序文
この記事では、SQL 言語の概要内容を中心に、SQL 言語における構文定義やデータ形式の定義について説明します。
1. SQLの概要
1. SQL言語の出現と発展
1972 年、IBM は実験的なリレーショナル データベース管理システム SYSTEM R の開発を開始しました。このシステムには、と呼ばれるクエリ言語が搭載されていました。四角(クエリを関係式として指定する) 言語。より多くの数学記号を使用します。
1974 年、ボイスとチェンバリンは SQUARE を次のように修正しました。続編(構造化英語クエリ言語) 言語。のちにSEQUELと略称されるようになった。SQL( Structured Query Language )、つまり「Structured Query Language」ですが、SQL の発音は依然として「続編」です。今では SQL が標準になりました。
2. SQL 言語は、リレーショナル データベースの 3 レベルのスキーマをサポートします。
ユーザーはSQL言語を使用して基本的なテーブルとビューを操作します
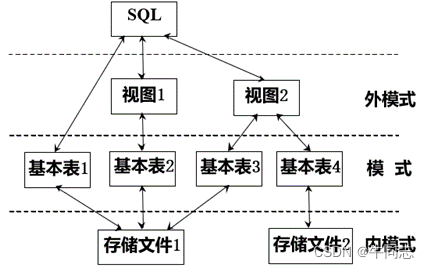
(1) 基本テーブル
1.単独で独立して存在するテーブル、テーブルに対応するリレーションシップ。(リレーショナル データベースでは、テーブルは「リレーション」と呼ばれることがよくあります)
2. 1 つ (または複数) の基本テーブルがストレージ ファイルに対応します。
3. テーブルには複数のインデックスを含めることができ、インデックスもストレージ ファイルに格納されます。
(2) ファイルの保存
1. ストレージ ファイルの論理構造は、リレーショナル データベースの内部モードを構成します。
2.保存されたファイルの物理構造は任意であり、ユーザーには透過的です。。
(3) ビュー
1. 1 つまたは複数のベーステーブルまたはビューから派生したテーブル
2.対応するデータは保存せず、ビューの定義のみを保存する仮想テーブルです。
3. SQL言語の特徴
(1) 総合的かつ一体的
1.SQL言語含むデータ定義言語(DDL、データ定義言語)、データ操作言語(DML、データ操作言語)、データ制御言語( DCL、データ制御言語) の機能が 1 つにまとめられています。
2. データベースのライフサイクルのすべてのアクティビティを独立して完了できます。
1.定义和修改、删除关系模式,定义和删除视图,插入数据,建立数据库;
2.对数据库中的数据进行查询和更新;
3.数据库重构和维护
4.数据库安全性、完整性控制,以及事务控制
5.嵌入式SQL和动态SQL定义
3.ユーザーデータベースの運用開始後、データベースの運用に影響を与えることなく、必要に応じていつでもモードを段階的に変更できます。。
4. 統合データ演算子
(2) 非手続き型言語
SQL言語を使用する場合、ユーザーは「何をするか」を提案するだけでよく、アクセスパスやデータへのアクセス方法を理解する必要はありません。アクセスパスの選択とSQLの操作処理はシステムが自動で完了。
(3) セット指向
SQL は集合演算を使用します。
1.操作对象、查找结果可以是元组的集合
2.一次插入、删除、更新操作的对象可以是元组的集合
(4) 同じ文法構造で複数の用法を提供する
SQL は、オンラインで対話的に使用するために独立して使用できる独立した言語です。
SQL も埋め込み言語です。SQL は、プログラマーがプログラムを設計するときに使用できる高級言語 (C、C++、Java など) プログラムに埋め込むことができます。
4. SQLの構文概要
(1) SQLの中核となる動詞
| SQL関数 | オペレーター |
| データクエリ | 選択する |
| データ定義 | 作成、変更、削除 |
| データ操作 | 挿入、更新、削除 |
| データ管理 | 許可、取り消し |
(2) SQL言語の記述規則
1.SQL关键字不区分大小写
2.对象名和列名不区分大小写
3.字符值和日期值区分大小写
4.一条SQL语句可以单行或多行编写
2. データ定義
SQLのデータ定義機能には、データベース定義、テーブル定義、ビュー、インデックスの定義が含まれます。
| 操作オブジェクト | 作成する | 消去 | 改訂 |
