記事ディレクトリ
モデル紹介
SimCSEモデルは主に 2 つの部分に分かれており、1 つは教師なし部分、もう 1 つは教師あり部分です。全体的な構造を次の図に示します。
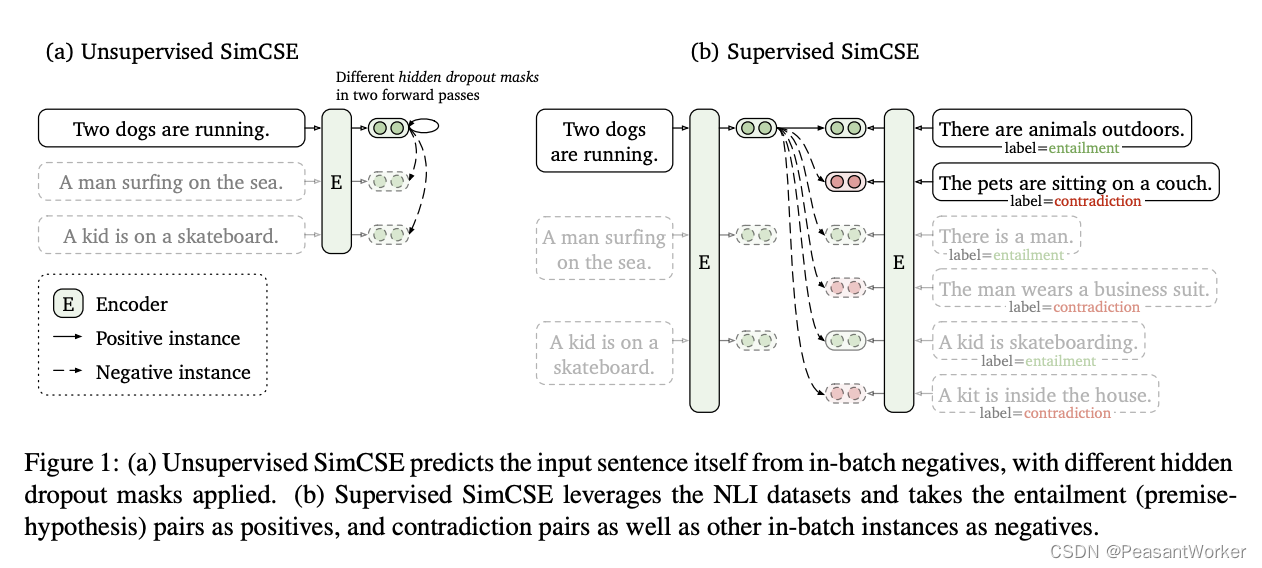
論文アドレス: https://arxiv.org/pdf/2104.08821.pdf
教師なし SimCSE
データ
教師なし部分の場合、最も賢明なのは、Dropoutデータ拡張を使用して肯定的な例を構築し、それによって肯定的なサンプルのペアを構築し、一方、否定的なサンプルのペアはbatch同じ文内の別の文であることです。
次に、文がモデルに 2 回入力されると、なぜ 2 つの異なるベクトルが得られるのかと疑問に思う人もいるかもしれません。
これは、dropoutモデル内に層があり、ニューロンがランダムに非活性化されると、トレーニング段階で同じ文がモデルに入力され、異なる出力が得られるためです。
コードを見ると、より直感的です。
class TrainDataset(Dataset):
def __init__(self, data, tokenizer, model_type="unsup"):
self.data = data
self.tokenizer = tokenizer
self.model_type = model_type
def text2id(self, text):
if self.model_type == "unsup":
text_ids = self.tokenizer([text, text], max_length=MAXLEN, truncation=True, padding='max_length', return_tensors='pt')
elif self.model_type == "sup":
text_ids = self.tokenizer([text[0], text[1], text[2]], max_length=MAXLEN, truncation=True, padding='max_length', return_tensors='pt')
return text_ids
def __len__(self):
return len(self.data)
def __getitem__(self, index):
return self.text2id(self.data[index])
Bert同じ文が 2 回繰り返されると、Encoder2 つの類似した文ベクトルが生成され、これが正の例とみなされることがわかります。
モデル
class SimcseUnsupModel(nn.Module):
def __init__(self, pretrained_bert_path, drop_out) -> None:
super(SimcseUnsupModel, self).__init__()
self.pretrained_bert_path = pretrained_bert_path
config = BertConfig.from_pretrained(self.pretrained_bert_path)
config.attention_probs_dropout_prob = drop_out
config.hidden_dropout_prob = drop_out
self.bert = BertModel.from_pretrained(self.pretrained_bert_path, config=config)
def forward(self, input_ids, attention_mask, token_type_ids, pooling="cls"):
out = self.bert(input_ids, attention_mask, token_type_ids, output_hidden_states=True)
if pooling == "cls":
return out.last_hidden_state[:, 0]
if pooling == "pooler":
return out.pooler_output
if pooling == 'last-avg':
last = out.last_hidden_state.transpose(1, 2)
return torch.avg_pool1d(last, kernel_size=last.shape[-1]).squeeze(-1)
if self.pooling == 'first-last-avg':
first = out.hidden_states[1].transpose(1, 2)
