1. Qu'est-ce que l'idempotence
2. Pourquoi avons-nous besoin de l'idempotence
3. Comment gérer le délai d'attente de l'interface ?
4. Comment concevoir l'idempotence. Le processus de base de la conception idempotente
d'identification unique globale . 5. Huit solutions pour atteindre l'idempotence : sélection + insertion + clé primaire/conflit d'index unique, insertion directe + clé primaire/conflit d'index unique, machine à états idempotente, extraire le jeton de la table anti-duplication le verrouillage pessimiste (tel que la sélection pour la mise à jour) le verrouillage optimiste le verrouillage distribué 6. Résumé
1. Qu'est-ce que l'idempotence ?
L'idempotence est un concept en mathématiques et en informatique.
En mathématiques, l'expression fonctionnelle de l'idempotence est : f(x) = f(f(x)). Par exemple, la fonction permettant de trouver la valeur absolue est idempotente, abs(x) = abs(abs(x)).
En informatique, idempotent signifie que demander une ressource une fois et plusieurs fois devrait avoir les mêmes effets secondaires, ou que l'impact de plusieurs requêtes est le même que celui de l'exécution d'une seule requête.
cause
En général, il existe quatre raisons aux problèmes idempotents dans les systèmes logiciels :
① Soumission répétée par l'utilisateur : Généralement, cela signifie qu'une fois que l'utilisateur a rempli les informations du formulaire, l'utilisateur clique plusieurs fois sur le bouton de soumission en raison de la lenteur de la réponse.
②Appel illégal : fait référence au tiers déboguant l'adresse de l'interface par des moyens inverses, puis en l'appelant plusieurs fois via des robots d'exploration ou des outils d'interface.
③ Nouvelle tentative d'échec : dans les projets distribués, lorsque l'appelé rencontre un délai d'attente ou une exception, le mécanisme de compensation des nouvelles tentatives de l'appelant est déclenché.
④Message répété : fait généralement référence au projet qui introduit MQ. Pour le même message, le producteur l'envoie plusieurs fois ou le consommateur le consomme à plusieurs reprises.
2. Pourquoi avez-vous besoin d’idempotence ?
Par exemple :
Nous développons une fonction de transfert, en supposant que notre appel à l'interface en aval expire. Dans des circonstances normales, le délai d'attente peut être dû à une perte de paquets lors de la transmission réseau, ou il peut ne pas être envoyé lorsque la demande est effectuée, ou il se peut que la demande arrive, mais que le résultat renvoyé soit perdu. Pouvons-nous réessayer à ce moment-là ? Si je réessaye, vais-je transférer une somme d’argent ?
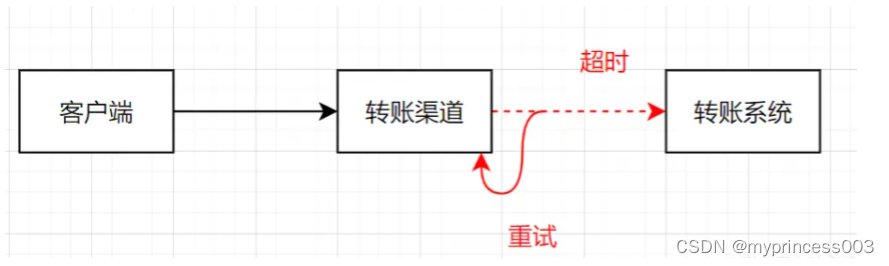
Les systèmes Internet actuels sont presque tous découplés et isolés, et il y aura des appels mutuels à distance entre différents systèmes. L’appel d’un service distant comporte trois états : réussite, échec ou expiration du délai. Les deux premiers sont des états définis, tandis que le timeout est un état inconnu. Lorsque notre transfert expire, si le système de transfert en aval effectue un contrôle idempotent et que nous effectuons une nouvelle tentative, nous pouvons alors nous assurer que le transfert se déroule normalement et nous pouvons également garantir qu'il n'y aura pas de transfert supplémentaire.
