記事ディレクトリ
マノリス・ケリス教授(MIT 計算生物学ディレクター)による「人工知能と機械学習」
メインコンテンツは表現学習のpart2です。
圧縮 (オートエンコーダー)、パラメータ分布のキャプチャ (VAE)、表現学習のための 2 番目のネットワーク (GAN) の使用
前のセクションの知識のレビュー:表現学習の定義と最初の方法: プレテキスト テキストを紹介しました。
このセクションの内容は、以前のブログ「学習モデルの原理リファレンス:生成モデル (オートエンコーダー、VAE、GAN)」とかなり重複しています。ここでは、データからのメソッドを使用して意味のある表現 z を学習することに重点が置かれています。
以下はチューブへのリンクです。
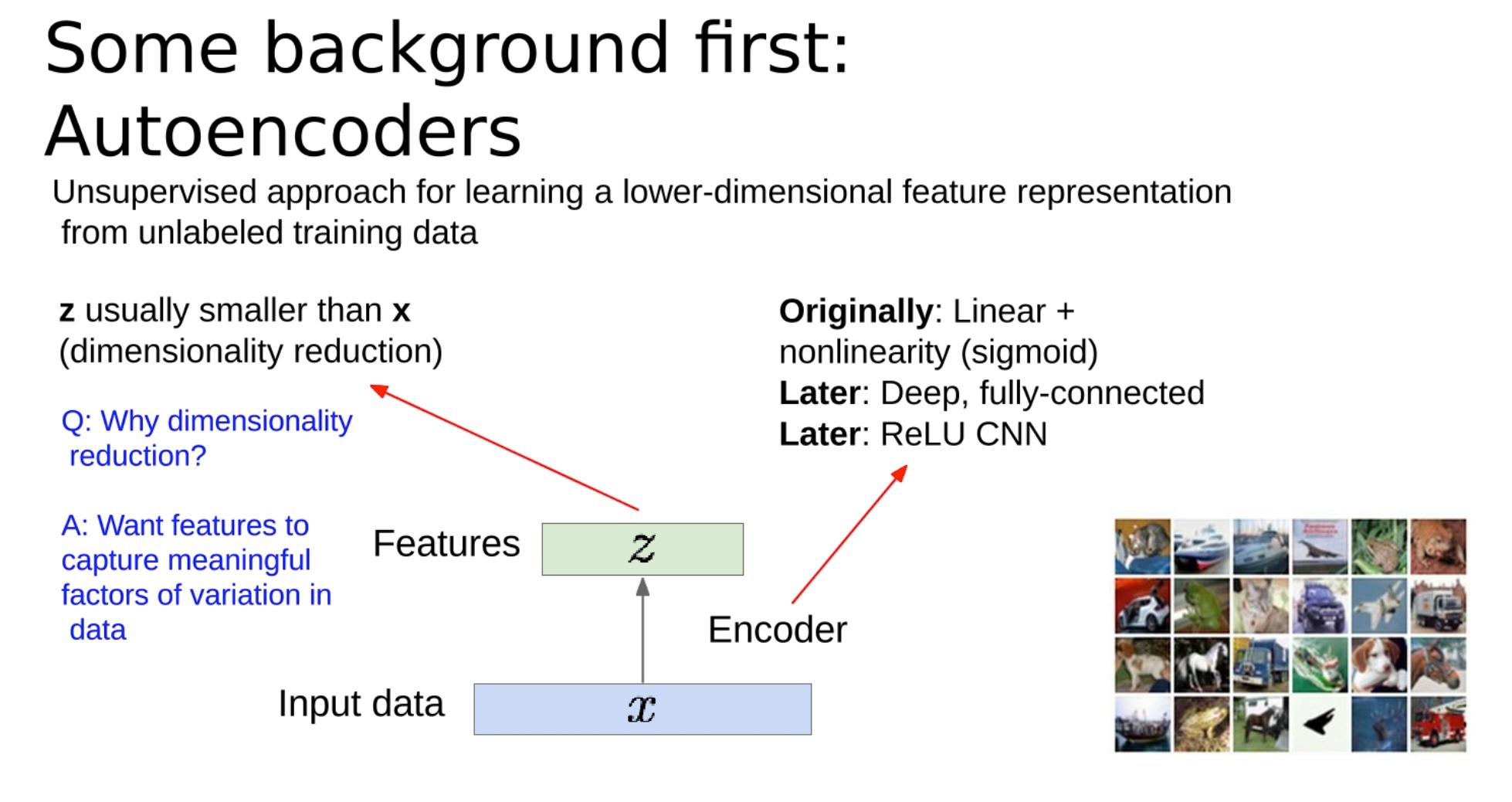
圧縮:自動エンコーダ

オートエンコーダーは、入力データの効率的なエンコーディングを学習するために使用される人工ニューラル ネットワークです。これは教師なし学習方法であり、ラベル付きトレーニング データを必要としません。

-
オートエンコーダの構造は、エンコーダとデコーダで構成されます。
-
エンコーダは入力データ (X で示す) の次元を削減し、潜在空間表現またはエンコード (Z で示す) と呼ばれることが多い圧縮表現を作成します。目標は、特徴がデータ内の意味のある変動を捕捉できるように次元を削減することです。このZは私たちが学びたい意味のあるものです
-
デコーダは圧縮データを取得し、元の入力データを再構築します。ここでの考え方は、優れたエンコーディングを使用して元のデータを正確に再構築できるということです。
-
-
次元削減の理由:
-
これにより、モデルの計算の複雑さとストレージ要件が軽減されます。
-
さらに重要なのは、オートエンコーダーに、データ内の基礎となる構造またはパターン、基本的にはデータの「本質」を捕捉するコンパクトな表現を学習させることです。
-
表現学習は、圧縮 (z の小さい次元) によって実現されます。
-
入力と出力は実際には x であるため、追加のラベル y は必要ありません。
-
当初、オートエンコーダは線形活性化関数を使用した完全接続ニューラル ネットワークとして実装され、その後、シグモイドなどの非線形活性化関数が使用されました。時間が経つにつれて、ReLU (Rectified Linear Unit) 非線形活性化関数を使用する畳み込みニューラル ネットワーク (CNN) など、より深く複雑な構造が導入されました。
