Yellowbrick は、Scikit-Learn API を拡張して視覚化を機械学習ワークフローに組み込む新しい Python ライブラリです。
Yellowbrick は、Scikit-Learn、Matplotlib、Numpy などの多くのサードパーティ ライブラリに依存する必要があります。
Yellowbrick は、Scikit-Learn を視覚的な分析および診断ツールで拡張する、オープンソースの純粋な Python プロジェクトです。また、Yellowbrick API は matplotlib をラップして、公開可能なグラフとインタラクティブなデータ探索を作成しながら、開発者がグラフをきめ細かく制御できるようにします。ユーザーにとって、Yellowbrick は機械学習モデルのパフォーマンス、安定性、予測値の評価に役立ち、機械学習ワークフロー全体にわたる問題の診断を支援します。
最近では、ワークフローの多くが、グリッド検索方法、標準化された API、GUI ベースのアプリケーションを通じて自動化されています。ただし、実際には、徹底的な検索よりも人間の直観と指導の方が効率的に高品質のモデルを磨き上げることができます。モデル選択プロセスを視覚化することで、データ サイエンティストは最終的な解釈可能なモデルに移行し、落とし穴を回避できます。
Yellowbrick ライブラリは、データ サイエンティストがモデル選択プロセスをガイドできるようにする機械学習用の診断視覚化プラットフォームです。Yellowbrick は、新しいコア オブジェクトである視覚化ツールを使用して Scikit-Learn API を拡張します。視覚化ツールを使用すると、Scikit-Learn Pipeline パイプラインの一部として視覚モデルを適合および変換でき、高次元データの変換全体を通じて視覚的な診断を提供できます。
機械学習の視覚化は、機械学習の結果を理解し、モデルを改善するためにどのようなアクションをとるべきかを知るのに役立ちます。それがイエローブリックの使命です。
Yellowbrick を使用すると、次のことが簡単になります。
1. 機能の選択
2. ハイパーパラメータを調整する
3. モデルのスコアを解釈する
4. テキストデータの可視化
インストール
Yellowbrick ライブラリをインストールする最も簡単な方法は、pip次のコマンドを使用することです。
pip install yellowbrickイエローブリックを使用する
Yellowbrick API は、Scikit-Learn と完全に連携するように特別に設計されています。以下は、Scikit-Learn と Yellowbrick を使用した一般的なワークフローの例です。
