このレッスンでは、主に Curl コマンドの使用法と一般的なケースを理解します。このレッスンの内容を学ぶ前に、HTTP リクエスト プロセスと Linux オペレーティング システムの基本を理解する必要があります。
まず、最初に Curl について紹介しましょう。Curl は、Linux コマンド ラインのツールです。クライアント リクエストをシミュレートし、HTTP または HTTPS としてのリクエスト プロトコルに従います。前のコースでは、Chrome ブラウザでの開発者ツールについて学びました。同様のツールですが、IDE ツールではなくコマンドライン ツールである点が異なります。
実際、多くのシナリオでコマンド ライン ツールが必要です。スクリプトのセットがあり、HTTP API インターフェイスを呼び出す必要がある場合、または独自の Web サイト サーバーのステータスを監視する必要がある場合は、コマンドを使用して HTTP\HTTPS を作成する必要があります。呼び出しをリクエストし、結果を取得します。
また、Web サイトの障害や問題を素早く分析するツールを使用する必要がある場合、ブラウザではなくコマンドライン ツールも必要になるため、運用保守エンジニアは Curl の使用が重要であることを理解しています。コマンドは非常に必要です。
カールの使用
このクラスの内容は Curl コマンドを中心に展開し、いくつかのシナリオの使用体験を共有します。
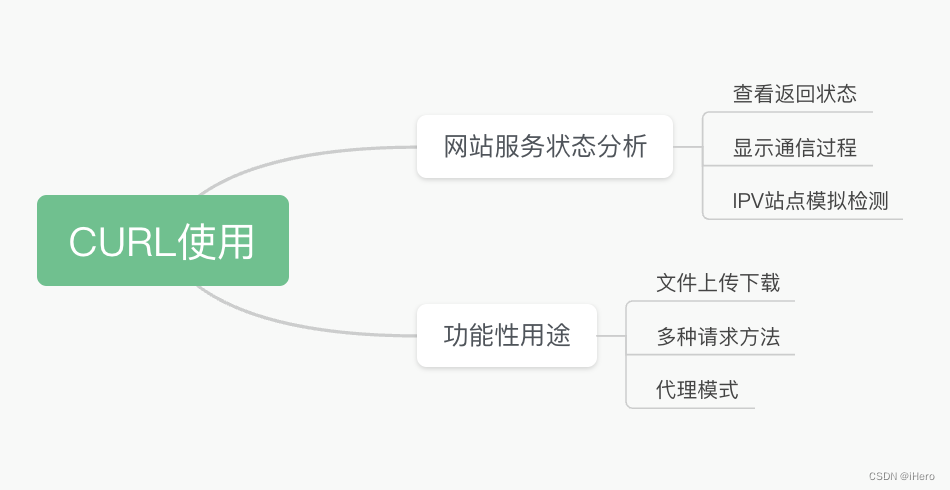
Curl の使用法は 2 つの主なカテゴリに分類されます。
1 つは Web サイトのサービス分析で、エンジニアは Web サイトの復帰状況を知りたい、HTTP 通信プロセス全体を理解したい、シミュレーション テストのための IPV6 サービス サイト環境などの具体的なシナリオを知りたい、などです。
2 番目のタイプは、機能的な目的での使用です。ここでは、Curl がファイルをアップロードおよびダウンロードする方法、アップロードを再開する方法、複数の HTTP リクエストを開始する方法、アクセスに Curl のプロキシ モードを使用する方法を学びます。
ウェブサイトのサービス分析
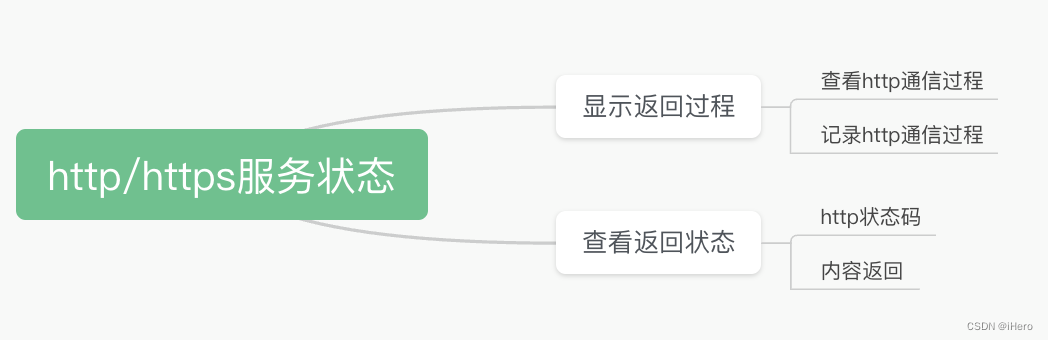
まずはWebサイトのサービス分析から始めましょう。Web サイトのステータス分析について話していると、学生からよく質問を受けます。「Web サイトが開けない場合はどうすればよいですか?」などです。自分でサービスをインストールしたのですが、ブラウザを開いたときにリクエストができません。どうすれば分析できますか? このような質問をすると、Web サイト サービス全体のトラブルシューティングについてあまり明確なアイデアが得られないと思います。以下に整理してみましょう。
サイトを展開して変更した後は、まずサーバーのステータスを分析し、次のプロセスから開始する必要があります。
- プロセスが開始されたかどうか見てみましょう? それは存在しますか?
