YOLO シリーズのターゲット検出アルゴリズムのデバッグ プロセスは以前に完了しており、今日は主にすべてのデバッグを要約します。
ここでの conda 環境についてはここでは繰り返しません。requirement.txt ファイルを直接使用するだけです。また、参照することもできますYOLOX 5の設定プロセスへ
データセットの処理
YOLOv5 には独自のデータセット形式があり、ブロガーのデータセットは COCO 形式であるため、独自に YOLO 形式に変換する必要があります。
次のコードを変更する必要があります:
COCO アノテーション ファイル: JSON ファイル アドレス
parser.add_argument('--json_path',default='/data/datasets/coco/annotations/instances_train2017.json', type=str,help="input: coco format(json)")
生成されたYOLO形式アノテーションファイルアドレス:TXTファイルアドレス
parser.add_argument('--save_path', default='/home/ubuntu/outputs/yolov5/yolov5/train', type=str,help="specify where to save the output dir of labels")
保存データセットの対応アドレス:train2017.txt
list_file = open(os.path.join(ana_txt_save_path, 'train2017.txt'), 'w')
データセットのイメージアドレスを書き込みます。
list_file.write('/data/datasets/coco/images/train2017/%s.jpg\n' % (head))
完全なコードは次のとおりです。
import os
import json
from tqdm import tqdm
import argparse
parser = argparse.ArgumentParser()
# 这里根据自己的json文件位置,换成自己的就行
parser.add_argument('--json_path',
default='/data/datasets/coco/annotations/instances_train2017.json', type=str,
help="input: coco format(json)")
# 这里设置.txt文件保存位置
parser.add_argument('--save_path', default='/home/ubuntu/outputs/yolov5/yolov5/train', type=str,
help="specify where to save the output dir of labels")
arg = parser.parse_args()
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = box[0] + box[2] / 2.0
y = box[1] + box[3] / 2.0
w = box[2]
h = box[3]
# round函数确定(xmin, ymin, xmax, ymax)的小数位数
x = round(x * dw, 6)
w = round(w * dw, 6)
y = round(y * dh, 6)
h = round(h * dh, 6)
return (x, y, w, h)
if __name__ == '__main__':
json_file = arg.json_path # COCO Object Instance 类型的标注
ana_txt_save_path = arg.save_path # 保存的路径
data = json.load(open(json_file, 'r'))
if not os.path.exists(ana_txt_save_path):
os.makedirs(ana_txt_save_path)
