目次
1. 基本的な使い方
インターネット上にはこれを使用する方法がたくさんありますが、find_element_by_xpath私が使用した比較的selenium新しい方法によると、webdriverこの方法はもう使用できないため、find_element_by_xpath代わりに使用する必要がありますfind_element(By.XPATH,'A XPATH Value')。
web_element = driver.find_element(By.XPATH,'A XPATH Value')
2.xpathについて
(1) Webページからxpathをコピーします。
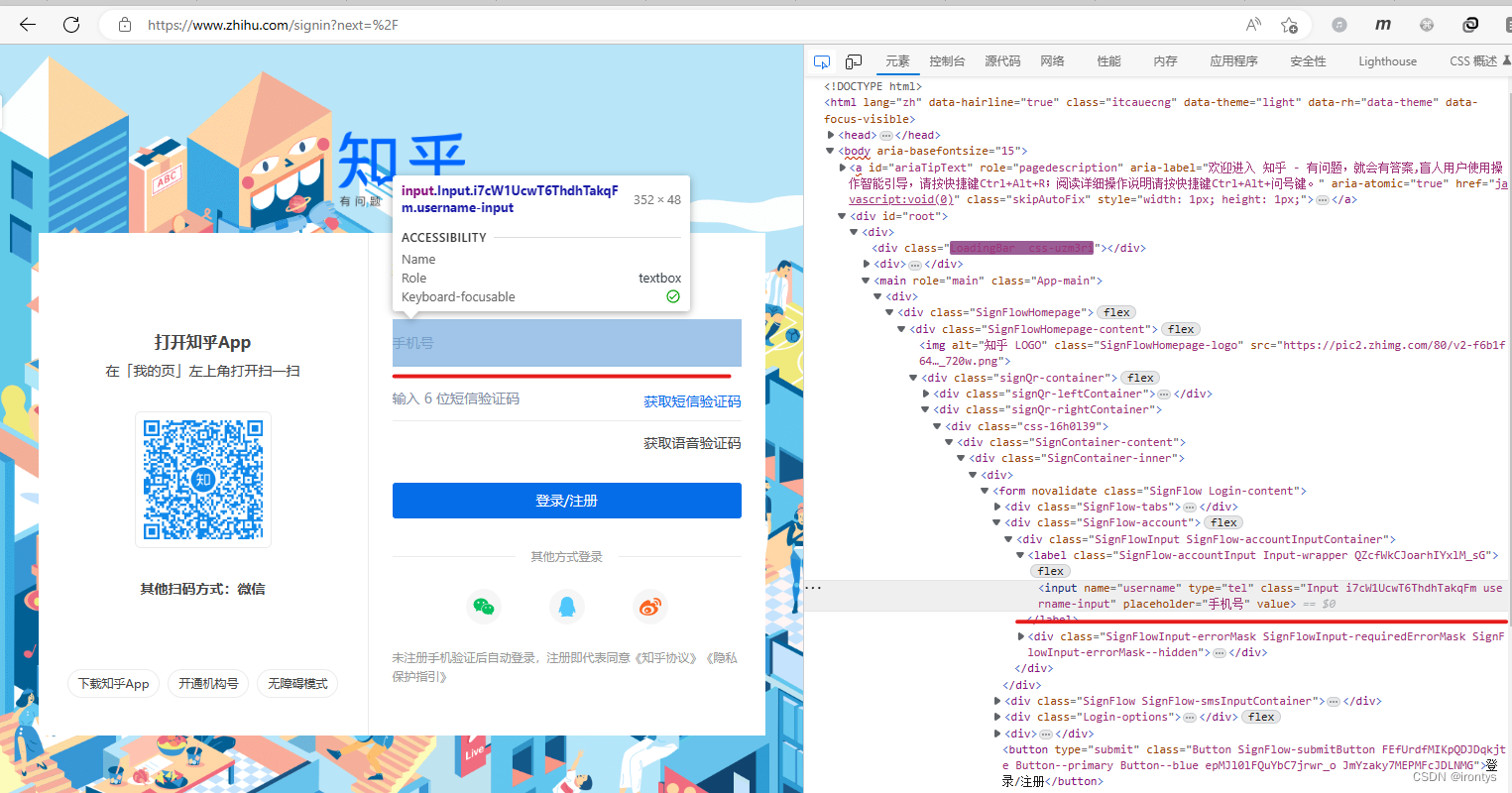
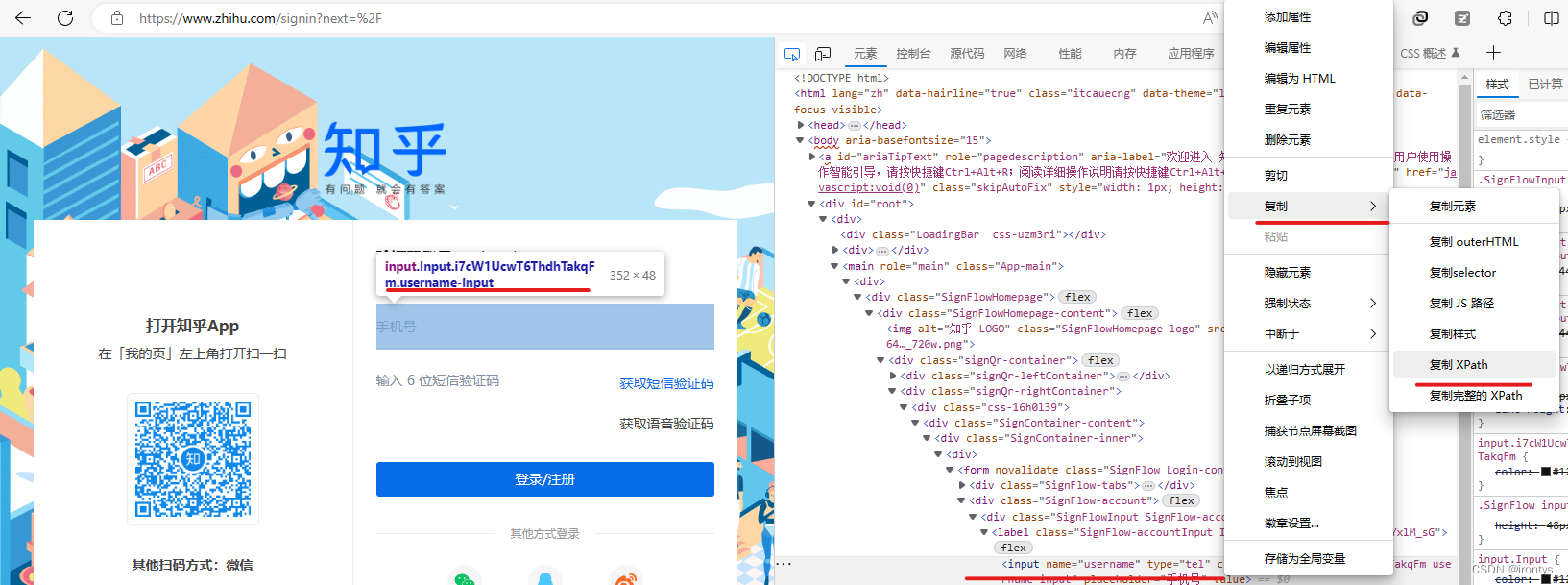
この記事で使用されている愚かな xpath 値は、次のような xpath の使用です。Webページの左上隅にあるアイコンを
直接クリックし、要素をクリックすると、ソース コード内の場所が右側に表示されます。ソース コード の位置を右クリックすると xpath を取得できますが、ソース コードが変更されると xpath も変更される可能性があるため、この種の xpath は「良くありません」F12
(2) xpath がなぜこのようになるのか
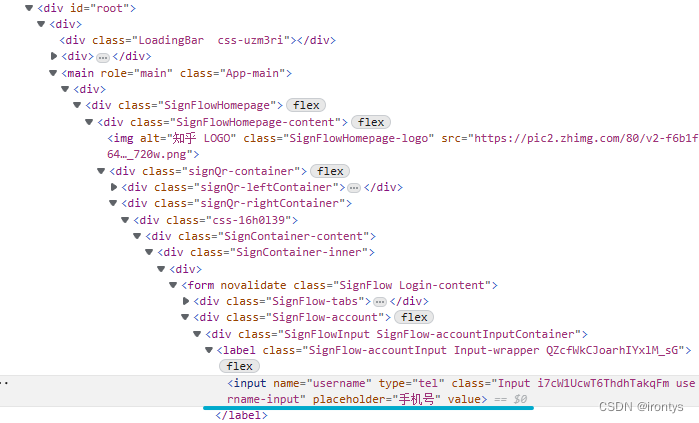
まず、先ほど述べた xpath の簡単な分析を実行します。
//*[@id="root"]/div/main/div/div/div/div/div[2]/div/div[1]/div/div[1]/form/div[2]/div/label/input
