データサービスはデータ構築において重要な役割を果たします。データサービスとは正確には何ですか? APIを外部に提供するだけですか?とても簡単?
この部分のコンテンツを読み終えた後は、データ サービスの製品機能設計とシステム アーキテクチャ設計を真にマスターできることを願っています。データ サービスの設計や商用製品の選択に非常に役立つからです。
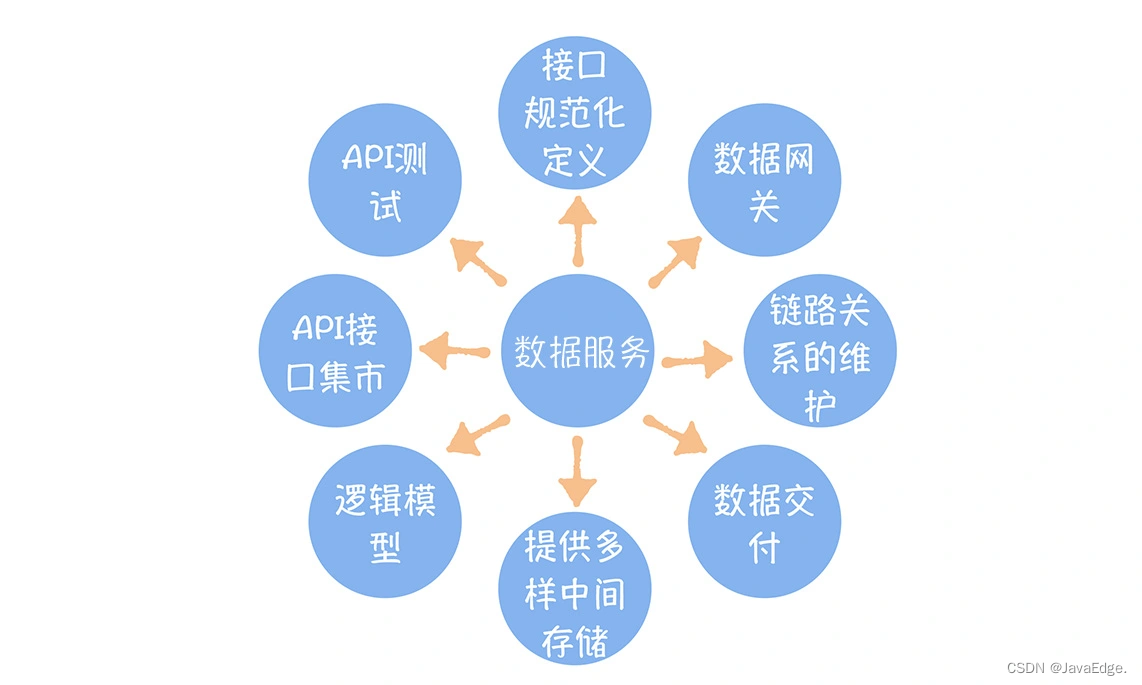
1 データサービスが持つべき8つの機能
上記の問題を解決するには、データ サービスには少なくとも 8 つの機能が必要です。例えば、データへのアクセス方法が多様でアクセス効率が低い、データやインターフェースを共有する方法がない、どのアプリケーションがデータにアクセスしているのか分からない…などです。
大きな菜鳥駅を想定すると、たくさんの棚があり、各棚の前に宅配便を受け取るのを手伝ってくれるスタッフがいて、同時に多くの行列ができています。
速達を受け取るには、まずインターフェース(受け取りコードを一律に使用するなど)について合意します。次に、異なるチームが宅配業者を確実に受け取れるようにするために、各チームの流れを制限します (たとえば、チームは一度に 1 人だけを受け取ることができます)。宅配業者を受け取ると、駅の機械がスキャンしてどの宅配業者が受け取ったかを記録するため、追跡に便利です。
この期間中、彩鳥郵便局のサービスは速達だけでなく、戸別配達にもアップグレードされました。生鮮食品の棚は冷蔵冷蔵庫、書類や封筒の棚はファイルキャビネットなど、速達の種類に応じた棚も異なります。
宅配業者を受け取る人にとって、生鮮食品を買ったり、封筒を買ったりすると、何列にも並ばなければならず不便です。一般に、宅配便を受け取る人は 1 つの列にのみ並ぶのが最善であり、郵便局のスタッフが複数の棚から宅配便を一度に取り出すのを手伝ってくれます。
しかし、郵便局には棚が多すぎるため、宅配便を受け取る人全員が各棚とチームをすぐに見つけられるように、郵便局ではガイドを提供しています。駅員にミスをさせないために、駅員は勤務する前に厳しい試験に合格しなければならない。
データサービスの 8 つの機能に戻ります。take Express の例では、次のことができます。
