感情と乾物を持って、WeChat で [荒廃した古代伝説] を検索し、この異なるプログラマーに注目してください。
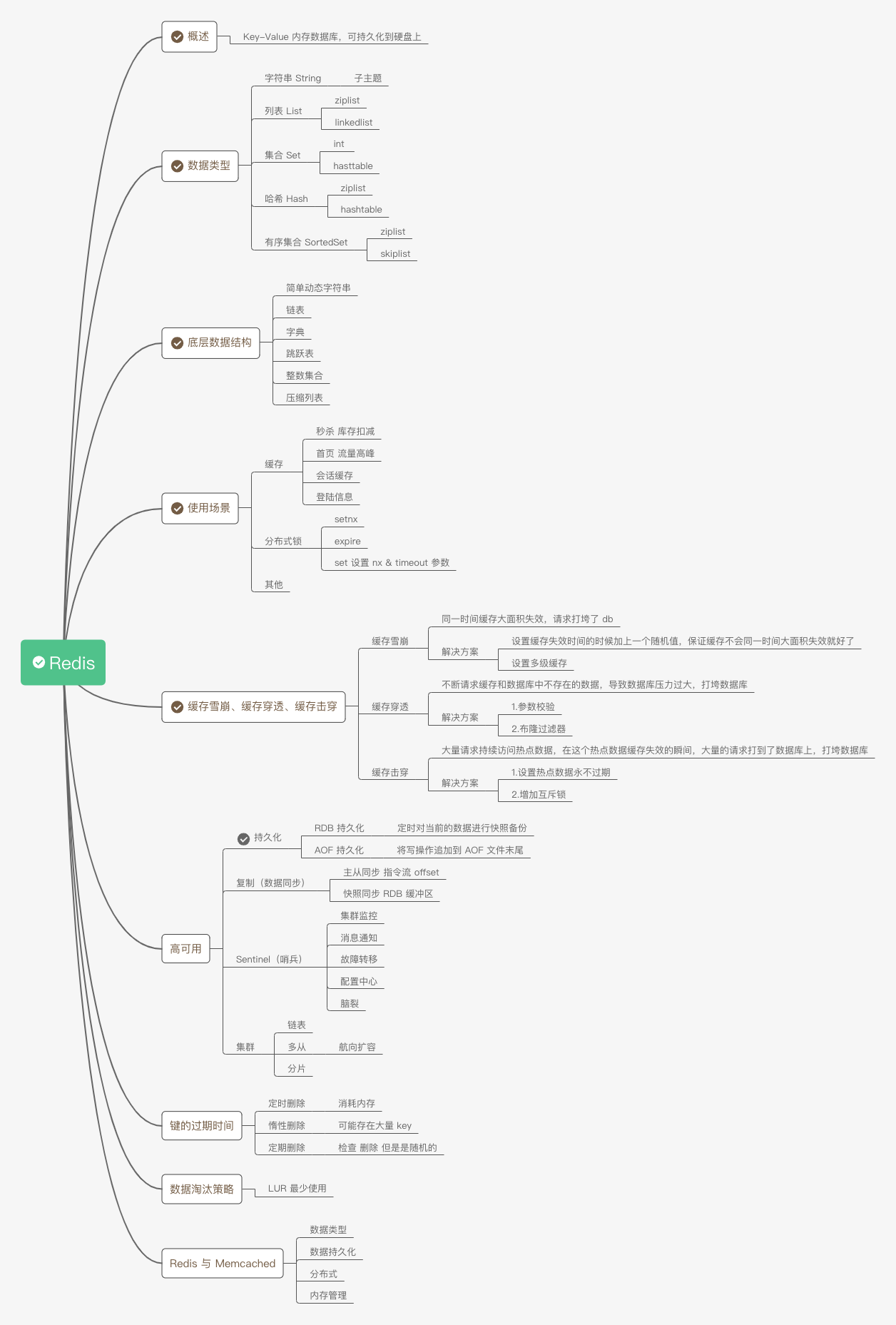
概要
Redis は、ディスクに永続化できるキーと値のメモリ内データベースです。キーのタイプは文字列のみですが、値のタイプは文字列、リスト、ハッシュ テーブル、セット、または順序付きセットにすることができます。
データの種類
Redis には、文字列、リスト、ハッシュ テーブル、セット、順序付きセットの 5 つのデータ型があります。
Redis には 8 つのエンコーディング (基礎となる実装) があります。つまり、long 型の整数、embstr によってエンコードされた単純な動的文字列、単純な動的文字列、辞書、両端リンク リスト、圧縮リスト、整数セット、ジャンプ リスト、辞書です。
弦

文字列オブジェクトのエンコーディングは、int、raw、または embstr です。
文字列オブジェクトが整数値を格納し、この整数値がlong型で表現できる場合、文字列オブジェクトはその整数値を文字列オブジェクト構造のptr属性に格納し(void*をlongに変換し)、文字列オブジェクトを int にエンコードします。
文字列オブジェクトが文字列値を保持し、文字列値の長さが 39 バイトを超える場合、文字列オブジェクトは単純な動的文字列 (SDS) を使用して文字列値を保存し、オブジェクトを raw に設定してエンコードします。
文字列オブジェクトが文字列値を格納し、その文字列値の長さが 39 バイト以下の場合、文字列オブジェクトは embstr エンコーディングを使用して文字列値を格納します。
> set hello world
OK
> get hello
"world"
> del hello
(integer) 1
> get hello
(nil)
リスト
[外部リンク画像の転送に失敗しました。ソース サイトには盗難防止リンク メカニズムがある可能性があります。画像を保存して直接アップロードすることをお勧めします (img-xhOv3PHP-1603168774635)(https://raw.githubusercontent.com/haxianhe/) pic/master/image/20200513150726 .png)]
リスト オブジェクトのエンコードは ziplist または linkedlist にすることができます。
ziplist でエンコードされたリスト オブジェクトは、基礎となる実装として圧縮リストを使用し、各圧縮リスト ノードはリスト要素を保持します。
linkedlist によってエンコードされたリスト オブジェクトは、基礎となる実装として両端リンク リストを使用します。各両端リンク リスト ノードには文字列オブジェクトが格納され、各文字列オブジェクトにはリスト要素が格納されます。
> rpush list-key item
(integer) 1
> rpush list-key item2
(integer) 2
> rpush list-key item
(integer) 3
> lrange list-key 0 -1
1) "item"
2) "item2"
3) "item"
> lindex list-key 1
"item2"
> lpop list-key
"item"
> lrange list-key 0 -1