オートエンコーダーは、異常検出、ノイズ除去、データ視覚化のための次元削減などのさまざまなタスクに使用できます。

オートエンコーダーをトレーニングするときは、その機能を使用して元のデータを再構築できることを期待しています。これはラベルを必要としないため、教師なし学習の一種です。トレーニングは通常、元の入力と再構成された入力の差を測定する L2 損失関数 (平均二乗誤差とも呼ばれる) を最小化することによって行われます。
図の右側の例では、エンコーダとデコーダはそれぞれ 4 つの畳み込み (conv) 層と 4 つのデコンボリューション (upconv) 層で構成されています。
トレーニング後、デコーダー部分を破棄し、エンコーダー部分のみを保持できます。エンコーダは特徴抽出器として機能し、入力データを圧縮された特徴表現に変換できるようになりました。
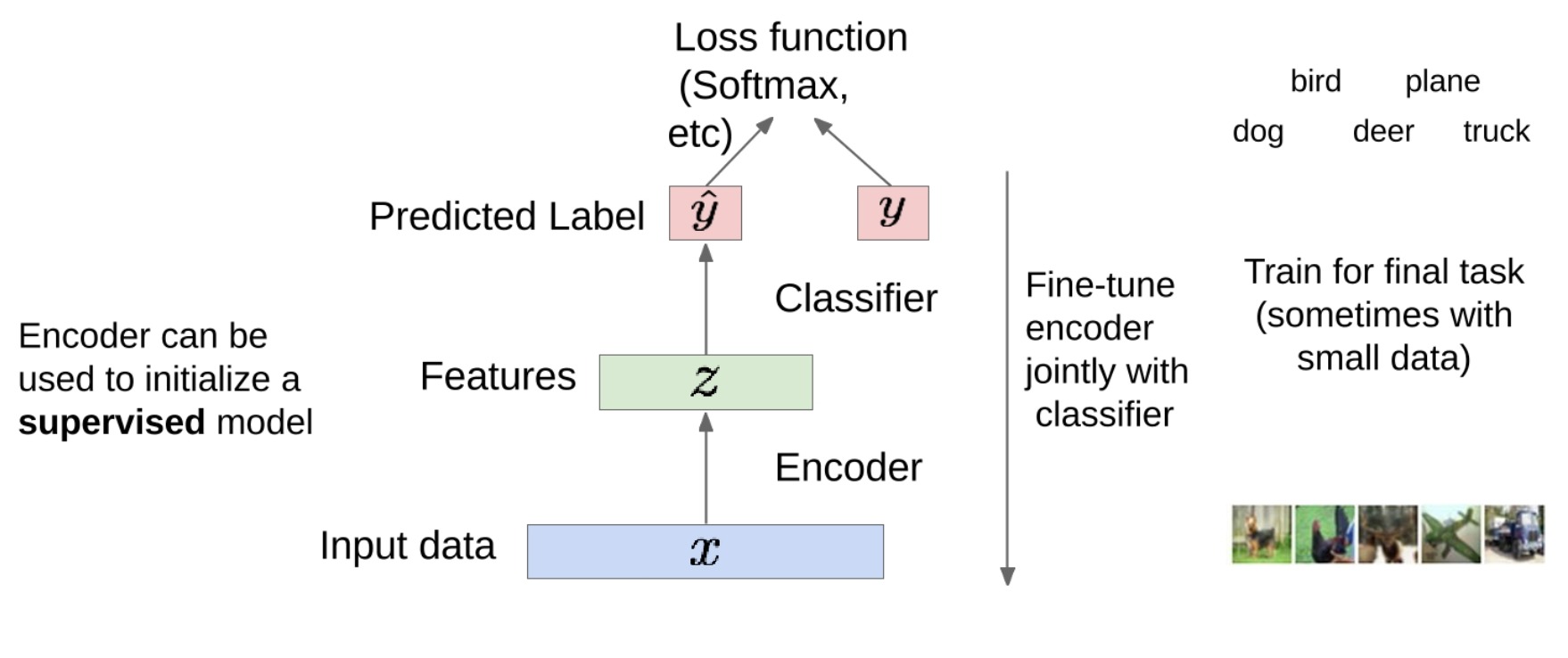
これらの機能を分類などの最終タスクのトレーニングに使用できます。この場合、ラベルが必要になるため、これは教師あり学習の一種です。
具体的には、分類器をエンコーダーの出力に接続できます。分類器は、ソフトマックス、クロスエントロピーなどの損失関数を使用してトレーニングし、各クラスの確率を予測できます。
その後、モデル全体を微調整できます。これは、分類器の重みを更新するだけでなく、エンコーダーの重みも更新することを意味します。これにより、エンコーダは最終タスクにより適切に適応できるようになります。
このアプローチは、エンコーダーが大量のラベルなしデータで事前トレーニングされており、データ内のいくつかの基本パターンをキャプチャする方法を学習しているため、データが小さい場合に特に役立ちます。これにより、少量のラベル付きデータを迅速かつ効率的に微調整できます。最初に大量のデータでトレーニングを行わずに、小さなデータセットで予測を行うことは困難です。

オートエンコーダーはデータを再構築し、特徴を学習して教師ありモデルを初期化できます。トレーニング データの変動要因をキャプチャできるため、オートエンコーダーから新しい画像を生成できるでしょうか?
