
1. 説明
アテンションのメカニズムとは何か、また、セルフ アテンション、クエリ、キーと値、マルチヘッド アテンションなど、トランスフォーマーに関連するいくつかの重要なキーワードとブロックについて説明しました。このパートでは、これらのアテンション ブロックがトランスフォーマー ネットワーク、アテンション、セルフ アテンション、マルチヘッド アテンション、マスクされたマルチヘッド アテンション、トランスフォーマー、BERT、および GPT の作成にどのように役立つかを説明します。
2. 内容:
- RNN の課題と、Transformer モデルがそれらの課題をどのように克服できるか(パート 1 で紹介)
- アテンション メカニズム — セルフ アテンション、クエリ、キー、値、マルチヘッド アテンション (パート 1 で紹介)
- 変圧器ネットワーク
- GPT の基本 (パート 3 で説明)
- BERT の基本 (パート 3 で説明します)
3. 変圧器ネットワーク
論文 - 必要なのは注意だけです (2017)
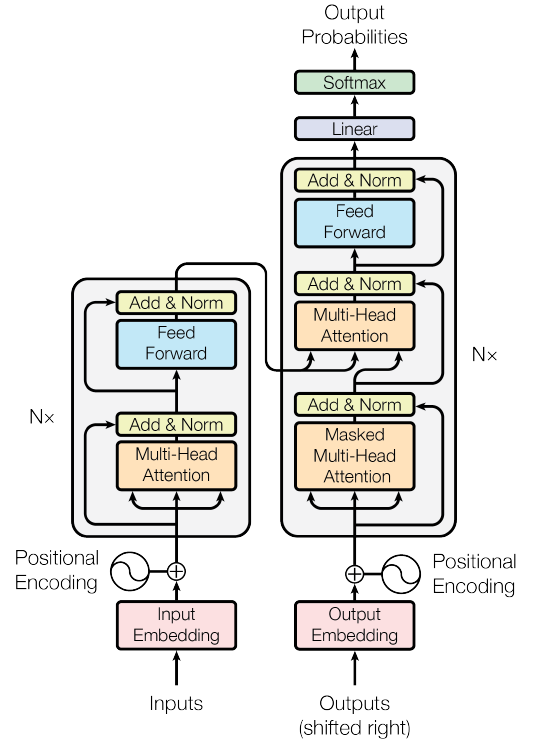
図 1. 変圧器ネットワーク (出典: 画像は原文から引用)
図 1 に変圧器ネットワークを示します。このネットワークは、NLP、さらにはコンピューター ビジョン ( Vision Transformer )の最適なモデルとして RNN に取って代わりました。
ネットワークは、エンコーダとデコーダの 2 つの部分で構成されます。
機械翻訳では、エンコーダを使用して元の文をエンコードし、デコーダを使用して翻訳文を生成します。Transformer のエンコーダは文全体を並列処理できるため、RNN よりも高速かつ優れています。RNN は文を一度に 1 単語ずつ処理します。
3.1 エンコーダブロック

図 2. 変圧器ネットワークのエンコーダ部分 (出典: 画像は原文から引用)
エンコーダ ネットワークは入力から始まります。ここでは、文全体が一度にフィードされます。次に、それらは「input embedding」ブロックに埋め込まれます。次に、文内の各単語に「位置エンコーディング」が追加されます。このエンコードは、文内の各単語の位置を理解するために非常に重要です。位置埋め込みがない場合、モデルは文全体を順序や意味のない単語が詰まった袋として認識します。
詳細に:
3.1.1 入力エンベディング
— 文内の単語「犬」は、埋め込み空間を使用してベクトル埋め込みを取得できます。埋め込みとは、任意の言語の単語をそのベクトル表現に単純に変換することです。例を図 3 に示します。埋め込み空間では、類似した単語は同様の埋め込みを持ちます。たとえば、「猫」という単語と「子猫」という単語は埋め込み空間内で非常に近くなりますが、「猫」と「感情」という単語は空間内でより遠くになります。 。

図 3. 入力埋め込み (出典: 著者作成の画像)
3.1.2 位置コーディング
異なる文内の単語は異なる意味を持つ可能性があります。たとえば、「a. 私はかわいい犬を飼っています (動物/ペット - 位置 5)」と「b.」の単語「dog」です。なんて怠け者の犬なんだ!(値なし - 位置 4)、別の意味を持ちます。位置エンコーディングを支援します。これは、文内の単語のコンテキストと位置に基づいて情報を提供するベクトルです。
どのような文章でも、単語は次々に現れ、意味を持ちます。文中の単語がごちゃ混ぜになっていると、その文は意味が通じなくなります。ただし、コンバーターが文をロードするときは、それらを順番にロードするのではなく、並列的にロードします。Transformer アーキテクチャには並列ロード時の単語の順序が含まれないため、文内の単語の位置を明示的に定義する必要があります。これは、コンバータが文内で 1 つの単語が次の単語に続いていることを理解するのに役立ちます。ここで、位置情報の埋め込みが役に立ちます。これは単語の位置を定義するベクトル エンコーディングです。この位置埋め込みは、アテンション ネットワークに入る前に入力埋め込みに追加されます。図 4 は、アテンション ネットワークに入力される前の入力エンベディングと位置エンベディングを直感的に理解できるようにします。

