインストールする (推奨)
- Chrome プラグイン経由でインストールする (推奨)
- ES プラグインを介してインストールする (推奨されません)
Docker経由でインストールする
#拉取镜像
docker pull salgat/elasticsearch-head
#启动容器
docker run -d --name elasticsearch-head -p 9100:9100 salgat/elasticsearch-head
注:
フロントエンドとバックエンドを個別に開発するため、クロスドメインの問題が発生し、次のようにサーバー上で CORS 構成を行う必要があります。
vim elasticsearch.yml
# 新加
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-headers: Authorization
Chrome プラグインを介してインストールすると、この問題は発生しません
Chrome拡張機能経由でインストール
Chrome アプリ ストアを開いてポータルをインストールします

新しいインデックスを作成することもできます
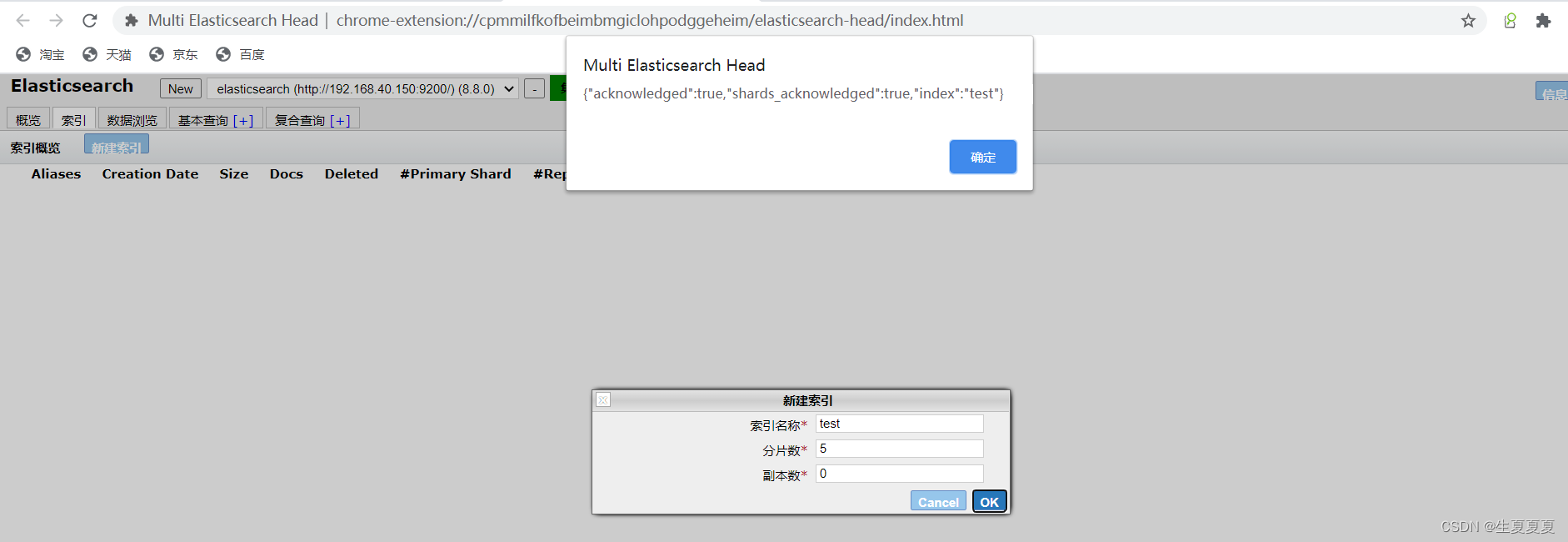
推奨事項: chrome プラグインを使用してインストールすることをお勧めしますが、ネットワーク環境が許可しない場合は、他の方法でインストールしてください。
ElasticSearch の基本概念
索引
- インデックスは Elasticsearch の論理データの論理ストレージであるため、より小さな部分に分割できます。
- インデックスは、リレーショナル データベースのテーブルと考えることができます。インデックスの構造は、特に元の値を保存しないため、高速かつ効率的な全文インデックス作成のために準備されています。
- Elasticsearch では、インデックスを 1 台のマシンに保存することも、複数のサーバーに分散させることもでき、各インデックスには 1 つ以上のシャードがあり、各シャードには複数のレプリカを含めることができます。
ドキュメンテーション
-