この疑問は、変分オートエンコーダー (略して VAE) につながります。
変分オートエンコーダは、データを再構築するだけでなく、これまでに見たことのない新しいデータを生成する特別なタイプのオートエンコーダです。これにより、VAE は生成モデル (新しい画像やテキストの生成など) の分野で非常に役立ちます。
パラメータ分布 (分散) のキャプチャ: 変分オートエンコーダ
原理紹介
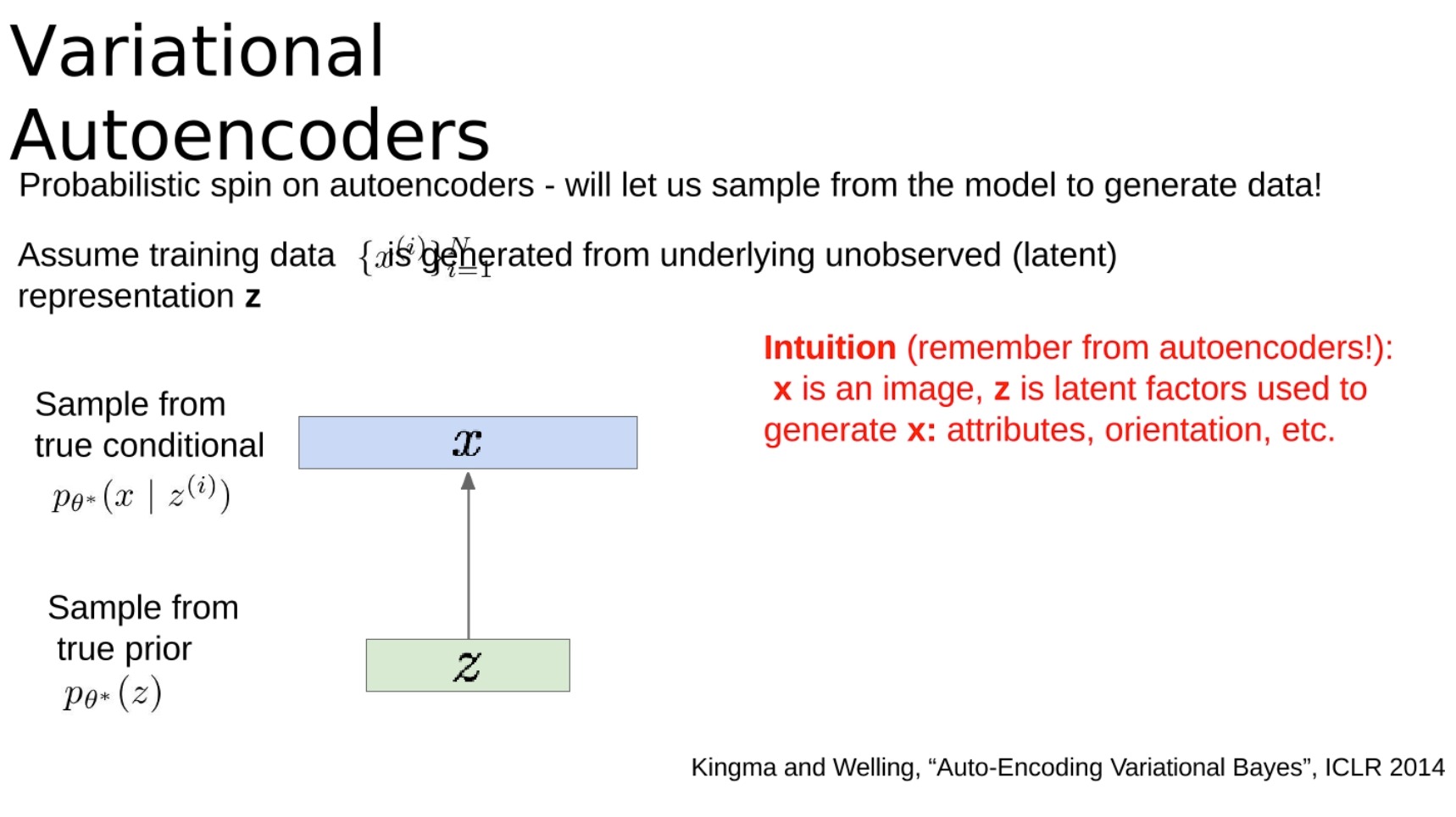
変分オートエンコーダーはオートエンコーダーの確率的解釈を提供し、モデルからサンプリングしてデータを生成できるようにします。トレーニングデータXXがあるとします。X は、観測されていない (潜在的な)ZZZによって生成されました。
直感的に (オートエンコーダーが何であるかを思い出してください!): XXXはイメージ、ZZはZはXXを生成するために使用されますXの潜在的な要素: 属性、方向性など。
-
この生成モデルの真のパラメータ $θ*$ を推定したいと考えています。
-
このモデルをどのように表現すればよいでしょうか?
- 前のp ( Z ) p(Z)を選択しますp ( Z )は、ガウス分布などの単純な形式です。
- 条件p ( x ∣ z ) p(x|z)p ( x ∣ z ) (生成された画像) => 複雑すぎるため、ニューラル ネットワークで表現されます。

-
モデルをトレーニングするにはどうすればよいですか?
-
ベイジアン ネットワークから生成モデルを学習するための戦略を思い出してください。トレーニング データの尤度を最大化するためのモデル パラメーターを学習します (モデルの下でトレーニング データの尤度を最大化するモデル パラメーターのセットを見つける必要があります)。
-
p θ ( x ) = ∫ p θ ( x ) p θ ( x ∣ z ) dz p_θ(x) = ∫p_θ(x)p_θ(x|z)dzp私( × )=∫p私( × ) p私( x ∣ z ) d z
-
ここで潜在変数 z を導入すると、以下で説明するように状況が複雑になります。
-

-
-
-
上記の内容は、ICLR 2014 の Kingma と Welling による論文「Auto-Encoding variational Bayes」から引用されています。
gpt4 を使用した簡単な例:
あなたが美術商であり、その仕事はゴッホの絵画をできるだけリアルに複製できる機械を作成することであると仮定します。まず、マシンをトレーニングするには、ゴッホの原画をいくつか収集する必要があります。これはトレーニング データです。