Yellowbrickのチュートリアルディレクトリは以下の通りです、参考URL:
https://pythonhosted.org/ yellowbrick/examples/examples.html

以下の図はYellowbrickのビジュアライザモジュールのフローチャートです。
機能の視覚化
この例では、Rank2D が特定のメトリックまたはアルゴリズムを使用してデータセット内の各特徴のペアごとの比較を実行し、左下の三角形プロットの形式でそれらのランクを返す方法を示します。
from yellowbrick.features import Rank2Dvisualizer = Rank2D(features=features, algorithm='covariance')visualizer.fit(X, y) # Fit the data to the visualizervisualizer.transform(X) # Transform the datavisualizer.poof() # Draw/show/poof the data
より多くの機能を備えていることが、必ずしもより優れたモデルであるとは限りません。モデルの特徴が多いほど、モデルは分散による誤差の影響を受けやすくなります。したがって、効果的なモデルを生成するために必要な特徴量を最小限に抑えたいと考えています。
特徴を削除する一般的なアプローチは、モデルにとって最も重要でない特徴を削除することです。次に、相互検証中にモデルのパフォーマンスが実際に向上したかどうかを再評価します。
特徴の重要度は、モデルの特徴の相対的な重要性を視覚化するのに役立つため、このタスクに適しています。
from yellowbrick.model_selection import FeatureImportancesviz = FeatureImportances(model)viz.fit(X, y)viz.show()
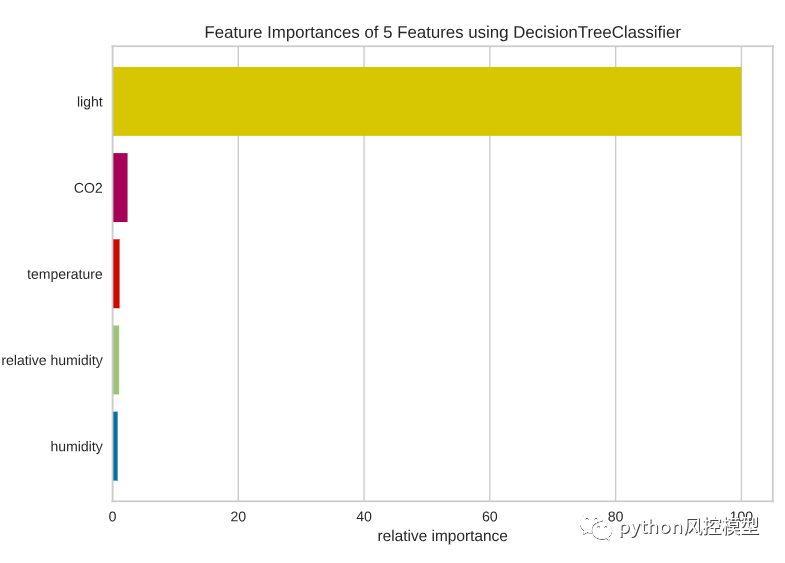
DecisionTreeClassifier の最も重要な機能は光であり、次に CO2、温度が続くようです。
データには多くの特徴が含まれていないことを考慮して、湿度は削除しません。ただし、モデルに多くの特徴がある場合は、分散によるエラーを防ぐために、モデルにとって重要ではない特徴を削除する必要があります。
下の画像は、他のイエローブリック機能を視覚化した例です。