Elasticsearch に保存される主要なエンティティはドキュメントと呼ばれます。リレーショナル データベースに例えると、ドキュメントはデータベース テーブル内のレコードの行に相当します。
-
ドキュメントは複数のフィールドで構成されており、各フィールドはドキュメント内で複数回出現する場合があります。このようなフィールドは複数値フィールドと呼ばれます。
各フィールドのタイプ (テキスト、値、日付など)。フィールド タイプは、フィールドに他のサブドキュメントまたは配列が含まれる複合タイプにすることもできます。
地図
すべてのドキュメントはインデックスに書き込まれる前に分析されます。入力テキストを用語に分割する方法と、どの用語をフィルタリングするか。この動作はマッピングと呼ばれ、ルールは通常ユーザーによって定義されます。
ドキュメントタイプ
- Elasticsearch では、インデックス オブジェクトにさまざまな目的のオブジェクトを保存できます。たとえば、ブログ アプリケーションでは記事やコメントを保存できます。
- 各ドキュメントは異なる構造を持つことができます。
- 異なるドキュメント タイプで同じプロパティに異なるタイプを設定することはできません。たとえば、title というフィールドは、同じインデックス内のすべてのドキュメント タイプで同じタイプを持つ必要があります。
RESTful API
Elasticsearch は、基本的な CRUD、インデックス作成、インデックス削除、その他の操作を含む豊富な RESTful API 操作を提供します。
非構造化インデックスを作成する
Lucene では、インデックスを作成するにはフィールド名とフィールド タイプを定義する必要があります。Elasticsearch では非構造化インデックスが提供されます。これは、インデックス構造を作成せずにデータをインデックスに書き込むことができることを意味します。実際、Elasticsearch の最下層は構造化操作を実行します。ユーザーに対して透過的です。
空のインデックスを作成する
PUT /haoke
{
"settings": {
"index": {
"number_of_shards": "2", #分片数