- Cainiao ステーションとしてのデータ サービス
- ワーカーを API 分離ライブラリとして考える
- 中間収納としての棚
- 宅配業者はそれをデータだと考えている
8つの機能に対応:
- インターフェースの標準化定義、配送業者が合意した配送コードを取得し、統一配送コードに基づいて配送業者を取得
- データ ゲートウェイは、各棚の前のキューの流れを制限して、各キューが高速に到達できるようにするものとみなすことができます。
- 郵便局は誰がどの宅配便を受け取ったかを記録するため、リンク関係の維持がわかります。
- データ配送は、速達と宅配サービスを同時に提供する郵便局と言えます。
- さまざまなタイプの棚とみなすことができるさまざまな中間ストレージを提供します
- 論理モデルは、複数の棚から速達便を受け取ることができるスタッフ メンバーとみなすことができます。
- API インターフェースは、ステーションのさまざまな棚にあるさまざまなチームのためのガイドとみなすことができます。
- APIテストは駅員の入社前テストといえる
この話を通じて、データ サービスの 8 つの機能をすでに鮮明に理解できましたか? 次に、データサービスの8つの機能には具体的にどのような機能があるのかを見ていきましょう。
1.1 インターフェースの標準化された定義
インターフェイスの標準化された定義は、特急を受け取るときに合意した受け取りコードです。データ サービスは、データ アプリケーションごとに異なる中間ストレージを保護し、統合された API を提供します。
データ サービス インターフェイスの概略図:
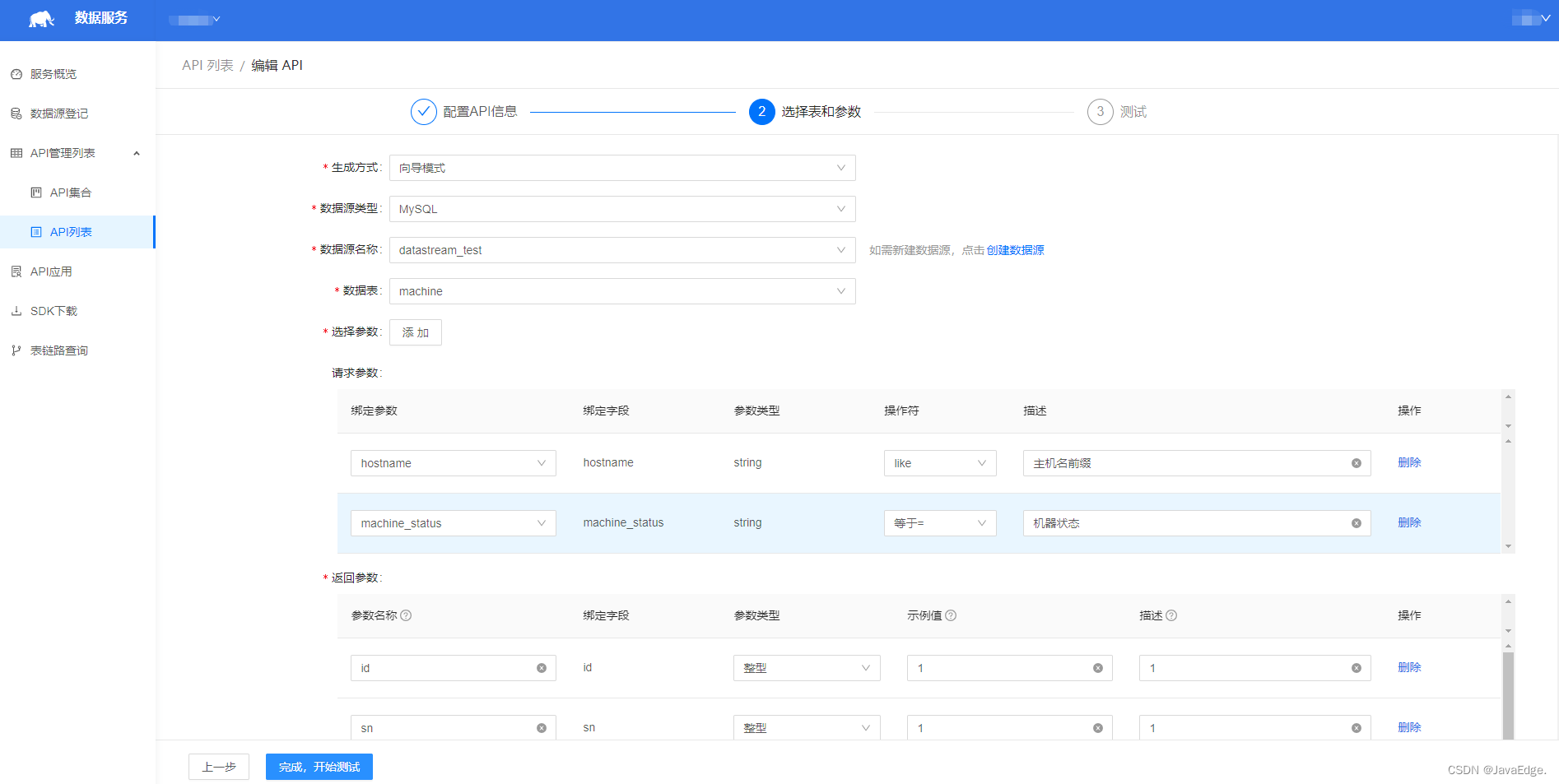
上の図では、データ サービス上の各 API インターフェイスの入力パラメーターと出力パラメーターを定義できます。
1.2 データゲートウェイ
データサービスはゲートウェイサービスとして、認証、権限、電流制限、監視の4つの主要な機能を備えている必要があり、これがデータとインターフェースの多重化の前提となります。これはルーキーの駅前で宅配業者を受け取るときと同じで、各チームの動線を認証して制限する必要があります。
認証済み
