通常の構文: メタ文字を使用して文字列と一致するように配置および結合します。オンライン テスト式は、下のリンクを直接クリックしてオンライン正規表現をテストできます。OSCHINA.NETオンライン ツール、ostools は開発者とデザイナーにオンライン ツールを提供し、jsbin オンライン CSS を提供します、JS デバッグ、オンライン Java API ドキュメント、オンライン PHP API ドキュメント、オンライン Node.js API ドキュメント、Less CSS コンパイラ、MarkDown コンパイラ、およびその他のオンライン ツール
1. 正規表現の導入
ローカルターミナルを開き、次のコードをインポートします。
pip install re2. 正規表現オブジェクト
2.1 re.RegexObject
re.compile() は RegexObject オブジェクトを返します。
2.2re.MatchObject
group() は、RE によって一致した文字列を返します。
-
start() は試合が開始された位置を返します
-
end() は一致が終了する位置を返します
-
scan() は、一致した位置 (開始、終了) を含むタプルを返します。
3. 正規表現修飾子 - オプションのフラグ
正規表現には、一致するパターンを制御するためのオプションのフラグ修飾子をいくつか含めることができます。修飾子はオプションのフラグとして指定されます。複数のフラグはビット単位の OR(|) で指定できます。re.I | re.M が I フラグと M フラグに設定されている場合:
| 修飾子 | 説明する |
|---|---|
| re.I | 一致する大文字と小文字を区別しないようにする |
| re.L | ロケールを意識したマッチングを行う |
| レム | 複数行の一致、^ と $ に影響する |
| レス | make . 改行を含むすべての文字に一致します |
| リユー | Unicode 文字セットに従って文字を解析します。このフラグは \w、\W、\b、\B に影響します。 |
| レックス | このフラグを使用すると、より柔軟な書式設定が可能になり、理解しやすい正規表現を作成できます。 |
4. 正規表現のメタ文字
| モデル | 説明する |
|---|---|
| ^ | 文字列の先頭と一致します (何と) |
| $ | 文字列の末尾と一致します。(何で終わる) |
| 。 | 改行を除く任意の文字と一致します。 |
| [...] | 個別にリストされた文字のグループを表すために使用されます: [amk] は、「a」、「m」、または「k」に一致します。 |
| [^...] | [] にない文字: [^abc] は、a、b、c 以外の文字と一致します。 |
| * | 0 個以上の式と一致します。 |
| + | 1 つ以上の式と一致します。 |
| ? | 前述の正規表現で定義された 0 または 1 つのフラグメントと一致します。貪欲ではありません |
| {n} | 前の式の n 回の出現と一致します。たとえば、「o{2}」は「Bob」の「o」とは一致しませんが、「food」の両方の「o」には一致します。 |
| {n,} | 直前の n 個の式に正確に一致します。たとえば、「o{2,}」は「Bob」の「o」とは一致しませんが、「foooood」のすべての「o」には一致します。「o{1,}」は「o+」と同等です。「o{0,}」は「o*」と同等です。 |
| {n,m} | 前述の正規表現で定義されたセグメントの n ~ m 倍を貪欲に照合します。 |
| あ| b | a または b に一致する |
| () | グループを示す括弧で囲まれた式と一致します |
| (?>) | バックトラッキングを省略した、マッチングのための独立したパターン。 |
| \w | 英数字のアンダースコアと一致する |
| \W | 数字以外の文字とアンダースコアを一致させます |
| \s | [\t\n\r\f] に相当する任意の空白文字と一致します。 |
| \S | null 以外の任意の文字に一致します |
| \d | [0-9] に相当する任意の数値と一致します。 |
| \D | 数字以外のすべてに一致します |
| \A | 一致文字列の開始 |
| \Z | 文字列の末尾と一致します。改行がある場合は、改行の前の最後の文字列のみと一致します。 |
| \z | 文字列の末尾に一致する |
| \G | 前回の試合が行われた場所での試合。 |
| \b | 単語の境界、つまり単語とスペースの間の位置と一致します。たとえば、「er\b」は「never」の「er」と一致しますが、「動詞」の「er」とは一致しません。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \n, \t, 等。 | 匹配一个换行符。匹配一个制表符, 等 |
| \1...\9 | 匹配第n个分组的内容。 |
| \10 | 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式。 |
正则表达式:常用元字符
. //匹配除换行符以外的任意字符
\w //匹配字母或数字
\s //匹配任意的空白字符
\d //匹配数字
\n //匹配一个换行符
\t //匹配一个制表符
//用于校验
^ //匹配字符串的开始
$ //匹配字符串的结尾
\W //匹配非字母或数字或下划线
\D //匹配非数字
\S //匹配非空白符
a|b //匹配字符a或字符b
() //匹配括号内的表达式,也表示一个组
[...]//匹配字符组中的字符
[^...]// 匹配除了字符组中的字符的所有字符
a-zA-Z0-9 //匹配所有的数字和字母量词:控制前面的元字符出现的次数
* //重复0次或多次
+ //重复一次或更多次
? //重复0次或一次
{n} //重复n次
{n,} //重复n次或更多次
{n,m}//重复n到m次*贪婪匹配和惰性匹配
.* //贪婪匹配 (.*默认往多的去找)
.*? //惰性匹配 (?让*尽可能少的匹配结果)【了解贪心匹配和惰性匹配】