En fait, outre l’exemple du transfert, il existe de nombreux autres exemples de développement quotidien qui nécessitent de prendre en compte l’idempotence. Par exemple:
Lorsque les consommateurs MQ (middleware de messages) lisent des messages, ils peuvent lire des messages en double. (Consommation répétée)
Par exemple, lors de la soumission d'un formulaire, si vous cliquez rapidement sur le bouton Soumettre, deux éléments de données identiques peuvent être générés (soumission répétée par le front-end).
Dans un scénario distribué, il est extrêmement difficile d'obtenir un accord fort et cohérent entre plusieurs systèmes d’entreprise. L'une des hypothèses les plus simples et réalisables est d'assurer une cohérence éventuelle, ce qui nécessite que le serveur donne la même réponse lors du traitement d'une requête répétée, sans provoquer d'effets secondaires sur les données persistantes (c'est-à-dire des opérations multiples et des opérations uniques. Les résultats doivent être cohérent d’un point de vue commercial).
Si une API est idempotente, l’initiateur de l’appel peut réessayer en toute sécurité. Cela correspond à notre hypothèse générale. Fournir l’idempotence est quelque chose que les prestataires de services doivent faire.
Avoir l'idempotence peut garantir que notre interface ne sera pas affectée par diverses tentatives anormales ou des verrouillages de requêtes malveillantes.
3. L'interface a expiré, comment y remédier ?
Que devons-nous faire si notre appel à l’interface en aval expire ?
Il y a deux options à traiter :
Solution 1 : le système en aval fournit une interface de requête correspondante. Si l'interface expire, vérifiez d'abord l'enregistrement correspondant. S'il réussit, il passera par le processus de réussite. S'il s'agit d'un échec, il sera traité comme un échec.
En prenant notre exemple de transfert comme exemple, le système de transfert fournit une interface pour interroger les enregistrements de transfert. Si le système de canal appelle le système de transfert en heures supplémentaires, le système de canal vérifie d'abord l'enregistrement pour voir si le transfert a réussi ou échoué. En cas de succès, il suivra le processus réussi et réessayera de lancer le transfert s'il échoue.
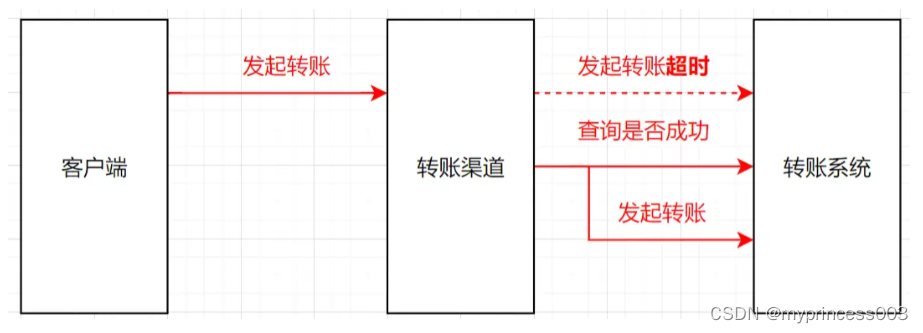
Solution 2 : l'interface en aval prend en charge l'idempotence. Si le système en amont appelle un délai d'attente, lancez simplement une nouvelle tentative.