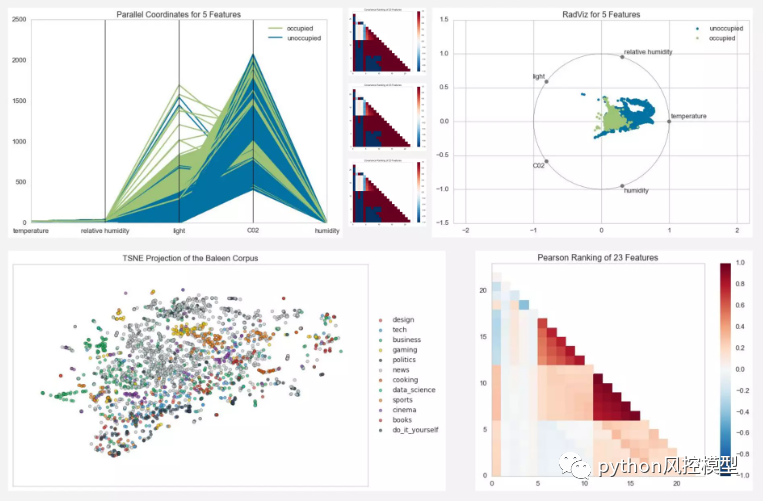
モデルの視覚化
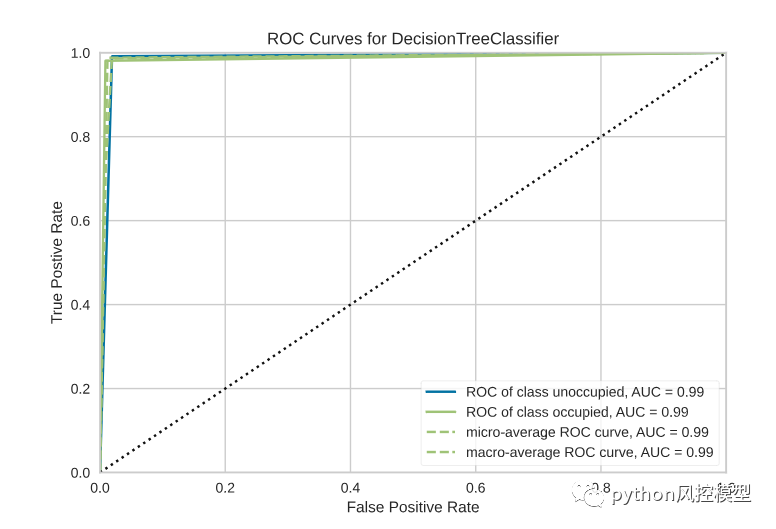
この例では、Scikit-Learn 分類器をインスタンス化してから、Yellowbrick の ROCAUC クラスを使用して、感度と特異性の間の分類器のトレードオフを視覚化します。
from sklearn.svm import LinearSVCfrom yellowbrick.classifier import ROCAUCmodel = LinearSVC()model.fit(X,y)visualizer = ROCAUC(model)visualizer.score(X,y)visualizer.poof()
データを視覚化する
ランキング機能
データ内の各特徴のペアはどの程度相関していますか? 特徴の 2 次元ランキングでは、一度に特徴ペアを考慮するランキング アルゴリズムが利用されます。ピアソン相関を使用してスコアを付け、共線関係を検出しました。
from yellowbrick.features import Rank2Dvisualizer = Rank2D(algorithm='pearson')visualizer.fit(X, y)visualizer.transform(X)visualizer.show()
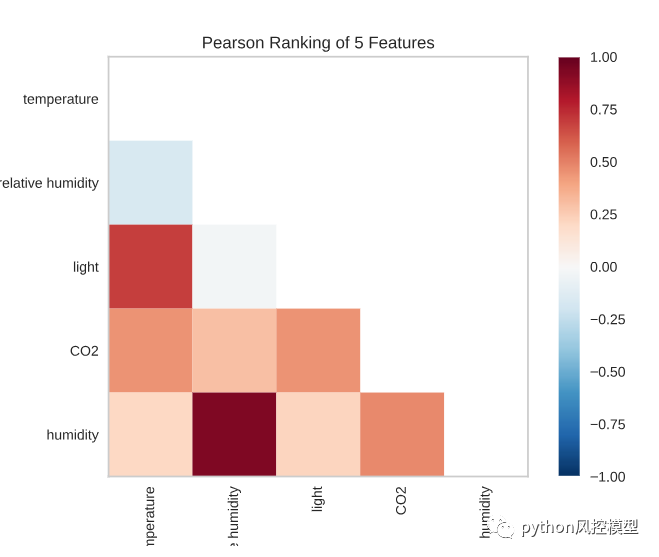
データによると、湿度は相対湿度と密接に関係しています。光は温度と密接に関係しています。これらの機能は通常連動しているため、これは当然のことです。
カテゴリバランス
分類モデルに関する最大の課題の 1 つは、トレーニング データ内のクラスの不均衡です。アンバランスなクラスの場合、分類子はすべての多数クラスが高いスコアを取得すると単純に推測できるため、高い f1 スコアは良い評価スコアではない可能性があります。
したがって、カテゴリの分布を視覚化することが非常に重要です。ClassBalance棒グラフを使用してカテゴリの分布を視覚化できます。
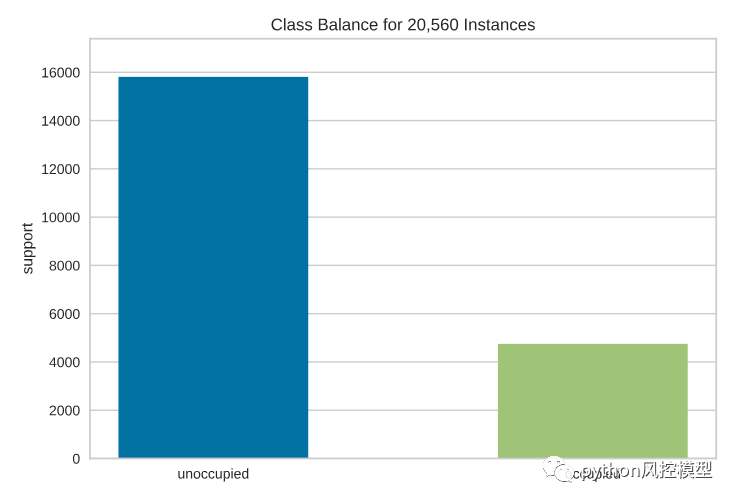
占有されているデータよりも占有されていないデータの方がはるかに多いようです。これを知ることで、層別サンプリングや重み付けなど、さまざまな手法を利用してクラスの不均衡に対処し、より有益な結果を得ることができます。
モデルの結果を視覚化する
ここで、98% という f1 スコアは実際には何を意味するのかという質問に戻ります。f1スコアが上昇すると、あなたの会社の利益は増加しますか?