"number_of_replicas": "0" #副本数
}
}
}
インデックスの削除
#删除索引
DELETE /haoke
{
"acknowledged": true
}
データの挿入
URL ルール:
POST /{index}/{type}/{id}
POST /haoke/_doc/1001
#数据
{
"id":1001,
"name":"张三",
"age":20,
"sex":"男"
}
Googleプラグインを使用したadvanced reset client操作が成功した後
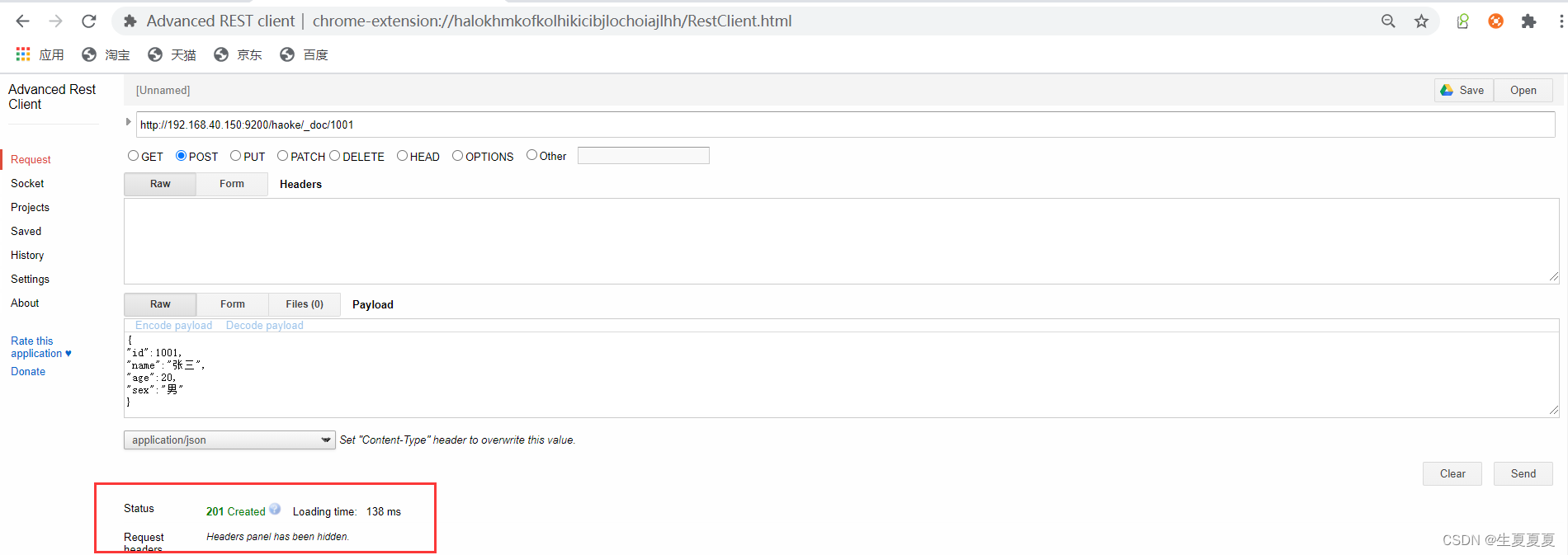
ElasticSearchHead を通じてデータをプレビューすることで、挿入したばかりのデータを確認できます。
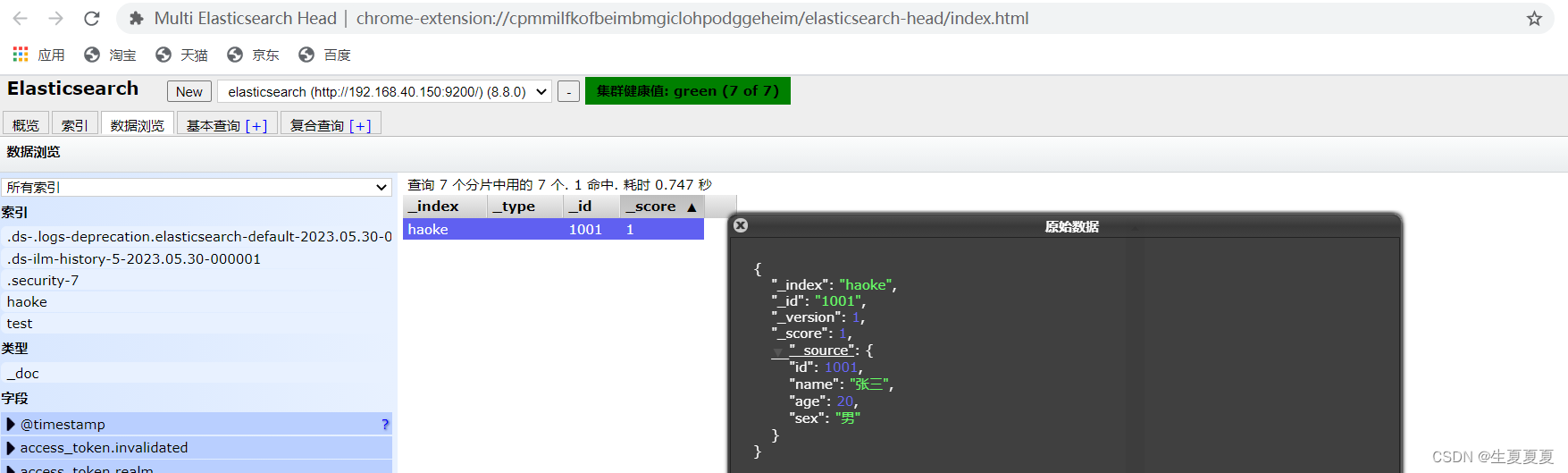
注: 非構造化インデックスを事前に作成する必要はなく、データを直接挿入するとデフォルトでインデックスが作成されます。
ID を指定せずにデータを挿入します。
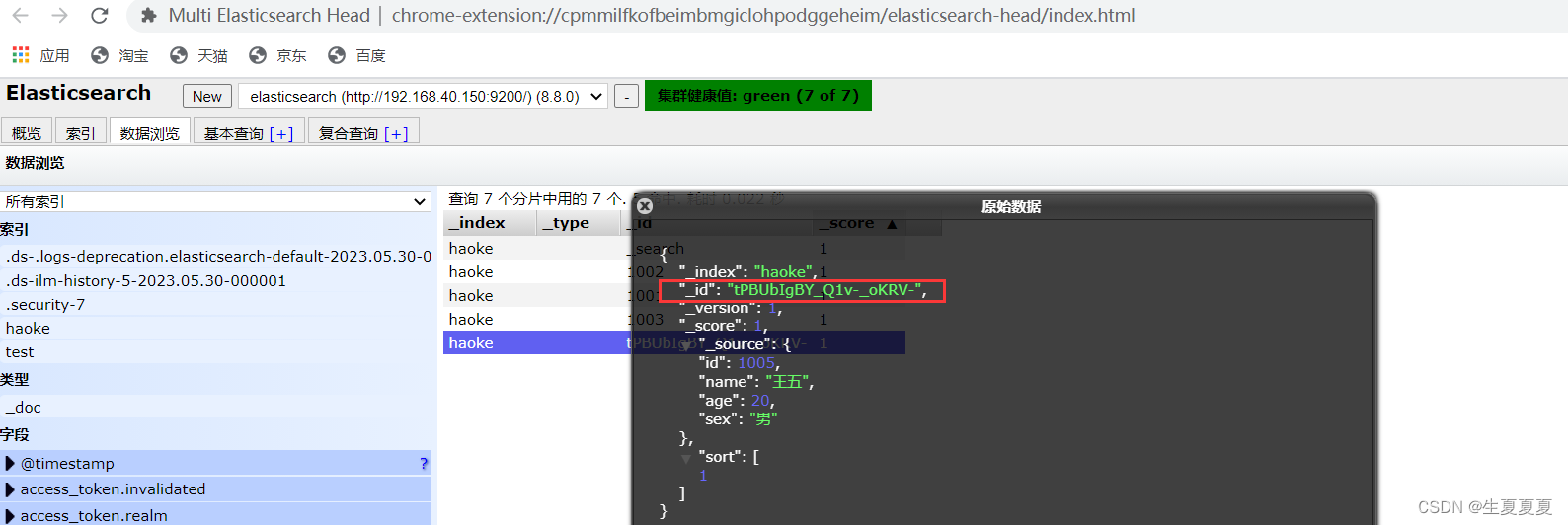
データを更新する
Elasticsearchでは文書データの変更はできませんが、上書き更新は可能です。
PUT /haoke/_doc/1001
{
"id":1001,
"name":"大漂亮",
"age":21,
"sex":"女"
}
更新された結果は次のとおりです。
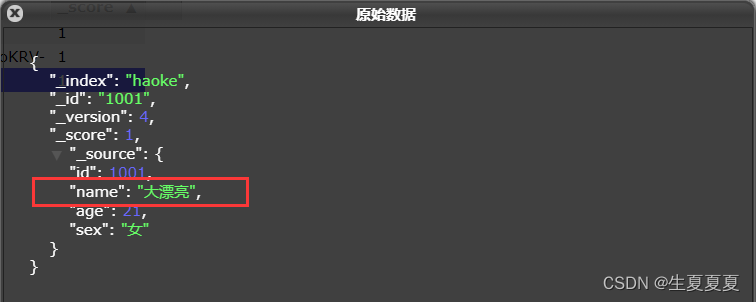
データが上書きされていることがわかります。問題は、部分的に更新できるかどうかです。- わかりました。先ほどドキュメントデータは更新できないと言いましたよね?
実際には、内部的にはドキュメント データが引き続きクエリされ、その後上書き操作が実行されます。その手順は次のとおりです。
- 古いドキュメントからJSONを取得する
- それを修正する
- 古い文書を削除する
- 新しいドキュメントのインデックスを作成する
#注意:这里多了_update标识
POST /haoke/_update/1001
{
"doc":{
"age":66
}
}