last = out.hidden_states[-1].transpose(1, 2)
first_avg = torch.avg_pool1d(first, kernel_size=last.shape[-1]).squeeze(-1)
last_avg = torch.avg_pool1d(last, kernel_size=last.shape[-1]).squeeze(-1)
avg = torch.cat((first_avg.unsqueeze(1), last_avg.unsqueeze(1)), dim=1)
return torch.avg_pool1d(avg.transpose(1, 2), kernel_size=2).squeeze(-1)
# 有实验表明cls的pooling方式效果最好
simcse注意深い学生は、何、明らかに同じであることに気づきましたbert。
はい、 と比較するとBert、 がSimcse変更されただけで、データ強調にdrop_out使用されますBertが、計算ではLossコントラストSimcseが導入されましたLoss
def train(self, train_dataloader, dev_dataloader):
self.model.train()
for batch_idx, source in enumerate(tqdm(train_dataloader), start=1):
real_batch_num = source.get('input_ids').shape[0] # source.get('input_ids').shape [64, 2, 64]
input_ids = source.get('input_ids').view(real_batch_num * 2, -1).to(self.device) # shape[128, 64]
attention_mask = source.get('attention_mask').view(real_batch_num * 2, -1).to(self.device) # shape[128, 64]
token_type_ids = source.get('token_type_ids').view(real_batch_num * 2, -1).to(self.device) # shape[128, 64]
out = self.model(input_ids, attention_mask, token_type_ids) # out.shape [128, 768]
loss = self.simcse_unsup_loss(out)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
if batch_idx % 10 == 0:
logger.info(f'loss: {
loss.item():.4f}')
corrcoef = self.eval(dev_dataloader)
self.model.train()
if self.best_loss > corrcoef:
self.best_loss = corrcoef
torch.save(self.model.state_dict(), self.model_save_path)
logger.info(f"higher corrcoef: {
self.best_loss:.4f} in batch: {
batch_idx}, save model")
def simcse_unsup_loss(self, y_pred):
y_true = torch.arange(y_pred.shape[0], device=self.device)
y_true = (y_true - y_true % 2 * 2) + 1
sim = F.cosine_similarity(y_pred.unsqueeze(1), y_pred.unsqueeze(0), dim=-1)
sim = sim - torch.eye(y_pred.shape[0], device=self.device) * 1e12
sim = sim / 0.05
loss = F.cross_entropy(sim, y_true)
return loss
train関数のsource出力には、以下に示すように3 つの短いセグメントが含まれます: 、 、最初の次元は、2 番目の次元は入力された文の数です。2 つの文が入力される (同じ文が2 回入力される) ため、最初の次元は次のようにBertなります。2 次元は 2、3 次元は文章です。tokenizerinput_idstoken_type_idsattention_mask

