Mushen 版の「手を使って学ぶディープラーニング」の学習ノートです。学習プロセスを記録しています。詳細な内容については書籍を購入してください。
B ステーションのビデオ リンク
オープンソース チュートリアル リンク
畳み込み層の複数入力複数出力チャネル
誰もが最も気にするハイパーパラメータの 1 つ:

RGB 画像は単なる行列ではなく、3 xhxw の形状です:

マルチ入力チャネルの計算プロセス:
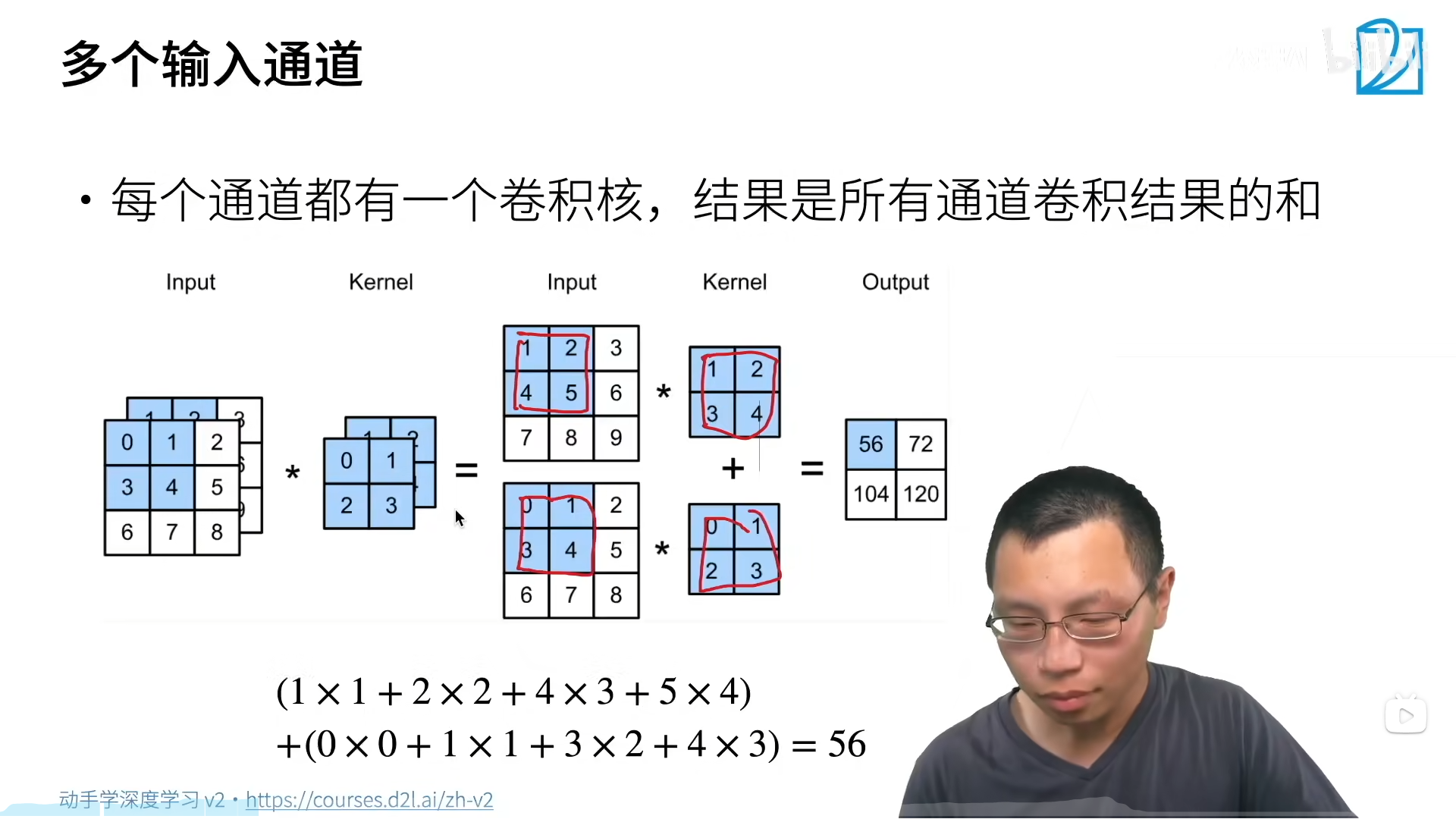

これまでのところ、入力チャネルがいくつあっても、単一の出力チャンネル 出力にも複数のチャンネルがあり、それぞれが出力チャンネルを生成する複数の 3D コンボリューション カーネルを持つことができます。
マルチ出力チャネルの計算プロセス:

各出力チャネルは異なるパターンを認識でき、入力チャネルのカーネルは入力内のパターンを認識して結合します:

1x1 畳み込み層の計算のみがチャネル上で発生します:
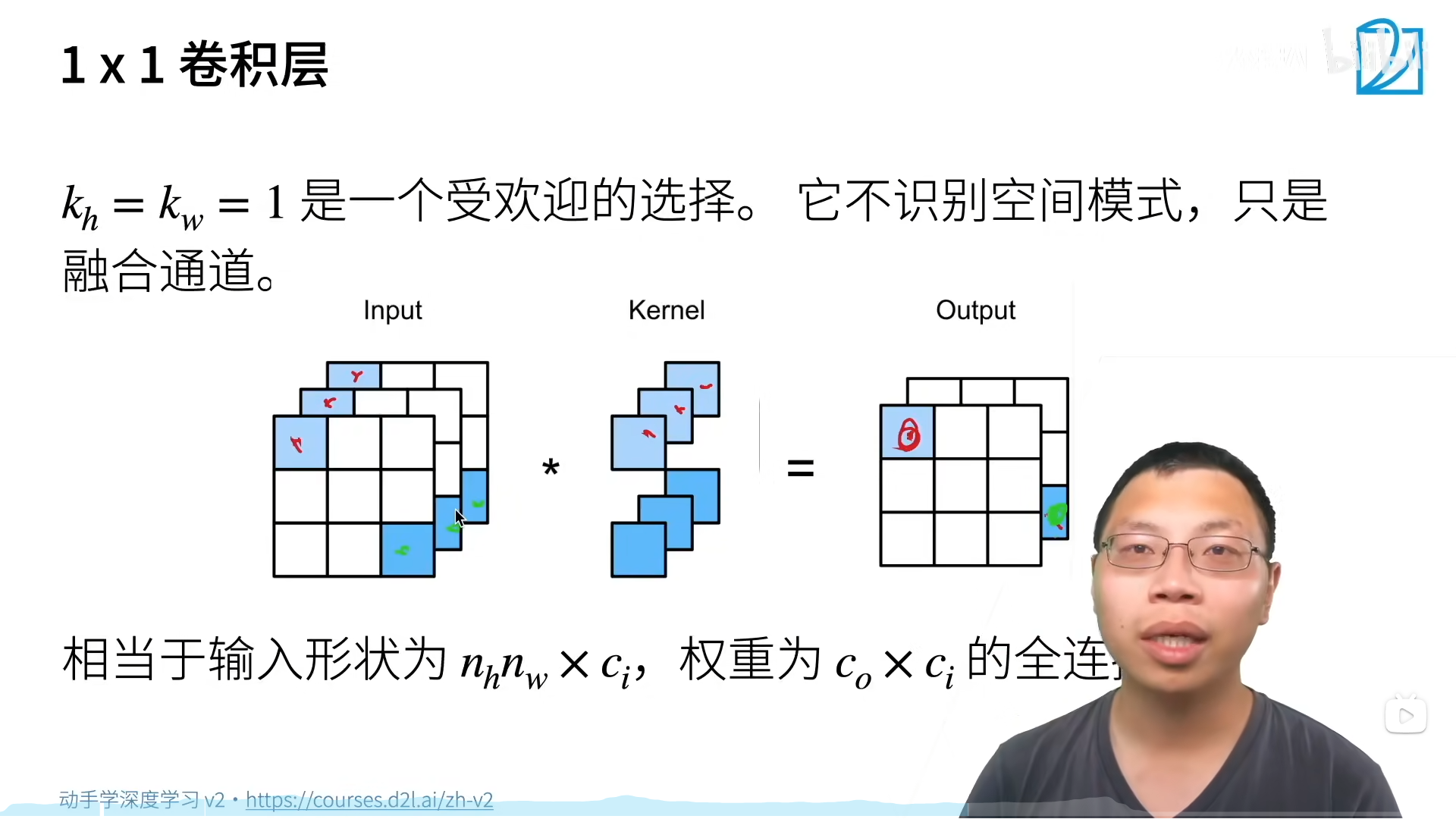
計算の複雑さ:

出力チャネルの数畳み込み層のハイパーパラメータの数です
各入力チャンネルには独立した 2 次元コンボリューション カーネルがあり、すべてのチャンネルの結果が加算されて出力チャンネルの結果が得られます。
各出力チャンネルには独立した 3D コンボリューション カーネルがあります

実践的な学習
複数の入力チャンネル
import torch
from d2l import torch as d2l
def corr2d_multi_in(X, K):
# 先遍历“X”和“K”的第0个维度(通道维度),再把它们加在一起
return sum(d2l.corr2d(x, k) for x, k in zip(X, K))
X = torch.tensor([[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]],
[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0]]])
K = torch.tensor([[[0.0, 1.0], [2.0, 3.0]], [[1.0, 2.0], [3.0, 4.0]]])
print(X.shape, K.shape)
corr2d_multi_in(X, K)
torch.Size([2, 3, 3]) torch.Size([2, 2, 2])
tensor([[ 56., 72.],
[104., 120.]])
複数の出力チャンネル
def corr2d_multi_in_out(X, K):
# 迭代“K”的第0个维度,每次都对输入“X”执行互相关运算。
# 最后将所有结果都叠加在一起
return torch.stack([corr2d_multi_in(X, k) for k in K], 0)
K = torch.stack((K, K + 1, K + 2), 0)
K.shape
torch.Size([3, 2, 2, 2])
corr2d_multi_in_out(X, K)
tensor([[[ 56., 72.],
[104., 120.]],
[[ 76., 100.],
[148., 172.]],
[[ 96., 128.],
[192., 224.]]])
1x1 コンボリューション
def corr2d_multi_in_out_1x1(X, K):
c_i, h, w = X.shape
c_o = K.shape[0]
X = X.reshape((c_i, h * w))
K = K.reshape((c_o, c_i))
# 全连接层中的矩阵乘法
Y = torch.matmul(K, X)
return Y.reshape((c_o, h, w))
X = torch.normal(0, 1, (3, 3, 3))
K = torch.normal(0, 1, (2, 3, 1, 1))
Y1 = corr2d_multi_in_out_1x1(X, K)
Y2 = corr2d_multi_in_out(X, K)
assert float(torch.abs(Y1 - Y2).sum()) < 1e-6
Y1.shape, Y2.shape
(torch.Size([2, 3, 3]), torch.Size([2, 3, 3]))
# 调用pytorch
from torch import nn
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1, stride=2) # 输出通道、输入通道、卷积核尺寸、步幅大小