- プロセスの状態は正常ですか? 実行中ですか、それともデッドロック状態ですか?
また、CPUなどのリソース使用率からプロセスが正常範囲内かどうかの分析や、ログによるエラー情報の分析にも利用できます。
プロセスのステータスが正常であることを分析した後、クライアントからサーバーへのアクセスに問題がある理由を理解する必要があります。
- まず、基盤となるネットワークからネットワークのステータスを ping できるかどうかを確認し、次に、TCP 接続が正常に確立されているかどうかを確認します。現時点では、
Telnet または TCPdump を使用してパケットをキャプチャまたは分析できます。
ネットワークの正常な状態を特定した後、上位層、つまりアプリケーション層で問題を探します。Web サイトが HTTP/HTTPS Web サービスを提供する場合は、サーバーへのHTTP リクエストをシミュレートして、ヘッダー情報が適切かどうかを判断する必要があります。サーバーから返された身体情報は要件を満たしているため、現時点では関連ツールを使用して分析する必要があると予想されます。Curl
コマンドは、このプロセスで非常に優れた役割を果たします。
Web サイトの HTTP/HTTPS サービス ステータスのチェックについて言えば、Curl コマンドはこの分析のために主にどのような側面をチェックしますか?
最も一般的なシナリオは、サーバー全体から返されるステータスを確認することです。先頭のヘッダー情報にはHTTPのステータス情報(Status Code)が含まれており、値が200であれば正常応答、異常応答であれば500、404、403などの値が表示されます。このステータス コードを使用して、問題の原因となる可能性のある方向を直接特定します。たとえば、403 はアクセス制限が原因である可能性があり、404 はファイルが見つからない可能性があり、500 はプログラムに問題がある可能性があります。
場合によっては、返される本文の内容が期待を満たしているかどうかを分析することを選択します。これはすべて Curl コマンドで実現できます。
Curlコマンドの使用形式
次にCurlの使い方を見ていきましょう。
まず、Curl コマンドの後にオプションを追加します。これは、Curl がリクエストを開始するためのパラメータを構成することを意味します (オプション)。最後に、リクエストする必要がある URL を追加します。ここでは、-i オプションを追加します。これは、ターミナルのみを意味します。 -i を追加せずにサーバーから返されたヘッダー情報を確認します。次に、デフォルトで返された本文データの内容を表示します。-o Output.txt が追加された場合、サーバーから返されたコンテンツをファイルに出力することを意味します。
その方法を見てみましょう。
