著者サイト:Quma Records
機械学習の実例
前回の記事の説明で、机器学习(機械学習)について少し理解できたと同時に、机器学习(機械学習)という言葉に対してそれほど抵抗がなくなりました。
では、机器学习それは私たちの実生活でどのような問題を解決してくれるのでしょうか? あるいは、従来のソリューションでは現時点では実現できません。
-
1. 生産ライン上の製品画像を解析し、分類できる。これは
图像分类カテゴリに分類され、通常は卷积神经网络(CNN) またはを使用しますTransformer。 -
2. 脳に腫瘍があるかどうかを検出するために使用できます。つまり
图像语义分割、画像内の各ピクセルは (腫瘍の正確な位置と形状を特定したいため)、通常卷积神经网络(CNN) またはを使用して分類されますTransformer。 -
3. ニュース記事の自動分類。これは
自然语言处理(NLP) のカテゴリに分類され、より具体的には である必要があります文本分类。循环神经网络(RNN) とを使用して卷积神经网络解決できますが、明らかにTransformer処理効果が優れています。 -
4. 悪意のあるコメントを自動的にマークします。これも
文本分类カテゴリであり、ソリューションもNLP最適なツールです。 -
5. 長い文書を自動的に要約します。短編小説を読んで、その物語の内容を要約するようなものですか?あるいはストーリーライン。これは
NLPのブランチであり、 と呼ばれ文本摘要、NLP処理にツールも使用します。 -
6.
聊天机器人または をビルドします个人助理。これには、 (NLU) や をNLP含む多くのコンポーネントが関係します。自然语言理解问答模块 -
7. 多数の業績指標に基づいて、会社の翌年の収益性を予測します。これは、 (線形回帰)、 (多項式回帰) モデルなどの任意の (回帰モデル)
回归任务を使用して解決できる (つまり、予測値)に属します。過去のパフォーマンス メトリックのシーケンスを考慮する場合は、 、 、および を使用します。回归模型线性回归多项式回归RNNCNNTransformer -
8. アプリは音声コマンドに応答します。これは
语音识别、オーディオ サンプルを処理する必要があることです。オーディオ サンプルは長く複雑なシーケンスであり、通常はRNN、、、CNNおよび を使用してTransformer処理されます。 -
9. クレジット カードの不正行為を検出します。これは に属します
异常检测。隔离森林(分離フォレスト)、高斯混合模型(ガウス混合モデル)、および(オートエンコーダー)を使用できます自动编码器。 -
10. 購入状況に応じて顧客をセグメント化し、市場セグメントごとに異なるマーケティング戦略を立てます。これは (クラスタリング) であり、 、など
聚类を使用して実現できます。k-meansDBSCAN -
11. 図を使用して、複雑な高次元データ セットを表現します。これは
数据可视化通常、 に関連しています降维技术。 -
12. 顧客の過去の購入に基づいて、興味のある製品を推奨します。これは に属します
推荐系统。1 つのアプローチは、過去の購入 (および顧客に関するその他の情報) を人工神经网络(ANN) にフィードし、最も可能性の高い次の購入を出力させることです。このニューラル ネットワークは通常、すべての顧客の過去の購入シーケンスに基づいてトレーニングされます。 -
13. ゲーム用のインテリジェント ロボットを作成します。これは多くの場合、 の分岐である (RL) を使用して解決できます。これは、プレイヤーが特定のゲームをプレイするたびに、エージェント (ボットなど) が時間の経過とともに報酬を最大化するアクションを選択するようにトレーニングします (ボットは報酬を獲得する可能性があります
强化学习) 。机器学习環境 (ゲームなど) 内で一部の健康状態が失われたとき。囲碁の世界チャンピオンを破った有名なAlphaGoプログラムは、RLを使用して構築されました。