1) "item2"
2) "item"
集める
[外部リンク画像の転送に失敗しました。ソース サイトには盗難防止リンク メカニズムがある可能性があります。画像を保存して直接アップロードすることをお勧めします (img-YecB5kUU-1603168774637)(https://raw.githubusercontent.com/haxianhe/) pic/master/image/20200513161259 .png)]
コレクション オブジェクトのエンコードは intset または hashtable にすることができます。
intset でエンコードされたコレクション オブジェクトは、基礎となる実装として整数コレクションを使用します。
ハッシュテーブルでエンコードされたコレクション オブジェクトは、基礎となる実装として辞書を使用します。辞書の各キーは文字列オブジェクトであり、各文字列オブジェクトにはコレクション要素が含まれますが、辞書の値はすべて NULL に設定されます。
> sadd set-key item
(integer) 1
> sadd set-key item2
(integer) 1
> sadd set-key item3
(integer) 1
> sadd set-key item
(integer) 0
> smembers set-key
1) "item"
2) "item2"
3) "item3"
> sismember set-key item4
(integer) 0
> sismember set-key item
(integer) 1
> srem set-key item2
(integer) 1
> srem set-key item2
(integer) 0
> smembers set-key
1) "item"
2) "item3"
ハッシュ

ハッシュ オブジェクトのエンコーディングは、ziplist または hashtable にすることができます。
ziplist によってエンコードされたハッシュ オブジェクトは、基礎となる実装として圧縮リストを使用します。ハッシュ オブジェクトに追加される新しいキーと値のペアがあるたびに、プログラムは最初にキーを保持する圧縮リスト ノードをファイルの末尾にプッシュします。圧縮リストを選択し、値を保持する圧縮リスト ノードを圧縮リストの末尾にプッシュします。
hashtable によってエンコードされたハッシュ オブジェクトは、基礎となる実装として辞書を使用し、ハッシュ オブジェクト内の各キーと値のペアは辞書のキーと値のペアに格納されます。
> hset hash-key sub-key1 value1
(integer) 1
> hset hash-key sub-key2 value2
(integer) 1
> hset hash-key sub-key1 value1
(integer) 0
> hgetall hash-key
1) "sub-key1"
2) "value1"
3) "sub-key2"
4) "value2"
> hdel hash-key sub-key2
(integer) 1
> hdel hash-key sub-key2
(integer) 0
> hget hash-key sub-key1
"value1"
> hgetall hash-key
1) "sub-key1"