| データベース | データベースの作成 | データベースを削除 | |
| 表面 | テーブルの作成 | ドロップテーブル | 他の机 |
| 索引 | インデックスの作成 | ドロップインデックス | |
| ビュー | ビューの作成 | ドロップビュー |
1.モード
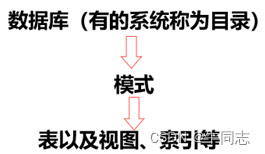
(1) モードの概念
論理データ構造またはオブジェクトのコレクション
(2) パターンの関連ルール
1. スキーマはユーザーに対応し、スキーマは 1 人のデータベース ユーザーのみが所有でき、スキーマの名前はユーザーの名前と同じになります。
2. 通常、ユーザーが作成したデータベース オブジェクトは、ユーザーと同じ名前でスキーマに保存されます。
3. 同じスキーマ内のデータベース オブジェクトの名前は一意である必要がありますが、異なるスキーマ内のデータベース オブジェクトは同じ名前を持つことができます。
4. デフォルトでは、ユーザーが参照するオブジェクトは、それ自体と同じ名前を持つスキーマ内のオブジェクトです。別のスキーマ内のオブジェクトを参照したい場合は、オブジェクト名の前にオブジェクトが属するスキーマを指定する必要があります。 。
(3) スキーマを定義する
例 1:
CREATE SCHEMA “S-T” AUTHORIZATION WANG;
ユーザー WANG の学生コースを定義する控えめ"
例 2:
CREATE SCHEMA AUTHORIZATION WANG;
例 2 ではスキーマ名が指定されておらず、スキーマ名のデフォルトはユーザー名です。
スキーマを定義すると、実際には名前空間が定義されます。, このスペースでは、基本的なテーブル、ビュー、インデックスなど、スキーマに含まれるデータベース オブジェクトを定義できます。
CREATE TABLE 、 CREATE VIEW および GRANT 句は CREATE SCHEMA で使用できます。
スキーマを作成するの標準構文規則は次のとおりです。
CREATE SCHEMA <模式名> AUTHORIZATION <用户名>[<表定义子句>|<视图定义子句>|<授权定义子句>]
例 3:
CREATE SCHEMA TEST AUTHORIZATION ZHANG
CREATE TABLE TAB1 (COL1 SMALLINT,
COL2 INT,
COL3 CHAR(20),
COL4 NUMERIC(10,3),
COL5 DECIMAL(5,2) );
ユーザー ZHANG に対してスキーマ TEST が作成され、その中にテーブル TAB1 が定義されます
(テーブルの定義については後述します)。
(4) 削除モード
削除モードの標準構文規則は次のとおりです。
DELETE SCHEMA <模式名> <CASCADE|RESTRICT>
1. CASCADE (カスケード) は、
スキーマの削除中に、スキーマ内のすべてのデータベース オブジェクトを削除します。
2. RESTRICT (制限)
スキーマに下位のデータベース オブジェクト (テーブル、ビューなど) が定義されている場合、削除ステートメントの実行を拒否します。
スキーマに従属オブジェクトがない場合にのみ実行されます。
2. データ型(フィールド)
属性にどのデータ型を選択するかは、実際の状況に応じて、一般に次の 2 つの側面から決まります。
1.取值范围
2.做哪些运算
3. 基本テーブル
(1) 基本テーブルの定義
命名規則と規則 (テーブル名と列名):
1.必须以字母开头
2.1-30个字符长度
3.只允许包含A–Z, a–z, 0–9, _, $, and #
4.在一个模式内保证命名的唯一
5.不能使用Oracle内部的关键字
一般的な形式は次のとおりです。
CREATE TABLE <表名>
(<列名> <数据类型> [列级完整性约束条件]
,[<列名> <数据类型> [列级完整性约束条件]]
……
,[<表级完整性约束性条件>]);
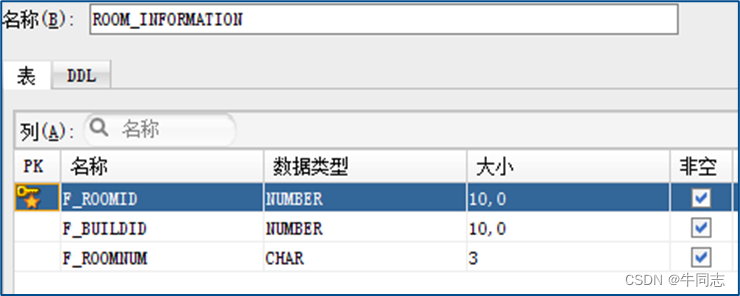
例 1:
CREATE TABLE ROOM_INFORMATION
(