ご覧のとおり、データは部分的に更新されています。
インデックスの削除
Elasticsearch では、ドキュメント データを削除するには、パラメータを追加せずに DELETE リクエストを開始するだけで済みます。
DELETE /haoke/_doc/1001

存在しないデータを削除すると、404 応答が発行されます。
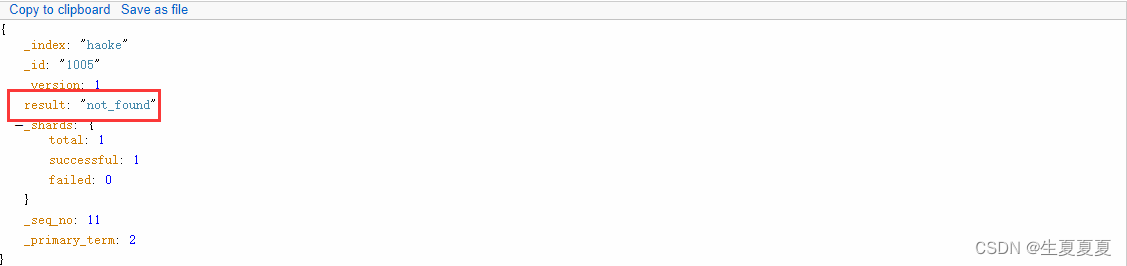
ドキュメントを削除しても、すぐにディスクから削除されるわけではなく、削除済みとしてマークされるだけです。Elasticsearch は、後でインデックスを追加するときに、削除されたコンテンツをバックグラウンドでクリーンアップします。【バッチ操作に相当】
データの検索
IDに基づいてデータを検索する
GET /haoke/_doc/tPBUbIgBY_Q1v-_oKRV-
#返回的数据如下
{
_index: "haoke"
_id: "tPBUbIgBY_Q1v-_oKRV-"
_version: 1
_seq_no: 4
_primary_term: 1
found: true
_source: {
id: 1005
name: "王五"
age: 20
sex: "男"
}-
}
すべてのデータを検索する
GET /haoke/_search
すべてのデータをクエリすると、デフォルトでは 10 レコードのみが返されることに注意してください