2) "value1"
注文されたセット
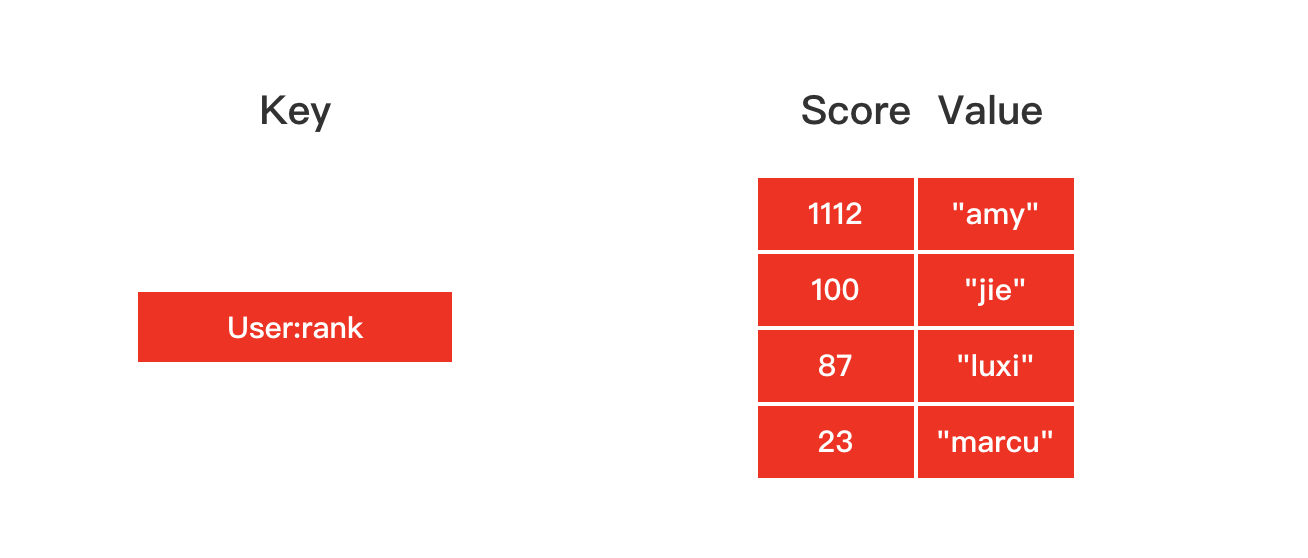
順序付けされたコレクション オブジェクトのエンコードは、ziplist または Skiplist にすることができます。
ziplist によってエンコードされた順序付きコレクション オブジェクトは、基礎となる実装として圧縮リストを使用します。各コレクション要素は、隣り合う 2 つの圧縮リスト ノードによって保存されます。最初のノードは要素のメンバーを保存し、2 番目のノードは要素のスコアを保存します。要素。
Skiplist によってエンコードされた順序付きコレクション オブジェクトは、基盤となる実装として zset 構造を使用し、zset 構造には辞書とスキップ リストが同時に含まれます。
> zadd zset-key 728 member1
(integer) 1
> zadd zset-key 982 member0
(integer) 1
> zadd zset-key 982 member0
(integer) 0
> zrange zset-key 0 -1 withscores
1) "member1"
2) "728"
3) "member0"
4) "982"
> zrangebyscore zset-key 0 800 withscores
1) "member1"
2) "728"
> zrem zset-key member1
(integer) 1
> zrem zset-key member1
(integer) 0
> zrange zset-key 0 -1 withscores
1) "member0"
2) "982"
基礎となるデータ構造
単純な動的文字列
struct sdshdr {
// 记录 buf 数组中已使用字节的数量
// 等于 SDS 所保存字符串的长度
int len;
// 记录 buf 数组中未使用字节的数量
int free;
// 字节数组,用于保存字符串
char buf[];
};
図 2-1 に SDS の例を示します。
- free 属性の値は 0 です。これは、この SDS が未使用のスペースを割り当てていないことを意味します。
- len 属性の値は 5 です。これは、この SDS が 5 バイトの文字列を保存することを意味します。
- buf 属性は char 型の配列です。配列の最初の 5 バイトには 5 つの文字「R」、「e」、「d」、「i」、「s」がそれぞれ格納され、最後のバイトには Null が格納されます。文字「\0」。
[外部リンク画像の転送に失敗しました。ソース サイトには盗難防止リンク メカニズムがある可能性があります。画像を保存して直接アップロードすることをお勧めします (img-ax80qTIF-1603168774641)(https://raw.githubusercontent.com/haxianhe/) pic/master/image/20200506153334 .png)]
リンクされたリスト
各リンク リスト ノードは、adlist.h/listNode 構造によって表されます。
typedef struct listNode {
// 前置节点
struct listNode *prev;
// 后置节点
struct listNode *next;
// 节点的值
void *value;
} listNode;