もちろん、この例のリストは数え切れないほどありますが、机器学习取り組むことができるタスクの信じられないほどの広さと複雑さ、そしてそれぞれのタスクに使用するテクニックの種類を理解していただければ幸いです。
機械学習システムの種類
机器学习システムにはさまざまな種類がありますが、大まかに以下の基準に従っていくつかのカテゴリに分類できますが、それだけではありません。
监督1. トレーニング中の生徒の監督方法は、 、无监督、半监督などに細分化できますが、自我监督これらに限定されません。- 2. トレーニング中に即時増分学習が可能かどうかは、
在线学习とに分けられます批量学习。 新数据点3.と を単純に已知数据点比較するだけではどのように機能しますか? それとも、トレーニング データのパターンを調べて予測モデルを構築することで機能するのでしょうか?基于实例的学习これはとに分けられます模型的学习。
もちろん、これらの基準は固定されているわけではなく、いつでも好きなように組み合わせることができます。説明しましょ垃圾邮件过滤器う!人間が提供したサンプル データでトレーニングされた深度神经网络(ディープ ニューラル ネットワーク) モデルを使用して動的に学習できるため、効率的な学習システムになります。垃圾邮件在线基于模型监督
トレーニング監督
机器学习システムは、トレーニング中に受け取った监督数量合計に応じて类型分割できます。カテゴリはたくさんありますが、ここでは Talking 监督、无监督、自我监督、 Learning半监督のみ强化を取り上げます。
教師あり学習
では监督学习、アルゴリズムに提供される解 (训练集目的の解を含む) を と呼びます标签。

スパム フィルターは、多くの電子メールとその分類 (スパム) についてトレーニングされており、新しいメールを分類する方法を学習する必要があります。
特征グループ(走行距離、年式、ブランドなど)に基づいて目標値を予測することも可能です。トレーニングのために、機能や価格を含む多くの車の例を入力する必要があります。このタスクは と呼ばれます回归。
注:
回归模型分類に使用できるものもありますし、その逆も同様です。逻辑回归(ロジスティック回帰) は、特定のクラスの確率に対応する値 (例: スパムの確率 20%) を出力できるため、分類によく使用されます。

回归问题: 入力特徴が与えられた場合、値を予測します (通常は複数の入力特徴があり、場合によっては複数の出力値が存在します)。
教師なし学習
无监督学習において训练数据は必要ありません标记。システムは教師なしで学習しようとします。
ブログの訪問者に関する大量のデータがあると仮定すると、聚类算法同様の訪問者のグループを検出するために実行することができます。また、算法これがどのグループに属しているかを Access に伝える必要はありません。Access は、ユーザーの助けなしにこれらのリンクを見つけることができます。訪問者の 40% は漫画が好きで、通常放課後にブログを読んでいる 10 代の若者であり、20% は SF が好きで週末に訪問する大人であることに気づくかもしれません。(階層的クラスタリング アルゴリズム)を使用すると层次聚类算法、各グループをより小さなグループに分割することもできるため、各グループに対して投稿のターゲットを絞るのに役立ちます。
(教師なし学習用のラベルなしトレーニング セット)
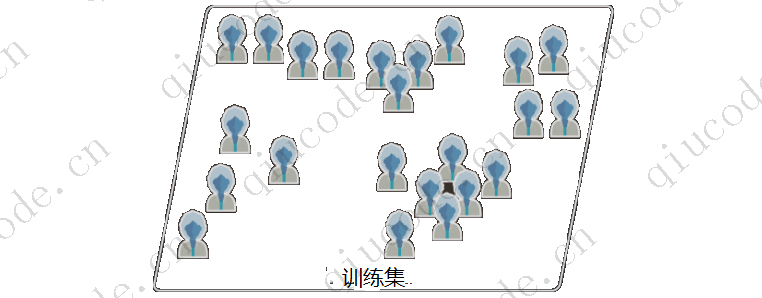
(クラスタリング)
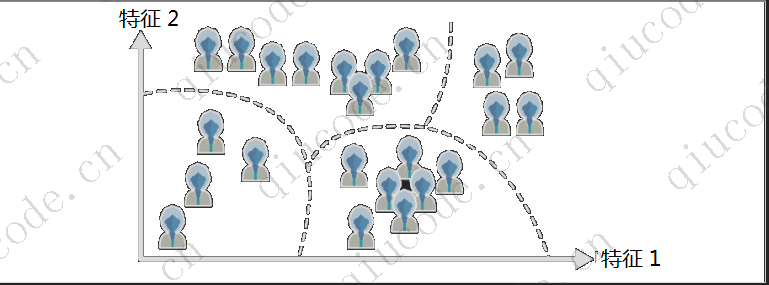