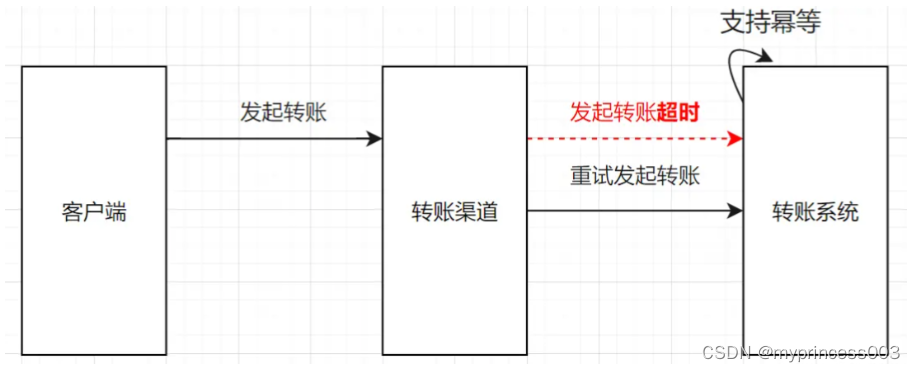
Les deux solutions sont plutôt bonnes, mais s'il s'agit d'un scénario de consommation répétée de MQ, la première solution n'est pas très appropriée, nous avons donc toujours besoin de l'interface externe du système en aval pour prendre en charge l'idempotence.
4. Comment concevoir l'idempotence
Puisque de nombreux scénarios doivent prendre en compte l'idempotence, comment concevoir l'idempotence ?
Un service idempotent exige que, quelle que soit l'extrême gravité de la demande répétée, elle soit cohérente. À ce stade, les conditions suivantes doivent être remplies :
Externe : renvoie exactement le même résultat
En interne : aucun changement dans son propre état
Pour le prestataire : À proprement parler, les champs de la requête doivent être exactement les mêmes, et le prestataire considère qu'il s'agit d'une requête répétée. Mais dans l'environnement actuel, nous n'avons peut-être pas d'exigences aussi strictes.Nous pensons généralement que tant que les paramètres commerciaux clés sont les mêmes, il s'agit d'une demande répétée et doit être traitée par idempotence.
Pour les appelants du service : le traitement des résultats idempotents doit être bien effectué et plusieurs requêtes renvoyant le même résultat doivent être traitées correctement
La conception idempotente doit être aussi simple, fiable et efficace que possible (trop de logique idempotente affectera la convivialité et les performances)
Simplicité : Le processus et la logique idempotents doivent être aussi simples et
fiables que possible : non seulement en fonctionnement normal, mais également dans certains scénarios anormaux. Sinon, la conception idempotente La signification sera considérablement réduite
. Efficacité : L'exécution de la logique idempotente ne peut pas être prend du temps. Pour certaines interfaces à forte concurrence, il est nécessaire de minimiser l'exécution fastidieuse de la logique idempotente.
La facilité d'utilisation et l'évolutivité de la conception générale des composants idempotents sont également importantes.
Idempotent signifie le caractère unique d’une demande. Quelle que soit la solution que vous utilisez pour concevoir l’idempotence, vous avez besoin d’un identifiant unique au monde pour marquer cette demande comme unique.
Si vous utilisez un index unique pour contrôler l'idempotence, alors l'index unique est unique
Si vous utilisez la clé primaire de la base de données pour contrôler l'idempotence, alors la clé primaire est unique
Si vous utilisez le verrouillage pessimiste, la balise sous-jacente est toujours un identifiant globalement unique
—— — ———————————
ID mondialement unique
ID mondialement unique, comment le générer ? Vous vous souvenez, comment l'ID de clé primaire de la base de données est-il généré ?
Oui, on peut utiliser l'UUID, mais les inconvénients de l'UUID sont plus évidents : l'espace occupé par sa chaîne est relativement grand, l'ID généré est trop aléatoire, la lisibilité est mauvaise et il n'y a pas d'incrément.
Nous pouvons également utiliser l'algorithme Snowflake (Snowflake) pour générer un identifiant unique.
L'algorithme Snowflake est un algorithme permettant de générer des identifiants distribués globalement uniques, et les identifiants générés sont appelés identifiants Snowflake. Cet algorithme a été créé par Twitter et est utilisé pour identifier les tweets.
Un identifiant Snowflake comporte 64 bits.