インターフェイスのセキュリティの問題を解決するために、データ サービスはまず、登録された各アプリケーションにアクセスキーとシークレットキーのペアを割り当てます。これは、アプリケーションが API インターフェイスを呼び出すたびに保持する必要があります。
公開された API ごとに、API の担当者がアプリケーションを承認でき、承認されたアプリケーションのみがインターフェイスを呼び出すことができます。
API インターフェースの担当者は、アプリケーションのフローを制限し (たとえば、1 秒あたりの QPS を 200 以下に制限する)、それが超過した場合にヒューズをトリガーすることができます。
インターフェースを多重化するには電流制限機能が必要であり、そうでないと異なるアプリケーション間で相互影響を与えてしまいます。
アプリケーションからインターフェースへの認可の概略図

もちろん、データ サービスは、インターフェイスのリクエスト応答時間の 90%、インターフェイス呼び出しの数、失敗の数など、インターフェイス関連のモニタリングも提供します。また、長期間呼び出されなかった API も監視します。時間はオフラインである必要があります。この利点は、無駄なインターフェイスが追加のリソースを占有するのを防ぐことです。
1.3 リンク全体を開く

データ サービスは、データ モデルとデータ アプリケーション間のリンク関係を維持する責任も負う必要があります。
上図のビジネス分析はデータ アプリケーションであり、Zhen Meili はデータ アプリケーション開発者です。テーブル A と B のデータを取得するためにデータ サービスの特定のインターフェイスにアクセスしたい場合、彼女は次の権限を申請する必要があります。インターフェースの出版社、Ma Shuai。その後、ビジネス分析はインターフェイスを通じてデータを取得できます。
データ サービスは、ビジネス分析とテーブル A と B のアクセス関係をデータ センターのメタデータ センターにプッシュします。次に、メタデータ センターのテーブル A、B、および A と B の上流のすべてのテーブル (図の D、E) には、ビジネス分析データ アプリケーションのラベルがあります。