可视化算法これも无监督学习良い例です。ラベルのない複雑なデータを大量に与えると、プロットされたデータの 2D または 3D 表現を簡単に出力できます。これらのアルゴリズムは、データがどのように編成されているかを理解し、場合によっては予期しないパターンを識別できるように、できる限り多くの構造を保持しようとします (たとえば、入力空間内の個別のクラスターが視覚化内で重ならないようにします)。
関連タスク降维。目標は、多くの情報を失わずにデータを簡素化することです。これを実現する 1 つの方法は、特征複数の相関関係を 1 つに結合することです。たとえば、車の走行距離はその年式と密接に関係している可能性があるため、それらはと呼ばれる降维算法車の磨耗を表す 1 つの表現に結合されます。特征特征提取

训练数据通常、 を別の機械学習アルゴリズム (たとえば监督学习算法)に供給する前に、降维算法を削減してみることをお勧めします。実行が速くなり、データが占有するディスクとメモリのスペースが減り、場合によってはパフォーマンスが向上する場合もあります。训练数据维数
异常检测また 1 つ无监督任务。たとえば、異常なクレジット カード取引を検出して不正行為を防止したり、製造上の欠陥を特定したり、データを別の学習アルゴリズムに入力する前にデータ セットから外れ値を自動的に削除したりします。システムはトレーニング中にほとんどが正常なインスタンスを表示するため、それらのインスタンスを認識することを学習し、新しいインスタンスを見たときに、それが正常なインスタンスに見えるかどうか、または何かが異常である可能性があるかどうかを判断できます。
非常によく似たタスクです新颖性检测。このタスクは、 内のすべてのインスタンスとは異なるように見える新しいインスタンスを検出することを目的としています训练集。训练集これは、検出したいインスタンスに対して非常に「クリーン」である必要があります算法。たとえば、犬の写真が何千枚もあり、そのうちの 1% がチワワである場合、新颖性检测算法チワワの新しい写真は考慮すべきではありません新颖性。一方で、异常检测算法これらの犬は非常にまれであり、他の犬とは大きく異なるため、(チワワには悪気はありません)として分類されるかもしれないと主張するかもしれません异常。
(異常検出)

关联规则学习(相関ルール学習) は一般的なもので无监督任务、その目的は大量のデータをマイニングし、属性間の興味深い関係を発見することです。たとえば、あなたがスーパーマーケットを経営しているとします。販売ログを実行すると、关联规则BBQ ソースとチップスを購入する人はステーキも購入する傾向があることが判明する可能性があります。したがって、これらのアイテムを互いに近くに配置することをお勧めします。
半教師あり学習
通常、時間と費用がかかるため、タグ付けのインスタンスは非常に少数に标记数据なります。大量未标记一部のアルゴリズムは、部分的にラベル付けされたデータを処理できます。これを といいます半监督学习。
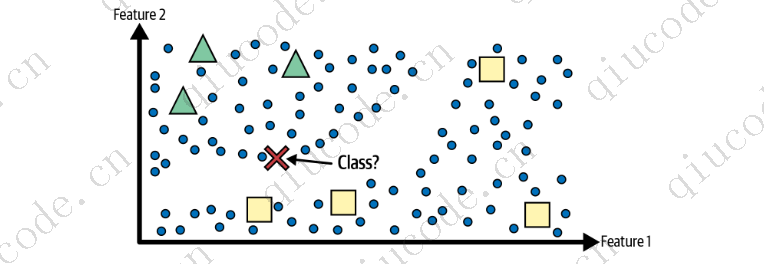
この図では、2 つのクラス (三角形と正方形) があります半监督学习。ラベルのない例 (円) は、ラベル付きの正方形に近いにもかかわらず、新しいインスタンス (十字) を正方形のクラスではなく三角形のクラスとして分類するのに役立ちます。
たとえば、一部の写真ホスティング サービス (Google フォト) では、写真をサービスにアップロードすると、写真 1、5、11 には同じ人物 A が写っており、写真 2、5、7 には別の人物 B が写っていることが自動的に認識されます。 。これは无监督アルゴリズム (クラスタリング) の一部です。これで、システムに必要なのは、これらの人々が誰であるかを伝えることだけです。人物ごとに 1 つ追加するだけで标签、各写真に写っている人物の名前が表示されるので、写真の検索に便利です。
ほとんどの半监督学习アルゴリズムは、无监督と の监督アルゴリズムの組み合わせです。たとえば、アルゴリズムを使用して聚类類似したインスタンスをグループ化し聚类、标签各インスタンスに最も一般的なものでラベルを付けることができます未标记。全体数据集がカバーされれば、任意のアルゴリズム标记を使用できます。监督学习