Bit 1 : Le bit le plus élevé de long en Java est le bit de signe, qui représente un nombre positif ou négatif. Un nombre positif est 0 et un nombre négatif est 1. Généralement, l'ID généré est un nombre positif, donc la valeur par défaut est 0.
Les 41 premiers bits suivants sont l'horodatage, indiquant le nombre de millisecondes depuis l'époque sélectionnée.
Les 10 bits suivants représentent l'ID de l'ordinateur, évitant ainsi les conflits.
Les 12 bits restants représentent le numéro de série de l'ID généré sur chaque machine, ce qui permet de créer plusieurs ID Snowflake dans la même milliseconde.

Bien entendu, l'identifiant unique au monde peut également utiliser l'Uidgenerator de Baidu ou la Feuille de Meituan.
Le processus de base de la conception idempotente
Le processus de traitement idempotent, en dernière analyse, consiste en fait à filtrer les requêtes reçues. Bien entendu, la requête doit avoir une étiquette d'identification globalement unique. Alors, comment juger si la demande a été reçue auparavant ? Stockez la demande et lors de la réception de la demande, vérifiez d'abord l'enregistrement de stockage, renvoyez le dernier résultat si l'enregistrement existe et traitez la demande s'il n'existe pas.
Le traitement idempotent général est le suivant :

5. Huit schémas pour réaliser l'idempotence Le
processus de base de la conception idempotente est similaire. Passons brièvement en revue les huit schémas pour la réalisation idempotente ~
select+insert+primary key/unique index conflict
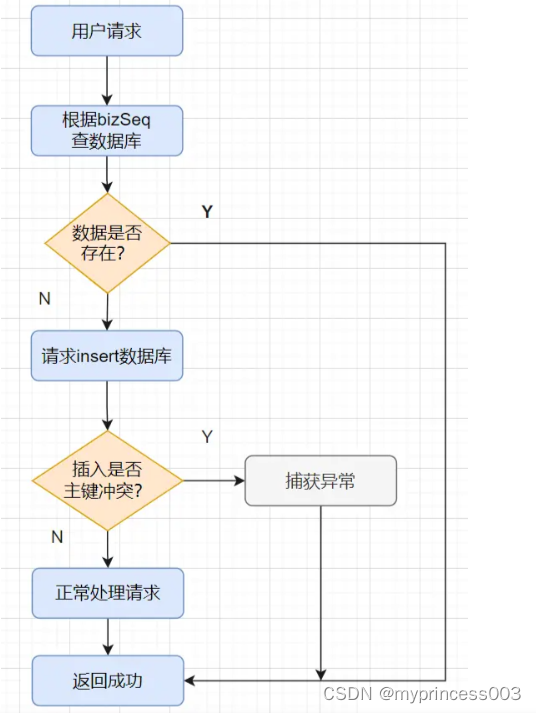
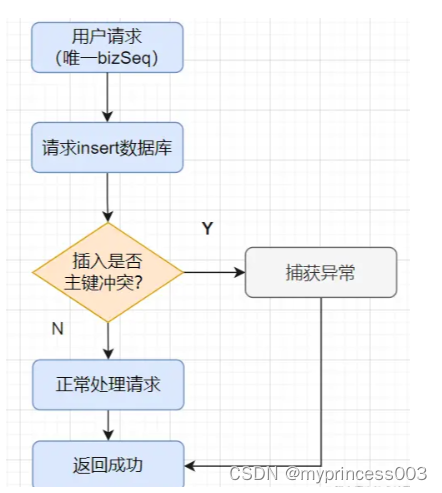
Dans le développement quotidien, afin de réaliser l'idempotence de l'interface de transaction, je l'ai implémenté comme ceci :
Lorsque la demande de transaction arrive, je sélectionnerai d'abord la table de flux de la base de données en fonction du champ bizSeq du numéro de série unique de la demande
Si les données existent déjà, interceptez la demande répétée et renvoyez directement le succès ;
si les données n'existent pas, effectuez l'insertion par insertion, si l'insertion réussit, renvoyez directement le succès, si l'insertion génère une exception de conflit de clé primaire, interceptez l'exception et puis retournez directement le succès.