テーブル D の出力タスクが異常である場合、馬帥はメタデータ センターを通じて、そのタスクがビジネス分析データ製品のデータ出力に影響を与えることを迅速に判断できます。同時に、Ma Shuaishuai がテーブル D をオフラインにしたい場合、このテーブルにラベルがあるかどうかを確認することで、このテーブルの下流にアプリケーション アクセスがまだあるかどうかをすぐに判断できます。API インターフェイスの承認をキャンセルすると、メタデータ センターはテーブルの関連タグもクリーンアップします。
データアプリケーションには多くのページが含まれており、影響を分析する際にアプリケーションの粒度だけを分析するのは粗すぎるため、タスクに異常がある場合には、どのデータ製品なのかだけでなく、どのページなのかも把握する必要があります。インターフェイスを認証するときに、ページ名をマークできます。
1.4 プッシュおよびプルのデータ配信方法
皆さんが耳にするデータ サービスはすべて API インターフェイスの形式で提供されますが、実際のビジネス シナリオでは API だけでは十分ではありません。APIはプル方式と呼ばれていますが、実際の業務ではプッシュも必要です。
たとえば、リアルタイムのライブ ブロードキャスト シナリオでは、販売者はイベントに関する販売データをできるだけ早く取得する必要があります。このとき、データ サービスにはプッシュ機能が必要です。私はこれをデータ ドアツーと呼んでいます。ドアサービス。データ サービスはリアルタイムでデータを Kafka に書き込み、アプリケーションは Kafka のトピックをサブスクライブすることでリアルタイムのデータ プッシュを取得できます。
1.5 中間ストレージを使用してデータクエリを高速化する
データ内の台中データは、Hive または Spark コンピューティング エンジンに基づく Hive テーブルの形式で存在しますが、データ製品の低遅延および高同時アクセス要件を満たすことができません。
一般的なアプローチは、Hive テーブルからリアルタイム クエリ機能を提供する中間ストレージにデータをインポートすることです。データ サービスは、アプリケーション シナリオに応じて複数の中間ストレージをサポートする必要があります。一般的に使用されるいくつかの中間ストレージとシナリオがリストされています。

1.6 データ再利用を実現する論理モデル
