上記の続き:Ceph 分散ストレージシリーズ (2): ceph-deploy メソッドで 3 ノード ceph クラスターをデプロイする
通常、クラスターの拡張は一連のビジネス上の問題などにより避けられない一般的なものであるため、今回は前回の記事でデプロイした3ノードCephクラスタをベースに、新たなノードの容量を拡張する実験を再度行ってまとめてみましょう!
一般に、クラスター拡張には 2 つの状況があります。
- 新しいサーバーノードを追加してクラスター容量を拡張します
- 元のサーバーに新しいハードディスク (OSD) を追加して、クラスターの容量を拡張します。
個人的な理解: 実際、これら 2 つの拡張方法は一般的に OSD を追加することを目的としていますが、元のサーバーに新しいハードディスクを配置するための追加のハードディスク容量がない場合、唯一の選択肢はクラスター拡張のために新しいサーバーを追加することです。
以下では、これら 2 つの展開状況に基づいて一連のテストと説明を行っていきます。
新しいサーバーを追加して容量を拡張する
1. サーバーの準備
クラスタのステータスが正常であれば、クラスタの容量を拡張します。
今回は環境上の制限により、新しいサーバー、つまり新しいノードが追加されますが、サーバーのバージョンは引き続き使用されます。Centos7.8.2003
環境情報:
| IPアドレス | CPU名 | 追加ディスク (OSD) | クラスターの役割 |
|---|---|---|---|
| 192.168.56.125 | ceph-node1 | 10G ディスク (/dev/sdb) | mon、mgr、osd0 (マスターノード) |
| 192.168.56.126 | ceph-node2 | 10G ディスク (/dev/sdb) | osd1 |
| 192.168.56.127 | ceph-node3 | 10G ディスク (/dev/sdb) | osd2 |
192.168.56.128 |
ceph-node4 |
一块5G磁盘(/dev/sdb) |
osd3 (新增节点) |
ノード拡張の準備作業は、クラスタ全体を展開する場合の各ノードの準備作業と基本的に同じです。
一部の展開準備の詳細についてはここでは繰り返しません。詳細な準備作業については、Ceph 分散ストレージ シリーズ (2)も参照してください。 : ceph-deploy モードのデプロイメント 3 ノード ceph クラスター
1. ファイアウォールと selinux (拡張ノードの実行) をオフにします。
sed -i "s/SELINUX=enforcing/SELINUX=permissive/g" /etc/selinux/config
setenforce 0
systemctl stop firewalld
systemctl disable firewalld
2. hosts ファイルを構成します (クラスター内のすべてのノードで実行する必要があります)
保证集群内所有主机名与ip解析正常
[root@ceph-node1 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.56.125 ceph-node1
192.168.56.126 ceph-node2
192.168.56.127 ceph-node3
192.168.56.128 ceph-node4
[ceph-admin@ceph-node1 cluster]$ ping ceph-node4
PING ceph-node4 (192.168.56.128) 56(84) bytes of data.
64 bytes from ceph-node4 (192.168.56.128): icmp_seq=1 ttl=64 time=0.475 ms
…………
3. デプロイメントユーザーを作成し、sudo 権限を構成します
クラスター内の他のノードにはすでにデプロイメント ユーザーが存在し、クラスターは正常に実行されているため、新しく追加されたノードでのみ実行できます。
$ useradd ceph-admin
$ echo "123456" | passwd --stdin ceph-admin
$ echo "ceph-admin ALL = NOPASSWD:ALL" | tee /etc/sudoers.d/ceph-admin
$ chmod 0440 /etc/sudoers.d/ceph-admin
4. パスワードレスアクセスの設定 (マスターノードnode1で実行)
[root@ceph-node1 ~]# su - ceph-admin
[ceph-admin@ceph-node1 ~]$ ssh-copy-id ceph-admin@ceph-node1
5. NTP同期の設定(新規ノード実行)
$ yum -y install ntp #安装ntp,如果已安装,那就忽略这条命令
$ vim /etc/ntp.conf
注释掉默认的server配置项:
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
添加配置项:
server 192.168.56.125 #node1-ntp服务器
重启ntp服务
$ systemctl restart ntpd
$ systemctl enable ntpd
查看ntp连接情况和状态
[root@ceph-node4 ~]# ntpq -p
remote refid st t when poll reach delay offset jitter
==============================================================================
*ceph-node1 120.25.115.20 3 u 6 64 1 0.325 -173.07 0.000
6. ノード構成の yum ソースを追加します
a. Alibaba Cloud のベース ソースと epel ソースを追加します
备份系统原本的源
$ mkdir /mnt/repo_bak
$ mv /etc/yum.repos.d/* /mnt/repo_bak
添加新源
$ wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
$ wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
b. ceph の yum ソースを追加します
vim /etc/yum.repos.d/ceph.repo
[Ceph]
name=Ceph
baseurl=http://download.ceph.com/rpm-nautilus/el7/x86_64
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
priority=1
[Ceph-noarch]
name=Ceph noarch packages
baseurl=http://download.ceph.com/rpm-nautilus/el7/noarch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
priority=1
[ceph-source]
name=Ceph source packages
baseurl=http://download.ceph.com/rpm-nautilus/el7/SRPMS
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
priority=1
更新yum缓存及系统软件
yum makecache
yum -y update
2. 拡張を開始する
1. Cephパッケージを新しいノードにインストールします(メインノードnode1上で操作します)。
(--no-adjust-repos パラメータの意味: ローカルに設定されたソースを使用し、ソースを変更しないでください。問題を防ぐため)
[ceph-admin@ceph-node1 ~]$ su - ceph-admin
[ceph-admin@ceph-node1 cluster]$ cd cluster
[ceph-admin@ceph-node1 cluster]$ ceph-deploy install --no-adjust-repos ceph-node4
以前に ceph-deploy を使用してクラスターがインストールされておらず、ceph-deploy コマンドがない場合は、手動インストールも可能です。
yum -y install ceph ceph-radosgw
2. ceph-deploy を使用して OSD を追加します
内部にデータが含まれるディスクの場合は、最初にデータをクリアする必要があります (詳細については、ceph-depoy disc zap --help を参照してください)。
列出所有节点上所有可用的磁盘
[ceph-admin@ceph-node1 cluster]$ ceph-deploy disk list ceph-node4
清除数据
sudo ceph-deploy disk zap {
osd-server-name} {
disk-name}
eg:ceph-deploy disk zap ceph-node2 /dev/sdb
クラスターを追加する前に、クラスターの OSD ステータスを確認できます。
[ceph-admin@ceph-node1 cluster]$ ceph osd stat
3 osds: 3 up (since 22h), 3 in (since 22h); epoch: e37
クリーンなディスクの場合は、上記のデータ消去操作を無視して、OSD を直接追加できます
(ここでは、新しく追加した /dev/sdb ディスクを追加しています)。
[ceph-admin@ceph-node1 cluster]$ ceph-deploy osd create --data /dev/sdb ceph-node4
上記の追加コマンドを実行すると、OSD ステータスを表示できます。
[ceph-admin@ceph-node1 cluster]$ ceph osd stat
4 osds: 4 up (since 7s), 4 in (since 7s); epoch: e41
[ceph-admin@ceph-node1 cluster]$ ceph -s
cluster:
id: 130b5ac0-938a-4fd2-ba6f-3d37e1a4e908
health: HEALTH_OK
services:
mon: 1 daemons, quorum ceph-node1 (age 45h)
mgr: ceph-node1(active, since 45h)
osd: 4 osds: 4 up (since 47s), 4 in (since 47s)
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 4.0 GiB used, 31 GiB / 35 GiB avail
pgs:
新增节点查看
[root@ceph-node4 ~]# pvs
PV VG Fmt Attr PSize PFree
/dev/sdb ceph-e734e119-37de-484b-861e-030f6adb8c29 lvm2 a-- <5.00g 0
[root@ceph-node4 ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
devtmpfs 487120 0 487120 0% /dev
tmpfs 497840 0 497840 0% /dev/shm
tmpfs 497840 7860 489980 2% /run
tmpfs 497840 0 497840 0% /sys/fs/cgroup
/dev/sda3 8377344 1784808 6592536 22% /
/dev/sda1 1038336 162708 875628 16% /boot
tmpfs 99572 0 99572 0% /run/user/0
tmpfs 497840 52 497788 1% /var/lib/ceph/osd/ceph-3
以上で、新規サーバーの追加とクラスターの拡張の操作は完了です。
新しいハードドライブを追加して容量を拡張します
1. ハードドライブを追加する
デフォルトでは、新しく追加されたハードディスクはサーバーを再起動することによってのみ認識されます。ただし、通常、クラスターの実行中にクラスターを拡張するため、クラスターに影響を与えないように、サーバーが新しく追加されたハードディスクを認識していることを確認する必要があります。電源が入っているときのディスク。