L'organigramme est le suivant
/**
* 幂等处理
*/
Rsp idempotent(Request req){
Object requestRecord =selectByBizSeq(bizSeq);
if(requestRecord !=null){
//拦截是重复请求
log.info("重复请求,直接返回成功,流水号:{}",bizSeq);
return rsp;
}
try{
insert(req);
}catch(DuplicateKeyException e){
//拦截是重复请求,直接返回成功
log.info("主键冲突,是重复请求,直接返回成功,流水号:{}",bizSeq);
return rsp;
}
//正常处理请求
dealRequest(req);
return rsp;
}
Pourquoi avez-vous besoin de try...catch...pour intercepter les exceptions répétées après avoir déjà sélectionné la requête ?
En effet, dans un scénario à forte concurrence, lorsque deux requêtes sont sélectionnées, elles peuvent ne pas être trouvées, puis elles vont toutes au lieu d'insertion.
Bien entendu, il est également possible de remplacer la clé primaire de la base de données par un index unique, qui est un identifiant globalement unique.
Insertion directe + conflit clé primaire/index unique
Dans le schéma 5.1, la demande de transaction dans la table de flux sera d'abord vérifiée pour déterminer si elle existe, puis insérera l'enregistrement de la demande s'il n'existe pas. Si la probabilité de requêtes répétées est relativement faible, nous pouvons directement insérer la requête et utiliser le conflit clé primaire/index unique pour déterminer s'il s'agit d'une requête répétée.
/**
* 幂等处理
*/
Rsp idempotent(Request req){
try{
insert(req);
}catch(DuplicateKeyException e){
//拦截是重复请求,直接返回成功
log.info("主键冲突,是重复请求,直接返回成功,流水号:{}",bizSeq);
return rsp;
}
//正常处理请求
dealRequest(req);
return rsp;
}
Ne confondez pas tout le monde, il y a en fait une différence entre la conception anti-lourde et idempotente. L'anti-duplication vise principalement à éviter les données en double, il suffit d'intercepter les demandes en double. En plus d'intercepter les requêtes traitées, la conception idempotente nécessite également que le même résultat soit renvoyé à chaque fois pour la même requête. Cependant, dans de nombreux cas, leur traitement peut être similaire, mais la réponse est différente.
Machine à états idempotente
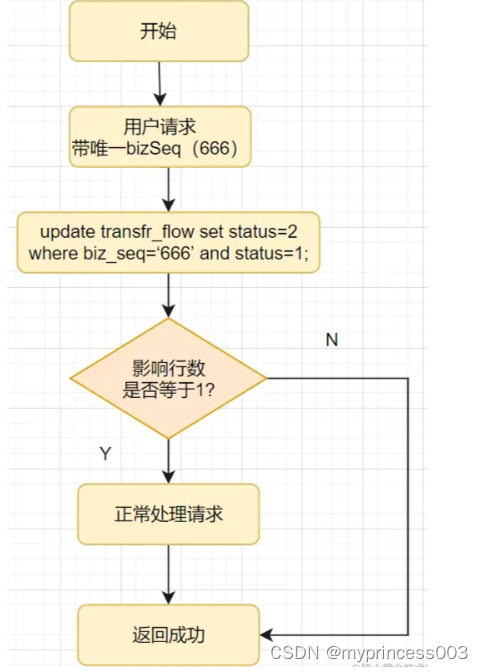
De nombreuses tables métier sont avec état. Par exemple, la table de flux de transfert aura 0 en attente, 1 en traitement, 2 en réussite et 3 en échec. Lorsque le flux de transfert est mis à jour, la mise à jour de l'état du flux est impliquée, c'est-à-dire que la machine à états (c'est-à-dire le diagramme de changement d'état) est impliquée. Nous pouvons utiliser la machine à états pour atteindre l'idempotence, voyons comment elle est mise en œuvre.