各棚に係員がいますが、急行を受け取る人には愛想が悪く、急行を一人で全部受け取るのがベストです。データ サービスの論理モデルに似ています。
データ サービスで論理モデルを定義し、その論理モデルに基づいて API を公開できます。論理モデルの背後には複数の物理テーブルがあります。ユーザーの観点から見ると、1 つのインターフェイスで複数の異なる物理テーブルにアクセスできます。
論理モデルはデータベース ビューと比較できます。物理モデルと比較すると、論理モデルはテーブルとフィールド間のマッピングのみを定義し、データはクエリ中に動的に計算されます。論理モデルは、同じ主キーを持つ物理モデルで構成される大きな幅の広いテーブルとみなすことができます。論理モデルは、データの再利用の問題を解決します。同じ物理モデル上で、アプリケーションは独自のニーズに応じて異なる論理モデルを構築でき、各アプリケーションは異なる列を参照します。
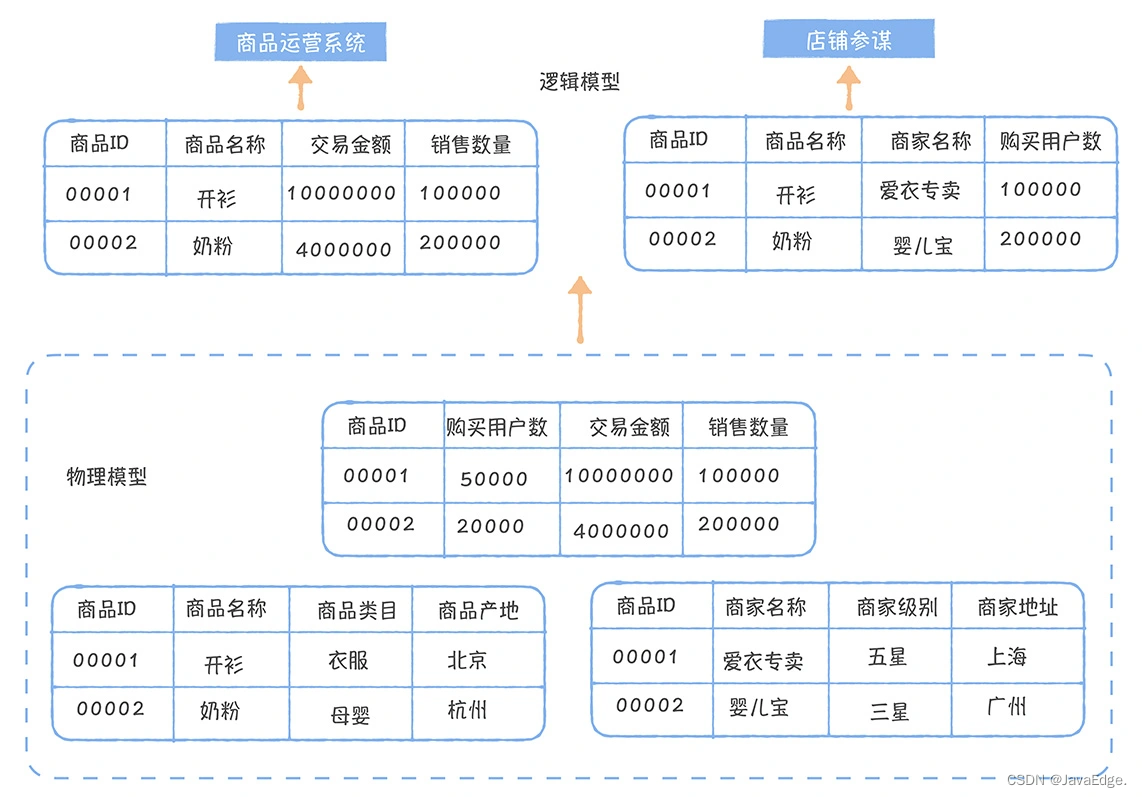
上記の例では、物理モデルが 3 つありますが、主キーは製品 ID であり、商品の運用システムと店舗スタッフについては 2 つの異なる論理モデルを構築し、異なる視点からデータを確認することができます。実際には存在しませんが、クエリの際、論理モデルによってマッピングされた物理モデル フィールドに従って、リクエストを複数の物理モデルに動的に分割し、複数のクエリ結果を集約して論理モデルのクエリ結果を取得します。
1.7 インターフェースの再利用を実現するための API マーケットプレイスを構築する
インターフェースの再利用を実現するにはAPIマーケットを構築する必要があり、アプリケーション開発者はAPIマーケットで既存のデータインターフェースを直接見つけ、そのインターフェースのAPI権限を直接申請することで、開発を繰り返すことなくデータにアクセスできるようになります。
データ サービスは、メタデータ センターを通じて、インターフェイスによってアクセスされるテーブルに関連付けられたインジケーターを取得できます。ユーザーはインジケーターの組み合わせに基づいてインターフェイスをフィルタリングし、目的のデータに従ってデータを提供できるインターフェイスを検索し、閉ループを形成できます。
データサービスはどのように実装すべきでしょうか?