username = self.driver.find_element(By.XPATH,'//*[@id="root"]/div/main/div/div/div/div/div[2]/div/div[1]/div/div[1]/form/div[2]/div/label/input').text
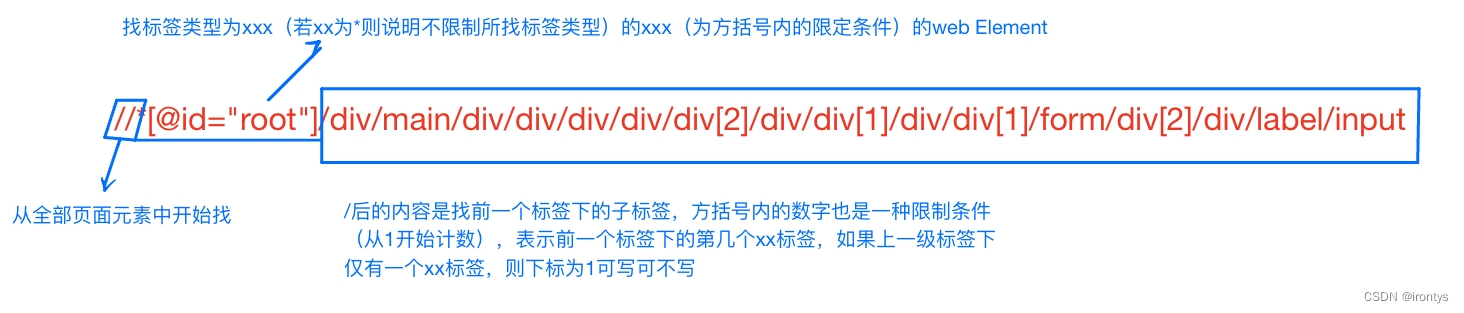
上記の xpath は、上記の python3 ステートメントと組み合わせると、次のように解釈できます。 this ではself.driver、web elementすべてのタグの中から (最初のタグのため//)、最初のタグを見つけます (find_element メソッドが使用されているため、これは後で展開されます)。は tag 属性の id で、その値は*「root」の任意の ( ため) タグ、その下の最初の div タグ、その下の最初の div タグ、その下の最初の div タグ*4、その下の 2 番目の div タグです。 it div タグの下の最初の label タグ、その下の最初の input タグなので、input タグが最終的に見つかります。
3. ニーズに応じて xpath をカスタマイズする
(1) 複数の xpath メソッドを同じ HTML タグに対応させることができます
xpath の原理をほぼ理解した後は、必要に応じて xapth を設計し、上記の xpath をどのように記述するかが可能です。
①変更
//*[@id="root"]/div/main/div/div/div/div/div[2]/div/div[1]/div/div[1]/form/div[2]/div/label/input
:
//div[@id="root"]/div/main/div/div/div/div/div[2]/div/div[1]/div/div[1]/form/div[2]/div/label/input