ハードディスクの追加方法についてはこれ以上説明する必要はありませんので、オンラインでサーバーに認識させる方法に直接進みましょう。
ハードディスクの前にサーバーのステータスを特定します。
[root@ceph-node2 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 20G 0 disk
├─sda1 8:1 0 1G 0 part /boot
├─sda2 8:2 0 2G 0 part [SWAP]
└─sda3 8:3 0 17G 0 part /
sdb 8:16 0 10G 0 disk
└─ceph--fab2d4ae--c169--4fcf--8a71--594251496f6d-osd--block--c2613e3c--a71c--4176--a5d6--f016a1e36bd4 253:0 0 10G 0 lvm
sr0 11:0 1 1G 0 rom
次のコマンドを実行してデバイス情報を更新します。
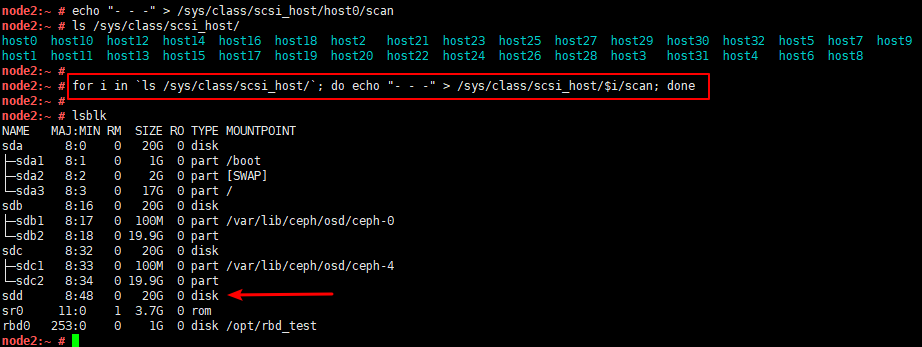
echo "- - -" > /sys/class/scsi_host/host0/scan
/sys/class/scsi_host/ 配下に複数のホスト ファイルがある場合は、それぞれを変更する必要がありますが、
このコマンドを直接実行することもできます (個人的なテストに利用可能)
for i in `ls /sys/class/scsi_host/`; do echo "- - -" > /sys/class/scsi_host/$i/scan; done
確認のため以前の写真を投稿します。
2. OSDをクラスターに追加します
実際、OSD を追加するにはさまざまな方法があり、OSD を手動で初期化して追加することも、ceph-deploy を使用してすばやく追加することもできます。
ここでは引き続き ceph-deploy を例に挙げますが、手動での追加方法については、後で拡張コンテンツの形で示します。
ceph-deployにハードディスクを追加する方法は、上記のノード追加後にOSDを追加する方法と基本的に同じなので、ここでもう一度説明します。
マスターノードnode1実行(ceph-deployがインストールされたノード)
まず、新しい OSD が配置されているサーバーの利用可能なディスクを確認します (出力の最後の行に注目してください)。
[ceph-admin@ceph-node1 cluster]$ ceph-deploy disk list ceph-node2
[ceph_deploy.conf][DEBUG ] found configuration file at: /home/ceph-admin/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (2.0.1): /bin/ceph-deploy disk list ceph-node2
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] debug : False
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] subcommand : list
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x7fdc07b20488>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] host : ['ceph-node2']
[ceph_deploy.cli][INFO ] func : <function disk at 0x7fdc07d6c938>
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] default_release : False
[ceph-node2][DEBUG ] connection detected need for sudo
[ceph-node2][DEBUG ] connected to host: ceph-node2
[ceph-node2][DEBUG ] detect platform information from remote host
[ceph-node2][DEBUG ] detect machine type
[ceph-node2][DEBUG ] find the location of an executable
[ceph-node2][INFO ] Running command: sudo fdisk -l
[ceph-node2][INFO ] Disk /dev/sda: 21.5 GB, 21474836480 bytes, 41943040 sectors
[ceph-node2][INFO ] Disk /dev/sdb: 10.7 GB, 10737418240 bytes, 20971520 sectors
[ceph-node2][INFO ] Disk /dev/mapper/ceph--fab2d4ae--c169--4fcf--8a71--594251496f6d-osd--block--c2613e3c--a71c--4176--a5d6--f016a1e36bd4: 10.7 GB, 10733223936 bytes, 20963328 sectors
[ceph-node2][INFO ] Disk /dev/sdc: 5368 MB, 5368709120 bytes, 10485760 sectors
清除数据
[ceph-admin@ceph-node1 cluster]$ ceph-deploy disk zap ceph-node2 /dev/sdc
………………
[ceph-node2][WARNIN] Running command: /bin/dd if=/dev/zero of=/dev/sdc bs=1M count=10 conv=fsync
[ceph-node2][WARNIN] --> Zapping successful for: <Raw Device: /dev/sdc>
OSDの追加