F_ROOMID NUMBER(10,0) NOT NULL
,F_BUILDID NUMBER(10,0) NOT NULL
,F_ROOMNUM CHAR(3) NOT NULL
,CONSTRAINT ROMM_INFORMATION_PK PRIMARY KEY
(
F_ROOMID
)
ENABLE
);
(2) 基本テーブルの修正
ベーステーブルの一般的な形式を変更します。
ALTER TABLE <表名>
[ADD <新列名> <数据类型> [完整性约束]]
[DROP <完整性约束名>]
[ALTER COLUMN <列名> <数据类型>];
で
1.<表名>是要修改的基本表。
2.ADD子句用于增加新列和新的完整性约束条件
3.DROP子句用于删除指定的完整性约束条件
4.ALTER COLUMN子句用于修改原有的列定义。包括修改列名和数据类型。
例 1:
ALTER TABLE ROOM_INFORMATION ADD F_ROOMATTR VARCHAR2(10);
ルーム属性フィールドの列を ROOM_INFORMATION に追加します。データ型は varcr2(10) です。
例 2:
ALTER TABLE ROOM_INFORMATION ALTER COLUMN F_ROOMATTR VARCHAR2(20);
新しく追加された部屋属性フィールドは、varchar(10) では現在の値を格納するのに十分ではないため、varchar2(20) に拡張する必要があります。
注:
基本テーブルに既存のデータがあるかどうかに関係なく、新しく追加された列はすべて null 値になります。
元の列定義を変更すると、既存のデータが破壊される可能性があります。
(3) 基本テーブルの削除
一般的な形式は次のとおりです。
DROP TABLE <表名> [RESTRICT|CASCADE];
1.デフォルトは制限です。
2. RESTRICT が選択されている場合: テーブルの削除には制限があります。
削除する基本テーブルは、他のテーブルの制約によって参照できません。(CHECK、FOREIGN KEY、その他の制約など)、ビュー、トリガー (トリガー)、ストアド プロシージャや関数などが存在しない可能性があります。テーブルに依存するオブジェクトがある場合、そのテーブルを削除することはできません。
3. カスケードを選択した場合:その後、テーブルの削除に制限はありません。基本テーブルを削除すると、ビューなどの関連する依存オブジェクトも一緒に削除されます。
4. 索引
インデックス: キー (テーブルまたはビュー内の 1 つ以上の列から生成) とポインター (データの保存場所にマップするポインター) が含まれます。
(1) インデックスのルール
1. インデックスの作成とメンテナンスは DBA と DBMS によって行われます。
- インデックスの作成と取り消しは DBA またはテーブルの所有者によって行われ、他のユーザーは自由にインデックスを作成したり取り消したりすることはできません。
- インデックスはシステムによって自動的に選択され、維持されます。(ユーザーはインデックスの使用を指定する必要はなく、インデックスを開いたり、インデックスの再インデックス操作を実行したりする必要もありません。これらのタスクは DBMS によって自動的に完了します)。
2. インデックスを作成するかどうかは、テーブルのデータ サイズとクエリの要件によって決まります。
- 基本テーブルのレコード数が多く、レコードが長いほど、インデックスの作成が必要になり、インデックス作成後のクエリの高速化効果が顕著になります。
- レコードが少ない基本的なテーブルの場合、インデックスを作成しても意味がありません。
- インデックスは、データ クエリまたはデータ処理の要件に従って作成する必要があります (クエリ頻度が高く、リアルタイム要件が高いデータの場合は、インデックスを確立する必要があります。それ以外の場合は、インデックス作成の問題を考慮する必要はありません)。
3. 基本的なテーブル。インデックスを作成しすぎないでください。
- インデックス ファイルはファイル ディレクトリとストレージ領域を占有し、インデックスが多すぎるとシステムの負荷が増加します。