まず、Curl コマンドを使用して baidu.com をリクエストします。この時点では、本文の HTML コードのみが返されることがわかります。返される応答ヘッド情報のみを確認したい場合はどうすればよいでしょうか? -I オプションを追加すると、サーバーから返された関連ヘッダー情報が表示されます。これには、多くの応答ヘッド情報が含まれています。たとえば、HTTP プロトコル タイプは 1.1、サーバー ステータス コードは 200 で、これは次のことを示します。サーバーは正常に戻ります。同時に、サーバーから返されたデータの長さ、タイプ、キャッシュされたヘッダー情報を確認できます。
上記は Curl で使用される一般的なモードですが、おそらくほとんどの学生はより明確に理解できるはずです。次に、いくつかの特別なシナリオを詳しく見てみましょう。
ここで私のブログ アドレスの URL をリクエストします (コマンド:curl www.taida.ltd)。デフォルトの本文データが返されていないことがわかります。なぜ?サーバーは 301 や 302 リダイレクトなどの一部のリダイレクト ステータス コードを返すため、本文データはなく、ヘッダー情報のみが返されるため、最初にヘッダー情報の内容を確認できます。
この時点で、通信プロセス全体をより包括的に理解したい場合は、-v (コマンド:curl www.taida.ltd) パラメーターを追加できます。リクエストサーバーがリクエストを送信したかどうかを確認できますか? クライアントから送信されたリクエストの内容と、サーバーから返された内容を確認できます。 -v パラメータを追加すると、通信プロセス全体が出力されます。
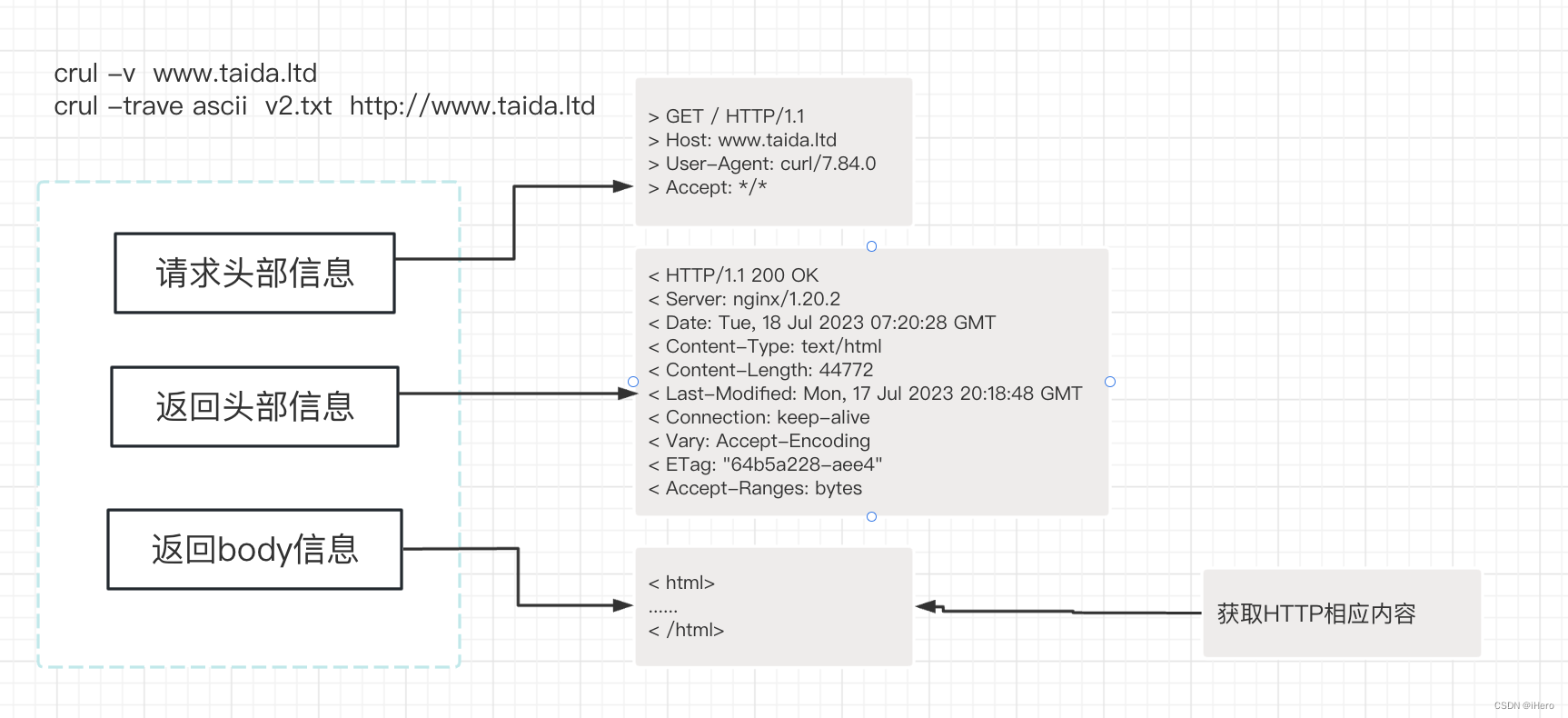
ここでは、-v を追加した後のリクエスト プロセス全体を確認できます。これには、リクエストのヘッダー情報、サーバーから返されるヘッダー情報、サーバーから返される本文情報がある場合、その本文情報が含まれます。プリントアウトすることもできます。
ヘッダー情報では、サービス ステータスのステータス コードに注目する必要がある場合があります。通常、次のルールに従って分析できます。
ステータス コードが 100 ~ 199 の場合、サーバーは通常は情報応答を返しましたが、完全な HTTP 要求応答が完全には確立されていないことを意味します。
200~299 は成功応答を意味し、このステータスコードを見ると、サーバーはこのリクエストを正常に処理していると考えられます。
300 ~ 399 はリダイレクトを意味し、301、302 などの一般的なリダイレクト ステータス コードです。
400 を超える場合は、クライアントのリクエスト メソッドが正常な応答を取得できないことを意味します。403、404、499、400 およびその他の関連エラー コードなどのステータス コードを詳細に分析する必要があります。理解できない場合は、Baidu または Google でエラー コードを検索して、その意味を確認してください。
500+ は通常、サーバー プログラムまたはロジック関連のサービス応答に問題があります。