[ceph-admin@ceph-node1 cluster]$ ceph-deploy osd create --data /dev/sdc ceph-node2
クラスターのステータスを表示する
[ceph-admin@ceph-node1 cluster]$ ceph osd stat
4 osds: 4 up (since 59s), 4 in (since 59s); epoch: e59
拡張コンテンツ
1.OSDマニュアルの追加
これは通常、ceph-deploy を使用してデプロイされていないクラスターで使用され、比較的複雑ですが、簡単に見てみましょう。
簡単にまとめると以下のコマンドになります
ceph osd create 创建osd id
mkfs.xfs -f /dev/sdd 格式化新加硬盘
mkdir /var/lib/ceph/osd/ceph-6/
mount /dev/sdd /var/lib/ceph/osd/ceph-6/ 创建数据存储目录及挂载
ceph-osd -i 6 --mkfs --mkkey 初始化数据
ceph auth add osd.6 mgr "allow profile osd" mon "allow profile osd" osd "allow *" -i /var/lib/ceph/osd/ceph-6/keyring 注册验证密钥
ceph osd crush add osd.6 0.01939 root=default host=node1 将新增osd添加至crush中
ceph-osd -i 6 启动
1.OSD-IDの作成
マスターノードnode1が実行される
ここでの作成の後に ID 番号を続けることもできますが、一部の ID のスキップを避けるために、クラスター自体に ID 番号を指定させることが最善です。
node1:/etc # ceph osd create
7
node1:/etc # ceph osd stat
8 osds: 7 up, 7 in
2. データ格納ディレクトリを作成してマウントする
新しいハードディスクはノード 2 にあり、ハードディスクもノード 2 にマウントする必要があるため、ここではノード 2 で実行されます。
node2:~ # ls /var/lib/ceph/osd/
ceph-0 ceph-4
node2:~ # mkdir /var/lib/ceph/osd/ceph-7
node2:~ # mount /dev/sdd /var/lib/ceph/osd/ceph-7/
3. OSDストレージデータの初期化
node2:~ # ceph-osd -i 7 --mkfs --mkkey
2020-07-22 15:28:00.109102 7f23e503cd00 -1 auth: error reading file: /var/lib/ceph/osd/ceph-7/keyring: can't open /var/lib/ceph/osd/ceph-7/keyring: (2) No such file or directory
2020-07-22 15:28:00.146961 7f23e503cd00 -1 created new key in keyring /var/lib/ceph/osd/ceph-7/keyring
2020-07-22 15:28:00.284581 7f23e503cd00 -1 journal FileJournal::_open: disabling aio for non-block journal. Use journal_force_aio to force use of aio anyway
2020-07-22 15:28:00.352819 7f23e503cd00 -1 journal FileJournal::_open: disabling aio for non-block journal. Use journal_force_aio to force use of aio anyway
2020-07-22 15:28:00.354151 7f23e503cd00 -1 journal do_read_entry(4096): bad header magic
2020-07-22 15:28:00.354189 7f23e503cd00 -1 journal do_read_entry(4096): bad header magic
2020-07-22 15:28:00.357097 7f23e503cd00 -1 read_settings error reading settings: (2) No such file or directory
2020-07-22 15:28:00.402933 7f23e503cd00 -1 created object store /var/lib/ceph/osd/ceph-7 for osd.7 fsid e78f0997-b26d-3f1d-b235-b5f1d68fc169
コマンド解析:パラメータ:
ceph-osd -i [osd-ID]--mkfs --mkkey
- –id/-i ID 自分の名前の ID 部分を設定します (OSD の ID 番号、つまり OSD 番号を設定します)
- –mkfs [新しい] データ ディレクトリを作成します (新しいデータ ディレクトリを作成します)
- –mkkey 新しい秘密鍵を生成します (新しい鍵を生成します)
4. 検証キーを登録し、OSD にアクセスするための他のコンポーネントの権限を設定します。
構成されている他の OSD の登録構成情報を表示する
node1:/var/lib/ceph/osd # ceph auth list
installed auth entries:
osd.0
key: AQAUpw5f3AhkAhAASxBAgXJznrQ8Cv3TgkirSg==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
osd.1
key: AQAVpw5fBdo8MBAAxBm7V8n3j09wO3TedyLfJA==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
·················
構成された OSD 構成情報に従って、新しく追加された OSD を構成します。