図 3-1 に示すように、複数の listNode は、prev ポインタと next ポインタを介して両端リンク リストを形成できます。

Redis のリンク リスト実装の特徴は次のように要約できます。
- ダブルエンド: リンク リスト ノードには前ポインタと次ポインタがあり、ノードの前ノードと後ノードを取得する複雑さは O(1) です。
- 非巡回: ヘッド ノードの prev ポインタとテール ノードの next ポインタが両方とも NULL を指し、リンク リストへのアクセスは NULL で終了します。
- 先頭ポインタと末尾ポインタを使用する場合: リスト構造の先頭ポインタと末尾ポインタを使用して、連結リストの先頭ノードと末尾ノードを取得するプログラムの複雑さは O(1) です。
- リンク リスト長カウンタを使用する場合: プログラムはリスト構造の len 属性を使用して、リストが保持するリンク リスト ノードをカウントします。リンク リスト内のノード数を取得するプログラムの複雑さは O(1) です。
- ポリモーフィズム: リンク リスト ノードは void* ポインターを使用してノード値を格納し、リスト構造内の dup、free、match の 3 つの属性を通じてノード値に型固有の関数を設定できるため、リンク リストを使用してノード値を格納できます。さまざまな種類の価値観。
辞書
dicttht は、ジッパー メソッドを使用してハッシュの衝突を解決するハッシュ テーブル構造です。
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
Redis の辞書 dict には、再ハッシュ操作の便宜のために 2 つのハッシュ テーブル dicttht が含まれています。展開するときは、一方の辞書のキーと値のペアをもう一方の辞書に再ハッシュし、スペースを解放し、完了後に 2 つの辞書の役割を交換します。
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
再ハッシュ操作は一度に完了するのではなく、段階的に完了します。これは、一度にあまりにも多くの再ハッシュ操作を実行することによるサーバーへの過剰な負荷を避けるためです。
プログレッシブ再ハッシュは、辞書の rehanadx を記録することによって行われます。これは 0 から始まり、再ハッシュするたびに増分されます。たとえば、再ハッシュでは、dict[0] を dict[1] に再ハッシュする必要があります。今回は、dict[0] の table[rebashidx] のキーと値のペアを dict[1] に再ハッシュし、テーブル[rebashidx] は null を指し、rebashidx++ を作成します。
再ハッシュ中、辞書に対して追加、削除、検索、または更新操作が実行されるたびに、プログレッシブ再ハッシュが実行されます。
プログレッシブ リハッシュを使用すると、辞書内のデータが 2 つの辞書に分散されるため、辞書の検索操作も対応する辞書で実行する必要があります。
/* Performs N steps of incremental rehashing. Returns 1 if there are still
* keys to move from the old to the new hash table, otherwise 0 is returned.