次に、コンソールに戻ってさらにデモを進めてみましょう。
-v パラメーター (curl -v www.taida.ltd) を使用すると、サーバーから返されたステータス コードが 301 であることがわかります。これは、リダイレクトされたステータス コードが返されたことを意味し、場所のヘッダー情報は次のようになります。与えられた。ステータス コード 301 は、リクエストが別のアドレスに直接リダイレクトされていることを示しており、location の後のアドレスがリダイレクトされたアドレスであることがわかります (Location: http://www.taida.ltd/jeson)。このとき、Curl コマンドの 1 ステップでこのアドレスを要求することはできますか? 現時点では、-L パラメーターを使用して実現できます。
ここでは、効果を確認するために -L パラメーター (curl -L http://www.taida.ltd) を追加します。このとき、通信プロセス全体が変更され、多くの本文情報が出力されることがわかります。出力された情報の先頭に戻って、通信プロセスを見てみましょう。
まず、サーバーが初めてリダイレクト ステータス (301 リダイレクト) を返したときに、Curl がリダイレクトされたアドレスに対してリクエストを再度開始し、最終的に最後のリクエストの本文データと応答コードを取得することがわかります。
次に、コンソール上の他の Curl シナリオと、Curl リクエストにリクエスト ヘッダー情報を追加する方法について詳しく説明していきます。
まず、ここにデータ パッケージをダウンロードするためのリンクがあることがわかります。これはダウンロード パッケージ (大量のデータ) であるため、-I パラメーターを追加します。返されたヘッド ヘッダー情報、ステータス コードを確認してください。リクエストの開始後にサーバーから返されるメッセージは 404 で、パッケージが見つからなかったことを示します。では、なぜここで 404 が返されるのでしょうか? このリクエスト リンクに特別なセキュリティ設定を行ったので、Nginx でリターン 404 ルールを直接設定し、クライアントが通常にアクセスしてダウンロードする前にリファラー情報を取得するように要求しました。Referer は、HTTP リクエスト ヘッダー内の共通情報ヘッダーであり、リクエストの送信元のアドレスを示すことがわかっています。
次に、Curl リクエストに Referer ヘッダー リクエストを追加します。ここで -e オプションを追加します (curl -e "http://www.taida.ltd/" -I http://www.taida.ltd/download) /ywgs_lg.tgz
) を追加し、サーバーのルールに一致し、正常にアクセスできるように、必要な参照リンク アドレス URL を追加します。。
見てみましょう。このときに返されるのはステータス コード 200 です。
カールコマンドの使い方