キーワード検索データ
#查询年龄等于20的用户
GET /haoke/_search?q=age:20
結果は次のとおりです。

DSL検索
Elasticsearch は、DSL クエリ (Query DSL) と呼ばれる豊富で柔軟なクエリ言語を提供し、より複雑で強力なクエリを構築できます。
DSL (Domain Specific Language) は、JSON リクエスト本文の形式で表示されます。
POST /haoke/_search
#请求体
{
"query" : {
"match" : {
#match只是查询的一种
"age" : 20
}
}
}
実装: 30 歳以上の男性ユーザーをクエリします。
POST /haoke/user/_search
#请求数据
{
"query": {
"bool": {
"filter": {
"range": {
"age": {
"gt": 30
}
}
},
"must": {
"match": {
"sex": "男"
}
}
}
}
}
クエリ結果

全部調べて
POST /haoke/_search
#请求数据
{
"query": {
"match": {
"name": "lh ttd lyj"
}
}
}

ハイライトを追加するには、ハイライトを追加するだけです
POST /haoke/_search
#请求数据
{
"query": {
"match": {
"name": "lh"
}
}
"highlight": {
"fields": {
"name": {
}
}
}
}

重合
Elasticsearch では、SQL の group by 操作と同様に、集計操作がサポートされています。
POST /haoke/_search
{
"aggs": {
"all_interests": {
"terms": {
"field": "age"
}
}
}
}
年齢別に集計すると以下のような結果になりました。

この結果から、20 歳のデータは 2 つ、21 歳、35 歳、50 歳、80 歳のデータは 1 つであることがわかります。