*
* Note that a rehashing step consists in moving a bucket (that may have more
* than one key as we use chaining) from the old to the new hash table, however
* since part of the hash table may be composed of empty spaces, it is not
* guaranteed that this function will rehash even a single bucket, since it
* will visit at max N*10 empty buckets in total, otherwise the amount of
* work it does would be unbound and the function may block for a long time. */
int dictRehash(dict *d, int n) {
int empty_visits = n * 10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
while (n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long) d->rehashidx);
while (d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while (de) {
uint64_t h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}
ジャンプ台
これは、ソートされたコレクションの基礎となる実装の 1 つです。
ジャンプ テーブルは、マルチポインター順序付きリンク リストに基づいて実装されており、複数の順序付きリンク リストとみなすことができます。
[外部リンク画像の転送に失敗しました。ソース サイトにはリーチ防止メカニズムがある可能性があります。画像を保存して直接アップロードすることをお勧めします (img-kflaiIwR-1603168774642)(https://raw.githubusercontent.com/haxianhe/pic) /マスター/イメージ/20200506154158 .png)]
検索する場合は、上位層のポインタから検索を開始し、対応する区間を見つけてから、次の層に移動して検索します。以下の図は、22 を見つけるプロセスを示しています。
[外部リンク画像の転送に失敗しました。ソース サイトには盗難防止リンク メカニズムがある可能性があります。画像を保存して直接アップロードすることをお勧めします (img-ucObpoFV-1603168774643)(https://raw.githubusercontent.com/haxianhe/) pic/master/image/20200506154222 .png)]
赤黒ツリーなどのバランスの取れたツリーと比較して、ジャンプ テーブルには次の利点があります。
- バランスを保つために回転などの操作が必要ないため、挿入速度が非常に速くなります。
- 実装が簡単。
- ロックフリー操作のサポート。
整数のセット
整数セット (intset) は、Redis が整数値を保存するために使用する抽象データ構造で、int16_t、int32_t、または int64_t 型の整数値を保存でき、セット内に重複する要素がないことが保証されます。
各 intset.h/intset 構造体は整数のセットを表します。
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;
図 6-1 は、整数のセットの例を示しています。
- エンコーディング属性の値は INTSET_ENC_INT16 です。これは、整数セットの基になる実装が int16_t 型の配列であり、セットには int16_t 型のすべての整数値が格納されることを意味します。
- length 属性の値は 5 で、整数コレクションに 5 つの要素が含まれていることを示します。
- コンテンツ配列には、コレクション内の 5 つの要素が昇順で保持されます。
各コレクション要素は int16_t 型の整数値であるため、コンテンツ配列のサイズは sizeof(int16_t) * 5 = 16 * 5 = 80 ビットに等しくなります。