これで、基本的なオートエンコーダーが完成しました。ゴッホの絵を見せて、それを再現させてみます。オートエンコーダーのエンコード部分は、ゴッホの絵画のいくつかの基本的な特徴 (色、スタイル、主題など) を理解しようとし、これらの特徴を潜在表現と呼ばれる形式に抽象化します。解読部分では、これらの潜在的な表現からゴッホのオリジナルの絵画を再構築しようとします。試行錯誤を通じて、オートエンコーダーはゴッホの絵画をうまく複製する方法を学習しました。
しかしここで問題が発生します。ゴッホの絵画のようなまったく新しいものを機械で作成したい場合はどうすればよいでしょうか? ここで、変分オートエンコーダ (VAE) が役立ちます。
変分オートエンコーダでは、マシンにゴッホの絵画を複製する方法を学習させるだけでなく、ゴッホの絵画の背後にある基本ルールのいくつかを理解するよう要求します。私たちは、このマシンが、各点がゴッホ風の絵画の可能性に対応する、ある種の「ゴッホの絵画の可能性のある空間」を作成できるようにしたいと考えています。
具体的には、エンコーダが固定の潜在表現を与えるだけでなく、潜在表現の確率分布も与えることを期待します。このようにして、この分布からランダムにサンプリングし、いくつかの新しい潜在表現を取得し、これらの潜在表現をデコーダーを通じて新しい絵画に渡すことができます。
私たちの場合、マシンはゴッホの絵画を再現する方法を学習しただけでなく、ゴッホの絵画の背後にある基本的なルール、色の合わせ方、主題の選択方法なども理解したかのようです。したがって、これまでに見たことのない潜在表現が与えられた場合でも、機械はこれらのルールに基づいてゴッホのように見える新しい絵画を作成することができます。
- Explainp θ ( x ) = ∫ p θ ( x ) p θ ( x ∣ z ) dz p_θ(x) = ∫p_θ(x)p_θ(x|z)dzp私( × )=∫p私( × ) p私( x ∣ z ) d z:
「尤度」は、モデルとモデル パラメーターが与えられた場合に実際のデータが観測される可能性がどの程度であるかを表す確率用語です。尤度を最大化することで、モデルがトレーニング データを生成する可能性が最も高くなるパラメーターのセットを見つけます。
この戦略は FVBN を学習させる場合には有効ですが、潜在変数 z を導入すると状況は複雑になります。潜在変数 z は、モデルに導入する隠れ変数であり、直接観察できないいくつかの要素を表します。たとえば、ゴッホの絵画の例では、 z はゴッホの絵画スタイル、カラー マッチングなどを表す場合があります。
潜在変数 z を取得した後は、z の真の値がわからないため、トレーニング データの尤度を直接計算することはできません。この問題を解決するために、上記の式の積分を使用して、考えられるすべての Z 値を合計しました。この積分は、考えられるすべての z 値を考慮し、それらの z 値におけるトレーニング データの尤度の合計を計算したことを意味します。