input_idsbatch_sizebertmax_length
次に、loss計算プロセスを各ステップに分けて見ていきます。
1. 128 文が与えられた場合、0 ~ 127 のインデックスを生成します。
y_true = torch.arange(y_pred.shape[0], device=self.device)

2. 各文に対応するリアルタグを生成
y_true = (y_true - y_true % 2 * 2) + 1

y_trueこのステップと最初のステップの違いに注意してくださいy_true。
ここでy_true、実際には、次のような各文に対応する肯定的な例のインデックスですbatch。
与第0个句子相似的句子索引为1
与第1个句子相似的句子索引为0
与第2个句子相似的句子索引为3
与第2个句子相似的句子索引为2
文0から数え始めたことに注意してください
3. 2 つのペア間の類似性を計算します。
sim = F.cosine_similarity(y_pred.unsqueeze(1), y_pred.unsqueeze(0), dim=-1)
y_pred寸法は[128、768]です。
sim寸法は[128、128]です。
各行は現在の文と他の文の類似度を表しており、このとき対角線上の値は 1 になります。
4. 対角線の値をより大きな数に増幅して、loss対角線に対する自身の影響を排除します (負の無限大でクロス エントロピーを計算すると、ほぼ 0 になります)。
sim = sim - torch.eye(y_pred.shape[0], device=self.device) * 1e12
5. ハイパーパラメータの温度係数を掛ける理由については、実験の結果、効果が良いこと0.05が示されているとしか言えません。0.05
sim = sim / 0.05
6. クロスエントロピー損失を利用して対比損失を表現し、類似文を分類として扱い、正例との距離を縮め、負例との距離を広げる同一文内では、2回入力された文を除いて正例となる文章はすべて否定的なbatch例bertです
loss = F.cross_entropy(sim, y_true)
効果

監視付き SimCSE
データ
教師なしとは異なり、教師なしの入力は単一のtext文ですが、教師ありデータセットは[text, text+, text-]次の 3 つの文です。

モデル
モデル部分は教師ありモデル部分と同じであり、コーディングや文ベクトル抽出bertにも使用されます。encodecls
さまざまな部分に注目してloss計算してみましょう。
def simcse_sup_loss(self, y_pred):
y_true = torch.arange(y_pred.shape[0], device=self.device)
use_row = torch.where((y_true + 1) % 3 != 0)[0]
y_true = (use_row - use_row % 3 * 2) + 1
sim = F.cosine_similarity(y_pred.unsqueeze(1), y_pred.unsqueeze(0), dim=-1)
sim = sim - torch.eye(y_pred.shape[0], device=self.device) * 1e12
sim = torch.index_select(sim, 0, use_row)
sim = sim / 0.05
loss = F.cross_entropy(sim, y_true)
return loss
1. 0 ~ 191 のインデックスを生成します。
y_true = torch.arange(y_pred.shape[0], device=self.device)
2. 使用するインデックスを選択します 3 番目の文がない場合はlabel3 番目の文が否定例となり、3 番目の文が使用されない場合はbatch同じ文内の他の文が否定例とみなされます。
use_row = torch.where((y_true + 1) % 3 != 0)[0]
3. 3 番目の文の後の実際のラベルを破棄します。
y_true = (use_row - use_row % 3 * 2) + 1
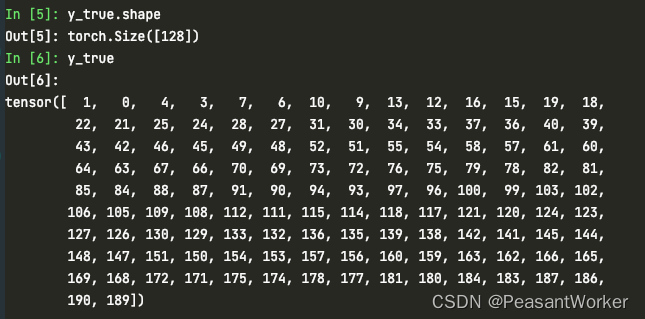
4. 2 つのペア間の類似度を計算します。simこのときの次元は[192, 192]3 番目の文の否定例も含めて です。
sim = F.cosine_similarity(y_pred.unsqueeze(1), y_pred.unsqueeze(0), dim=-1)

5. 対角寸法の影響を排除する
sim = sim - torch.eye(y_pred.shape[0], device=self.device) * 1e12
6. 有用な行を選択する
sim = torch.index_select(sim, 0, use_row)

7. 教師なし法と一致して、クロスエントロピー損失を計算します。
loss = F.cross_entropy(sim, y_true)
効果

要約する
偉大な道からシンプルな道へ
すべてのコードはにアップロードされていますGithub。リンク: https://github.com/seanzhang-zhichen/simcse-pytorch
データセット:抽出コード: hlva