[外部リンク画像の転送に失敗しました。ソース サイトには盗難防止リンク メカニズムがある可能性があります。画像を保存して直接アップロードすることをお勧めします (img-I3RXVvul-1603168774644)(https://raw.githubusercontent.com/haxianhe/) pic/master/image/20200506154613 .png)]
圧縮されたリスト
圧縮リストはメモリを節約するために Redis によって開発され、特別にコード化された一連の連続したメモリ ブロックで構成されるシーケンシャル データ構造です。
圧縮リストには任意の数のノード (エントリ) を含めることができ、各ノードはバイト配列または整数値を保持できます。
図 7-1 は圧縮リストのさまざまなコンポーネントを示し、表 7-1 は各コンポーネントのタイプ、長さ、および目的を記録しています。
[外部リンク画像の転送に失敗しました。ソース サイトには盗難防止リンク メカニズムがある可能性があります。画像を保存して直接アップロードすることをお勧めします (img-SiOPfejX-1603168774644)(https://raw.githubusercontent.com/haxianhe/) pic/master/image/20200506154718 .png)]
図 7-2 は、圧縮されたリストの例を示しています。
- list zlbytes 属性の値は 0x50 (10 進数で 80) で、圧縮リストの合計長が 80 バイトであることを示します。
- リストの zltail 属性の値は 0x3c (10 進数 60) です。これは、圧縮リストの開始アドレスを指すポインタ p がある場合、オフセットを追加することで末尾ノード エントリ 3 のアドレスを計算できることを意味します。 60 をポインタ p に設定します。
- list zllen 属性の値は 0x3 (10 進数の 3) で、圧縮リストに 3 つのノードが含まれていることを示します。
[外部リンク画像の転送に失敗しました。ソース サイトには盗難防止リンク メカニズムがある可能性があります。画像を保存して直接アップロードすることをお勧めします (img-zalMscrT-1603168774645)(https://raw.githubusercontent.com/haxianhe/) pic/master/image/20200506154848 .png)]
使用するシーン
キャッシュ
ホットスポット データをメモリに配置し、メモリの最大使用量とキャッシュのヒット率を確保するための排除戦略を設定します。
雷控除在庫
ホームページのトラフィックのピーク
セッションキャッシュ
Redis を使用すると、複数のアプリケーション サーバーのセッション情報を均一に保存できます。
アプリケーション サーバーがユーザーのセッション情報を保存しなくなると、アプリケーション サーバーには状態がなくなり、ユーザーは任意のアプリケーション サーバーをリクエストできるようになり、高可用性とスケーラビリティを実現しやすくなります。
ログイン情報
Redis を使用して、ユーザーのログイン情報をキャッシュできます。
分散ロック
分散シナリオでは、スタンドアロン環境のロックを使用して複数のノード上のプロセスを同期することはできません。
Redis に付属の SETNX コマンドを使用して分散ロックを実装できます。最初に setnx を使用してロックを競合し、次に、expired を使用してロックの解放忘れを防ぐためにロックに有効期限を追加します。
setnx 後に Expired を実行する前に、プロセスが予期せずクラッシュしたり、メンテナンスのために再起動する必要がある場合はどうなりますか?
set の nx および timeout パラメータを設定したり、setnx と Expired を 1 つのコマンドに結合したりできます。
他の
Set は共通の友人などの機能を実現するために交差や結合などの操作を実装できます。
ZSet は秩序ある操作を実現し、リーダーボードなどの機能を実現します。
キャッシュなだれ、キャッシュペネトレーション、キャッシュブレークダウン
キャッシュ雪崩
同時に、広い範囲でキャッシュに障害が発生し、リクエストにより DB が破壊されます。
解決:
- キャッシュ時間のパースペクティブを設定するときにランダムな値を追加して、広い領域で同時にキャッシュが失敗しないようにします。
- マルチレベルキャッシュを設定する
キャッシュの侵入
キャッシュとデータベースに存在しないデータを継続的に要求するため、データベースに過剰な負荷がかかり、データベースが破損します。
解決:
- パラメータチェック
- ブルームフィルター
キャッシュの内訳
大量のリクエストがホット データにアクセスし続けます。ホット データ キャッシュに障害が発生した瞬間に、大量のリクエストがデータベースにヒットし、データベースが破壊されます。