コンソールのデモを終了して、Curl コマンドの使用方法をさらに見てみましょう。
HTTPS サイトにアクセスしている場合、HTTPS サイトは公開証明書とカスタム証明書の種類に分けられます。公開証明書の場合は、ローカルで秘密キーを追加する必要はありません。自分で作成したカスタム証明書の場合は、この時点でクライアントにキーを配置し、Curl に -E を追加して HTTPS サーバーを要求する必要があります。
その他の用途として、先ほどのデモで Referer ヘッダーを追加しましたが、その他の HTTP プロトコル ヘッダー情報を追加することもでき、HTTP リクエスト ヘッダーはユーザーがカスタマイズしたり書き換えたりすることができます。ここで特定の Web サイトをリクエストするときに、リクエストのブラウザ側で使用されているブラウザの種類を示す --user-agent ヘッダーを追加しました。
先ほどの説明でヘッダー情報はHTTPの標準ヘッダー情報であることがわかりましたが、カスタムリクエストヘッダー情報を追加することはできますか? もしそうならどうやって?現時点では、--head を通じてカスタム ヘッダー情報を追加できます。ここでは、Content-Type を追加するデモを示します。application/json は、リクエストのタイプ ヘッダー情報です。
もう 1 つの部分は、IPv6 を検出しているサーバー サイトをシミュレートすることです。
IPv6 は、IPv4 の IP アドレス不足を解決するために使用されることがわかっています。現在、多くの大規模 Web サイトではすでに IPv6 の使用が義務付けられ、IPv6 プロトコルをサポートしており、多くの基地局または独自の IP アドレスに IPv6 アドレスを割り当てることもできるようになるでしょう。ローカル アドレスに IPv6 アドレスがあり、サーバーが IPv6 サービスをサポートしている場合は、DNS 解決が IPv6 解決を優先する可能性が非常に高くなります。このようにして、IPv6 サービス サイトを検出する条件が満たされましたが、どうすればよいでしょうか?
コードに示すように、このような方法で実行できます。具体的に説明します。
curl -6 -vo /dev/null --resolve "static.meituan.net:80:[240e:ff:e02c:1:21::]" "http://static.meituan.net/bs/@mtfe/knb-core/latest/dist/index.js"
curl -6 は、IPv6 リクエストが開始されたことを示します。-v は実際の通信プロセスを示します。-o は、リクエストによって返された本体データをローカルの空のデバイスに配置することを意味します。つまり、本体データは表示されず、ヘッダー情報のみが表示されます。これは、-I の機能と同等です。–resolve はドメイン名と IP を解決することを意味し、ドメイン名 static.meituan.net のリクエスト アドレスを手動で指定して IPv6 アドレスに解決し、その後にリクエストされた URL を続けます。