id_map = {
} # coco数据集的id不连续!重新映射一下再输出!
with open(os.path.join(ana_txt_save_path, 'classes.txt'), 'w') as f:
# 写入classes.txt
for i, category in enumerate(data['categories']):
f.write(f"{
category['name']}\n")
id_map[category['id']] = i
# print(id_map)
# 这里需要根据自己的需要,更改写入图像相对路径的文件位置。
list_file = open(os.path.join(ana_txt_save_path, 'train2017.txt'), 'w')
for img in tqdm(data['images']):
filename = img["file_name"]
img_width = img["width"]
img_height = img["height"]
img_id = img["id"]
head, tail = os.path.splitext(filename)
ana_txt_name = head + ".txt" # 对应的txt名字,与jpg一致
f_txt = open(os.path.join(ana_txt_save_path, ana_txt_name), 'w')
for ann in data['annotations']:
if ann['image_id'] == img_id:
box = convert((img_width, img_height), ann["bbox"])
f_txt.write("%s %s %s %s %s\n" % (id_map[ann["category_id"]], box[0], box[1], box[2], box[3]))
f_txt.close()
# 将图片的相对路径写入train2017或val2017的路径
list_file.write('/data/datasets/coco/images/train2017/%s.jpg\n' % (head))
list_file.close()
生成されたデータセット アノテーション ファイルの形式は次のとおりです。
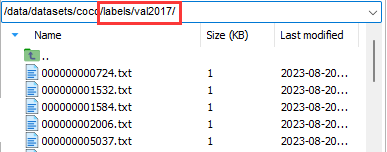
このフォルダーの下には、データに対応するファイル val2017.txt もあります。内容は次のとおりです。
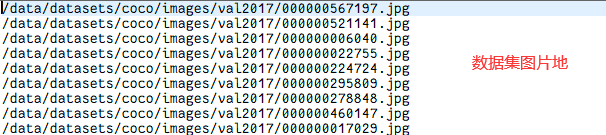
つまり、データセットの構造は次のとおりです。
images
train2017
XXX.jpg
val2017
XXX.jpg
labels
train2017
XXX.txt
train2017.txt
val2017
XXX.txt
val2017.txt
この時点で、データセットの処理は完了します。
YOLOv5 のデバッグ
データセットの処理が完了した後、トレーニング プロセスでは、対応するパラメーターとファイル構成を変更するだけで済みます。
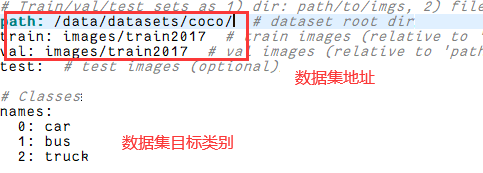
まず、coco128.yaml ファイルを変更し、次のように変更します。
次に、使用するモデルを設定します。YOLOv5 は YOLOv5s、YOLOv5m、YOLOv5l、YOLOvx の 4 つのバージョンに分かれており、順番にパフォーマンスが向上します。ブロガーは YOLOv5l バージョンを選択し、同時に YOLOv5l のウェイト ファイルをダウンロードします。
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='/data/programs/yolov5/yolov5l.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='/home/ubuntu/outputs/yolov5/yolov5/models/yolov5l.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
