1. Introduction to CDL
CDL (full name Change Data Loader) is a real-time data integration service based on the Kafka Connect framework. The CDL service can capture database Data Change events from various OLTP databases and push them to kafka, and then push them to the big data ecosystem through the sink connector.
CDL currently supports data sources such as MySQL, PostgreSQL, Oracle, Hudi, Kafka, and ThirdParty-Kafka. The target end supports writing to Kafka, Hudi, DWS, and ClickHouse.
2. CDL structure
The CDL service contains two important roles: CDLConnector and CDLService. CDLConnector is an instance that specifically performs data capture tasks, including Source Connector and Sink Connector. CDLService is an instance responsible for managing and creating tasks.
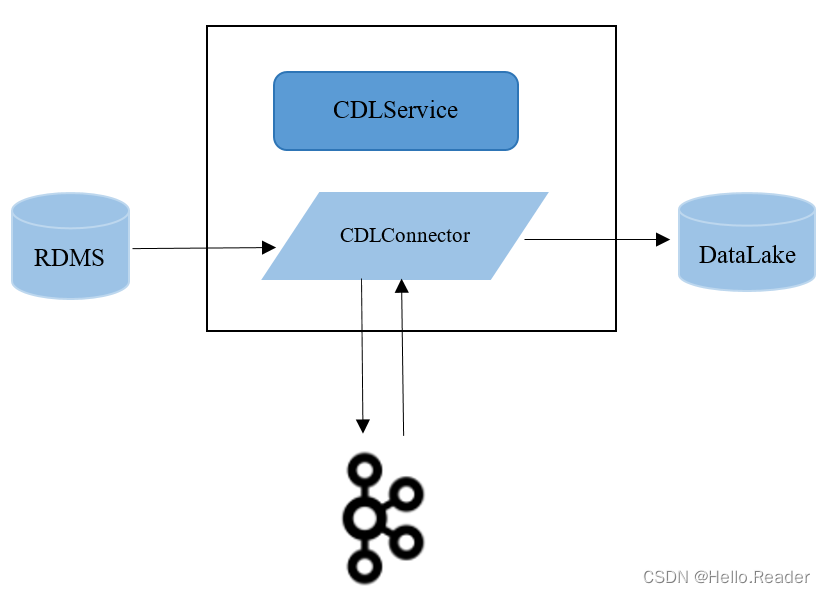
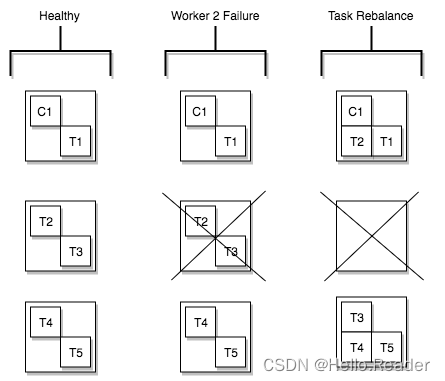
The CDLService in the CDL service is a multi-master mode, and any CDLService can perform business operations; the CDLConnector is a distributed mode, providing high reliability and rebalance capabilities. The number of tasks specified when creating a task will be among the CDLConnector instances in the entire cluster. Balance between nodes to ensure that the number of tasks running on each instance is approximately the same. If a CDLConnector instance is abnormal or the node is down, the task will rebalance the number of tasks on other nodes.
3. The relationship between CDL and other components
The CDL component is based on the Kafka Connect framework. The captured data is transferred through kafka topics, so it first relies on the kafka component. Secondly, CDL itself stores the metadata information and monitoring information of the task. These data are stored in the database, so it also relies on DBService component.