これはほんの小さな変更です。
② 別の例は、
タグの完全な xpath 値です。
/html/body/div[1]/div/main/div/div/div/div/div[2]/div/div[1]/div/div[1]/form/div[2]/div/label/input
と/html/body/div[1]は//div[@id="root"]同じであり、相互に置き換えることができます。
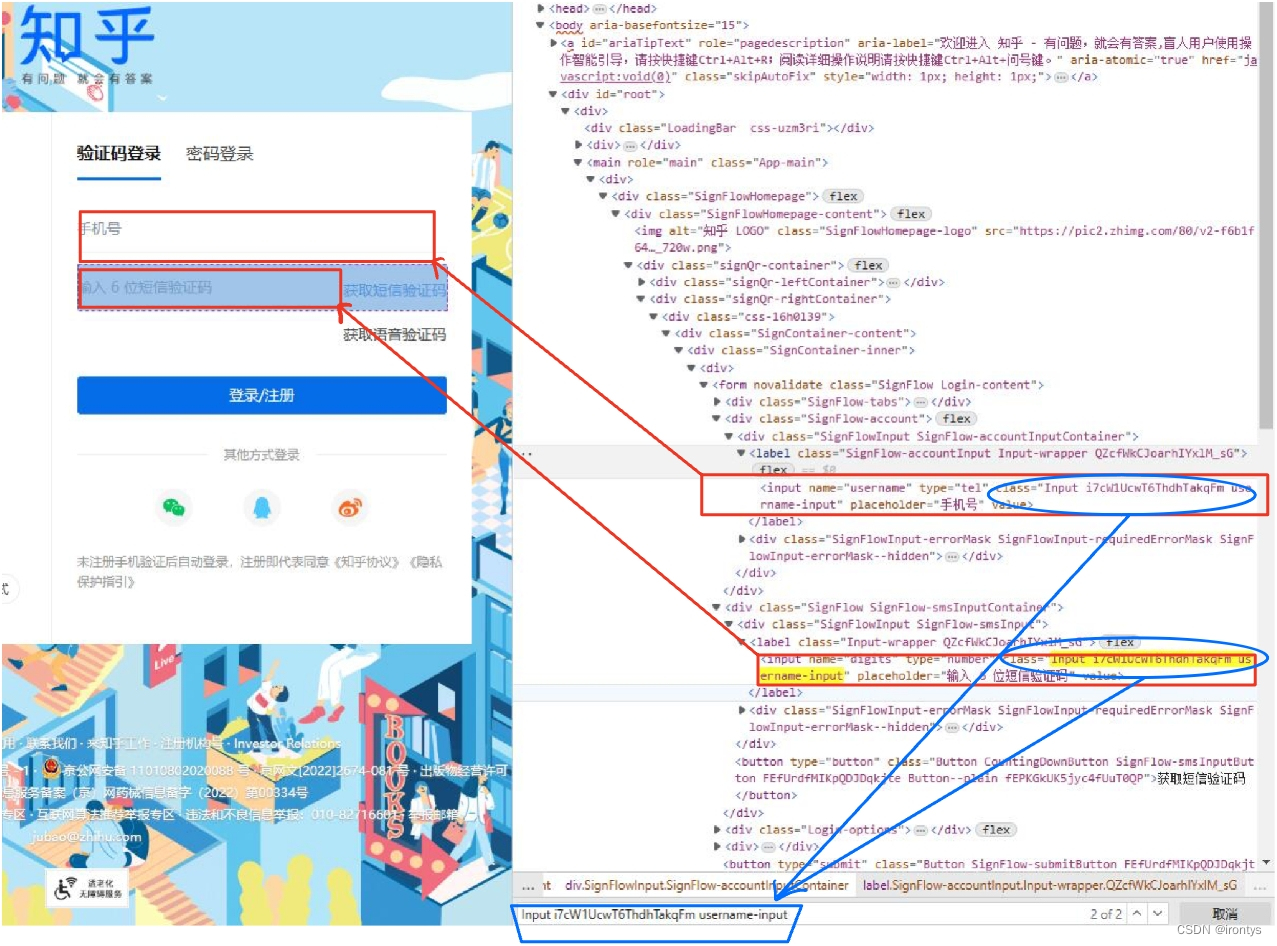
(2) タグの属性情報に従ってカスタムxpath値を取得する
input上記のタグには という属性があることがわかりますclass。これはvalue、"Input i7cW1UcwT6ThdhTakqFm username-input" コンソールでctrl+F検索した後Input i7cW1UcwT6ThdhTakqFm username-input、 を持つタグが 2 つだけ(またはこの条件を満たす入力タグが 2 つ)あることがわかりますclass="Input i7cW1UcwT6ThdhTakqFm username-input"。入力モバイルを取得したいと考えています。電話番号 対応する xpath (以下の Python コードで使用) は次のように設計できます。
phone_number = self.driver.find_element(By.XPATH,'XPATH')
//input[@class="Input i7cW1UcwT6ThdhTakqFm username-input"]
または
//*[@class="Input i7cW1UcwT6ThdhTakqFm username-input"]
