言語モデルを調べる
導入
このブログ投稿では、BERT、BART、T5 などの大規模言語モデルについて説明します。2020 年の LL.M. 分野における重要な発展には、これらのモデルの開発が含まれます。BERT と T5 は Google によって開発され、BART は Meta によって開発されました。発売日順にモデルの詳細を紹介していきます。前回のブログ投稿「自然言語処理の自己回帰モデル」では、生成の事前トレーニング済みトランスフォーマーの自己回帰特性について説明しました。このブログでは、これらのモデルが自己回帰モデルとどのように異なるかを比較します。前回の投稿をまだチェックしていない方は、ぜひチェックしてみてください。BERT の論文は 2018 年に、BART は 2019 年に、T5 は 2020 年に発表されました。論文の内容も同様の順序で紹介していきます。
トランスフォーマーの双方向エンコーダー表現 (BERT)
BERT モデルは、マルチレイヤー双方向 Transformer エンコーダーに基づいています。BERT は、すべてのレイヤーで左右のコンテキストを共同で調整することにより、ラベルなしテキストの深い双方向表現を事前トレーニングすることを目的としています。したがって、出力層を 1 つ追加するだけで、事前トレーニングされた BERT モデルを微調整して、最先端のモデルを作成できます。BERT は、マスクされた言語モデルの事前トレーニング目標を使用して、一方向の制約を克服します。BERT の事前トレーニングも次の文の予測によって完了します。
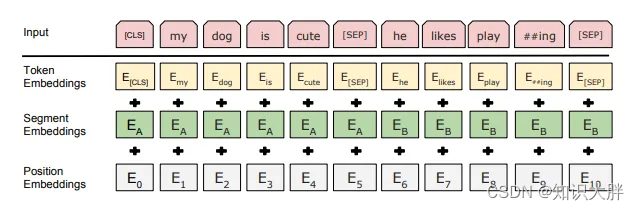
Transformer と比較すると、BERT の入力表現は、トークンの埋め込み、セグメントの埋め込み、および位置の埋め込みの合計です。特別なカテゴリ マーカーと文区切りマーカーも追加されました。トークン埋め込みは、30,000 の語彙を持つチャンク埋め込みです。事前トレーニングで使用されるデータセットは BookCorpus と Wikipedia です。
マスクされた言語モデル
MLM の事前トレーニングでは、入力シーケンス内の単語の 15% が取得されます。そのうち 80% はブロックされ、10% はランダムな単語に置き換えられ、10% は変更されませんでした。したがって&#