2 データサービスシステムのアーキテクチャ設計
データ サービスを実装する場合、主にクラウド ネイティブの論理モデルと自動データ エクスポートが使用されます。
- データ サービスの設計を完了するための私の方法から学ぶことができます
- または、商用製品を選択する場合は、アーキテクチャの選択を参照してください。
2.1 クラウドネイティブ
主要な利点は、各サービスが少なくとも 2 つのコピーを持ち、高いサービス可用性を実現すると同時に、アクセス量に応じてサービスのコピー数を動的に調整できること、サービス ディスカバリに基づいて、透過的で柔軟なスケーリングを実現できることです。クライアントのために。相互影響を避けるため、リソースはコンテナに基づいてサービス間で分離されます。これらの機能は、高い同時実行性、低い遅延、およびオンライン データ クエリを備えたデータ サービスに適しています。

データ サービスのデプロイメント アーキテクチャ。公開された各 API インターフェイスは、k8s サービスに対応します。各サービスは、ポッドの複数のコピーで構成されます。バックエンド ストレージ エンジンにアクセスするための各 API インターフェイスのコードは、ポッドに対応するコンテナ内で実行されます。 API インターフェース呼び出しの数が変化し、Pod を動的に作成および破棄できます。
Envoy は、HTTP リクエストを複数のサービス ポッドにロード バランシングできるサービス ゲートウェイです。Ingress Controller は、Kubernetes の各サービスのポッドの変更を表示し、ポッド IP を Envoy に動的に書き戻すことで、動的なサービス検出を実現できます。フロントエンド APP、Web またはビジネス システム サーバー エンドは、4 層の負荷分散 LB を通じて Envoy にアクセスします。
クラウドネイティブ設計は次のことを解決します。
- データサービスの異なるインターフェース間のリソースの分離
- リクエスト量に応じたダイナミックな水平展開が実現可能
- Envoyで電流制限と融合を実現
2.2 論理モデル
物理モデルと比較すると、論理モデルには実際のデータは保存されず、論理モデルと物理モデル間のマッピングのみが含まれ、データはクエリのたびに動的に生成されます。論理モデルの設計により、異なるインターフェイスを使用して同じデータに対して必要なデータのみを表示する必要性が解決されます。
データサービスロジックモデルのシステム設計図:
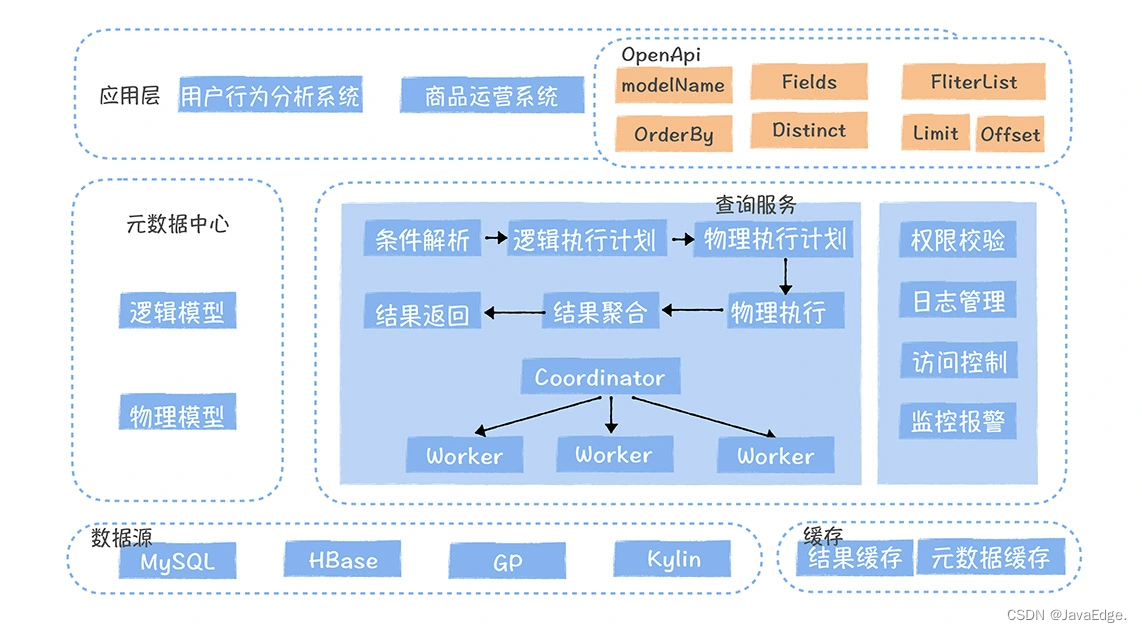
インターフェイス パブリッシャーは、データ サービス内で同じ主キーを持つ複数の物理テーブルを選択して論理モデルを構築し、その論理モデルに基づいてインターフェイスをパブリッシュします。API サービスがクエリ要求を受信した後、論理モデルと物理モデルのフィールド間のマッピング関係に従って、論理実行プランが物理モデルの物理実行プランに分解され、複数の物理モデルが実行のために発行されます。最後に、実行結果が分析され、集計されてクライアントに返されます。