自己教師あり学習
机器学习もう 1 つのアプローチでは、実際には完全未标记な数据集ビルドから開始します。繰り返しになりますが、全体が特定されれば、任意のアルゴリズムを使用できます。このメソッドは と呼ばれます。たとえば、多数の画像がある場合、各画像の小さな部分をランダムにマスクして、元の画像を復元できます。トレーニング中に、として使用され、として使用されます。完全标记数据集数据集标记监督学习自我监督学习未标记数据集训练模型蒙版图像模型的输入原始图像标签
(左画像が入力、右画像が出力)

結果として得られるモデルは、それ自体、たとえば修复损坏画像を削除したり、写真から不要なオブジェクトを削除したりする場合に非常に役立ちます。しかし、多くの場合、自我监督学习トレーニングされたモデルを使用することが最終目標ではありません。多くの場合、少し異なるタスク (本当に関心のあるタスク) のためにモデルを調整し、微調整する必要があります。
あなたが本当に飼いたいと思っているのは宠物分类模型、ペットの写真があれば、それがどの種に属しているかを教えてくれるということです。未标记ペットの写真の大量のコレクションがある場合は、 を使用して画像モデルをトレーニングすることから数据集始めることができます。行儀が良くなると、さまざまなペットの種類を区別できるようになります。顔を隠した猫の画像がある場合、犬の顔を追加してはならないことを認識している必要があります。自我监督学习修复修复
モデルのアーキテクチャがそれを許可していると仮定すると (そしてほとんどが許可しています)、画像ではなく種をペットにする神经网络ようにモデルを微調整することが可能です。最後のステップでは、モデルを微調整します。モデルは、猫、犬、その他のペット種がどのようなものであるかをすでに知っているため、このステップは、モデルがその種についてすでに知っていることと、その種についてすでに知っていることとの間のマッピングを学習できるようにするためにのみ必要です。私たちがそこに期待していること。预测修复标记``````数据集标签
あるタスクから別のタスクに知識を伝達することは、特に使用される場合(つまり、複数のレイヤーで構成されている場合) 、今日最も重要なテクニックの 1 つ
迁移学习です。机器学习深度神经网络神经元神经网络
一部の人は、それを完全に処理するため、自监督学习それを一部とみなします。ただし、トレーニング中に使用 (生成) されるため、その点ではより近いものになります。通常、や の処理などのタスクに使用されますが、と と同じタスクに焦点を当てます。主に と。つまり、別のカテゴリとして考えるのが最善です。无监督学习未标记数据集自我监督学习标签监督学习无监督学习聚类降维异常检测自我监督学习监督学习分类回归自我监督学习
強化学習
强化学习全く異なる種類のものです机器学习。学习系统この論文で言及されているように代理、環境を観察し、行動を選択して実行し、報酬を得る (または負の報酬の形で罰する) ことが可能です。次に、時間の経過とともに最大の利益を得るには、自行学习何が最善であるか策略( と呼ばれる)でなければなりません。策略ポリシーは、特定の状況でエージェントがどのようなアクションを選択する必要があるかを定義します。

たとえば、多くは歩き方を学習するためにアルゴリズムを机器人採用しています。もこのプログラムの好例です。2017 年 5 月に当時世界 1 位だった柯潔を囲碁の対局で破り、大きく報道されました。何百万ものゲームを分析し、それ自体と多くのゲームをプレイすることで勝利戦略を学習します。チャンピオンとの試合中は学習がオフになることに注意してください。学習したポリシーが適用されるだけです。强化学习DeepMindAlphaGo强化学习AlphaGo