Par exemple, une fois le transfert réussi, le flux de transfert en cours est mis à jour vers un état réussi et le code SQL est écrit comme suit :
update transfr_flow set status=2 where biz_seq=‘666’ and status=1;
Rsp idempotentTransfer(Request req){
String bizSeq = req.getBizSeq();
int rows= "update transfr_flow set status=2 where biz_seq=#{bizSeq} and status=2;"
if(rows==1){
log.info(“更新成功,可以处理该请求”);
//其他业务逻辑处理
return rsp;
}else if(rows==0){
log.info(“更新不成功,不处理该请求”);
//不处理,直接返回
return rsp;
}
log.warn("数据异常")
return rsp:
}
状态机是怎么实现幂等的呢?
第1次请求来时,bizSeq流水号是 666 ,该流水的状态是处理中,值是 1 ,要更新为2-成功的状态 ,所以该update语句可以正常更新数据,sql执行结果的影响行数是1,流水状态最后变成了2。
第2请求也过来了,如果它的流水号还是 666 ,因为该流水状态已经2-成功的状态 了,所以更新结果是0,不会再处理业务逻辑,接口直接返回成功。
Les schémas d'extraction des tables anti-duplication
1 et 2 sont basés sur l'unicité de bizSeq sur la table de flux métier. Plusieurs fois, le numéro de série unique de notre table métier doit être généré par le système back-end, ou nous souhaitons que la fonction anti-duplication soit séparée de la table métier. À ce stade, nous pouvons créer une fonction anti-duplication distincte tableau. Bien entendu, la table anti-duplication utilise également le caractère unique de la clé primaire/de l'index. Si l'insertion dans la table anti-duplication entre en conflit, elle renverra directement le succès. Si l'insertion réussit, la demande sera traitée.
token token
token Le schéma de tokens comprend généralement deux phases de requête :
Le client demande à demander un jeton, et le serveur génère un jeton et renvoie
au client une demande de jeton, et le serveur vérifie le jeton.
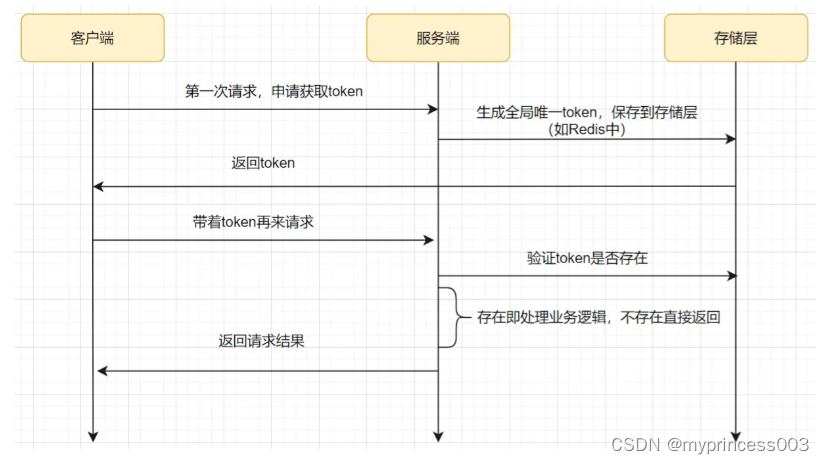
Le client lance une demande pour demander un jeton.
Le serveur génère un jeton unique au monde, l'enregistre dans Redis (généralement un délai d'expiration est défini), puis le renvoie au client.
Le client lance une demande avec le jeton.
Le serveur accède à redis pour confirmer si le jeton existe. Généralement, redis.del(token) est utilisé. S'il existe, il sera supprimé avec succès, c'est-à-dire que la logique métier sera traitée. Si la suppression échoue, l'entreprise la logique ne sera pas traitée et le résultat sera renvoyé directement.