Yellowbrick は、分類問題の結果を視覚化するために使用できるさまざまなツールを提供します。これらの中には、聞いたこともないものもあるかもしれませんが、モデルを説明するのに非常に役立ちます。
混同行列
空いているカテゴリでの間違った予測の割合は何ですか? 占有階級における予測の誤りの割合は何ですか? 混同行列は、この質問に答えるのに役立ちます。
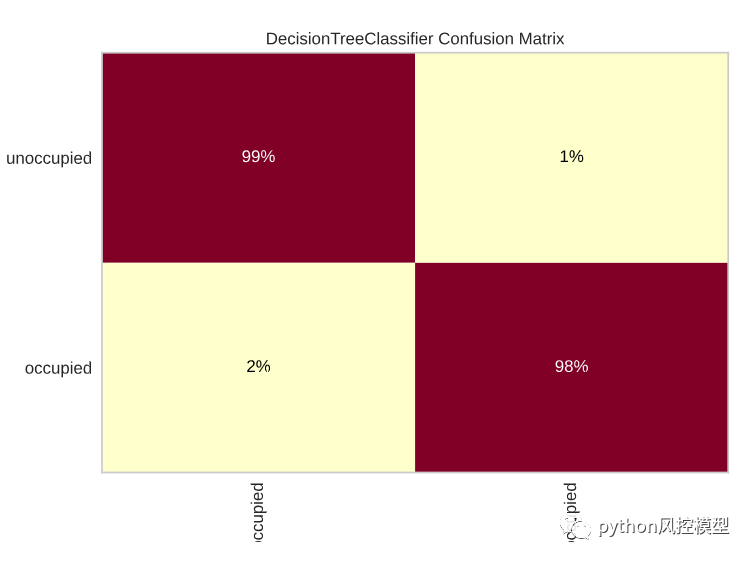
占有クラスでは誤った予測の割合が高いようです。したがって、スコアを改善するには、占有クラスで正しい予測の数を増やすように試みることができます。
これは yellowbrick の他のモデルのスコア視覚化の例です。
どうすればモデルを改善できるでしょうか?
モデルのパフォーマンスは理解できたので、モデルをどのように改善できるでしょうか? モデルを改善するには、次のようにします。
-
モデルの過小適合または過適合を防ぐ
-
推定器にとって最も重要な特徴を見つける
モデルを改善する方法を見つけるために、Yellowbrick が提供するツールを調べていきます。
検証曲線
モデルには多くのハイパーパラメータを含めることができます。トレーニング データを正確に予測するハイパーパラメータを選択できます。最適なハイパーパラメータを見つける良い方法は、グリッド検索でこれらのパラメータの組み合わせを選択することです。
しかし、これらのハイパーパラメータがテスト データを正確に予測することもどのようにしてわかるのでしょうか? 単一のハイパーパラメータのトレーニング データとテスト データへの影響をプロットすると、推定器が特定のハイパーパラメータ値に対して過小適合しているか過大適合しているかを判断するのに役立ちます。
検証曲線はスイート スポットを見つけるのに役立ちます。このハイパーパラメーターを下回るまたは上回る値は、データの過小適合または過適合のいずれかになります。
from yellowbrick.model_selection import validation_curveviz = validation_curve(model, X, y, param_name="max_depth",param_range=np.arange(1, 11), cv=10, scoring="f1",)
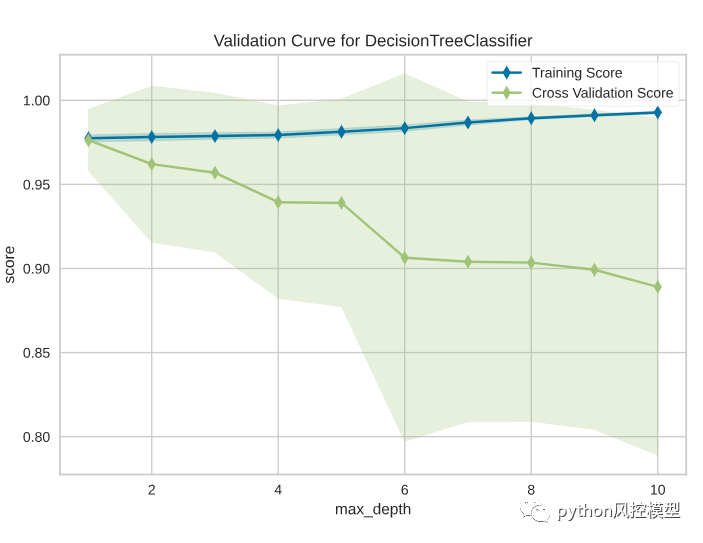
この図から、最大深さの数値が大きいほどトレーニング スコアは高くなりますが、相互検証スコアは低くなっていることがわかります。デシジョン ツリーが深くなるほど、過剰適合が容易になるため、これは当然のことです。
したがって、スイート スポットは、相互検証スコアが減少しない場所、つまり 1 になります。