それぞれの環境の osd 構成情報に従って osd を追加するだけです。
node2:~ # ceph auth add osd.7 mgr "allow profile osd" mon "allow profile osd" osd "allow *" -i /var/lib/ceph/osd/ceph-7/keyring
added key for osd.7
5. 新しい OSD をクラッシュ マップに追加します
node2:~ # ceph osd tree #查看osd权重(即weight值)
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.13574 root default
-7 0.05817 host node1
2 hdd 0.01939 osd.2 up 1.00000 1.00000
5 hdd 0.01939 osd.5 up 1.00000 1.00000
6 hdd 0.01939 osd.6 up 1.00000 1.00000
-3 0.03879 host node2
0 hdd 0.01939 osd.0 up 1.00000 1.00000
4 hdd 0.01939 osd.4 up 1.00000 1.00000
-5 0.03879 host node3
1 hdd 0.01939 osd.1 up 1.00000 1.00000
3 hdd 0.01939 osd.3 up 1.00000 1.00000
7 0 osd.7 down 0 1.00000
node2:~ # ceph osd crush add osd.7 0.01939 root=default host=node2
add item id 7 name 'osd.7' weight 0.01939 at location {
host=node2,root=default} to crush map
6.OSDを開始する
node2:~ # ceph-osd -i 7
starting osd.7 at - osd_data /var/lib/ceph/osd/ceph-7 /var/lib/ceph/osd/ceph-7/journal
node2:~ # ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.15512 root default
-7 0.05817 host node1
2 hdd 0.01939 osd.2 up 1.00000 1.00000
5 hdd 0.01939 osd.5 up 1.00000 1.00000
6 hdd 0.01938 osd.6 up 0.01939 1.00000
-3 0.05817 host node2
0 hdd 0.01939 osd.0 up 1.00000 1.00000
4 hdd 0.01939 osd.4 up 1.00000 1.00000
7 hdd 0.01938 osd.7 up 1.00000 1.00000
-5 0.03879 host node3
1 hdd 0.01939 osd.1 up 1.00000 1.00000
3 hdd 0.01939 osd.3 up 1.00000 1.00000
2.OSDを削除する
1:将osd down掉
ceph osd down osd.0
(这样停止的话,osd会被集群自动启动起来,所以保险起见还是在osd所在服务器将osd所属服务给停掉 systemctl stop ceph-osd@0)
2:将osd从集群中退出
ceph osd out osd.0
3:从crush中移除节点
ceph osd crush remove osd.0
4:删除节点
ceph osd rm osd.0
5:删除OSD节点认证(不删除编号会占住)
ceph auth del osd.0
6:删除crush map中对应OSD条目
ceph crush remove osd.0
ceph-deploy によってデプロイさ
れた ceph クラスター osd のサービス操作コマンドは次のとおりです。systemctl start/stop/status ceph-osd@33OSD的ID号
エラー処理
以下のように、サーバーに残ったLVM形式のOSDは削除できません。
[root@ceph-node4 ~]# lsblk
……
sdb
└─ceph--29357d7b--f5da--44f8--b4f7--e81d6eb4113d-osd--block--05e52761--2aa1--461b--9dd0--ac5b807f8a25 253:0 0 5G 0 lvm
……
LVM レガシー情報の削除
[root@ceph-node4 ~]# dmsetup ls
ceph--29357d7b--f5da--44f8--b4f7--e81d6eb4113d-osd--block--05e52761--2aa1--461b--9dd0--ac5b807f8a25 (253:0)
[root@ceph-node4 ~]# dmsetup remove ceph--29357d7b--f5da--44f8--b4f7--e81d6eb4113d-osd--block--05e52761--2aa1--461b--9dd0--ac5b807f8a25
フォーマットする必要があります
[root@ceph-node4 ~]# mkfs.xfs -f /dev/sdb
meta-data=/dev/sdb isize=512 agcount=4, agsize=327680 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=1310720, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
LVM レガシー情報が削除されていない場合、次のようなエラーが表示されます:
RuntimeError: command returns non-zero exit status: 1
Failed to run command: /usr/sbin/ceph-volume --cluster ceph lvm create --bluestore --data / dev/sdb
GenericError: 1 つの OSD を作成できませんでした
終わり……