ただし、この積分を直接計算することは、特に z の次元が高い場合には非常に困難になることがよくあります。このため、この積分を近似するには、変分推論 (下記を参照)などの近似方法を使用する必要があります。変分オートエンコーダは、この戦略を使用する例です。
- Q: これを行うと何が問題になるのでしょうか? 答え: 扱いが難しい!
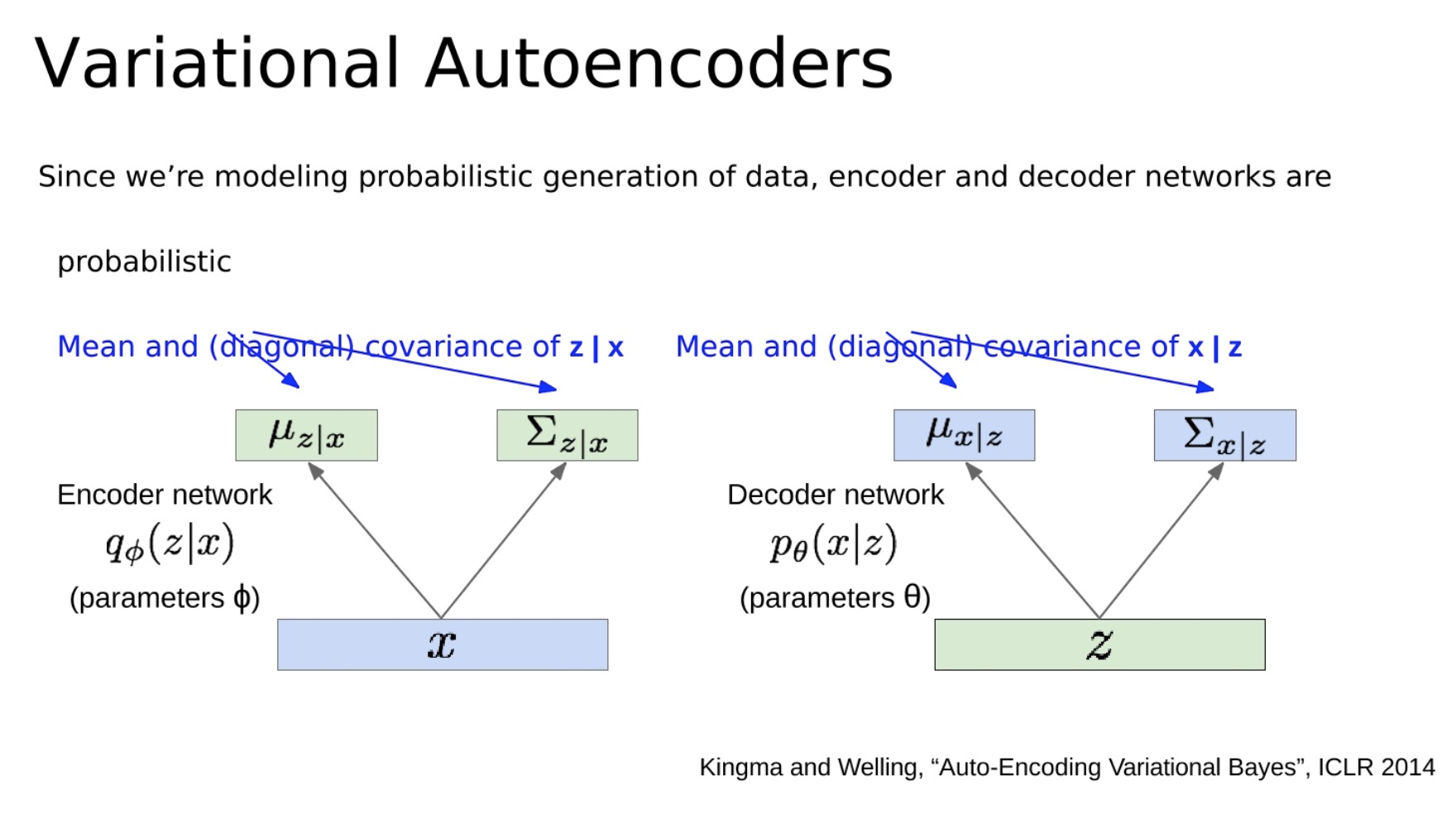
- データの確率的生成をモデル化しているためエンコーダーとデコーダーのネットワークは確率的です。これらは、潜在変数 z の条件付き平均と (対角) 共分散、および x の条件付き平均と (対角) 共分散をモデル化します。
従来のオートエンコーダでは、エンコーダの出力は特定の潜在ベクトル z であり、デコーダを通じて入力データ x を再構築するために直接使用されます。ただし、VAE では、エンコーダは実際に、潜在ベクトル z にわたる確率分布のパラメーター(通常は平均と共分散を含むガウス分布) を出力します。これは、潜在ベクトル z が未定義であることを意味します。**この確率分布からサンプリングされた任意の値になる可能性があります。**これにより、VAE が新しい異なるデータを生成できるようにする追加のランダム性が導入されます。
同時に、デコーダは再構成データ x を直接生成するのではなく、** x の確率分布のパラメーター (** 通常はガウス分布の平均と共分散も) を生成します。これは、潜在ベクトル z が与えられると、デコーダーによって与えられる確率分布にすべて適合するさまざまな異なるデータ x を生成できることを意味します。
この確率論的なモデリング アプローチにより、VAE はデータ生成プロセスをより適切にシミュレートできるようになり、モデルから新しい異なるデータをサンプリングできるようになります。これは、生成モデルとしての VAE の重要な特性です。
-
問題は、そのようなモデルのトレーニングには確率分布の積分の計算が含まれることですが、これは通常 **困難** です。たとえば、考えられるすべての潜在変数 z に対応する確率の積分を計算する必要がありますが、特に潜在空間が高次元である場合、これは計算上実行不可能です。
-
VAE では、エンコーダ ネットワーク (推論ネットワークとしても知られています) は、潜在変数 z の事後確率分布 P(z|x) のパラメータを学習しようとします。次に、デコーダ ネットワーク (生成ネットワークとしても知られています) は、観測変数 x の確率分布 P(x|z) のパラメータを学習しようとします。
-
VAE の重要なアイデアは、これらの扱いにくい確率分布を近似する変分推論の方法を導入することです。具体的には、扱いやすい近似分布 Q(z|x) を導入し、この分布を真の事後分布 P(z|x) にできるだけ近づけようとします。次に、この近似分布の変分下限 (ELBO、証拠下限とも呼ばれます) を最大化することで、モデルのパラメーターをトレーニングできます。