Verrou pessimiste (tel que sélection pour mise à jour)
Qu'est-ce qu'un verrou pessimiste ?
En termes simples, c'est très pessimiste : chaque fois que j'exploite les données, j'ai l'impression que d'autres vont les modifier à moitié, donc chaque fois que j'obtiens les données, elles seront verrouillées. Le point officiel est que les ressources partagées ne sont utilisées que par un thread à la fois, les autres threads sont bloqués et les ressources sont transférées vers d'autres threads après utilisation.
Comment le verrouillage pessimiste contrôle-t-il l’idempotence ? Il s’agit du verrouillage, qui est généralement mis en œuvre conjointement aux transactions.
Voici un scénario commercial pour mettre à jour une commande :
En supposant que la commande soit trouvée en premier, si elle est en cours de traitement, l'affaire est traitée, puis le statut de la commande est mis à jour pour être terminé. Si la commande est retrouvée et qu'elle est en état de traitement, elle sera retournée directement
Le pseudocode global est le suivant :
begin; # 1.开始事务
select * from order where order_id='666' # 查询订单,判断状态
if(status !=处理中){
//非处理中状态,直接返回;
return ;
}
## 处理业务逻辑
update order set status='完成' where order_id='666' # 更新完成
commit; # 5.提交事务
Ce scénario est une opération non atomique. Dans un environnement à forte concurrence, une entreprise peut être exécutée deux fois :
Lorsqu'une requête A est en cours d'exécution, une autre requête B démarre également l'opération de jugement d'état. Parce que la requête A n'a pas encore eu le temps de changer d'état, la requête B peut également être exécutée avec succès, ce qui entraîne l'exécution d'une affaire deux fois.
Vous pouvez utiliser le verrouillage pessimiste de la base de données (sélectionner... pour la mise à jour) pour résoudre ce problème.
begin; # 1.开始事务
select * from order where order_id='666' for update # 查询订单,判断状态,锁住这条记录
if(status !=处理中){
//非处理中状态,直接返回;
return ;
}
## 处理业务逻辑
update order set status='完成' where order_id='666' # 更新完成
commit; # 5.提交事务
Le order_id doit être un index ou une clé primaire. Verrouillez simplement cet enregistrement. S'il ne s'agit pas d'un index ou d'une clé primaire, la table sera verrouillée !
Le verrouillage pessimiste verrouille une ligne de données lors de la même opération de transaction. Les autres requêtes ne peuvent qu'attendre. Si la transaction en cours prend beaucoup de temps, cela affectera grandement les performances de l'interface. Il n’est donc généralement pas recommandé d’utiliser le verrouillage pessimiste pour ce faire.
Verrouillage optimiste
Le verrouillage pessimiste présente des problèmes de performances, vous pouvez essayer le verrouillage optimiste.
Qu’est-ce que le verrouillage optimiste ?
Les verrous optimistes sont très optimistes lors de l'exploitation des données, pensant que d'autres ne modifieront pas les données en même temps, donc les verrous optimistes ne seront pas verrouillés. Jugez simplement quand la mise à jour est effectuée, si d'autres ont modifié les données pendant cette période.
Comment implémenter le verrouillage optimiste ?