論理モデルに関連付けられた物理モデルはさまざまなクエリ エンジンに分散できますが、現時点ではパフォーマンス要因を考慮して、主キー ベースのフィルタリングのみがサポートされています。
2.3 データの自動エクスポート
データサービスはデータセンター内のテーブルを選択し、中間ストレージにデータをエクスポートし、外部にAPIを提供します。データはいつ中間ストレージにインポートされますか? データの出力が完了するまでお待ちください。
したがって、ユーザーがデータセンター内のテーブルを選択し、テーブルの中間ストレージを定義すると、データサービスは自動的にデータエクスポートタスクを生成し、同時にテーブルの出力タスク間の依存関係を確立します。出力タスクが完了すると、データ エクスポート サービスがトリガーされ、データが中間ストレージにエクスポートされます。このとき、API インターフェイスを通じて最新のデータを照会できます。

3 まとめ
データ サービスは API インターフェイスほど単純ではありませんが、その背後には、データを標準化して配信するための完全なプロセス セットがあります。この記事では、データ サービスの 8 つの主要な機能設計と 3 つのシステム アーキテクチャ設計を学習しました。
- データサービスは、データセンターモデルとデータアプリケーション間のフルリンク接続を実現し、どのアプリケーションが影響を受けるか分からないタスク異常影響分析とデータオフラインの問題を解決します。
- 同じ主キーの物理モデルに基づいて論理モデルを構築できるため、データの再利用の問題が解決され、インターフェイス モデルの公開効率が向上します。
- データ サービスは、サービスの高可用性、柔軟なスケーリング、リソースの分離の問題を解決できるクラウド ネイティブの設計パターンを採用する必要があります。
データサービスは、データ配信プロセスの高速化とデータ配信後の運用保守管理の効率化に重要な役割を果たしており、データセンターの重要なコンポーネントでもあります。

よくある質問
データ サービスが、どのアプリケーションがデータにアクセスするかという問題を解決したい場合、すべてのデータ アプリケーションがデータ サービスを通じてデータ センターのデータを取得する必要があることを保証する必要があります。データセンターの出口だけ?
データ サービスがデータ センターの唯一の出口であることを保証するには、次の手段を使用します。
-
データ サービスのアクセス許可を決定します。承認されたアプリケーションのみがデータ サービスにアクセスでき、他のアプリケーションはデータ サービスにアクセスできません。
-
ネットワーク分離の実装: データ サービスを独立したネットワークに展開し、承認されたアプリケーションのみがネットワーク分離を通じてデータ サービスにアクセスできるようにします。
-
認証と認可の実装: データ サービスにアクセスするアプリケーションごとに、認可されたアプリケーションのみがデータ サービスにアクセスできるようにするために、認証と認可が必要です。
-
監査と監視の実装: データ サービスにアクセスするアプリケーションごとに、承認されたアプリケーションのみがデータ サービスにアクセスできるようにし、異常な状況を適時に検出して処理できるようにするために、監査と監視が必要です。