-
-
これが、VAE のトレーニングにいくつかの扱いにくい確率分布が含まれるにもかかわらず、それでも効率的にトレーニングできる理由です。
-
以前に書いたブログを挿入します:モデルの生成 (オートエンコーダー、VAE、GAN)
数学的導出

対数尤度および KL 発散の計算を含む、変分オートエンコーダー (VAE) の数学的導出。
VAE では、データの対数尤度、log P ( x ) log P(x) を最大化することが目標です。l o g P ( x )、ここで x はトレーニング データです。私たちのモデルには潜在変数 z が含まれているため、この可能性を得るには、z のすべての可能な値を合計する必要がありますが、通常は計算できません。したがって、この可能性を近似する方法を見つける必要があります。
私たちの戦略は、近似事後分布q ( z ∣ x ) q(z|x) を導入することです。q ( z ∣ x )、真の事後分布p ( z ∣ x ) p(z|x)p ( z ∣ x )。VAE では、通常q ( z ∣ x ) q(z|x)q ( z ∣ x )は、平均と共分散がエンコーダ ネットワークによって与えられるガウス分布です。
次に、対数尤度log P ( x ) log P(x)を取得できます。l o g P ( x )は 2 つの部分の合計として書き換えられます。
- 最初の部分は、期待される対数尤度E [ log P ( x ∣ z ) ] E[log P(x|z)]です。E [ l o g P ( x ∣ z )]、ここで z はq ( z ∣ x ) q(z|x)サンプリングにより得られるq ( z ∣ x )
- 2 番目の部分はq ( z ∣ x ) q(z|x)です。q ( z ∣ x )およびp ( z ∣ x ) p(z|x)p ( z ∣ x )間の KL 発散DKL ( q ( z ∣ x ) ∣ ∣ p ( z ∣ x ) ) D_{KL}(q(z|x)||p(z|x))DKL _( q ( z ∣ x ) ∣∣ p ( z ∣ x ))。
次に、KL 発散をさらにq ( z ∣ x ) q(z|x)として書き直すことができます。q ( z ∣ x )と事前分布p ( z ) p(z)p ( z )と追加の補正項の間の KL 発散
上記の導出では、次のことがわかります。
最初の部分 (予想される対数尤度) は、再パラメータ化トリックによってサンプリングして推定できます。これは、 q ( z ∣ x ) q(z|x)からのサンプル z のミニバッチを使用できることを意味します。q ( z ∣ x )をサンプリングし、x ∣ zx|zx ∣ zの可能性再パラメータ化トリックのおかげで、このプロセスは微分可能であるため、勾配降下法を使用して最適化できます。