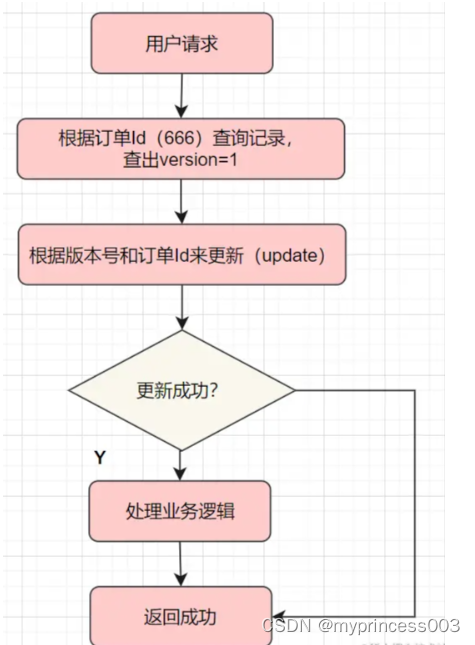
Il s'agit d'ajouter une colonne de numéro de version au tableau et de mettre à jour la version de l'enregistrement à chaque mise à jour (version=version+1). Le processus spécifique consiste d'abord à connaître le numéro de version actuel, puis lors de la mise à jour et à modifier les données, à confirmer s'il s'agit du numéro de version que l'on vient de découvrir et, si tel est le cas, à effectuer la mise à jour.
Par exemple, avant de mettre à jour, vérifiez d'abord les données et le numéro de version trouvé est version =1
select order_id,version from order where order_id='666';
Utilisez ensuite la version = 1 et l'ID de commande ensemble comme condition, puis mettez à jour
update order set version = version +1,status='P' where order_id='666' and version =1
La logique métier ne peut être traitée qu'une fois la dernière mise à jour réussie. Si la mise à jour échoue, la valeur par défaut est de répéter la demande et de revenir directement.
Pourquoi est-il recommandé que le numéro de version soit auto-incrémenté ?
Parce qu'il y a un problème ABA dans le verrouillage optimiste, si la version est toujours auto-croissante, il n'y aura pas de situation ABA.
Verrous distribués
La logique des verrous distribués pour atteindre l'idempotence est que lorsqu'une demande arrive, essayez d'abord d'obtenir un verrou distribué. En cas de succès, la logique métier sera exécutée. Sinon, si l'acquisition échoue, la demande sera rejetée et le la demande sera retournée directement. Le processus d'exécution est illustré dans la figure ci-dessous :
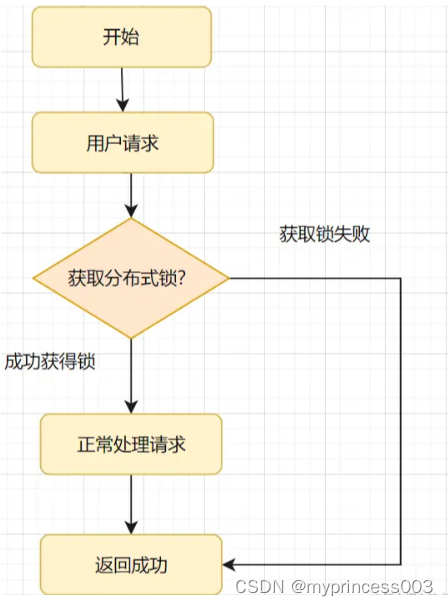
Les verrous distribués peuvent utiliser Redis ou ZooKeeper, mais Redis est meilleur car il est plus léger.
Le verrouillage distribué Redis peut être implémenté à l'aide de la commande SET EX PX NX + numéro de série unique. La clé du verrouillage distribué doit être l'identifiant unique de l'entreprise. Lorsque Redis exécute l'action de définition de la clé, le délai d'expiration doit être
défini Le délai d'expiration ne peut pas être trop court, il est trop court pour intercepter des requêtes répétées et ne peut pas être défini sur une durée trop longue, ce qui occuperait de l'espace de stockage.
6. Résumé
L'idempotence devrait être un gène pour les programmeurs qualifiés. C'est la principale considération lors de la conception d'un système, en particulier dans les systèmes de capitaux en ligne tels que les plateformes de paiement tierces, les banques et les sociétés financières sur Internet. Efficace, les données doivent être exactes, il ne peut donc y avoir aucun problème tel qu'une déduction excessive, un paiement excédentaire, etc., qui seront difficiles à gérer et réduiront considérablement l'expérience utilisateur.