これは、IPv6 全体のシミュレートされた検出の方法です。引き続きデモンストレーションを行ってください。この時点で、全体のリターン ステータスとリクエスト プロセスを確認できます。
さて、上記は Curl による Web サイトの調査の一部です。
カール機能の使用
次に、Web サイト分析やトラブルシューティングのシナリオで Curl を使用する以外の機能の使用方法をいくつか理解していきます。
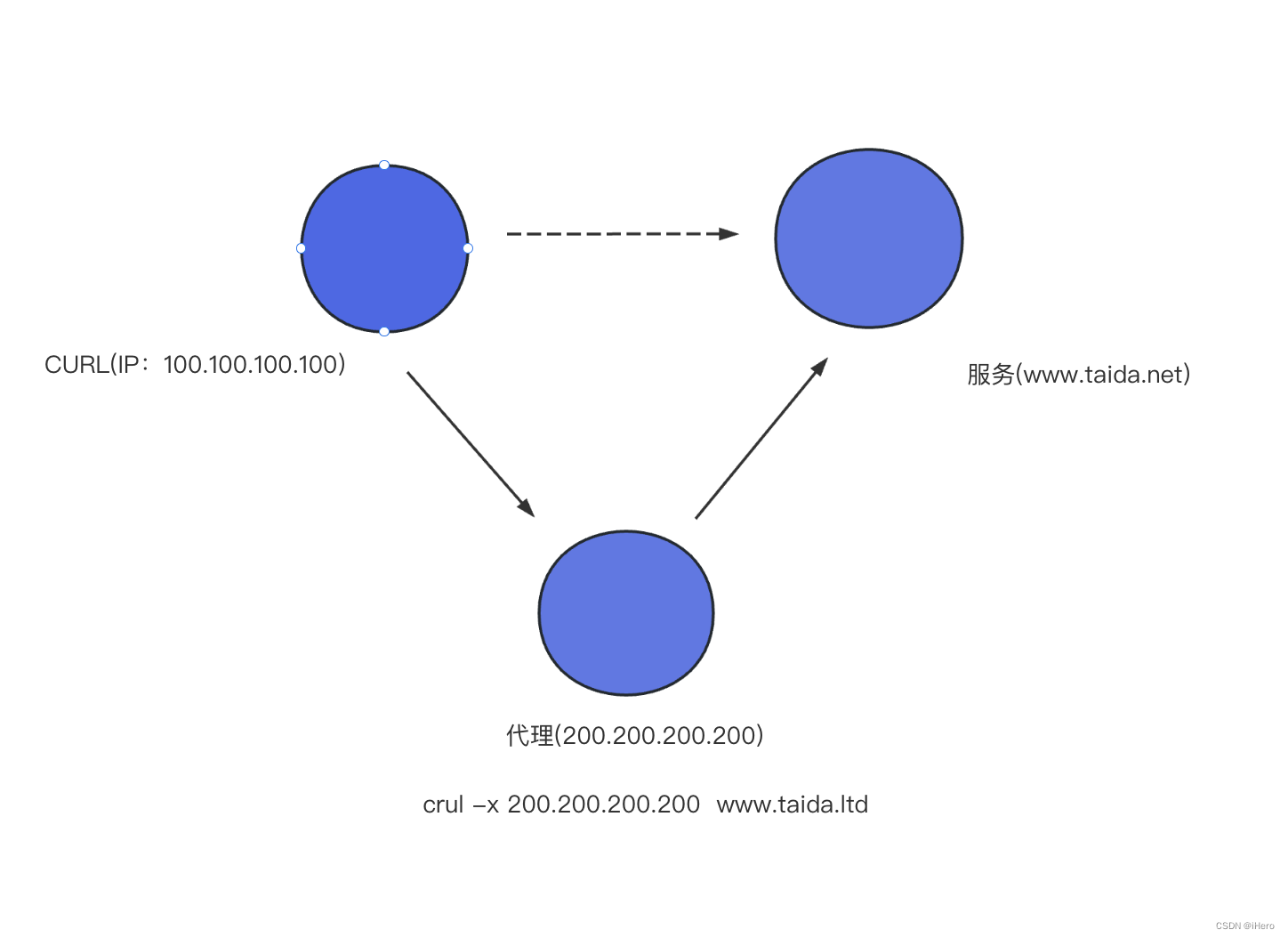
まず、1 つ目の方法はプロキシ モードで、Curl コマンドがプロキシ形式のリクエストをサポートできることがわかります。
ここでのプロキシの IP が 200.200.200.200 であるとします。次に、-x を追加するだけです。つまり、200.200.200.200 のマシンを介してサーバー サイトをリクエストします。これは、プロキシを介してアクセスする方法です。
もう 1 つはファイルのアップロードとダウンロードで、このような形式でファイルをアップロードできます。FTP プロトコルを通じてファイルを直接ダウンロードすることもできます。-C を追加すると、ブレークポイント再開が有効になります。ブレークポイント再開については、この図を参照してください。クライアントとサーバーは、ダウンロードおよびダウンロード時にこのパッケージのインデックスを取得します。ネットワークのジッターや変動がある場合、再度ダウンロードする場合は、このインデックスの値に基づいて直接ダウンロードを続行することも、元のブレークポイントの長さの範囲値に基づいてダウンロードを続行することもできるため、ファイルを安定してダウンロードしたい場合は、アップロードを再開する方法を使用できます。ブレークポイントから。
Curl の HTTP リクエスト メソッド
最後の部分では、Curl コマンドの HTTP リクエスト メソッドを紹介します。
上で紹介した Curl では、サーバーのコンテンツを取得するために get メソッドが使用されていますが、get メソッド以外にも、post、add、option などの HTTP リクエスト メソッドが存在します。ただし、リクエスト メソッドを指定したい場合は、-X オプションにリクエスト メソッドを追加することで指定できます。
たとえば、-X post はサーバーにリクエストを POST することを意味します。arg1 はパラメータの名前、その後にパラメータの値、次に 2 番目のパラメータ arg2 とパラメータの値 (この場合はデータ) です。リクエストの情報は投稿の形式で送信されます。もう 1 つは put メソッドで、-X put を介して渡すこともできます。-d は渡した値です。delete メソッドを使用する場合は、サーバーに要求し、特定された URL のリソースを削除します。