2 番目の部分 (KL 発散) は、q ( z ∣ x ) q(z|x) であることがわかっているため、解析的に計算できます。q ( z ∣ x )およびp ( z ) p(z)p ( z )はすべてガウス分布であり、それらの間の KL 発散は閉じた形式の解を持ちます。
したがって、これら 2 つの部分の合計を最適化することで VAE モデルをトレーニングできます。

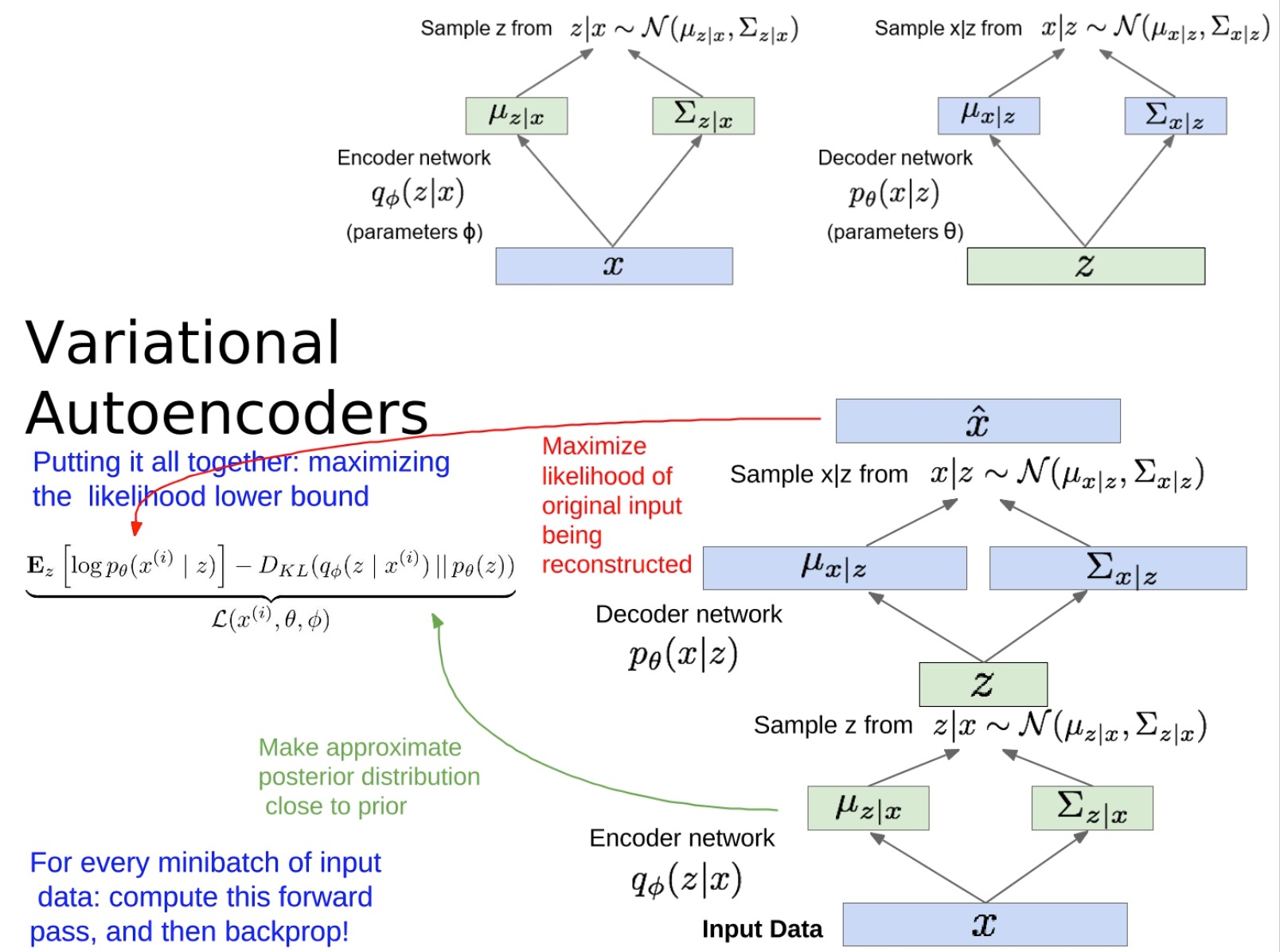
-
このセクションでは、VAE をトレーニングする方法を要約します。
- まず、入力データをエンコーダー ネットワークに通過させて潜在変数 z の分布パラメーターを取得し、次にこの分布から z をサンプリングします。次に、z がデコーダ ネットワークを通過して再構築された入力の分布パラメータを取得し、この分布からサンプリングして再構築された入力を取得します。目標は、この再構成された入力を元の入力 (「再構成された入力」部分) にできるだけ近づけることです。
- さらに、エンコーダーによって与えられる潜在変数 z の分布を、選択した事前分布 (通常は標準正規分布) に近づけたいと考えています。これは、近似事後分布を事前分布に近づける部分です。これは、エンコーダによって与えられた分布と事前の分布の間の KL 発散を計算することによって実現されます。
-
モデルのトレーニングでは、上記 2 つの部分の合計を最適化することで実行されます。この合計はいわゆる「証拠の下限 (ELBO)」であり、私たちの目標はこの下限をできるだけ大きくすることです。この下限を最適化するために、確率的勾配降下法を使用できます。入力データの小さなバッチごとに、最初に順伝播を計算して ELBO の値を取得し、次に逆伝播を実行してモデルのパラメーターを更新します。
実際には、期待値の計算には積分が必要であり、直接積分は通常非常に難しいため、通常はモンテカルロ法を使用してこの積分を近似します。つまり、エンコーダーによって与えられた分布から何度もサンプリングし、期待値の推定値としてサンプルの平均を計算します。
データを生成する
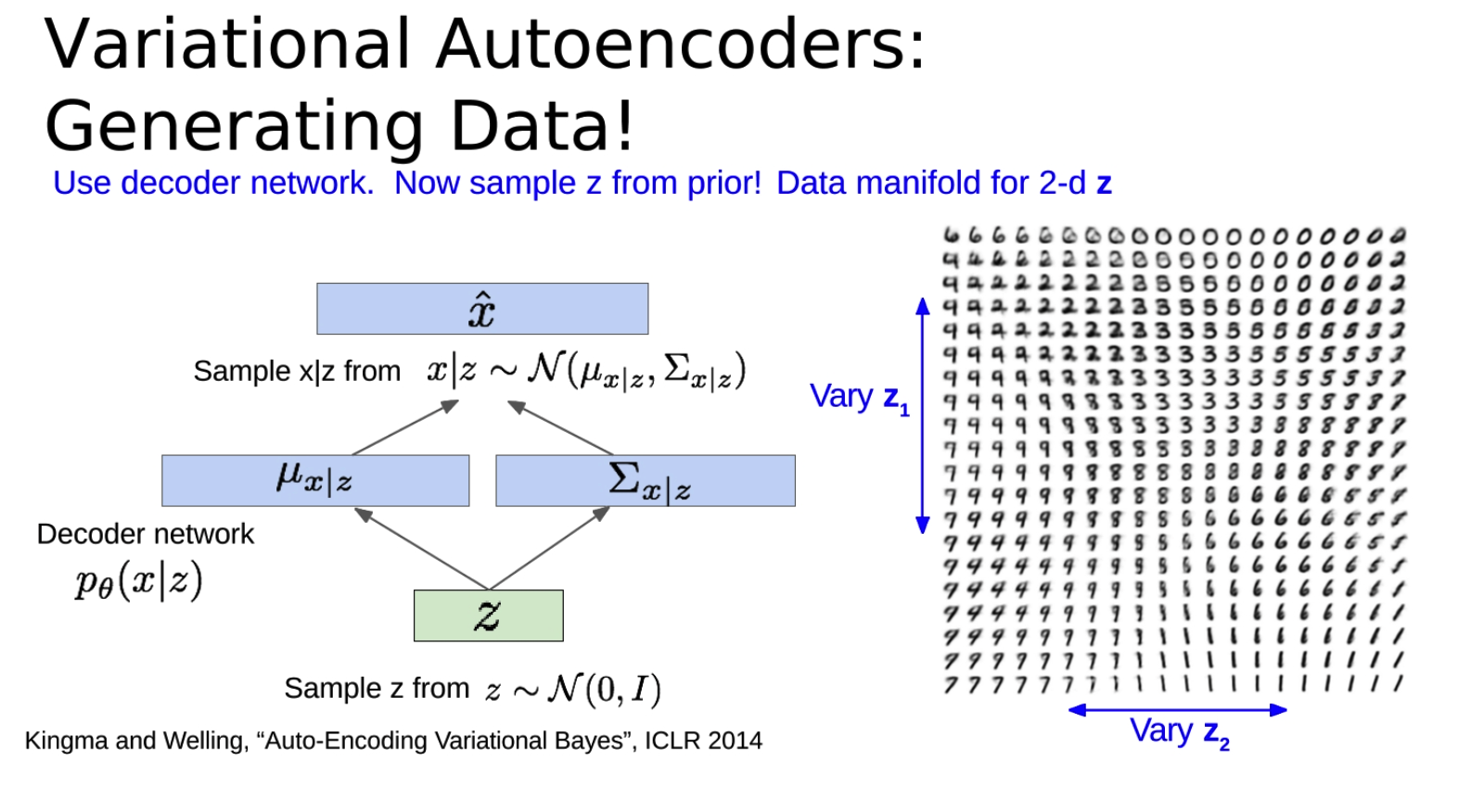
-
トレーニングされた変分オートエンコーダー (VAE) をデータ生成に使用する方法について。
-
まず、潜在変数 z が事前分布 (通常は標準正規分布) からサンプリングされ、次に z がデコーダ ネットワークに入力されて入力を再構成するための分布パラメータが取得され、生成されたデータがこの分布からサンプリングされます。これがVAEの生成プロセスです。
-
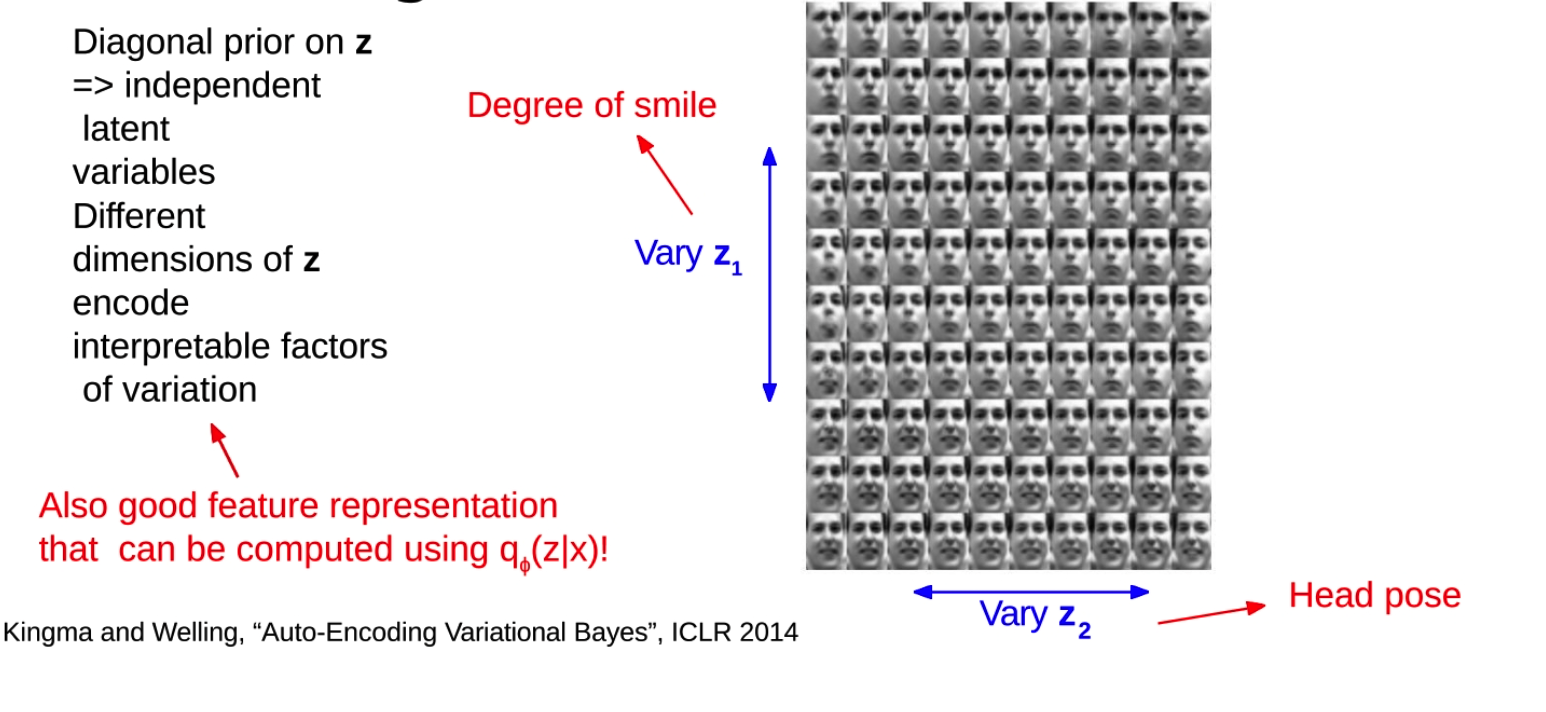