- インデックスはそれ自身で維持する必要があり、基本テーブルのデータが追加、削除、または変更された場合は、基本テーブルとの整合性を保つためにインデックス ファイルもそれに応じて変更する必要があります。
- インデックスが多すぎると、データの追加、削除、変更の速度に影響します。
(2) インデックスの使用を避ける
⑴ 包含太多重复值的列;
⑵ 查询中很少被引用的列;
⑶ 值特别长的列;
⑷ 查询返回率很高的列(where sex=‘M’);
⑸ 具有很多NULL值的列;
⑹ 需要经常插、删、改的列;
⑺ 记录较少的基本表;
⑻ 需进行频繁、大批量数据更新的基本表。
(3) インデックスを構築する
一般的な形式は次のとおりです。
CREATE [UNIQUE][CLUSTERED] INDEX <索引名>
ON <表名>(<列名>[<次序>][,<列名>[<次序>]]…);
1. インデックスはテーブルの 1 つ以上の列に構築でき、列名はカンマで区切られます。各 <column name> の後に、<order> を使用してインデックス値の並べ替え順序を指定することもできます。これには、ASC (昇順、デフォルトは昇順) または DESC (降順) を指定できます。
2.個性的このインデックスの各インデックス値が一意のデータ レコードのみに対応することを示します。
3.クラスター化された構築されるインデックスがクラスター化インデックスであることを示します。いわゆるクラスター化インデックスとは、インデックス項目の順序がテーブル内のレコードの物理的な順序と一致するインデックス構成を指します。
(4) インデックスを削除する
一般的な形式:
DROP INDEX <索引名>;
5. 見る
(1) ビューの作成
一般的な形式。
CREATE VIEW <视图名> [(<列名>[,<列名>]…)]AS
<子查询>[WITH CHECK OPTION];
知らせ:
- サブクエリには任意の複雑な SELECT ステートメントを使用できますが、ORDER BY 句と DISTINCT 句は通常は許可されません。
- WITH CHECK OPTION は、ビューに対して UPDATE、INSERT、および DELETE 操作を実行するときに、更新、挿入、または削除された行がビュー定義の述語条件 (つまり、サブクエリの条件式) を満たしていることを確認する必要があることを意味します。
(2) ビューの削除
一般的な形式:
DROP VIEW <视图名> [CASCADE];
ビューが削除されると、ビューの定義がデータ ディクショナリから削除されます。他のビューがこのビューからエクスポートされる場合は、CASCADE カスケード削除ステートメントを使用して、このビューとそこから派生したすべてのビューを削除します。
基本テーブルを削除すると、基本テーブルから派生したビュー(定義)はすべて削除されませんが、すべて使用できなくなります。これらのビュー (定義) を削除するには、DROP VIEW ステートメントを使用する必要があります。
(3) ビューを更新する
1. ビューを介したデータの挿入、削除、および変更を指します。
2. ビューは仮想テーブルであるため、ビューの更新は最終的に基本テーブルの更新に変換されます。
3. ユーザーが意図的か非意図的かを問わず、ビューを通じてデータを更新し、ビューのスコープに属さない基本テーブル データを操作することを防ぐために、ビューの定義時に [WITH CHECK OPTION] 句を追加できます。 。
ビューでのデータ更新を許可しない操作:
1.由两个以上基本表导出的视图
2.视图的列来自列表达式函数
3.视图中有分组子句或使用DISTINCT短语
4.视图定义中有嵌套查询,且内层查询中涉及与外层一样的导出该视图的基本表
5.在一个不允许更新的视图上定义的视图
要約する
読者の皆様は、記事が不適切な場合は修正していただけますようお願いいたします。
データベースの基本概念について質問がある場合は、以下を参照してください。
1.リレーショナル データベース (2) - リレーショナル代数
2.リレーショナル データベース (1) - リレーショナル データ モデルと関係
3.データベース システムの概要