解決;
- ホットスポット データが期限切れにならないように設定する
- ミューテックスを追加する
高可用性
持久化
Redis はインメモリ データベースであり、停電後にデータが失われないようにするには、メモリ内のデータをハードディスクに保存する必要があります。
RDB 永続性は、指定された間隔でデータセットのポイントインタイム スナップショットを実行します。
AOF 永続性は、サーバーが受信したすべての書き込み操作をログに記録します。この操作はサーバーの起動時に再度実行され、元のデータセットが再構築されます。コマンドは、Redis プロトコル自体と同じ形式を使用して、追加専用の方法でログに記録されます。Redis は、ログが大きくなりすぎるとバックグラウンドでログを書き換えることができます。
RDBの永続性
動作原理
Redis は fork() を呼び出して子プロセスを生成します。子プロセスはデータを一時ファイルに書き込みます。子プロセスが新しい RDB ファイルの書き込みを完了すると、古い RDB ファイルを置き換えます。
アドバンテージ
- RDB は、Redis データの非常にコンパクトな単一ファイルのポイントインタイム表現です。RDB ファイルはバックアップに最適です。たとえば、最新の 24 時間については 1 時間ごとに RDB ファイルをアーカイブし、30 日間毎日 RDB スナップショットを保存したい場合があります。これにより、災害が発生した場合に、異なるバージョンのデータ セットを簡単に復元できます。
- RDB は災害復旧に非常に適しており、単一のコンパクトなファイルであり、遠くのデータセンターや Amazon S3 (おそらく暗号化されている) に転送できます。
- Redis の親プロセスが永続化するために必要な作業は、残りのすべてを実行する子をフォークすることだけであるため、RDB は Redis のパフォーマンスを最大化します。親インスタンスはディスク I/O などを実行しません。
- RDB では、AOF と比較して大規模なデータセットをより高速に再起動できます。
RDB の永続性はバックアップに非常に適しています。
欠点がある
- Redis が動作しなくなった場合 (停電後など)、データ損失の可能性を最小限に抑える必要がある場合、RDB は適していません。RDB が生成されるさまざまなセーブ ポイントを構成できます (たとえば、少なくとも 5 分後、データ セットに対して 100 回の書き込みが行われた後などですが、複数のセーブ ポイントを持つことができます)。ただし、通常は 5 分以上ごとに RDB スナップショットを作成するため、何らかの理由で適切にシャットダウンせずに Redis が動作を停止した場合には、最新のデータが数分間失われることを覚悟しておく必要があります。
- RDB は、子プロセスを使用してディスク上に永続化するために、頻繁に fork() を行う必要があります。データセットが大きい場合、Fork() は時間がかかる可能性があり、データセットが非常に大きく CPU パフォーマンスが高くない場合、Redis が数ミリ秒、さらには 1 秒間クライアントへのサービスを停止する可能性があります。AOF も fork() する必要がありますが、耐久性を犠牲にすることなくログを書き換える頻度を調整できます。
-
システム障害が発生した場合、最後に作成されたスナップショットのデータは失われます。
-
RDB は fork() を使用してデータ永続化のための子プロセスを生成します。データが比較的大きい場合は時間がかかり、Redis が数ミリ秒間サービスを停止する可能性があります。データ量が多く、CPU のパフォーマンスがあまり良くない場合、サービスの停止時間が 1 秒に達する場合もあります。
AOF の永続性
動作原理
AOF ファイル (追加専用ファイル) の最後に書き込みコマンドを追加します。
AOF 永続性を使用するには、書き込みコマンドがディスク ファイルと確実に同期されるように同期オプションを設定する必要があります。これは、ファイルに書き込むと内容がすぐにディスクに同期されず、まず内容がバッファに保存され、その後オペレーティング システムがいつディスクに同期するかを決定するためです。次の同期オプションがあります。
| オプション | 同期周波数 |
|---|---|
| いつも | すべての書き込みコマンドは同期されます |
| 毎秒 | 毎秒同期する |
| いいえ | いつ同期するかを OS に決定させる |
- always オプションを使用すると、サーバーのパフォーマンスが大幅に低下します。