VAE の重要な特性は、異なる次元の潜在変数 z が通常、入力データ内の異なる要素をエンコードすることです。**これらの要因は通常説明可能です。** つまり、潜在変数の変化が生成されたデータにどのような影響を与えるかを理解できます。たとえば、顔の画像を処理する場合、笑顔の程度を制御する 1 つの潜在変数と、頭の姿勢を制御する別の潜在変数が存在する可能性があります。
-
事前分布から潜在変数 z をサンプリングし、ある次元に沿って z の値を変化させると、生成されたデータがどのように変化するかを観察できます。これは、モデルが何を学習したか、および潜在変数が入力データ内の情報をどのようにエンコードするかを理解するのに役立ちます。
-
最後に、エンコーダ ネットワークは入力データを潜在空間にマッピングできるため、特徴表現学習の方法として VAE を使用することもできます。これは、トレーニングされたエンコーダ ネットワークを分類やクラスタリングなどの他のタスクに使用できることを意味し、ラベルのないデータをより有効に活用できるようになります。
-
普及モデル
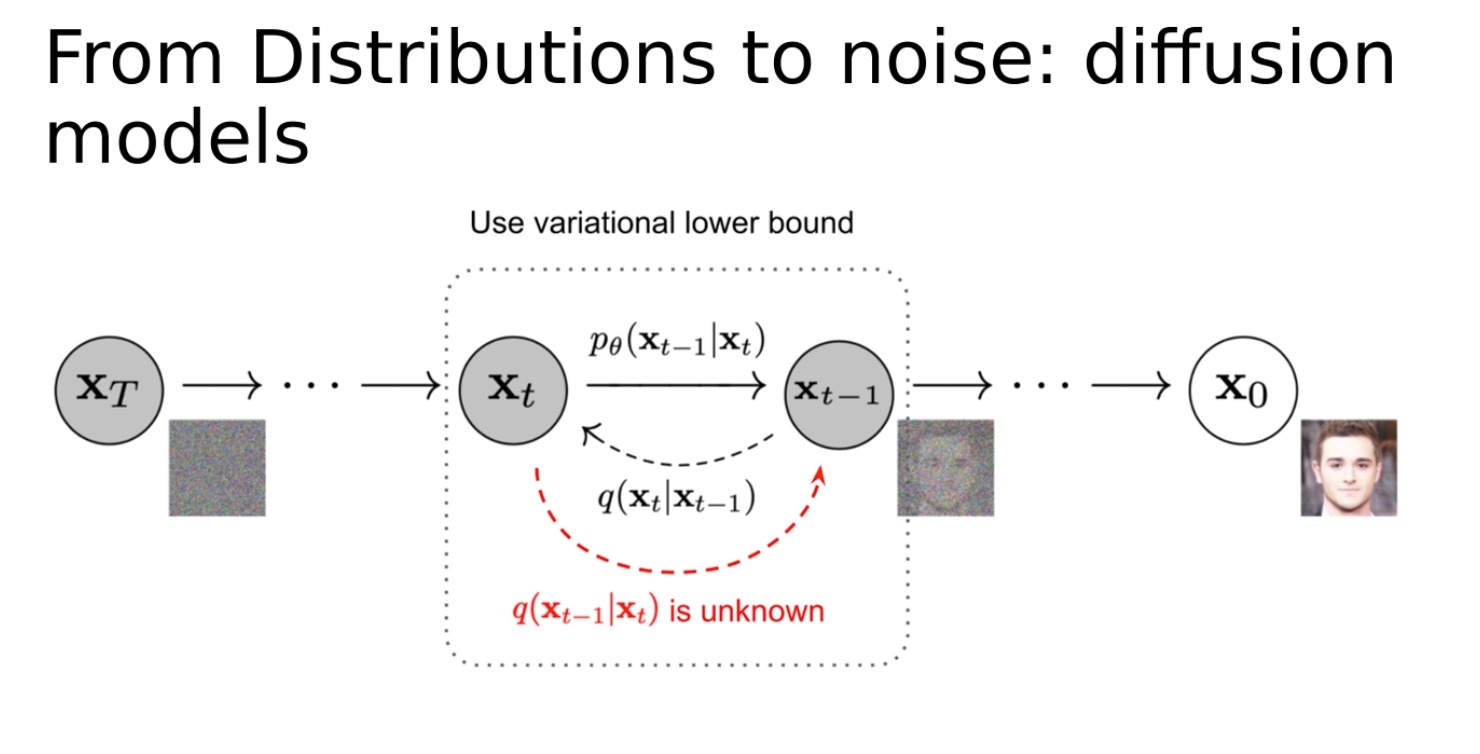
配信からノイズまで: 拡散モデル。これは、データ生成の問題を拡散プロセスとしてモデル化する生成モデリングとは異なるアプローチです。このプロセスでは、ランダムなノイズから始めて、生成したいデータになるまでこのノイズを徐々に変更します。このプロセスは、初期ノイズ分布からターゲット データ分布への連続的な変化として見ることができます。
長所短所

-
アドバンテージ:
-
生成モデルへの原則に基づいたアプローチ: VAE は、データの尤度を最大化する原則に基づいてモデル パラメーターを学習する確率モデルを使用します。
-
q ( z ∣ x ) q(z|x) を推論できます。q ( z ∣ x ) : VAE トレーニング プロセスのエンコーダー部分は、特徴表現学習の方法として使用でき、分類やクラスタリングなどの他のタスクに使用できます。
-
-
欠点:
-
尤度の下限を最大化する: VAE の目的関数は、尤度そのものではなく、尤度の下限です。これは、VAE のトレーニングがデータの尤度を完全に最適化していない可能性があるため、一部のタスクでは尤度を直接最適化する方法ほどうまく機能しない可能性があることを意味します。
-
低品質の生成サンプル: 他のいくつかの生成モデル手法 (敵対的生成ネットワーク、GAN など) と比較して、VAE によって生成されるサンプルは通常、ぼやけるなど、品質が低くなります。
-
-
VAE の現在の研究ホットスポットのいくつか
- これらには、事後分布のより豊富な近似 (混合ガウス モデル、GMM など) や潜在変数へのより多くの構造の組み込み (カテゴリ分布など) が含まれます。
2 番目のネットワーク: GAN を使用してトレーニングする

詳細については、以前のブログ「生成モデル (オートエンコーダー、VAE、GAN)」を参照してください。