図 4. 位置埋め込みの直感的な理解 (出典: 著者作成の画像)
これらの位置埋め込みを定義するにはさまざまな方法があります。たとえば、元の論文「Attending is All You Need」では、図 5 に示すように、著者らはサイン関数とコサイン関数を交互に使用してエンベディングを定義しています。

図 5. 元の論文で使用されている位置埋め込み (出典: 元の論文の画像)
この埋め込みはテキスト データには機能しますが、画像データには機能しません。したがって、オブジェクトの位置 (テキスト/画像) を埋め込む方法は複数あり、トレーニング中に修正または学習できます。基本的な考え方は、この埋め込みにより、単語を混乱させて意味を混乱させるのではなく、トランスフォーマー アーキテクチャが文内の単語の位置を理解できるようにするということです。
単語/入力の埋め込みと位置の埋め込みが完了すると、埋め込みはエンコーダの最も重要な部分に流れます。この部分には、「マルチヘッド アテンション」ブロックと「フィードフォワード」ネットワークという 2 つの重要なブロックが含まれています。
3.1.3 マルチヘッドアテンション
これが魔法が起こるメインブロックです。マルチヘッド アテンションについて詳しくは、このリンク ( 2.4 マルチヘッド アテンション)を参照してください。
ブロックは入力として、サブベクトル (文内の単語) を含むベクトル (文) を受け取ります。次に、マルチヘッド アテンションにより、ベクトルの各位置と他の位置の間のアテンションが計算されます。

図 6. スケーリングされたドット積アテンション (出典: 元の論文の画像)
上の図は、スケーリングされたドット積アテンションを示しています。これはセルフ アテンションとまったく同じですが、2 つのブロック (スケールとマスク) が追加されています。セフ・アテンションの詳細については、このリンク ( 2.1 セルフ・アテンション)を参照してください。
図 6 に示すように、スケールされたアテンションは、最初の行列乗算 (Matmul) の後にスケールを追加することを除いて、まったく同じです。
拡大縮小率は以下の通りです。

スケーリングされた出力はマスク レイヤに入ります。これはオプションのレイヤーであり、機械翻訳に役立ちます。

図7. アテンションブロック(出典:筆者作成画像)
図 7 は、アテンション ブロックのニューラル ネットワーク表現を示しています。単語の埋め込みは、最初にいくつかの線形レイヤーに渡されます。これらの線形層には「バイアス」項がないため、単なる行列の乗算にすぎません。レイヤーの 1 つは「キー」として表され、もう 1 つは「クエリ」として表され、最後のレイヤーは「値」として表されます。キーとクエリの間で行列の乗算を実行し、正規化すると、重みが得られます。これらの重みに値が乗算され、合計されて、最終的なアテンション ベクトルが得られます。このブロックはニューラル ネットワークで利用できるようになり、アテンション ブロックと呼ばれます。このようなアテンション ブロックを複数追加して、より多くのコンテキストを提供できます。最良の部分は、勾配逆伝播を取得してアテンション ブロック (キー、クエリ、値の重み) を更新できることです。
マルチヘッド アテンションは、複数のキー、クエリ、および値を取り込み、それを複数のスケーリングされたドット積アテンション ブロックに供給し、最後にアテンションを連結して最終出力を提供します。図 8 に示すように。

図8. 多頭注意(出典:筆者作成画像)
より簡単な説明: メイン ベクトル (文) にはサブベクトル (単語) が含まれており、各単語には位置的な埋め込みがあります。アテンションの計算では、各単語を「クエリ」として扱い、文内の他の単語に対応する「キー」を見つけて、対応する「値」の凸状の組み合わせを取得します。マルチヘッド アテンションでは、複数のアテンション (より良い単語の埋め込みとコンテキスト) を提供するために、複数の値、クエリ、およびキーが選択されます。これらの複数のアテンションは連結されて、最終的なアテンション値 (複数のアテンションすべてからのすべての単語のコンテキストの組み合わせ) が得られます。これは、単一のアテンション ブロックを使用するよりもはるかに優れています。
単純な単語の場合、マルチヘッド アテンションのアイデアは、単語の埋め込みを取得し、それを他の単語の埋め込み (または複数の単語) と組み合わせて、注意 (または複数の注意) を使用して、その単語のより良い埋め込みを生成することです (埋め込み周囲の単語のコンテキストの詳細)。
このアイデアは、クエリごとに異なる重みを使用して複数のアテンションを計算することです。
3.1.4 加算、ノルム、フィードフォワード
次のブロックは「加算と正規化」で、元の単語埋め込みの残りの接続を取得し、それらをマルチヘッド アテンション 埋め込みに追加し、平均 0、分散 1 に正規化します。
これは ' feedforward ' ブロックに入力され、その出力には 'add andnormalize' ブロックもあります。
マルチヘッド アテンションおよびフィードフォワード ブロック全体が、エンコーダー ブロック内で n 回 (ハイパーパラメーター) 繰り返されます。
3.2 デコーダブロック