惰性匹配是指尽可能少的去匹配

贪心匹配是指尽可能多的去匹配

简单案例一:' . '的应用

几个点就表示匹配几个字符

简单案例二:输出所有的数字

如果使用\w的话,输出的是包含数字字母和字符串的

如果使用\d的话,输出的则是10个单数字,并不是我们想要的结果

所以可以使用这个元字符来匹配
![]()

简单案例三:校验:要求只能输入11位的电话号码时
如果使用11个\d来确定11位电话号码的话,当前面和后面有字母时则也能通过
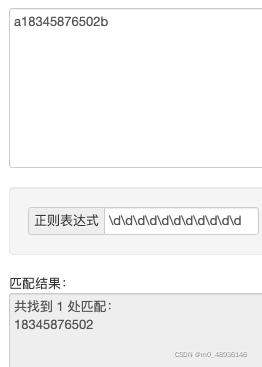
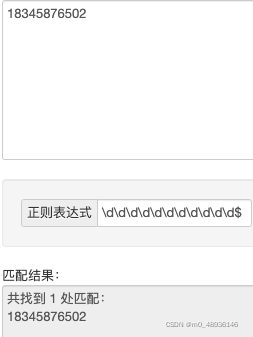
所以需要使用到^ 这个元字符,如果后面也存在字母,则需要使用$这个元字符

简单案例四:熟悉[...]
观察可以知道,只匹配[xxxx]中的值
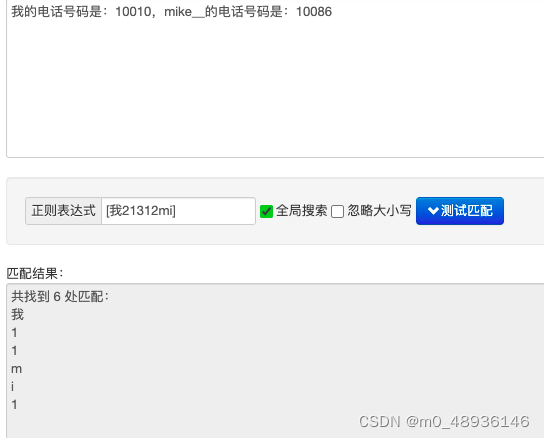
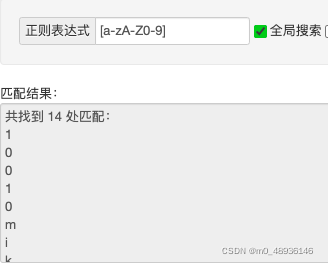
匹配字符串中所有的数字和字母[a-zA-Z0-9],该中括号里的'-'已经不是减的意思了,而是谁到谁的意思,表示a到z,A到Z,0到9。[a-zA-Z0-9_]==\w
成功匹配到了所有到数字和字母
5.组合字符
| .*? | 只匹配符合条件的最少字符,尽可能少的匹配 |
| .* | 任意一个字符 出现0次或多次 尽可能多的匹配 |
| [^0-9] | 取反,匹配数字之外 |
| [0-9] | 匹配任何数字。类似于[0123456789] |
| [a-z] | 匹配任何小写字母 |
| [A-Z] | 匹配任何大写字母 |
| [ab]cde | 匹配acde 或者 bcde |
| abc[de] | 匹配abcd 或 abce |
| [abcdef] | 匹配中括号内的任意字符 |
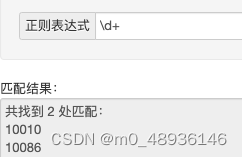
組み合わせケース 1 : (\d*): *は 0 回以上繰り返すことを意味するため、タイトルの「I」は数値ではなく、空の結果を返し、続行します。数値になるまで、数値の文字列を出力します。
![]()

(\d+): +は 1 回以上繰り返されるため、\d は \d+ に少なくとも 1 回存在する必要があります
「I」が数字ではない場合は、スキップして10010までジャンプします。+が1回以上繰り返されているため、1になった後に戻って数字かどうかを確認し、数字であれば続行します。 、文字列でない場合は前のlongに戻ります。