、意味は次のとおりです:self.driver最初のclass="Input i7cW1UcwT6ThdhTakqFm username-input"(制限された条件、無視しない@) input タグを検索します (この場合、*(任意のタグ) にすることができます)
上で述べたように、コンソールによってコピーされた xpath は一般にあまり良好ではありません (in私の意見)、ソース コードに何らかの変更があった場合、xpath を変更することは可能ですが、特定のタグの属性は通常は変更されないため、ソース コードの変更に直面した場合のコードのフォールト トレランスが向上します。 Webページのソースコード。
(3) 特定の xpath 条件を満たすすべての Web 要素要素を取得します
label 属性に従ってカスタマイズされた上記の xpath 値を使用すると、特定の xpath 条件を満たす Web 要素のすべての要素を一度に取得できます。これは、類似したデータをバッチで処理する場合に非常に便利です。上記の例では、次のことが必要です。携帯電話番号を入力した後に確認コードを入力する まだ find_element メソッドと完全な xpath メソッドを使用している場合は、次のような Python ステートメントを設計する必要がある場合があります。
phone_number = self.driver.find_element(By.XPATH,'//*[@id="root"]/div/main/div/div/div/div/div[2]/div/div[1]/div/div[1]/form/div[2]/div/label/input')
code = self.driver.find_element(By.XPATH,'//*[@id="root"]/div/main/div/div/div/div/div[2]/div/div[1]/div/div[1]/form/div[3]/div/label/input')
Web ページ上の xpath 値をコピーする必要があるたびに、
label 属性に従って xpath 値をカスタマイズする上記の方法を使用すると、次の Python コードを設計できます。
input_list = self.driver.find_elements(By.XPATH,'//input[@class="Input i7cW1UcwT6ThdhTakqFm username-input"]')
phone_number = input_list[0]
code = input_list[1]
self.driverfind_elements メソッドが使用され (find_element とは異なり、find_element は find_elements[0] です)、その戻り値は Web 要素のリストです。上記のコードの意味は次のとおりです: input_list は、このweb element下のclass="Input i7cW1UcwT6ThdhTakqFm username-input"すべてを含むweb elementリストです
(4) 相対パス + xpath 値

ユーザーのすべての回答情報のうち、承認数やタイトル情報、内容情報などを取得する必要がある場合もありますが、もちろん次のようなコードを書くことも可能です。
agree_list = self.driver.find_elements(By.XPATH,'//Button[@class="Button VoteButton VoteButton--up FEfUrdfMIKpQDJDqkjte"]/span')
titles = ....
content = ...