図 9. 変圧器ネットワークのデコーダ部分 (出典: 元の論文の画像)
エンコーダの出力もまた一連のエンベディングであり、位置ごとに 1 つのエンベディングがあり、各位置のエンベディングには、その位置での元の単語のエンベディングだけでなく、注意を使用して学習した他の単語に関する情報も含まれます。
これは、図 9 に示すように、変圧器ネットワークのデコーダ部分に供給されます。デコーダの目的は、何らかの出力を生成することです。「attention is all you need」という論文では、このデコーダは文章の翻訳 (英語からフランス語など) に使用されています。したがって、エンコーダーは英語の文を受け取り、デコーダーはそれをフランス語に翻訳します。他のアプリケーションでは、ネットワークのデコーダ部分は必要ないため、これについては詳しく説明しません。
デコーダ ブロックのステップ—
1.文の翻訳では、デコーダ ブロックはフランス語の文を受け取ります (英語からフランス語への翻訳の場合)。エンコーダーと同様に、ここでも単語の埋め込みと位置の埋め込みを追加し、それをマルチヘッド アテンション ブロックに送ります。
2. セルフ アテンション ブロックは、フランス語の文内の単語ごとにアテンション ベクトルを生成し、文内のある単語と別の単語の関連性を示します。
3. 次に、フランス語の文の注意ベクトルが英語の文の注意ベクトルと比較されます。これは、英語からフランス語への単語のマッピングが行われる部分です。
4. 最後のいくつかのレイヤーでは、デコーダーは英語の単語から可能な限り最良のフランス語の単語への翻訳を予測します。
5. プロセス全体を複数回繰り返して、テキスト データ全体の翻訳を取得します。
上記の各ステップで使用されるモジュールを図 10 に示します。

図 10. 文翻訳におけるさまざまなデコーダ ブロックの役割 (出典: 著者作成の画像)
デコーダには、マスクされたマルチヘッド アテンションという新しいブロックがあります。他のすべてのブロックは、エンコーダーで以前に見たものです。
3.2.1マスクマルチヘッドアテンション
これは、特定の値がマスクアウトされるマルチヘッド アテンション ブロックです。マスクされた値が空であるかチェックされていない確率。
たとえば、デコードする場合、出力値は将来の出力ではなく、以前の出力にのみ依存する必要があります。次に、将来の出力をマスクします。
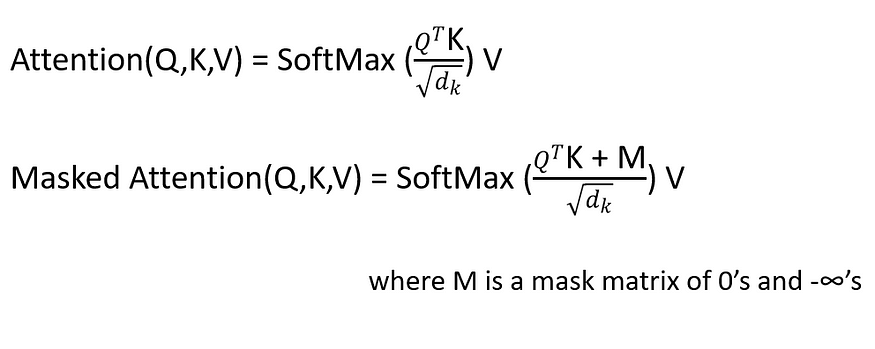
3.3 結果と結論

図 11. 結果 (出典: オリジナルの論文画像)
この論文では、英語からドイツ語、および英語からフランス語間の言語翻訳を他の最先端の言語モデルと比較しています。BLEU は、言語翻訳の比較に使用される指標です。図 11 から、大規模トランスフォーマー モデルが両方の翻訳タスクでより高い BLEU スコアを達成していることがわかります。また、トレーニングのコストも大幅に削減されました。
結論として、Transformer モデルは最先端の結果を取得しながら、計算コストを削減できます。
このパートでは、Transformer Networks のエンコーダー ブロックとデコーダー ブロック、および言語翻訳で各ブロックがどのように使用されるかについて説明します。次の最後のパート (パート 3) では、BERT (Bidirectional Encoder Representation from Transformers) や GPT (General Transformer) など、最近非常に有名になったいくつかの重要なトランス ネットワークについて説明します。
4. 引用
アシシュ・バスワニ、ノーム・シェイザー、ニキ・パルマー、ヤコブ・ウスコレイト、ライオン・ジョーンズ、エイダン・N・ゴメス、ウカシュ・カイザー、イリア・ポロスキン。2017. 必要なのは注意だけです。第 31 回神経情報処理システム国際会議 (NIPS'17) の議事録。Curran Associates Inc.、レッドフック、ニューヨーク州、米国、6000–6010。