学習曲線
データが増えるとモデルのパフォーマンスが向上しますか? 常にではありませんが、推定器は分散による誤差に対してより敏感になる可能性があります。このような場合に学習曲線が役に立ちます。
学習曲線は、さまざまな数のトレーニング サンプルを使用した推定器のトレーニング スコアと相互検証テスト スコアの間の関係を示します。
from yellowbrick.model_selection import LearningCurvefrom sklearn.model_selection import StratifiedKFold#Create the learning curve visualizercv = StratifiedKFold(n_splits=12)sizes = np.linspace(0.3, 1.0, 10)visualizer = LearningCurve(model, cv=cv, scoring='f1', train_sizes=sizes,)visualizer.fit(X, y) # Fit the data to the visualizervisualizer.show() # Finalize and render the figure
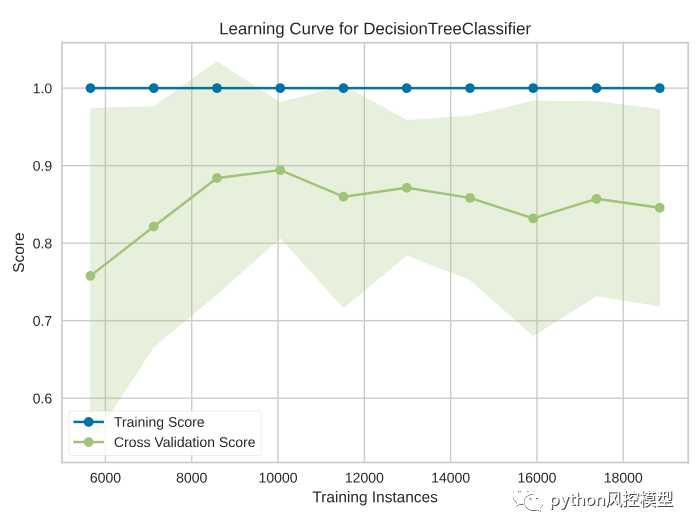
この図から、トレーニング インスタンスの数が約 8700 であると、最高の f1 スコアが得られることがわかります。トレーニング インスタンスの数が増えるほど、f1 スコアは低くなります。
上記の紹介に限定されず、Yellowbrick には他にも多くの用途があります。以下の図は、モデルの検索空間が大きくなるにつれて時間が指数関数的に増加することを示す Yellowbrick を示しています。
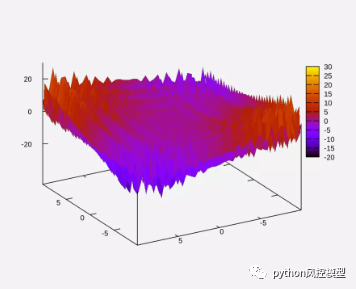
次の図は、Yellowbrick のハイパーパラメータ空間検索を示しています。


結論は
おめでとう!モデルの結果の解釈に役立つプロットを作成する方法を学びました。機械学習の結果を理解できると、パフォーマンスを向上させるための次のステップを見つけやすくなります。CSDN アカデミー コース「0 から 1 への Python データ サイエンスの旅」への参加を歓迎します。このコースには、データ サイエンス モデリングの実践的な事例が多数含まれています。以下の QR コードをスキャンして、忘れずにコースをブックマークしてください。

著作権に関する声明: この記事は公式アカウント (Python リスク管理モデル) からのものであり、許可なく、盗作はありません。CC 4.0 BY-SA 著作権契約に従って、転載する場合は、元のソースリンクとこの声明を添付してください。