......
for index,agree_info in enumerate(agree) :
agree = agree_list[i]
title = titles[i]
....
class="Button VoteButton VoteButton--up FEfUrdfMIKpQDJDqkjte"]ただし、回答情報に複数の(同意ボタン)がある場合は、不適切な例を挙げてください。
下の図の下線位置にあるボタンもclass="Button VoteButton VoteButton--up FEfUrdfMIKpQDJDqkjte"]解決方法ですか? (実際にはそうではありません、単なる例です)
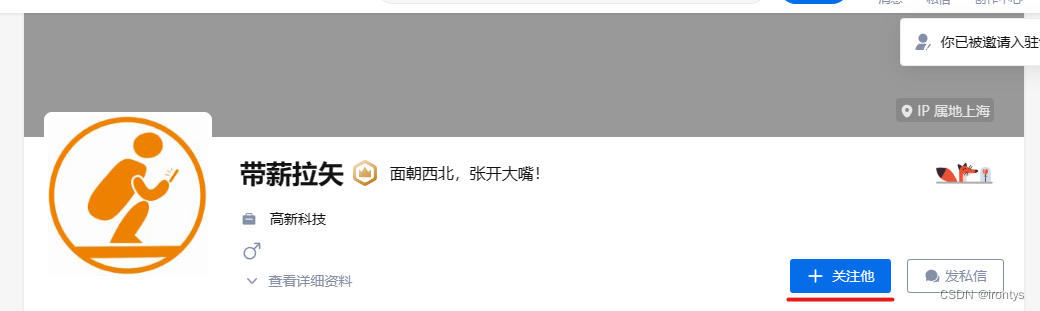
以下に考え方を示します:
あるクラスのこのメソッド
list_items = self.driver.find_elements(By.XPATH,'//div[@class="List-item"]')
for list_item in list_items :
agree = list_item.find_element(By.XPATH,'.//Button[@class="Button VoteButton VoteButton--up FEfUrdfMIKpQDJDqkjte"]/span')
...
......
注: 次のコードでは、xpath の先頭が//置き換えられ、self.driver が別の( )../に置き換えられ、この中のボタンのみが取得されます。\web elementlist_itemlist itemclass
4. xpath に対応する要素が表示されるのを暗黙的に待ちます。
ネットワーク速度の問題により、ページが完全に読み込まれるfind_element前に Python ファイルが他のメソッドを実行し、プログラムがエラーを報告して異常終了することを防ぐために、次のステートメントを使用して、xpath に対応する要素が表示されるのを待つことができます。 :
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
WebDriverWait(self.driver,10000).until(EC.presence_of_element_located((By.XPATH, 'XPATH')))
このうち、1000 は設定された最長の待機時間です。xpathタイムアウトに対応する要素がまだ表示されない場合、プログラムはエラーを報告します。使用した方法と比較して、この方法の利点は、対応する要素がsleep表示された後であることです。ページが表示された後、プログラムがまだ実行を待機しているという問題xpathなく、プログラムの実行が迅速に続行されます。xpath
5.WEBELEMENT.click()非表示(現在のビューに表示されていない)要素をクリックできない場合の解決方法
次のステートメントを使用できます
self.driver.execute_script("arguments[0].click();", web_element_clickable)
そのうちの1 つはweb_element_clickableクリック可能ですweb_element。
6. ページには一度にすべてのコンテンツが読み込まれません。
もう 1 つは、ページには一度にすべてのコンテンツが読み込まれるわけではありません。さらに多くのコンテンツを読み込むには、ページを下にスライドする必要があります。次の Python ステートメントを使用できます。次の例は、現在のページのコンテンツが 10 未満の場合です
。 xpath 値//div[@class="List-item"]、web element送信 条件が満たされるまでページを下にスクロールします。
ask_answers = self.driver.find_elements(By.XPATH,'//div[@class="List-item"]')
ask_answers_count = len(ask_answers)
# Scroll down until the count is at least 10
while ask_answers_count < valid_answers_count:
# Scroll by 100 pixels
self.driver.execute_script("window.scrollBy(0, 100);")
# Get the updated ask_answers_count of div elements with class "List-item"
ask_answers = self.driver.find_elements(By.XPATH,'//div[@class="List-item"]')
ask_answers_count = len(ask_answers)