次に、yolov5l.yaml ファイル内のカテゴリの数を変更します。

その後、実行可能になります。ここでは、epoch=100、batch-size=16 に設定します。ここでも、YOLOX はビデオ メモリを実際に消費しますが、終了後に実行できます。
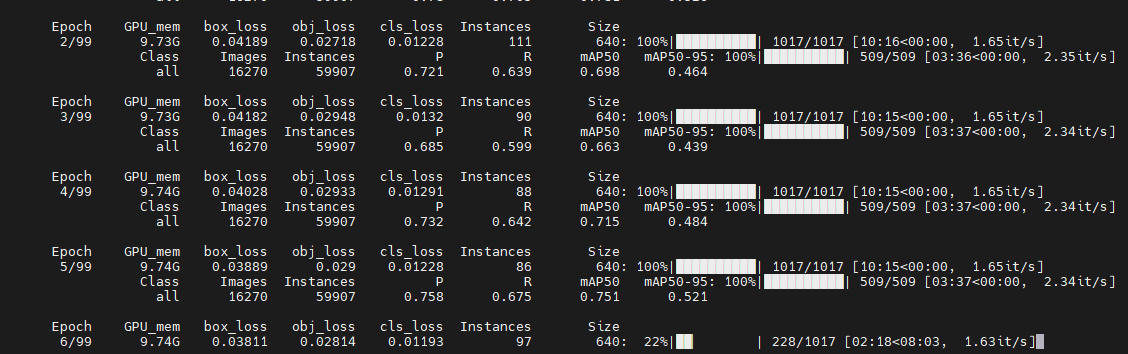
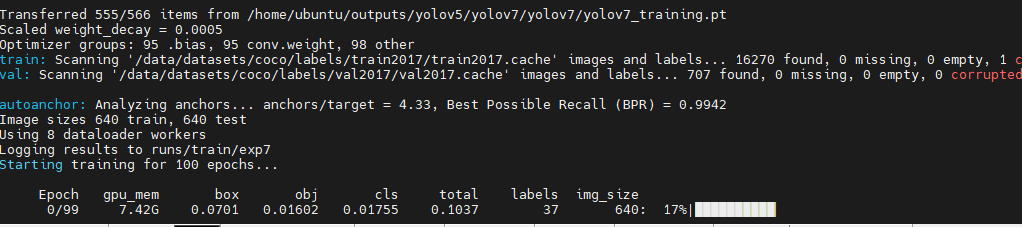
YOLOv7 のデバッグ
yolov5 をベースにした以前のデータ セットの構成が完了したので、YOLOv7 のデバッグがよりスムーズになります。まず、構成ファイルを変更し、train.py を見つけて、必要なファイルを確認して変更します。
ウェイト ファイル、つまりウェイトを使用するかどうかを選択します。ウェイト ファイル、つまりウェイトを使用すると、トレーニングが大幅に高速化され、初期値が高く、最終的にはあまり変化しない可能性があります。使用しない場合は、からのトレーニングを意味しますスクラッチの場合、トレーニングは遅くなる可能性があり、トレーニング時間は長くなります。さらに、YOLOv7 には移行学習バージョンも提供されており、こちらの方が使いやすいです。つまり、重みを使用するyolov7_training.pt
parser.add_argument('--weights', type=str, default='', help='initial weights path')
parser.add_argument('--cfg', type=str, default='/home/ubuntu/outputs/yolov5/yolov7/yolov7/cfg/training/yolov7.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/coco.yaml', help='data.yaml path')
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.p5.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=100)
次に、yolov7.yamlファイルを修正し、修正しnum_class=3ます
coco.yamlファイルを変更する
train: /data/datasets/coco/labels/train2017/train2017.txt # 118287 images
val: /data/datasets/coco/labels/val2017/val2017.txt # 5000 images
# number of classes
nc: 3
# class names
names: [ 'car', 'bus', 'truck' ]
そうすればうまくいきます。
ブレークポイントトレーニング
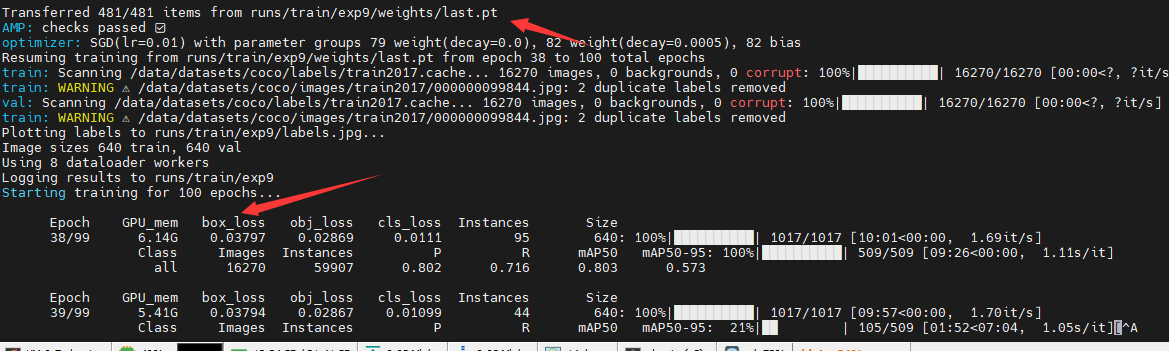
トレーニング プロセス中に、さまざまな理由でトレーニングが中断されることがよくあります。この問題を解決するために、YOLO シリーズ アルゴリズムはブレークポイント トレーニングを通じてトレーニングを再開します。YOLOv5 を例として、ファイル内で再開パラメーターを True に指定し、重みパラメーターを設定します。train.pyto トレーニング終了前のウェイトファイルのパスです。
parser.add_argument('--weights', type=str, default='/home/ubuntu/outputs/yolov5/yolov5/runs/train/exp9/weights/last.pt', help='initial weights path')
parser.add_argument('--resume', nargs='?', const=True, default=True, help='resume most recent training')