- Everysec オプションの方が適切です。これにより、システムがクラッシュしたときに失われるデータはわずか 1 秒だけであり、Redis はサーバーのパフォーマンスにほとんど影響を与えずに 1 秒ごとに同期を実行します。
- no オプションではサーバーのパフォーマンスはあまり向上せず、システムがクラッシュしたときに失われるデータの量も増加します。
サーバーの書き込みリクエストが増加するにつれて、AOF ファイルはますます大きくなります。Redis は、AOF ファイル内の冗長な書き込みコマンドを削除できる、AOF を書き換える機能を提供します。
アドバンテージ
- AOF Redis を使用すると耐久性が大幅に向上します。さまざまな fsync ポリシーを使用できます。fsync をまったく使用しない、fsync を毎秒実行する、クエリごとに fsync を実行するなどです。fsync のデフォルト ポリシーである 1 秒ごとの書き込みパフォーマンスは依然として優れています (fsync はバックグラウンド スレッドを使用して実行され、fsync が進行中でないときはメイン スレッドが懸命に書き込みを実行しようとします)。しかし、損失できるのは 1 秒分の書き込みだけです。
- AOF ログは追加専用のログであるため、停電が発生してもシークや破損の問題は発生しません。何らかの理由 (ディスクがいっぱいであるなどの理由) でログが書きかけのコマンドで終わっている場合でも、redis-check-aof ツールで簡単に修正できます。
- Redis は、AOF が大きくなりすぎると、バックグラウンドで AOF を自動的に書き換えることができます。Redis が古いファイルへの追加を継続している間、現在のデータセットの作成に必要な最小限の操作セットで完全に新しいファイルが生成され、この 2 番目のファイルの準備ができると、Redis は 2 つのファイルを切り替えて追加を開始するため、書き換えは完全に安全です。新しいもの。
- AOF には、理解しやすく解析しやすい形式で、すべての操作のログが次々に含まれます。AOF ファイルを簡単にエクスポートすることもできます。たとえば、FLUSHALL コマンドを使用してエラーのためにすべてをフラッシュした場合でも、その間にログの書き換えが実行されなかった場合は、サーバーを停止し、最新のコマンドを削除して、Redis を再度再起動するだけでデータセットを保存できます。
- データを復元する必要がある場合に失われるデータが少なくなります (どれだけ失われるかは同期戦略によって異なります)
- AOF ファイルが大きすぎる場合、Redis はバックグラウンドで自動的にファイルを書き換えます。
欠点がある
- 通常、AOF ファイルは、同じデータセットの同等の RDB ファイルよりも大きくなります。
- 正確な fsync ポリシーによっては、AOF は RDB よりも遅くなる可能性があります。一般に、fsync を 1 秒ごとに設定してもパフォーマンスは非常に高く、fsync を無効にすると、高負荷下でも RDB とまったく同じ速度になるはずです。それでも、RDB は、書き込み負荷が膨大な場合でも、最大レイテンシーについてより多くの保証を提供できます。
- AOF ファイルは RDB ファイルよりも大きいです
- AOF 永続化は、RDB 永続化よりも時間がかかります。
推奨事項
一般的に、PostgreSQL が提供するものと同等のデータ安全性が必要な場合は、両方の永続化メソッドを使用する必要があります。
データを非常に重視しているが、災害が発生した場合に数分間のデータ損失が許容される場合は、単純に RDB のみを使用できます。
AOF のみを使用するユーザーはたくさんいますが、RDB スナップショットを時々取得することは、データベースのバックアップを実行したり、再起動を高速化したり、AOF エンジンにバグが発生した場合に備えて優れたアイデアであるため、AOF のみを使用することはお勧めしません。
注: これらすべての理由により、将来的には AOF と RDB を単一の永続化モデルに統合することになる可能性があります (長期計画)。
- 最高のデータセキュリティを確保したい場合は、両方を使用してください。
- 数分間のデータの損失を許容できる場合は、永続化のために RDB を使用するだけで済みます。
- 永続化のために AOF を単独で使用することはお勧めできません
参考文献
- 例によるブルームフィルター
- Redis Bloomフィルター実戦「キャッシュ破壊、雪崩効果」
- Redis Bloom Filterの使い方と注意点
- CS-Notes-redis
- Javaファミリー-redis
- Redis の永続化
記事は継続的に更新されており、WeChatで「荒廃した古代伝説」を検索するとすぐに読むことができます。